Orientation- and Scale-Invariant Multi-Vehicle Detection and Tracking from Unmanned Aerial Videos


Abstract
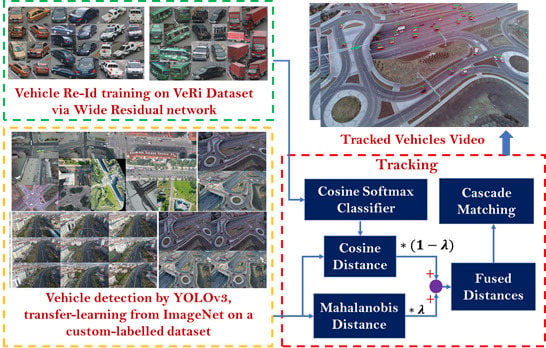
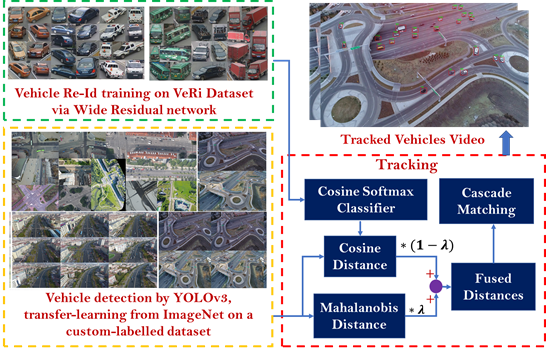
:
1. Introduction
2. Related Work
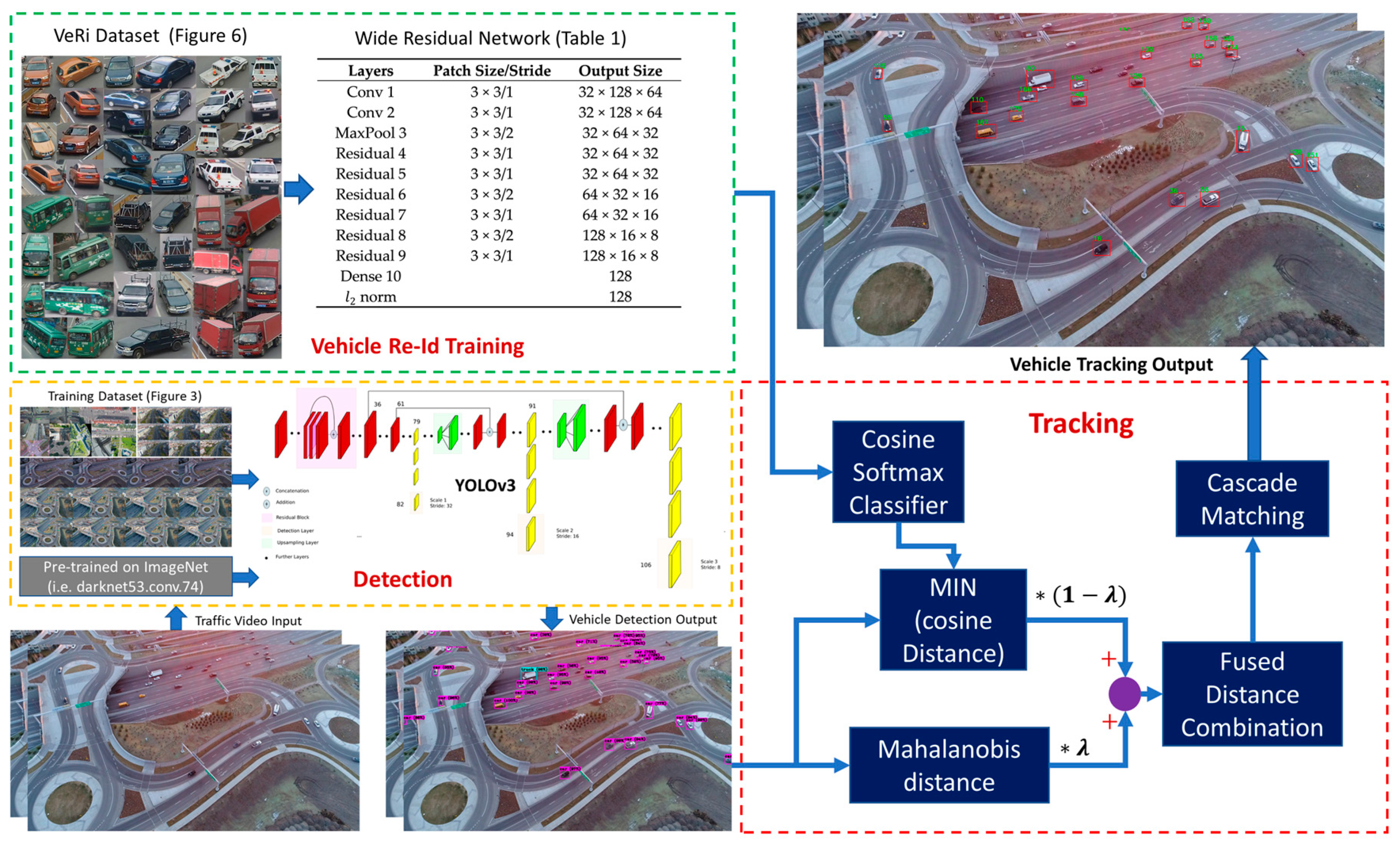
3. Methodology
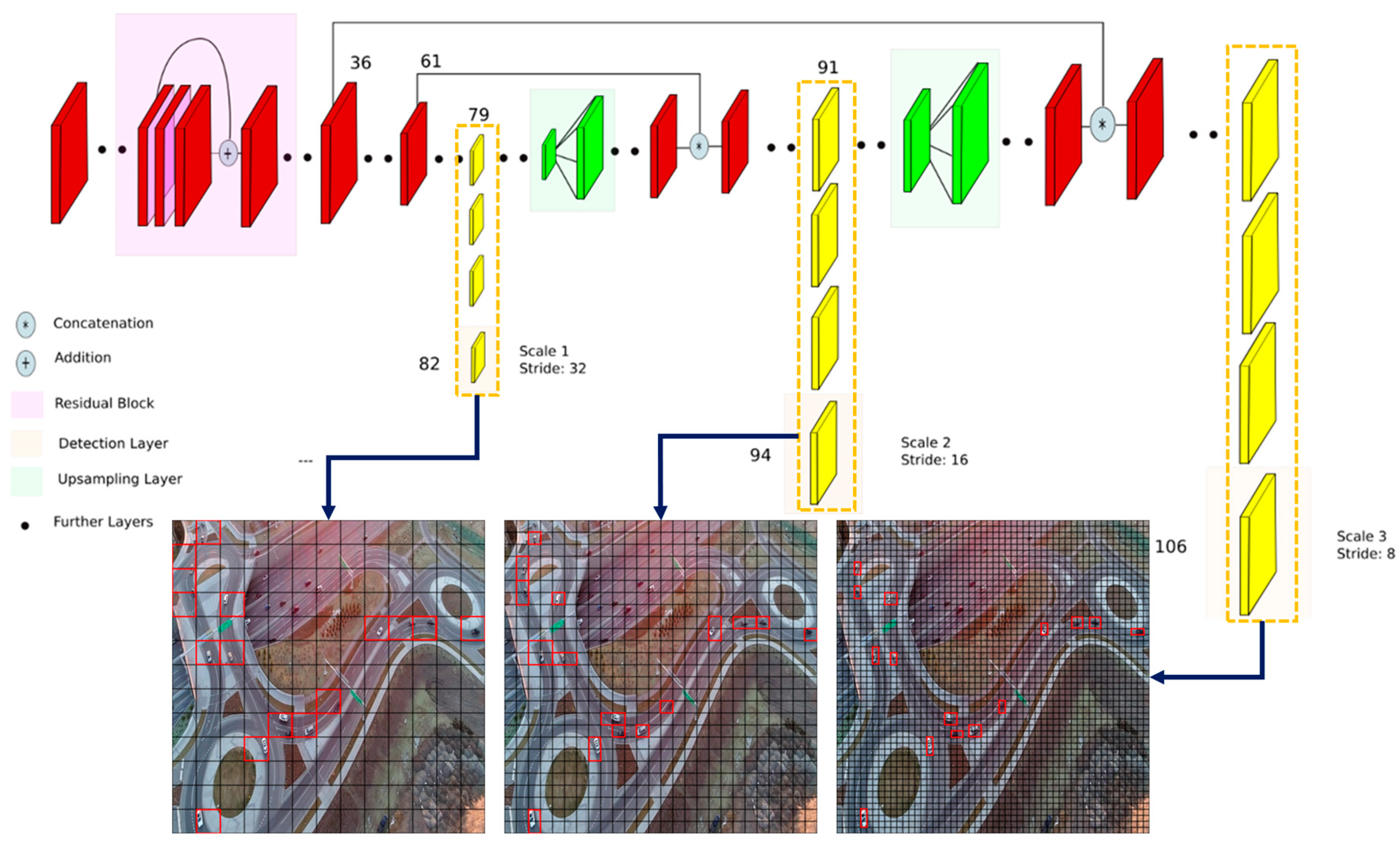
3.1. Detection
3.2. Tracking
3.2.1. Motion and Deep Appearance Features
3.2.2. Data Association
4. Experiments
- TP: True Positive, Number of positive observations that are correctly predicted as positive.
- FP: False Positive, Number of negative observations that are incorrectly predicted as positive.
- TN: True Negative, Number of negative observations that are correctly predicted as negative.
- FN: False Negative, Number of positive observations that are incorrectly predicted as negative.
- IDP: Identification Precision, True positive divided by the total number of observations that are predicted as positive.
- IDR: Identification Recall, True positive divided by the total number of positive observations.
- F1 score: Harmonic mean used to fuse IDP and IDR.
- MT and ML: These are to evaluate what portion of the trajectory of a vehicle is recovered by the tracking method. An object is mostly tracked (MT) if it is successfully tracked for at least 80% of its life span (the time during which it is observable in the video). If a track is recovered for less than 20% of its total length, it is said to be mostly lost (ML). It is irrelevant for MT and ML whether the identity of the object remains the same.
- IDSW: Number of times the identity of the tracked object changes.
