Deep Feature Fusion with Integration of Residual Connection and Attention Model for Classification of VHR Remote Sensing Images



Abstract
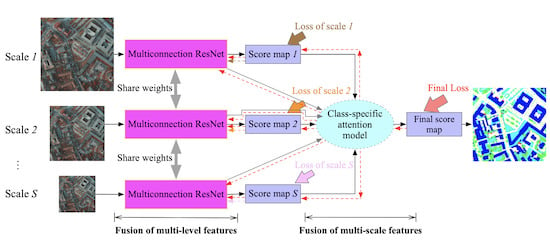
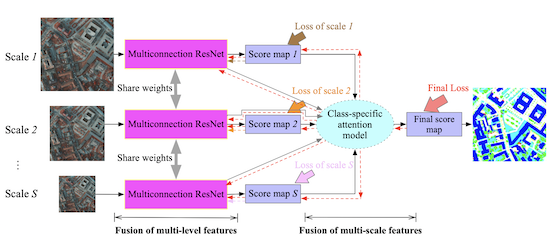
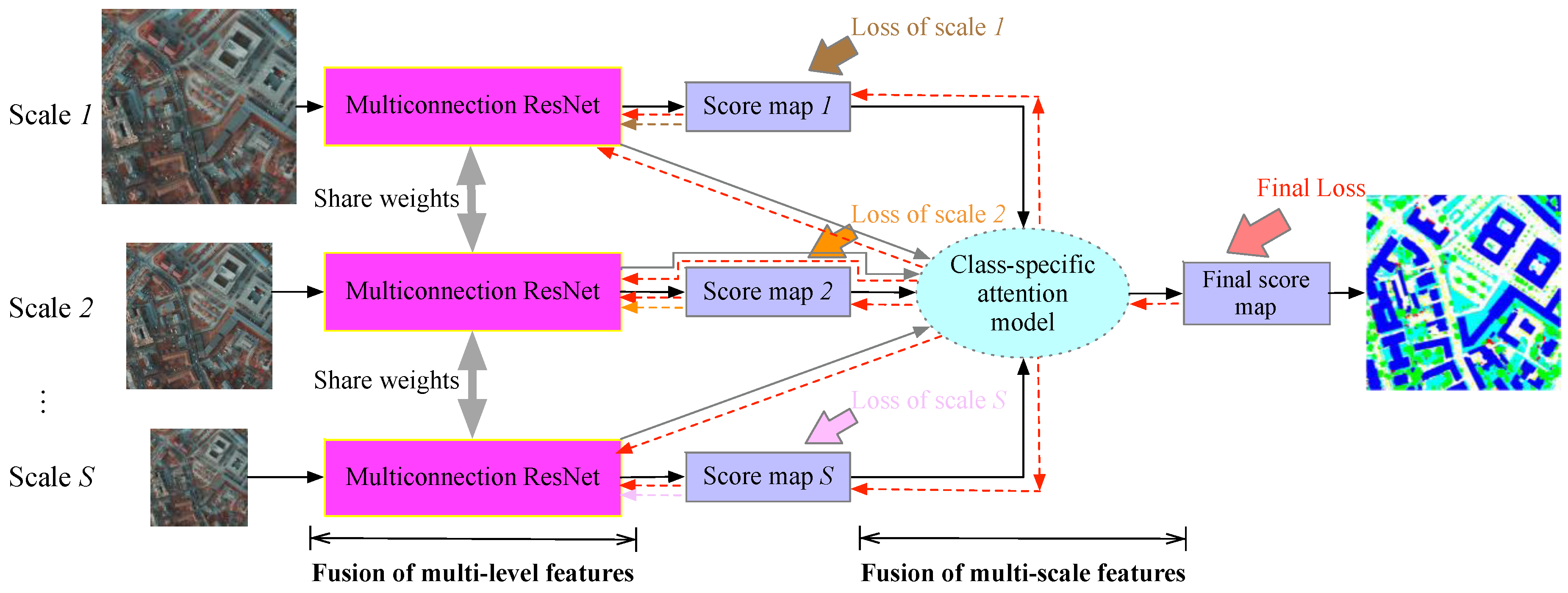
:
1. Introduction
- A multiconnection ResNet is proposed to fuse multilevel deep features corresponding to different layers of the FCN. The multiconnection residual shortcuts make it possible for low-level features to learn to cooperate with high-level features without introducing redundant information from the low-level features.
- A class-specific attention model is proposed to combine multiscale features. It can learn the contributions of various features for each geo-object at each scale. Thus, a class-specific scale-adaptive classification map can be achieved.
- A novel, end-to-end FCN is developed to integrate the multiconnection ResNet and class-specific attention model into a unified framework.
