2.1. Methods for 3D Point Cloud Geometric Modelling
3D reconstruction from indoor point cloud data gravitates around different approaches for automatic modelling with different granularities. The chosen method is often guided by the application needs in term of precision, resolution, complexity and completeness. For example, semantic model utilizations [
36] include the creation of as-built models for the monitoring of construction processes, while visually appealing virtual models of historical sites enable immersive experiences. While the latter emphasize high-quality visuals, semantic applications often rely on approximate reconstructions of the global scene which convey the object arrangement. Both semantic and virtual indoor 3D models can be extended using precise metric information to provide key information for public buildings or to assist indoor navigation. Several works address these different characteristics through shape representation, which has been extensively studied in the last century. Generally, we look for perceptually important shape features in either the shape boundary information, or the boundary plus interior content, as noted in [
37].
We can primarily distinguish between explicit and implicit shape representations. Explicit representations translate the shape of an object (e.g., a triangle mesh), while implicit representations indirectly encode the shape using a set of features (histograms, normal, curvature, etc.). Explicit representations are well suited for modelling 3D objects, whereas implicit representations are most often used for 3D object recognition and classification [
38]. In most reviews, point cloud modelling approaches are categorized regarding the type of representation, the type of input data or the type of algorithms used. In this section, we will study the algorithms depending on their context and available information, similar to F. Remondino in [
39].
3D reconstructions that make use only of the spatial attributes within point cloud data are found in many works. Delaunay-based methods are quite common in this area, and we invite the reader to study [
40] for a comprehensive survey of these methods. These approaches place rather strong requirements on the data and are impractical for scanned real-world scenes containing significant imperfections. Also, it is often necessary to optimize the polycount (total number of triangular polygons it takes to draw the model in 3D space) for memory efficiency. As such, quad meshing [
41] can lighten the representation and smoothness. A practical example of Boundary-Representation (B-Rep) can be found in Valero et al. [
42] for the reconstruction of walls. While these are interesting for their low input requirements, we investigate techniques more fitted toward dealing with challenging artifacts such as occlusion. Berger et al. [
43,
44] propose an exhaustive state-of-the-art surface reconstruction from point clouds. They reviewed thirty-two point cloud modelling methods by comparing their fit to noisy data, missing data, non-uniform sampling, and outliers, but also their requirements in terms of input features (normal, RGB data, scan data, etc.) and shape class (CAD, indoor, primitives, architectural, etc.). While surface smoothness approaches such as tangent planes, Poisson and Graph-Cut [
44] can quickly produce a mesh, they often lack robustness to occlusion and incompletion. Sweeping models, primitive instancing, Whitney regular stratification or Morse decompositions [
45] may be used for applications in robot motion planning and generally provide a higher tolerance for missing data.
Primitives are good candidates for indoor modelling with a high generalization potential, a low storage footprint and many application scenarios. Indeed, as noticed by the authors in [
46], parametric forms are “
mathematically complete, easily sampled, facilitate design, can be used to represent complex object geometries and can be used to generate realistic views”. They describe a shape using a model with a small number of parameters (e.g., a cylinder may be represented by its radius, its axis, and the start and end points). They can also be represented non-parametrically or converted through the process of tessellation. This step is used in polygon-based rendering, where objects are broken down from abstract primitive representations to meshes. As noted by authors in [
47], indoor environments are often composed of basic elements, such as walls, doors, windows, furniture (chairs, tables, desks, lamps, computers, cabinets) which come from a small number of prototypes and repeat many times. Such building components are generally formed of rigid parts whose geometries are locally simple (they consist of surfaces that are well approximated by planar, cylindrical, conical and spherical shapes.). An example is given in the work of Budroni and Boehm [
48], where the authors model walls by fitting CAD primitives. Furthermore, although variability and articulation are central (a door swings, a chair is moveable or its base rotates), such changeability is often limited and low dimensional. Thus, simple shapes are extensively used in the first steps of as-built modelling due to their compactness and the low number of parameters allowing efficient fitting methods [
49]. For more complex shapes, explicit parametric representations are still available (e.g., Bézier curves, B-spline, NURBS) but they are mostly used as design tools. Since their control points cannot easily be inferred from point cloud data, these representations are rarely used in shape analysis. An example of parametric collection is given by Lee et al. [
50]. They propose a skeleton-based 3D reconstruction of as-built pipelines from laserscan data. The approach allows the fully automated generation of as-built pipelines composed of straight cylinders, elbows, and tee pipes directly fitted. While the method provides good results, its specificity restrains a possible generalization. Fayolle and Pasko [
51] highlight the interaction potential given by parametrized objects within indoor environments. Indeed, through a clever binary CSG (Constructive Solid Geometry) or n-ary (FRep) construction tree structure, they store object-relations such that the user could modify individual parts impacting the entire logic of the object construction, including its topology. Such a parametrized model reconstruction is required in many fields, such as mechanical engineering or computer animation. Other relevant works highlight the papers of Fathi et al. [
36] for civil infrastructure reconstruction, or Adan and Huber [
52], which provides a 3D reconstruction methodology (wall detection, occlusion labelling, opening detection, occlusion reconstruction) of interior wall surfaces which is robust to occlusion and clutter. Both results are a primitive-based assembly based on these surfaces.