- MOTA: It is the most widely used metric since it summarizes the overall tracking accuracy in terms of FN, FP and IDSW as follows,where is the frame index, and is the number of ground truth vehicle objects.
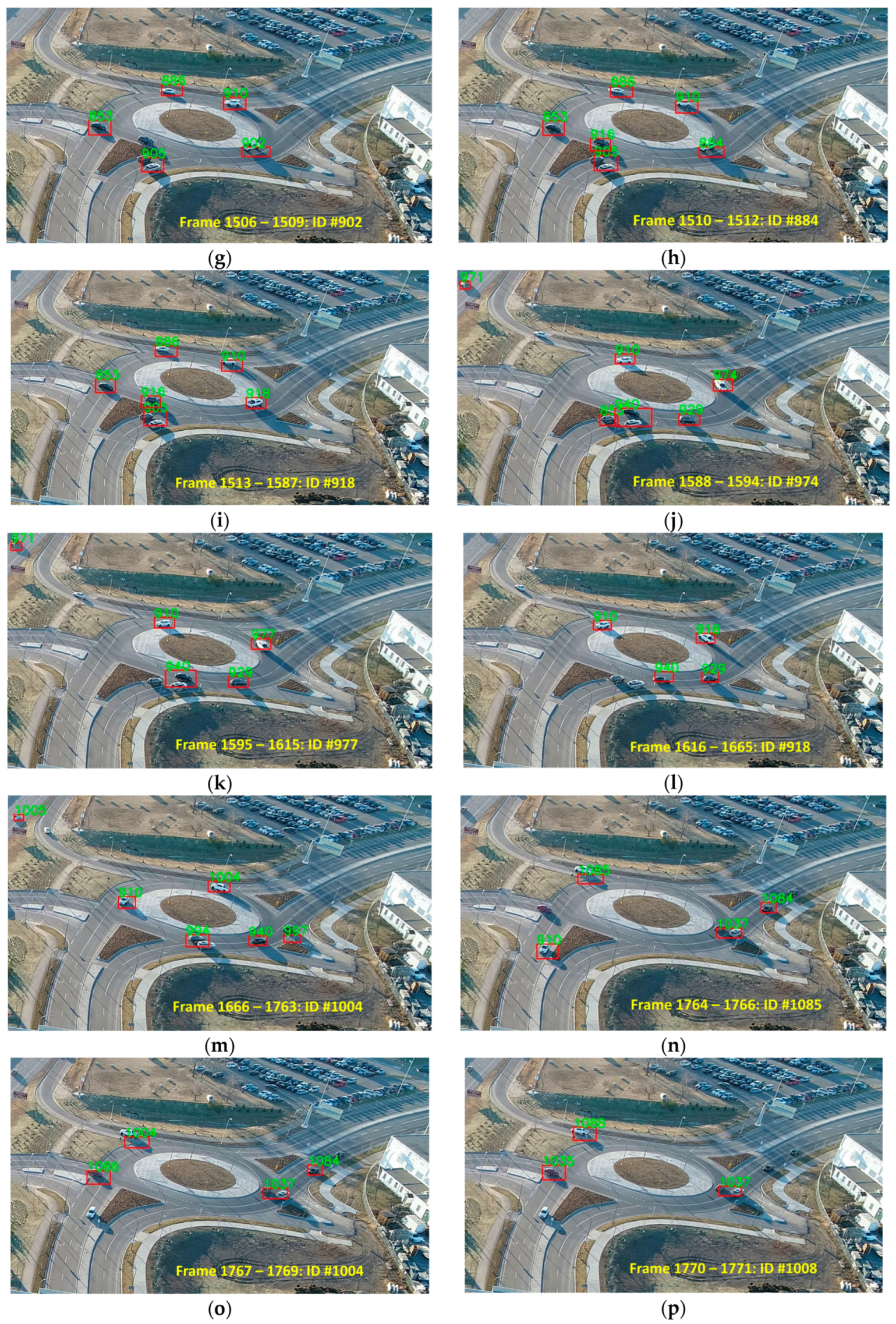
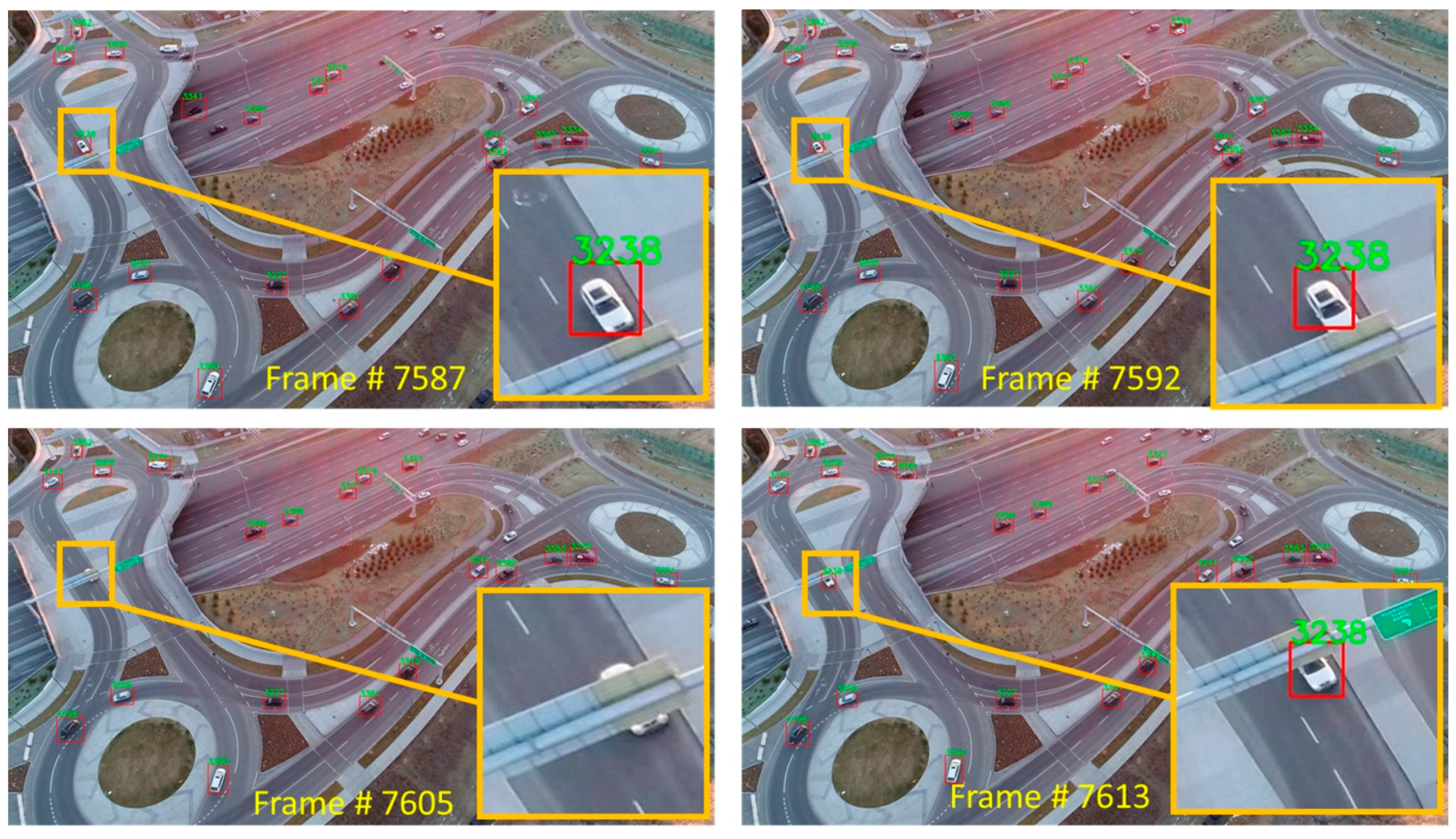
5. Results
6. Discussion
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shahbazi, M.; Théau, J.; Ménard, P. Recent applications of unmanned aerial imagery in natural resource management. GIScience Remote Sens. 2014, 51, 339–365. [Google Scholar] [CrossRef]
- Pajares, G. Overview and current status of remote sensing applications based on unmanned aerial vehicles (UAVs). Photogramm. Eng. Remote Sens. 2015, 81, 281–330. [Google Scholar] [CrossRef]
- Shakhatreh, H.; Sawalmeh, A.H.; Al-Fuqaha, A.; Dou, Z.; Almaita, E.; Khalil, I.; Othman, N.S.; Khreishah, A.; Guizani, M. Unmanned aerial vehicles (UAVs): A survey on civil applications and key research Challenges. IEEE Access 2019, 7, 48572–48634. [Google Scholar] [CrossRef]
- Menouar, H.; Guvenc, I.; Akkaya, K.; Uluagac, A.S.; Kadri, A.; Tuncer, A. UAV-enabled intelligent transportation systems for the smart city: Applications and challenges. IEEE Commun. Mag. 2017, 55, 22–28. [Google Scholar] [CrossRef]
- Kanistras, K.; Martins, G.; Rutherford, M.J.; Valavanis, K.P. Survey of unmanned aerial vehicles (uavs) for traffic monitoring. In Handbook of Unmanned Aerial Vehicles; Springer: Dordrecht, The Netherlands, 2015; ISBN 9789048197071. [Google Scholar]
- Barmpounakis, E.N.; Vlahogianni, E.I.; Golias, J.C. Unmanned aerial aircraft systems for transportation engineering: Current practice and future challenges. Int. J. Transp. Sci. Technol. 2016, 5, 111–122. [Google Scholar] [CrossRef]
- Khan, M.A.; Ectors, W.; Bellemans, T.; Janssens, D.; Wets, G. UAV-Based Traffic Analysis: A Universal Guiding Framework Based on Literature Survey. In Transportation Research Procedia; Elsevier: Amsterdam, The Netherlands, 2017. [Google Scholar]
