Improved Fully Convolutional Network with Conditional Random Fields for Building Extraction


Abstract
:1. Introduction
Related Works and Contributions
2. Materials and Methods
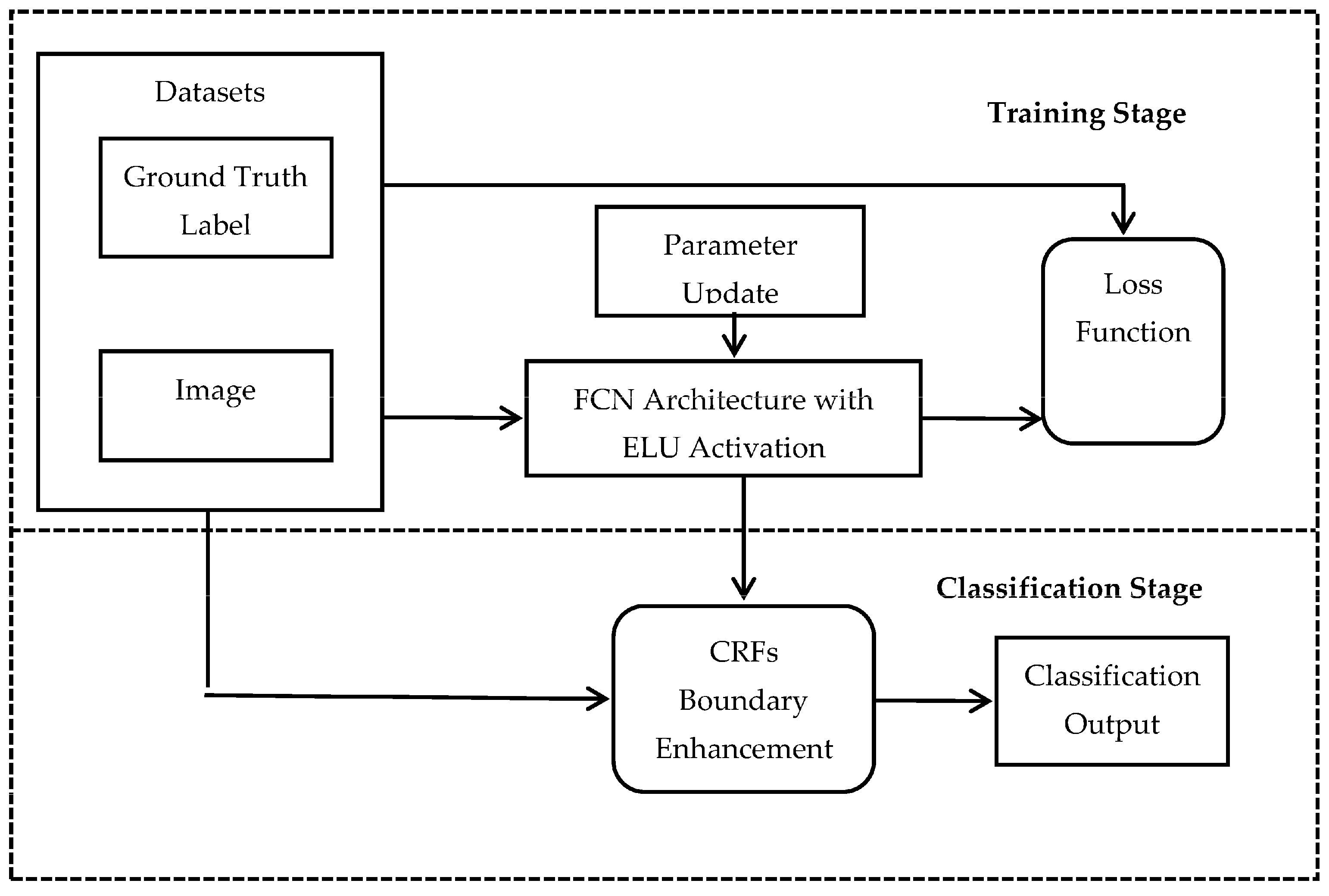
2.1. Proposed Methodology
2.1.1. Data Preprocessing
2.1.2. Building Extraction
Network Architecture
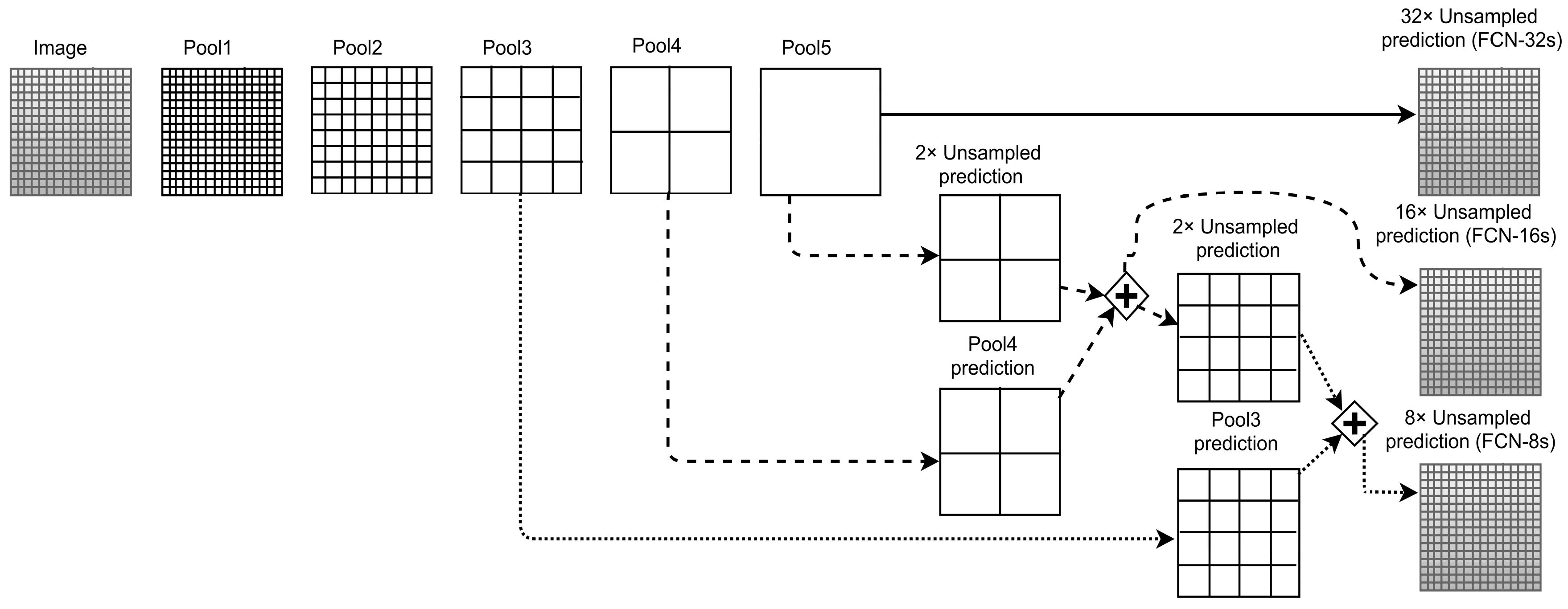
Fully Convolutional Network
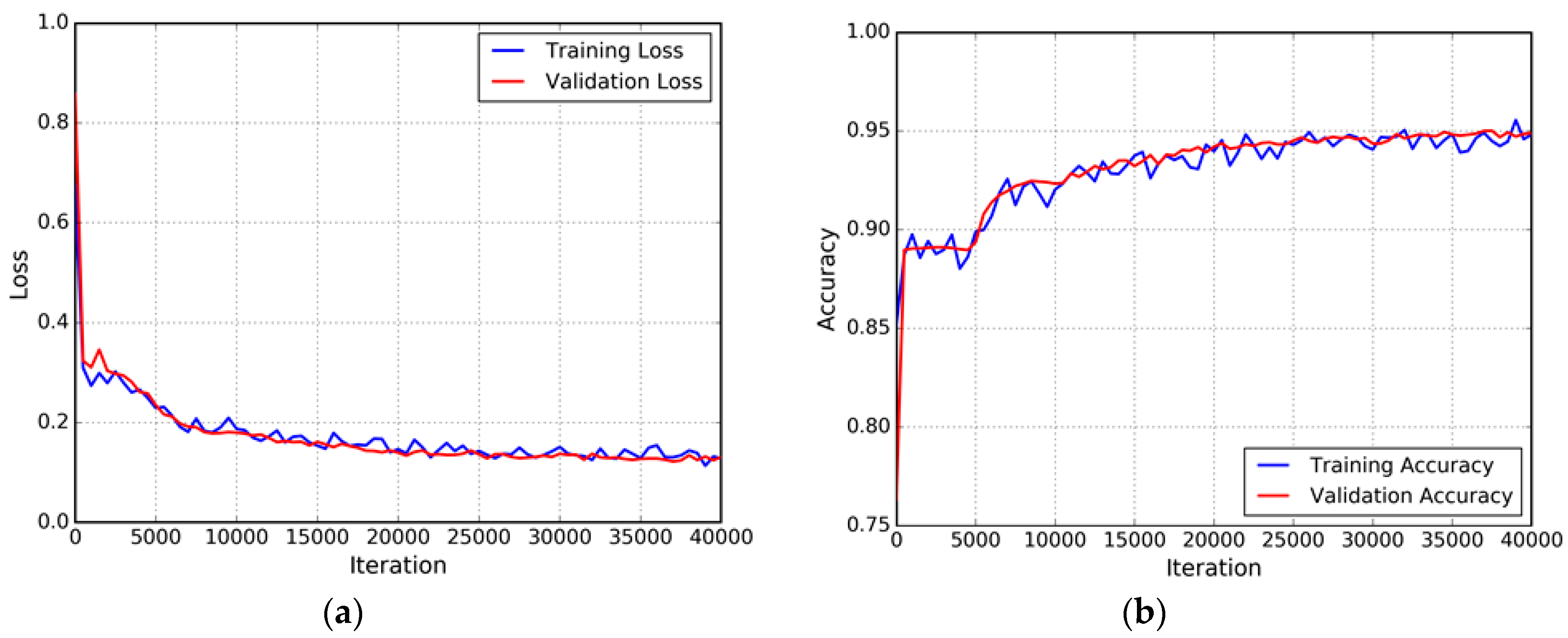
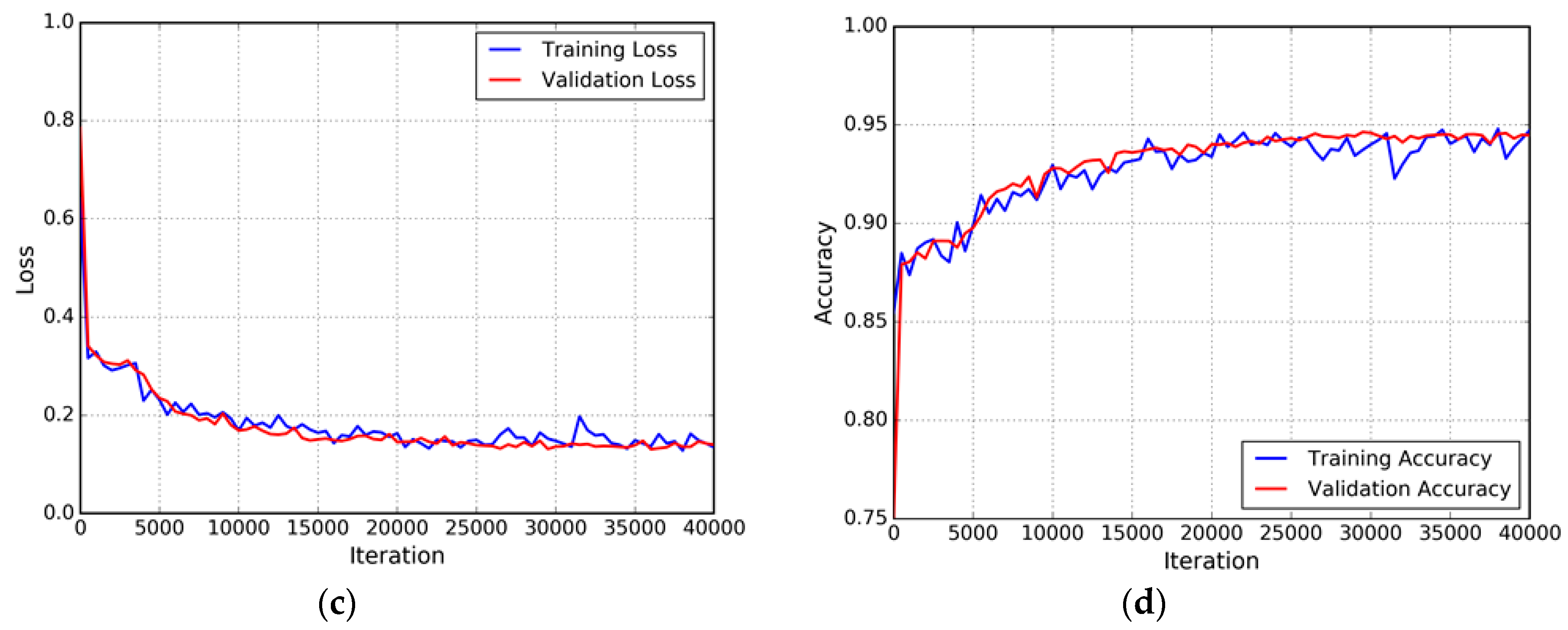
Network Training
2.1.3. Post-Classification Processing Using the Trained Network
