4.3.1. Influence of Network Structure on Network Performance
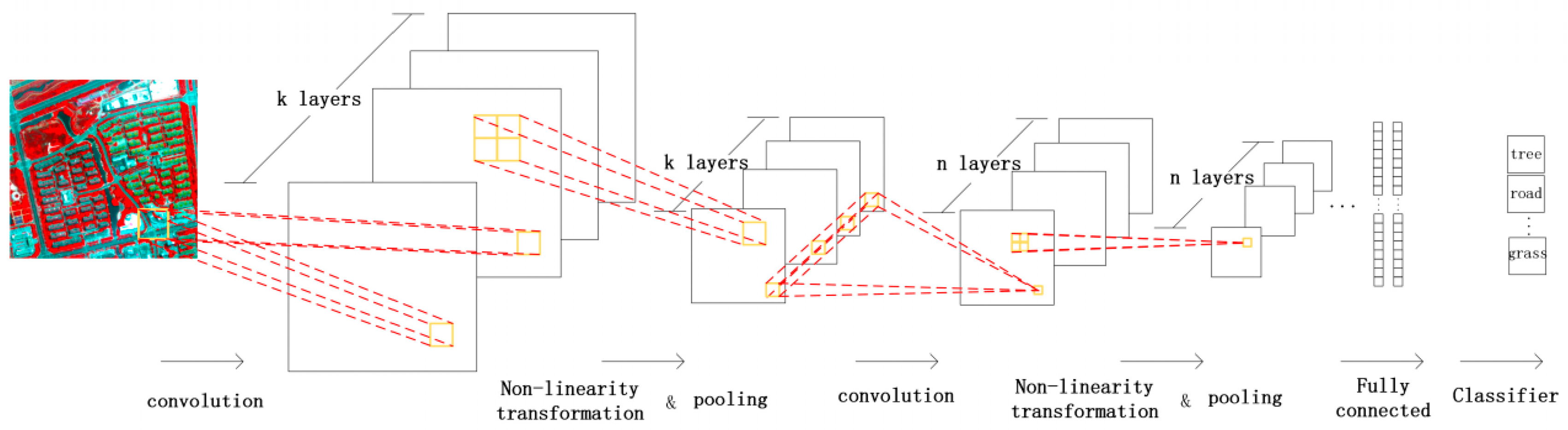
In this section, we analyze the influence of the depth of the network and the convolution kernel. For each category, 1000 labeled pixels were randomly selected from the BJ02 and GF02 images for training and validation. The remaining labeled data served as testing data.
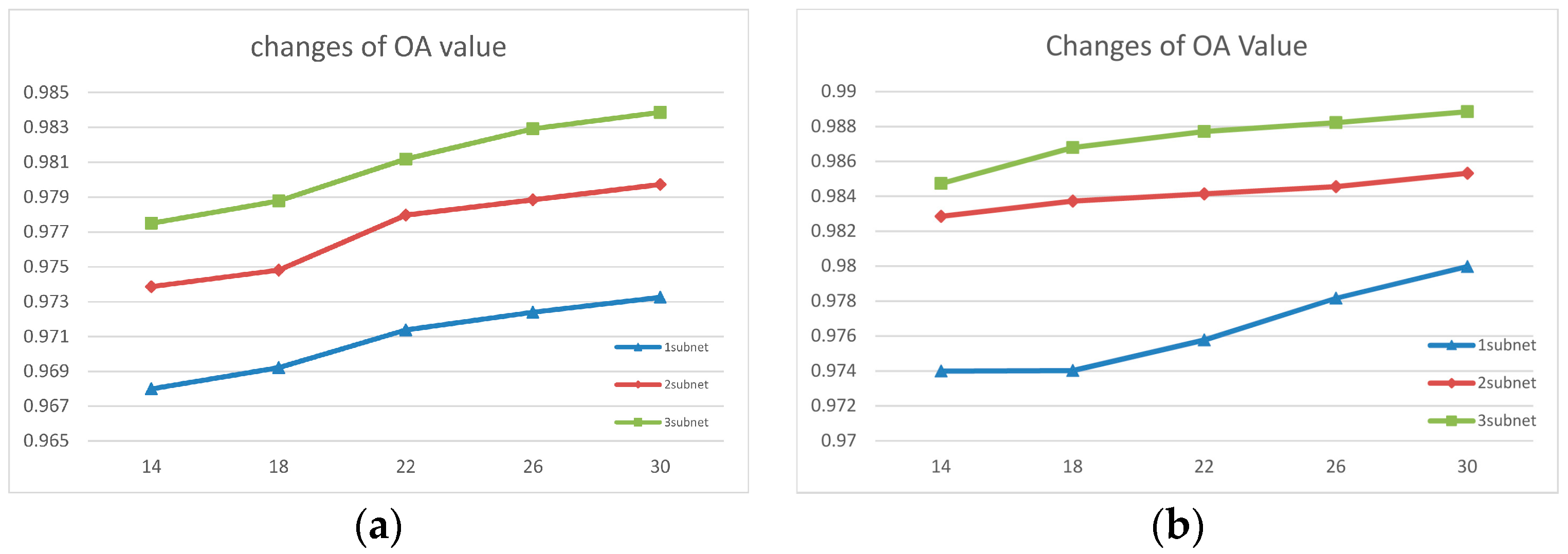
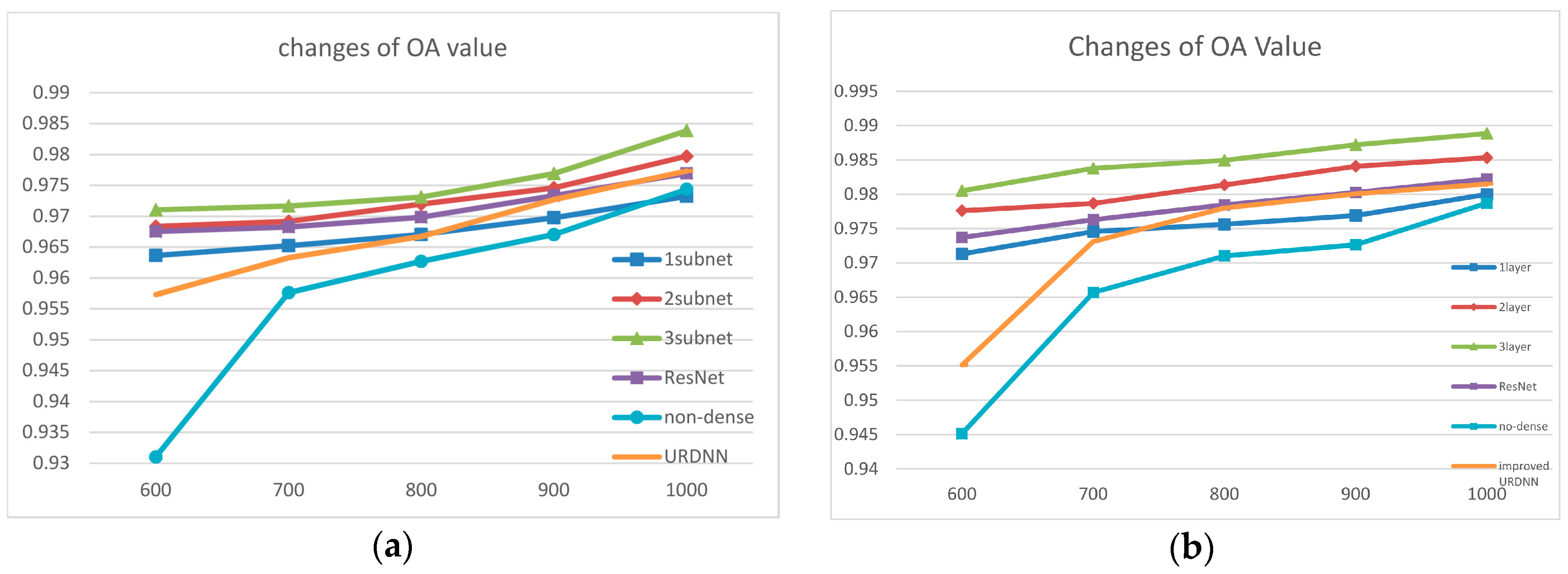
Figure 8a,b illustrate the changing of overall accuracy (OA) for two images under different network structures.
Table 2,
Table 3,
Table 4 and
Table 5 list the detailed classification results. The results were the averages of 5 runs of the experiments. We used the most popular OA and kappa as the criteria, in which OA represented the ratio of correct classified pixels to overall pixels and kappa was used for consistency check, serving as a criterion of the classification accuracy as well.
In
Figure 8, the vertical axis is the OA value, the horizontal axis is the depth of the convolution kernel. By comparing the results, it is clear that the network structure had a significant influence on the performance of the network.
We found a common trend in the classification accuracy of the BJ02 and GF02 experiments. Firstly, the accuracy of the network classification increased significantly with network depth. In particular, for the network using three subnets and one subnet, the increase in the accuracy of the network was larger than 1%. We theorize that this is because the shallow network focused more on the detailed features but those low-level features were not abstract enough. As the network went deeper, more hierarchical features were extracted. The extracted information contained not only the low-level information focusing on details but also the inherent features that were more discriminative, robust, general and representative of the nature of the ground objects. For the GF02 image, the network comprising two subnets achieved similar results when the kernel depth was small compared with the deeper networks. However, as the kernel depth increased, the difference in accuracy also increased gradually. Although it was not that obvious in the results from the BJ02 