1. Introduction
Sustainable Development Goals (SDGs) are a set of priority targets and indicators, such as certain levels of food security, air quality, and environmental health, for countries to achieve in order to improve the quality of human life and state of the environment [
1]. The United Nations and World Bank have set these goals and are encouraging, and in some cases supporting, countries to monitor their progress towards achieving these goals by 2030 [
2,
3]. Tracking the progress of countries towards these SDGs requires methods and data for measuring and monitoring resources. However, collecting and accessing the required data can be prohibitively expensive. Satellite imagery provides a key low-cost data source for contributing to achieving and measuring the SDGs [
2,
4,
5,
6]. As a result, big data sources, including remote sensing data, will be crucial for monitoring SDGs in the future [
4,
7], especially as the number of free data sources are growing [
8,
9]. Examples of these free sources include the CEOS Data Cube products [
8] and the United States Geological Survey (USGS) Global Visualization Viewer [
9]. The satellite images from these sources have long time series, increasingly high resolution, and are ‘analysis ready data’ that have been pre-processed and corrected for atmospheric effects. However, while these datasets address the cost barrier to measuring SDGs in terms of data acquisition cost, it can still be expensive and time-consuming to fill gaps in these data. Therefore, some countries have infrastructure and skill barriers to using satellite imagery data, despite the growing ease of access [
10].
With these barriers in mind, our paper is motivated by the need for environmental SDG monitoring by agencies with limited data processing resources, particularly in developing countries. We aim to improve the analyses that can be achieved while exclusively using freely available images, data, and software. We focus on a minimum core set of accessible data and free software tools which could be practically implemented to produce statistics to monitor SDGs.
Data gaps exist in free satellite image products, which present a challenge to pre-processing and analysing satellite imagery. Cloud cover is the most common cause of missing or unobserved pixels, particularly in tropical areas of the world [
11,
12]. One approach to fill image gaps is to create a composite map by using images of the missing pixels from a different point in time. This can result in using pixel compositions of a large temporal interval, in which time change on the ground may have occurred. For example, it may be necessary to fill in a part of a summer season image with pixels from a winter season image, because this is the closest match available. Advanced statistical methods have been developed to optimise compositing, e.g., by selecting the best possible pixels in the Landsat time series to use for compositing satellite images while using a parametric weighting scheme [
13]. However, these methods still require a time series of images with low cloud cover.
Interpolation methods attempt to fill data gaps while using statistical analyses as an alternative to image compositing. There are four main categories of interpolation methods (spatial-, spectral-, and temporal-based, or hybrids of these), with each being effective under different conditions (see [
14] for a technical review). We focus on methods which are most suited to interpolating data missing due to clouds. Spectral-based methods work best under conditions that commonly occur due to sensor failure, e.g. when some bands are missing but some are complete, or when the location of missing information is different [
14]. This is not suited to our application, since data that are missing due to cloud cover have no spectral band information at all in the missing regions [
14]. Temporal-based methods can be helpful in interpolating data that are missing due to clouds, however the interval of time between images with spectral information available cannot be too short or too long [
14]. Hybrid methods combine strengths and weaknesses of interpolation approaches and include spatio-temporal and spectral-temporal methods [
14], however these still require temporal and spectral information that may not be available in regions with persistent cloud cover for long periods of time. This may be too restrictive to expect from free satellite images, especially where cloud is an issue for many months of the year [
12]. A more adaptable approach is needed for these applications, which does not rely on the availability of spectral data in previous or subsequent time steps.
In this paper, we focus on the spatial interpolation category of methods, as these are the most applicable to the missing data due to cloud cover problem. Spatial statistical solutions to filling these data gaps exist, but some are limited in their real-world applicability. Spatial interpolation approaches kriging and co-kriging aim to use statistical analyses of the observed data to infer missing data [
15]. These approaches, which have been adapted from geostatistics [
15], can be accurate, but they have computational, scale, and assumption limitations [
16,
17,
18]. Despite their high accuracy for interpolating satellite images, neither kriging and co-kriging are suited to small scale or per pixel classifications due to computational inefficiencies [
16,
17]. Kriging produces maps optimal predictions and associated prediction standard errors well, even when applied to incomplete data [
19], while assuming that variables of interest are random and spatially correlated at some scale [
17]. However, it cannot capture the spatial structure of images well [
17]. Co-kriging methods perform better than kriging for interpolating missing images by incorporating secondary information or auxiliary variables [
17]. Co-kriging is computationally efficient and it produces accurate and unbiased estimates of pixel values of satellite images. However, it assumes a linear relationship and homogeneity between the image, which has missing pixels and the input images being used to interpolate [
17], which is often unrealistic in nature [
20].
Computational complexity, required assumptions about underlying data, and boundary effects all compound the incompatibilities with using such complex spatial methods for large spatial data. For example, spatial weights effects can occur when a relationship is assumed between the variable of interest and the geometry that was selected to represent it in space. This relationship may not exist due to the structure of the data [
20]. Another example of a challenge with using spatial methods for large spatial data and images are boundary effects, which can have a significant impact on how images and other spatial data are classified [
20]. Weiss et al. [
21] proposed a method to fill gaps due to cloud faster than geostatistical methods and at a very large scale (country level) with two algorithms that classify pixels based on the ratios of observed neighbouring pixel values at two points in time. This method overcomes computational efficiency issues that are faced when using kriging methods on pixel scale data [
16], however it requires access to a time series of images with consistently minimal cloud cover.
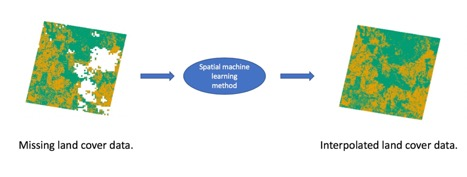
To meet the need for fast and accurate methods for interpolating missing data in satellite images, we present streamlined, fast, and accurate spatial machine learning methods to classify image features at the pixel level in satellite images with missing pixels. Our approach leverages key benefits of statistical machine learning methods for satellite imagery analysis: the ability to fit non-linear relationships, effectively cope with significantly large amounts of data, and high predictive accuracy [
22]. We predict the values of pixels based on their spatial location in the image while using these methods.
