SAR-to-Optical Image Translation Based on Conditional Generative Adversarial Networks—Optimization, Opportunities and Limits



Abstract
:
1. Introduction
2. Related Work
3. Aspects of Interest
- Dynamic range of signal intensity, speckle statistics: SAR images are characterized by the strong variability of signal intensity. Hence, an important question to address is how to handle the high dynamic range of SAR image intensities and the presence of speckle.
- Freedom/fiction: In contrast to hand-crafted operators for image processing, deep learning-based approaches are difficult to steer. This opens ways to alternative and creative data representations but also to fiction. In terms of data interpretation, the impact is different when looking at full images or local details. Accordingly, it is important to classify the impact of fiction.
- Geometry: Areas considered for image translation are characterized by a variable mix of land cover types, e.g., urban, forests, fields, settlements. It is expected that the quality of translation results will not be equal but vary, too.
- Spatial resolution: Case studies should be conducted for variable spatial resolutions in order to see resulting effects at structural details (e.g., smoothing) and larger scales (e.g., speckle handling).
- Training: Compared to many machine learning tasks, the amount of accessible training data is limited. Accordingly, it is important to try different training strategies for the translation task.
- Human perception: We follow the idea that cGAN-based approaches can support the interpretation of original SAR images by adding a complementary, artificially generated image. In this context, the focus is on human perception and the transition of speckled image parts.
- Follow-up applications: Besides visual perception, the properties of cGAN-based results in terms of follow-up applications have to be described. In this work, we have chosen road extraction as use case scenario.
4. Image-to-Image Translation Strategy
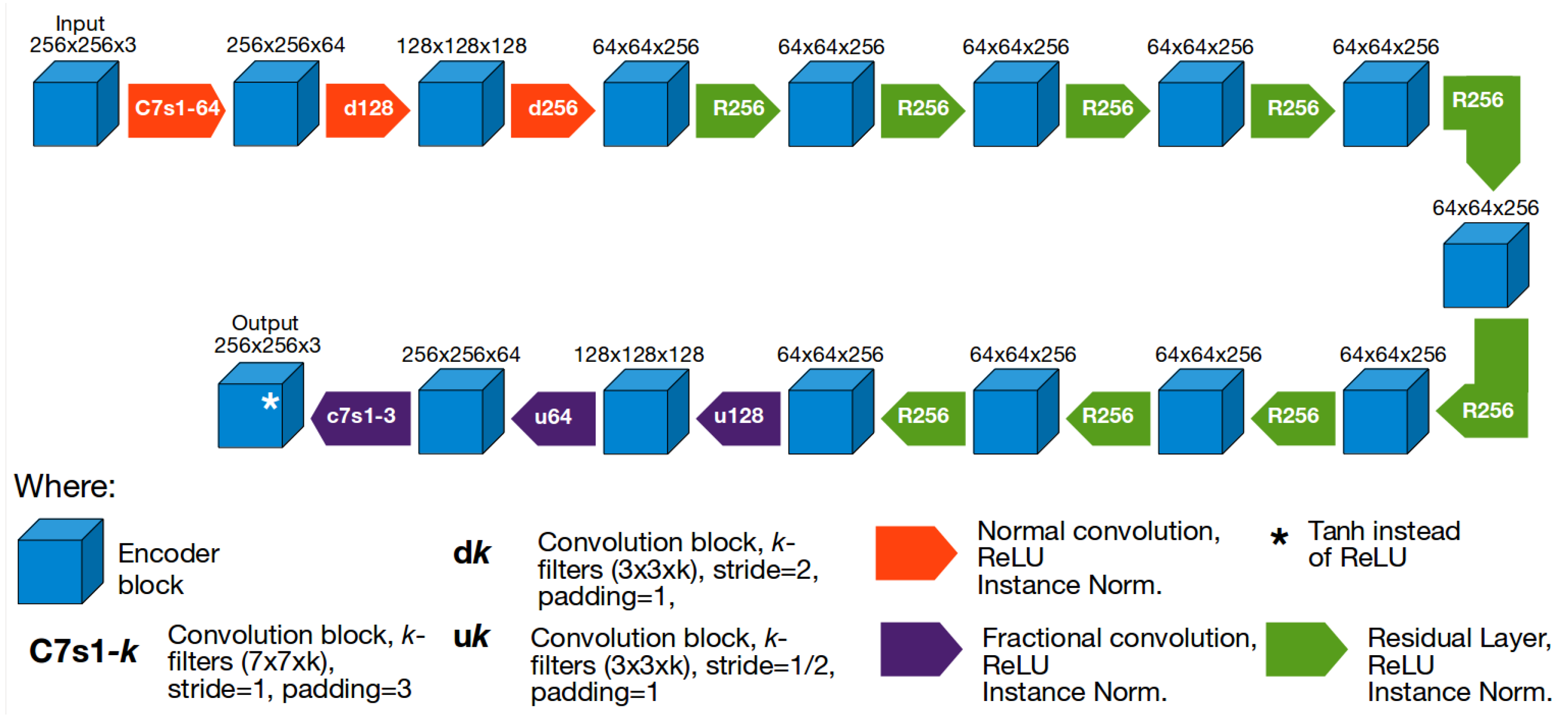
4.1. The CycleGAN Architecture
4.2. Optimization Steps
5. Case Study
5.1. Data for Case Study
5.2. Study Set Up
5.3. Results and Comparison
6. Inspection of CycleGAN Results
6.1. Support of Interpretation
6.2. Extraction of Features
6.3. Combination of Features and Context
7. Conclusions and Outlook
Author Contributions
Funding
Conflicts of Interest
References
- Auer, S.; Hinz, S.; Bamler, R. Ray-Tracing Simulation Techniques for Understanding High-Resolution SAR Images. IEEE Trans. Geosci. Remote Sens. 2010, 48, 1445–1456. [Google Scholar] [CrossRef]
- Argenti, F.; Lapini, A.; Bianchi, T.; Alparone, L. A tutorial on speckle reduction in synthetic aperture radar images. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–35. [Google Scholar] [CrossRef]
- Zhang, R.; Isola, P.; Efros, A.A. Colorful Image Colorization. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; pp. 649–666. [Google Scholar]
- Auer, S.; Hornig, I.; Schmitt, M.; Reinartz, P. Simulation-Based Interpretation and Alignment of High-Resolution Optical and SAR Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4779–4793. [Google Scholar] [CrossRef] [Green Version]
- Merkle, N.; Auer, S.; Müller, R.; Reinartz, P. Exploring the potential of conditional adversarial networks for optical and SAR image matching. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1811–1820. [Google Scholar] [CrossRef]
