1. Introduction
Synthetic aperture radar (SAR) is a prominent technology for acquiring terrain information, which can provide high-resolution images in all weather conditions, independent of day and night. Polarimetric SAR (PolSAR), in addition to the characteristics mentioned above, is able to use the backscattering of polarization waves from objects to form images. In recent years, research on PolSAR has attracted wide interest in the field of remote sensing, and applications of PolSAR images have gradually increased, such as crop classification [
1], ship detection [
2], and change detection [
3]. PolSAR image classification assigns a specific ground category to each pixel. Broadly, classification methods of PolSAR images can be divided into the categories listed below.
Many frequently used classification methods are based on target decomposition, such as Pauli decomposition [
4], entropy/alpha (H/α) decomposition [
5], Freeman decomposition [
6] and Yamaguchi decomposition [
7]. Target decompositions provide sound theories, so they have been widely studied [
8,
9]. Furthermore, the statistical distribution of PolSAR data is used for classifying PolSAR images. It is known that both the covariance matrix and the coherence matrix of each pixel in homogeneous areas have a complex Wishart distribution. Li Zhong Sen et al. [
10] proposed a method based on the Wishart distance for PolSAR image classification. Since then, the Wishart distance and its variants have become the choice for measuring similarities among pixels in many studies [
11,
12].
The above two methods are generally performed as an unsupervised classification. However, results of these methods are usually rough because they cannot distinguish different kinds of regions with similar characteristics well, or the same kind of region with certain different characteristics, so more guide information is needed to perform better classification. Supervised learning has recently become mainstream in PolSAR classification. It requires training samples with complete labels, thus further improving the classification accuracy.
Traditional supervised machine learning, which does not include deep learning, is frequently involved in PolSAR classification. One popular machine learning model is the support vector machine (SVM) [
13], which has been proved to be effective in the field of artificial intelligence and pattern recognition. In addition, ensemble learning such as random forest [
14] is also utilized. In 2006, Hinton et al. [
15] proposed an epoch-making work on deep belief networks (DBN). In 2012, Krizhevsky et al. [
16] applied a convolutional neural network (CNN) for ImageNet classification and achieved eminent results. Since then, deep learning has been accepted as a popular technique, the main advantage of which is automatic and hierarchical feature extraction. As one of the deep learning models, sparse auto-encoders (SAEs) have been successfully applied to PolSAR classification [
17,
18,
19,
20]. However, these methods process each pixel in isolation and utilize a small number of training samples, severely suffering from speckle noise and over-fitting. Although supervised methods can effectively improve the classification accuracy, the demand for robust feature representation and a large number of labeled samples remains to be solved.
Semi-supervised learning has been increasingly introduced into the field of remote sensing [
21,
22,
23] in order to alleviate the problems mentioned above. Semi-supervised classification utilizes unlabeled samples to expand training sets, which greatly contributes towards overcoming over-fitting and achieving a better classification accuracy. In general, semi-supervised classification can be divided into five categories, including generation models [
24], self-training models [
25], co-training models [
26], tranductive SVMs [
27], and graph-based models [
28]. Among all the semi-supervised models, the self-training model, the co-training model and the graph-based model are the most frequently used in PolSAR classification. A semi-supervised PolSAR classification method based on improved co-training has been proposed in the literature [
26]. Two sufficient and conditionally independent views were constructed for the co-training process based on features of PolSAR images, and a novel sample selection strategy for selecting reliable unlabeled samples is used to update this process. The algorithm achieves acceptable classification accuracy with limited labeled samples. Recently, the good performance of graph-based semi-supervised models has been proved in PolSAR classification. In [
28], the authors constructed a spatial-anchor graph to implement sparse representation of the feature space, and propagated category labels on the edge of the graph based on similarities of nodes of labeled samples and unlabeled samples to implement semi-supervised classification.
For graph-based semi-supervised classification, the construction of the graph is fairly complex, and label propagations rely on the inversion of a large matrix, which limits their application for remote sensing applications [
29]. As for co-training models, it is difficult to obtain sufficient and conditionally independent views. Semi-supervised learning based on self-training is promising. The idea is simple and efficient. Usually, a classifier, for example, a machine learning model or a deep learning model, is initialized first. Then unlabeled samples are selected to add to the training set according to similarities with neighboring labeled training samples. The classifier updates itself with the expanded training set to improve the classification accuracy. The key for self-training is to formulate an unlabeled sample selection strategy that can contribute to the training process.
In [
25], the authors proposed a superpixel restrained deep neural network with multiple decisions (SRDNN-MD). The proposed semi-supervised unlabeled sample selection strategy named multiple decisions (MD) include nonlocal decisions and local decisions. The nonlocal decision sets each label the training sample as the center of the nonlocal region. Then, similarities are determined jointly by the cosine distance, and the output prediction probability of the deep neural network is measured to select the most similar unlabeled sample. As for the local decision, each unlabeled sample is set as the center of a local region. Similarities between labeled training samples located in the local region and the unlabeled sample are measured by the spatial distance and the output prediction probability of the deep neural network. Finally, unlabeled samples are labeled as the same class as training samples according to similarities measured by nonlocal and local decisions. In addition, SRDNN-MD designs a superpixel-restrained term for the deep neural network to enhance the homogeneous characters of the same superpixel and reduce the impacts of the speckle noise. Another study [
29] proposed a bagging ensemble-based self-training method. In this method, when both the reliability and diversity of the selected samples are taken into account, the initial classifier should find samples that do not necessarily have the highest prediction probability. Two search strategies to select candidate unlabeled samples are considered and evaluated. One is to limit the search neighborhood around all labeled samples. The other is to set the search neighborhood around labeled samples of a particular category. Then, search areas of these two strategies iteratively grow until the entire image is covered.