experiments, by the joint efforts of the deepest network and the deepest kernel depth (deepest in all compared experimental structures), both images achieved outstanding experimental results. This also proves to some degree that with the combination of increasing depth of network and kernels, the extracted information gets closer to the nature of data, which is the key to distinguishing the pixels from different categories.
In addition to the network depth, the kernel depth also had a significant influence on the capability of the network. The depth of the convolution kernels was the amount of feature maps generated by each convolution. In our experiments, the three-subnet network achieved accuracies higher than 97.7% and 98.4% from the BJ02 and GF02 experiments, respectively, with only 14 convolution kernels. The accuracies were very satisfactory compared with the contrast experiments. In our experiments, when the convolution kernel depth varied from 14 to 30, the accuracy increased with the increasing kernel depth. The increasing kernel depth enable generation of more feature maps, which described the ground objects from different perspectives, making it easier to determine the intrinsic differences among different ground objects and, consequently, achieved better results for ground object classification. Meanwhile, the deepest kernel depth in our experiments was 30, which is not too much to cause redundancy or a large burden for the next layer. Thus, the network performance increasing with increasing kernel depth would not be abnormal. When the depth of the convolution kernel was 30, the overall accuracy was as high as 98.4% and 98.9% under the deepest network structure. From the GF02 and BJ02 experiments, sometimes the influence on the classification accuracy caused by the changes of the kernel depth was stronger in a shallow network than in a deeper network. This might be because in the shallower network, the hierarchical features extracted by the network were insufficient to contribute much to the increase in the classification accuracy of the network. Then, the increasing in diversity of the feature maps compensated for a lack of hierarchical features and made the extracted features more discriminative.