While parametric assemblage gives a lot of flexibility, in some cases, such as for highly complex shapes, there is a need for low geometric modelling deviations. In such scenarios, non-parametric representations such as polygonal meshes are employed to better fit the underlying data. However, the lack of compactness of these representations limits their use, especially when dealing with large point clouds. Hence, using a combination of both representations is advisable when a global representation is required. In such approaches, parametric representations are usually used as local representations and decomposed into parts (e.g., using CSG to represent each part with one or more geometric primitives). In contrast, triangle meshes are flexible enough to be used as global representations, since they can describe free-form objects in their entirety [
38]. For example, Stamos et al. [
53] present such a 3D modelling method on a church environment by combining planar segments and mesh elements. Using a different approach, Xiao and Furukawa [
19] propose the “Inverse CSG” algorithm to produce compact and regularized 3D models. A building is sliced, and for each slice, different features (free space constraint, line extraction, iterative 2D CSG model reconstruction) are extracted, stacked and textured to obtain a 3D model of walls. The method is interesting for its approach to leveraging 2D features and its noise robustness, but it will not process complex structures, furniture or non-linear walls. Other hybrid approaches introduced knowledge within workflows to try to overcome the main challenges, especially missing data. A significant work was published by Lafarge et al. [
54], which develops a hybrid modelling process where regular elements are represented by 3D primitives whereas irregular structures are described by mesh-based surfaces. These two different types of 3D representation interact through a non-convex energy minimization problem described in [
55]. The approach successfully employed for large outdoor environments shows the benefits of leveraging semantics for better point cloud fitting. The authors in [
56] present a reverse engineering workflow based on a hybrid modelling approach while also leveraging knowledge. They propose a linear modelling approach through cross-section of the object by fitting splines to the data and then sweeping the cross-section along a trajectory to form the object model. To realize such operations, they first extracted architectural knowledge based on the analysis of architectural documents to be used for guiding the modelling process. An example illustrated in [
57] provides a method to reconstruct the boundaries of buildings by extracting walls, doors, roofs and windows from façade and roofs point clouds. The authors use convex or concave polygons adjusted to different features separately. Interestingly, we note that the authors use knowledge to generate assumptions for the occluded parts. Finally, all polygons are combined to generate a polyhedron model of a building. This approach is interesting for its whole-to-part consideration, which leverages knowledge to optimize the ratio approximation/compactness.
While triangulation and hybrid modelling can be successfully used for various indoor scenarios, we notice that the most prominent module is the parametric modelling method. Its fit to both B-Rep and volumetric modelling accompanied by its high flexibility in representativity at different granularity levels will thus be further investigated in
Section 3. Also, we notice that in some works, the use of knowledge makes it possible to better describe shapes when used within the modelling workflow. We will thus investigate the literature for KI and KR in
Section 2.3.
