A Boundary Regulated Network for Accurate Roof Segmentation and Outline Extraction

 ,
, 


Abstract
:
1. Introduction
2. Materials and Methods
2.1. Data
2.2. Methodology
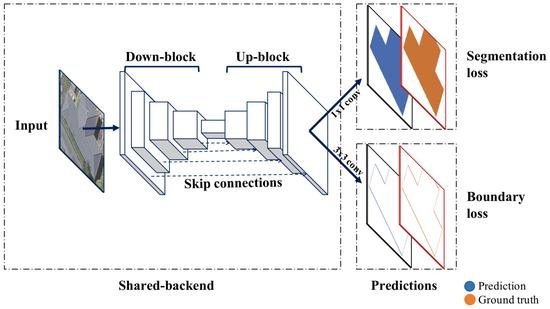
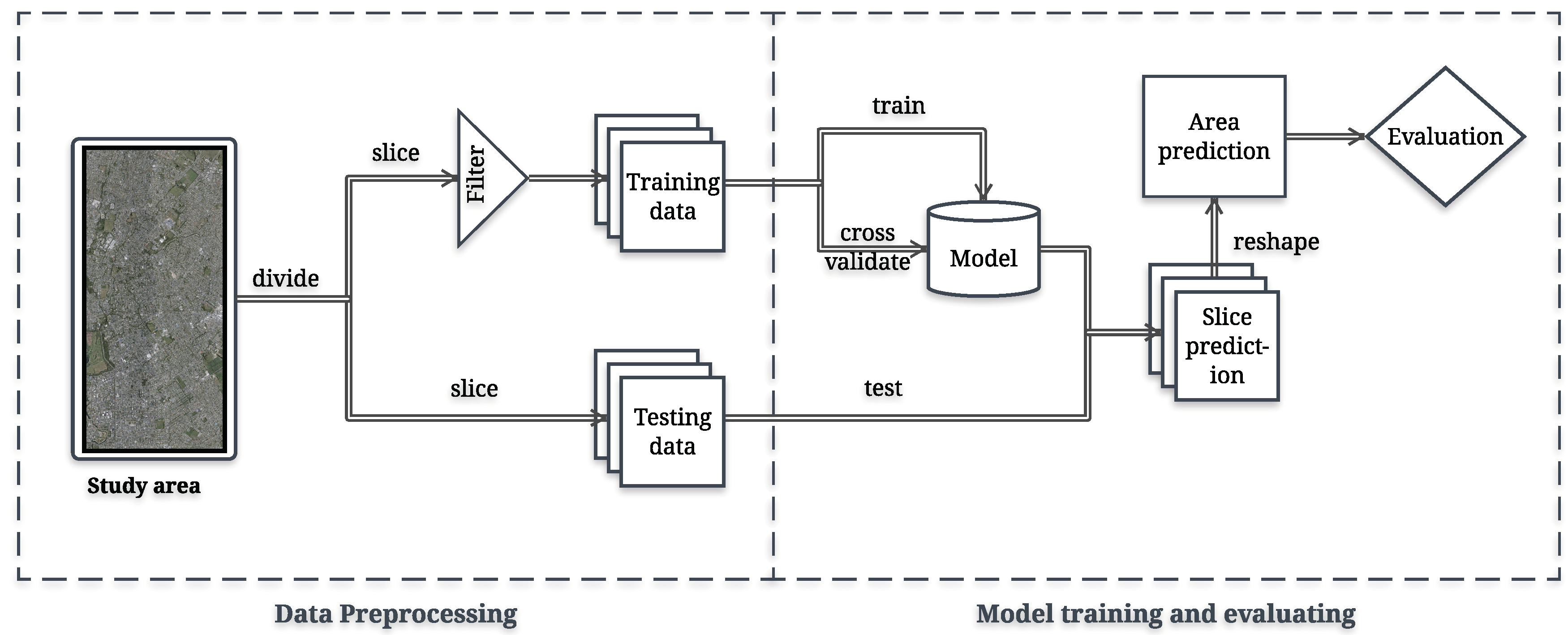
2.2.1. Data Preprocessing
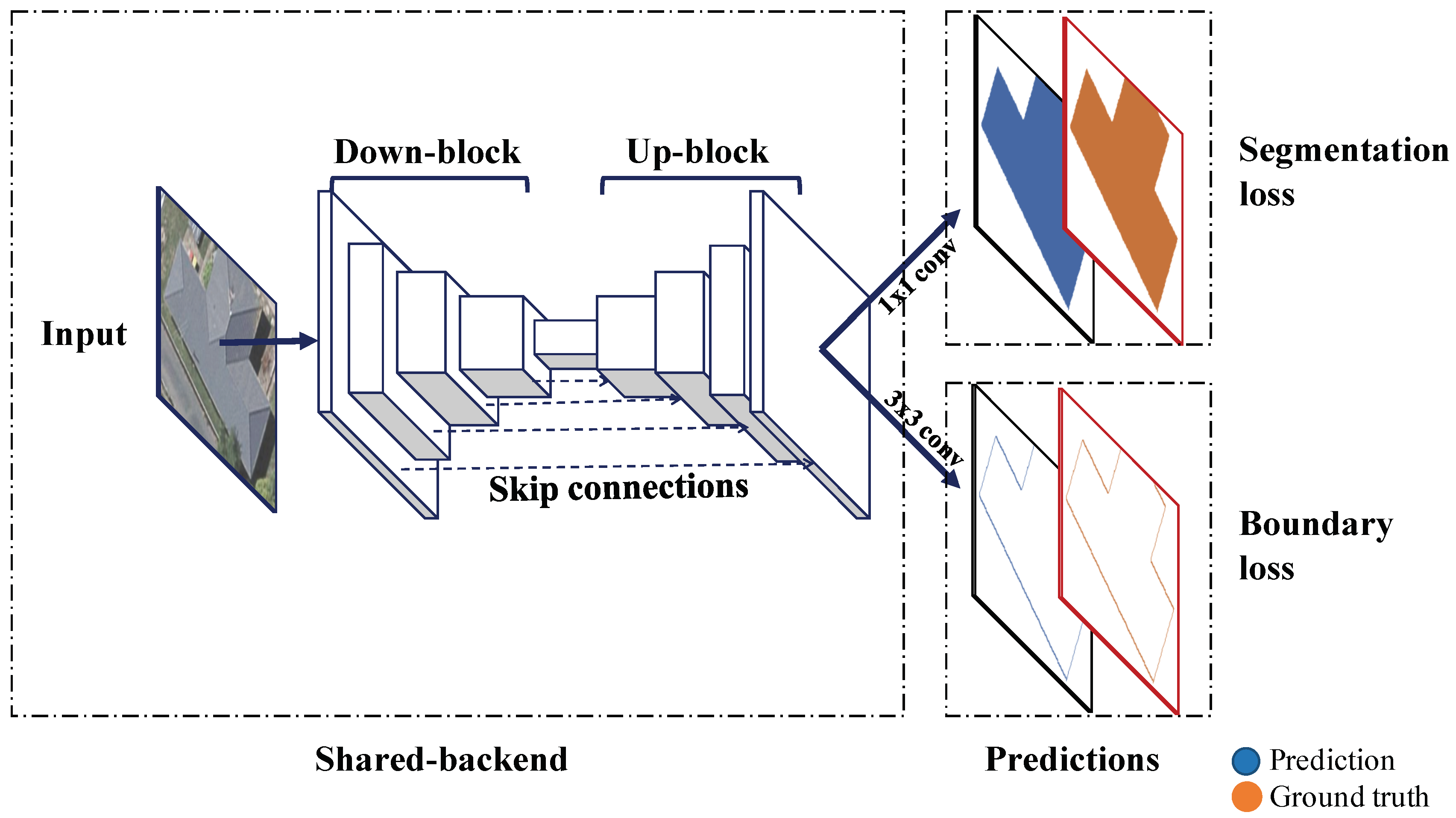
2.2.2. Boundary Regulated Network
- For these models, the prediction value of each pixel is solely based on the features within a localized receptive field (e.g., a 3 × 3 kernel). Therefore, global information (e.g., linear relationships between points and right