Although employing more subnets and utilizing deeper convolution kernel depths both increased the accuracy in our experiments, it did not mean that we could increase the depth of the network indefinitely. This is because the number of parameters to be trained would increase quickly when the network became wider and deeper. There would be a risk of overfitting when the amount of training samples was small as in our experiments, even though we used some novel approaches to reduce the influence of overfitting. Further, overly many feature maps increased the probability of redundancies and may increase the computation burden in the next layer, making the increase of the classification disproportional to the increase of the feature map numbers. If the increase of accuracy is not obvious while the network training difficulty is significantly increased, then it would make no sense to deepen or widen the network.
4.3.2. Influence of Network Components on Network Performance
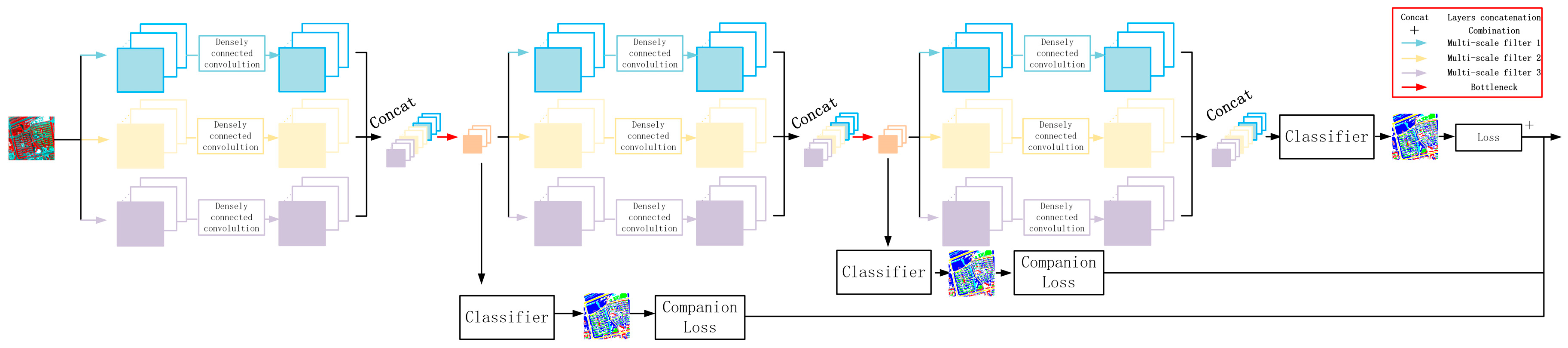
