Indoor Topological Localization Using a Visual Landmark Sequence

 , , ,
, , ,
Abstract
:1. Introduction
- We propose a novel visual landmark sequence-based indoor localization (VLSIL) framework to acquire indoor location through smartphone videos.
- We propose a novel topological node representation using sematic information of indoor objects.
- We present a robust landmark detector using a convolutional neural network (CNN) for landmark detection that does not need to retrain for new environments.
- We present a novel landmark localization system built on a second order hidden Markov model to combine landmark sematic and connectivity information for localization, which is shown to relieve the scene ambiguity problem where traditional methods have failed.
- We modified the HMM2-based localization algorithm to make it work in the case where part of the multiple-object landmark is detected.
- We have conducted more comprehensive experiments to demonstrate that our landmark detector outperforms detectors based on handcrafted features.
- We further tested the algorithm in a new experimental site to verify the generality of the detector and the localization method.
- We also conducted further analysis over the factors, including landmark sequence length and map complexity, that affect the performance of the algorithm.
2. Related Work
2.1. Visual Landmark Representation
2.2. Image-Based Localization
3. Visual Landmark Sequence-Based Indoor Localization (VLSIL)
4. Landmark Detection
4.1. Offline Phase
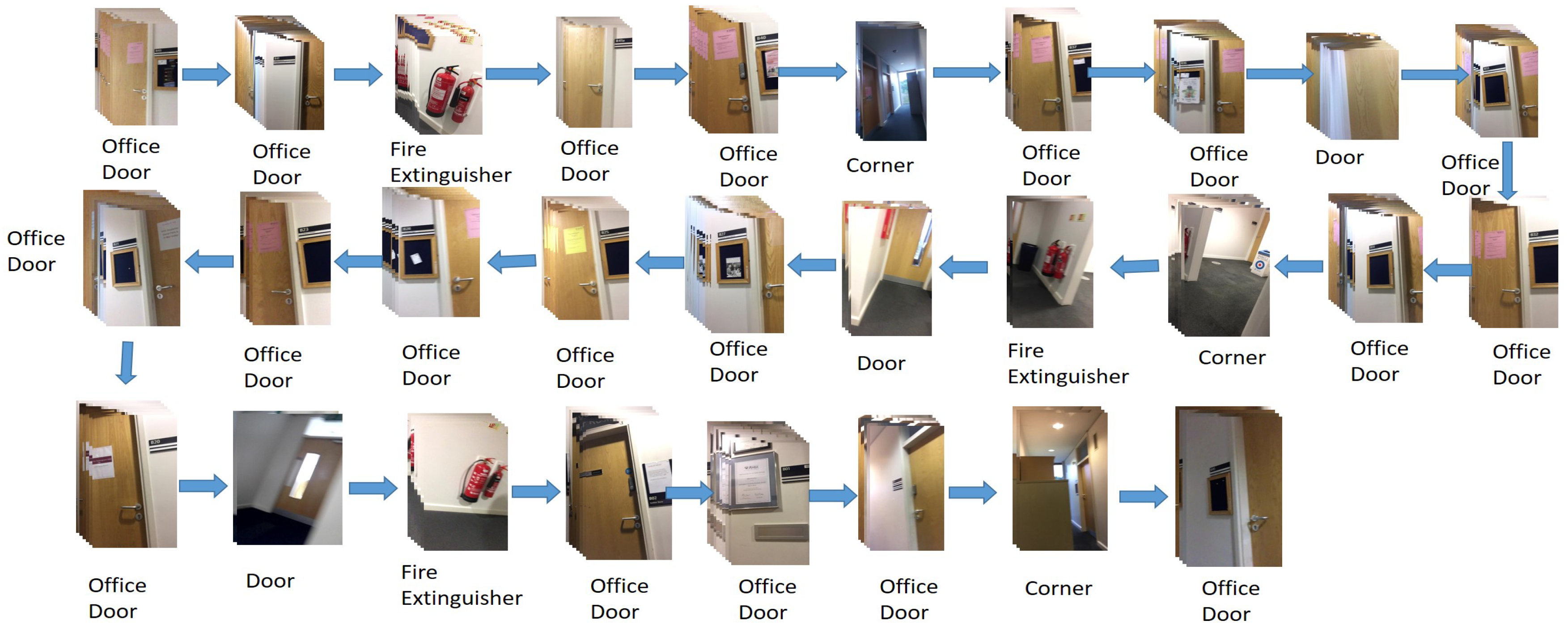
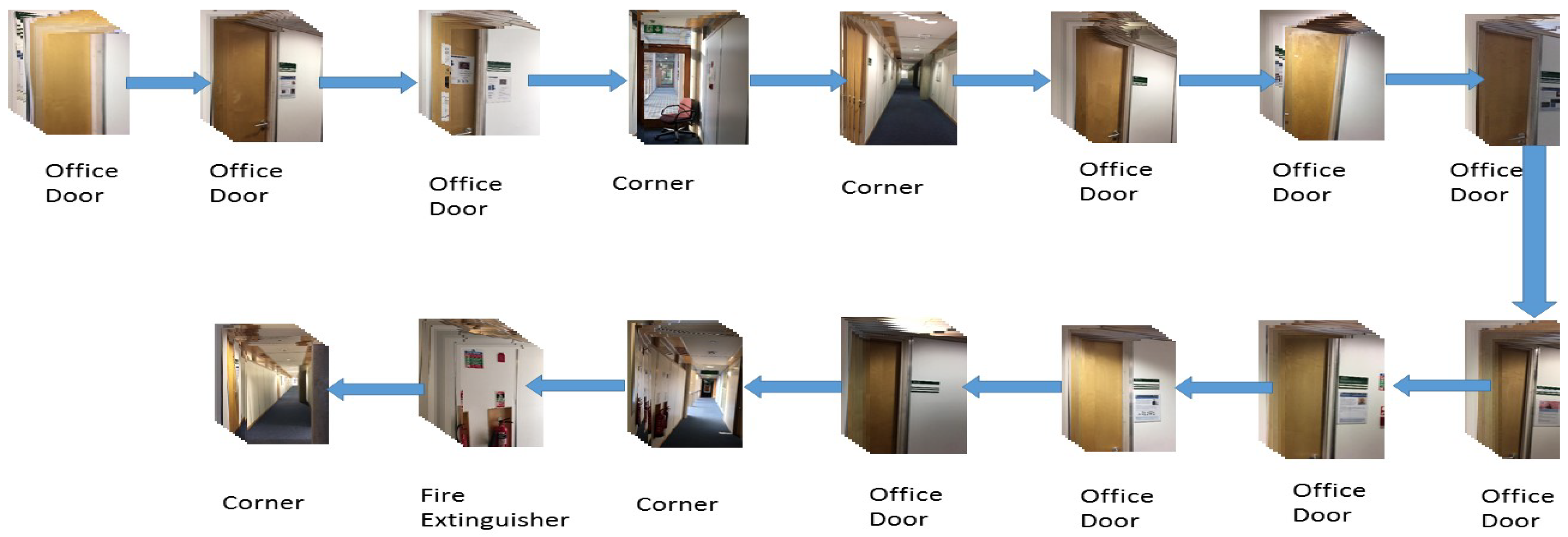
4.1.1. Landmark Definition
4.1.2. Training CNN-Based Indoor Object Classifier
4.2. Online Phase
4.2.1. Frame Extraction
4.2.2. Region Proposal
4.2.3. Landmark Type Determination
5. Visual Landmark Sequence Localization Using the Second Order Hidden Markov Model
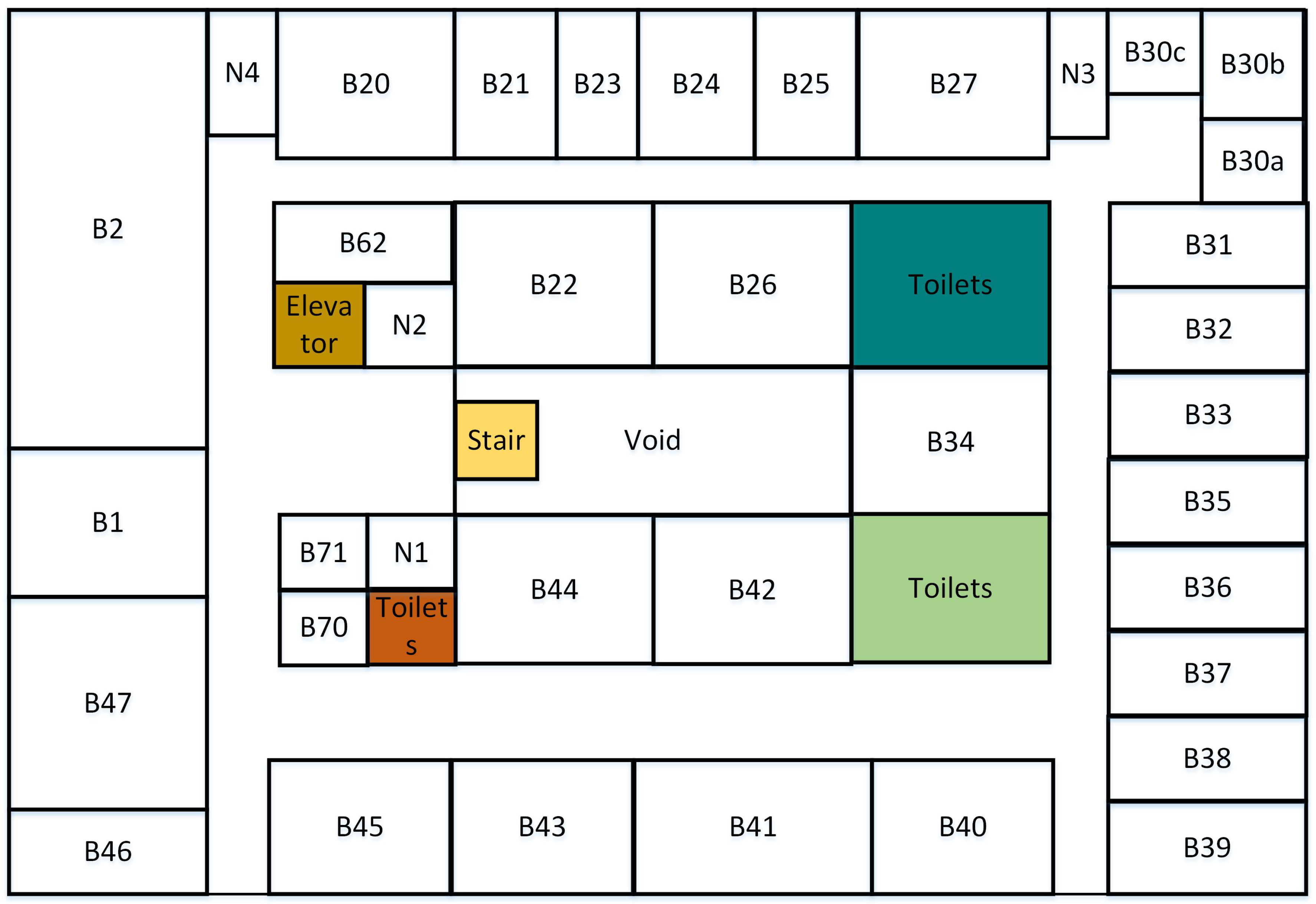
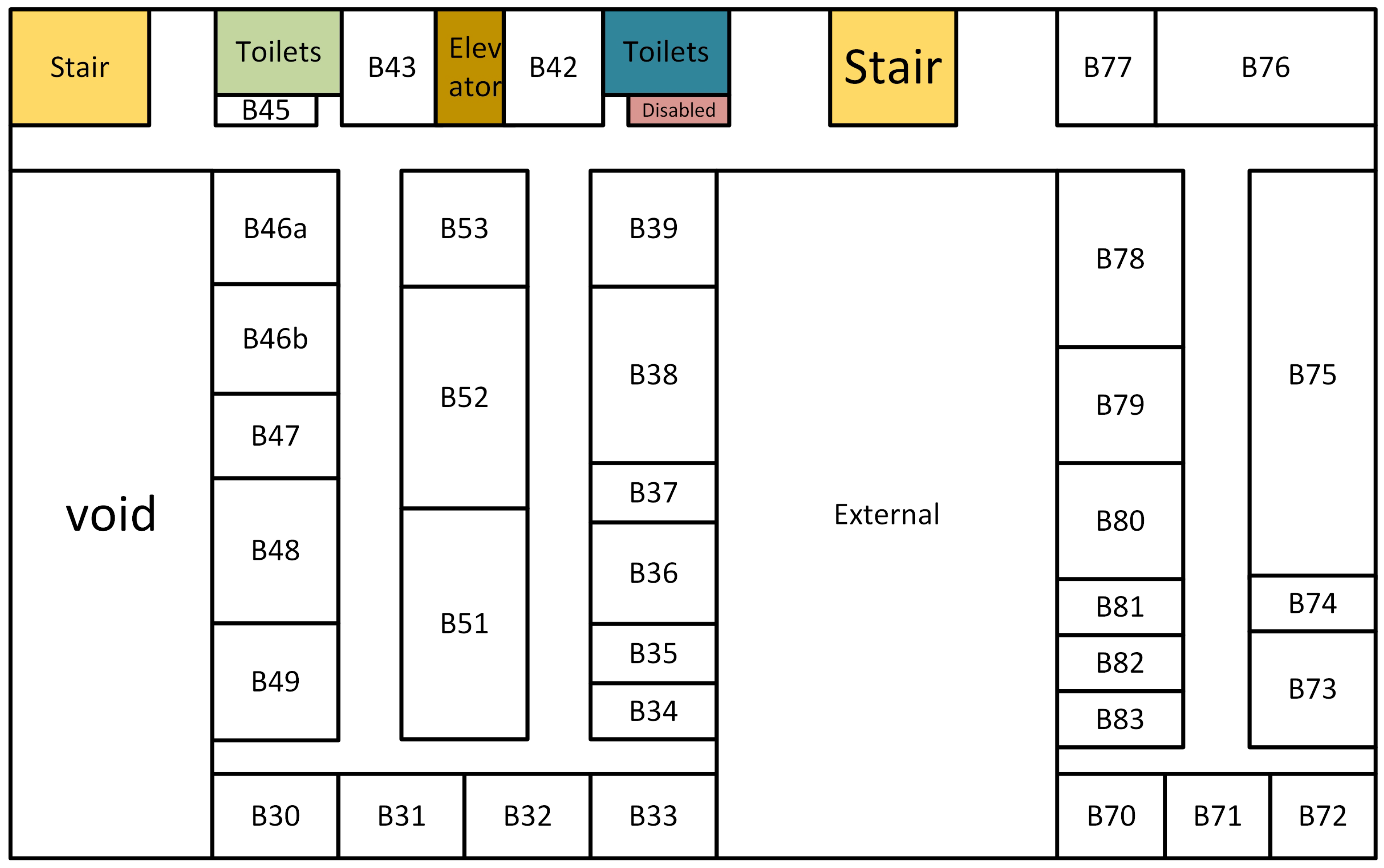
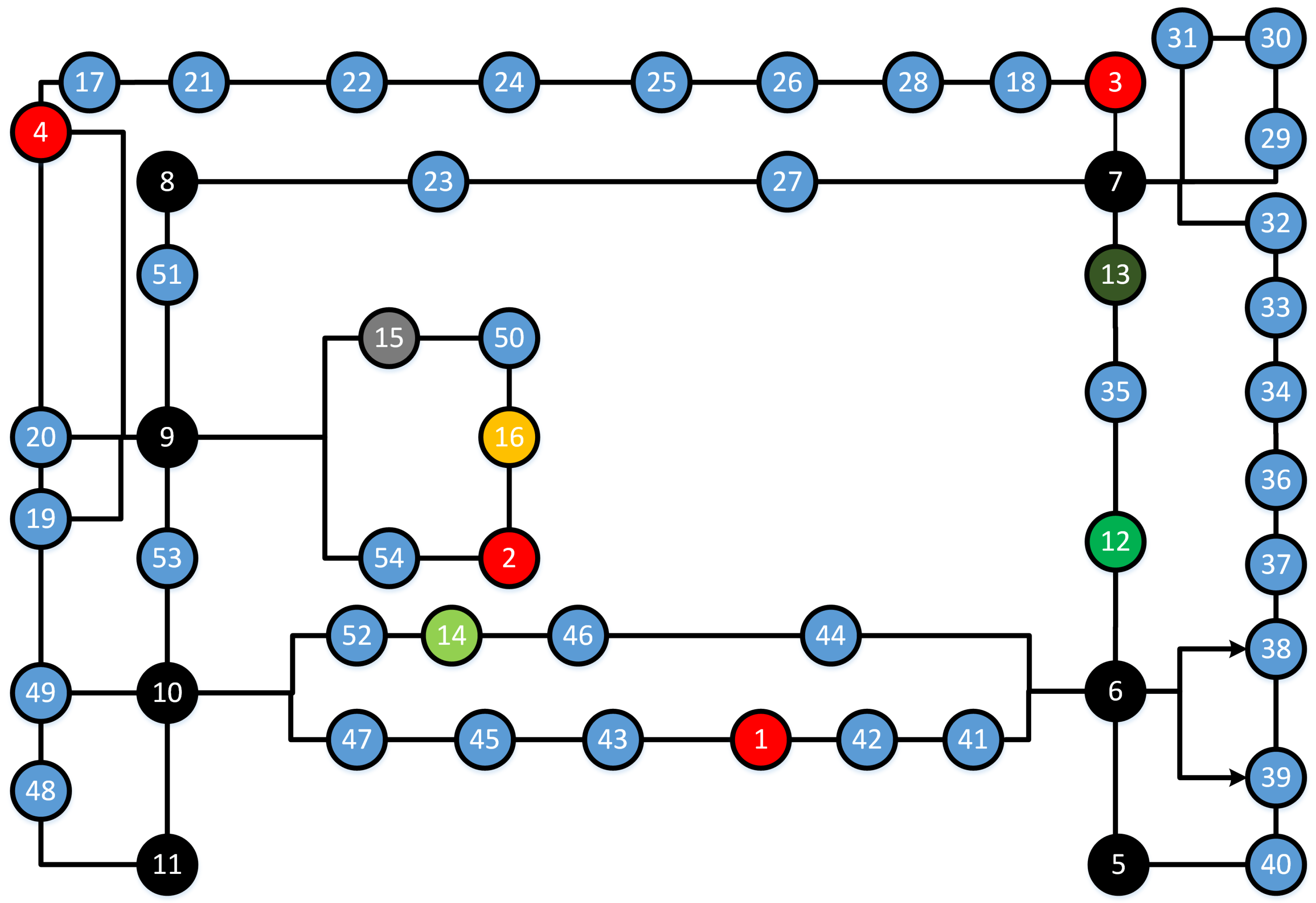
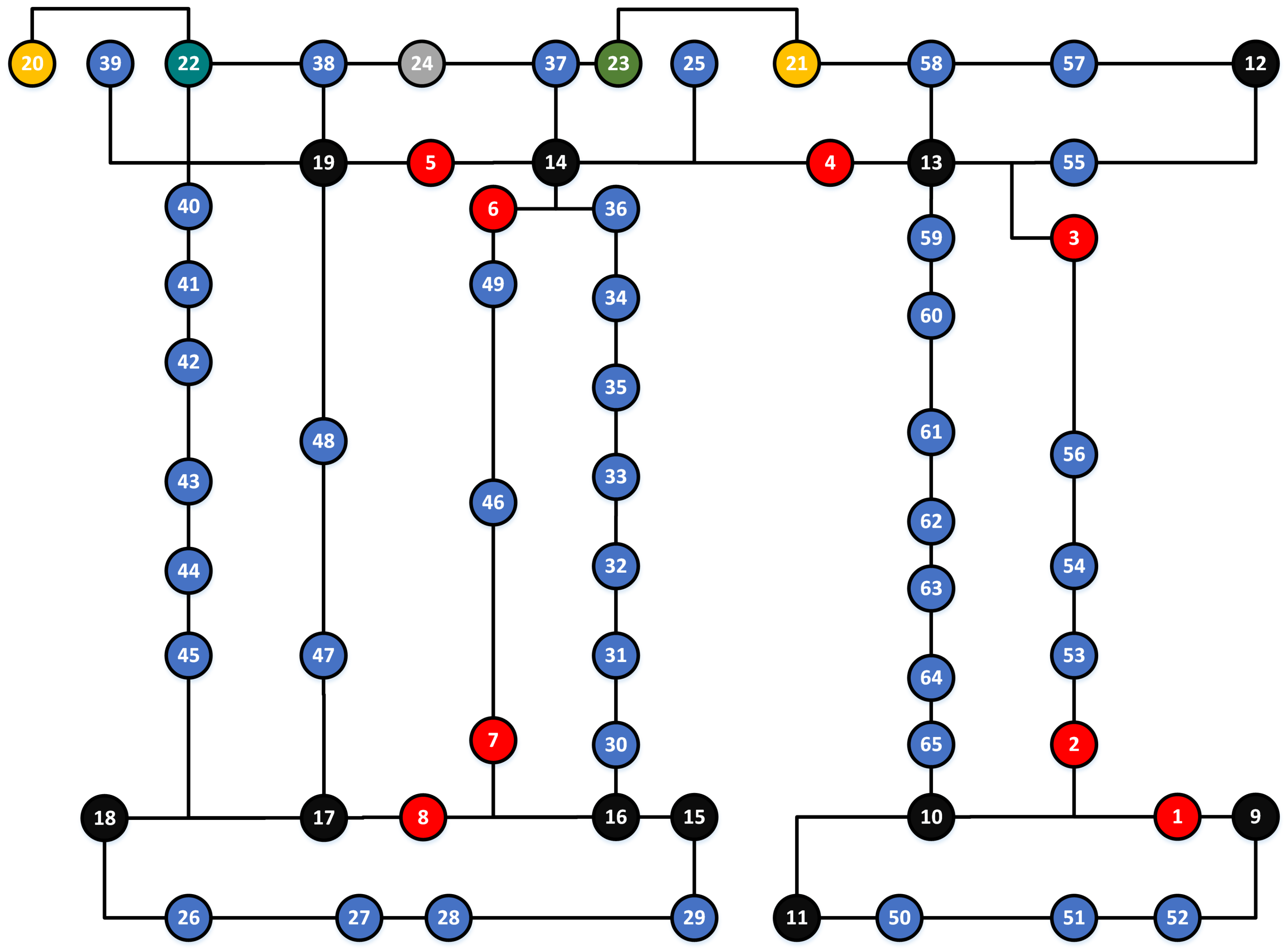