2. Related Works
2.1. From Convolutional Neural Networks to Fully Convolutional Networks
2.2. Fusion of Multilevel Deep Features
2.3. Fusion of Multiscale Deep Features
3. Deep Feature Fusion for Classification of VHR Remote Sensing Images
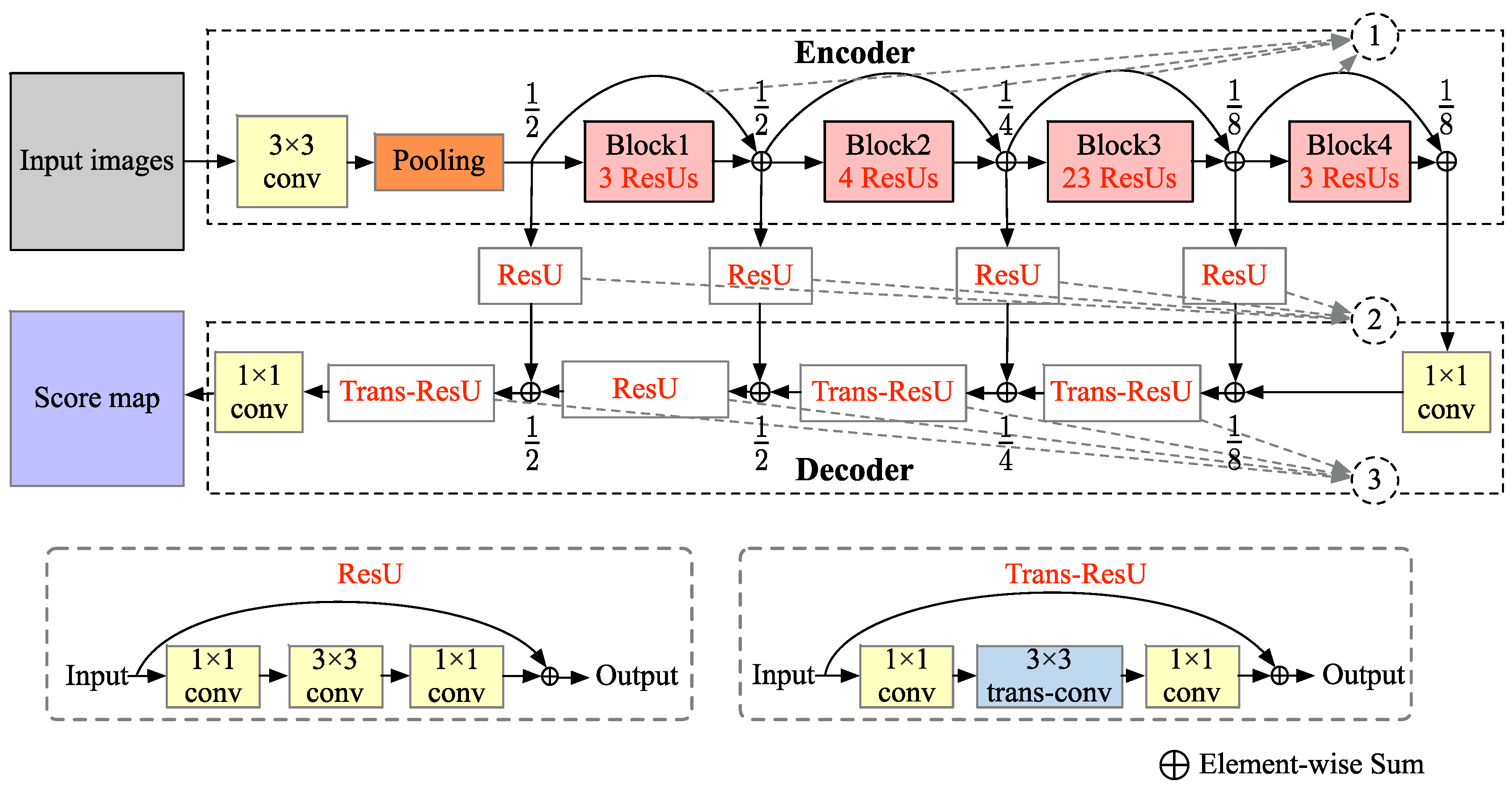
3.1. Multiconnection ResNet for Fusion of Multilevel Features
3.2. Class-Specific Attention Model for Fusion of Multiscale Features
3.3. Model Learning and Inference
4. Experiments
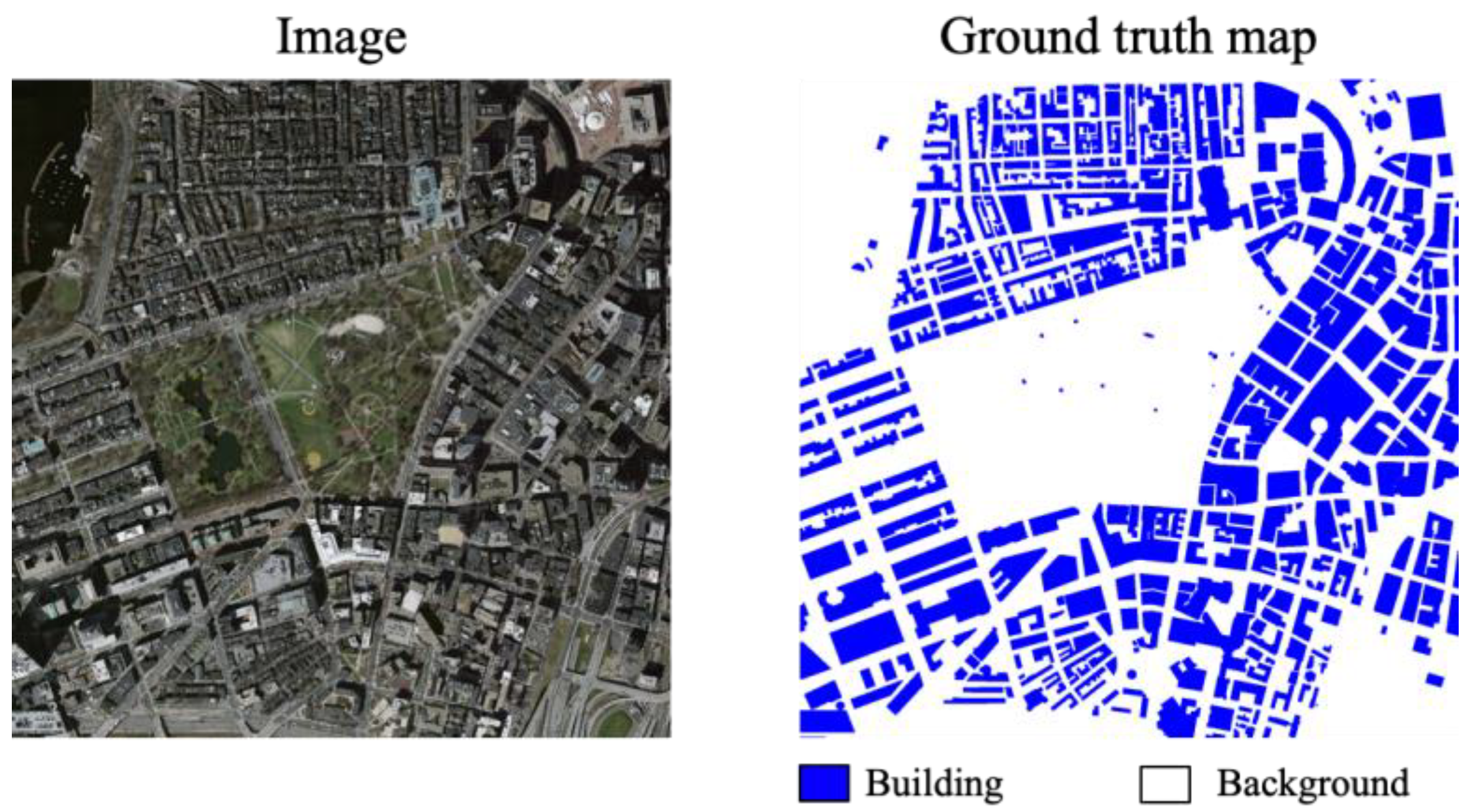
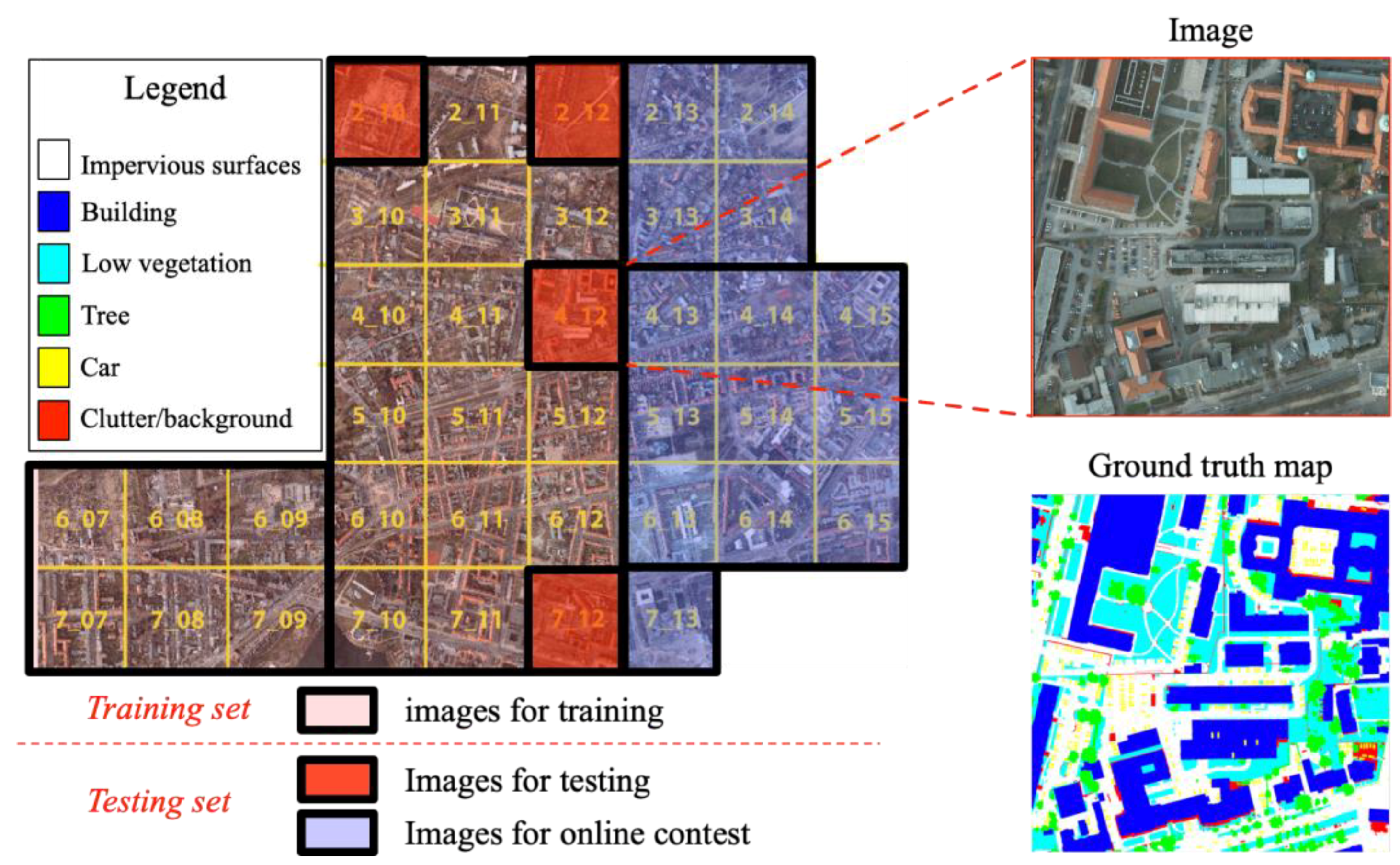
4.1. Experimental Data
4.2. Experimental Setup
4.2.1. Methods for Comparison
- Multiconnection ResNet: This is the first component of our proposed model, which introduces multiconnection residual shortcuts to make it possible for the convolutional layers to fuse multilevel deep features corresponding to different layers of the FCN. Multiconnection ResNet is referred to as mcResNet for convenience.
- Integration of multiconnection ResNet and class-specific attention model: This is the proposed end-to-end FCN, which integrates the multiconnection ResNet and class-specific attention model into a unified framework. For convenience, the proposed FCN is referred to as mcResNet-csAM.
- FCN-8s: There are three variants of FCN models: FCN-32s, FCN-16s, and FCN-8s. We chose FCN-8s for comparison, which has been shown to achieve better classification performance than its counterparts [20].