In previous sections, we discussed the reasons why using the dense concatenative convolution, multi-scale filters, as internal classifiers to construct the proposed method theoretically. Here, we use control variables to test the influences of these components, in order to verify the significance and rationality of choosing these components.
In
Table 6 and
Table 7 we display the OA, KAPPA, user accuracy and producer accuracy of each category.
(1) Influence of the multi-scale filters
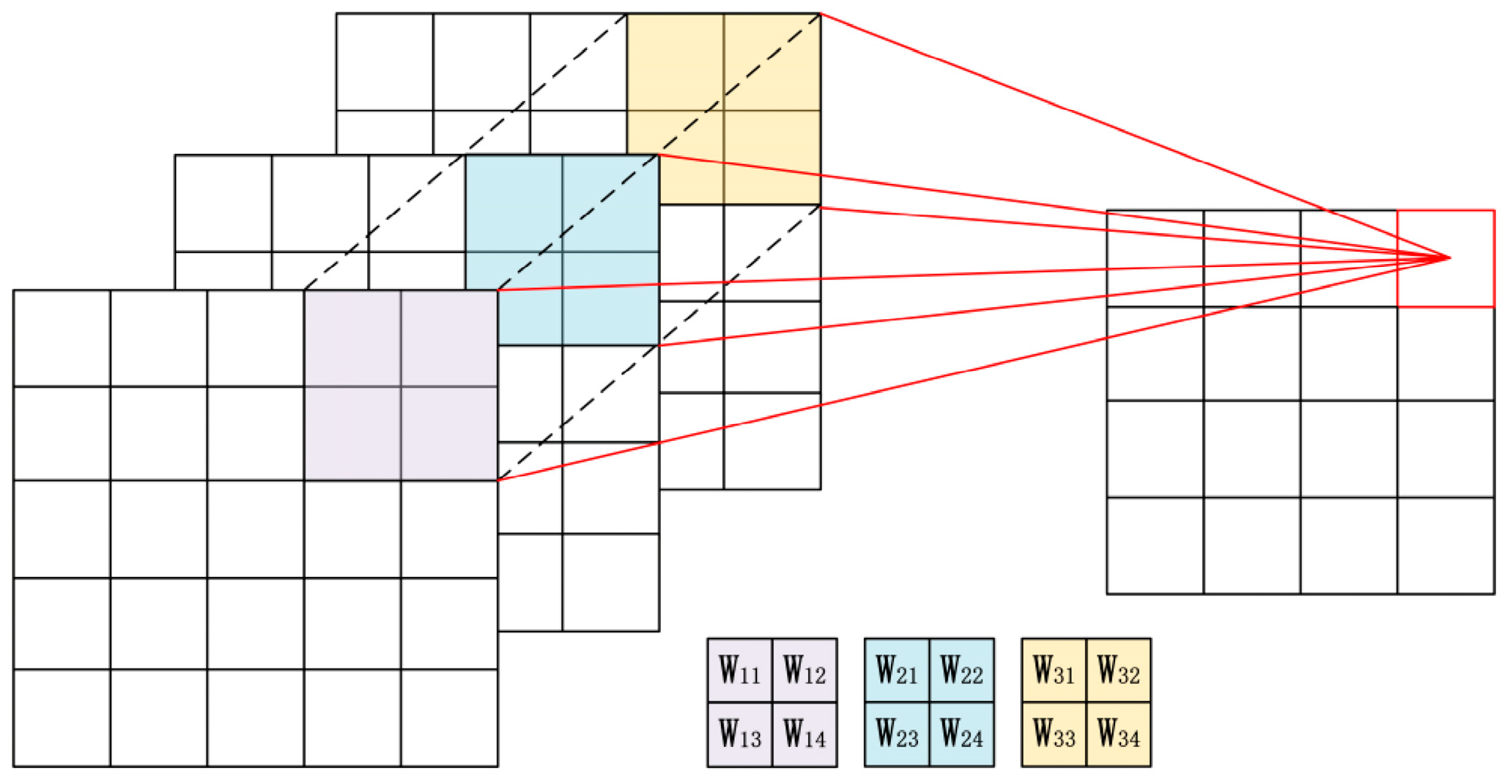
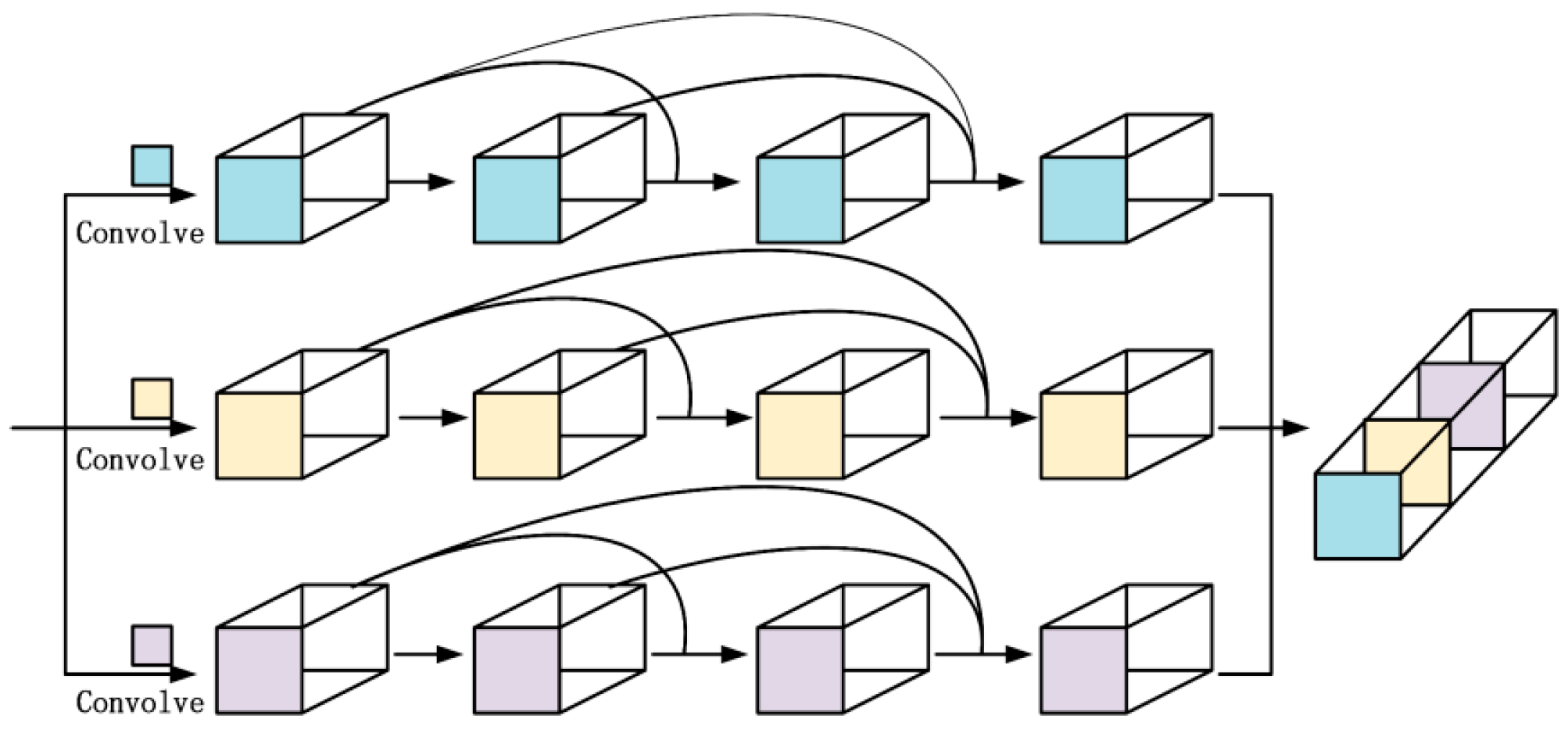
In the proposed method, we used multi-scale filters to get joint spatio-spectral information and diverse local spatial structure information. To determine the influence of multi-scale filters on the network, for both the BJ02 and GF02 experiments, we compared the proposed network with the networks using solely 1 1 kernels, 3 3 kernels, or 5 5 kernels. Those contrast experiments were implemented under the three-subnets network with filter depth of 30 and all the other parameters remained unchanged.