5.1. Topological Map
5.2. The Second Order Hidden Markov Model for Indoor Localization
5.2.1. The Emission Matrix of HMM2
5.2.2. The Transition Matrix of the HMM2
5.2.3. The Probabilistic Matrix of Landmark Type
5.3. The Extended Viterbi Algorithm for Indoor Localization
| Algorithm 1: Extended Viterbi finds the location sequence of maximum probability. |
| Input: A sequence of observations Y, transition matrix , emission matrix E, probabilistic matrix P, initial location Output: A sequence of states X
|
6. Evaluation
6.1. Setup
6.2. Landmark Detection
6.2.1. Indoor Object Recognition
6.2.2. Landmark Detection Performance
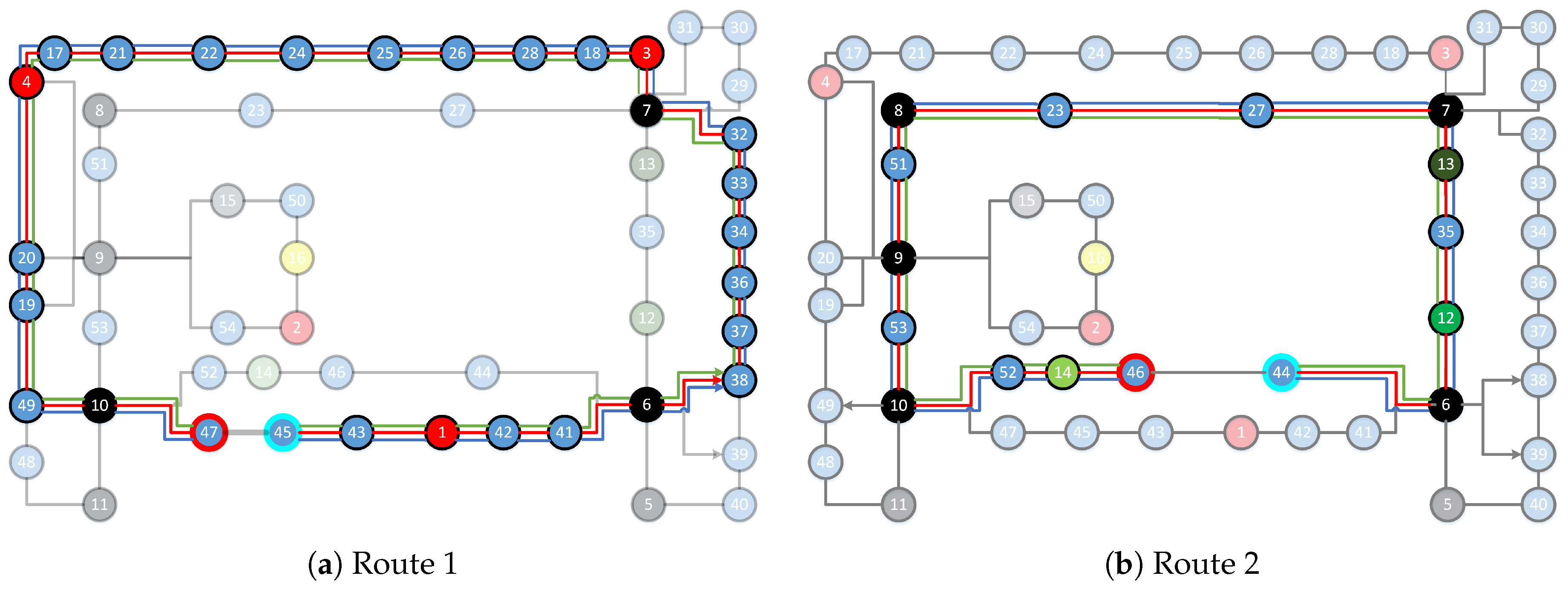
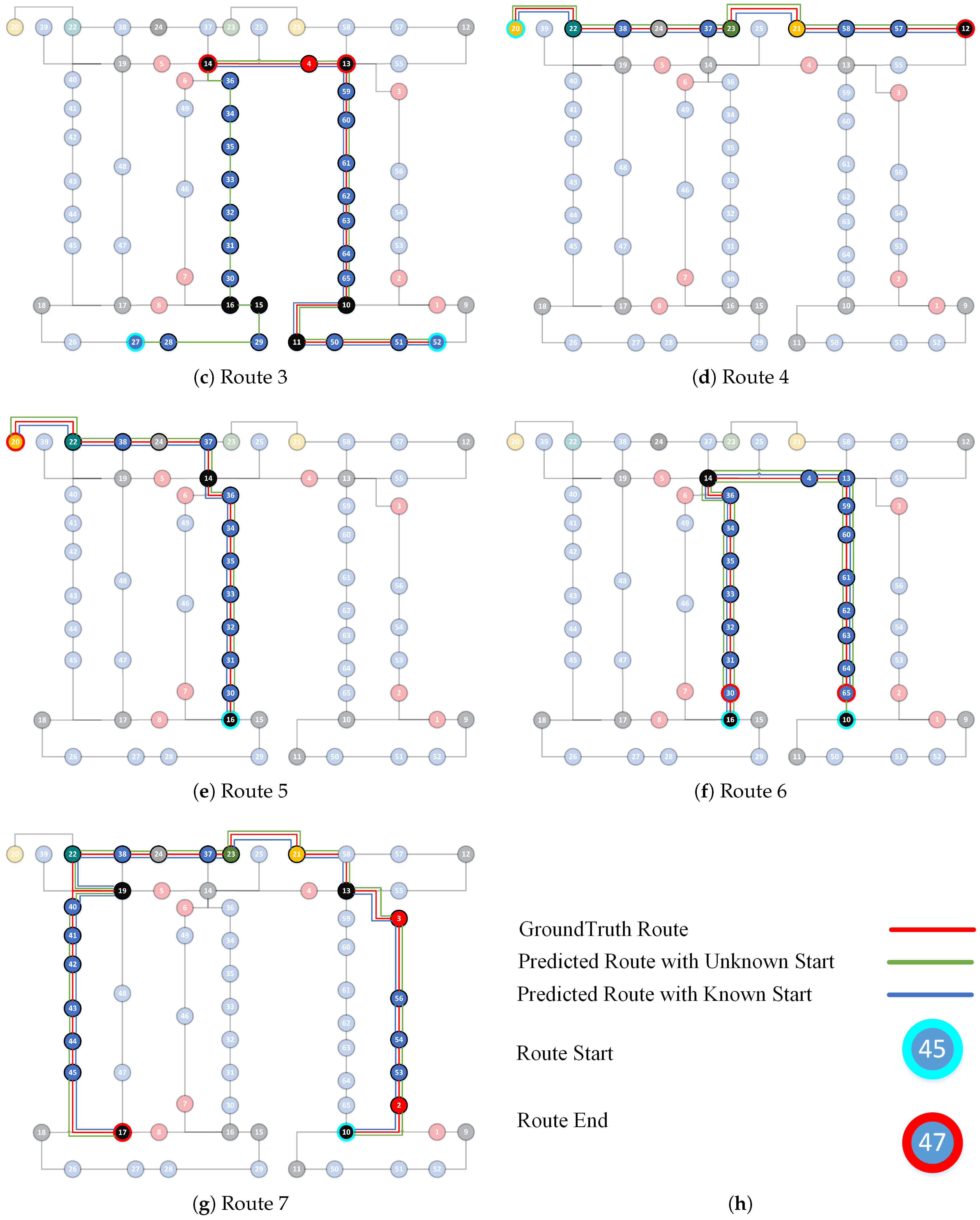
6.3. Localization
6.3.1. Performance
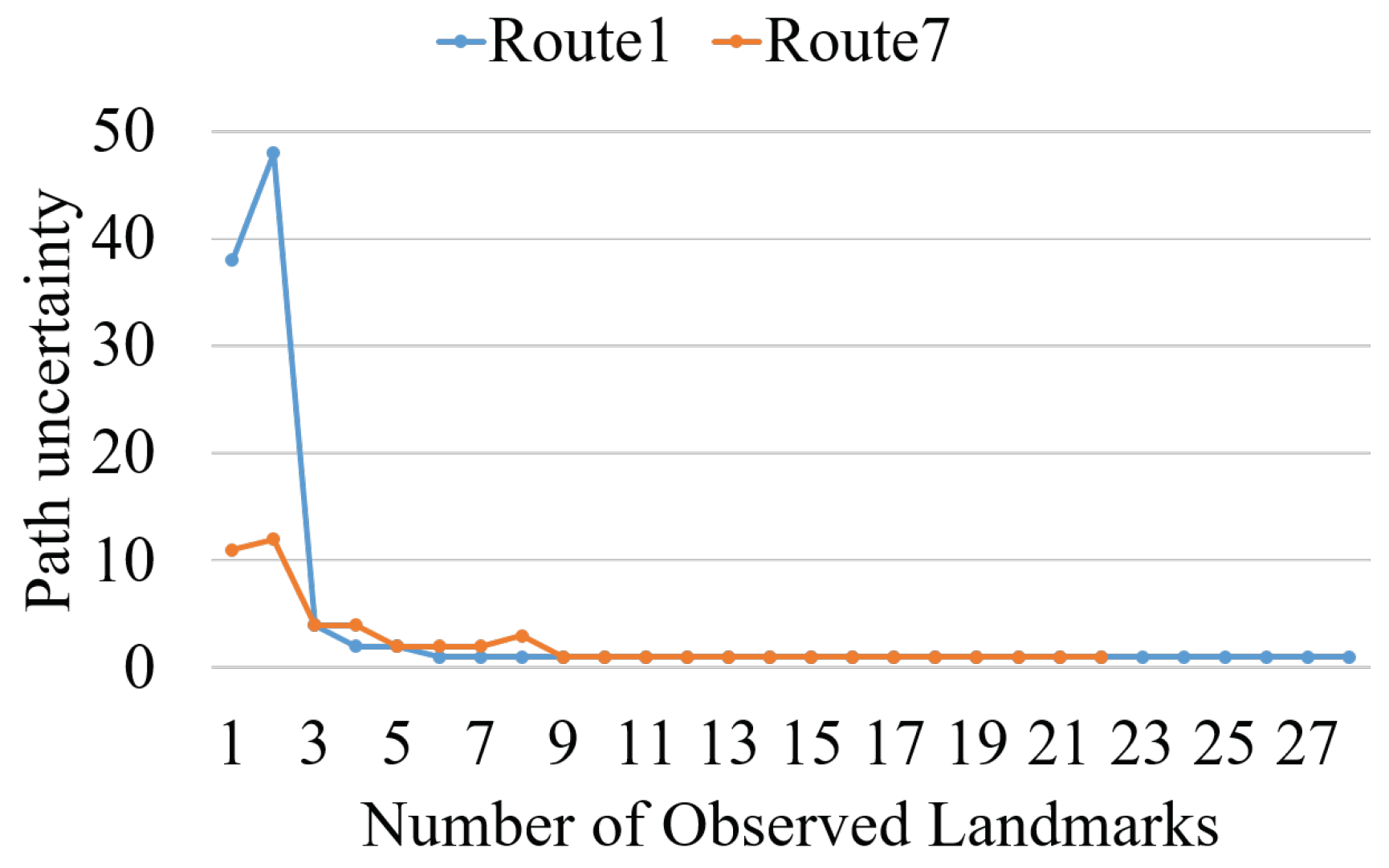
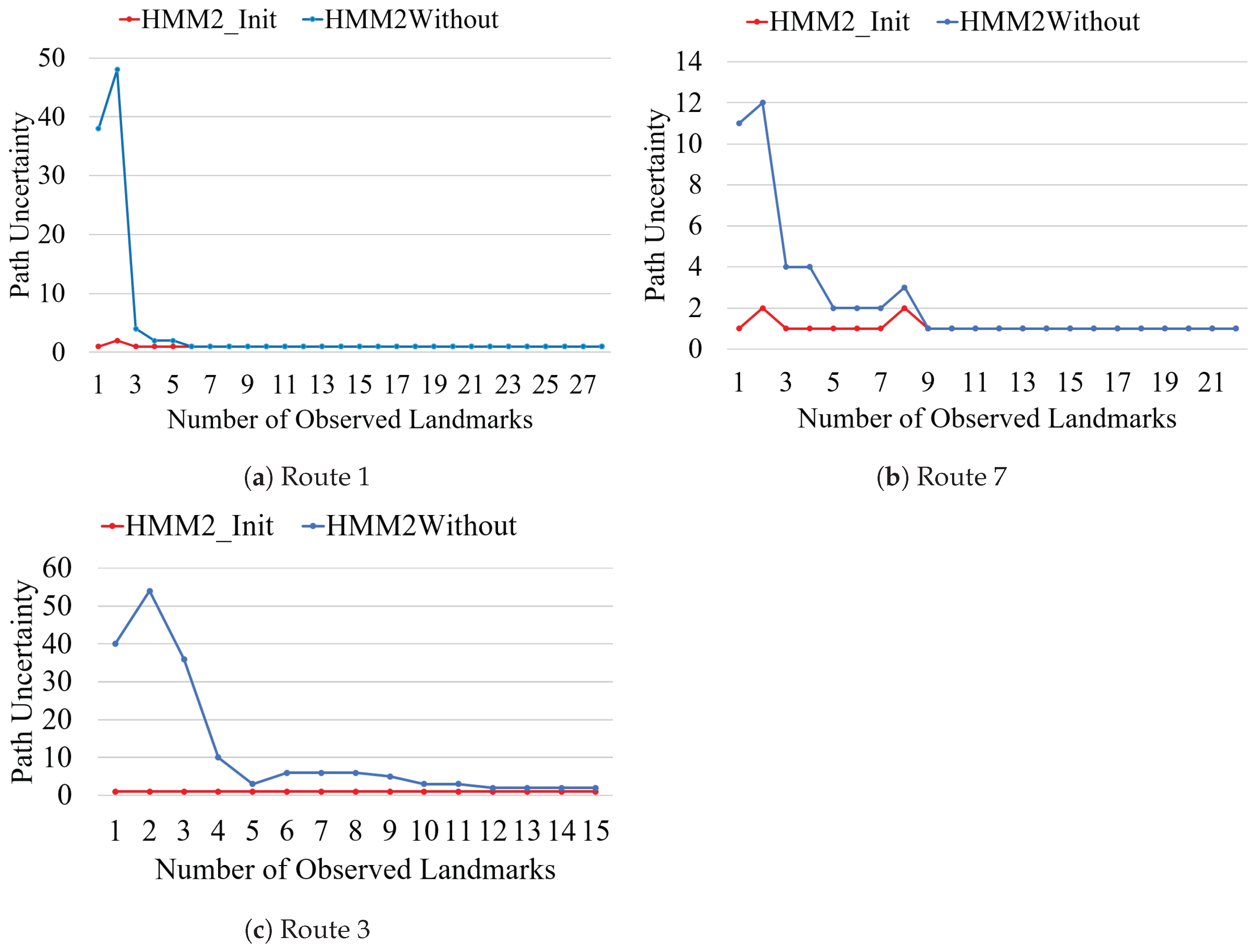
6.3.2. Analysis
7. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ranganathan, P.; Hayet, J.B.; Devy, M.; Hutchinson, S.; Lerasle, F. Topological navigation and qualitative localization for indoor environment using multi-sensory perception. Robot. Auton. Syst. 2002, 41, 137–144. [Google Scholar] [CrossRef]
- Cheng, H.; Chen, H.; Liu, Y. Topological Indoor Localization and Navigation for Autonomous Mobile Robot. IEEE Trans. Autom. Sci. Eng. 2015, 12, 729–738. [Google Scholar] [CrossRef]
- Bradley, D.M.; Patel, R.; Vandapel, N.; Thayer, S.M. Real-time image-based topological localization in large outdoor environments. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 3670–3677. [Google Scholar]
- Becker, C.; Salas, J.; Tokusei, K.; Latombe, J.C. Reliable navigation using landmarks. In Proceedings of the 1995 IEEE International Conference on Robotics and Automation, Nagoya, Japan, 21–27 May 1995; Volume 1, pp. 401–406. [Google Scholar]
- Kosecka, J.; Zhou, L.; Barber, P.; Duric, Z. Qualitative image based localization in indoors environments. In Proceedings of the 2003 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Madison, WI, USA, 18–20 June 2003; Volume 2, pp. 3–8. [Google Scholar]