We revisit the canonical geostatistical interpolation examples for satellite images that were previously explored by Pringle et al. (2009) [
16] and Zhang et al. (2007) [
23]. Due to the outlined challenges of implementing kriging and co-kriging for our application, we compare our methods with inverse distance weighted interpolation as an alternative well-established, accurate spatial interpolation method for remote sensing data. Inverse distance weighted interpolation uses spatial autocorrelation to interpolate unknown data by assigning more weight to the data closer to the observation of interest than data, which are geographically further away [
24]. This method has been used for remote sensing data for decades [
25] and with improvements in computing, it has recently been implemented for real-time analysis of sensor data [
26].
The objective of our study is to spatially interpolate missing values due to cloud cover within satellite images and image products by using latitude and longitude as covariates, and statistical machine learning methods. Based on the results of the study, we describe some general rules for identifying when using these spatial machine learning methods will likely yield accurate results and be a useful alternative to image compositing.
2. Materials and Methods
2.1. Study Area
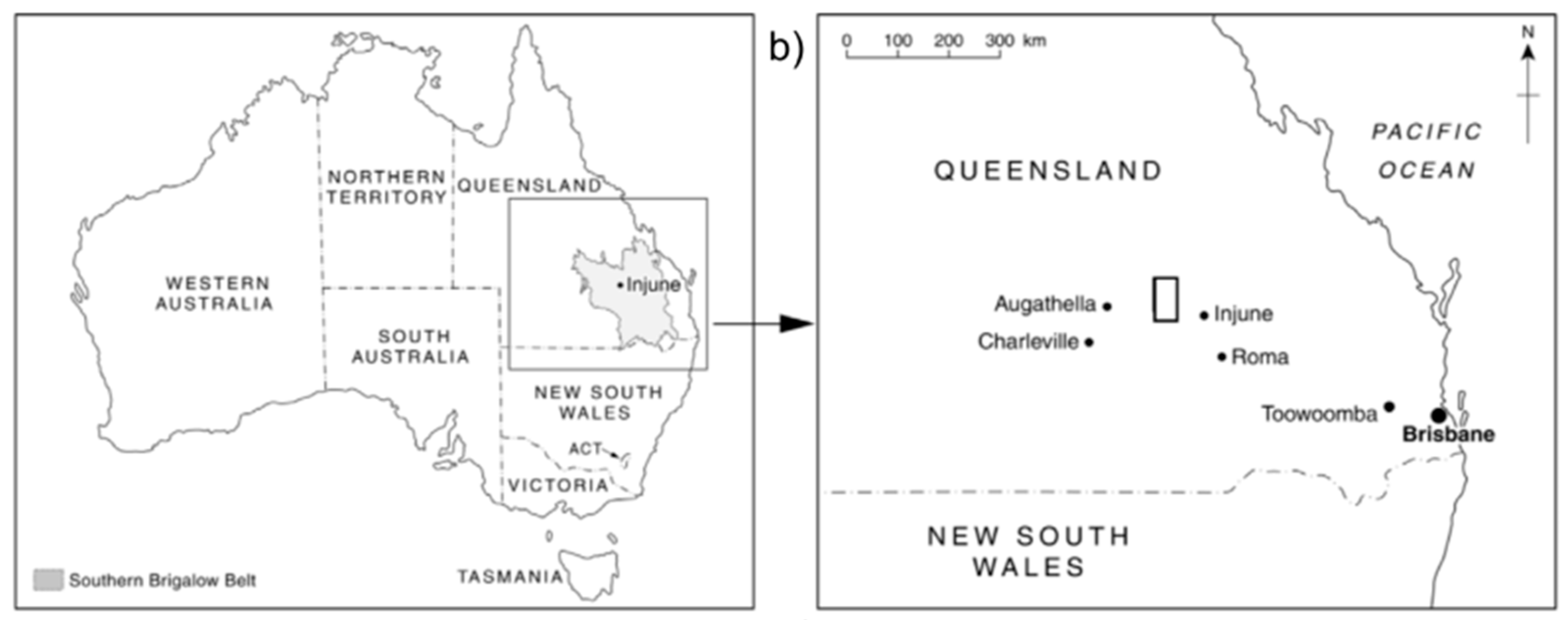
The study area is located approximately 100 km North West of the township of Injune in central southeast Queensland, Australia (see
Figure 1). The landscape in the study area, which is 180 km × 180 km (one Landsat 7 scene), mainly consists of forest, pasture, and agricultural land, with some areas abandoned to revegetation [
27]. Scattered buildings and unsealed roads are the main urban infrastructures present in the wider study area of Injune, however these are not present in the Landsat scene that was analysed [
27].
2.2. Datasets
Our application requires a map of land cover for the study area. Spatial and Foliage Projective Cover (FPC) data that were based on Landsat 7 Thematic Mapper TM satellite images of the study area were provided by Queensland Department of Environment and Science [
27]. FPC is defined as the vertically projected percentage cover of photosynthetic foliage or the fraction of the vertical view that is occluded by foliage [
28]. We have selected this variable, because the presence and extent of woodland or forest is relevant to SDG 15, which focuses on forest management [
29]. FPC can be manually collected in the field, however this is costly and time consuming, especially for large areas [
28], and so, alternatively, FPC can be calculated at a large scale for entire satellite images. The image files were read into the software R as raster format images while using the Raster package [
30]. From this data we extracted Foliage Projective Cover (FPC), latitude and longitude for each pixel.
We then used the FPC value of each pixel to describe the land cover as either grassland or woodland (a binary categorical variable). FPC values from 0% to 15% were classified as grassland and from 16% to 100% were classified as woodland. In Queensland, Australia FPC above 10% is generally classified as woody vegetation [
31], and we used a more conservative threshold of 15% that was based on advice of the FPC data provider, Queensland Department of Environment and Science. This binary categorisation of land cover was performed at the pixel scale for the entire images. We chose a binary land cover classification to simulate environmental monitoring, where binary information is required and useful, e.g., to differentiate between crop and not crop, forest and not forest, or species habitat or not. We use this simple binary land cover classification to explore the effectiveness of our methods at an uncomplicated level to demonstrate proof-of-concept. However, we also explore continuous values of FPC, which is a more complex landscape than the binary land cover classes.
