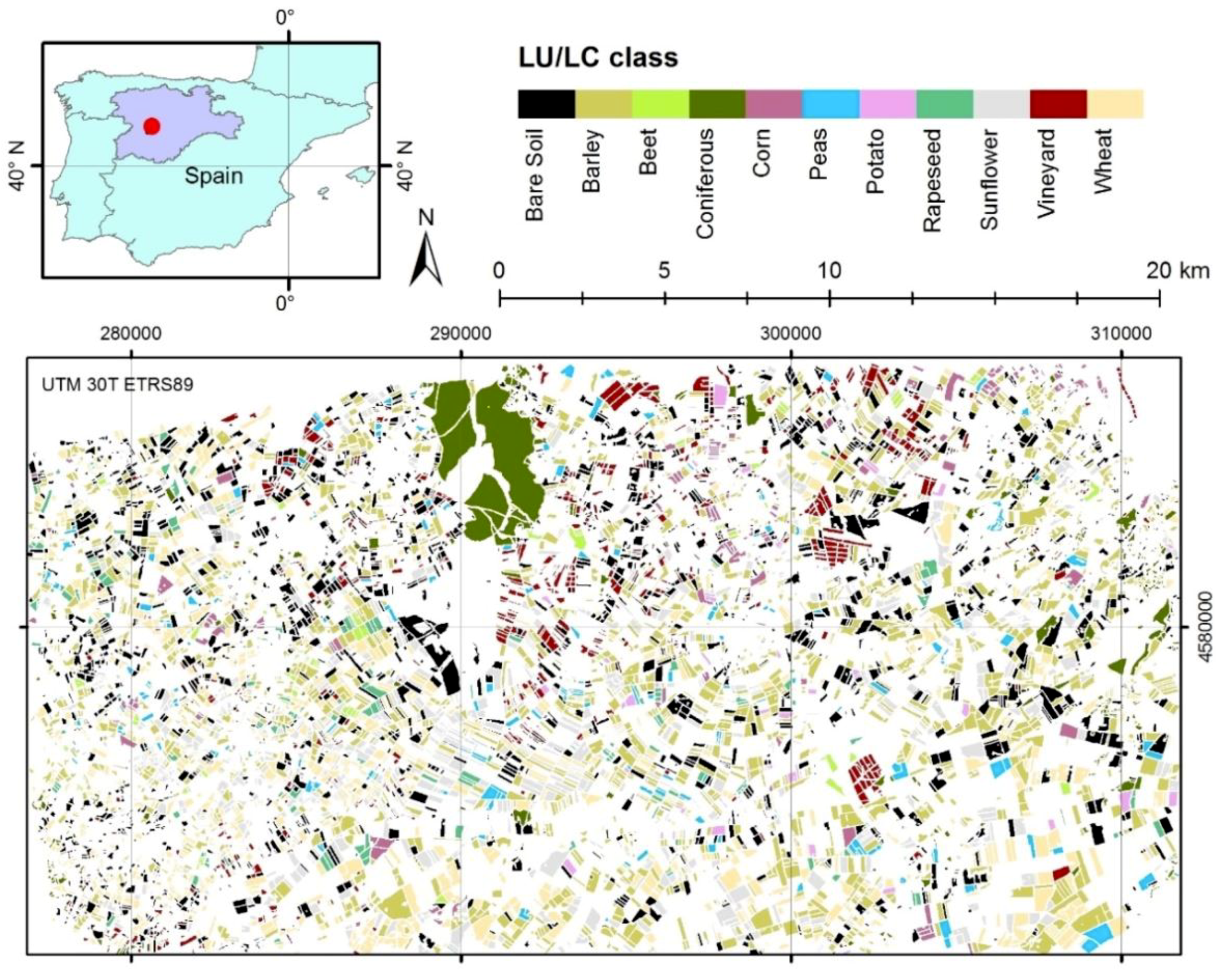
3.1. Land-Cover Classification and Accuracy Assessment
A new land-cover map resulted from each scenario of classification.