This paper proposes a novel semi-supervised PolSAR classification method based on self-training and superpixels. One important motivation of this work is the similarity and continuity inside each superpixel. First, the RGB PolSAR image that is formed by Pauli decomposition is over-segmented into superpixels by the simple linear iterative clustering (SLIC) algorithm [
30]. Then, we extract features of each pixel from its coherence matrix. To mitigate the effects of speckle noise, features of each pixel are re-represented using spatial weighting with its neighboring pixels in the same superpixel. Next, we propose a semi-supervised unlabeled sample selection method for expanding training sets. Label propagations for unlabeled samples can be guided well by our strategy. Finally, a self-training stacked sparse auto-encoder (SSAE) network iteratively updates itself with the expanded training set and generates the global classification map of the PolSAR image. In contrast to SRDNN-MD, which only selects the most reliable samples according to similarity metrics computed by local and nonlocal decisions, the proposed sample selection procedure ensures both the reliability and diversity of the selected unlabeled samples and makes the most of the similarity and continuity inside each superpixel to save required computations. The proposed procedure is also more concise than the procedure in [
29] because we do not need to grow the search region for unlabeled sample selections iteratively. Each superpixel is utilized only once to select samples. Moreover, we choose a single strong classifier rather than multiple weak classifiers to perform the PolSAR classification. Several groups of experiments were implemented on two representative PolSAR datasets and we obtained impressive results on the proposed self-training-based semi-supervised PolSAR classification.
The remainder of this paper is organized as follows.
Section 2 introduces components and the whole framework of the algorithm.
Section 3 compares the proposed algorithm with some existing PolSAR classification algorithms on two datasets to verify its effectiveness.
Section 4 discusses the parameter choices and experimental results in
Section 3.
Section 5 summarizes the full text and proposes further work to be studied in the future.
2. Methodology
2.1. Superpixel Segmentation
As an important branch in the field of segmentation, superpixels were first proposed by Ren et al. in 2003 [
31]. They were originally designed as preprocessing for optical images. Superpixels over-segment the image into homogeneous pixel blocks with adjacent positions and similar features. In recent years, it has become a promising technology in PolSAR image classification [
32,
33]. It is known that pixels within the same superpixel may share the same category to some extent, which may simplify the subsequent steps of the classification tasks.
The SLIC [
30] algorithm is utilized to generate superpixels in this paper. Compared with other algorithms [
34,
35,
36], SLIC generates regular superpixels with high boundary adherence and it implements them much more rapidly, using simple and efficient modified k-means clustering. Centers and their neighboring pixels in each superpixel are alternately updated according to a distance measure. Suppose [
,
,
,
,
] and [
,
,
,
,
] are vectors of two pixels.
L, A and
B are the luminance component and two color components of the LAB color space, respectively.
X and
Y are spatial coordinates. Then the distance measure
between two pixels is calculated as:
where
where
and
are the LAB color distance and the spatial distance of the two pixels, respectively.
m is the constant parameter that weighs the importance of
and
.
r is the pixel interval for producing roughly equally-sized superpixels.
, where
is the number of image pixels and
n is the number of superpixels. The steps of the SLIC algorithm are summarized below.
| Algorithm 1: SLIC |
| Input: The RGB PolSAR image, the number of superpixels n, threshold e. |
1: Evenly initialize n cluster centers by sampling pixels with interval r. Then cluster centers are moved to seed locations where the lowest gradient meets in a 3×3 neighborhood.
do: |
| 2: Search pixels in a 2r×2r region around each cluster center and calculate the distance measure from each searched pixel to the cluster center using (1), (2) and (3). |
| 3: Assign searched pixels to superpixels that involve the nearest cluster center. |
4: Calculate the average vector of each superpixel as the new cluster center.
5: Compute the residual error between the new cluster center and the previous cluster center using L2 norm.
while the residual error > e |
6: Check the number of pixels in each superpixel. If it is less than n/4, merge this superpixel with its adjacent one.
Output: The over-segmented PolSAR image with around n superpixels. |
2.2. Feature Representation of PolSAR Images
According to the polarizations of transmitted and received waves, the PolSAR system works in four polarization modes: HH, VV, HV, VH. The polarization scattering matrix
is used to represent the scattering characteristics of each pixel, which contain all the information about the target.
Each scattering parameter in the
matrix is a complex number. The scattering matrix is decomposed into a complex weighted sum of Pauli matrices, which is called Pauli decomposition. In the case of reciprocal backscattering
, the scattering matrix can be expressed as:
where
In this paper, the RGB image is formed by Pauli decomposition, whose three channels are
,
and
. The complex polarization vector is
. If the PolSAR data are multi-look processed for speckle reduction, the coherence matrix, which can also represent a pixel, is obtained as follows:
where
indicates the
th sample of vector
, the symbol
* indicates the complex conjugate, and
is the number of looks.
In addition, polarimetric characteristics can be extracted through target decomposition theories that reveal the invariance of polarization characteristics of the target under different wave polarization bases [
8]. The Yamaguchi decomposition [
7] theorem decomposes
T into four scattering powers, named as the volume scattering (
), the double-bounce scattering (
), the surface scattering (
) and the helix scattering (
), respectively. In this paper, each pixel is represented by a 10-dimension feature vector that is made up of components of
T and the Yamaguchi decomposition:
In order to mitigate the effects of speckle noise on the classification map, the spatial weighting method is utilized in our approach. For a specific pixel
p whose feature vector is
, we randomly choose
pixels that are in the same superpixel as pixel
p. If we suppose that features of these neighboring pixels are
, then the spatial weighting feature can be obtained as follows:
It is worth noting that the size of each superpixel may vary within certain ranges, so it is important to find a reasonable number of neighboring pixels
, which will be further discussed in the experiment section.
2.3. Semi-Supervised Unlabeled Sample Selection Based on Superpixels
As mentioned in
Section 1, in practical applications, to obtain a large number of labeled samples is time-consuming and labor-intensive. In PolSAR classification, because high resolution PolSAR images are usually obtained from a few national key laboratories with specific PolSAR sensor systems, and many experts are required to collect and label the original image, labeled data is even less, which limits the classification accuracy and generalization ability of models. Semi-supervised learning provides a compromise for this problem. It detaches the whole learning process from an interaction with the outside world and automatically uses unlabeled samples to improve the learning performance.
To take advantage of unlabeled samples, one motivation for our work is the "cluster assumption", that is, samples of the same cluster have a high probability of belonging to the same category. In this paper, superpixel segmentation is implemented to over-segment the image into many homogeneous clusters, so we utilize spatial relations obtained from superpixels along with prediction probabilities obtained from the classifier to propagate labels from labeled samples to unlabeled samples.