- Buch, N.; Velastin, S.A.; Orwell, J. A review of computer vision techniques for the analysis of urban traffic. IEEE Trans. Intell. Transp. Syst. 2011, 12, 920–939. [Google Scholar] [CrossRef]
- Al-Smadi, M.; Abdulrahim, K.; Salam, R.A. Traffic surveillance: A review of vision based vehicle detection, recognition and tracking. Int. J. Appl. Eng. Res. 2016, 11, 713–726. [Google Scholar]
- Sivaraman, S.; Trivedi, M.M. Looking at vehicles on the road: A survey of vision-based vehicle detection, tracking, and behavior analysis. IEEE Trans. Intell. Transp. Syst. 2013, 14, 1773–1795. [Google Scholar] [CrossRef]
- Ke, R.; Li, Z.; Kim, S.; Ash, J.; Cui, Z.; Wang, Y. Real-time bidirectional traffic flow parameter estimation from aerial videos. IEEE Trans. Intell. Transp. Syst. 2017, 18, 890–901. [Google Scholar] [CrossRef]
- Dai, Z.; Song, H.; Wang, X.; Fang, Y.; Yun, X.; Zhang, Z.; Li, H. Video-based vehicle counting framework. IEEE Access 2019, 7, 64460–64470. [Google Scholar] [CrossRef]
- Indira, K.; Mohan, K.V.; Nikhilashwary, T. Automatic license plate recognition. In Advances in Intelligent Systems and Computing; Springer: Berlin/Heidelberg, Germany, 2019. [Google Scholar]
- Ren, J.; Chen, Y.; Xin, L.; Shi, J.; Li, B.; Liu, Y. Detecting and positioning of traffic incidents via video-based analysis of traffic states in a road segment. IET Intell. Transp. Syst. 2016, 10, 428–437. [Google Scholar] [CrossRef]
- Zhang, S.; Wu, G.; Costeira, J.P.; Moura, J.M.F. FCN-rLSTM: Deep spatio-temporal neural networks for vehicle counting in city cameras. In Proceedings of the IEEE International Conference on Computer Vision, Venezia, Italy, 22–29 October 2017. [Google Scholar]
- Peppa, M.V.; Bell, D.; Komar, T.; Xiao, W. Urban traffic flow analysis based on deep learning car detection from CCTV image series. In Proceedings of the International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences—ISPRS Archives, Delft, The Netherlands, 1–5 October 2018. [Google Scholar]