- SegNet: SegNet was originally proposed for the semantic segmentation of roads and indoor scenes [21]. The main novelty of SegNet is that the decoder performs the nonlinear up-sampling according to max pooling indices in the encoder. Thus, SegNet can provide good performance with little time and space complexity.
- Global convolutional network (GCN): GCN is proposed to address both the classification and localization issues for semantic segmentation [52]. It achieves state-of-the-art performance on two public benchmarks: PASCAL VOC 2012 and Cityscapes.
- RefineNet: RefineNet is proposed to perform semantic segmentation, which is based on ResNet [53]. It achieves state-of-the-art performance on seven public datasets, including PASCAL VOC 2012 and NYUDv2. The RefineNet based on ResNet-101 was compared with ours in the experiments.
- PSPNet: PSPNet, which introduces the pyramid pooling module to fuse hierarchical scale features, is proposed for scene parsing and semantic segmentation [43]. It ranked first in the ImageNet scene parsing challenge in 2016. We used the modified ResNet-101 as the backbone of PSPNet in the experiments following the official implementation. In the training phase, we also used the auxiliary loss with the weight of 0.4.
- DeepLab V3+: DeepLab is proposed to conduct semantic segmentation by employing multiple dilated convolutions in the cascade to capture multiscale context, being motived by the fact that atrous/dilated convolutions can easily increase the field of view [54]. When compared with DeepLab V3, the DeepLab V3+ includes a simple decoder part to refine the results [55].