- Li, Q.; Zhu, J.; Liu, T.; Garibaldi, J.; Li, Q.; Qiu, G. Visual landmark sequence-based indoor localization. In Proceedings of the 1st Workshop on Artificial Intelligence and Deep Learning for Geographic Knowledge Discovery, Los Angeles, CA, USA, 7–10 November 2017; pp. 14–23. [Google Scholar]
- Ahn, S.J.; Rauh, W.; Recknagel, M. Circular coded landmark for optical 3D-measurement and robot vision. In Proceedings of the 1999 IEEE/RSJ International Conference on Intelligent Robots and Systems, Kyongju, Korea, 17–21 October 1999; Volume 2, pp. 1128–1133. [Google Scholar]
- Jang, G.; Lee, S.; Kweon, I. Color landmark based self-localization for indoor mobile robots. In Proceedings of the 2002 IEEE International Conference on Robotics and Automation, Washington, DC, USA, 11–15 May 2002; Volume 1, pp. 1037–1042. [Google Scholar]
- Basiri, A.; Amirian, P.; Winstanley, A. The use of quick response (qr) codes in landmark-based pedestrian navigation. Int. J. Navig. Obs. 2014, 2014, 897103. [Google Scholar] [CrossRef]
- Briggs, A.J.; Scharstein, D.; Braziunas, D.; Dima, C.; Wall, P. Mobile robot navigation using self-similar landmarks. In Proceedings of the IEEE International Conference on Robotics and Automation, San Francisco, CA, USA, 24–28 April 2000; Volume 2, pp. 1428–1434. [Google Scholar]
- Hayet, J.B.; Lerasle, F.; Devy, M. A visual landmark framework for indoor mobile robot navigation. In Proceedings of the 2002 IEEE International Conference on Robotics and Automation, Washington, DC, USA, 11–15 May 2002; Volume 4, pp. 3942–3947. [Google Scholar]
- Ayala, V.; Hayet, J.B.; Lerasle, F.; Devy, M. Visual localization of a mobile robot in indoor environments using planar landmarks. In Proceedings of the 2000 IEEE/RSJ International Conference on Intelligent Robots and Systems, Takamatsu, Japan, 31 October–5 November 2000; Volume 1, pp. 275–280. [Google Scholar]