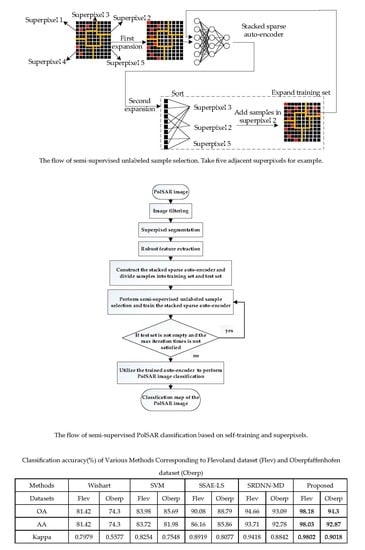
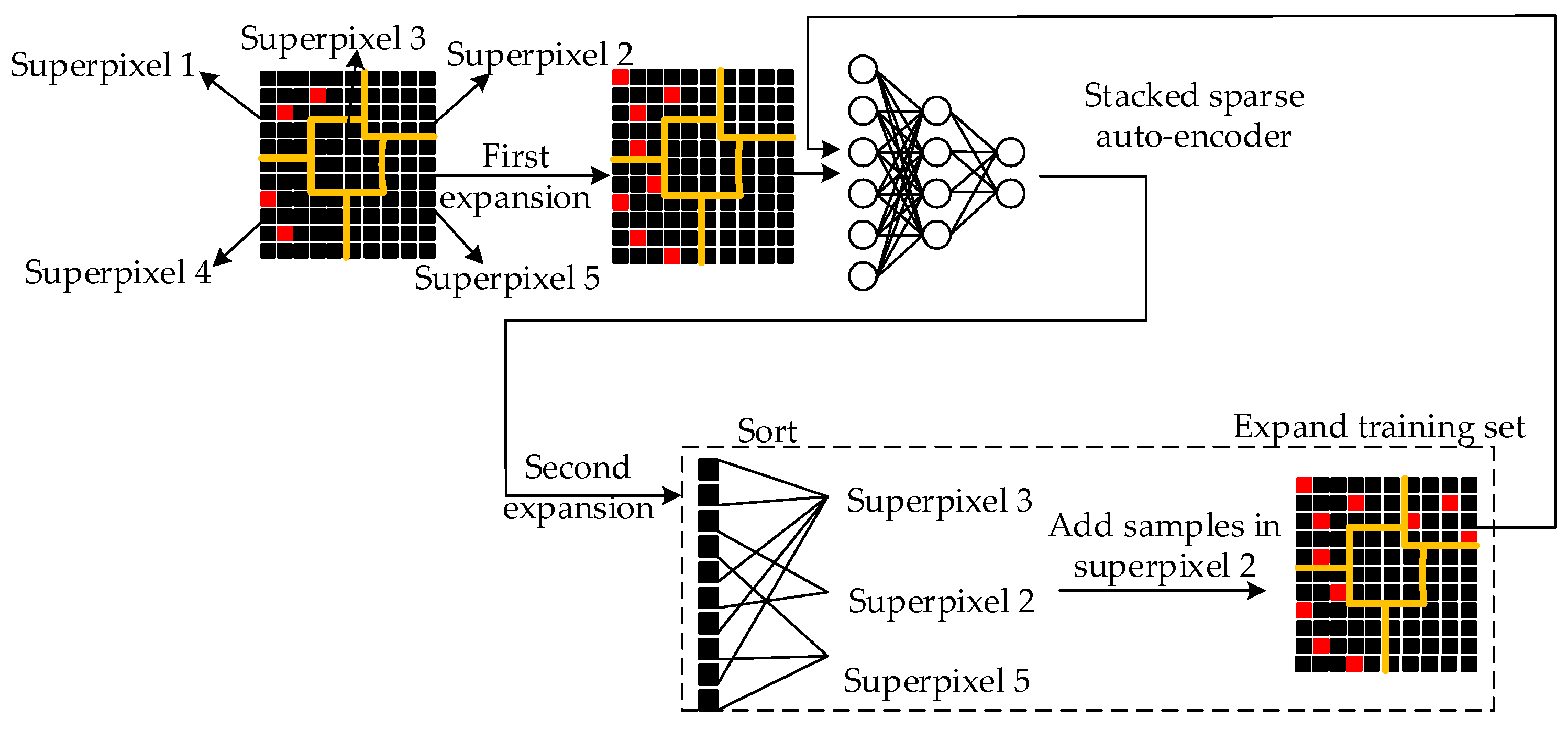
The method is illustrated in
Figure 1. In detail, the accurately-labeled sample set of the PolSAR image should be obtained first. Then we randomly select a certain number of pixels from each class to form the initial training set
, which is expressed as
, where
involves labeled training samples belonging to the
th class,
,
N is the number of categories of the PolSAR image. Remaining pixels in the PolSAR image are added to the candidate unlabeled sample set
and the test set
identically.
is utilized to expand the training set, and
is utilized to evaluate the classification performance.
Next, two expansions on the training set are performed in sequence. The first expansion is implemented as follows for each class:
For each sample in belonging to class , assuming that the sample is located in the superpixel , randomly select unlabeled pixels in and take as the label of these pixels. Then add samples in and selected pixels in to a new training set, named , where t indicates iteration times.
All pixels in are removed from , which indicates that superpixel has been traversed.
Input the training set into the classifier and train it for the first time. Then the classifier makes predictions on . Assuming that , where indicates the set of samples with prediction , where , the output probability of the classifier that corresponds to the predicted class is considered as the prediction confidence of each candidate unlabeled sample in . Next, we perform the second expansion on with the following steps for each class:
For all samples in predicted as class , sort their prediction confidence from high to low. Select unlabeled samples with the highest confidence and combine them into a set, named .
For each sample of , record the superpixel in which it falls. Count the number of samples that fall in different superpixels. The superpixel with the minimum number of samples is selected, which is recorded as .
Randomly select samples in , and take as the label of these samples. Add them to the training set and remove all pixels in from , which indicates that superpixel has been traversed.
Afterwards, we perform the second expansion on the training set iteratively and train the classifier iteratively. The process may finish by following two conditions. One is that the unlabeled sample set becomes empty so that the training set fails to expand. The other is to set the maximum iteration time as .
The proposed semi-supervised unlabeled sample selection method ensures both the reliability and diversity of the selected unlabeled samples. On the one hand, each superpixel is only traversed once to select unlabeled samples. The remaining candidate samples in the same superpixel are removed from . We choose the most representative samples, which can enhance the reliability and diversity of unlabeled sample selection and accelerate the training process.