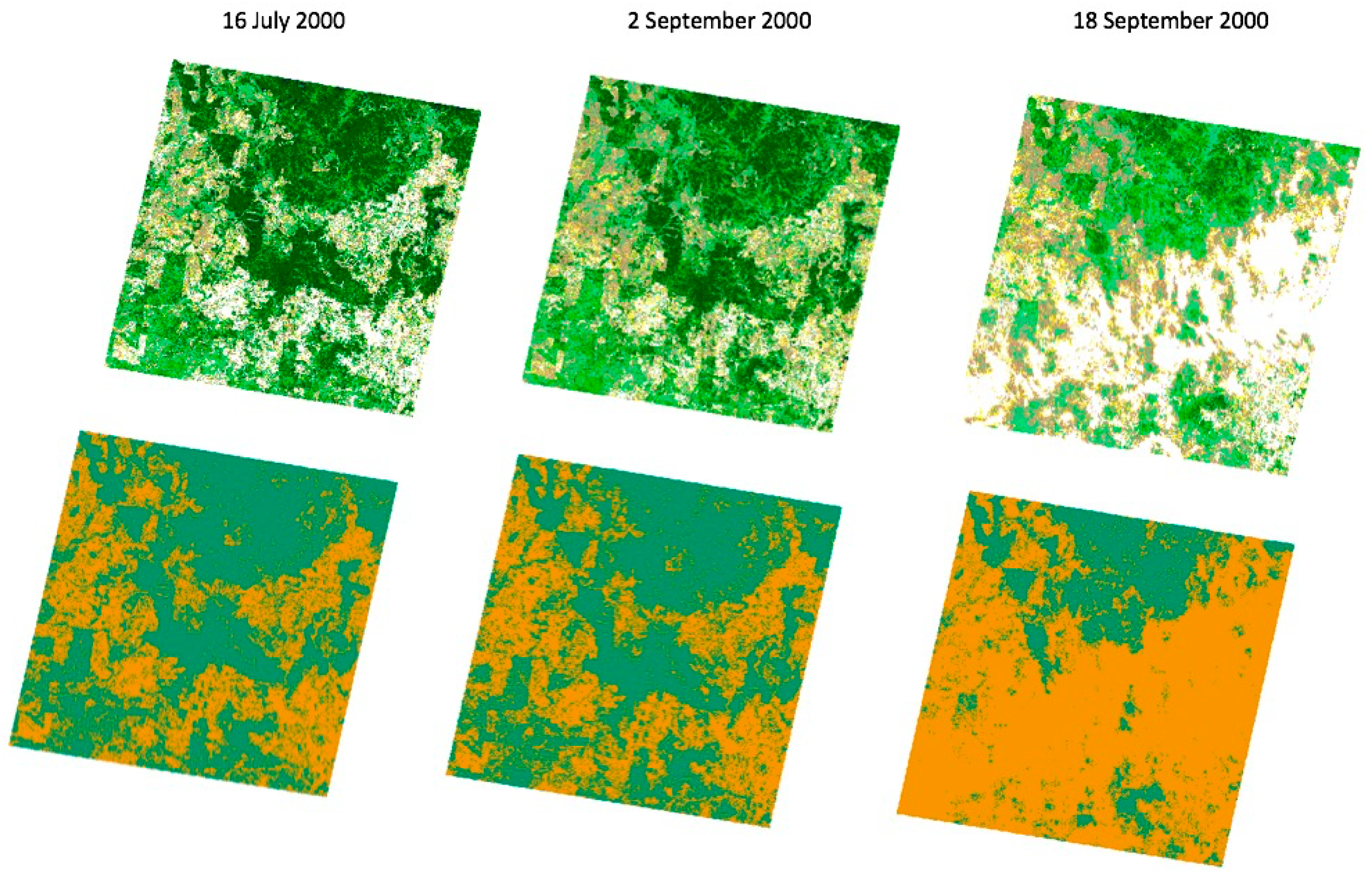
FPC data were selected from July and September 2000 to examine how the models perform in different seasons (winter and spring, respectively, in Australia).
Figure 2 shows the first two datasets have a mixture of woodland and grassland land cover, whereas the second spring dataset has noticeably more grassland land cover.
We first tested a simple scenario in which the majority of observations were one land cover class to explore the utility of our methods, and then explored more difficult cases where the land cover was heterogeneous. We intentionally selected a simulated dataset with a significantly higher proportion of grassland (18 September 2000). We chose this for proof of concept, because even if the models only predicted grassland, they would have high accuracy. If the models were unable to achieve high accuracy in this scenario, this would indicate other issues to explore in this approach. We also selected this dataset, because it approximates how a clearing event might appear in the landscape, with the sudden conversion of woodland to grassland, due to events such as intentional clearing for farmland, fire, etc. We used the results for this simple circumstance as the baseline for comparison with the more challenging scenario of a heterogeneous combination of two vegetation types, as seen in the 16 July and 2 September datasets.
We also examined whether converting FPC data to a binary classification before or after analysis made a difference to accuracy, in addition to examining whether the pattern of missing data affected the performance of the decision tree methods for predicting vegetation class and FPC value. To explore this, we trained the decision tree methods on continuous FPC values and predicted the continuous FPC values. Subsequently, we converted these continuous FPC values that were predicted by the models to a binary classification of grassland or woodland. We compared the accuracy of the converted FPC predictions with the accuracy of the predictions that were performed on FPC data, which had been converted to a binary classification of grassland and woodland prior to analysis.