angle relationships between lines) of building polygons cannot be utilized by these models.
- When capturing aerial imagery, it is inevitable to obtain noisy data, such as portions of buildings that are shadowed by surrounding trees. If the models are successfully trained to strictly segment the image solely by surrounding pixels, the hidden part of building polygon will be ignored.
2.3. Experimental Setup
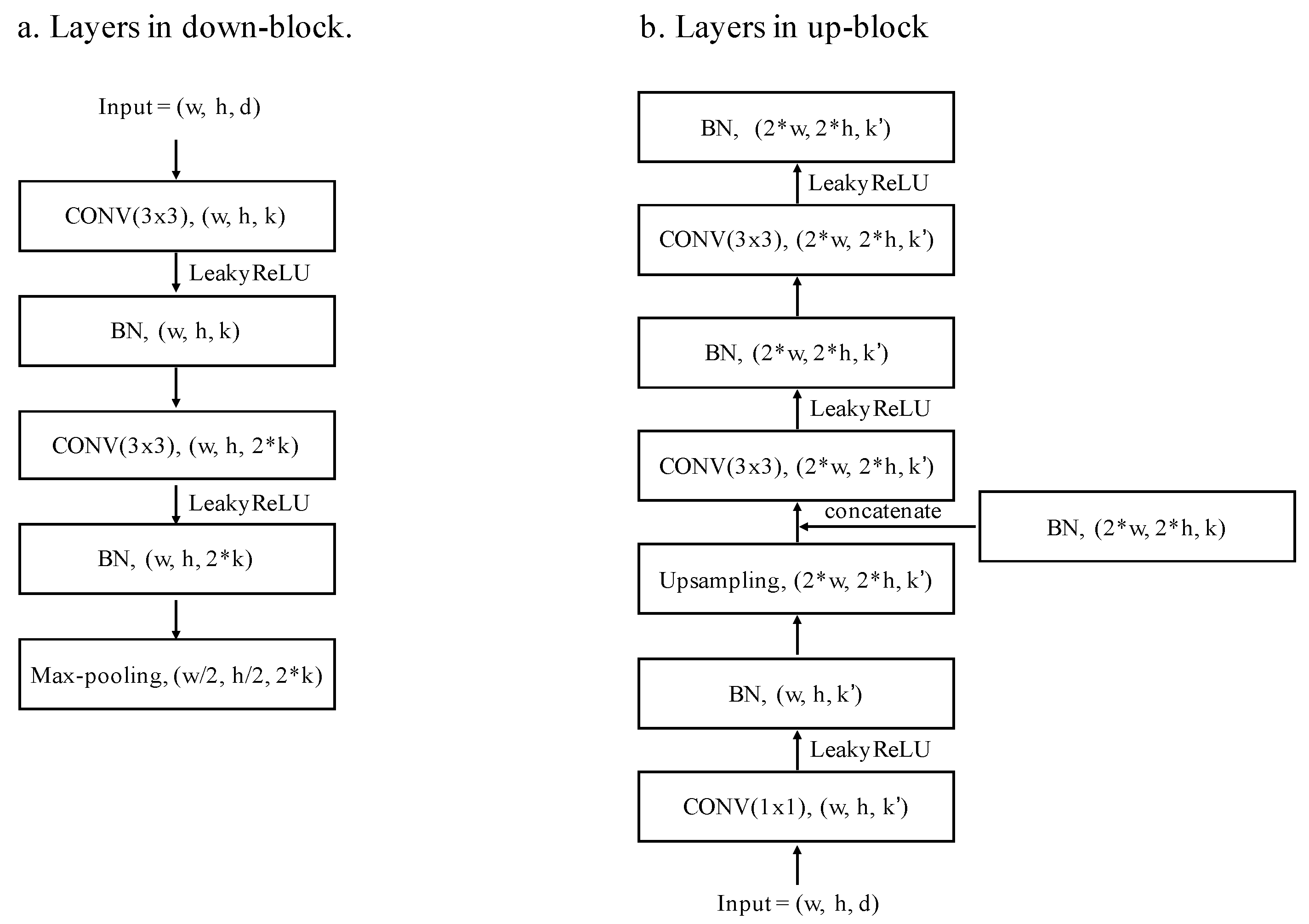
2.3.1. Architecture of the BR-Net
2.3.2. Integration of Different Components
3. Results
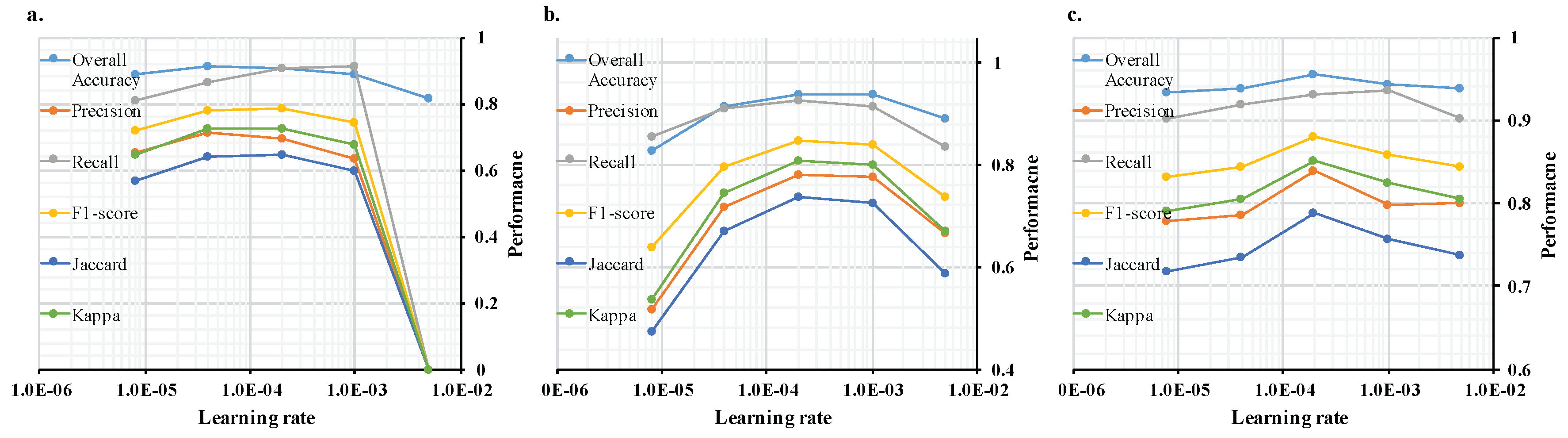
3.1. Hyper-Parameter Optimization
- As shown in Figure 5a, FCN8s model achieves the best performance with the learning rate of 2 × 10. For major metrics, FCN8s model shows similar values using learning rate between 4 × 10 and 2 × 10.
- As shown in Figure 5b, U-Net model shows the highest values of major metrics with the learning rate of 2 × 10. Under learning rates from 2 × 10 to 1 × 10, the performances of U-Net model are almost identical.
- As shown in Figure 5c, similar to FCN8s and U-Net methods, the BR-Net model reaches its best performance with the learning rate of 2 × 10.