On the other hand, the procedure of two expansions on the training set also balances the reliability and diversity of the selected unlabeled samples. In the first expansion, we use the "clustering assumption" to directly propagate labels to samples in the same superpixel. In the second expansion, we first obtain candidate samples from whose prediction confidences range from 1 to . Their confidences are high enough to guarantee the reliability. Then, we choose the superpixel that contains the minimum number of samples, which means samples within this superpixel are of great diversity. Therefore, these samples have potential to improve the classification performance.
In summary, the semi-supervised unlabeled sample selection method based on superpixels provides a novel and effective strategy for expanding training sets with unlabeled samples of great reliability and diversity, which fully utilizes the results of superpixel segmentation and the potential of semi-supervised learning.
2.4. Self-Training SSAEs
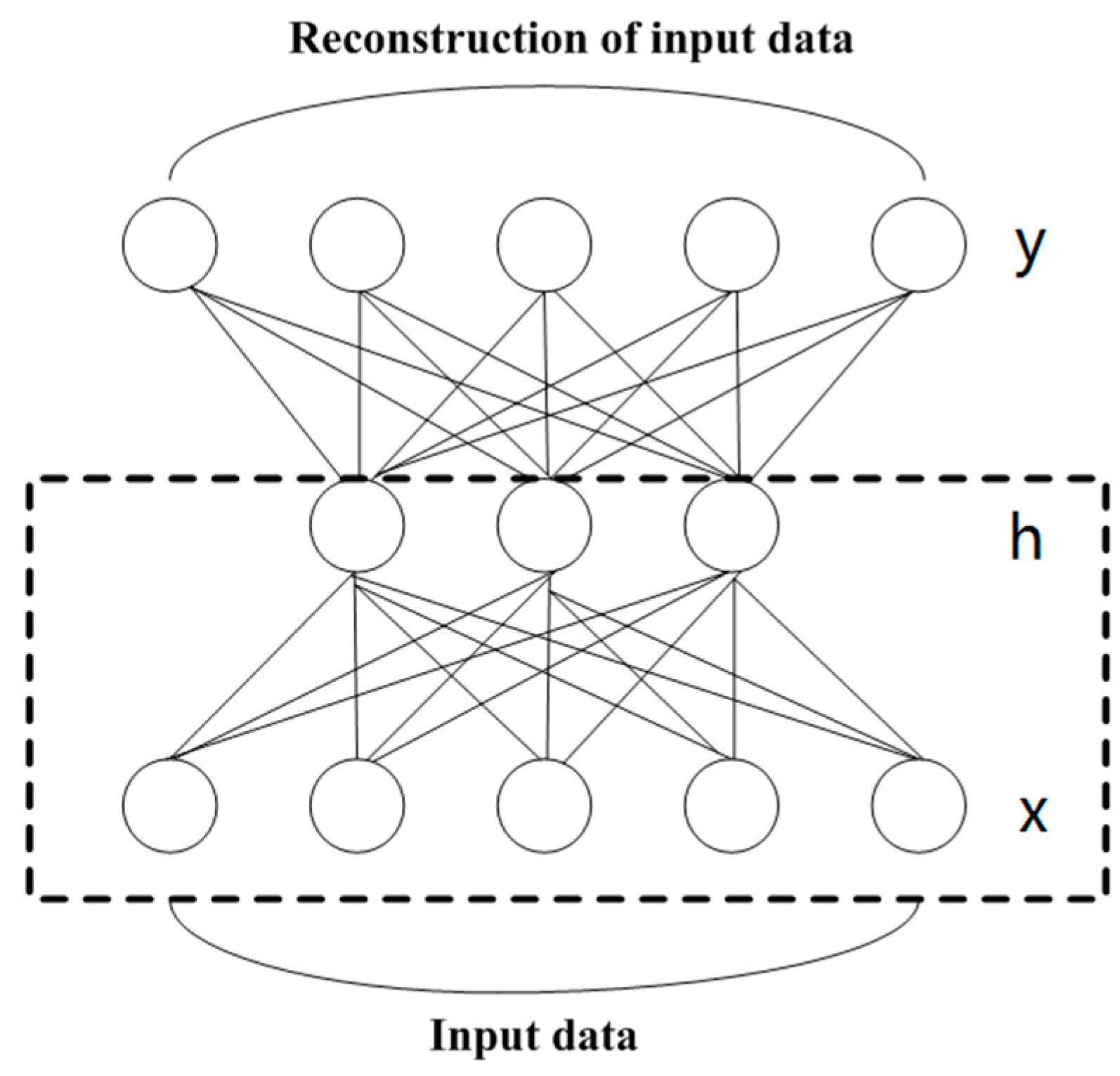
In is paper, we choose SSAE as the self-training classifier. Many characters of SSAE are adapted to PolSAR classification. It automatically generates low dimensional hidden-layer feature representations for each input pixel, which is suitable for pixel classification of PolSAR images. SSAEs are generally shallow networks with a small number of parameters, so that it protects the training from over-fitting. The training of SSAE includes unsupervised layer-by-layer greedy training and supervised fine-tuning.
Figure 2 shows the structure of an SAE composed of an input layer, a hidden layer and a reconstruction layer. The number of neurons in the input layer and the reconstruction layer are the same. The data at the second layer is the hidden feature vector learned by the SAE. If there is a sample
x, the hidden expression
h can be obtained as follows:
Later, the
h is decoded according to the formula given by (11) and the reconstruction
y is obtained:
where
W and
b are the weight matrix and bias vector, respectively.
f(
) and
g(
) are activation functions. The corresponding error function minimizing the difference between
x and
y is given by:
In order to get a compressed representation of
, we must perform a sparse restriction on the hidden layer. According to (13), the mean squared-error function of the SAE can be obtained as:
where
M is the number of samples,
is the sparse parameter,
is the average activation of the
jth hidden neuron and
h is the number of the hidden neurons. The KL divergence can be expressed as follows:
when the above error function (13) is at its minimum, the data of the hidden layer becomes an excellent feature of input sample
x.
When performing layer-by-layer greedy training for SSAE with several hidden layers, the feature vector of the first hidden layer is learned at first, then it is input into the next hidden layer. The process is repeated several times until all layers are trained. Next, a soft-max classifier is applied to produce the prediction probability distributions. The soft-max classifier is expressed as follows:
where
is a trainable parameter, and
q is the number of classes. When performing fine-tuning, the parameters of SSAEs are adjusted by the back propagation (BP) algorithm. Then, the trained network can be used for prediction and classification. The loss function is the cross entropy given by:
where, 1{
} is the indicator function.
