The Potential of Open Geodata for Automated Large-Scale Land Use and Land Cover Classification


Abstract
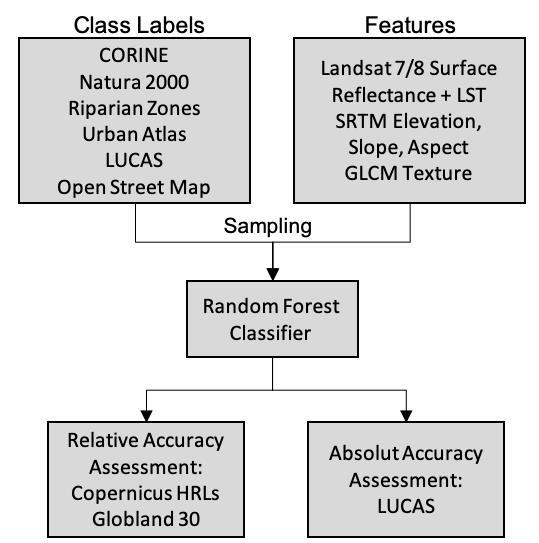
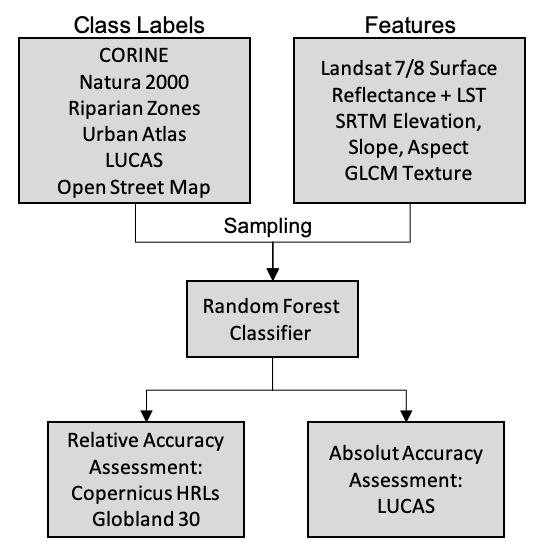
:
1. Introduction
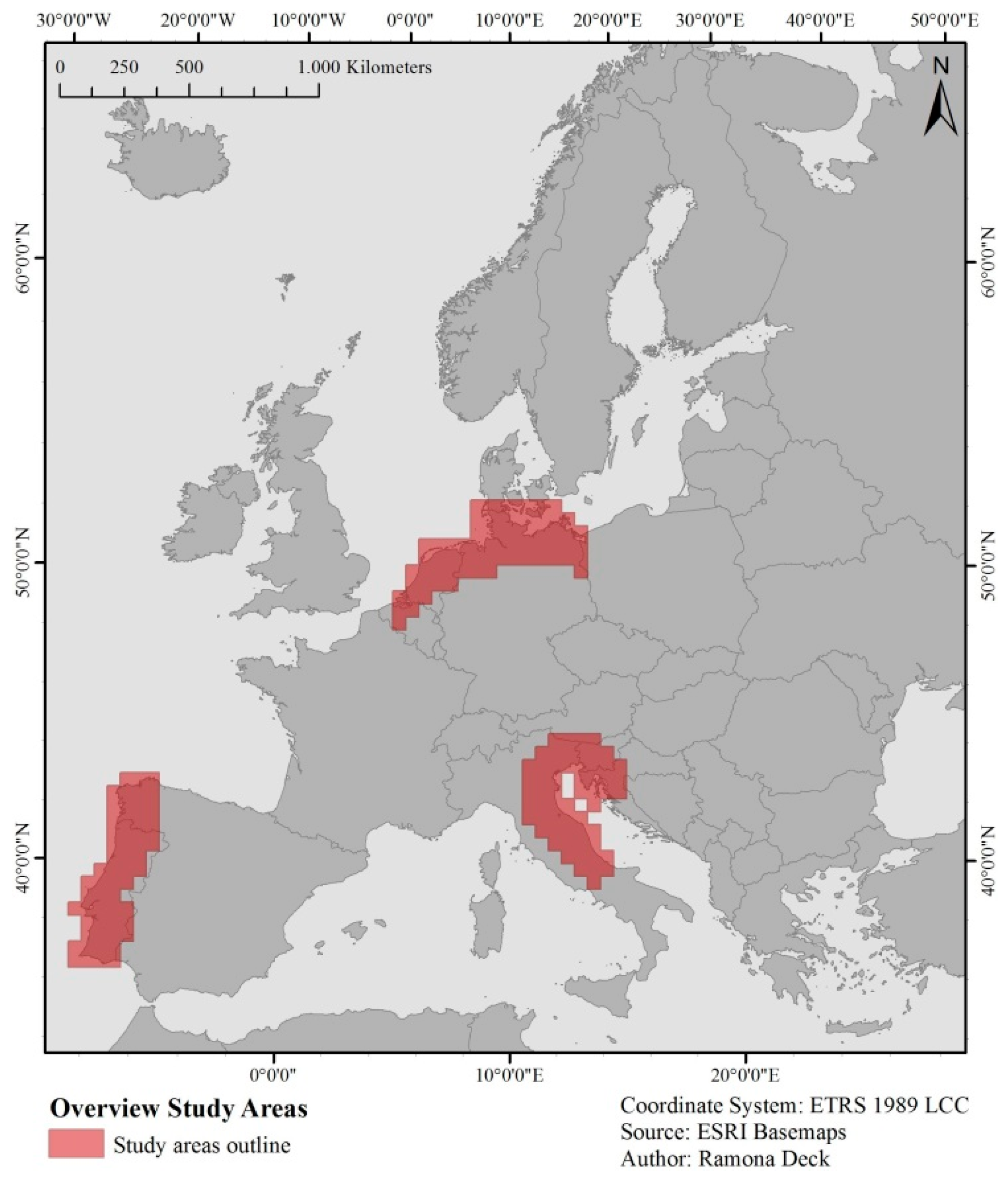
2. Study Areas and Data Basis
2.1. Study Area
2.2. Data Basis
2.2.1. Satellite Data
2.2.2. Land Use and Land Cover Data as Training and Reference Data Sets
- The coordination of information on the environment (CORINE) program of the European Commission seeks to gather information on the state of the environment and is responsible for the coordination of this compilation within the Member States or likewise at an international level. This standardization ensures compatibility of data and results in a homogeneous pan-European wall-to-wall data set containing information about land cover and land use, hereinafter referred to as the CORINE Land Cover (CLC) data set. Initiated in 1985 and produced by the European Environment Agency, the program published its first inventory in 1990 [12,13]. Updates followed in the years 2000, 2006, and latest 2012, constantly extending the area covered, peaking in 39 involved EEA Member States and a total area of 5.8 million km2 [14]. Some parameters were kept unmodified in all CORINE land cover versions comprising the minimum mapping unit (MMU) of 25 hectares, the minimum mapping width (MMW) of 100 m for linear objects, and the working scale of 1:100,000 or the three-level land cover nomenclature containing a total of 44 individual classes. Later versions also take more recent satellite images into account and computer-assisted photo-interpretation as well as semiautomated approaches to reduce labor-intensive photo-interpretation. Apart from SPOT-4/5 data (2006), further optical and near infrared satellite images, such as Landsat-7’s ETM (2000), IRS P6’s sensor LISS III (2006 and 2012), and RapidEye (2012) were also used [12].
- The Land Use and Coverage Area frame Survey (LUCAS) under the responsibility of EUROSTAT, the statistical office of the European Commission [15], is another European initiative related to land use and land cover inventory. LUCAS surveys are carried out every three years since 2006, and the latest published LUCAS survey dates from 2018 and comprises more than 330,000 collected sample points all over the 28 EU countries. The points are empirically registered in the field (in situ) and selected from a total of 1,100,000 points, distributed among the EU territory in a regular 2 km sampling grid. An MMU is not applicable. Instead, the surveyed point is defined as a circle with a radius of 1.5 m. Though, in specific cases, e.g., for nonhomogeneous classes, an extended observation area with a radius of 20 m around the actual point can be considered [16,17,18]. The classification system is subdivided into eight main land cover categories, comprising 84 subclasses and another 14 main categories describing land use, which are likewise segmented into 33 subcategories [13,15,19].