2.3. Cloud Simulation
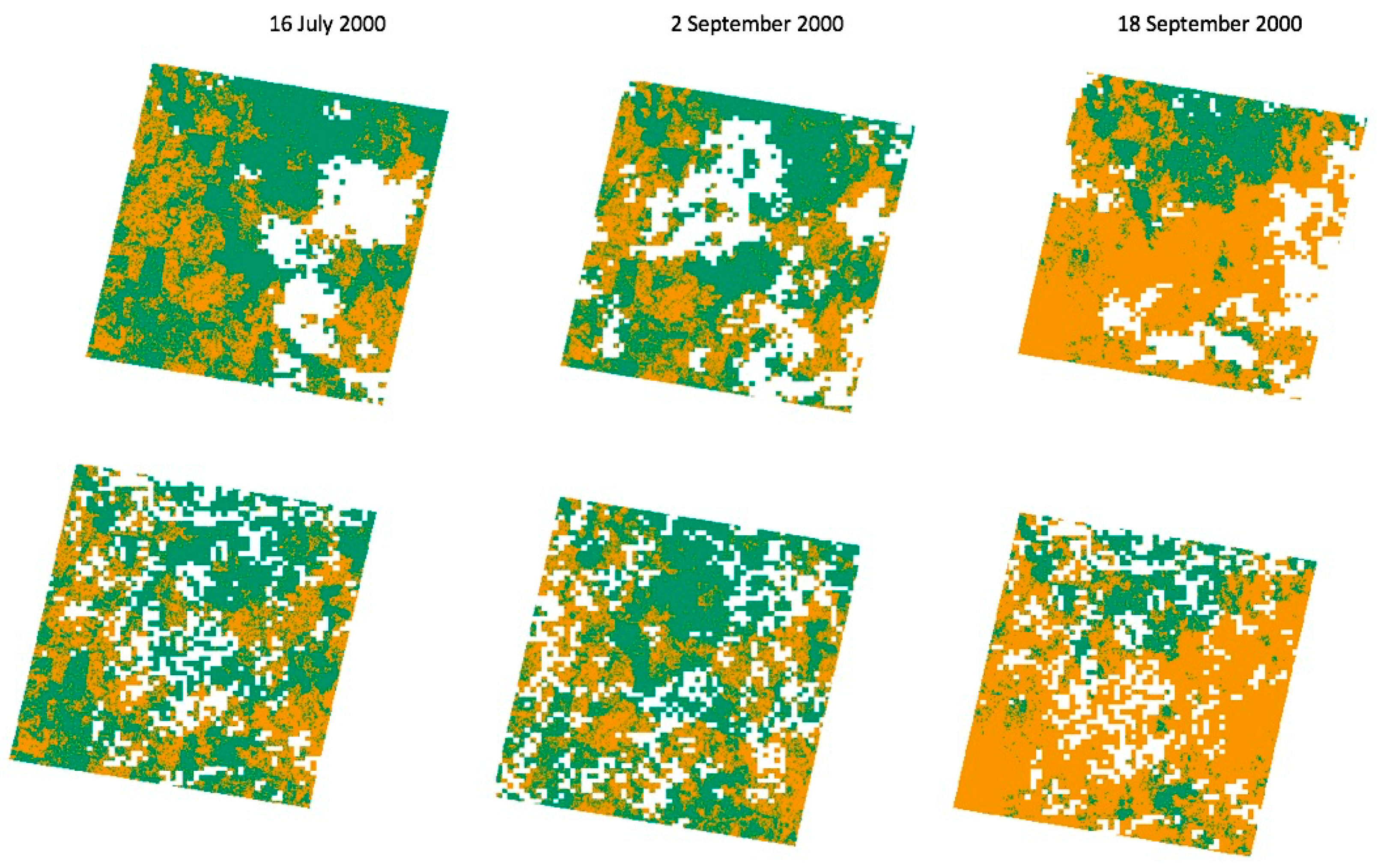
A simulated cloud mask was applied to random areas of the image to intentionally create ‘missing’ spectral data. The cloud-like shapes are simulated independently of the FPC data, while using a distance grid and applying a multivariate normal distribution, which is spatially autocorrelated with a covariance that exponentially declines with distance [
32]. The simulated cloud layer was overlaid on the FPC layer and the corresponding pixels under the ‘clouds’ had their spectral information that was removed in the FPC layer. The large cloud shapes have more missing pixels adjacent to each other in clumps to simulate large and dense cloud cover and the small cloud shapes have missing pixels scattered across a wider area of the image to simulate thinner and dispersed cloud cover.
Figure 3 shows plots of the images with simulated cloud patterns.
2.4. Methods Overview
We use machine learning methods to differentiate between two types of vegetation, namely grassland and woodland, and to predict the biophysical variable, Foliage Projective Cover (FPC), at the pixel level. We perform a simulation study to investigate the performance of our methods under different cloud patterns. A number of steps are required in order to perform the binary classification of grassland and woodland and FPC predictions. We show the overall process in
Figure 4 and also describe it below.
First, we begin with a complete satellite image product of FPC, where no data are missing; that is, every pixel has an FPC value that is derived from satellite imagery, a binary classification as grassland or woodland, a latitude, and a longitude. We simulate cloud like shapes in an image layer, and delete spectral data in these regions of the satellite image, leaving only latitude and longitude information about these ‘missing’ pixels. This leaves the majority of the pixels in the image with both classification and spatial information (referred to as ‘observed pixels’), and a proportion of pixels with only spatial information where the cloud occludes any other data (referred to as ‘missing pixels’). We separately store the original FPC value and binary classification of the now-missing pixels, assume that these are the true values for the purposes of model testing, and use these as the ground truth to validate model performance in future steps.
Second, we take a random sample of the observed pixels we use to train the machine learning algorithms (see
Figure 5). We randomly split this sample into a training set, containing 80% of the sampled pixels, and a testing set, containing 20% of the sampled pixels (see
Figure 5). In the training set, the actual classification of the pixel (grassland or woodland) is retained, as is the continuous FPC value. In the testing set, the class and FPC of the pixel is removed, so it is unknown to the machine learning model. We run our decision tree machine learning models on the training sample to build a model that can predict whether the vegetation type of the pixels is grassland or woodland. Afterwards, in a separate test, the same method is used to build a model that can predict the continuous FPC value of missing pixels.
Third, after training, the machine learning models are used to predict the class of pixels in the testing set, which is a subset of the observed pixels (see
Figure 4 and
Figure 5). We produce confusion matrices and accuracy statistics based on the results of predicting the class of pixels in the testing set to assess the predictive accuracy of the models. This allows for us to verify the effectiveness of the models for predicting the values of pixels missing due to cloud cover.
Fourth, the resulting models are then used to interpolate the land cover classification of any pixels missing in the image. We compare these to the ‘ground truth’ data that we stored earlier to evaluate the overall accuracy of our interpolation method, and therefore evaluate whether our proposed methods are useful, fast, and accurate.
We perform this training, testing, and accuracy assessment process on two random samples of observed pixels and two random samples of missing pixels per image with each of the different cloud patterns (six images and 24 samples) and implement both the gradient boosted machine and random forest algorithms. We apply this approach for both a binary classification of FPC and prediction of continuous FPC values.