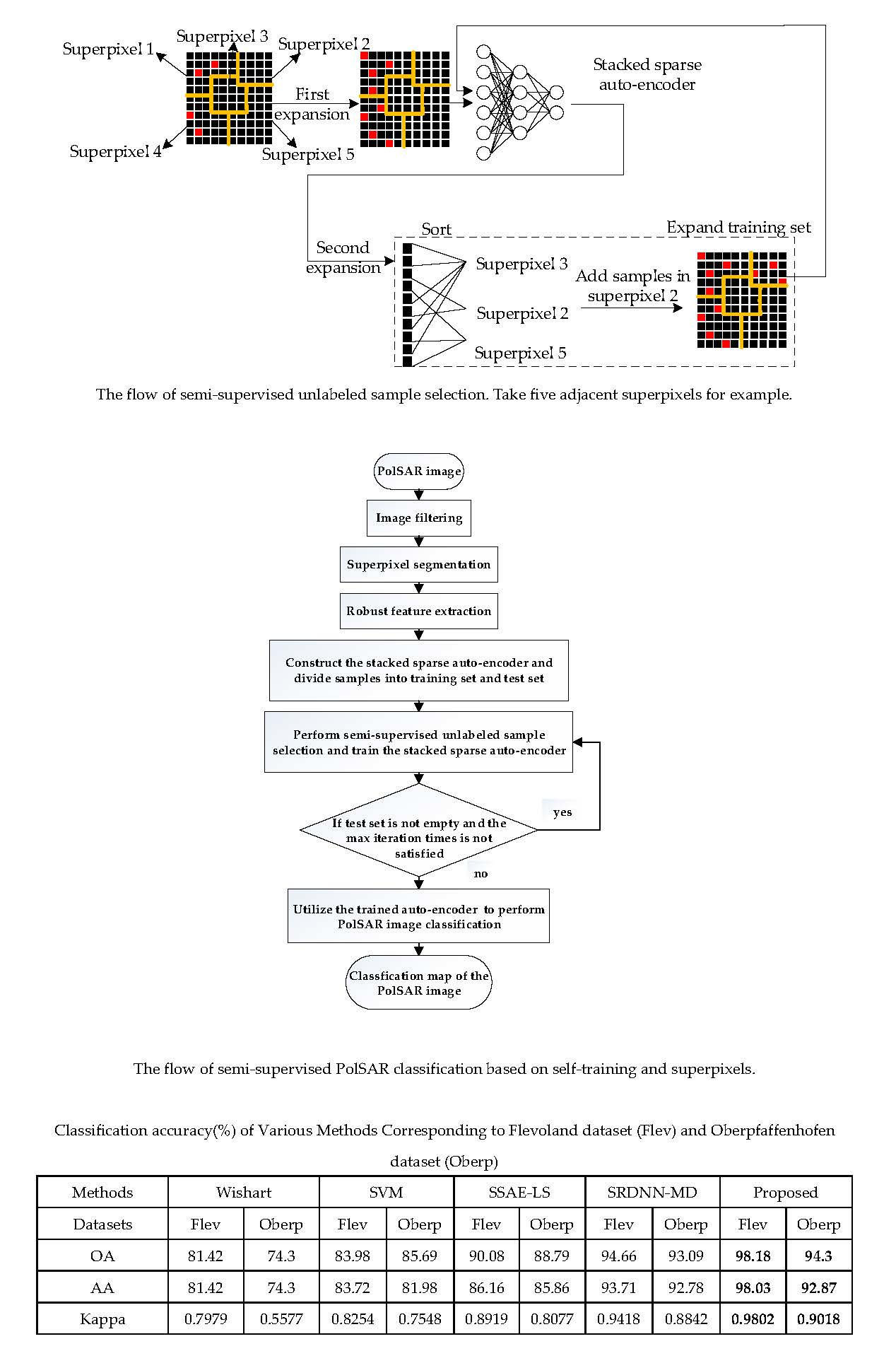
2.5. Procedure of the Proposed Algorithm
As described above, the proposed semi-supervised PolSAR classification algorithm firstly constructs a real feature vector that suppresses the speckle noise of each pixel based on the superpixel segmentation result. Then, an SSAE is trained with a few training samples. A series of superpixel-inspired methods are utilized to iteratively select reliable unlabeled samples according to their prediction confidences, using our two expansions on the training set. The classifier has already fitted those samples with high confidence well, so we take both the reliability and diversity of the samples into account. Next, the SSAE is iteratively self-trained using the expanded training set.
In summary, the description of the whole algorithm is given below.
| Algorithm 2: Semi-supervised PolSAR classification based on self-training and superpixels |
Input: The RGB PolSAR image.
1: The PolSAR image to be classified is filtered using the Lee refined filtering algorithm. |
| 2: Segment the Pauli RGB pseudo color image using the SLIC superpixel algorithm. |
| 3: Construct feature representation for each pixel in the PolSAR image. Calculate new feature representation that can suppress the speckle noise for each pixel p using spatial weighting. |
4: Prepare the initial training set , the candidate unlabeled sample set and the test set . Construct the self-training SSAE for classification. Set iteration times t = 0.
while is not empty and : |
| 5: Perform semi-supervised unlabeled sample selection and obtain the expanded training set . |
6: Use to train the SSAE.
end while |
7: Use to evaluate the classification performance of the method and utilize the trained auto-encoder to perform PolSAR image classification.