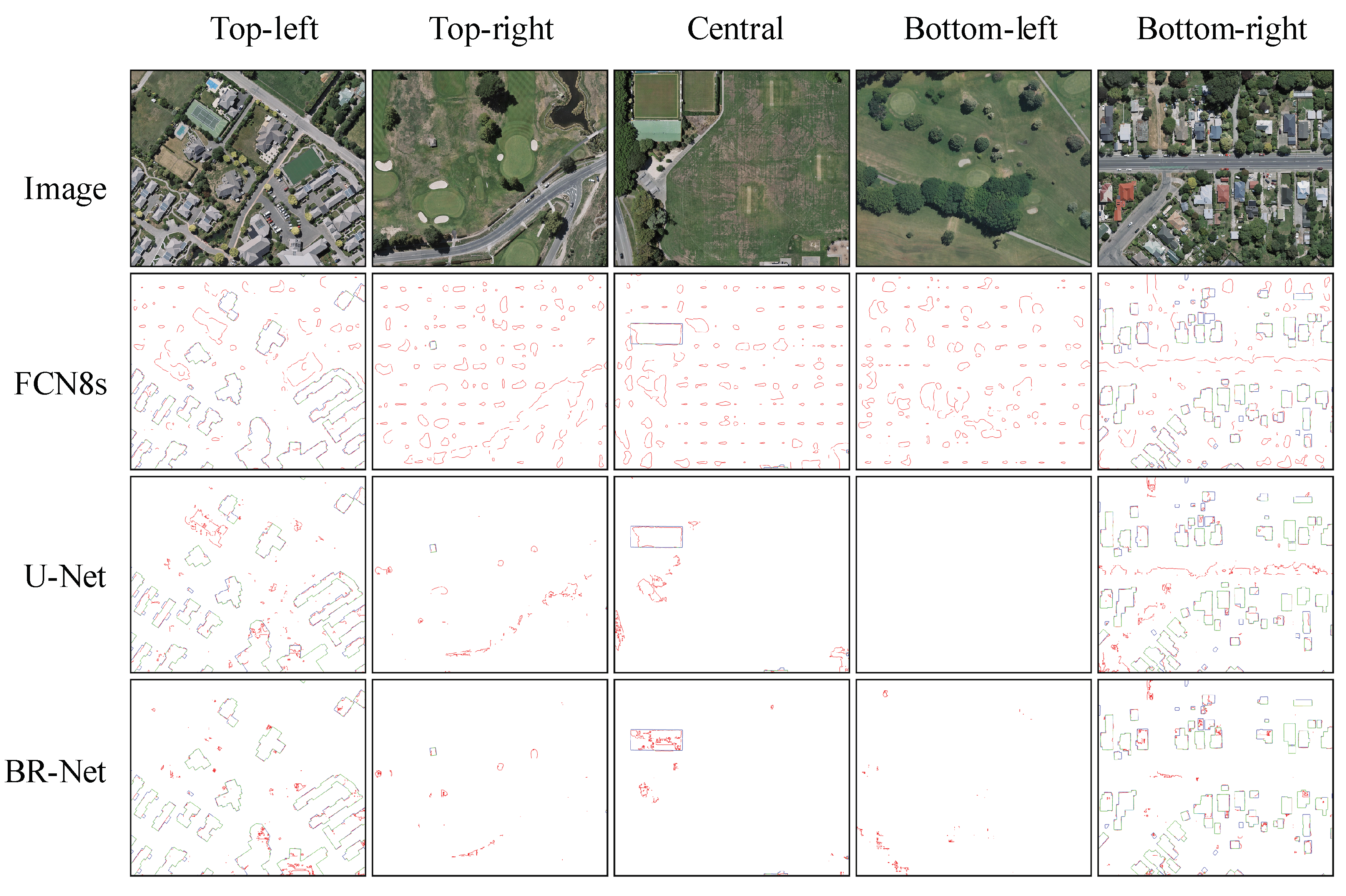
3.2. Qualitative Result Comparisons
3.2.1. Result Comparisons at Region Level
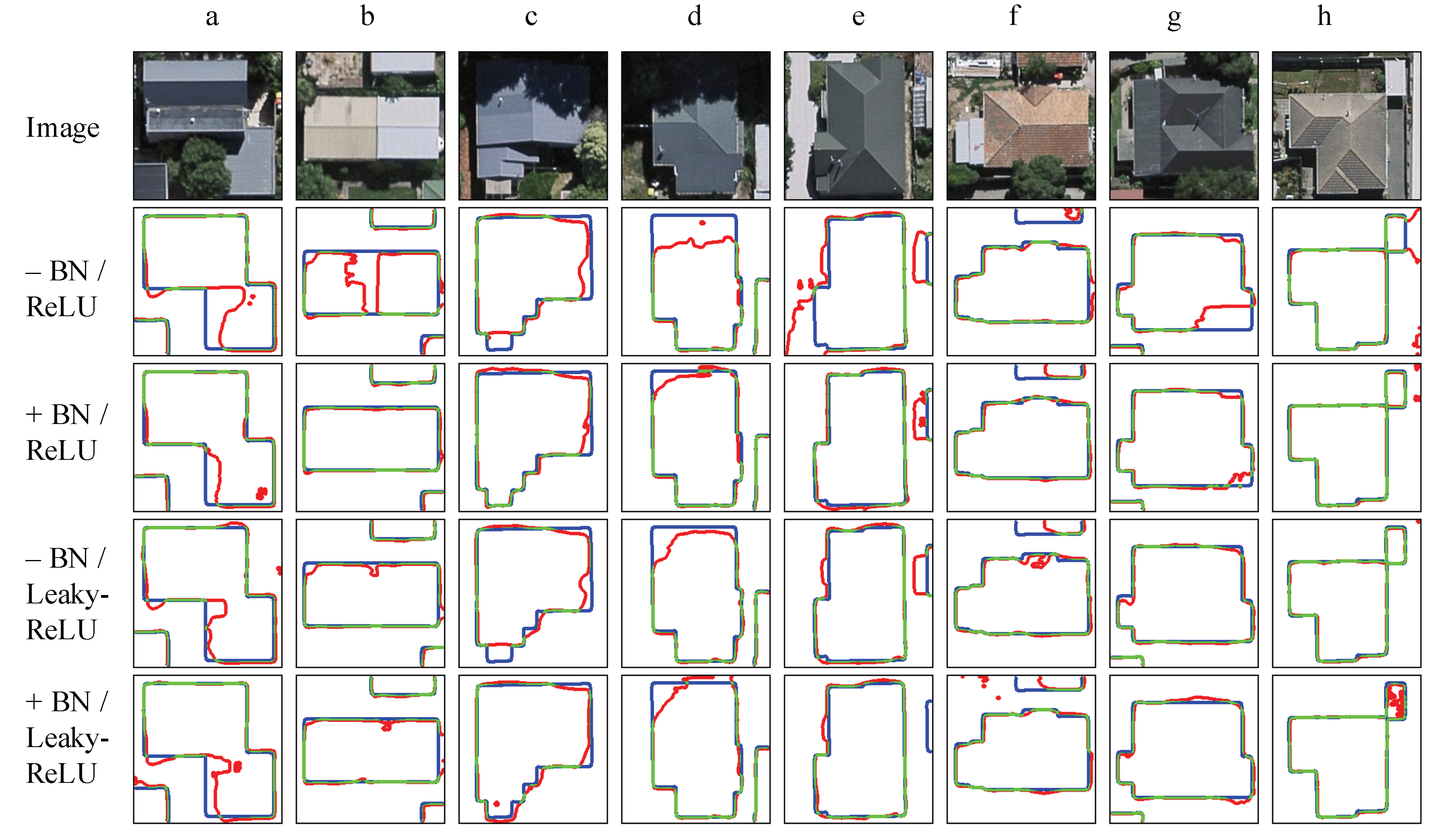
3.2.2. Result Comparisons at Single-House Level
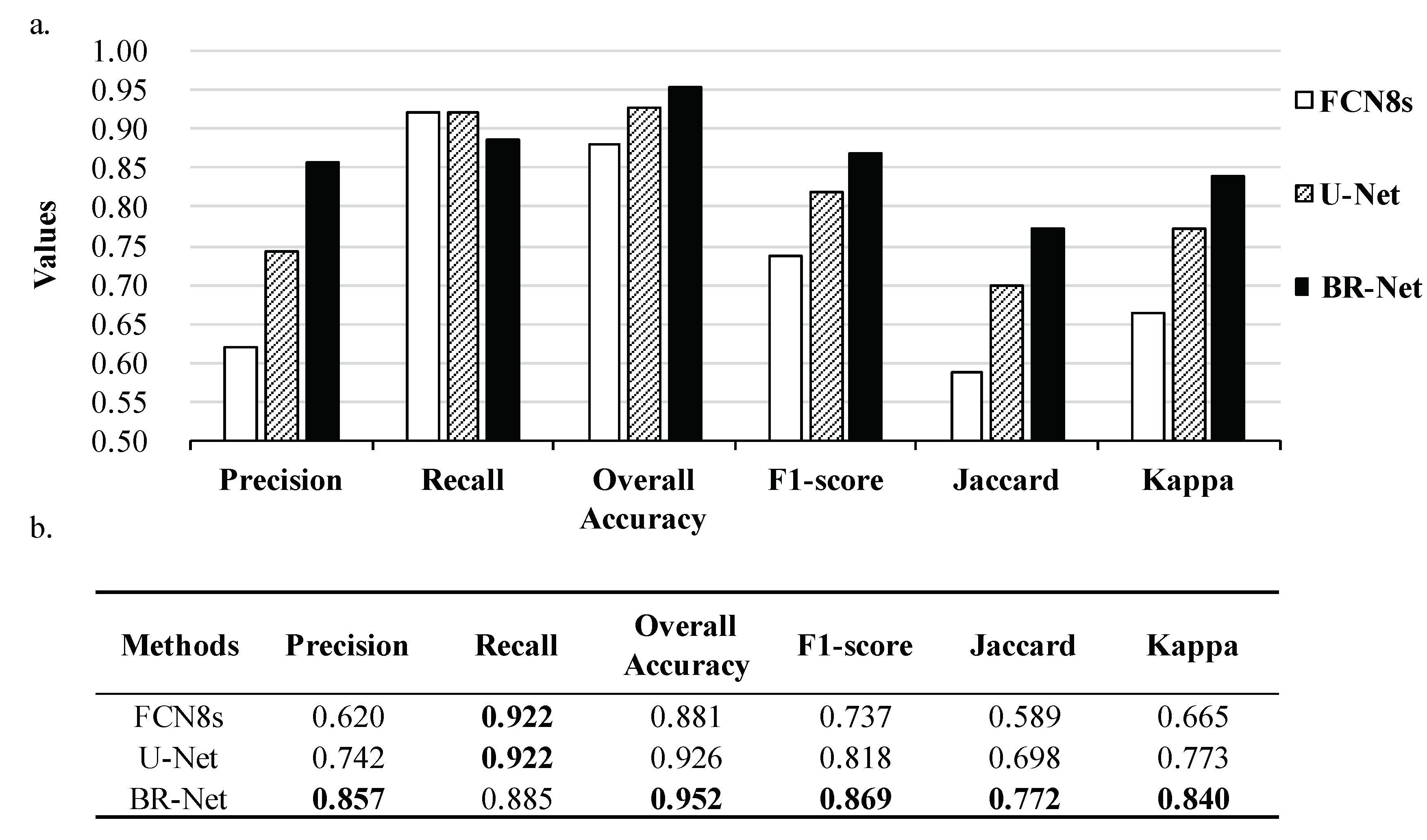
3.3. Quantitative Result Comparisons
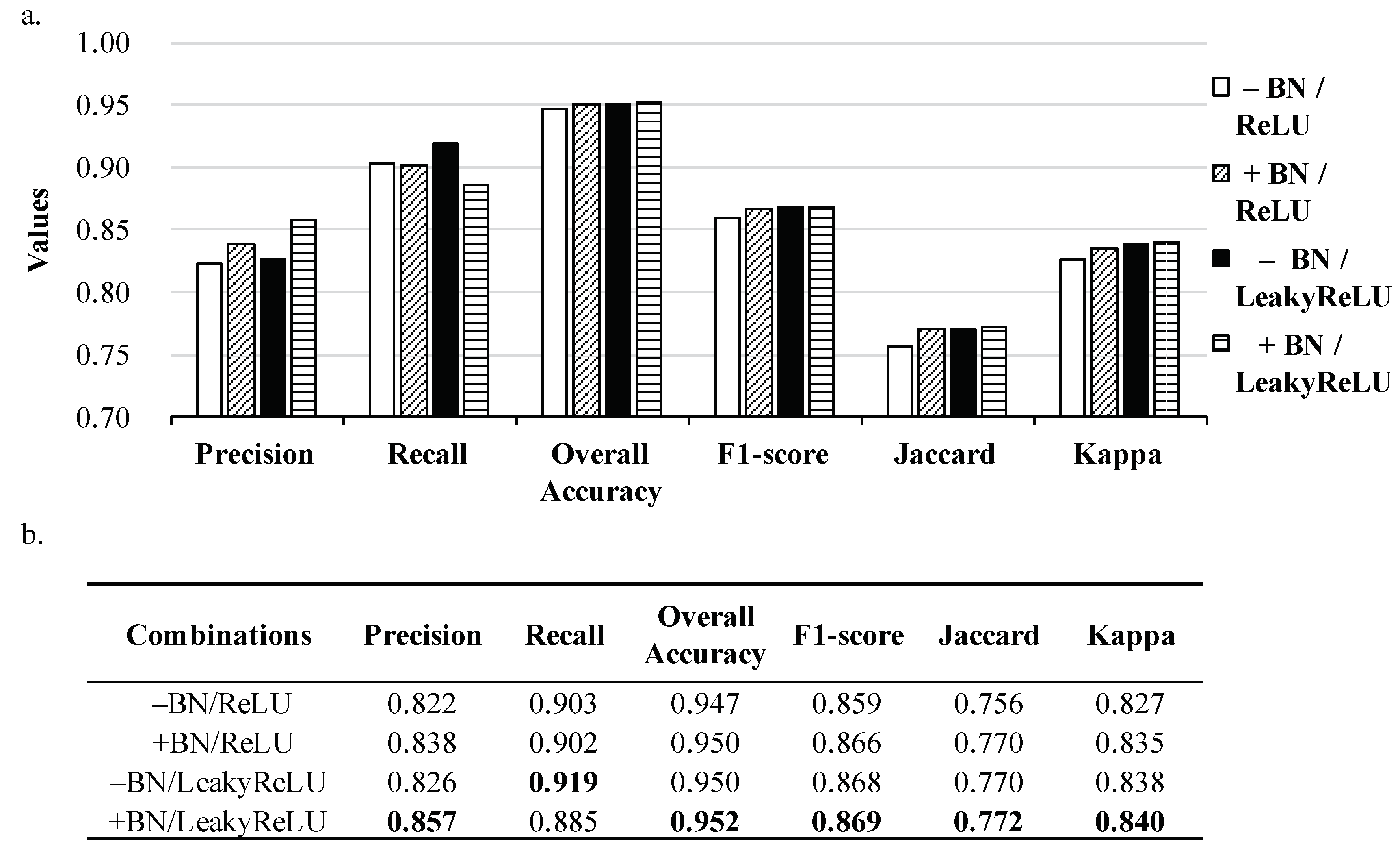
3.4. Sensitivity Analysis of Components
3.5. Computational Efficiency
4. Discussion
4.1. Regarding the Proposed BR-Net Model
4.2. Accuracies, Uncertainties, and Limitations
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| BN | Batch Normalization |
| ReLU | Rectified Linear Unit |
| FCN | Fully Convolutional Networks |
| FPS | Frames Per Second |
| BR-Net | Boundary Regulated Network |
References
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Li, M.; Zang, S.; Zhang, B.; Li, S.; Wu, C. A review of remote sensing image classification techniques: The role of spatio-contextual information. Eur. J. Remote Sens. 2014, 47, 389–411. [Google Scholar] [CrossRef]
- Chen, R.; Li, X.; Li, J. Object-based features for house detection from rgb high-resolution images. Remote Sens. 2018, 10, 451. [Google Scholar] [CrossRef]
- Xu, B.; Jiang, W.; Shan, J.; Zhang, J.; Li, L. Investigation on the weighted ransac approaches for building roof plane segmentation from lidar point clouds. Remote Sens. 2016, 8, 5. [Google Scholar] [CrossRef]
- Huang, Y.; Zhuo, L.; Tao, H.; Shi, Q.; Liu, K. A novel building type classification scheme based on integrated LiDAR and high-resolution images. Remote Sens. 2017, 9, 679. [Google Scholar] [CrossRef]
- Gilani, S.A.N.; Awrangjeb, M.; Lu, G. An automatic building extraction and regularisation technique using lidar point cloud data and orthoimage. Remote Sens. 2016, 8, 258. [Google Scholar] [CrossRef]
- Sahoo, P.K.; Soltani, S.; Wong, A.K. A survey of thresholding techniques. Comput. Vis. Graph. Image Process. 1988, 41, 233–260. [Google Scholar] [CrossRef]