According to the quantitative results, firstly, the accuracy of the network with 1 1 kernels was the worst. For the BJ02 experiments, the OA was only 94.5%. Compared with the network using 3 3 or 5 5 kernels, the difference was more than 3.6%. For the GF02 experiments, OA achieved 98.5% using 5 5 kernels while it decreased to 95.6% when the 1 1 kernels were used. For both experiments, using combination of three kernels reached highest accuracy. That using 3 3 and 5 5 filters increased the accuracy significantly, indicates that the spatial structure had a significant influence. The 1 1 kernels mainly used spectral correlation information.
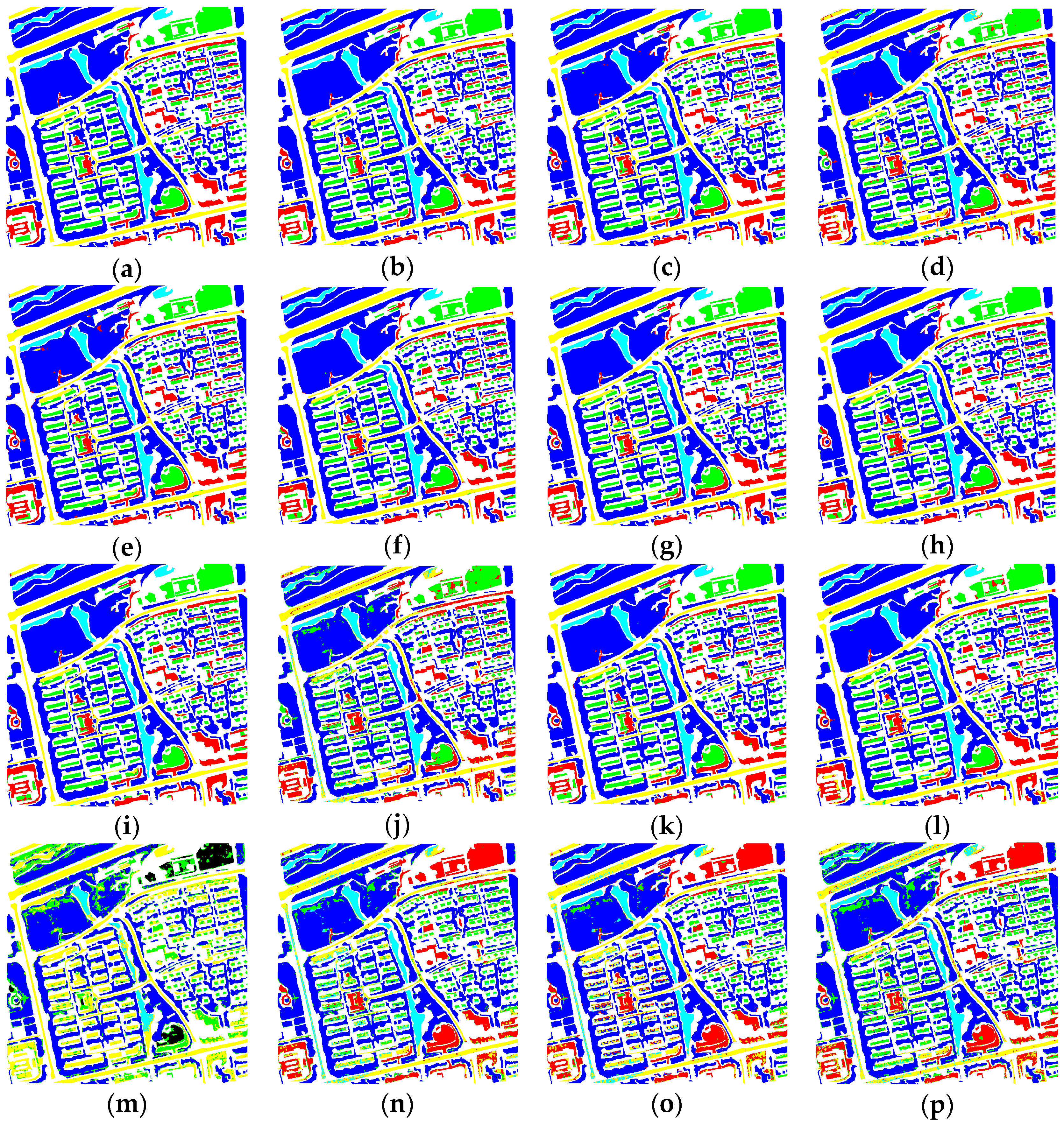
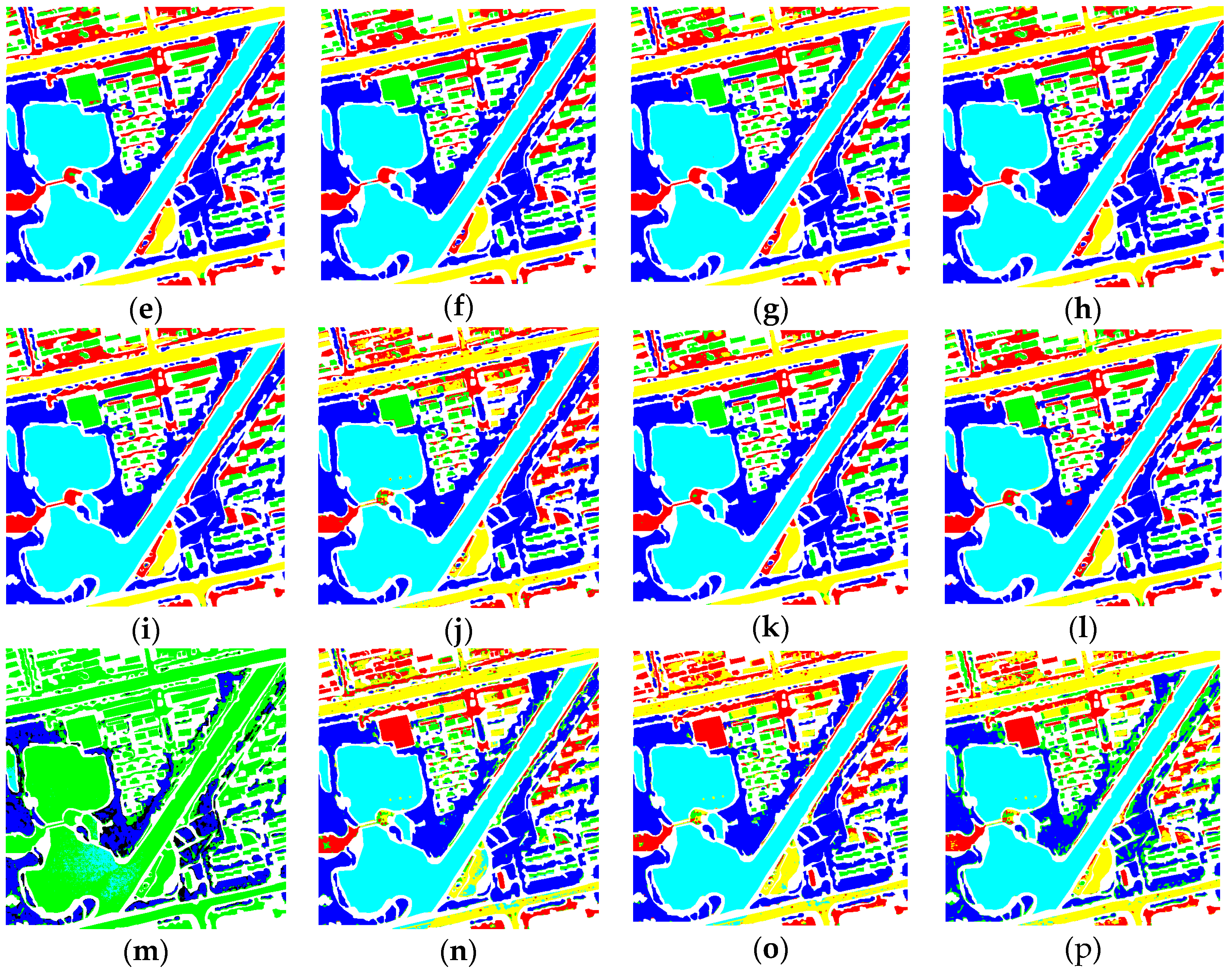
Figure 9 and
Figure 10 show the classification results from the BJ02 and GF02 experiments when using three different kinds of filters. Visually speaking, the results generated by using solely 1
1 kernels were heavily mottled. The commission errors were serious, no regardless of the inside ground objects or at the boundaries. When using the filters in larger scales, because the spatial structure information was considered, the commission and omission errors obviously decreased. For both the BJ02 and GF02 experiments, the network using 5
5 filters achieved the best result and the completeness of the ground objects was greatly improved compared with the network using other filters. Comparing these three methods with the proposed method, although the boundaries of some ground objects were mottled for the proposed method, the misclassifications between bare lands and building, bare land and roads and buildings and roads that were found in the others were significantly reduced and the results were more similar to the labeled images. We theorize that it is closely related to the joint of spatio-spectral information and the combination of diverse local structures. However, in all the methods, roads, bare lands and buildings were most likely to be misclassified compared with others. This might be because these ground objects used similar building materials; hence, those ground objects possessed similar spectral information and consequently resulted in the decrease in the classification accuracy.