We examine and compare the performance of two types of decision tree machine learning methods (in steps two and three above) in our study. They both use many simple decision trees to classify observations, however the algorithms combine them in different ways to reach final classifications and predictions. We compare the results of the decision tree methods with inverse distance weighted interpolation, which is an established, known interpolation method for remote sensing data. The methods will be described in more detail in
Section 2.5 and
Section 2.6.
A key benefit of the decision tree methods is that they only require a relatively small amount of the total data available to be effectively trained and perform accurate classifications. Even with data missing due to cloud cover, satellite images will have millions or billions of pixels that are available for training, and training on only thousands of pixels can produce accurate models for classifying the unknown test data.
2.5. Decision Tree Methods
Statistical machine learning methods, which are also called artificial intelligence methods, use algorithmic models to analyse data. These methods treat the way in which the data were generated or relationships between the variables as unknown [
33]. Decision trees are a category of machine learning methods that can be used to classify large amounts of data [
34]. Decision trees are first trained on data where the values of the observations are known, and are then used to predict the values of observations in the testing data, where the values of the observations are unknown.
Decision tree methods can be applied to large amounts of data due to their computational simplicity, which is useful for satellite imagery analysis that is performed on thousands or millions of pixels. Examples of the use of decision trees in the remote sensing literature include identifying land cover [
35], mapping forest change globally [
36], and identifying land use classes, such as agriculture, built up areas, and water in Surat city, India [
37]. However, decision tree methods in their simple form are prone to inaccuracy [
34]. It is very difficult, if not impossible, to accurately classify observations that are based on only one decision rule. For example, classifying pixels as bare earth or forest based on the value of only one variable would lead to very inaccurate results. By combining many simple decision trees, decision tree algorithms gradient boosted machine and random forest can perform highly accurate classifications. In our study, we compare the performance of these two popular types of decision tree methods.
2.5.1. Gradient Boosted Machine
Gradient boosted machine is a type of boosted decision tree method, which is configured to avoid the accuracy issues that are associated with simple, single decision trees [
34]. Boosting is the concept that it is easier to find and average many inaccurate or ‘weak’ decision rules than to find one that is highly accurate [
22]. A gradient boosted machine has three key components: a simple decision tree, also called a weak learner, a loss function, and an additive model. A weak learner is a simple decision tree, which, if used on its own, would predict the class of observations with low accuracy. Using boosting, decision trees are iteratively fit to training data, while using multiple weak learners to classify observations, gradually emphasising observations modelled inaccurately by the previous collection of trees. By focusing on the variability in the data unexplained by previous trees, with each new tree that is fit the variance, or error, is further reduced. This iterative minimisation of the loss function is the ‘boosting’ approach, and it is also called the gradient descent procedure, which is where the method gets its name [
22]. The loss function of a gradient boosted machine is given by
where
is a covariate,
is the dependent variable, and
is a single decision tree function mapping covariate observation
to dependent variable
[
38]. The gradient boosted machine uses the training data to estimate a decision tree that will accurately predict the class of observations, while minimising the expected value of the loss function
over the joint distribution of all the dependent variable and covariate values [
38]. Different loss functions can be chosen, and in this study, we choose the squared error loss function (
2, because it is effective and commonly used [
38]. This is also the default in the gbm package [
39] we used to fit the gradient boosted machine in the case study.
For a gradient boosted machine, as defined by [
38], each decision tree is expressed
That is, the gradient boosted machine is a combination of multiple weak learners ( in Equation (1)). is a constant value that is used as a threshold to split the observations into different classes. Depending on where an observation’s value for variable compares with the constant value, , the observation will either be placed into a final classification (terminal node) or continue to be analysed based on other values until a final classification is reached for that observation. The indicator function has the value 1 if the decision tree argument is true, e.g., the value of observation < and zero if it is false. These functions allow for the gradient boosted machine to classify observations while using many decision trees to reach a final classification. The variables that determine how observations are separated into different classifications and the values of those variables that represent the splits at non-terminal nodes in the tree are represented as .
The gradient boosted machine in our study is a combination of many weak learner decision trees that are fit to minimise the loss function, (
2 at each iteration, which as defined by [
38], can be expressed as:
Each new decision tree is fit to the covariates in a way that reduces the loss function,
. This reduction at each iteration of the algorithm approximates the gradient of the decrease in loss function that is necessary to improve the fit of the model to the data [
39]. Latitude and longitude are included as covariates
in our spatial gradient boosted machine.
2.5.2. Random Forest
The random forest algorithm is a decision tree method that uses bagging in order to reduce variance by averaging many inaccurate but approximately unbiased decision trees [
34]. Bagging is similar to boosting, in that it combines many weaker rules rather than using one decision rule, but boosting produces a sequence of weak decision rules and bagging takes an average [
22].
A random forest draws a bootstrap sample
of size N from the training data to grow a decision tree,
to the data. The trees are created by repeatedly and randomly selecting the
variables from the potential set of
variables, choosing the variable that best separates the data into two groups [
34]. This process is repeated to grow a forest of these decision trees classifiers expressed by [
34] as
Each observation
is classified not by just one of these trees, but by the forest of individual trees. This means each observation is classified based on what the majority of the decision trees predict. This can be expressed as
where
is the class prediction of the
random forest [
34]. In our spatial random forest, the latitude and longitude are included as covariates
which are randomly selected as
variables to grow the random forest classifiers in the final ensemble
and to classify observations.
2.5.3. Tuning Parameters and Computation
Tuning parameters can be set to change the running and performance of machine learning algorithms. For decision tree methods generally, we can choose different values of tuning parameters, such as the number of trees, learning rate, and interaction depth. The number of trees specifies how many simple decision trees will be fit by the algorithm, learning rate specifies the contribution of each individual tree to the overall model, and the interaction depth specifies how many interactions are fit (one way, two way, etc.) [
34]. The investigation and explanation of optimal values for these parameters is an entire body of research itself beyond the scope of this work (see Elith et al. (2008) [
34]). In this paper, we implement the gradient boosted machine and random forest algorithms based on recommendations from Elith et al. (2008) [
34], which in some cases are also the default values in the software packages that we use.
The gradient boosted machine models were fit while using the R package ‘gbm’ [
40]. The tuning parameters, number of trees, shrinkage parameter (also known as the learning rate), and interaction depth, were set using rule of thumb values that were specified by [
22]. The random forest models were fit using the package randomForest [
41]. We implement the inverted distance weighted interpolation method using the package gstat [
42] in R.