- Kanopoulos, N.; Vasanthavada, N.; Baker, R.L. Design of an image edge detection filter using the Sobel operator. IEEE J. Solid-State Circuits 1988, 23, 358–367. [Google Scholar] [CrossRef]
- Wu, Z.; Leahy, R. An optimal graph theoretic approach to data clustering: Theory and its application to image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 1993, 15, 1101–1113. [Google Scholar] [CrossRef]
- Tremeau, A.; Borel, N. A region growing and merging algorithm to color segmentation. Pattern Recognit. 1997, 30, 1191–1203. [Google Scholar] [CrossRef]
- Gómez-Moreno, H.; Maldonado-Bascón, S.; López-Ferreras, F. Edge detection in noisy images using the support vector machines. In International Work-Conference on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 2001; pp. 685–692. [Google Scholar]
- Zhou, J.; Chan, K.; Chong, V.; Krishnan, S.M. Extraction of Brain Tumor from MR Images Using One-Class Support Vector Machine. In Proceedings of the 2005 IEEE 7th Annual International Conference of the Engineering in Medicine and Biology Society (EMBS 2005), Shanghai, China, 17–18 January 2006; pp. 6411–6414. [Google Scholar]
- Xie, S.; Tu, Z. Holistically-Nested Edge Detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1395–1403. [Google Scholar]
- Viola, P.; Jones, M. Rapid Object Detection Using a Boosted Cascade of Simple Features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, p. I. [Google Scholar]
- Lowe, D.G. Object Recognition from Local Scale-Invariant Features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef] [Green Version]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2005), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Inglada, J. Automatic recognition of man-made objects in high resolution optical remote sensing images by SVM classification of geometric image features. ISPRS J. Photogramm. Remote Sens. 2007, 62, 236–248. [Google Scholar] [CrossRef]