(2) Influence of the internal classifier on the network
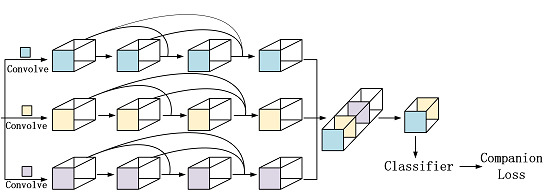
The purpose of using internal classifiers is to increase the transparency of the hidden layers. Inputting the feature maps generated by the hidden layers directly into the internal classifier to get the companion loss and then combining the companion loss with the loss from the final layer makes the features from hidden layers more discriminative, enhancing the robustness and reducing the information redundancies.
OA and KAPPA changed significantly when the network was with or without the internal classifiers. For the BJ02 experiments, OA decreased about 0.6% and KAPPA decreased 1%. With the internal classifiers removed, although the boundaries were well maintained, the completeness of the ground objects was not as good as that from using internal classifiers. There were obvious commission errors inside the ground objects. Some of them were in dots, some of them were in large areas, for example the bare lands and buildings inside the trees.
For the GF02 experiments, OA decreased 0.5% to 98.4%. KAPPA decreased 0.7% to 97.8%. From
Figure 9 clearly shows that, without the internal classifier the misclassifications between buildings and bare lands and between buildings and roads are more obvious, while the proposed methods preserved the completeness of the buildings better.
The decreased accuracy indicates that when internal classifiers are removed, the features used for the classification are not that discriminative and because the internal classifiers also had some effect on strengthening the gradients, when using the network with the internal classifiers, they could back propagate stronger feedback on gradients from different layers. Therefore, when those companion classifiers were removed, the accuracy decreased distinctly.