2.2 Experimental Design and Evaluation
2.2.1. Experimental Dataset
2.2.2. Experimental Design
2.2.3. Performance Evaluation
3. Results and Discussion
3.1. Results of the Comparison of the Variations of the Proposed Classifier
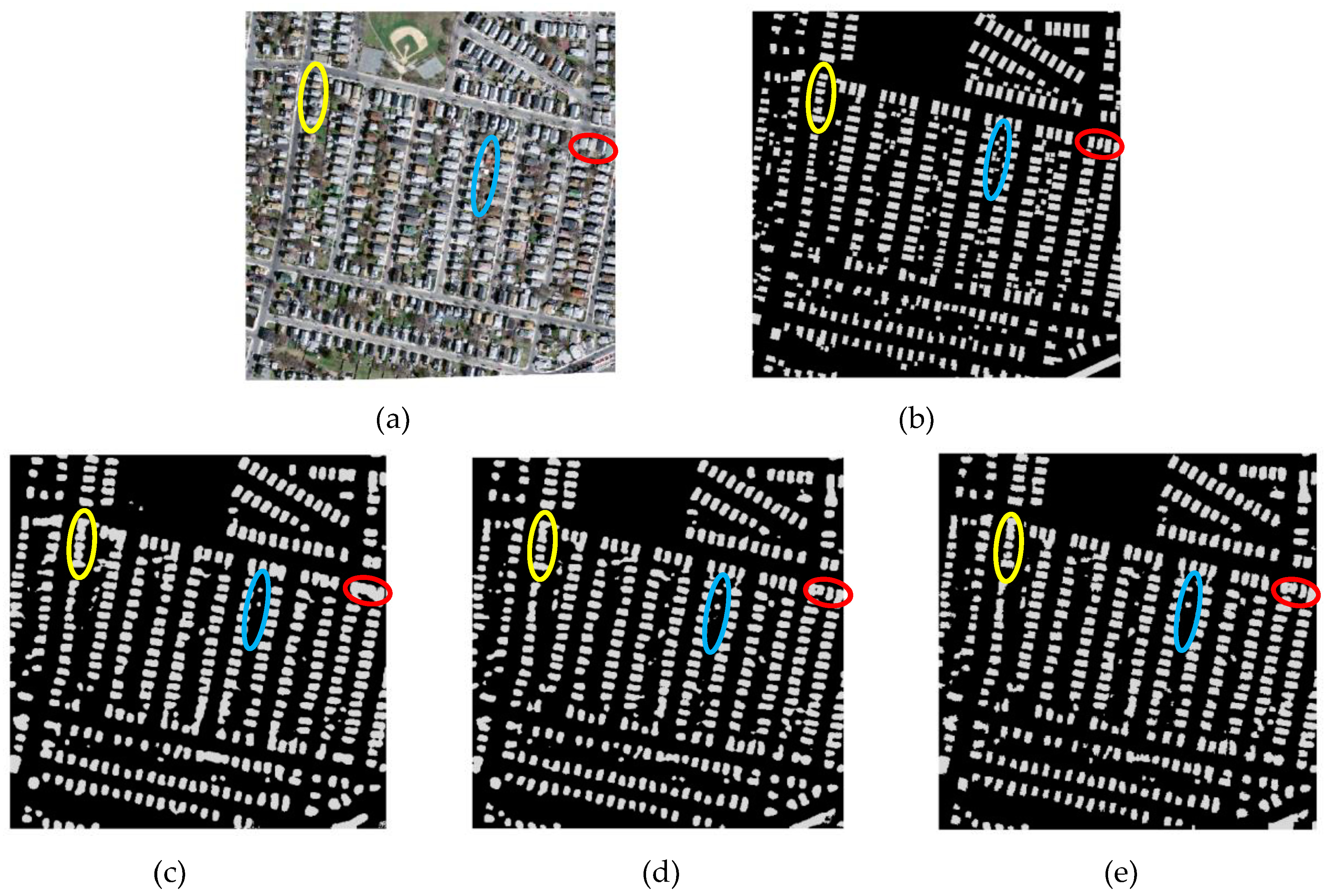
3.1.1. Qualitative Analysis of Comparison of Variation of Proposed Classifier
3.1.2. Quantitative Analysis of Comparison of Proposed Classifier
Results of Enhanced FCN (ELU-FCN)
Results of Post-Processing CRFs (ELU-FCN-CRFs) on Enhanced FCN (ELU-FCN)