- Tian, Y.; Yang, X.; Yi, C.; Arditi, A. Toward a computer vision-based wayfinding aid for blind persons to access unfamiliar indoor environments. Mach. Vis. Appl. 2013, 24, 521–535. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.C.; Tsai, W.H. Vision-based autonomous vehicle guidance for indoor security patrolling by a SIFT-based vehicle-localization technique. IEEE Trans. Veh. Technol. 2010, 59, 3261–3271. [Google Scholar] [CrossRef]
- Bai, Y.; Jia, W.; Zhang, H.; Mao, Z.H.; Sun, M. Landmark-based indoor positioning for visually impaired individuals. In Proceedings of the 2014 12th International Conference on Signal Processing, Hangzhou, China, 19–23 October 2014; pp. 668–671. [Google Scholar]
- Serrão, M.; Rodrigues, J.M.; Rodrigues, J.; du Buf, J.H. Indoor localization and navigation for blind persons using visual landmarks and a GIS. Procedia Comput. Sci. 2012, 14, 65–73. [Google Scholar] [CrossRef]
- Kawaji, H.; Hatada, K.; Yamasaki, T.; Aizawa, K. Image-based indoor positioning system: Fast image matching using omnidirectional panoramic images. In Proceedings of the 1st ACM International Workshop on Multimodal Pervasive Video Analysis, Firenze, Italy, 29 October 2010; pp. 1–4. [Google Scholar]
- Zitová, B.; Flusser, J. Landmark recognition using invariant features. Pattern Recognit. Lett. 1999, 20, 541–547. [Google Scholar] [CrossRef] [Green Version]
- Pinto, A.M.G.; Moreira, A.P.; Costa, P.G. Indoor localization system based on artificial landmarks and monocular vision. TELKOMNIKA Telecommun. Comput. Electron. Control 2012, 10, 609–620. [Google Scholar] [CrossRef]
- Lin, G.; Chen, X. A Robot Indoor Position and Orientation Method based on 2D Barcode Landmark. JCP 2011, 6, 1191–1197. [Google Scholar] [CrossRef]
- Kosmopoulos, D.I.; Chandrinos, K.V. Definition and Extraction of Visual Landmarks for Indoor Robot Navigation; Springer: Berlin/Heidelberg, Germany, 2002; pp. 401–412. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning deep features for scene recognition using places database. In Advances in Neural Information Processing Systems; 2014; pp. 487–495. Available online: http://places.csail.mit.edu/places_NIPS14.pdf (accessed on 3 January 2019).