Output: The classification map of the PolSAR image. |
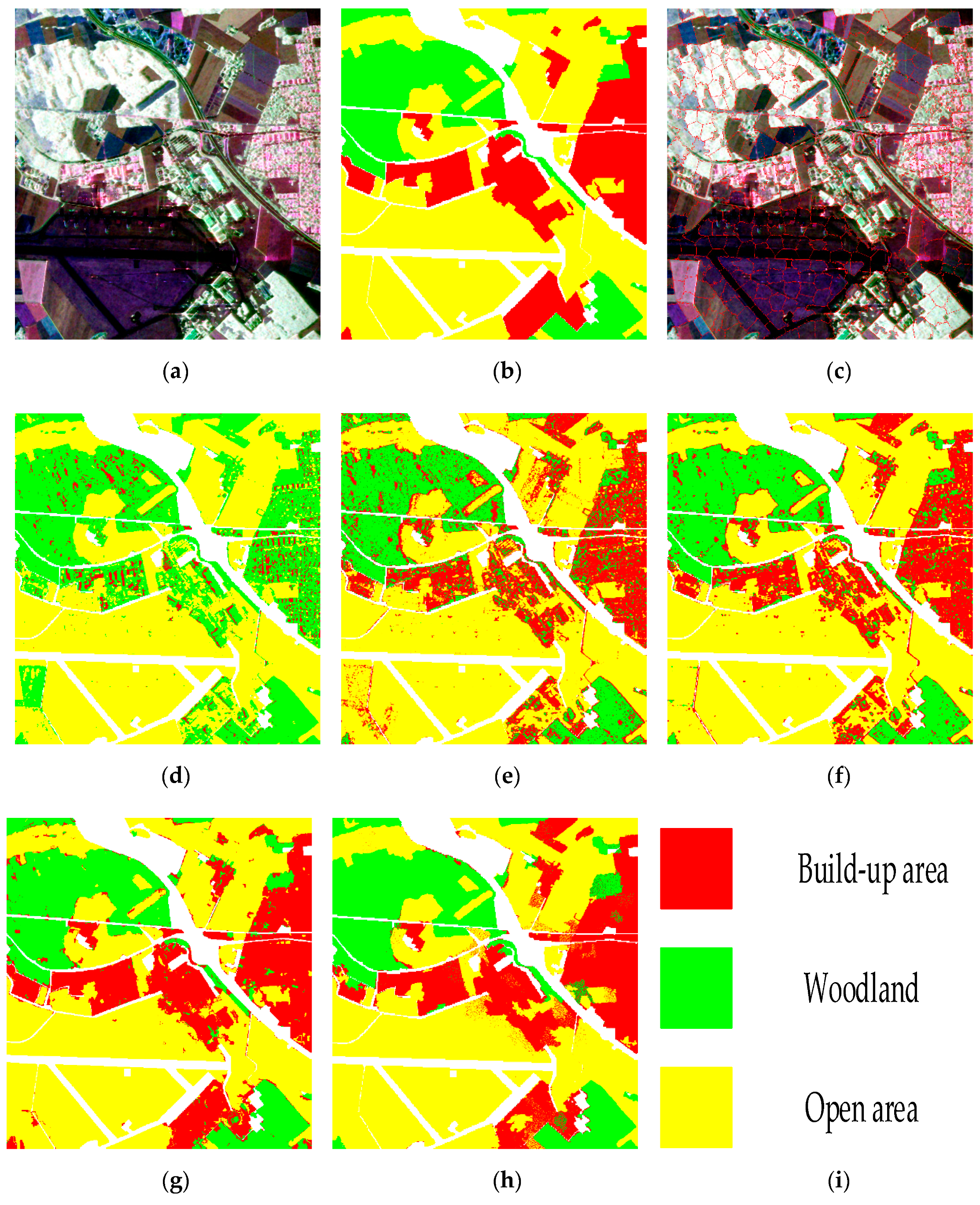
4. Discussion
4.1. Parameter Analysis
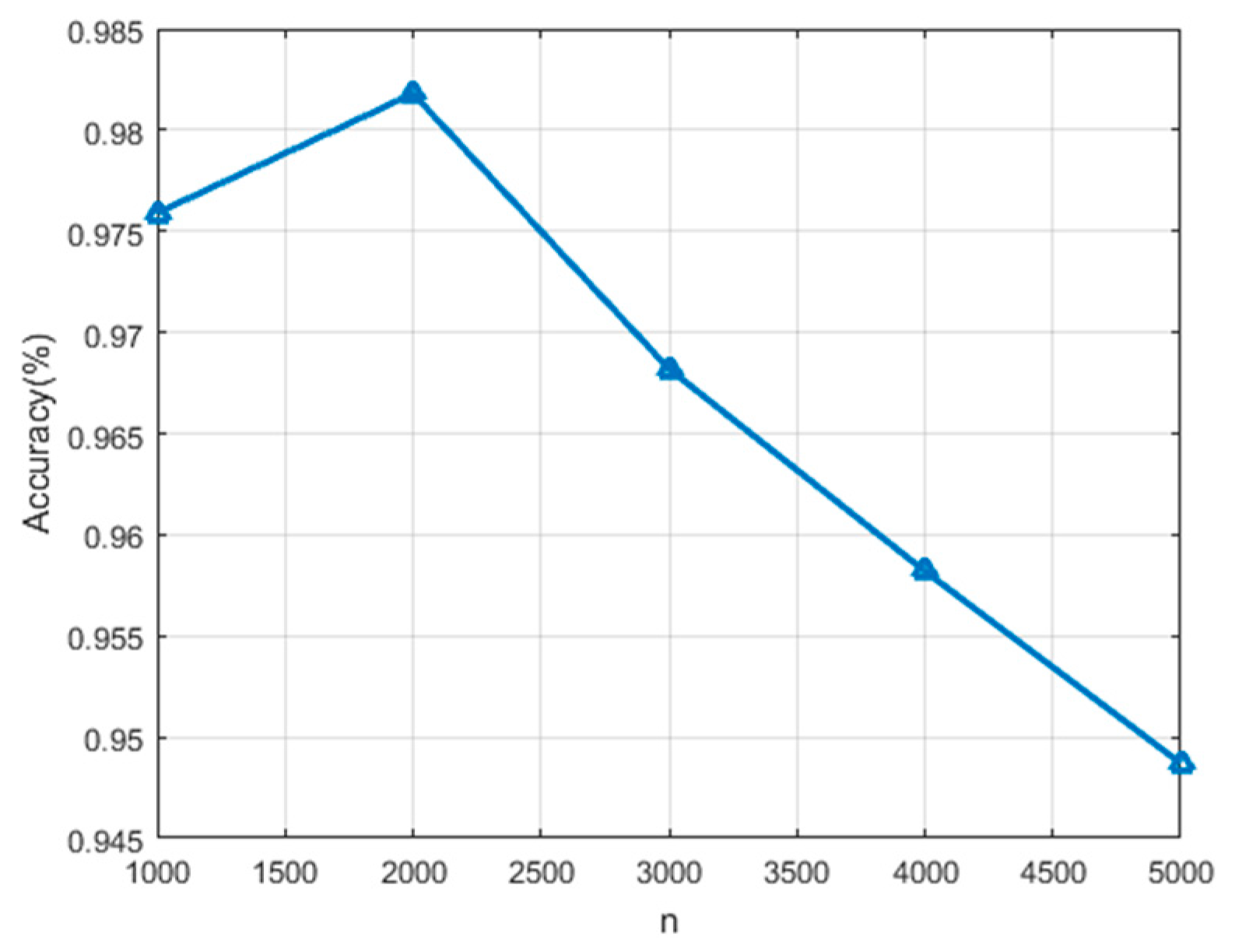
There are four significant parameters in the proposed algorithm, including the number of superpixels n, , and . We perform the following three group of experiments in this section to analyze the proper parameter choices, taking the classification of the Flevoland data as an example.