(3) Influence of the DenseNet on the network
We removed the densely connected convolution and utilized normal convolution instead. When the dense concatenation was removed, for two experiments, both of their OAs decreased by about 1% and KAPPAs decreased by about 1.5%. For the BJ02 experiments, according to the classification result images in
Figure 9, some pixels inside buildings or roads were misclassified as other ground objects obviously, for instance, the buildings on the right and the roads in the middle. For the GF02 experiments, from
Figure 10, some pixels inside the bare lands were obviously misclassified as roads close to the edges of the GF image.
This proves that DenseNet can make use of the advantages brought by the depth of the deep network, that deeper network possesses stronger expression ability. Because the dense concatenation reutilized the feature maps, the connections between the layers close to the input layers and output layers were shorter, which alleviated the problems harming the network performance, such as gradient disappearance, brought by the deeper network and made deepening the network more sensible.
4.3.3. Contrast Experiments with Other Networks
To test the effectiveness and practicability of the proposed method, we introduced five kinds of networks similar to the proposed method: DNN [
47], URDNN [
48], contextual deep CNN [
17], two-stream neural network [
26] and SAE + SVM [
49]. DNN uses deconvolution to realize an end-to-end, pixel-to-pixel classification. It has also become a prevalent method for per-pixel classification recently. URDNN utilizes the unsupervised network to support and control the supervised classification, using both labeled and unlabeled pixels to alleviate the overfitting problems caused by a small number of samples. We revised the original URDNN and added feature concatenation in the last layer to make it more comparable with the proposed method. Contextual deep CNN and two-stream network all rely on ResNet to reduce the problems like gradient disappearance and overfitting, which were coherent with our aim. SAE + SVM used the unsupervised method to extract features and then utilized SVM as the classifier for the classification. All the methods mentioned above were neural network algorithms. Besides neural network based methods, we also introduced some simple classification methods without using neural network for comparison, which were parallel piped, minimum distance, mahalanobis distance and maximum likelihood methods.
For the BJ02 experiment, the two networks utilizing ResNet achieved accuracies of 97.6% and 97.7%, respectively. The boundaries of the ground objects were well retained but there were some misclassifications in some small roads and inside the buildings and trees. Contextual deep CNN mainly misclassified buildings as bare lands, while the two-stream network performed well in the classification between buildings and bare lands but was prone to mix buildings with the roads. Those ground objects were similar in their spectral information. URDNN does not adopt ResNet to reduce gradient disappearance and overfitting but it utilizes the feature extraction of the unlabeled data and performed well with the classification accuracy of 97.7%. The DNN performed relatively poorly compared with the aforementioned methods. In addition to the previously mentioned misclassification, it also tended to misclassify bare lands as roads and resulted in lower classification accuracy. SAE + SVM was the only method solely relying on the unsupervised feature extraction but it performed worst.
The results from simple classification methods were much worse than what we have achieved using proposed neural network method, no matter from accuracy aspect or visual effect aspect. Some simple classification methods could do well on classifying simple ground object categories, such as water and tree. However, they seemed not to be suitable for classifying some complex or confusing categories, like bare land, building and road, which caused serious misclassification. From computational cost aspect, using such simple classification methods would be more efficient. It just needed several seconds to do the classification while we required about 4 h to train our network. But this efficiency could not compensate their deficiency in VHRRS image per-pixel classification accuracy.
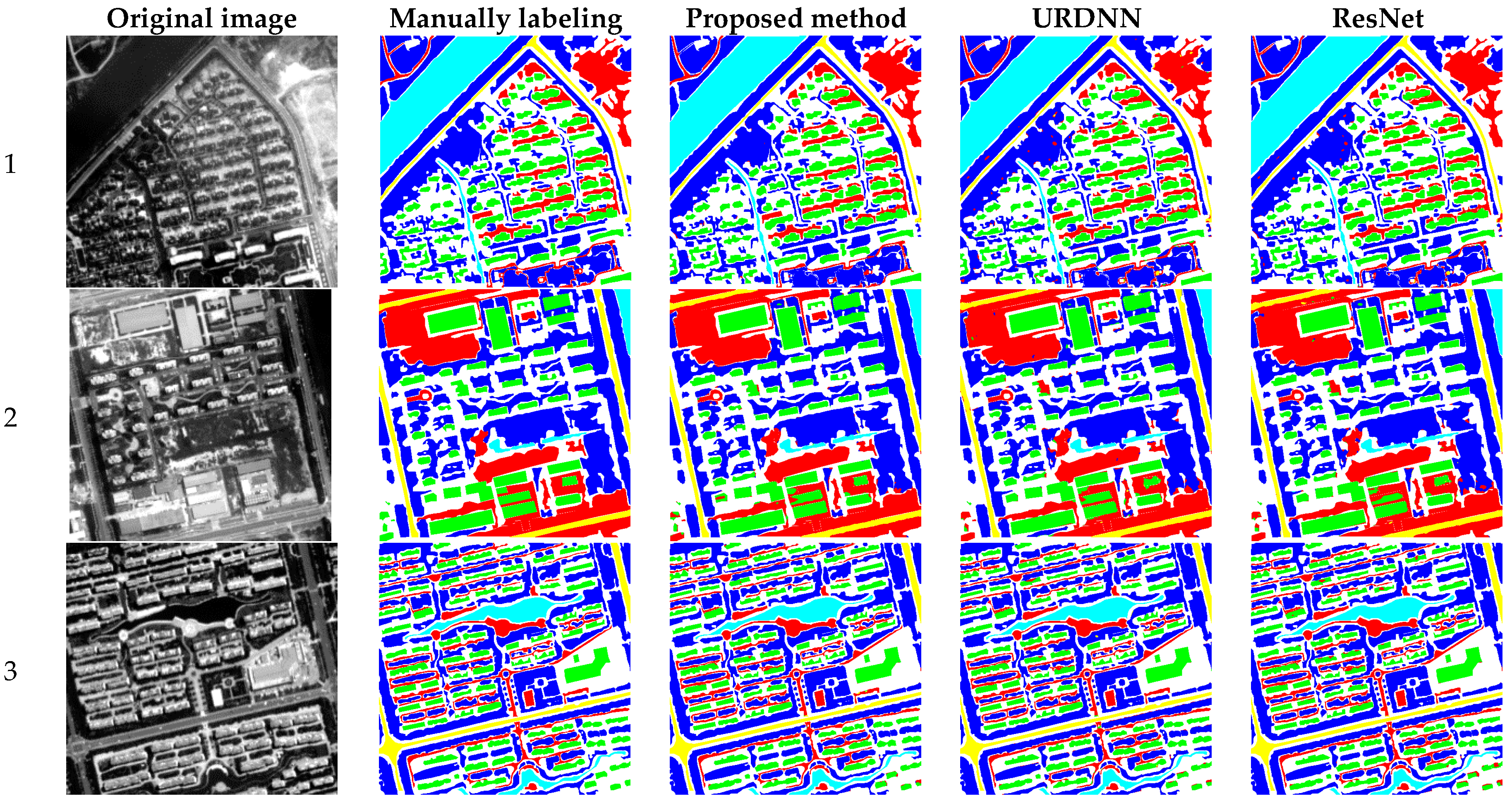
Compared with these contrast methods, the proposed method achieved the competitive results, with OA of 98.4% and kappa of 97.3%. From