- Werner, M.; Kessel, M.; Marouane, C. Indoor positioning using smartphone camera. In Proceedings of the 2011 International Conference on Indoor Positioning and Indoor Navigation, Guimaraes, Portugal, 21–23 September 2011; pp. 1–6. [Google Scholar]
- Liang, J.Z.; Corso, N.; Turner, E.; Zakhor, A. Image based localization in indoor environments. In Proceedings of the 2013 Fourth International Conference on Computing for Geospatial Research and Application, San Jose, CA, USA, 22–24 July 2013; pp. 70–75. [Google Scholar]
- Chen, C.; Yang, B.; Song, S.; Tian, M.; Li, J.; Dai, W.; Fang, L. Calibrate Multiple Consumer RGB-D Cameras for Low-Cost and Efficient 3D Indoor Mapping. Remote Sens. 2018, 10, 328. [Google Scholar] [CrossRef]
- Zhao, P.; Hu, Q.; Wang, S.; Ai, M.; Mao, Q. Panoramic Image and Three-Axis Laser Scanner Integrated Approach for Indoor 3D Mapping. Remote Sens. 2018, 10, 1269. [Google Scholar] [CrossRef]
- Lu, G.; Kambhamettu, C. Image-based indoor localization system based on 3d sfm model. In IS&T/SPIE Electronic Imaging; International Society for Optics and Photonics, 2014; p. 90250H. Available online: https://www.researchgate.net/publication/269323831_Image-based_indoor_localization_system_ based_on_3D_SfM_model (accessed on 3 January 2019).
- Van Opdenbosch, D.; Schroth, G.; Huitl, R.; Hilsenbeck, S.; Garcea, A.; Steinbach, E. Camera-based indoor positioning using scalable streaming of compressed binary image signatures. In Proceedings of the 2014 IEEE International Conference on Image Processing (ICIP), Paris, France, 27–30 October 2014; pp. 2804–2808. [Google Scholar]
- Hile, H.; Borriello, G. Positioning and orientation in indoor environments using camera phones. IEEE Comput. Gr. Appl. 2008, 28. [Google Scholar] [CrossRef]
- Mulloni, A.; Wagner, D.; Barakonyi, I.; Schmalstieg, D. Indoor positioning and navigation with camera phones. IEEE Pervasive Comput. 2009, 8, 22–31. [Google Scholar] [CrossRef]