2.2. Instance-Based Object Recognition and Model Fitting
Man-made objects populating indoor scenes often have low degrees of freedom and are arrangements of simple primitives. Beneath representation and compression efficiency [
53,
54,
55], there is a real need to independently model different objects of interest that can in turn host different relationship information. The process of instance-based object recognition is required for identifying objects with a known shape, or objects that are repeated throughout a facility. The predominance of primitive forms in these environments gives specific shape descriptors major control over the implicit representation. These can be categorized as geometric feature descriptors and symmetric feature descriptors. In many works, we find that planar detection plays a predominant role for the detection of elements in KE, specifically segmentation workflow.
Geometric feature descriptors: As such, predominant algorithms for geometric featuring in scientific literature are RANSAC [
58,
59,
60,
61,
62,
63,
64,
65,
66], Sweeping [
67], Hough [
68,
69,
70,
71] and PCA [
61,
72,
73,
74,
75,
76,
77]. The authors [
61,
78] provide a robust PCA approach for plane fitting. The paper by Sanchez [
63] primarily makes use of RANSAC to detect most building interiors, that may be modelled as a collection of planes representing ceilings, floors, walls and staircases. Mura et al. [
79] partitions an input 3D model into an appropriate number of separate rooms by detecting wall candidates and then studying the possible layout by projecting the scenarios in a 2D space. Arbeiter et al. [
80] present promising descriptors, namely the Radius-Based Surface Descriptor (RSD), Principal Curvatures (PC) and Fast Point Feature Histograms (FPFH). They demonstrate how they can be used to classify primitive local surfaces such as cylinders, edges or corners in point clouds. More recently, Xu et al. [
81] provide a 3D reconstruction method for scaffolds from a photogrammetric point cloud of construction sites using mostly point repartitions in specific reference frames. Funkhouser et al. [
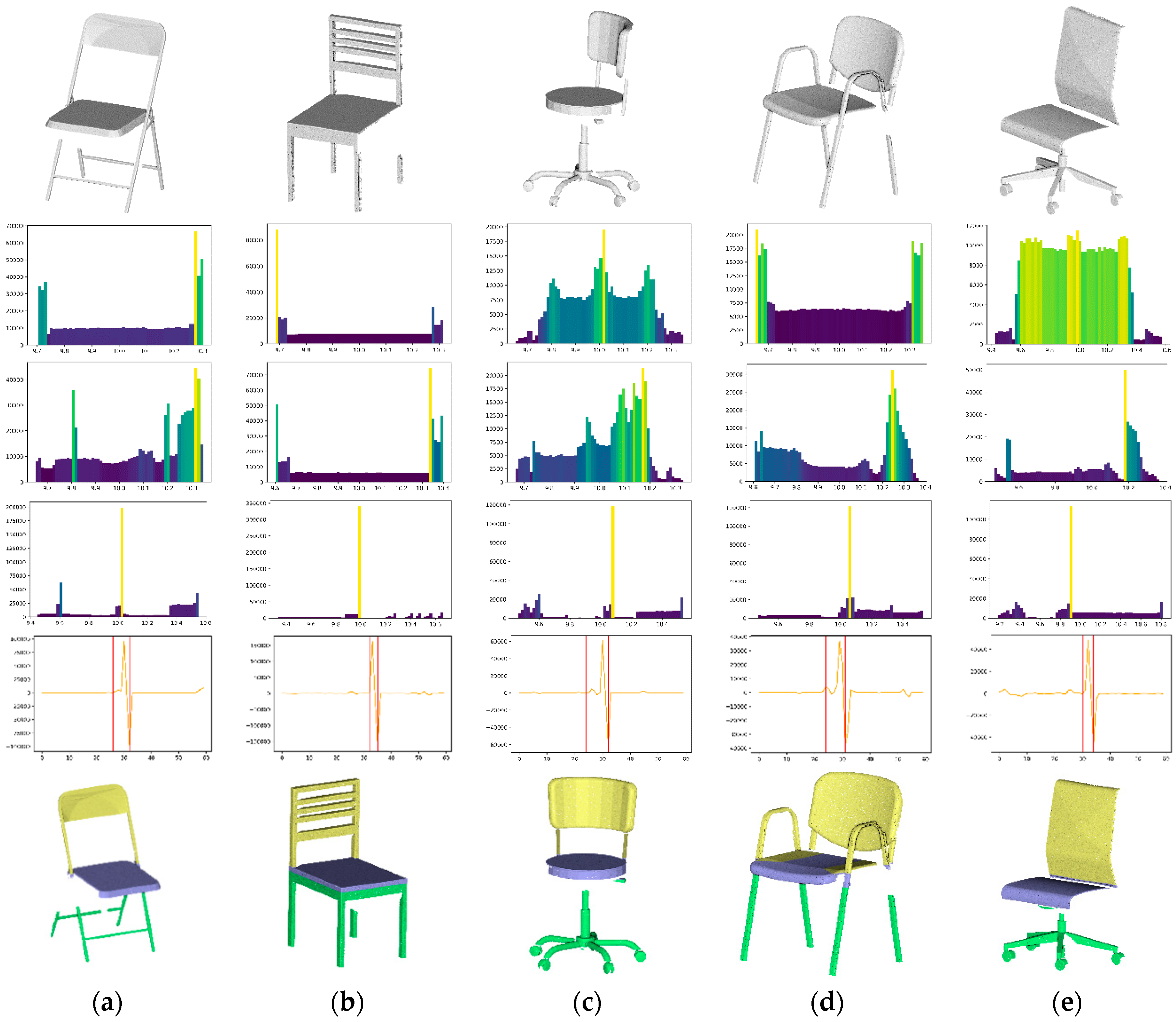
82] also propose a matching approach based on shape distributions for 3 models. They pre-process through random sampling to produce a continuous probability distribution later used as a signature for each 3D shape. The key contribution of this approach is that it provides a framework within which arbitrary and possibly degenerate 3D models can be transformed into functions with natural parameterizations. This allows simple function comparison methods to produce robust dissimilarity metrics and will be further investigated in this paper.
We find that using other sources of features both from analytical workflows as well as domain knowledge can contribute heavily to better segmentation workflows or for guiding 3D modelling processes.
Symmetry feature descriptors: Many shapes and geometrical models show symmetries—isometric transforms that leave the shape globally unchanged. If one wants to extract relationship graphs among primitives, symmetries can provide valuable shape descriptions for part modelling. In the computer vision and computer graphics communities, symmetry has been identified as a reliable global knowledge source for 3D reconstruction. The review in [