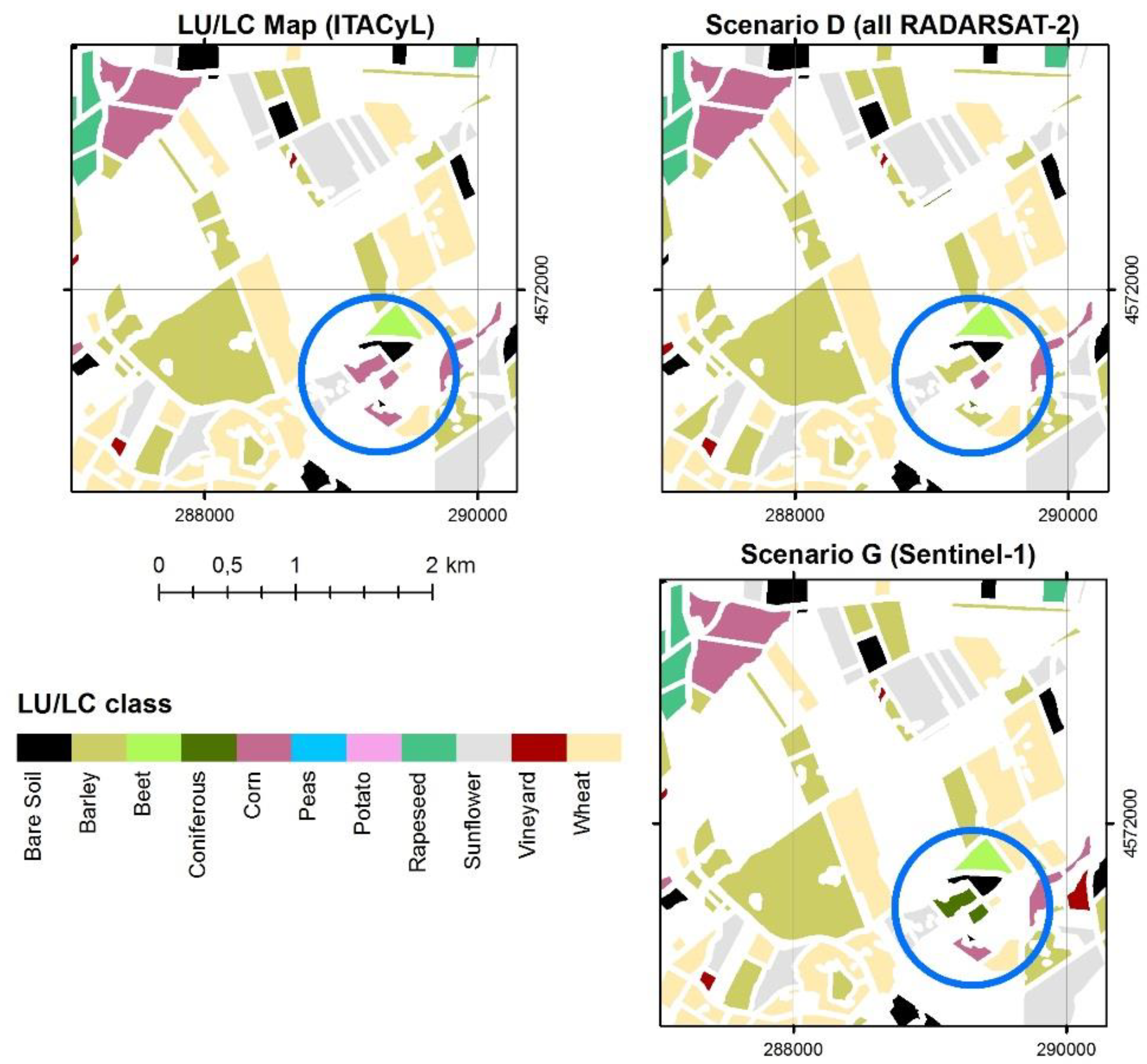
Figure 2 shows a detailed area of such maps from scenarios A and D as a given example. As it can be observed, the differences between them and with the reference map are minimal. Then, for each map, a classification accuracy assessment was carried out. The resulting overall classification accuracy and
kappa coefficient are provided in
Table 6. The overall accuracy for all scenarios ranged from 83% to 89.1%, with
kappa coefficients ranging from 0.79 to 0.88. The highest accuracy was achieved using all polarimetric observables and all scenes of RADARSAT-2 (scenario D). When Sentinel-1 dual-pol SAR data were used as input for the classification, the second-best accuracy (87.1%) was obtained, whereas using dual-pol RADARSAT-2 data (scenario F) provided a similar overall accuracy (86%). The accuracy of the dual-pol RADARSAT-2 data in the general computation of this study showed higher accuracy than previous studies in the literature [
35,
39]. From RADARSAT-2 scenarios, the accuracies of 89.1% and 86.6% for scenarios D and A, respectively, were quite similar; however, D required many more SAR images and parameters than A to achieve this small 2.5% improvement of accuracy. Taking that observation and considering the efficiency and costs of the SAR data, scenario A would be concluded to be more suitable for classification than scenario D.
Since the launch in April 2014 of Sentinel-1 by ESA, researchers have claimed the feasibility of dual-pol Sentinel-1 data as standalone input [
53,
54] or blended with optical data [
55,
56,
57] for LU/LC classification. Bargiel [
23] demonstrated a new crop classification approach that identified phenological sequence patterns of the crop types from a stack of Sentinel-1 data. He suggested the use of multitemporal SAR observables as a crucial factor for the improvement of crop classification.
The influence of the incidence angle for crop classification has also been explored. When the polarimetric observables derived from images at 36°, 31° and 25° were used by the classifier, the overall accuracies ranged from 83% to 86.6% and 0.79 to 0.84 for
kappa coefficients (
Table 6). The variation of the incidence angle seems not to influence the classification significantly in terms of overall accuracy, as it was observed that the highest accuracy of 86.6% (scenario A) was only slightly better (~3.5%) than the lowest accuracy (scenario C). In principle, shallower incidence angles are preferred for identification of crops [
58] due to the importance of these angles to minimize backscatter contributions from the soil. However, there is no conclusive evidence in the literature about which angle or narrow range of angles are the most adequate for classification purposes. Therefore, the influence of incidence angle seems to be very low, opening the way to combine all available incidence angles (as in scenario D).
Regarding the training/validating sampling, as it was previously mentioned, a 60-40% criterion was used, that is, a random sampling containing 60% of the samples from the data were selected as training dataset and the remaining 40% as validating dataset. To test the dependence of the accuracy on the training/validating sample, a new classification of all scenarios was run using a new random sampling (preserving the 60-40% criterion).