- Lu, G.; Yan, Y.; Sebe, N.; Kambhamettu, C. Indoor localization via multi-view images and videos. Comput. Vis. Image Understand. 2017, 161, 145–160. [Google Scholar] [CrossRef]
- Lu, G.; Yan, Y.; Ren, L.; Saponaro, P.; Sebe, N.; Kambhamettu, C. Where am i in the dark: Exploring active transfer learning on the use of indoor localization based on thermal imaging. Neurocomputing 2016, 173, 83–92. [Google Scholar] [CrossRef]
- Piciarelli, C. Visual indoor localization in known environments. IEEE Signal Process. Lett. 2016, 23, 1330–1334. [Google Scholar] [CrossRef]
- Vedadi, F.; Valaee, S. Automatic Visual Fingerprinting for Indoor Image-Based Localization Applications. IEEE Trans. Syst. Man Cybern. Syst. 2017. [Google Scholar] [CrossRef]
- Lee, N.; Kim, C.; Choi, W.; Pyeon, M.; Kim, Y. Development of indoor localization system using a mobile data acquisition platform and BoW image matching. KSCE J. Civ. Eng. 2017, 21, 418–430. [Google Scholar] [CrossRef]
- Chen, Z.; Zou, H.; Jiang, H.; Zhu, Q.; Soh, Y.C.; Xie, L. Fusion of WiFi, smartphone sensors and landmarks using the Kalman filter for indoor localization. Sensors 2015, 15, 715–732. [Google Scholar] [CrossRef]
- Deng, Z.A.; Wang, G.; Qin, D.; Na, Z.; Cui, Y.; Chen, J. Continuous indoor positioning fusing WiFi, smartphone sensors and landmarks. Sensors 2016, 16, 1427. [Google Scholar] [CrossRef]
- Gu, F.; Khoshelham, K.; Shang, J.; Yu, F. Sensory landmarks for indoor localization. In Proceedings of the 2016 Fourth International Conference on Ubiquitous Positioning, Indoor Navigation and Location Based Services (UPINLBS), Shanghai, China, 2–4 November 2016; pp. 201–206. [Google Scholar]
- Millonig, A.; Schechtner, K. Developing landmark-based pedestrian-navigation systems. IEEE Trans. Intell. Transp. Syst. 2007, 8, 43–49. [Google Scholar] [CrossRef]
- Betke, M.; Gurvits, L. Mobile robot localization using landmarks. IEEE Trans. Robot. Autom. 1997, 13, 251–263. [Google Scholar] [CrossRef] [Green Version]
- Boada, B.L.; Blanco, D.; Moreno, L. Symbolic place recognition in voronoi-based maps by using hidden markov models. J. Intell. Robot. Syst. 2004, 39, 173–197. [Google Scholar] [CrossRef]