4.2.2. Evaluation Criteria
4.2.3. Parameter Setting
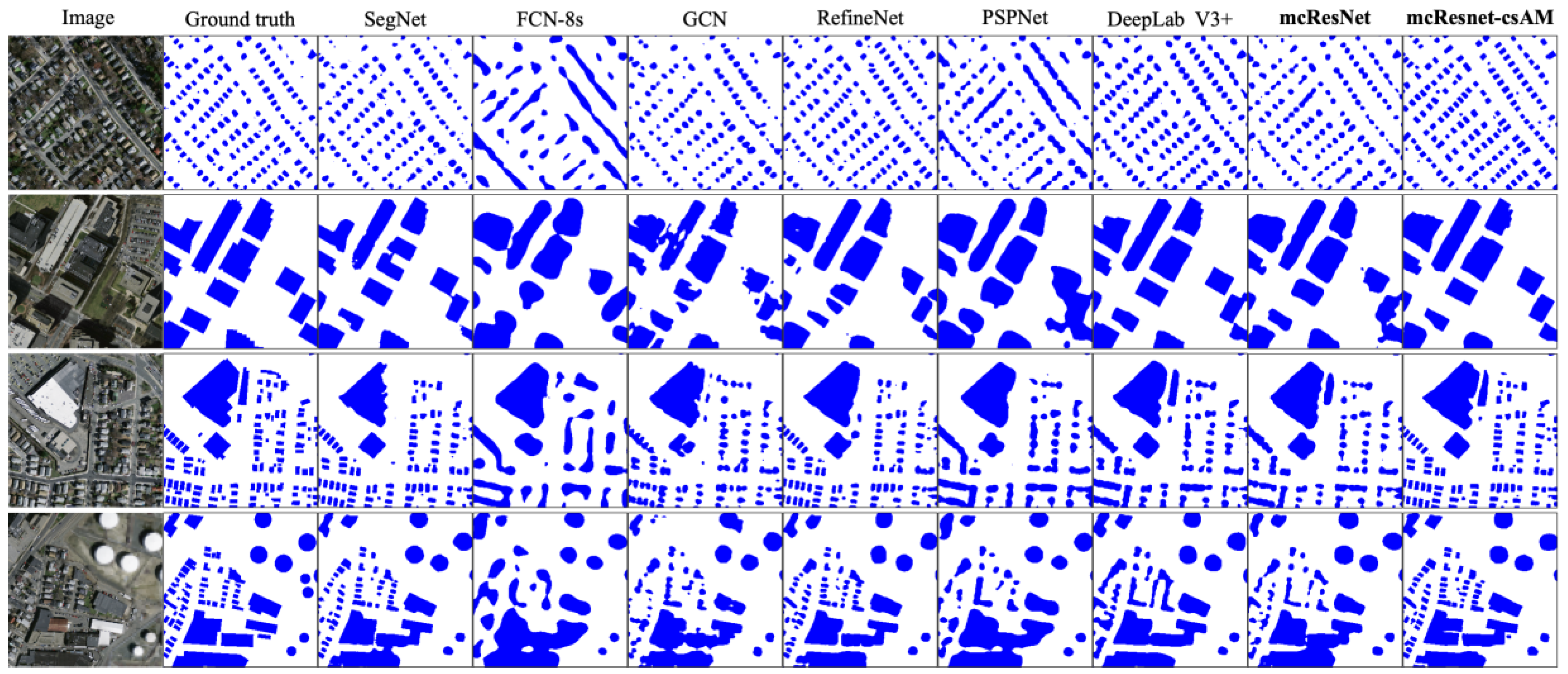
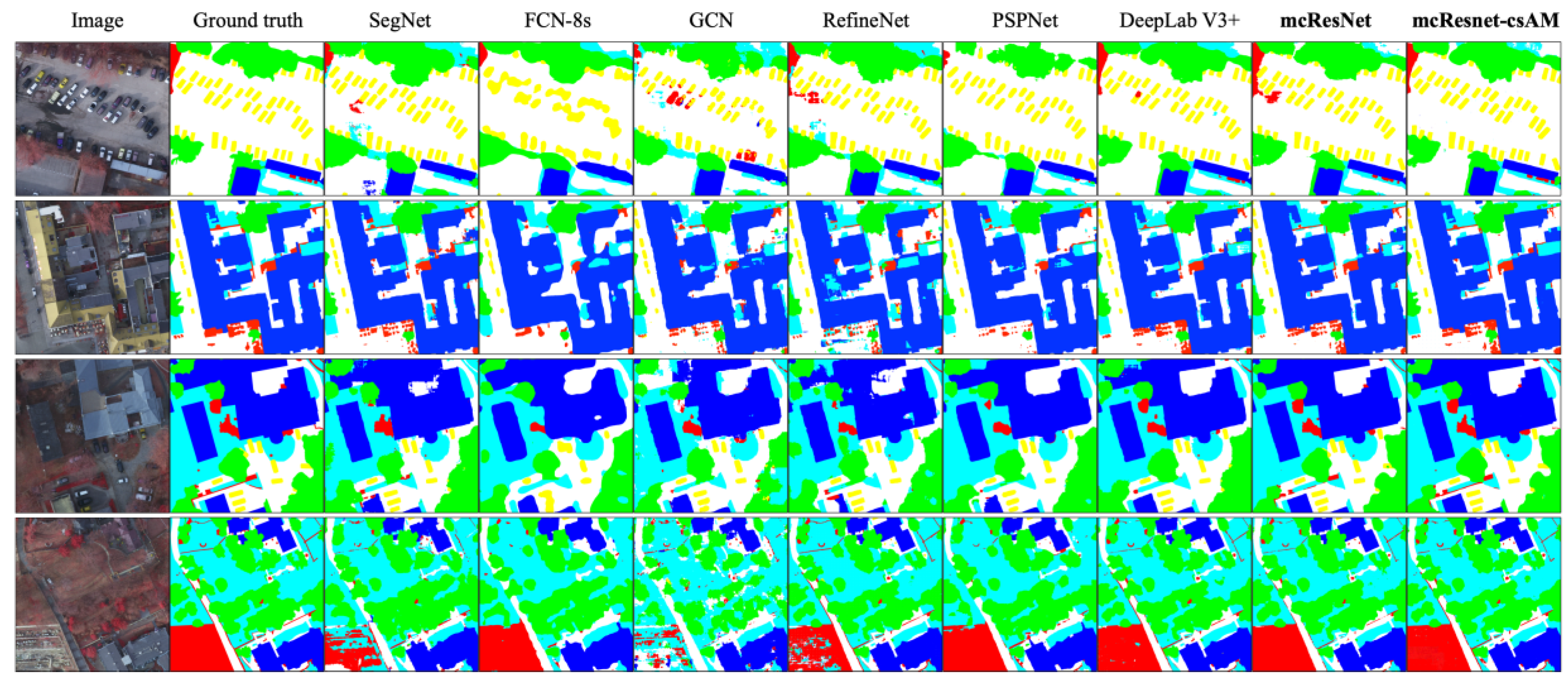
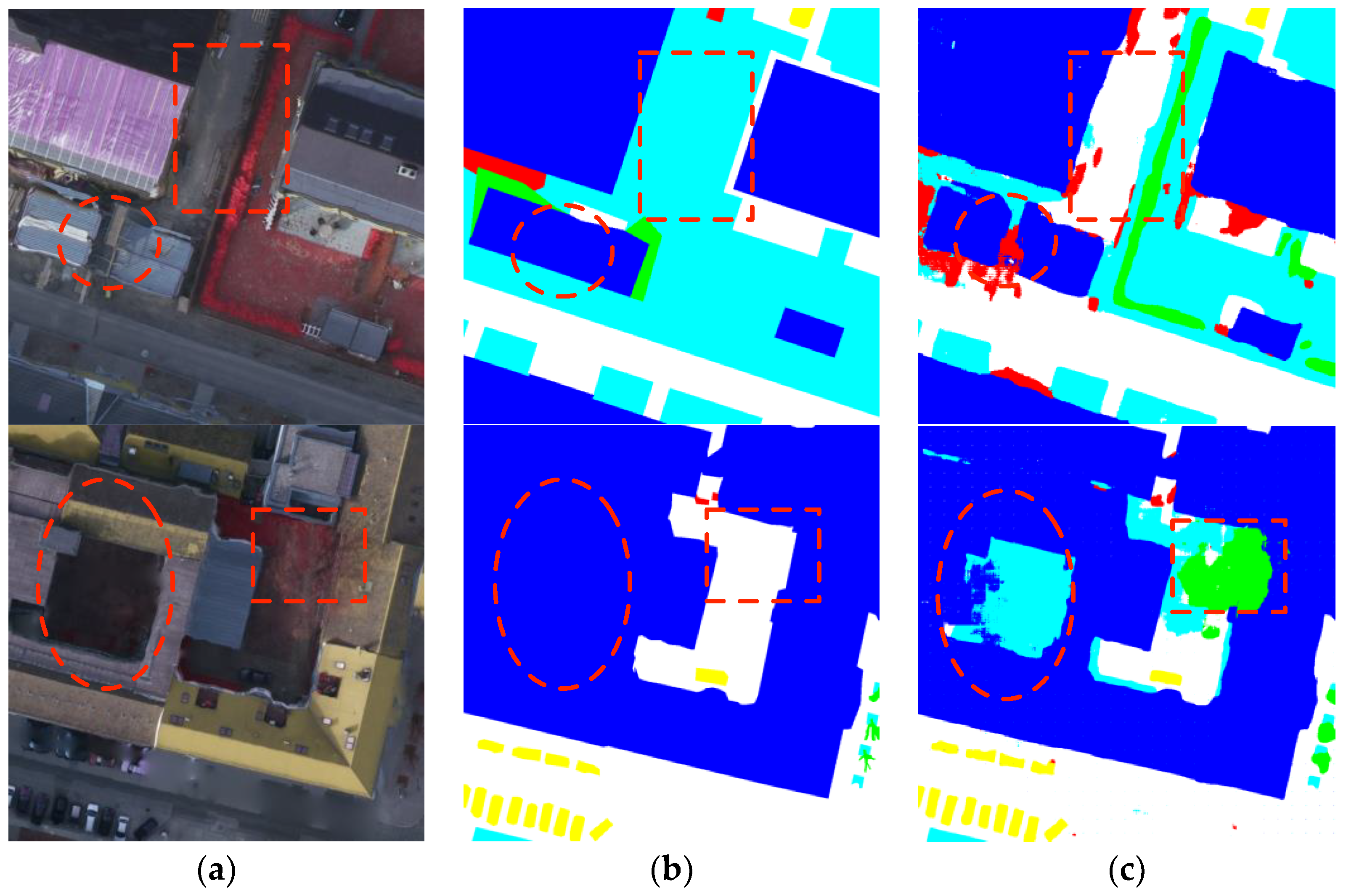
4.3. Comparison of Classification Results
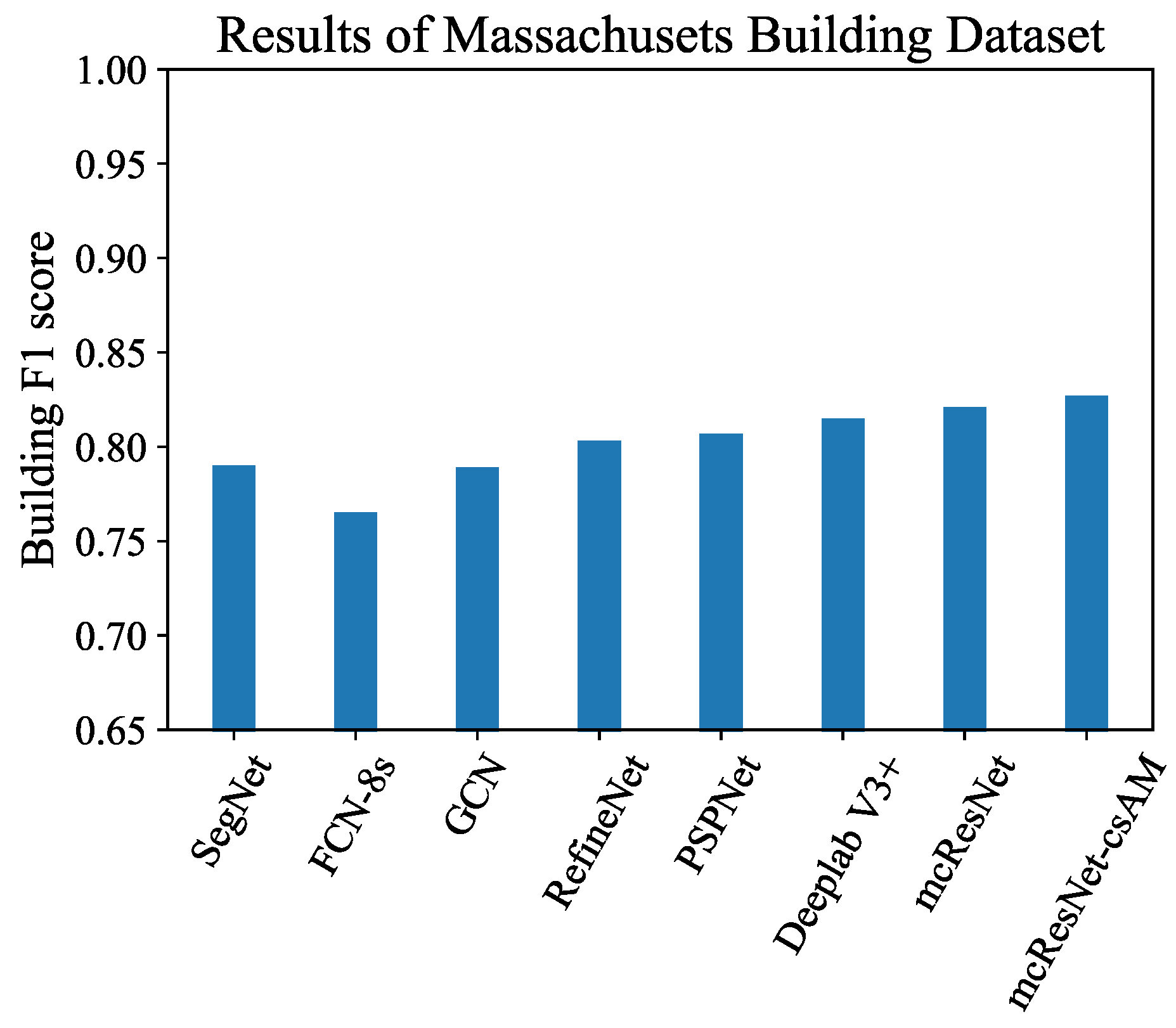
4.3.1. Results of Massachusetts Building Dataset
4.3.2. Results of ISPRS Potsdam Dataset
4.4. Results of ISPRS Potsdam 2D Semantic Labeling Contest
5. Discussion
5.1. Effect of Scale Setting
5.2. Comparison of Different Methods for Fusing Multi-Scale Features
5.3. Complexity Analysis
5.4. Effect of Data Quality
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Hunt, E.R.; Daughtry, C.S.T. What good are unmanned aircraft systems for agricultural remote sensing and precision agriculture? Int. J. Remote Sens. 2017, 39, 5345–5376. [Google Scholar] [CrossRef] [Green Version]
- Dash, J.P.; Watt, M.S.; Pearse, G.D.; Heaphy, M.; Dungey, H.S. Assessing very high resolution UAV imagery for monitoring forest health during a simulated disease outbreak. ISPRS J. Photogramm. Remote Sens. 2017, 131, 1–14. [Google Scholar] [CrossRef]
- Du, P.; Liu, P.; Xia, J.; Feng, L.; Liu, S.; Tan, K.; Cheng, L. Remote Sensing Image Interpretation for Urban Environment Analysis: Methods, System and Examples. Remote Sens. 2014, 6, 9458–9474. [Google Scholar] [CrossRef] [Green Version]
- Sevilla-Lara, L.; Sun, D.; Jampani, V.; Black, M.J. Optical flow with semantic segmentation and localized layers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3889–3898. [Google Scholar]
- Gao, P.; Wang, J.; Zhang, H.; Li, Z. Boltzmann Entropy-Based Unsupervised Band Selection for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 462–466. [Google Scholar] [CrossRef]
- Shen, L.; Wu, L.; Dai, Y.; Qiao, W.; Wang, Y. Topic modelling for object-based unsupervised classification of VHR panchromatic satellite images based on multiscale image segmentation. Remote Sens. 2017, 9, 840. [Google Scholar] [CrossRef]
- Pham, M.T.; Mercier, G.; Michel, J. PW-COG: An effective texture descriptor for VHR satellite imagery using a pointwise approach on covariance matrix of oriented gradients. IEEE Trans. Geosci. Remote Sens. 2016, 54, 3345–3359. [Google Scholar] [CrossRef]
- Zhang, X.; Du, S.; Wang, Q.; Zhou, W. Multiscale Geoscene Segmentation for Extracting Urban Functional Zones from VHR Satellite Images. Remote Sens. 2018, 10, 281. [Google Scholar] [CrossRef]
- Pham, M.-T.; Mercier, G.; Michel, J. Pointwise graph-based local texture characterization for very high resolution multispectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 1962–1973. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Shen, L.; Tang, H.; Chen, Y.H.; Gong, A.; Li, J.; Yi, W.B. A semisupervised latent dirichlet allocation model for object-based classification of VHR panchromatic satellite images. IEEE Geosci. Remote Sens. Lett. 2014, 11, 863–867. [Google Scholar] [CrossRef]