Table 7 shows the new results, where it is clear that the overall accuracy is quite similar to the results shown in
Table 6. The highest differences in overall accuracy are shown for scenarios A (1.2%), B (0.9%) and C (0.8%), whereas for scenario D there was not any difference. Likewise, the differences for the
kappa coefficient were negligible. Therefore, it can be concluded that, owing to the high number of samples, the accuracy does not vary depending on the sampling selection.
An important indicator of a successful classification is a high overall accuracy; however, getting an acceptable discrimination at the individual crop level is as important as a high overall accuracy, especially for some final applications. With this aim, the producer’s and user’s accuracies for individual covers are listed in
Table 8.
Results showed that rapeseed achieved the best PA results (>95%) in all scenarios, whereas barley achieved the second highest PA’s, ranging from 92.1% to 95.3%. The user’s accuracy (UA) of both crops was above 85% for all scenarios tested and achieved 100% for rapeseed in scenarios A and D. The results reported in this study for rapeseed agree with those found by Larrañaga and Álvarez-Mozos [
35]. Cereals (i.e., wheat and barley) normally show a similar behaviour during the growing season due to their very similar plant structure and phenology, which causes difficulty in separating them based on their backscatter characteristics. However, the results showed that polarimetric SAR data at C-band were capable of classifying wheat and barley with high PAs ranging from 79.9% to 95.3%. Among these crops, barley achieved better results than wheat, with high PAs (95.1%, 95.1% and 95.3%) for scenarios A, E and D, respectively. In agreement with the result obtained in scenario D for barley, Larrañaga and Álvarez-Mozos [
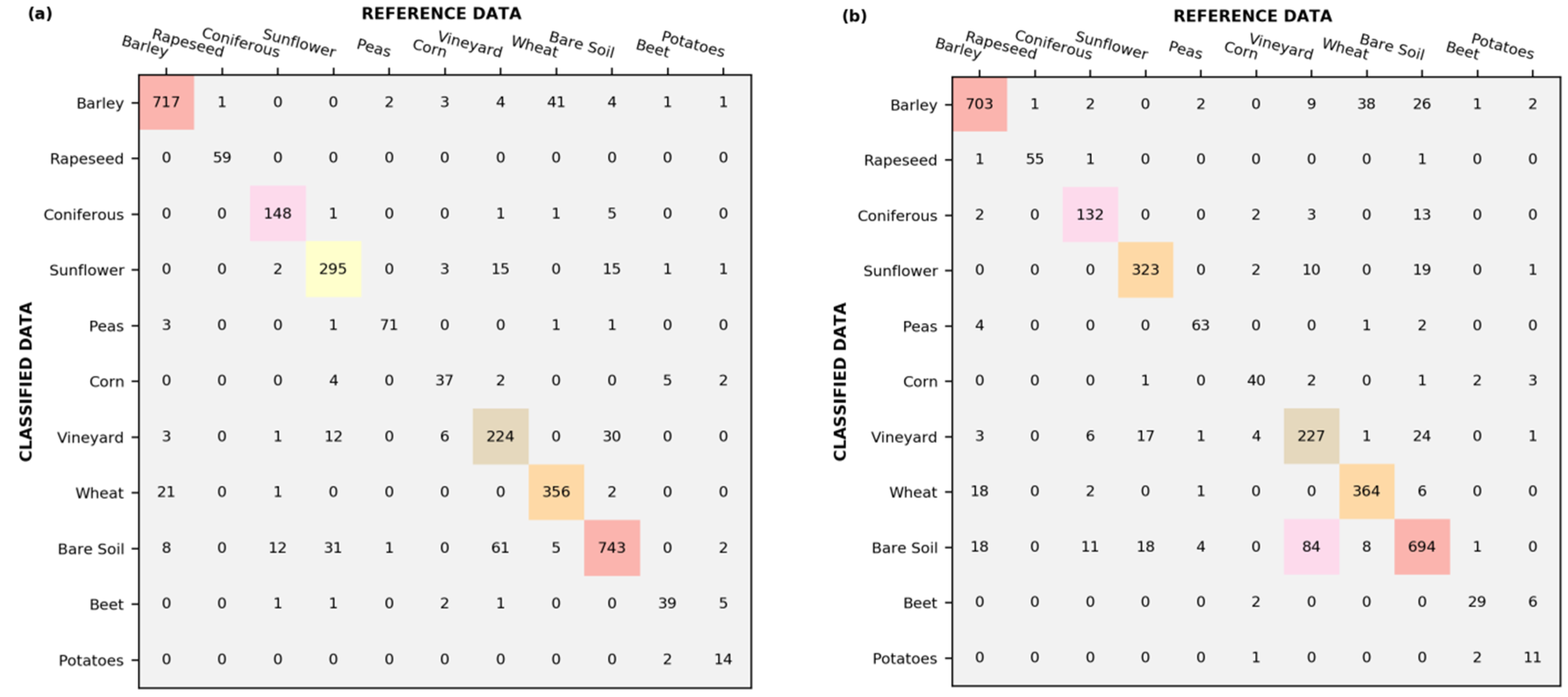
35] also reported a high PA for barley when different polarimetric observables were added to the H-V linear quad-pol data. The highest accuracy for wheat (88.3% and 88.1%) took place when Sentinel-1 dual-pol data (scenario G) or all polarimetric observables and images were used for classification (scenario D). In the specific confusion matrices for scenarios D (
Figure 3a) and G (
Figure 3b), most of the wheat plots were classified properly (356 out of 404 for scenario D and 364 out of 412 for scenario G). Only a small misclassification between wheat and barley was produced, which is explained by their similar plant structure. As shown in
Table 8, RADARSAT-2 dual-pol scenario (F) showed good results (92.1% and 81.2%) for barley and wheat, respectively. The results reported from the dual-pol scenarios suggest that VH/VV dual polarization mode is a good choice for discriminating cereals from other crops and agrees with findings by McNairn et al. [
8] and Veloso et al. [
59]. Although barley and wheat were found to be well classified, the PA and UA of the third cereal considered, corn, are not as good as expected with regard to previous results found in the literature [
39]. The best PA was shown in scenario G with Sentinel-1 dual-pol data (78.4%) and scenario E (78.2%). Corn in scenario C also provided the second poorest PA in this study, with just 54% of the corn plots classified correctly.