- Sochor, J.; Spanhel, J.; Herout, A. BoxCars: Improving fine-grained recognition of vehicles using 3-D bounding boxes in traffic surveillance. IEEE Trans. Intell. Transp. Syst. 2019, 20, 97–108. [Google Scholar] [CrossRef]
- Naphade, M.; Chang, M.C.; Sharma, A.; Anastasiu, D.C.; Jagarlamudi, V.; Chakraborty, P.; Huang, T.; Wang, S.; Liu, M.Y.; Chellappa, R.; et al. The 2018 NVIDIA AI city challenge. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Luo, W.; Xing, J.; Milan, A.; Zhang, X.; Liu, W.; Zhao, X.; Kim, T.-K. Multiple object tracking: A literature review. arXiv 2014, arXiv:1409.7618. [Google Scholar]
- Liu, X.; Liu, W.; Ma, H.; Fu, H. Large-scale vehicle re-identification in urban surveillance videos. In Proceedings of the IEEE International Conference on Multimedia and Expo, Seattle, WA, USA, 11–15 July 2016. [Google Scholar]
- Liu, H.; Tian, Y.; Wang, Y.; Pang, L.; Huang, T. Deep relative distance learning: Tell the difference between similar vehicles. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2167–2175. [Google Scholar]
- Tang, Z.; Wang, G.; Xiao, H.; Zheng, A.; Hwang, J.N. Single-camera and inter-camera vehicle tracking and 3d speed estimation based on fusion of visual and semantic features. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Feng, W.; Ji, D.; Wang, Y.; Chang, S.; Ren, H.; Gan, W. Challenges on large scale surveillance video analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 69–76. [Google Scholar]
- Lv, Y.; Duan, Y.; Kang, W.; Li, Z.; Wang, F.Y. Traffic flow prediction with big data: A deep learning approach. IEEE Trans. Intell. Transp. Syst. 2015, 16, 865–873. [Google Scholar] [CrossRef]
- Kathuria, A. What’s new in YOLO v3. Towar. Data Sci. 2018. Available online: https://towardsdatascience.com/yolo-v3-object-detection-53fb7d3bfe6b (accessed on 1 July 2019).