- Aytekin, Ö.; Zöngür, U.; Halici, U. Texture-based airport runway detection. IEEE Geosci. Remote Sens. Lett. 2013, 10, 471–475. [Google Scholar] [CrossRef]
- Dong, Y.; Du, B.; Zhang, L. Target detection based on random forest metric learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1830–1838. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Ciresan, D.; Giusti, A.; Gambardella, L.M.; Schmidhuber, J. Deep neural networks segment neuronal membranes in electron microscopy images. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 2843–2851. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Proceedings of Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes (voc) challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.-F. Imagenet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Guo, Z.; Shao, X.; Xu, Y.; Miyazaki, H.; Ohira, W.; Shibasaki, R. Identification of village building via Google Earth images and supervised machine learning methods. Remote Sens. 2016, 8, 271. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic Segmentation of Small Objects and Modeling of Uncertainty in Urban Remote Sensing Images Using Deep Convolutional Neural Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1520–1528. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U–Net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Cham, Switherland, 2015; pp. 234–241. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. CVPR 2017, 1, 4. [Google Scholar]
- Wu, G.; Shao, X.; Guo, Z.; Chen, Q.; Yuan, W.; Shi, X.; Xu, Y.; Shibasaki, R. Automatic Building Segmentation of Aerial Imagery Using Multi-Constraint Fully Convolutional Networks. Remote Sens. 2018, 10, 407. [Google Scholar] [CrossRef]
- Polak, M.; Zhang, H.; Pi, M. An evaluation metric for image segmentation of multiple objects. Image Vis. Comput. 2009, 27, 1223–1227. [Google Scholar] [CrossRef]
- Carletta, J. Assessing agreement on classification tasks: The kappa statistic. Comput. Linguist. 1996, 22, 249–254. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; Volume 30, p. 3. [Google Scholar]