The lowest accuracies were found for potatoes in 4 out of 7 scenarios, which were followed by corn. The scenario G is the worst of all scenarios, with a PA of 45.8%; this means that the classification at this scenario missed 54.2% of the potato areas on the ground, indicating a tendency for the model to misclassify potatoes. Due to their broad leaves, potatoes are mostly misclassified as beets (
Figure 3b), which also have a similar plant structure. From all scenarios analysed for beet, scenario A (RADARSAT-2 at 36°) provided the highest PA (93.2%) followed by scenario E (83.7%). Scenario G (Sentinel-1 data using the backscattering coefficients and the ratio) also provided a high accuracy (82.9%) for beets. The accuracy reported in this study with Sentinel-1 data is higher than the accuracy provided by Sonobe et al. [
56]. They achieved a PA of 74.6% using KELM (Kernel-based Extreme Learning Algorithm) and VV polarization data.
The PA of bare soil reached the highest accuracy (92.9%) in scenario D and accuracies above 84% for the rest of the scenarios. These good results for bare soil could be related to the use of cross-polarization as one of the inputs for the classifier. The use of cross-polarization makes the distinction between bare soil and vegetation-covered surfaces easier because the vegetation canopies depolarize the incident radiation more strongly than bare surfaces. Although bare soil provided a high PA in scenario D, 120 plots of bare soil were misclassified (
Figure 3a); this shows, together with the vineyard, the highest confusion (61 plots, approximately 7% of the total of this category).
The potential of SAR images for classifying vineyards has also been investigated. Measurements on vineyards are not easy, given the high number of poles and metallic wires supporting the runners and the space between runners. As expected, no high accuracies were achieved for vineyards. Scenario A (RADARSAT-2 data at 36°) showed the highest PA (73.5%) and scenario C the lowest (61.3%). Scenario C was run using RADARSAT-2 data at 25°, so this poor accuracy could be related to the fact that at C-band, steep angles are more sensitive to ground conditions and less sensitive to the plant features; in contrast, shallower angles increase the interaction with the vegetation, therefore reducing the contribution of the soil and increasing the possibility of getting better accuracy, as it is shown for scenario A. Even though the poorer results are obtained for vineyard relative to other land covers, its accuracy could be considered acceptable.
The misclassification among forested areas, agricultural crops and grassland is expected in land-cover applications. However, L-band SAR data are known to provide an excellent source of information for forest cover mapping and it decreases the misclassification between covers due to its significant penetration capability relative to vegetation canopies. Our results showed high PAs and UAs, ranging from 83.1% to 91.5% and 82.5% to 94.9%, respectively. Scenario F (RADARSAT-2 dual-pol data) was found to provide the best PA that was slightly higher (0.5%) than scenario E (91%). Therefore, we could conclude that C-band SAR data were able to provide reliable classification of coniferous.
Sunflower and peas were also analysed. Sunflower obtained PAs above 81% in all scenarios with the exception of scenario C, which provided a PA of 74.2%. SAR data dual-pol scenarios (G and F) showed the highest accuracies (90% and 89.1%). The results found for sunflower using dual-pol data improved the results found by Skakun et al. [
39]. However, Larrañaga and Álvarez-Mozos [
35] obtained a PA of 100% for sunflower when they applied VV-VH dual-pol configuration of RADARSAT-2 data with just two backscattering coefficients in the two polarization channels. The difference in accuracy (~11%) between their results and our findings could be related to the fact that we added the ratio (VH/VV) as input into the classifier and because the number of sunflower plots and images is higher. Skakun et al. [
39] used RADARSAT-2 backscattering intensity (VV, VH and HH) in beam mode (FQ8W) with incidence angle ranging from 26.1° to 29.4° to run a multitemporal crop classification in Ukraine. They found PA and UA of 60% and 63.5% for sunflower. Although the poorest accuracy (74.2%) found for sunflower was when RADARSAT-2 data at 25° were used in the classifier, our study demonstrated that the use of different polarimetric observables (beyond backscattering coefficients) improved the classification of sunflower when SAR data with low incidence angle are used in the classifier.
Finally, for peas, the highest PA was found in scenario D (95.9%), when all polarimetric observables and images were employed by the classifier. However, there is a high difference (19.2%) between the highest and the lowest accuracy (76.7%) provided by scenario C. In terms of UA, after rapeseed and coniferous, peas showed the highest accuracies (scenario A, 93.7%; scenario F, 95.9%). The results found for peas in this study improved those found by Larrañaga and Álvarez-Mozos [
35].
Figure 3a shows that only three plots of peas were confused with barley and bare soil in this study.