83] provides valuable insights on symmetry analysis both at a global and local scale. It highlights the ability of symmetries to extract features better, describing furniture using a KR, specifically an ontology. In this paper, the extracted symmetric patches are treated as alphabets and combined with the transforms to construct an inverse-shape grammar [
84]. The paper of Martinet et al. [
85] provides an exhaustive review of accurate detection of symmetries in 3D Shapes. These are used for planar and rotational symmetries in Kovacs et al. [
86] to define candidates’ symmetry planes for perfecting CAD models by reverse engineering. The paper is very interesting for its ability to leverage knowledge about the shape symmetries. Adan and Huber [
52] list façade reconstruction methods, mainly based on symmetry study and reconstitution of planar patches, and then proposes a method that can handle clutter and occluded areas. While they can achieve a partial indoor reconstruction of walls and openings, it necessitates specific scan positions independently treated by ray-tracing. All these features play an important role for implicit geometric modelling, but also in shape-matching methods.
Feature-based shape matching: For example, symmetry descriptors are used to query a database for shape retrieval in [
87]. The authors in [
88] propose a model reconstruction by fitting from a library of established 3D parametric blocks, and Nan et al. [
89] make use of both geometric and symmetric descriptors to best-fit candidates from a 3D database, including a deformable template fitting step. However, these methods often include a pre-segmentation step and post-registration phase, which highly condition the results and constrain the methodology to perfect shapes without outliers or missing data. Following this direction, F. Bosché [
90] proposes a method using CAD model fitting for dimensional compliance control in construction. The approach is robust to noise and includes compliance checks of the CAD projects with respect to established tolerances to validate the current state of construction. While the approach permits significant automation, it requires a coarse registration step to be performed by manually defining pair points in both datasets. To automate the registration of models with candidates, the Iterative Closest Point (ICP) method [
91] is often used for fine registration, with invariant features in [
92], based on least squares 3D surface and curve matching [
93], non-linear least squares for primitive fitting [
94] or using an energy minimization in graph [
95]. The recent works of Xu et al. in [
96,
97] present a global framework where co-segmented shapes are deformed by scaling corresponding parts in the source and target models to fit a point cloud in a constrained manner using non-rigid ICP and deformation energy minimization. These works are foundations and provide research directions for recovering a set of locally fitted primitives with their mutual relations.