- Li, E.; Femiani, J.; Xu, S.; Zhang, X.; Wonka, P. Robust rooftop extraction from visible band images using higher order CRF. IEEE Trans. Geosci. Remote Sens. 2015, 53, 4483–4495. [Google Scholar] [CrossRef]
- Plaza, A.; Martínez, P.; Pérez, R.; Plaza, J. Spatial/spectral endmember extraction by multidimensional morphological operations. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2025–2041. [Google Scholar] [CrossRef]
- Canny, J. A computational approach to edge detection. In Readings in Computer Vision; Elsevier: New York, NY, USA, 1987; pp. 184–203. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning (ICML-10), Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Nagi, J.; Ducatelle, F.; Di Caro, G.A.; Cireşan, D.; Meier, U.; Giusti, A.; Nagi, F.; Schmidhuber, J.; Gambardella, L.M. Max-Pooling Convolutional Neural Networks for Vision-Based Hand Gesture Recognition. In Proceedings of the 2011 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 16–18 November 2011; pp. 342–347. [Google Scholar]
- Novak, K. Rectification of digital imagery. Photogramm. Eng. Remote Sens. 1992, 58, 339–344. [Google Scholar]
- Shore, J.; Johnson, R. Properties of cross-entropy minimization. IEEE Trans. Inf. Theory 1981, 27, 472–482. [Google Scholar] [CrossRef] [Green Version]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Guo, Z.; Chen, Q.; Wu, G.; Xu, Y.; Shibasaki, R.; Shao, X. Village Building Identification Based on Ensemble Convolutional Neural Networks. Sensors 2017, 17, 2487. [Google Scholar] [CrossRef] [PubMed]
- Mboga, N.; Persello, C.; Bergado, J.R.; Stein, A. Detection of Informal Settlements from VHR Images Using Convolutional Neural Networks. Remote Sens. 2017, 9, 1106. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–657. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Fully Convolutional Networkss for Remote Sensing Image Classification. In Proceedings of the 2016 IEEE International on Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 5071–5074. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Combinations | BN | ReLU | LeakyReLU |