- Zhou, B.; Li, Q.; Mao, Q.; Tu, W.; Zhang, X. Activity sequence-based indoor pedestrian localization using smartphones. IEEE Trans. Hum.-Mach. Syst. 2015, 45, 562–574. [Google Scholar] [CrossRef]
- Kosecká, J.; Li, F. Vision based topological Markov localization. In Proceedings of the IEEE International Conference on Robotics and Automation, New Orleans, LA, USA, 26 April–1 May 2004; Volume 2, pp. 1481–1486. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems; 2015; pp. 91–99. Available online: https://arxiv.org/abs/1506.01497 (accessed on 3 January 2019).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; 2012; pp. 1097–1105. Available online: https://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf (accessed on 3 January 2019).
- Uijlings, J.R.; Van De Sande, K.E.; Gevers, T.; Smeulders, A.W. Selective search for object recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Thede, S.M.; Harper, M.P. A second-order hidden Markov model for part-of-speech tagging. In Proceedings of the the 37th Annual Meeting of the Association for Computational Linguistics on Computational Linguistics, College Park, MD, USA, 20–26 June 1999; pp. 175–182. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Oliva, A.; Torralba, A. Modeling the shape of the scene: A holistic representation of the spatial envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type | CN | DTT | DR | DP | ELV | FE | MTT | ST | WLL | WMTT |
|---|---|---|---|---|---|---|---|---|---|---|
| Training | 56 | 60 | 155 | 63 | 60 | 250 | 58 | 113 | 104 | 55 |
| Testing | 29 | 25 | 33 | 22 | 23 | 36 | 24 | 37 | 31 | 20 |
| Methods | CN | DTT | DR | DP | ELV | FE | MTT | ST | WLL | WMTT | Overall |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | 17.2% | 64.0% | 90.9% | 68.2% | 0.0% | 100% | 0.0% | 56.8% | 3.2% | 0.0% | 44.3% |
| ANN | 82.8% | 80.0% | 97.0% | 86.4% | 73.9% | 97.2% | 87.5% | 70.3% | 61.3% | 80.0% | 81.8% |