We have seen that knowledge extraction for indoor scenario is mostly driven by three categories of features namely geometric, symmetric and for shape matching. Moreover, object-relationships among the basic objects of these scenes satisfy strong priors (e.g., a chair stands on the floor, a monitor rests on the table) as noted by [
47], which motivates the inclusion of knowledge through KI for a better scene understanding and description.
2.3. Knowledge Integration (KI) for Object-Relationship Modelling
3D indoor environments demand to be enriched with semantics to be used in the applications described in
Section 1. This has led to the creation of standards such as LADM [
98], IndoorGML [
99] or IFC (Industry Foundation Class) [
100], which were motivated by utilizations in the AEC industry, navigation systems or land administration. Indeed, the different models can deal with semantically annotated 3D spaces and can operate with abstract spaces and subdivision views, and have a notion of geometry and topology while maintaining the relationship between objects. The choice of one model or another is mainly guided by usage and its integration within one community. Therefore, semantically rich 3D models provide a great way to extend the field of application and stresses new ways to extract knowledge a priori for a fully autonomous Cognitive Decision System (CDS). The CDS can, in turn, open up new solutions for industries listed in the Global Industry Classification Standard [
101].
In their work, Tang et al. [
38] separate this process into geometric modelling, object recognition, and object relationship modelling. Whereas a CAD model would represent a wall as a set of independent planar surfaces, a BIM model would represent the wall as a single, volumetric object with multiple surfaces, as well as adjacency relationships between the wall and other entities in the model, the identification of the object as a wall, and other relevant properties (material characteristics, cost, etc.). This includes topological relationships between components, and between components and spaces. Connectivity relationships indicate which objects are connected to one another and where they are connected. Additionally, containment relationships are used to describe the locations of components that are embedded within one another (e.g., a window embedded within a wall).
Ochmann et al. [
69] present an automatic reconstruction of parametric walls and openings from indoor point clouds. Their approach reconstructs walls as entities with constraints on other entities, retaining wall relationships and deprecating the modification of one element onto the other. The authors of [
23,
102,
103,
104] extend the processes of the parametric modelling of walls and openings to BIM modelling applications. More recently, the paper by Macher et al. [
68] presented a semi-automatic approach for the 3D reconstruction of walls, slabs and openings from a point cloud of a multi-storey building, and provides a proof of concept of OBJ for IFC manual creation. While these approaches have contributed to new possibilities for the semantic modelling of walls and slabs, the object-relationship is limited to topological relationships.