- Marcos, D.; Volpi, M.; Kellenberger, B.; Tuia, D. Land cover mapping at very high resolution with rotation equivariant CNNs: Towards small yet accurate models. ISPRS J. Photogramm. Remote Sens. 2018, 145, 96–107. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–8 December 2012; pp. 1097–1105. [Google Scholar]
- Ye, D.; Li, Y.; Tao, C.; Xie, X.; Wang, X. Multiple Feature Hashing Learning for Large-Scale Remote Sensing Image Retrieval. ISPRS Int. J. Geo-Inf. 2017, 6, 364. [Google Scholar] [CrossRef]
- Li, E.; Xia, J.; Du, P.; Lin, C.; Samat, A. Integrating Multilayer Features of Convolutional Neural Networks for Remote Sensing Scene Classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 5653–5665. [Google Scholar] [CrossRef]
- Zheng, X.; Yuan, Y.; Lu, X. A Deep Scene Representation for Aerial Scene Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 4799–4809. [Google Scholar] [CrossRef]
- Zhang, C.; Sargent, I.; Pan, X.; Li, H.; Gardiner, A.; Hare, J.; Atkinson, P.M. An object-based convolutional neural network (OCNN) for urban land use classification. Remote Sens. Environ. 2018, 216, 57–70. [Google Scholar] [CrossRef] [Green Version]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 26–29 November 1990; pp. 396–404. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–12 June 2015; pp. 3431–3440. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef]
- Li, Y.; Chen, Y.; Liu, G.; Jiao, L. A Novel Deep Fully Convolutional Network for PolSAR Image Classification. Remote Sens. 2018, 10, 1984. [Google Scholar] [CrossRef]
- Fu, G.; Liu, C.; Zhou, R.; Sun, T.; Zhang, Q. Classification for high resolution remote sensing imagery using a fully convolutional network. Remote Sens. 2017, 9, 498. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning deconvolution network for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 1520–1528. [Google Scholar]
- Liu, Y.; Fan, B.; Wang, L.; Bai, J.; Xiang, S.; Pan, C. Semantic labeling in very high resolution images via a self-cascaded convolutional neural network. ISPRS J. Photogramm. Remote Sens. 2018, 145, 78–95. [Google Scholar] [CrossRef] [Green Version]
- Wang, H.; Wang, Y.; Zhang, Q.; Xiang, S.; Pan, C. Gated convolutional neural network for semantic segmentation in high-resolution images. Remote Sens. 2017, 9, 446. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Zhang, N.; Xie, S. Hyperspectral image classification based on nonlinear spectral–spatial network. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1782–1786. [Google Scholar] [CrossRef]
- Gaetano, R.; Ienco, D.; Ose, K.; Cresson, R. A Two-Branch CNN Architecture for Land Cover Classification of PAN and MS Imagery. Remote Sens. 2018, 10, 1746. [Google Scholar] [CrossRef]
- Perez, D.; Banerjee, D.; Kwan, C.; Dao, M.; Shen, Y.; Koperski, K.; Marchisio, G.; Li, J. Deep learning for effective detection of excavated soil related to illegal tunnel activities. In Proceedings of the IEEE Ubiquitous Computing, Electronics and Mobile Communication Conference, New York, NY, USA, 19–21 October 2017; pp. 626–632. [Google Scholar]