The first group of experiments discuss the effect of the number of superpixels on the classification performance. The discussed parameter
n ranges from 1000 to 5000, and the interval is 1000. Other parameters are kept unchanged in this discussion. The experiment results are shown in
Figure 5. The best classification accuracy is obtained when
n is set to 2000. We infer that if the parameter is too large, the number of pixels contained in each superpixel will reduce, which is not conducive to eliminating the speckle noise, and is not conducive to performing the proposed semi-supervised unlabeled sample selection method because the diversity of samples may be lost. In contrast, if the parameter is set too small, the number of pixels contained in each superpixel will increase, which is likely to propagate incorrect labels to the selected unlabeled samples, thus reducing the classification accuracy.
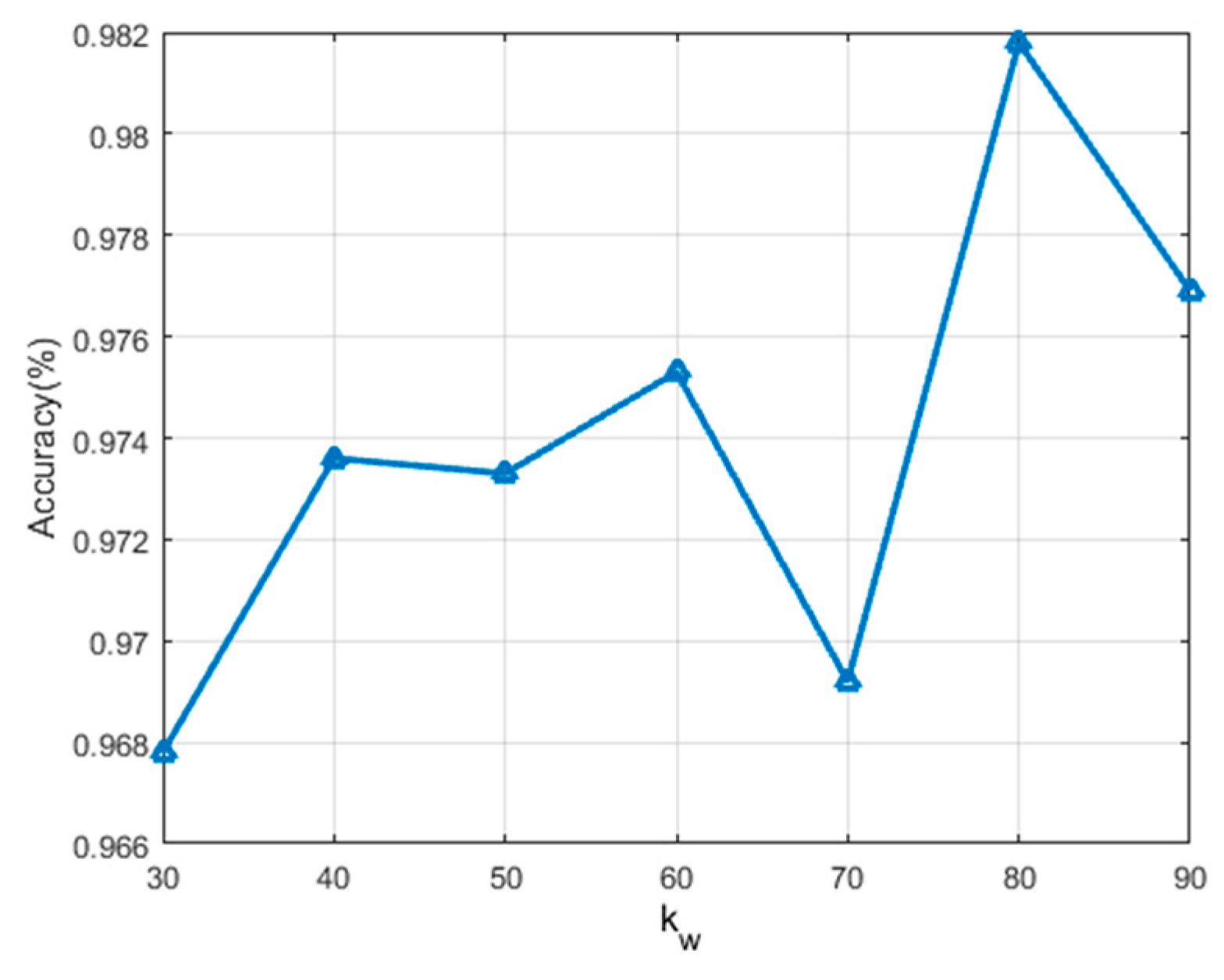
In addition, the effect of
on the classification performance is discussed in the second group of experiments.
is closely related to the robust feature representation that can effectively suppress the speckle noise in the neighborhood of each pixel. The experiment results are shown in
Figure 6. It can be seen that the fold line has multiple peaks, and the highest accuracy is obtained when
. We conclude that selecting a larger number of neighborhood pixels is more conducive to suppressing speckle noise and improving the classification performance. However,
is also limited by the minimum size of superpixels, so it cannot increase infinitely.