| Ours | 100% | 96.0% | 100% | 95.5% | 95.7% | 100% | 100% | 100% | 100% | 95.0% | 98.6% |
| Methods | CN | DTT | DR | DP | ELV | FE | MTT | ST | WLL | WMTT | AVERAGE |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM | 0.29 | 0.78 | 0.50 | 0.77 | Nan | 0.44 | Nan | 0.67 | 0.06 | Nan | Nan |
| ANN | 0.89 | 0.87 | 0.84 | 0.90 | 0.76 | 0.77 | 0.88 | 0.78 | 0.70 | 0.86 | 0.82 |
| Ours | 1 | 0.96 | 1 | 0.98 | 0.98 | 1 | 1 | 1 | 0.98 | 0.93 | 0.98 |
| Route | Landmarks Counts | ANN | Ours | ||||
|---|---|---|---|---|---|---|---|
| DL | CDL | WDL | DL | CDL | WDL | ||
| 1 | 28 | 30 | 25 | 5 | 28 | 28 | 0 |
| 2 | 16 | 16 | 16 | 0 | 16 | 16 | 0 |
| 3 | 15 | 20 | 15 | 5 | 15 | 15 | 0 |
| 4 | 10 | 10 | 10 | 0 | 10 | 10 | 0 |
| 5 | 14 | 18 | 14 | 4 | 14 | 14 | 0 |
| 6 | 18 | 26 | 18 | 6 | 18 | 18 | 0 |
| 7 | 22 | 29 | 22 | 7 | 22 | 22 | 0 |
| Route | HMM | HMM2 | ||
|---|---|---|---|---|
| Without | With | Without | With | |
| 1 | 18 | 9 | 1 | 1 |
| 2 | 8 | 2 | 1 | 1 |
| 3 | 1137 | 82 | 2 | 1 |
| 4 | 2 | 2 | 1 | 1 |
| 5 | 12 | 1 | 1 | 1 |
| 6 | 18,346 | 5556 | 2 | 1 |
| 7 | 4 | 2 | 1 | 1 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, J.; Li, Q.; Cao, R.; Sun, K.; Liu, T.; Garibaldi, J.M.; Li, Q.; Liu, B.; Qiu, G. Indoor Topological Localization Using a Visual Landmark Sequence. Remote Sens. 2019, 11, 73. https://doi.org/10.3390/rs11010073
Zhu J, Li Q, Cao R, Sun K, Liu T, Garibaldi JM, Li Q, Liu B, Qiu G. Indoor Topological Localization Using a Visual Landmark Sequence. Remote Sensing. 2019; 11(1):73. https://doi.org/10.3390/rs11010073
Chicago/Turabian StyleZhu, Jiasong, Qing Li, Rui Cao, Ke Sun, Tao Liu, Jonathan M. Garibaldi, Qingquan Li, Bozhi Liu, and Guoping Qiu. 2019. "Indoor Topological Localization Using a Visual Landmark Sequence" Remote Sensing 11, no. 1: 73. https://doi.org/10.3390/rs11010073
APA StyleZhu, J., Li, Q., Cao, R., Sun, K., Liu, T., Garibaldi, J. M., Li, Q., Liu, B., & Qiu, G. (2019). Indoor Topological Localization Using a Visual Landmark Sequence. Remote Sensing, 11(1), 73. https://doi.org/10.3390/rs11010073