- Lu, Y.; Perez, D.; Dao, M.; Kwan, C.; Li, J. Deep Learning with Synthetic Hyperspectral Images for Improved Soil Detection in Multispectral Imagery. In Proceedings of the IEEE Ubiquitous Computing, Electronics and Mobile Communication Conference, New York, NY, USA, 8–10 November 2018; pp. 8–10. [Google Scholar]
- Zhao, W.; Du, S.; Emery, W.J. Object-based convolutional neural network for high-resolution imagery classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3386–3396. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional neural networks for large-scale remote-sensing image classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef]
- Zhong, Z.; Li, J.; Cui, W.; Jiang, H. Fully convolutional networks for building and road extraction: Preliminary results. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium, Beijing, China, 10–15 July 2016; pp. 1591–1594. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Yang, H.; Wu, P.; Yao, X.; Wu, Y.; Wang, B.; Xu, Y. Building extraction in very high resolution imagery by dense-attention networks. Remote Sens. 2018, 10, 1768. [Google Scholar] [CrossRef]
- Chen, L.-C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Mboga, N.; Georganos, S.; Grippa, T.; Lennert, M.; Vanhuysse, S.; Wolff, E. Fully Convolutional Networks and Geographic Object-Based Image Analysis for the Classification of VHR Imagery. Remote Sens. 2019, 11, 597. [Google Scholar] [CrossRef]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Cao, R.; Chen, Y.; Shen, M.; Chen, J.; Zhou, J.; Wang, C.; Yang, W. A simple method to improve the quality of NDVI time-series data by integrating spatiotemporal information with the Savitzky-Golay filter. Remote Sens. Environ. 2018, 217, 244–257. [Google Scholar] [CrossRef]
- Marmanis, D.; Schindler, K.; Wegner, J.D.; Galliani, S.; Datcu, M.; Stilla, U. Classification with an edge: Improving semantic image segmentation with boundary detection. ISPRS J. Photogramm. Remote Sens. 2018, 135, 158–172. [Google Scholar] [CrossRef] [Green Version]
- Zhang, W.; Huang, H.; Schmitz, M.; Sun, X.; Wang, H.; Mayer, H. Effective fusion of multi-modal remote sensing data in a fully convolutional network for semantic labeling. Remote Sens. 2017, 10, 52. [Google Scholar] [CrossRef]
- Liu, W.; Rabinovich, A.; Berg, A.C. Parsenet: Looking wider to see better. arXiv 2015, arXiv:1506.04579. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. arXiv 2015, arXiv:1511.07122. [Google Scholar]
- Farabet, C.; Couprie, C.; Najman, L.; LeCun, Y. Learning hierarchical features for scene labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed]
- Eigen, D.; Fergus, R. Predicting depth, surface normals and semantic labels with a common multi-scale convolutional architecture. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13–16 December 2015; pp. 2650–2658. [Google Scholar]