Combined Results All Variation of Networks
3.1.3. Comparison of Variation of Proposed Classifier on Network Complexity
3.2. Results of Comparison of the Proposed Method with Pre-Existing Classifiers
4. Conclusions and Future Works
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| CRFs | Conditional Random Fields |
| DCNN | Deep Convolutional Neural Network |
| ELU | Exponential Linear Unit |
| FCN | Fully Convolutional Network |
| FN | False Negative |
| FP | False Positive |
| GTLabel | Ground Truth Label |
| IoU | Intersection Over Union |
| NRG | Near Infrared, Red, Blue |
| PASCAL VOC | PASCAL Visual Object Classes |
| PCA | Principal Component Analysis |
| ReLU | Rectified Linear Unit |
| RGB | Red, Green, Blue |
| SVM | Support Vector Machine |
| TN | True Negative |
| TP | True Positive |
| VGI | Volunteered Geographic Information |
References
- Planet. Planet Doubles Sub-1 Meter Imaging Capacity with Successful Launch of 6 Skysats. Available online: https://www.planet.com/pulse/planet-doubles-sub-1-meter-imaging-capacity-with-successful-launch-of-6-skysats/ (accessed on 22 December 2017).
- Digital Globe. Open Data for Disaster Recovery. Available online: https://www.digitalglobe.com/ (accessed on 12 November 2017).
- FAA. UAS Integration Pilot Program. Available online: https://www.faa.gov/uas/programs_partnerships/uas_integration_pilot_program/ (accessed on 12 November 2017).
- Space News. U.S. Government Eases Restrictions on DigitalGlobe. Available online: http://spacenews.com/40874us-government-eases-restrictions-on-digitalglobe/ (accessed on 12 December 2017).