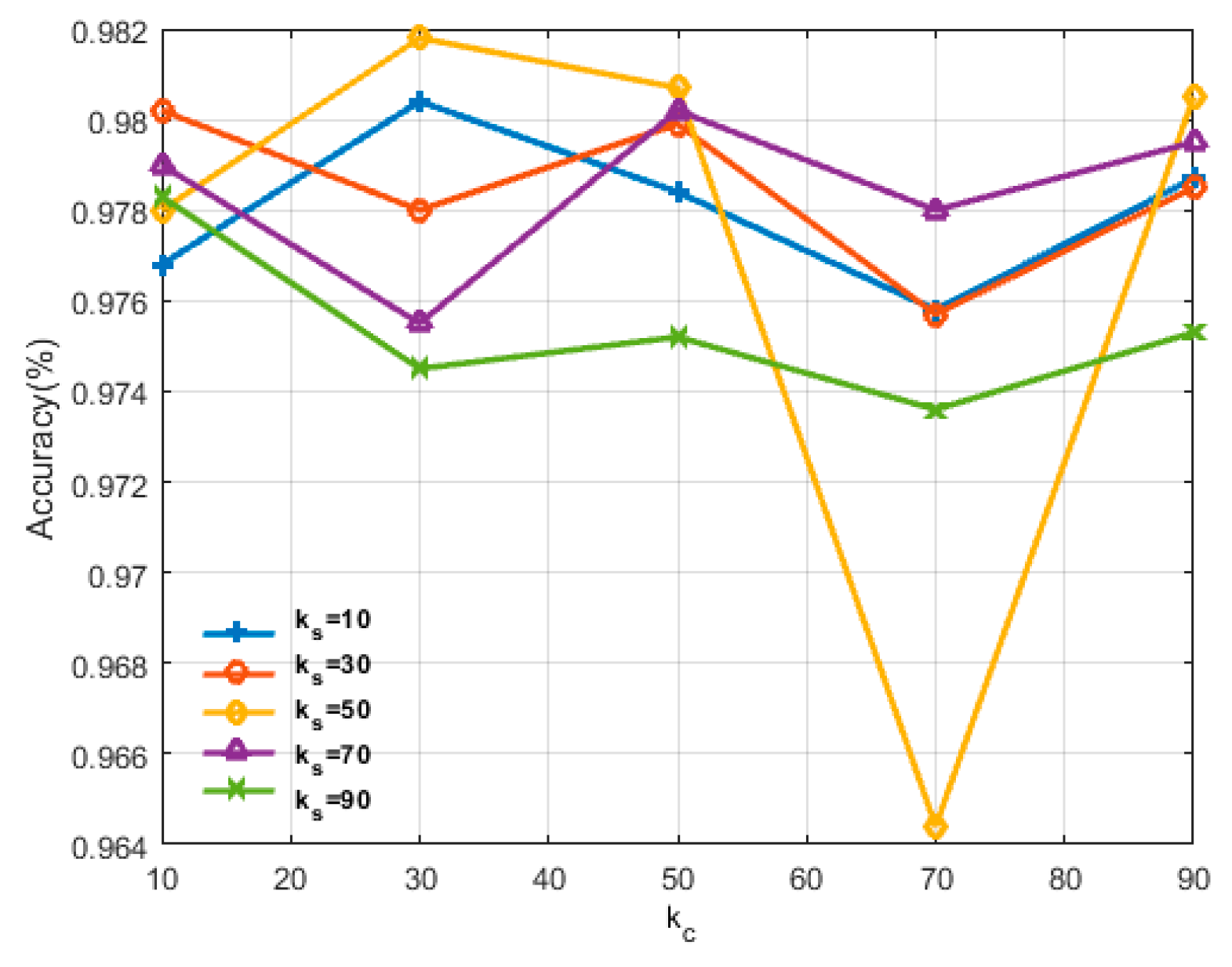
In the last group of experiments, we will discuss the effect of combinations of
and
used in the proposed semi-supervised unlabeled sample selection method.
controls the maximum number of selected unlabeled samples per class in each iteration, and
automatically controls the lower bound of the prediction confidence. We implemented the following experiments using a grid search. Each of the two parameters takes five values, which are 10, 30, 50, 70 and 90, respectively.
Figure 7 shows the experiment results. The abscissa represents
and the ordinate represents the classification accuracy.
Five fold lines that are marked with different shapes show effects of five different values of
in combination with
on the classification accuracy.
Figure 7 shows that
are the best choices for the proposed algorithm. It can also be inferred that two parameters mutually influence each other, as the variation in trends of all the lines is not always the same. On the one hand, the increment of
and
can increase the quantity and diversity of the selected samples, but on the other hand, it may import more uncertain information due to some inaccurately propagated labels. Thus, the values of
and
should be considered together and carefully selected.
To summarize, we over-segmented the Flevoland image into about 2000 homogeneous areas and used , by default for all experiments on the Flevoland dataset in this paper. With respect to the Oberpfaffenhofen data, we did the same parameter analysis as above. The number of superpixels n was set to 500 because there are larger homogeneous areas in the Oberpfaffenhofen image. The best choices of , and are 600, 30 and 80, respectively.
4.2. Performance Analysis
As mentioned in
Section 3.2 and
Section 3.3, the proposed algorithm obtains the best performance using the same sampling rate as the compared algorithms. We believe that this is due to the following reasons.
Wishart performs clustering according to the Wishart distance without any supervised information, which increases the possibility of misclassification. SVM is suitable for the classification of small samples, but it seems difficult for SVM to find the exact hyperplane when the number of categories increases. SSAE-LS is a typical supervised PolSAR classification algorithm that is greatly limited by the quantity and the quality of the training samples. It cannot recognize categories with few samples, such as buildings in the Flevoland dataset.
We also found that the two semi-supervised algorithms in this paper performed better, which may be because these algorithms can expand the training set by making full use of information from unlabeled samples. Nevertheless, there are obvious performance differences between them.
From our point of view, local and nonlocal similarity metrics used in SRDNN-MD may introduce some errors to unlabeled sample selection. Especially when regions of several categories with similar feature representations are close to each other, the edge of each category is affected by its neighboring categories. Pixels of two neighboring categories may locate in the same superpixel. The superpixel-restrained term introduced into the classifier in SRDNN-MD can enhance feature consistency within each superpixel, while it also brings confusing information of neighboring categories to the classifier. SRDNN-MD only has weak regional consistency between each category.
In contrast, the proposed algorithm selects unlabeled samples from the same superpixel that contains samples of great reliability and diversity so that the probability is greater than if they belong to the same category, which can reduce incorrect semi-supervised label propagations. This is helpful for the subsequent self-training process of the classifier. By innovatively proposing the semi-supervised unlabeled sample selection method based on superpixels, we effectively expand the training set and fully utilize the results of superpixel segmentation and the potential of semi-supervised learning. For these reasons, our method can obtain excellent classification results with a limited number of labeled training samples.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}