- Bermudez, J.; Happ, P.; Oliveira, D.; Feitosa, R. SAR to optical image synthesis for cloud removal with generative adversarial networks. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, IV-1, 5–11. [Google Scholar] [CrossRef]
- Merkle, N.; Fischer, P.; Auer, S.; Müller, R. On the Possibility of Conditional Adversarial Networks for Multi-Sensor Image Matching. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 2633–2636. [Google Scholar] [CrossRef]
- Zhu, J.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef]
- Chierchia, G.; Cozzolino, D.; Poggi, G.; Verdoliva, L. SAR Image Despeckling Through Convolutional Neural Networks. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5438–5441. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Dabov, K.; Foi, A.; Katkovnik, V.; Egiazarian, K. Image denoising by sparse 3-D transform-domain collaborative filtering. IEEE Trans. Image Process. 2007, 16, 2080–2095. [Google Scholar] [CrossRef] [PubMed]
- Deledalle, C.; Denis, L.; Tupin, F.; Reigber, A.; Jäger, M. NL-SAR: A unified nonlocal framework for resolution-preserving (Pol)(In)SAR denoising. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2021–2038. [Google Scholar] [CrossRef]
- Ao, D.; Dumitru, C.O.; Schwarz, G.; Datcu, M. Dialectical GAN for SAR image translation: From Sentinel-1 to TerraSAR-X. Remote Sens. 2018, 10, 1597. [Google Scholar] [CrossRef]
- Isola, P.; Zhu, J.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar] [CrossRef]
- Wang, P.; Patel, V.M. Generating High Quality Visible Images from SAR Images Using CNNs. In Proceedings of the 2018 IEEE Radar Conference (RadarConf18), Oklahoma City, OK, USA, 23–27 April 2018; pp. 570–575. [Google Scholar]
- Ley, A.; D’Hondt, O.; Valade, S.; Hänsch, R.; Hellwich, O. Exploiting GAN-Based SAR to Optical Image Transcoding for Improved Classification via Deep Learning. In Proceedings of the EUSAR 2018, Aachen, Germany, 4–7 June 2018; pp. 396–401. [Google Scholar]
- He, W.; Yokoya, N. Multi-Temporal Sentinel-1 and -2 Data Fusion for Optical Image Simulation. ISPRS Int. J. Geo-Inf. 2018, 7, 389. [Google Scholar] [CrossRef]
- Hughes, L.H.; Schmitt, M.; Mou, L.; Wang, Y.; Zhu, X.X. Identifying corresponding patches in SAR and optical images with a pseudo-siamese CNN. IEEE Geosci. Remote Sens. Lett. 2018, 15, 784–788. [Google Scholar] [CrossRef]
- Hughes, L.; Schmitt, M.; Zhu, X. Mining hard negative samples for SAR-optical image matching using generative adversarial networks. Remote Sens. 2018, 10, 1152. [Google Scholar] [CrossRef]
- Schmitt, M.; Hughes, L.H.; Zhu, X.X. The SEN1-2 dataset for deep learning in SAR-optical data fusion. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2018, IV-1, 141–146. [Google Scholar] [CrossRef]
- Grohnfeldt, C.; Schmitt, M.; Zhu, X. A Conditional Generative Adversarial Network to Fuse SAR and Multispectral Optical Data for Cloud Removal from Sentinel-2 Images. In Proceedings of the IGARSS 2018—2018 IEEE International Geoscience and Remote Sensing Symposium, Valencia, Spain, 22–27 July 2018; pp. 1726–1729. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv, 2014; arXiv:1411.1784. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training By Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning—Volume 37, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Instance normalization: The missing ingredient for fast stylization. arXiv, 2016; arXiv:1607.08022. [Google Scholar]
- Kingma, D.; Ba, J. Adam: A method for stochastic optimization. arXiv, 2014; arXiv:1412.6980. [Google Scholar]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; Volume 9, pp. 249–256. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Nice, France, 2014; pp. 2672–2680. [Google Scholar]