- Mayer, H. Automatic object extraction from aerial imagery—A survey focusing on buildings. Comput. Vis. Image Underst. 1999, 74, 138–149. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 1, 1097–1105. [Google Scholar] [CrossRef]
- Shu, Y. Deep Convolutional Neural Networks for Object Extraction from High Spatial Resolution Remotely Sensed Imagery. Ph.D. Thesis, University of Waterloo, Waterloo, ON, Canada, 2014. [Google Scholar]
- Yuan, J. Automatic building extraction in aerial scenes using convolutional networks. arXiv, 2016; arXiv:1602.06564. [Google Scholar]
- Nielsen, J. Participation Inequality: Encouraging More Users to Contribute, Alertbox. Available online: http: //www. useit.com/alertbox/participation_inequality fifth (accessed on 22 July 2017).
- Marcu, A.; Leordeanu, M. Dual local-global contextual pathways for recognition in aerial imagery. arXiv, 2016; arXiv:1605.05462. [Google Scholar]
- Yuan, J.; Cheriyadat, A.M. Learning to count buildings in diverse aerial scenes. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Fort Worth, TX, USA, 4–7 November 2014; pp. 271–280. [Google Scholar]
- Huertas, A. Detecting buildings in aerial images. Comput. Vis. Graph. Image Process. 1998, 41, 131–152. [Google Scholar] [CrossRef]
- Peng, J.; Liu, Y.C. Model and context—Driven building extraction in dense urban aerial images. Int. J. Remote Sens. 2005, 26, 1289–1307. [Google Scholar] [CrossRef]
- Levitt, S.; Aghdasi, F. An investigation into the use of wavelets and scaling for the extraction of buildings in aerial images. In Proceedings of the IEEE 1998 South African Symposium on Communications and Signal Processing, Rondebosch, South Africa, 8 September 1998; pp. 133–138. [Google Scholar]
- Inglada, J. Automatic recognition of man-made objects in high resolution optical remote sensing images by SVM classification of geometric image features. ISPRS J. Photogramm. Remote Sens. 2007, 62, 236–248. [Google Scholar] [CrossRef]
- Sumer, E.; Turker, M. An adaptive fuzzy-genetic algorithm approach for building detection using high-resolution satellite images. Comput. Environ. Urban Syst. 2013, 39, 48–62. [Google Scholar] [CrossRef]
- Alshehhi, R.; Reddy, P.; Lee, W.; Dalla, M. Simultaneous extraction of roads and buildings in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2017, 130, 139–149. [Google Scholar] [CrossRef]
- Mnih, V. Machine Learning for Aerial Image Labeling. Ph.D. Thesis, University of Toronto, Toronto, ON, Canada, 2013. [Google Scholar]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]
- Bittner, K.; Cui, S.; Reinartz, P.; Vi, C.; Vi, W.G. Building extraction from remote sensing data using fully convolutional networks. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 481–486. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv, 2013; arXiv:1312.4400. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Arbor, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Xiangyu, Z.; Shaoqing, R.; Jian, S. Delving deep into rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Saito, S.; Aoki, Y. Building and road detection from large aerial imagery. SPIE/IS&T Electron. Imaging 2015, 9405, 3–14. [Google Scholar]
- Saito, S.; Takayoshi, Y.; Yoshimitsu, A. Multiple object extraction from aerial imagery with convolutional neural networks. Electron. Imaging 2016, 60, 1–9. [Google Scholar] [CrossRef]
- Huang, Z.; Guangliang, C.; Hongzhen, W.; Haichang, L.; Limin, S.; Chunhong, P. Building extraction from multi-source remote sensing images via deep deconvolution neural networks. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 1835–1838. [Google Scholar]
- Maggiori, E.; Member, S.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Liu, Z.; Li, X.; Luo, P.; Loy, C.C.; Tang, X. Deep learning markov random field for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1520–1528. [Google Scholar]
- Chen, L.; Papandreou, G.; Member, S.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. arXiv, 2016; arXiv:1606.00915. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Sun, J.; Zhang, X.; Ren, S. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R.; Member, S. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. arXiv, 2015; arXiv:1511.00561. [Google Scholar]
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and accurate deep network learning by exponential linear units (ELUs). arXiv, 2015; arXiv:1511.07289. [Google Scholar]
- Krahenbuhl, P.; Koltun, V. Efficient inference in fully connected crfs with gaussian edge potentials. Adv. Neural Inf. Process. Syst. 2011, 24, 109–117. [Google Scholar]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Muruganandham, S. Semantic segmentation of satellite images using deep learning. Master’s Thesis, Lulea University of Technology, Luleå, Sweden, 2016. [Google Scholar]
- Hu, F.; Xia, G.-S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Nogueira, K.; Penatti, O.A.B.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef] [Green Version]
- Shotton, J.; Winn, J.; Rother, C. Textonboost for image understanding: Multi-class object recognition and segmentation by jointly modeling texture, layout, and context. Int. J. Comput. Vis. 2009, 81, 2–23. [Google Scholar] [CrossRef]
- Tensorflow. An Open-Source Machine Learning Framework for Everyone. Available online: https://www.tensorflow.org/ (accessed on 11 September 2017).