2.6. Samples, Accuracy Measurements
The random forest, gradient boosted machine, and inverse distance weighted interpolation methods were trained on samples of 8000 pixels in the satellite image, and predictions were made on 2000 pixels each time (an 80%/20% training and testing data split [
34]). In the training sets the proportion of grassland ranged from 31–38%, 34–36%, and 61–78% for the 16 July, 2 September, and 18 September 2000 data, respectively. The proportions were the same in the testing set, except the 18 September 2000 data grassland ranged from 61–71%. The proportion of woodland in the training sets ranged from 62%–66%, 64–66%, and 22–37% for the 16 July, 2 September, and 18 September 2000 data, respectively. In the testing sets, the proportion of woodland ranged from 62–69%, 64–66%, and 22–39% for the 16 July, 2 September, and 18 September 2000 data, respectively.
The accuracy of the methods was assessed while using overall accuracy, producer’s accuracy, and user’s accuracy statistics produced from confusion matrices for binary classification of vegetation type. Producer’s accuracy (which is related to omission error) is the probability the observation in the data is classified as the same class and user’s accuracy (which is related to commission error) is the probability the classified observations are the same class in the reference data [
43]. The accuracy of the methods for the prediction of continuous FPC values was assessed while using root mean squared error (RMSE) and mean absolute error (MAE). Root mean squared error is calculated by taking the average of the squared model residuals, and then taking the square root of this average [
44]. The mean absolute error is the average of the residuals i.e., the average of the difference between the predicted and observed values [
45]. The overall, producer’s, and user’s accuracy statistics were produced while using the caret package [
46] in R.
We performed one-way ANOVA tests. ANOVA tests identify differences between group means, and whether these differences are statistically significant or not to identify differences in mean overall accuracy and RMSE between groups based on methods, pixel class (missing or observed), image dates, and cloud pattern (small or large) [
47]. We report the F statistic and the corresponding p-value [
47]. We also present Tukey post-hoc test results [
47] to identify significant pairwise differences between groups. These statistics were produced in base R while using the ‘aov’ function.
4. Discussion
Monitoring progress towards the Sustainable Development Goals (SDGs) provides important insights into the state of the environment and quality of human life in countries, but the cost of collecting data is a barrier to measuring the SDGs. Free satellite images are a key data source to overcoming this barrier, however there are associated quality issues with these images due to missing data from cloud cover, especially in tropical areas. We have presented streamlined spatial machine learning methods that can fill gaps in satellite images due to missing data to address this challenge, and classify pixels into different vegetation types to identify grassland and woodland.