The work of Fisher in [
105] introduces domain knowledge of standard shapes and relationships into reverse engineering problems. They rightfully state that there are many constraints on feature relationships in manufactured objects and buildings which are investigated in this paper. Indeed, for a general workflow, one must provide a recovery process even when data is very noisy, sparse or incomplete through a general shape knowledge. Complete data acquisition (impossible in practice for some situations) through inference of occluded data permits the discovery of shape and position parameters that satisfy the knowledge-derived constraints. Formalizing knowledge would therefore be useful to apply known relationships when fitting point cloud data and get better shape parameter estimates. It can also be used to infer data about unseen features, which directs our work to consider ontologies. In this area, the work of Dietenbeck et al. [
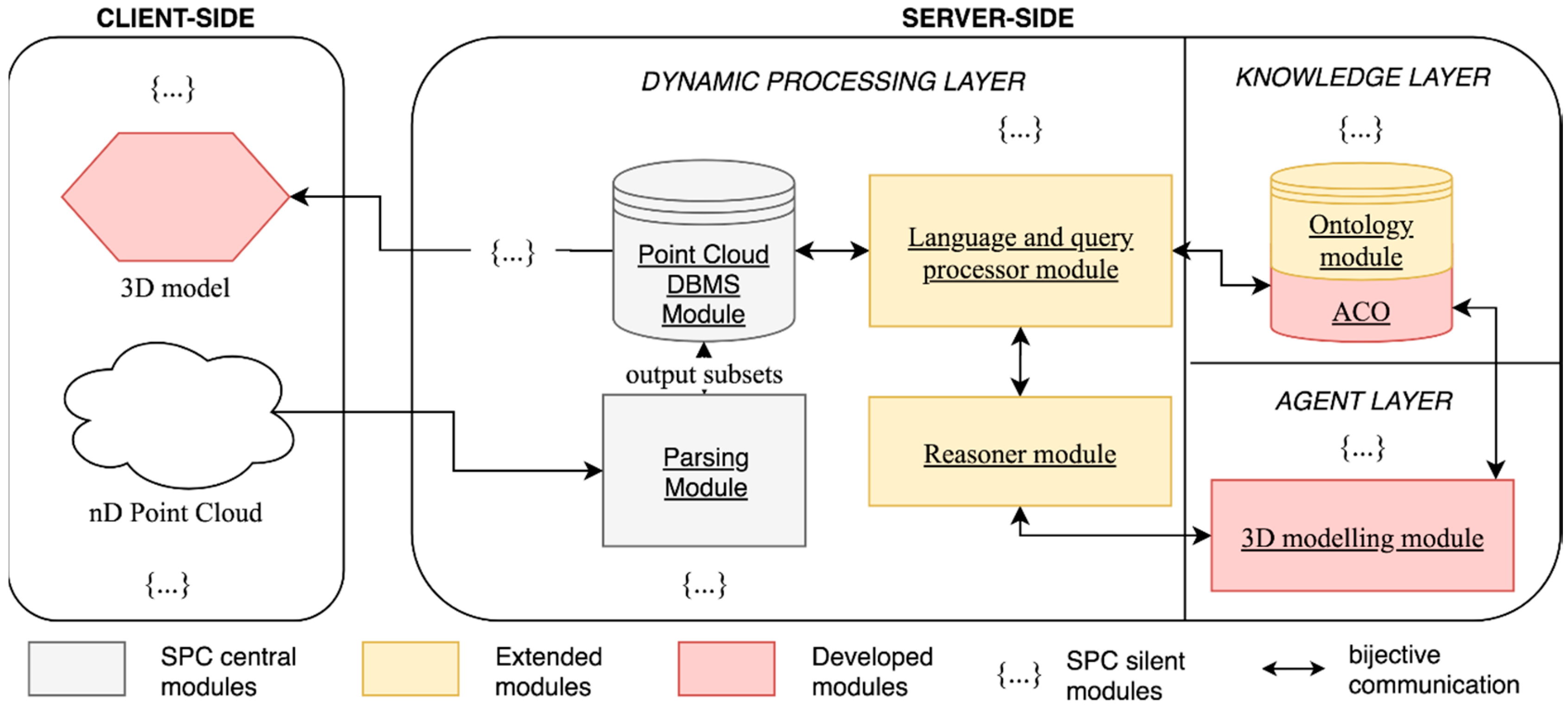
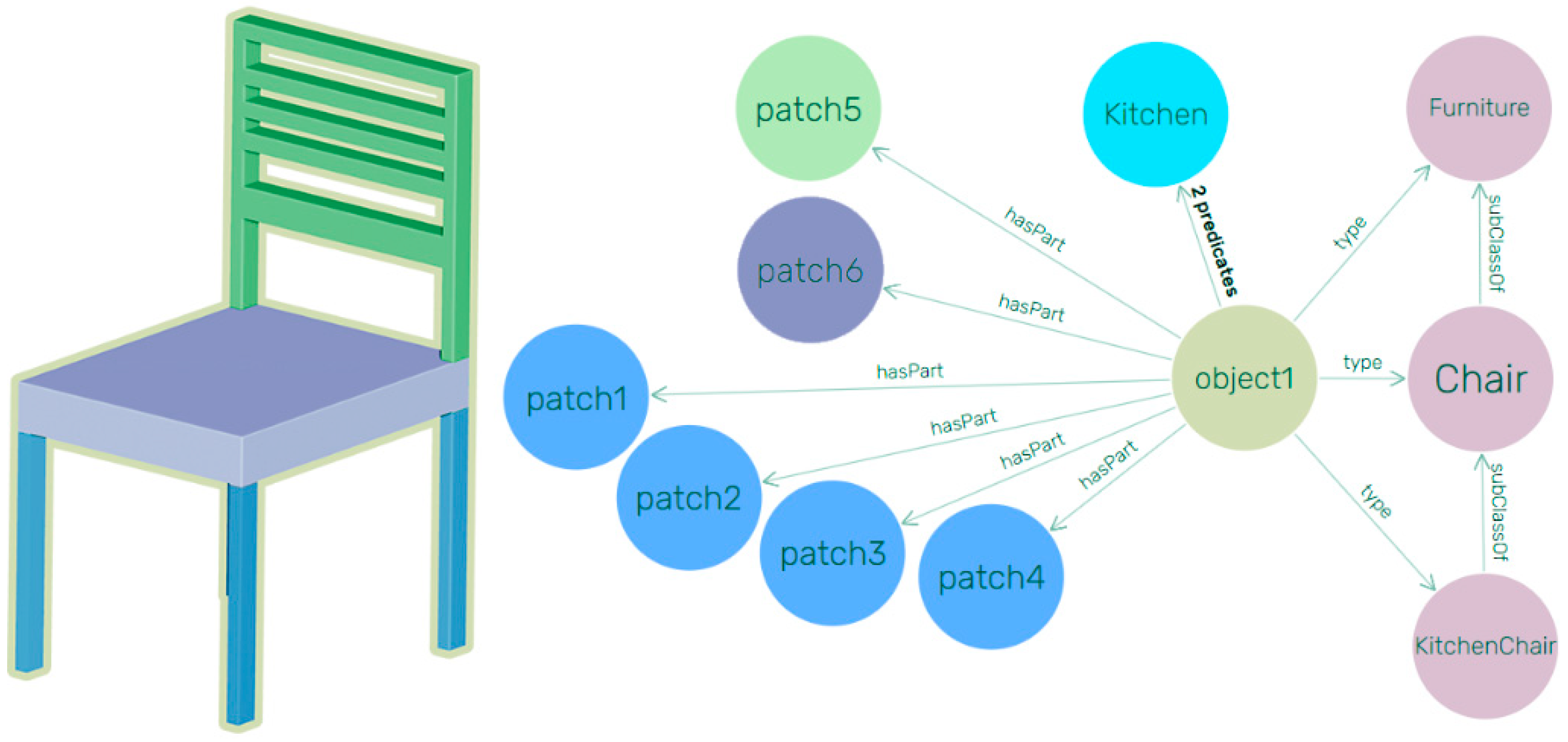
6] makes use of multi-layer ontologies for integrating domain knowledge in the process of 3D shape segmentation and annotation. While they provide only an example and a manual approach for meshes, they describe an expert knowledge system for furniture in three conceptual layers, directly compatible with the three meta-models of the Smart Point Cloud Infrastructure introduced in [
31] and extended in [
29]. The first layer corresponds to the basic properties of any object, such as shapes and structures, whereas the upper layers are specific to each application domain and describe the functionalities and possible configurations of the objects in this domain. By using domain knowledge, the authors perform searches among a set of possible objects, while being able to suggest segmentation and annotation corrections to the user if an impossible configuration is reached. This work will be further investigated within our workflow. Using a different approach, Son and Kim [
106] present a semantic as-built 3D modelling pipeline to reconstruct structural elements of buildings based on local concavity and convexity. They provide different types of functional semantics and shapes with an interesting parameter calculation approach based on analytic features and domain knowledge. These works are fundamental and greatly illustrate the added benefit of leveraging knowledge.