- Ruder, S. An overview of gradient descent optimization algorithms. arXiv, 2016; arXiv:1609.04747. [Google Scholar]
- Bergstra, J.; Bengio, Y. Random search for hyper-parameter optimization. J. Mach. Learn. Res. 2012, 13, 281–305. [Google Scholar]
- Wiedemann, C.; Heipke, C.; Mayer, H.; Jamet, O. Empirical evaluation of automatically extracted road axes. In Empirical Evaluation Techniques in Computer Vision; IEEE Computer Society Press: Washington, DC, USA, 1998; pp. 172–187. [Google Scholar]
- Yu, H.; Yang, W.; Xia, G.-S.; Liu, G. A color-texture-structure descriptor for high-resolution satellite image classification. Remote Sens. 2016, 8, 259. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Abbreviation | Description |
|---|---|---|
| Selected network | FCN | Fully convolutional network |
| Variation of selected network | ELU-FCN | FCN + ELU activation |
| Proposed method | ELU-FCN-CRFs | FCN + ELU activation + CRFs |
| Image ID | 1 | 2 | 3 | 4 | 5 | 6 | Mean |
|---|---|---|---|---|---|---|---|
| FCN | 97.13 | 95.22 | 95.06 | 97.64 | 91.05 | 88.48 | 94.09 |
| ELU-FCN | 97.79 | 95.33 | 97.70 | 98.31 | 91.36 | 90.44 | 95.16 |
| ELU-FCN-CRFs | 97.89 | 95.36 | 97.69 | 98.37 | 91.38 | 90.45 | 95.19 |
| Models | Precision | Recall | F1-Score | IoU | |
|---|---|---|---|---|---|
| Baseline | FCN | 94.76 | 91.63 | 93.09 | 86.96 |
| Proposed Method | ELU-FCN | 94.79 | 93.42 | 93.81 | 88.93 |
| ELU-FCN-CRFs | 95.07 | 93.40 | 93.93 | 89.08 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shrestha, S.; Vanneschi, L. Improved Fully Convolutional Network with Conditional Random Fields for Building Extraction. Remote Sens. 2018, 10, 1135. https://doi.org/10.3390/rs10071135
Shrestha S, Vanneschi L. Improved Fully Convolutional Network with Conditional Random Fields for Building Extraction. Remote Sensing. 2018; 10(7):1135. https://doi.org/10.3390/rs10071135
Chicago/Turabian StyleShrestha, Sanjeevan, and Leonardo Vanneschi. 2018. "Improved Fully Convolutional Network with Conditional Random Fields for Building Extraction" Remote Sensing 10, no. 7: 1135. https://doi.org/10.3390/rs10071135
APA StyleShrestha, S., & Vanneschi, L. (2018). Improved Fully Convolutional Network with Conditional Random Fields for Building Extraction. Remote Sensing, 10(7), 1135. https://doi.org/10.3390/rs10071135