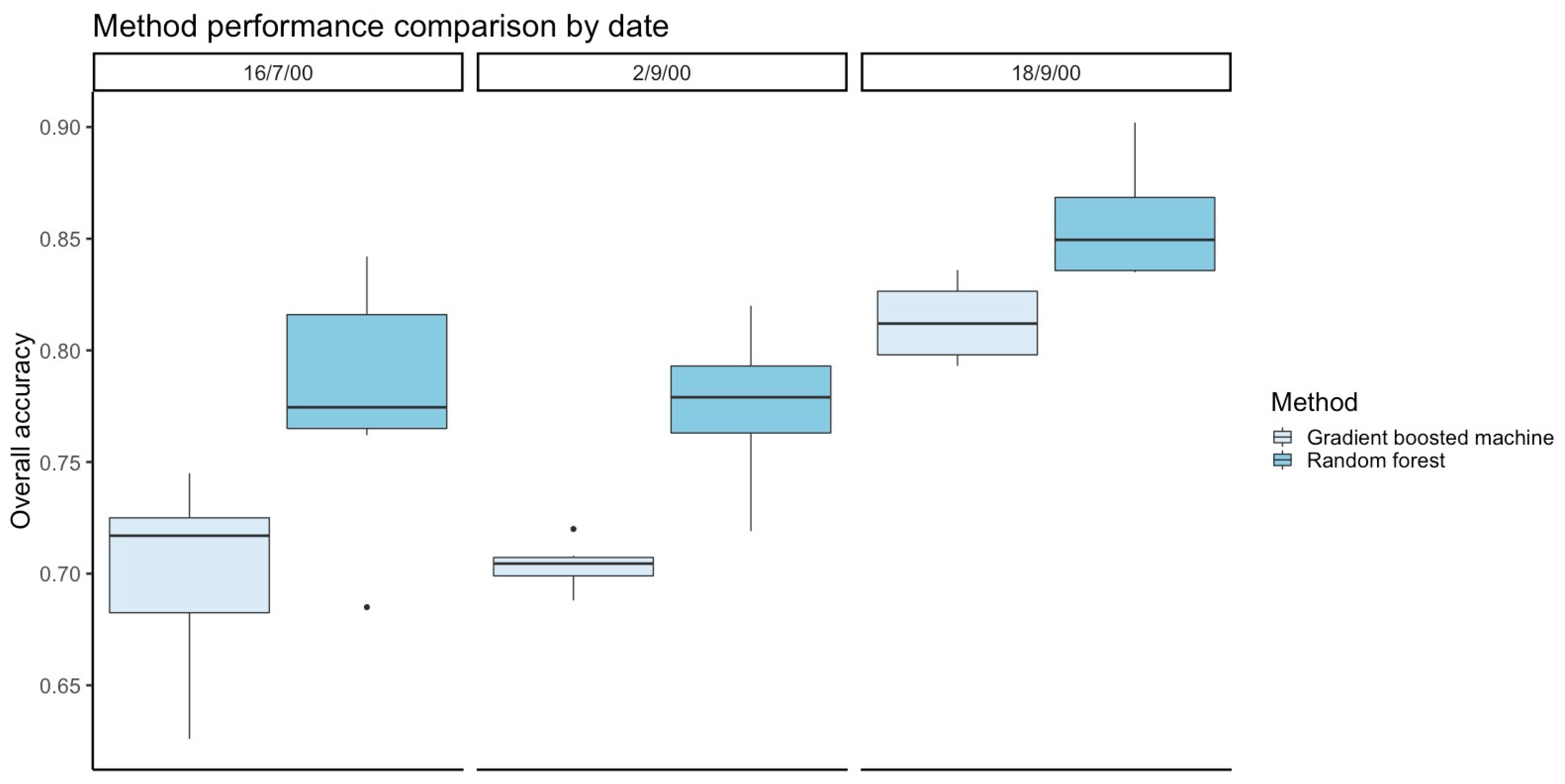
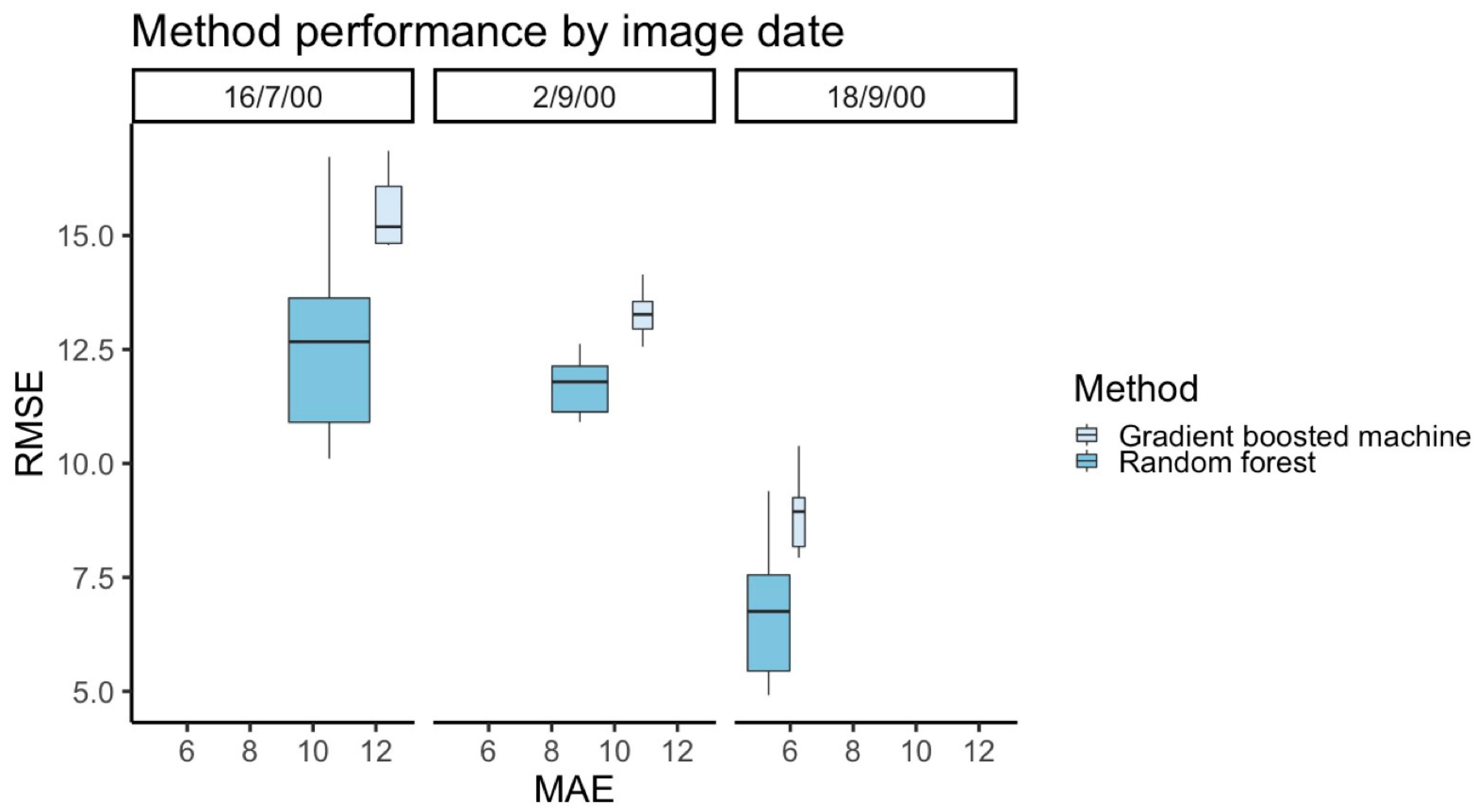
The spatial gradient boosted machine and random forest methods produce fast and accurate predictions (overall accuracy between 0.63 and 0.90) of pixel class over entire images for both the observed and missing pixels. Overall, random forest had higher accuracy for performing binary classification of pixels and predicting FPC values than gradient boosted machine without an increase in computation time. Of the decision tree models, we would recommend using the random forest rather than gradient boosted machine for binary image classification and continuous variable prediction tasks. Random forest also had consistently higher accuracy for performing prediction of continuous FPC values than inverse distance weighted interpolation across all images, cloud patterns, and pixels classes. This held true for both prediction of continuous FPC values and binary classification of pixels as grassland or woodland. Inverse distance weighted interpolation had consistently higher accuracy than gradient boosted machine for predicting continuous FPC. Overall, random forest was the most accurate of the three methods for binary classification and FPC prediction.
This accurate binary classification was achieved by converting continuous FPC values into binary classes from the outset, and then using the decision tree methods to predict a binary classification. Changing that order by predicting continuous FPC using the methods and then converting to a binary classification was substantially less accurate for both decision tree methods. This loss of accuracy was worse for the gradient boosted machine. We recommend transforming from a continuous value to binary classification prior to analysis and training the methods on the binary classification problem rather than converting continuous predictions to binary classifications after initial analysis.
The binary land cover classification that we performed in the case study show the methods perform well in a simple case, however land cover maps are usually more detailed and extensive in terms of number of categories and the scale e.g., detailed classifications at state or country level. In future work, it would be of interest to explore how the methods perform in a scenario with more land cover classes, particularly because the methods perform well at the more complex task of predicting continuous data.
Counterintuitively, the accuracy of image classification was not impacted by size of the clouds; we did not identify a clear pattern where the models identified pixels in the small cloud pattern more accurately than the large cloud pattern. Rather, the land cover heterogeneity seemed to influence model performance more than the pattern of the simulated clouds. The gradient boosted machine and random forest both had highest accuracy for binary classification when identifying missing pixels in the 18 September 2000 image, which had more grassland. Overall, random forest had higher accuracy for performing binary classification of pixels than gradient boosted machine.