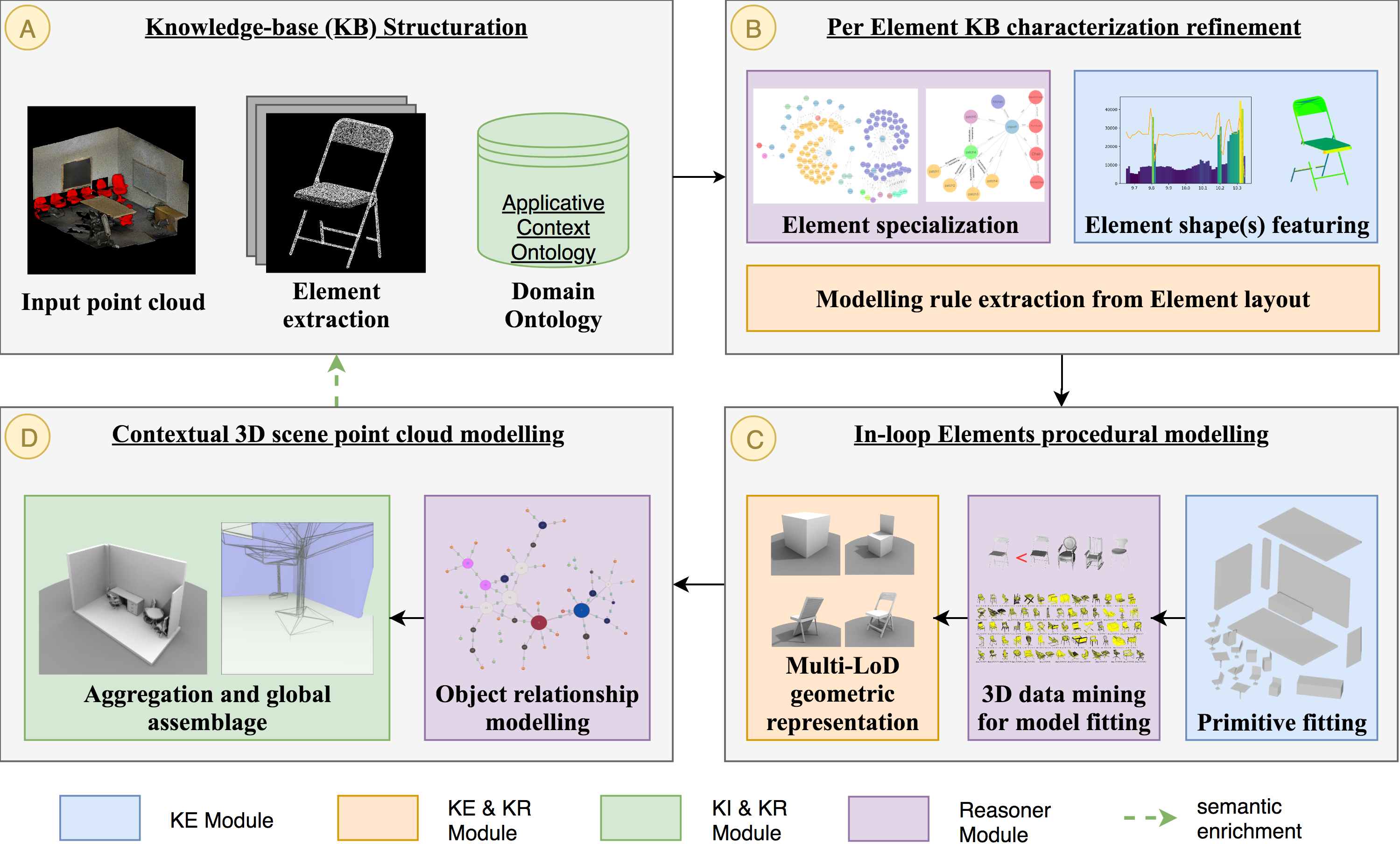
KI and KR are an important part of any intelligent system. In this review, we noticed that the use of ontologies provided an interesting addition to knowledge formalization and made it possible to better define object-relationships. Coupled with a KE approach treating geometric, symmetric and shape matching features, they could provide a solid foundation for procedural modelling based on a 3D point cloud. Therefore, we develop a method (
Section 3) inspired by these pertinent related works.



























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