Figure 9, although some boundaries of ground objects were not well preserved, for instance, some building boundaries, the errors inside the ground objects were greatly reduced. The ground objects extracted by the proposed method were more complete. Although there were still misclassifications between buildings and bare lands and between bare lands and roads, the classification result was getting more similar to the labeled ground truth.
For the GF02 experiment, the proposed method achieved an OA as high as 98.9%, which is about 0.7% higher compared with other contrast methods. ResNet-based contextual deep CNN achieved the best result in five contrast methods. Although the improved URDNN did not use ResNet, its OA were all over 98.1%. However, compared with the proposed method, these contrast methods did not preserve the completeness of the ground objects well enough, especially inside the buildings and bare lands. In addition, there are more commission errors on the boundaries of the buildings and the roads. The SAE + SVM method performed poorly in the GF02 experiment as well, the bare lands and the roads were heavily mixed, so the results looked mottled. The simple classification methods without using neural network also behaved worse compared with proposed method, especially in some confusing categories, like building and bare land.
The proposed network was not advantageous in terms of training and classification time because it contains many convolutions that are very time-consuming, especially for those 5 5 convolutions. Although we reduced the depth of filters to control it but time training time for the whole network was about 4 h when the subnet number was three and filter depth was 30, using the Quadro K620 graphic card. In the testing, the time to generate the classification result was 1.2 s, which was not too long.
4.3.4. Influence of Training Data Size on Network Performance
Because of the complexity of the deep network and the large number of parameters to be trained, when the labeled training data were few, overfitting tended to happen and resulted in the decrease in the classification accuracy. The network performance was not in proportion to the network depth. In the field of per-pixel classification of VHRRS, it is hard to acquire the labeled data. Therefore, it is challenging to make the model more robust with a small number of samples. For the BJ02 and GF02 experiments, we chose 600, 700, 800, 900 and 1000 pixels for each category as training samples. The changes of the overall accuracy are shown in
Figure 11, in which ResNet represents the contextual deep CNN and non-dense represented the proposed method with the densely connected convolution removed. For the BJ02 and GF02 experiments, the decease of the amount of training samples generated some similar trends.
Firstly, when using 600 training samples, the proposed method with three subnets achieved the best results. In the BJ02 experiments, the OA reached 97%; and in the GF02 experiments, OA reached 98%, both of which were satisfactory. Secondly, we could see that although the accuracies of all the methods decreased when the amount of training sample was reduced, when using the URDNN and the proposed method with densely connected removed, the speed and range of the decease were quicker and larger. When using DenseNet and ResNet, the changes were relatively steady. Especially for the contextual deep CNN, the changes were quite small, which proved that its model is quite robust. Our proposed method changed more obviously when using 3 subnets than using 2 subnets or one subnet, this was because the 3-subnets network was more complicated and had more parameters. Although it employed DenseNet and internal classifiers to reduce the gradient disappearance and overfitting, it was prone to be influenced by the number of samples than the simpler networks. However, it still achieved satisfactory results with a small number of samples.
When the densely connected convolution was removed, the network classification accuracy decreased rapidly as the number of training samples was reduced, which also proves that the increase in the transparency of the hidden layers was beneficial to counter the overfitting problem. DenseNet was useful for the network to extract more discriminative features and made the models more appropriate for the training and classification in the circumstance of small number of training samples.
In general, the proposed method performed consistently when the training data were reduced. It was suitable for the scenario of the RHRRS classification where the labeled training data were lacking. It could strengthen the capability of data extraction of the network, enabling the network to achieve better results when the number of samples is small.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}