- Lin, G.; Shen, C.; Van Den Hengel, A.; Reid, I. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3194–3203. [Google Scholar]
- Chen, L.-C.; Yang, Y.; Wang, J.; Xu, W.; Yuille, A.L. Attention to scale: Scale-aware semantic image segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3640–3649. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT press: Cambridge, MA, USA, 2016. [Google Scholar]
- Mnih, V. Machine Learning for Aerial Image Labeling; University of Toronto (Canada): Toronto, ON, USA, 2013. [Google Scholar]
- Peng, C.; Zhang, X.; Yu, G.; Luo, G.; Sun, J. Large Kernel Matters—Improve Semantic Segmentation by Global Convolutional Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4353–4361. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Chen, L.-C.; Papandreou, G.; Schroff, F.; Adam, H. Rethinking atrous convolution for semantic image segmentation. arXiv 2017, arXiv:1706.05587. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Sherrah, J. Fully convolutional networks for dense semantic labelling of high-resolution aerial imagery. arXiv 2016, arXiv:1606.02585. [Google Scholar]
- Chen, G.; Zhang, X.; Wang, Q.; Dai, F.; Gong, Y.; Zhu, K. Symmetrical dense-shortcut deep fully convolutional networks for semantic segmentation of very-high-resolution remote sensing images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1633–1644. [Google Scholar] [CrossRef]
- Yang, H.; Yu, B.; Luo, J.; Chen, F. Semantic segmentation of high spatial resolution images with deep neural networks. GISci. Remote Sens. 2019, 56, 749–768. [Google Scholar] [CrossRef]
- Piramanayagam, S.; Schwartzkopf, W.; Koehler, F.W.; Saber, E. Classification of remote sensed images using random forests and deep learning framework. In Proceedings of the SPIE Remote Sensing, Scotland, UK, 26–29 September 2016; p. 100040L. [Google Scholar]
- Liu, Y.; Piramanayagam, S.; Monteiro, S.T.; Saber, E. Semantic segmentation of multisensor remote sensing imagery with deep ConvNets and higher-order conditional random fields. J. Appl. Remote Sens. 2019, 13, 016501. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | F1 | OA |
|---|---|---|
| SegNet | 79.9 | 92.9 |
| FCN-8s | 76.4 | 92.9 |
| GCN | 78.9 | 92.8 |
| RefineNet | 80.3 | 93.1 |
| PSPNet | 80.7 | 93.2 |
| DeepLab V3+ | 81.5 | 94.2 |
| mcResNet | 81.6 | 94.0 |
| mcResNet-csAM (3 scales) | 82.7 | 94.6 |
| Methods | Imp surf (F1) | Building (F1) | Low veg (F1) | Tree (F1) | Car (F1) | Mean F1 | OA |
|---|---|---|---|---|---|---|---|
| SegNet | 89.0 | 93.7 | 87.3 | 84.9 | 89.2 | 88.8 | 87.9 |
| FCN-8s | 87.8 | 94.9 | 85.6 | 83.7 | 81.5 | 86.7 | 87.0 |
| GCN | 79.6 | 94.1 | 78.4 | 79.3 | 85.9 | 83.5 | 83.3 |
| RefineNet | 88.1 | 94.3 | 83.7 | 84.9 | 88.9 | 88.0 | 87.2 |
| PSPNet | 89.8 | 95.8 | 85.9 | 86.0 | 88.1 | 89.1 | 88.8 |