In addition to the accuracy of the different combinations of SAR observables, the individual LU/LC analyses provided an interesting insight into the feasibility of the multitemporal series. After the results mentioned above, the best classification took place for rapeseed, barley, wheat and peas, all of which are spring crops, having their growing cycle between March and June, when the availability of images is higher (
Table 3). Conversely, the worst results were found for summer crops, with growing cycles spanning until the beginning of fall (corn, potatoes and vineyard), which is not covered by the SAR series. Although with reasonably good results, sunflowers, beets and potatoes are also summer crops and could not achieve the optimal results found for the spring crops. Thus, it can be reasoned that, as suspected, the multitemporal-based classification clearly enhances the results of the polarimetric-based classification.
3.2. Attribute Evaluation
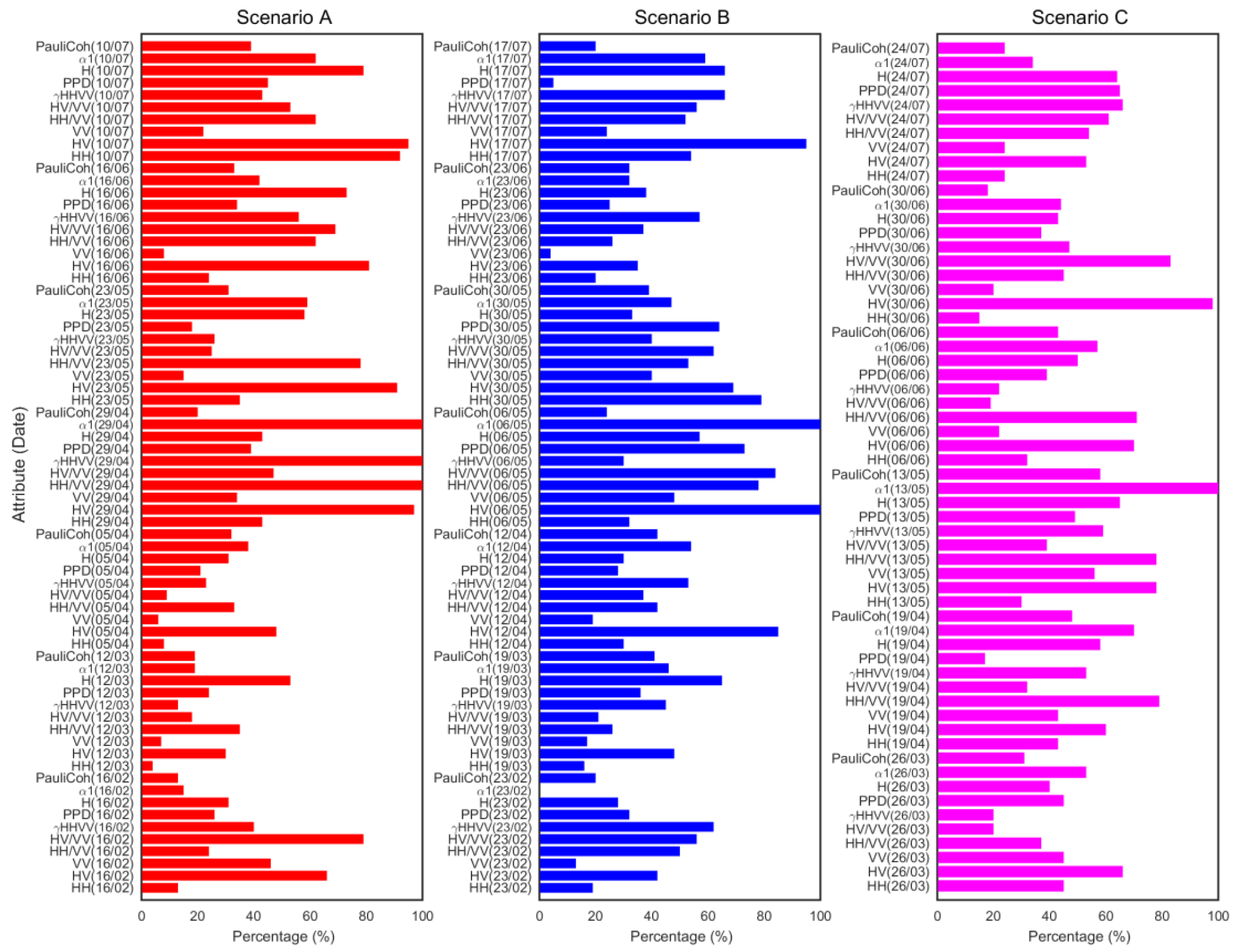
C5.0 shows the degree to which each attribute (SAR observable per date) contributes to the classifier and provides the percentage of training cases in the data file for which the value of that attribute is known and used for the construction of the classifier. Due to the large number of attributes used for each scenario, the attribute evaluation provided by C5.0 is very useful to know how individual attributes contribute to the construction of the classifier.
Figure 4 shows the attribute usage across the first three scenarios (A, B and C) that were run with 70, 60 and 60 attributes, respectively. In terms of polarimetric observables, the importance of the dominant alpha angle (α
1) can be clearly seen, followed by the cross-polar backscattering coefficient (HV) and the backscattering ratios (HH/VV and HV/VV). The large usage of these polarimetric observables at specific acquisition dates implied that the information they supplied was useful for crop separation. Additionally, the contribution of the correlation between the co-polar channels (γ
HHVV) is important in scenario A. The least important polarimetric observables used in these scenarios were VV, γ
P1P2 and polarized difference phase (PPD).