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Milan, A.; Leal-Taixé, L.; Reid, I.; Roth, S.; Schindler, K. MOT16: A benchmark for multi-object tracking. arXiv 2016, arXiv:1603.00831. [Google Scholar]
- Yoon, J.H.; Lee, C.-R.; Yang, M.-H.; Yoon, K.-J. Structural constraint data association for online multi-object tracking. Int. J. Comput. Vis. 2019, 127, 1–21. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Venezia, Italy, 22–29 October 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Cai, Z.; Fan, Q.; Feris, R.S.; Vasconcelos, N. A unified multi-scale deep convolutional neural network for fast object detection. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2016. [Google Scholar]
- Tang, T.; Zhou, S.; Deng, Z.; Zou, H.; Lei, L. Vehicle detection in aerial images based on region convolutional neural networks and hard negative example mining. Sensors 2017, 17, 336. [Google Scholar] [CrossRef]
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P.A. SINet: A scale-insensitive convolutional neural network for fast vehicle detection. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1010–1019. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [Green Version]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Anisimov, D.; Khanova, T. Towards lightweight convolutional neural networks for object detection. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance, AVSS 2017, Lecce, Italy, 29 August–1 September 2017. [Google Scholar]
- Chen, L.; Zhang, Z.; Peng, L. Fast single shot multibox detector and its application on vehicle counting system. IET Intell. Transp. Syst. 2018, 12, 1406–1413. [Google Scholar] [CrossRef]
- Zhao, D.; Fu, H.; Xiao, L.; Wu, T.; Dai, B. Multi-object tracking with correlation filter for autonomous vehicle. Sensors 2018, 18, 2004. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the—30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An improved YOLOv2 for vehicle detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef]
- Kim, K.-J.; Kim, P.-K.; Chung, Y.-S.; Choi, D.-H. Multi-scale detector for accurate vehicle detection in traffic surveillance data. IEEE Access 2019, 7, 78311–78319. [Google Scholar] [CrossRef]
- Ju, M.; Luo, J.; Zhang, P.; He, M.; Luo, H. A simple and efficient network for small target detection. IEEE Access 2019, 7, 85771–85781. [Google Scholar] [CrossRef]
- Wang, X.; Cheng, P.; Liu, X.; Uzochukwu, B. Focal loss dense detector for vehicle surveillance. In Proceedings of the 2018 International Conference on Intelligent Systems and Computer Vision, ISCV 2018, Fez, Morocco, 2–4 April 2018. [Google Scholar]
- Huang, J.; Rathod, V.; Sun, C.; Zhu, M.; Korattikara, A.; Fathi, A.; Fischer, I.; Wojna, Z.; Song, Y.; Guadarrama, S.; et al. Speed/accuracy trade-offs for modern convolutional object detectors. In Proceedings of the—30th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Du, D.; Qi, Y.; Yu, H.; Yang, Y.; Duan, K.; Li, G.; Zhang, W.; Huang, Q.; Tian, Q. The unmanned aerial vehicle benchmark: Object detection and tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 370–386. [Google Scholar]
- Benjdira, B.; Khursheed, T.; Koubaa, A.; Ammar, A.; Ouni, K. Car Detection using unmanned aerial vehicles: Comparison between faster R-CNN and YOLOv3. In Proceedings of the 2019 1st International Conference on Unmanned Vehicle Systems-Oman, UVS, Muscat, Oman, 5–7 February 2019. [Google Scholar]
- Cao, X.; Wu, C.; Yan, P.; Li, X. Linear SVM classification using boosting HOG features for vehicle detection in low-altitude airborne videos. In Proceedings of the International Conference on Image Processing, ICIP, Brussels, Belgium, 11–14 September 2011. [Google Scholar]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. A hybrid vehicle detection method based on viola-jones and HOG + SVM from UAV images. Sensors 2016, 16, 1325. [Google Scholar] [CrossRef] [PubMed]
- Liang, P.; Teodoro, G.; Ling, H.; Blasch, E.; Chen, G.; Bai, L. Multiple kernel learning for vehicle detection in wide area motion imagery. In Proceedings of the 15th International Conference on Information Fusion, FUSION, Singapore, 9–12 July 2012. [Google Scholar]
- Grabner, H.; Nguyen, T.T.; Gruber, B.; Bischof, H. On-line boosting-based car detection from aerial images. ISPRS J. Photogramm. Remote Sens. 2008, 63, 382–396. [Google Scholar] [CrossRef]
- Sun, X.; Wang, H.; Fu, K. Automatic detection of geospatial objects using taxonomic semantics. IEEE Geosci. Remote Sens. Lett. 2010, 7, 23–27. [Google Scholar] [CrossRef]
- Niknejad, H.T.; Mita, S.; McAllester, D.; Naito, T. Vision-based vehicle detection for nighttime with discriminately trained mixture of weighted deformable part models. In Proceedings of the IEEE Conference on Intelligent Transportation Systems, ITSC, Washington, DC, USA, 5–7 October 2011. [Google Scholar]