| DeepLab V3+ | 90.9 | 96.0 | 86.3 | 85.7 | 89.8 | 89.7 | 89.5 |
| mcResNet | 91.6 | 95.7 | 86.0 | 85.8 | 90.2 | 89.8 | 89.5 |
| mcResNet-csAM (3 scales) | 92.4 | 96.2 | 86.2 | 86.0 | 90.3 | 90.2 | 90.0 |
| Methods | Imp surf (F1) | Building (F1) | Low veg (F1) | Tree (F1) | Car (F1) | OA | Remark |
|---|---|---|---|---|---|---|---|
| AZ3 | 93.1 | 96.3 | 87.2 | 88.6 | 96.0 | 90.7 | with DSM |
| CASIA2 [25] | 93.3 | 97.0 | 87.7 | 88.4 | 96.2 | 91.1 | |
| DST_6 [56] | 92.4 | 96.4 | 86.8 | 87.7 | 93.4 | 90.2 | |
| CVEO [57] | 91.2 | 94.5 | 86.4 | 87.4 | 95.4 | 89.0 | |
| CAS_Y2 [58] | 92.6 | 96.2 | 87.3 | 87.7 | 95.7 | 90.4 | |
| RIT6 [59] | 92.5 | 97.0 | 86.5 | 87.2 | 94.9 | 90.2 | |
| RIT_L7 [60] | 91.2 | 94.6 | 85.1 | 85.1 | 92.8 | 88.4 | |
| HUSTW4 | 93.6 | 97.6 | 88.5 | 88.8 | 94.6 | 91.6 | with DSM |
| BUCTY5 | 93.1 | 97.3 | 86.8 | 87.1 | 94.1 | 90.6 | with DSM |
| mcResNet-csAM (SWJ_2) | 94.4 | 97.4 | 87.8 | 87.6 | 94.7 | 91.7 |
| Scale Setting | Massachusetts Building Dataset | ISPRS Potsdam Dataset | |
|---|---|---|---|
| F1 | Mean F1 | OA | |
| Scales = {1, 0.75} | 82.4 | 91.3 | 91.6 |
| Scales = {1, 0.5} | 82.2 | 90.9 | 91.4 |
| Scales = {1, 0.75, 0.5} | 82.7 | 91.6 | 91.9 |
| Scales = {1, 0.5, 0.25} | 81.0 | 89.5 | 91.1 |
| Scales = {1, 0.75, 0.5, 0.25} | 81.7 | 90.8 | 91.3 |
| Methods | Massachusetts Building Dataset | ISPRS Potsdam Dataset | |
|---|---|---|---|
| F1 | Mean F1 | OA | |
| Max pooling | 82.2 | 91.1 | 91.1 |
| Average pooling | 81.4 | 89.6 | 90.2 |
| FPN | 82.0 | 90.9 | 91.2 |
| mcResNet-csAM | 82.7 | 91.6 | 91.9 |
| Model | Model Size | Time |
|---|---|---|
| SegNet | 116 M | 14 s |
| FCN-8s | 537 M | 26 s |
| GCN | 234 M | 18 s |
| RefineNet | 454 M | 24 s |
| Deeplab V3+ | 437 M | 23 s |
| PSPNet | 262 M | 18 s |
| mcResNet | 234 M | 16 s |
| mcResNet-csAM (3 scales) | 237 M | 26 s |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Shen, L.; Qiao, W.; Dai, Y.; Li, Z. Deep Feature Fusion with Integration of Residual Connection and Attention Model for Classification of VHR Remote Sensing Images. Remote Sens. 2019, 11, 1617. https://doi.org/10.3390/rs11131617
Wang J, Shen L, Qiao W, Dai Y, Li Z. Deep Feature Fusion with Integration of Residual Connection and Attention Model for Classification of VHR Remote Sensing Images. Remote Sensing. 2019; 11(13):1617. https://doi.org/10.3390/rs11131617
Chicago/Turabian StyleWang, Jicheng, Li Shen, Wenfan Qiao, Yanshuai Dai, and Zhilin Li. 2019. "Deep Feature Fusion with Integration of Residual Connection and Attention Model for Classification of VHR Remote Sensing Images" Remote Sensing 11, no. 13: 1617. https://doi.org/10.3390/rs11131617
APA StyleWang, J., Shen, L., Qiao, W., Dai, Y., & Li, Z. (2019). Deep Feature Fusion with Integration of Residual Connection and Attention Model for Classification of VHR Remote Sensing Images. Remote Sensing, 11(13), 1617. https://doi.org/10.3390/rs11131617