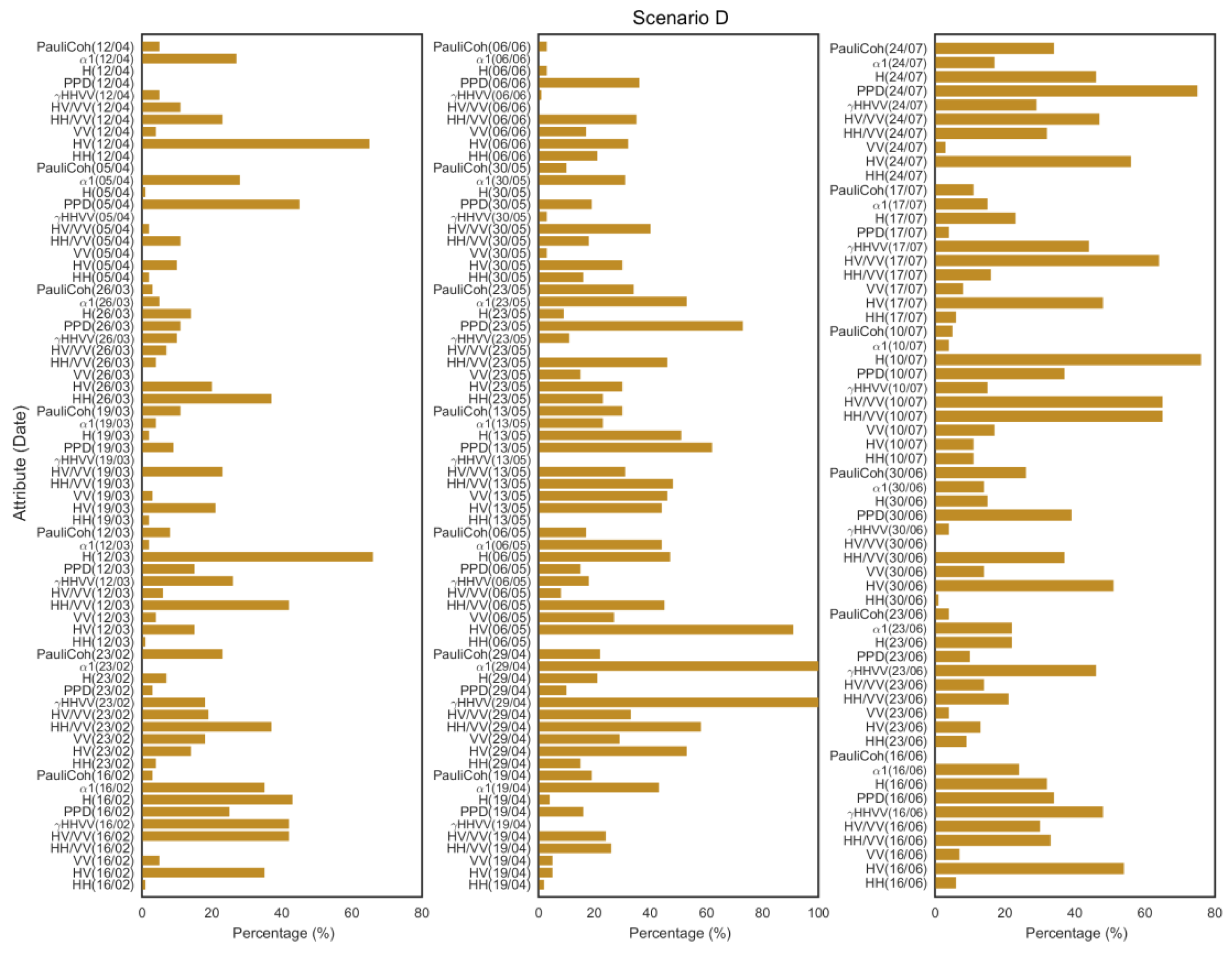
Scenario D (
Figure 5) was the more complex scenario tested in this study with 200 attributes used. Like scenarios A, B and C, the dominant alpha angle (α
1), γ
HHVV and the cross-polar backscattering coefficient (HV) are the most important observables. Many polarimetric observables at certain dates show null percentage, mainly because C5.0 does not show the attributes with values smaller than 1%.