- Leon, L.C.; Hirata, R. Vehicle detection using mixture of deformable parts models: Static and dynamic camera. In Proceedings of the Brazilian Symposium of Computer Graphic and Image Processing, Ouro Preto, Brazil, 22–25 August 2012. [Google Scholar]
- Pan, C.; Sun, M.; Yan, Z. The study on vehicle detection based on DPM in traffic scenes. In Proceedings of the International Conference on Frontier Computing, Tokyo, Japan, 13–15 July 2016; pp. 19–27. [Google Scholar]
- Chen, X.; Xiang, S.; Liu, C.L.; Pan, C.H. Vehicle detection in satellite images by hybrid deep convolutional neural networks. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1797–1801. [Google Scholar] [CrossRef]
- Kim, C.; Li, F.; Ciptadi, A.; Rehg, J.M. Multiple hypothesis tracking revisited. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015. [Google Scholar]
- Rezatofighi, S.H.; Milan, A.; Zhang, Z.; Shi, Q.; Dick, A.; Reid, I. Joint probabilistic data association revisited. In Proceedings of the IEEE International Conference on Computer Vision, Las Condes, Chile, 11–18 December 2015. [Google Scholar]
- Lee, M.-H.; Yeom, S. Tracking of moving vehicles with a UAV. In Proceedings of the 2018 Joint 10th International Conference on Soft Computing and Intelligent Systems (SCIS) and 19th International Symposium on Advanced Intelligent Systems (ISIS), Toyama, Japan, 5–8 December 2018; pp. 928–931. [Google Scholar]
- Bewley, A.; Ge, Z.; Ott, L.; Ramos, F.; Upcroft, B. Simple online and realtime tracking. In Proceedings of the International Conference on Image Processing, ICIP, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Goli, S.A.; Far, B.H.; Fapojuwo, A.O. An accurate multi-sensor multi-target localization method for cooperating vehicles. In Theoretical Information Reuse and Integration; Springer: Berlin/Heidelberg, Germany, 2016; pp. 197–217. [Google Scholar]
- Wojke, N.; Bewley, A. Deep cosine metric learning for person re-identification. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision, WACV, Lake Tahoe, NV, USA, 12–15 March 2018. [Google Scholar]
- Wojke, N.; Bewley, A.; Paulus, D. Simple online and realtime tracking with a deep association metric. In Proceedings of the International Conference on Image Processing, ICIP, Beijing, China, 17–20 September 2018. [Google Scholar]
- Liu, X.; Liu, W.; Mei, T.; Ma, H. PROVID: Progressive and multimodal vehicle reidentification for large-scale urban surveillance. IEEE Trans. Multimed. 2018, 20, 645–658. [Google Scholar] [CrossRef]
- Zhu, J.; Zeng, H.; Huang, J.; Liao, S.; Lei, Z.; Cai, C.; Zheng, L. Vehicle re-identification using quadruple directional deep learning features. IEEE Trans. Intell. Transp. Syst. 2019, 1–11. [Google Scholar] [CrossRef]
- Luo, W.; Yang, B.; Urtasun, R. Fast and furious: Real time end-to-end 3D detection, tracking and motion forecasting with a single convolutional net. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018. [Google Scholar]
- Zheng, L.; Bie, Z.; Sun, Y.; Wang, J.; Su, C.; Wang, S.; Tian, Q. MARS: A Video Benchmark for Large-Scale Person Re-Identification. In Computer Vision–ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer: Cham, Switzerland, 2016; pp. 868–884. [Google Scholar]
- Li, J.; Chen, S.; Zhang, F.; Li, E.; Yang, T.; Lu, Z. An adaptive framework for multi-vehicle ground speed estimation in airborne videos. Remote Sens. 2019, 11, 1241. [Google Scholar] [CrossRef]
- Lyu, S.; Chang, M.-C.; Du, D.; Wen, L.; Qi, H.; Li, Y.; Wei, Y.; Ke, L.; Hu, T.; Del Coco, M.; et al. UA-DETRAC 2017: Report of AVSS2017 & IWT4S challenge on advanced traffic monitoring. In Proceedings of the 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–7. [Google Scholar]
- Shah, S.; Dey, D.; Lovett, C.; Kapoor, A. AirSim: High-Fidelity Visual and Physical Simulation for Autonomous Vehicles; Springer: Cham, Switzerland, 2018. [Google Scholar]
- Niu, H.; Gonzalez-Prelcic, N.; Heath, R.W. A UAV-based traffic monitoring system-invited paper. In Proceedings of the 2018 IEEE 87th Vehicular Technology Conference (VTC Spring), Porto, Portugal, 3–6 June 2018; pp. 1–5. [Google Scholar]
- Wang, L.; Chen, F.; Yin, H. Detecting and tracking vehicles in traffic by unmanned aerial vehicles. Autom. Constr. 2016, 72, 294–308. [Google Scholar] [CrossRef]
- Leitloff, J.; Rosenbaum, D.; Kurz, F.; Meynberg, O.; Reinartz, P. An operational system for estimating road traffic information from aerial images. Remote Sens. 2014, 6, 11315–11341. [Google Scholar] [CrossRef]
- Heintz, F.; Rudol, P.; Doherty, P. From images to traffic behavior—A UAV tracking and monitoring application. In Proceedings of the FUSION 2007–2007 10th International Conference on Information Fusion, Quebec, QC, Canada, 9–12 July 2007. [Google Scholar]