|---|---|---|---|
| – BN / ReLU | * | ||
| + BN / ReLU | * | * | |
| – BN / LeakyReLU | * | ||
| + BN / LeakyReLU | * | * |
| Stage | FCN8s | U-Net | BR-Net (−BN/ReLU) | BR-Net (+BN/ReLU) | BR-Net (−BN/LeakyReLU) | BR-Net (+BN/LeakyReLU) |
|---|---|---|---|---|---|---|
| Training (FPS) | 29.3 | 91.7 | 88.1 | 80.2 | 86.6 | 78.9 |
| Testing (FPS) | 130.2 | 280.6 | 276.5 | 252.5 | 274.1 | 249.9 |
| Methods | Precision | Recall | Overall Accuracy | F1-score | Jaccard | Kappa |
|---|---|---|---|---|---|---|
| U-Net | 0.742 | 0.922 | 0.926 | 0.818 | 0.698 | 0.773 |
| basic BR-Net 1 | 0.822 | 0.903 | 0.947 | 0.859 | 0.756 | 0.827 |
| negative BR-Net 2 | 0.768 | 0.951 | 0.936 | 0.845 | 0.739 | 0.806 |
| optimized BR-Net 3 | 0.857 | 0.885 | 0.952 | 0.869 | 0.772 | 0.840 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, G.; Guo, Z.; Shi, X.; Chen, Q.; Xu, Y.; Shibasaki, R.; Shao, X. A Boundary Regulated Network for Accurate Roof Segmentation and Outline Extraction. Remote Sens. 2018, 10, 1195. https://doi.org/10.3390/rs10081195
Wu G, Guo Z, Shi X, Chen Q, Xu Y, Shibasaki R, Shao X. A Boundary Regulated Network for Accurate Roof Segmentation and Outline Extraction. Remote Sensing. 2018; 10(8):1195. https://doi.org/10.3390/rs10081195
Chicago/Turabian StyleWu, Guangming, Zhiling Guo, Xiaodan Shi, Qi Chen, Yongwei Xu, Ryosuke Shibasaki, and Xiaowei Shao. 2018. "A Boundary Regulated Network for Accurate Roof Segmentation and Outline Extraction" Remote Sensing 10, no. 8: 1195. https://doi.org/10.3390/rs10081195
APA StyleWu, G., Guo, Z., Shi, X., Chen, Q., Xu, Y., Shibasaki, R., & Shao, X. (2018). A Boundary Regulated Network for Accurate Roof Segmentation and Outline Extraction. Remote Sensing, 10(8), 1195. https://doi.org/10.3390/rs10081195