- Johnson, J.; Alahi, A.; Fei-Fei, L. Perceptual Losses for Real-Time Style Transfer and Super-Resolution; Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 694–711. [Google Scholar]
- Lucic, M.; Kurach, K.; Michalski, M.; Bousquet, O.; Gelly, S. Are GANs created equal? A large-scale study. In Proceedings of the 32Nd International Conference on Neural Information Processing Systems; Curran Associates Inc.: New York, NY, USA, 2018; pp. 698–707. [Google Scholar]
- Pitz, W.; Miller, D. The TerraSAR-X Satellite. TGRS 2010, 48, 615–622. [Google Scholar] [CrossRef]
- Schneider, M.; Müller, R.; Krauss, T.; Reinartz, P.; Hörsch, B.; Schmuck, S. Urban Atlas—DLR Processing Chain for Orthorectification of Prism and AVNIR-2 Images and TerraSAR-X as Possible GCP Source. In Proceedings of the 3rd ALOS PI Symposium, Buffalo, NY, USA, 5–7 May 2010; pp. 1–6. [Google Scholar]
- Lee, H.; Tseng, H.; Huang, J.; Singh, M.; Yang, M. Diverse Image-to-Image Translation via Disentangled Representations. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Baier, G.; Zhu, X.X. GPU-based nonlocal filtering for large scale SAR processing. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 7608–7611. [Google Scholar]
- Chu, C.; Zhmoginov, A.; Sandler, M. CycleGAN, a master of steganography. arXiv, 2017; arXiv:1712.02950. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018. [Google Scholar]
- Henry, C.; Azimi, S.M.; Merkle, N. Road segmentation in SAR satellite images with deep fully convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1867–1871. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Imagery | Urban Atlas | SEN1-2 |
|---|---|---|
| Optical | Satellite ALOS PRISM 2.5 m resolution | Satellite Sentinel 2 RGB bands <1% cloud coverage |
| SAR | Satellite TerraSAR-X stripmap mode 1.25 m resolution | Satellite Sentinel 1 Vertically polarized 5 m azimuth 20 m range |
| Set | Cities (Files per Site, 46 in Total) |
|---|---|
| Training | Aveiro (2), Bonn (2), Bristol (4), Dublin (2), Kalisz (11), Leeds (3), Le Havre (2), Lincoln (4), London (7) |
| Development | London (2), Portsmouth (2) |
| Test | Rzeszow (3), Stara Zagora (1), Wirral (1) |
| Imagery | IoU | Precision | Recall |
|---|---|---|---|
| CycleGAN | 35.63% | 61.63% | 45.78% |
| NL-SAR | 38.58% | 63.24% | 49.72% |
| SAR | 40.45% | 65.08% | 51.66% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fuentes Reyes, M.; Auer, S.; Merkle, N.; Henry, C.; Schmitt, M. SAR-to-Optical Image Translation Based on Conditional Generative Adversarial Networks—Optimization, Opportunities and Limits. Remote Sens. 2019, 11, 2067. https://doi.org/10.3390/rs11172067
Fuentes Reyes M, Auer S, Merkle N, Henry C, Schmitt M. SAR-to-Optical Image Translation Based on Conditional Generative Adversarial Networks—Optimization, Opportunities and Limits. Remote Sensing. 2019; 11(17):2067. https://doi.org/10.3390/rs11172067
Chicago/Turabian StyleFuentes Reyes, Mario, Stefan Auer, Nina Merkle, Corentin Henry, and Michael Schmitt. 2019. "SAR-to-Optical Image Translation Based on Conditional Generative Adversarial Networks—Optimization, Opportunities and Limits" Remote Sensing 11, no. 17: 2067. https://doi.org/10.3390/rs11172067
APA StyleFuentes Reyes, M., Auer, S., Merkle, N., Henry, C., & Schmitt, M. (2019). SAR-to-Optical Image Translation Based on Conditional Generative Adversarial Networks—Optimization, Opportunities and Limits. Remote Sensing, 11(17), 2067. https://doi.org/10.3390/rs11172067