- Liu, F.; Liu, X.; Luo, P.; Yang, Y.; Shi, D. A new method used in moving vehicle information acquisition from aerial surveillance with a UAV. In Advances on Digital Television and Wireless Multimedia Communications; Springer: Berlin/Heidelberg, Germany, 2012; pp. 67–72. [Google Scholar]
- Cao, X.; Wu, C.; Lan, J.; Yan, P.; Li, X. Vehicle detection and motion analysis in low-altitude airborne video under urban environment. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 1522–1533. [Google Scholar] [CrossRef]
- Ren, W.; Beard, R.W. Trajectory tracking for unmanned air vehicles with velocity and heading rate constraints. IEEE Trans. Control Syst. Technol. 2004, 12, 706–716. [Google Scholar] [CrossRef]
- Cao, X.; Gao, C.; Lan, J.; Yuan, Y.; Yan, P. Ego motion guided particle filter for vehicle tracking in airborne videos. Neurocomputing 2014, 124, 168–177. [Google Scholar] [CrossRef]
- Cao, X.; Lan, J.; Yan, P.; Li, X. Vehicle detection and tracking in airborne videos by multi-motion layer analysis. Mach. Vis. Appl. 2012, 23, 921–935. [Google Scholar] [CrossRef]
- Krause, J.; Stark, M.; Deng, J.; Fei-Fei, L. 3D Object representations for fine-grained categorization. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 1–8 December 2013; pp. 554–561. [Google Scholar]
- Geiger, A.; Lenz, P.; Urtasun, R. Are we ready for autonomous driving? The KITTI vision benchmark suite. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 3354–3361. [Google Scholar]
- Zagoruyko, S.; Komodakis, N. Wide Residual Networks. arXiv 2016, arXiv:1605.07146. [Google Scholar] [Green Version]
- Bernardin, K.; Stiefelhagen, R. Evaluating multiple object tracking performance: The clear mot metrics. EURASIP J. Image Video Process. 2008, 2008, 246309. [Google Scholar] [CrossRef]
- Ristani, E.; Solera, F.; Zou, R.; Cucchiara, R.; Tomasi, C. Performance measures and a data set for multi-target, multi-camera tracking. In Computer Vision—ECCV 2016 Workshops; Hua, G., Jégou, H., Eds.; Springer: Cham, Switzerland, 2016; pp. 17–35. [Google Scholar]
- Xiang, Y.; Alahi, A.; Savarese, S. Learning to track: Online multi-object tracking by decision making. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV) IEEE, Washington, DC, USA, 7–13 December 2015; pp. 4705–4713. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layers | Patch Size/Stride | Output Size |
|---|---|---|
| Conv 1 | 3 × 3/1 | 32 × 128 × 64 |
| Conv 2 | 3 × 3/1 | 32 × 128 × 64 |
| MaxPool 3 | 3 × 3/2 | 32 × 64 × 32 |
| Residual 4 | 3 × 3/1 | 32 × 64 × 32 |
| Residual 5 | 3 × 3/1 | 32 × 64 × 32 |
| Residual 6 | 3 × 3/2 | 64 × 32 × 16 |
| Residual 7 | 3 × 3/1 | 64 × 32 × 16 |
| Residual 8 | 3 × 3/2 | 128 × 16 × 8 |
| Residual 9 | 3 × 3/1 | 128 × 16 × 8 |
| Dense 10 | 128 | |
| -norm | 128 |
| Video | Total # | |||||||
|---|---|---|---|---|---|---|---|---|
| DJI video 1 | 4969 | 4804 | 0 | 3 | 165 | 100.00 | 96.68 | 98.3 |
| DJI video 2 | 864 | 647 | 56 | 0 | 217 | 92.03 | 74.88 | 82.6 |
| DJI video 3 | 6984 | 6134 | 22 | 0 | 850 | 99.64 | 87.83 | 93.4 |
| M0101 | 191 | 170 | 3 | 0 | 21 | 98.27 | 89.01 | 93.4 |
| Scene 2 | 153 | 138 | 16 | 0 | 15 | 89.61 | 100.00 | 94.5 |
| Scene 5 | 5901 | 4881 | 23 | 0 | 985 | 99.53 | 83.21 | 90.6 |
| Video | Total # | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| DJI video 1 | 14496 | 11949 | 0 | 0 | 2456 | 52.63% | 0% | 24 | 82.89 |
| DJI video 2 | 5413 | 3529 | 299 | 0 | 1298 | 46.15% | 0% | 90 | 68.83 |
| DJI video 3 | 15120 | 7319 | 38 | 0 | 2543 | 44% | 4% | 45 | 82.63 |
| M0101 | 558 | 4441 | 8 | 0 | 610 | 76.19% | 0% | 8 | 88.74 |
| Scene 2 | 10027 | 9385 | 783 | 0 | 597 | 90.90% | 0% | 13 | 86.11 |
| Scene 5 | 16061 | 11305 | 161 | 0 | 3227 | 68.57% | 5.7% | 22 | 78.77 |
| 74.5 | 55.0 | 61.5 | 47.3 | 19.5 | 43.0 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, J.; Simeonova, S.; Shahbazi, M. Orientation- and Scale-Invariant Multi-Vehicle Detection and Tracking from Unmanned Aerial Videos. Remote Sens. 2019, 11, 2155. https://doi.org/10.3390/rs11182155
Wang J, Simeonova S, Shahbazi M. Orientation- and Scale-Invariant Multi-Vehicle Detection and Tracking from Unmanned Aerial Videos. Remote Sensing. 2019; 11(18):2155. https://doi.org/10.3390/rs11182155
Chicago/Turabian StyleWang, Jie, Sandra Simeonova, and Mozhdeh Shahbazi. 2019. "Orientation- and Scale-Invariant Multi-Vehicle Detection and Tracking from Unmanned Aerial Videos" Remote Sensing 11, no. 18: 2155. https://doi.org/10.3390/rs11182155
APA StyleWang, J., Simeonova, S., & Shahbazi, M. (2019). Orientation- and Scale-Invariant Multi-Vehicle Detection and Tracking from Unmanned Aerial Videos. Remote Sensing, 11(18), 2155. https://doi.org/10.3390/rs11182155