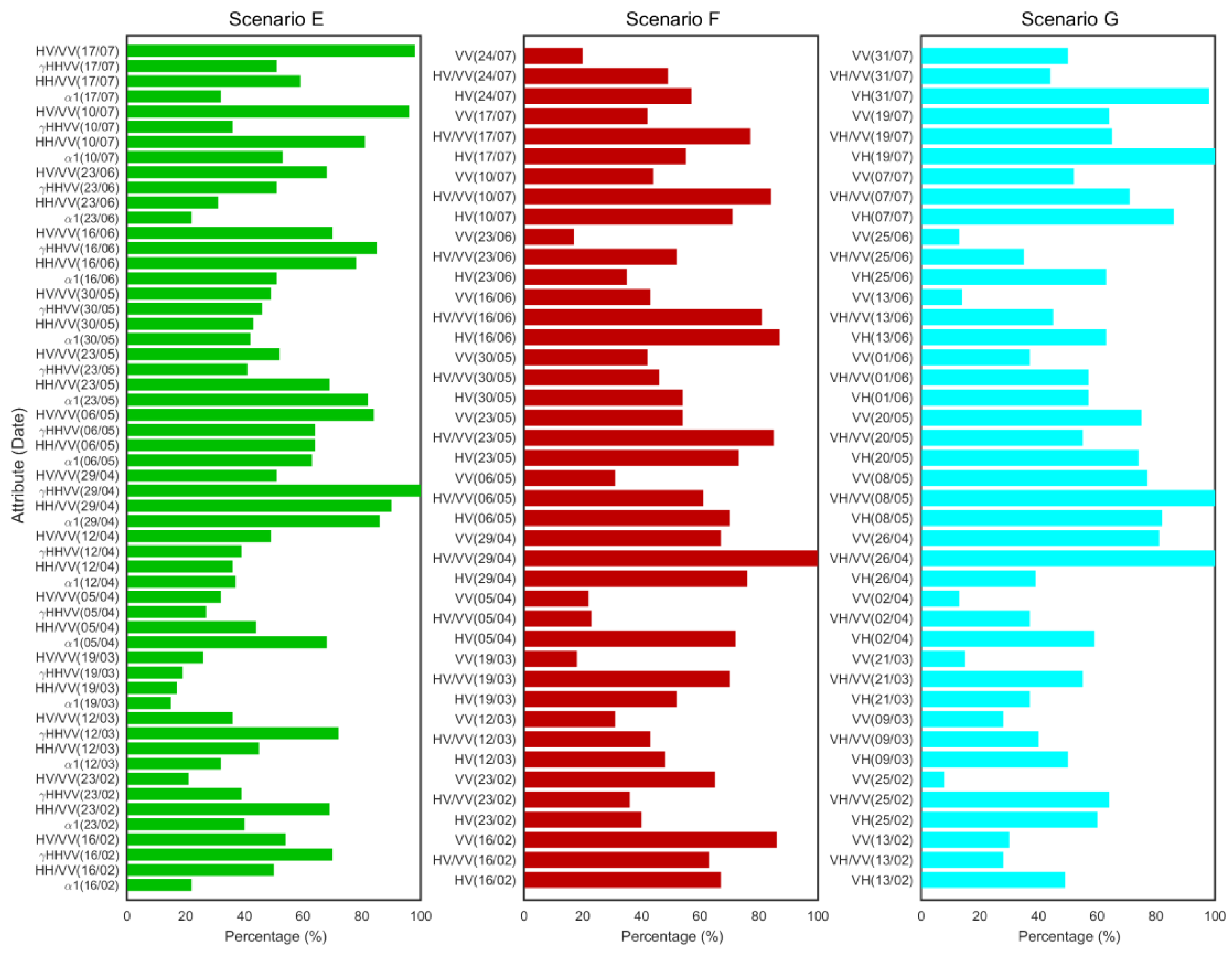
The attributes of the last three scenarios (E, F and G) are shown in
Figure 6. These scenarios used 56 (E), 42 (F) and 42 (G) attributes. Scenario E showed a clear influence of γ
HHVV on April 29, with 100% of the cases used in the classifier. In scenarios F and G (with just three polarimetric observables used), the cross-polar ratios (HV/VV and VH/VV) provided a high weight to the classifier.
In terms of the acquisition dates, the RADARSAT-2 scenes with highest importance, along with the polarimetric observables, were April 29, May 06 and May 13. For Sentinel-1, the images were from April 26 and May 08. Skriver [
60] reported a study to determine the optimum parameters for classification using airborne C- and L-band polarimetric SAR data. He found that at C-band, early acquisition, that is, in April, has a high discrimination potential but May acquisition provides the largest discrimination potential. He also reported that for May, the correlation coefficient between HH and VV as well as the ratio between HV and VV (among others) showed clear potential for separation. The results of this study agree with these findings. The fact that April and May had major relevance in the multi-temporal series is not surprising, since as previously mentioned, during this interval the most important vegetative growing stages of the crops in the area coincide, that is, maximum growth for the spring crops and development stage for the summer crops.