While there are many benefits to the decision tree methods, as with any statistical method it is important to be aware of and address issues, such as overfitting and bias/variance tradeoff. It is noted that the boosting and bagging aspects of the gradient boosted machine and random forest algorithms that were adopted in this paper are designed to address these issues [
34,
38]. In our analyses, the decision tree methods were demonstrated to achieve high accuracy for both training and test data, indicating good fit and an acceptable bias/variance balance. This engenders confidence in the ability of the models to adequately predict missing data that were generated by cloud cover in the case study.
Another issue is training and testing sample selection for both observed and missing pixels. If there is a class imbalance in the image, such as more grassland in the missing pixel region and the randomly selected training set includes mostly or only woodland pixels, the trained method might be more likely to incorrectly classify the test set as woodland. A potential solution could be to select a training set deliberately from a region of the image with a combination of the classes you want to predict, however this may also introduce bias to the model. In this study, we simulated the clouds so knew what the true classifications were in the image, however this will not be so in real cases of missing data due to cloud cover. In cases where there is a class imbalance in the image and the methods produce inaccurate results due to lack of balanced training data, while using the composite approach for interpolation may be more appropriate.
In the case where large amounts of spectral data are missing from images over long periods of time, such as most of the year in the tropics [
12], the use of our methods can provide fast results to a level of accuracy that can be practically useful for informing decisions, even with a more heterogenous landscape (minimum 0.60 overall accuracy for binary classification) or highly accurate results for images with a higher prevalence of one class (up to 0.90 overall accuracy). Of course, there is error that is associated with model derived estimates, so confidence intervals should be considered and any additional available data or local knowledge when interpreting the results.
In this scenario, because we simulated missing data, we were able to validate the predictions that the methods produced, because we had the “true” value of the pixels. However, in the case where the true values of the pixels are unknown, this will not be possible for the testing data which are being classified. This is not an argument against using statistical methods to interpolate missing values when the data are truly missing. Rather, it is a caution to keep in mind that there will be uncertainty regarding the land cover classifications, as there is in any model, and hence to consider the confidence intervals around the model predictions.
Our application of these methods was motivated by considering what agencies and developing countries can achieve with a minimum core set of free resources to perform analyses in operational programs to gain insights into their environment and contribute to monitoring environmental SDGs. We describe three core free resources to monitor environmental SDGs. First, free satellite images and satellite image derived data products. These images can be downloaded for free from a number of sources, including CEOS Data Cube products [
8] and the USGS Global Visualization Viewer [
9], or Google earth engine [
48]. These are only a selection of products currently available, and many more resources are being produced and shared over time. Second, free open source software products with online resources and communities can be used to produce estimates of the SDGs, and indeed other statistics. Here, we used R software [
49]. Third, spatial information (i.e., latitude and longitude) can be extracted from any satellite image at no cost using code in open source software. The latitude and longitude of an image will remain intact, regardless of whether the spectral information associated with those pixels exists. Through our case study, we have shown by using these three free resources, measuring selected SDGs which are observable directly or by proxy from satellite images as accurately is possible, which offers opportunities to measure SDGs effectively, even in regions where missing data due to cloud cover or limited available infrastructure or funding to collect data are issues.
Our intention in describing and demonstrating the use of these free resources is not to prescribe the best practice or most accurate resources and methods for measuring SDGs or to dismiss directly collected data or more complex methods. Rather, the intention is to provide a streamlined path to monitoring SDGs in a tangible and fast manner, while still providing reasonable accuracy. By using these three minimum resources, this is achievable. Although the inclusion of auxiliary variables was not explored in this study, it is noted that as with any statistical model including informative covariates will improve the classification accuracy of the proposed methods. Here, we have presented the minimum core resources to measure selected environmental SDGs while only using free resources and streamlined methods.
Here, we explored the use of latitude and longitude as covariates in decision tree methods to classify pixels into different types of land cover as relevant to environmental SDG 15 life on land; specifically forest cover monitoring and deforestation detection [
6]. We focused on this SDG in our approach, and our methods are specifically useful for contributing to:
SDG Indicator 15.1.1 Forest area as a proportion of total land area; and,
SDG indicator 15.3.1 Proportion of land that is degraded over total land area.
These methods may aid in the monitoring of different SDGs which are also measurable from satellite images, such as identifying bodies of water, level of sediment in water sources, presence of crop land, and other environmental features. Further investigation could also be done into the application of these spatial methods to predicting satellite image spectral band values directly, rather than products that are derived from the spectral band values, such as FPC.
5. Conclusions
The Sustainable Development Goals (SDGs) are important indicators of quality of human life and the environment, which are a priority for countries to progress towards meeting by 2030. Some key barriers to monitoring the SDGs include the cost of acquiring and collecting data, lack of infrastructure, and required skills within countries and organisations to produce statistics from satellite imagery data [
10]. Satellite imagery is a useful, freely available data source that can directly contribute to monitoring and measuring the SDGs [
2,
4,
5] and it addresses the issue of cost of data acquisition. However, missing data due to cloud cover and ways to fill in these gaps as effectively as possible are issues with these images, especially in tropical regions of the world.
We have presented two fast and accurate spatial machine learning methods that meet the need for effective ways to fill gaps in images due to missing data, and produce statistics to monitor indicators of SDG 15; life on land, related to forest management. The results showed our random forest method was more accurate than inverse distance weighted interpolation for predicting Foliage Projective Cover (FPC) for missing and observed data across all images in the study. Our methods are implemented in free software, performing binary classification of both observed and missing pixels into vegetation classes; woodland and grassland, and predicting continuous FPC values. These accurate classifications are possible using only latitude and longitude of the pixels as covariates, which can be extracted from any satellite image, regardless of cloud cover. We have provided some general rules of thumb for when our approach would be most useful, and recognise cases when an alternative, such as the traditional compositing approach, may be more suitable for filling in image gaps due to limitations of our approach.
Our methods are effective for contributing to SDG 15 related to forest management, and importantly could also be applied to other environmental SDGs identifiable in satellite images, such as SDG 6: Clean sanitation and water through water quality and water extent, and SDG 2: end hunger by identifying crop type and crop area. By using these methods and the core set of minimum free resources, we describe satellite images, software, methods, and spatial information; it is possible for other users and countries to effectively monitor and model environmental SDGs, importantly at low cost in terms of finances, infrastructure, and experience working with satellite imagery data.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}