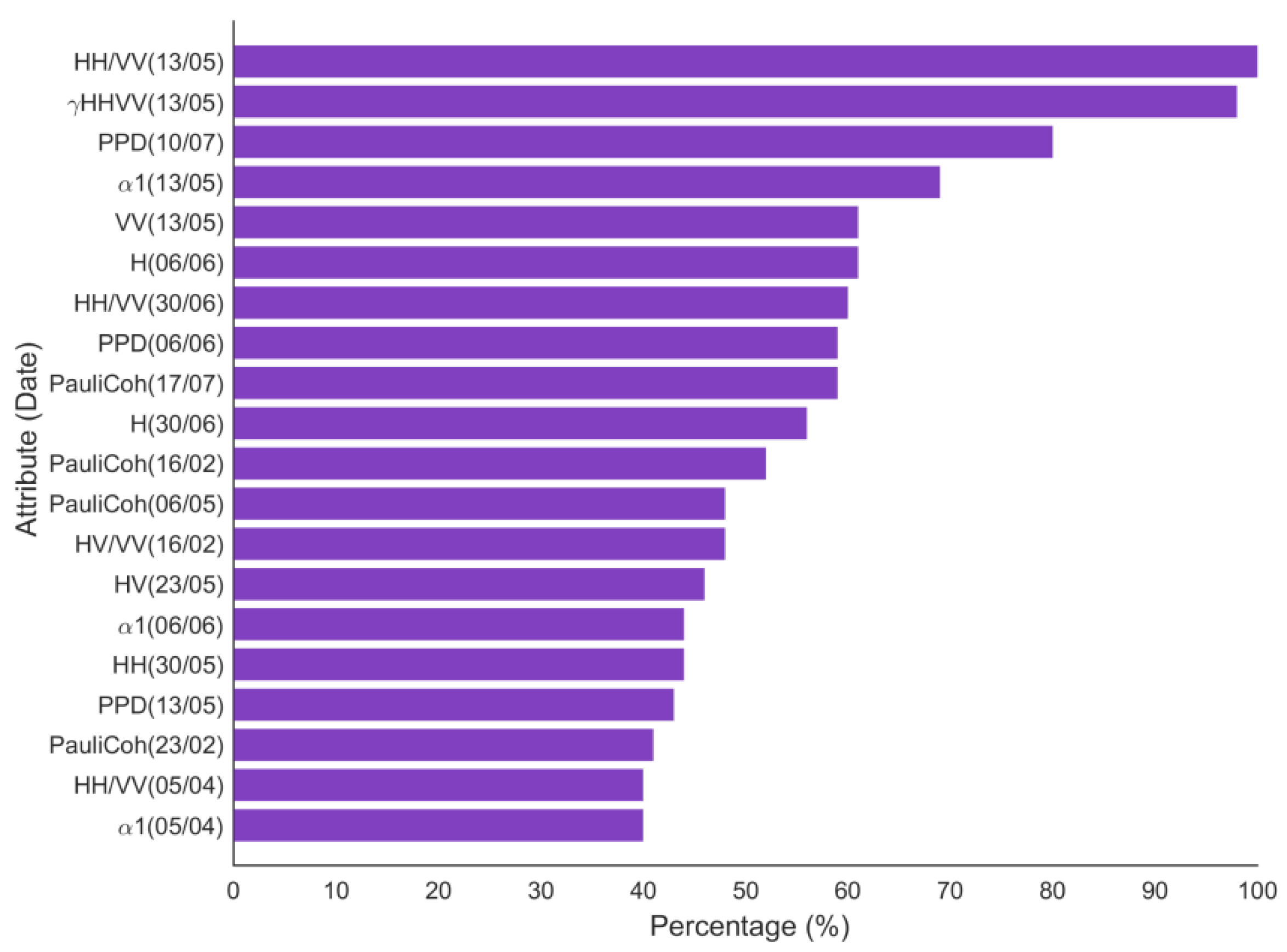
As a final test of the evaluation of attribute importance, a focussed pairwise crop analysis was conducted to estimate which observable contributed more to distinguishing wheat and barley, which were similar in structure and therefore expected to have a similar signal response. This test was performed for scenario D as a given example, which gathers all the possible attributes. The resulting pairwise analysis between these two crops (
Figure 7) showed HH/VV as the highest contributor (100%) to separate both crops, followed by γ
HHVV.
Regarding the acquisition dates, the pairwise analysis with RADARSAT-2 emphasized the higher importance of May 13 as a key date reflecting the cereal growing cycle.
Feasible Applications Using the Importance of Attributes
The aim of the former analysis was to evaluate the weight of each observable in the classification to avoid redundant or useless data without losing accuracy. Choosing scenario D as an example, the feasibility of a reduced dataset for classification was tested. First, a new scenario (H) was created using the polarimetric observables with the three highest contributions in D: γ
HHVV, HV and α
1 (
Figure 5).
Comparing the classification results for D and H, a slight difference (0.7%) between scenario D (89.1%) and scenario H (88.4%) in terms of the overall accuracy was found. At individual crop level (
Table 9), the use of attributes with the highest contribution improved the PA and UA accuracy of some crops compared with the results from scenario D (
Table 9). For crops such as vineyard, beet and potato, the PA improvement between scenario D and H was of approximately 5% and corn showed the highest difference (8.3%). Other crops such as peas showed a slight decrease in PA from scenario H (88.2%) to scenario D (95.9%). All data considered, the accuracy of scenario H is similar to scenario D, whilst reducing dramatically the number of observables and therefore it is much more cost-effective.
The second analysis consisted of a new classification only for the pairwise crops—wheat and barley—using solely the paramount observables resulting from the importance analysis of the previous section, that is, HH/VV and γ
HHVV (Scenario I). The accuracy assessment resulting for this new scenario (
Table 10) is remarkable in comparison with the previous results of scenario D, in which all the observables were included. Both the PA and UA increased in I, meaning that the importance analysis afforded a powerful tool for separating crops with similar response, even improving the accuracy of the classification whilst reducing effectively the inputs needed (from 10 to 2, in this case).
In order to explore the pairwise crop classification with limited inputs, a third analysis (named scenario J) was carried out from RADARSAT-2 data. This scenario was run using only the two main observables from Scenario I (HH/VV and γ
HHVV) and the three dates with highest importance (April 29, May 06 and May 13). Comparing the results of scenario J (
Table 10) with the previous scenario I, it is noticeable that the accuracy has decreased but to a very small extent given the reduced dataset included on J. Indeed, if compared to the general scenarios A-G (with much more polarimetric observables and dates), the accuracy provided by scenario J is slightly higher (~0.5%) than scenarios B and F, whilst for wheat the PA is higher than for scenarios A, B, E and F. Again, the results of the importance analysis enabled a way to reduce the inputs whilst maintaining a remarkable accuracy.

 and
and 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}