- The Natura 2000 (NK2) data set only represents land cover and land use within selected Natura 2000 sites plus a surrounding buffer zone of 2 km and is therefore not a seamless wall-to-wall data set. The project was initiated by EEA and first published in 2006, an updated version was published for 2012 and covers 28 Member States. The underlying idea was to enhance support of biodiversity monitoring. N2K targets are habitats and zones valuable for endangered species and aims to stop the decline of these substantial areas. Customized to the needs of surveying and assessment of ecosystems and their services, an MMU of 0.5 ha and an MMW of 10 m is used. The four-level nomenclature consists of 62 classes and is based on main features of the already existing Mapping and Assessment of Ecosystems and their Services (MAES) typology combined with that of CLC. Especially level four meets the project specific requirements of N2K definitions. The total N2K area of interest aggregates to 160,444 km2. Along with very high resolution (VHR) SPOT-5 and SPOT-6 data, features of CLC, the European Urban Atlas (UA), Forest HRL, and additional reference and in situ data at country scale also serve as data for the classification [20].
- Riparian Zones (RPZ) also provide LU/LC information for selected regions, thereby focusing on European rivers and adjacent buffer zones [17]. Riparian Zones are defined as the interface or transition zone between contiguous terrestrial and aquatic ecosystems, like rivers, streams, lakes, or even the sea [21]. Only rivers starting with a Strahler level of three are considered and buffer zones are adapted according to this level. The data set was also initiated by EEA and published in 2012 with a total coverage of approximately 525,000 km2 distributed in 39 Member States. An MMU of 0.5 ha and an MMW of 10 m is used, and accordingly the four-level nomenclature is referred to MAES and CORINE albeit containing 80 classes in this case. The main data sources are VHR SPOT-5 and SPOT-6 satellite data augmented by UA, HRL Imperviousness Degree and Tree Cover Density, CLC, Landsat-5/8, and N2K, amongst others.
- The European Urban Atlas (UA) is a local data set of the Copernicus land monitoring services and is supported by the European Space Agency (ESA) and the European Environment Agency (EEA). As its name implies, LU/LC is tailored to the needs of urban areas, which can be very fragmented and therefore, an MMU of 0.25 ha for urban classes and 1 ha for non-urban classes is used. The data set is produced for major agglomerations, more precisely for so-called functional urban areas (FUA) and first published in 2006, followed by an updated version in 2012 with further updates planned in five-year cycles. The latest version covers 697 FUA, which includes most cities and their commuting zone exceeding 50,000 inhabitants in 28 Member States. The nomenclature is based on CORINE and GMES Urban Services. UA contains 28 classes in a four-level nomenclature, of which 17 are urban, while 11 are rural. The data mainly consists of VHR SPOT-5 satellite images combined with additional navigation data.
- The OpenStreetMap (OSM) project started in 2004 in London and can be considered as a product of the development of today’s Web 2.0 that relies on a network of participating individuals that ties together the updating and exchanging of information [22]. Therefore, the integrity and coverage depends on the dedication of the people willing to map places and add information. User contribution is a core part of this crowdsourced project and given that anybody can edit OSM, rapid changes can be updated continuously. Hence, not only geographical trained persons, but rather amateurs can contribute to this patchwork project. With the collaboration of supporters, geographic information can be supplemented by ancillary information including names, cultural, or environmental information, which cannot be determined by remote sensing [23,24]. For completion of the maps, GPS tracks, satellite imagery, out-of-copyright maps, and aerial imagery was used. Aside from individual user participation, the import of already available public domain geographical information plays a major role [25].
- Four Copernicus high resolution layers belonging to the pan-European section of the Copernicus program each providing information on a single LU/LC type, namely imperviousness (ranging 0–100%), forest (no forest, broadleaved, or coniferous forest), wetlands (binary), and permanent water bodies (binary). The wall-to-wall layers are generated at 20 m spatial resolution and cover 39 EEA Member States (5.8 million km2). The main data bases for the multispectral and object-oriented classification approach are multitemporal HR satellite imagery plus ancillary data available (e.g., vegetation indices, biophysical parameters) [26]. The maps are semi automatically produced in a collaborative initiative between the EEA, industry, and the EEA Member States.
- GlobeLand30-2010 (GL30) is a seamless LU/LC data set with a global coverage at 30 m spatial resolution, developed mainly from Landsat and Chinese Huanjing-1 (HJ-1) satellite imagery. Ten major LU/LC classes are labeled, which are cultivated land, forest, grassland, shrubland, wetland, water bodies, tundra, artificial surfaces, bare land, and permanent snow and ice. Classification was implemented through pixel-based classification with subsequent object filtering to reduce the salt and pepper phenomenon [27,28].
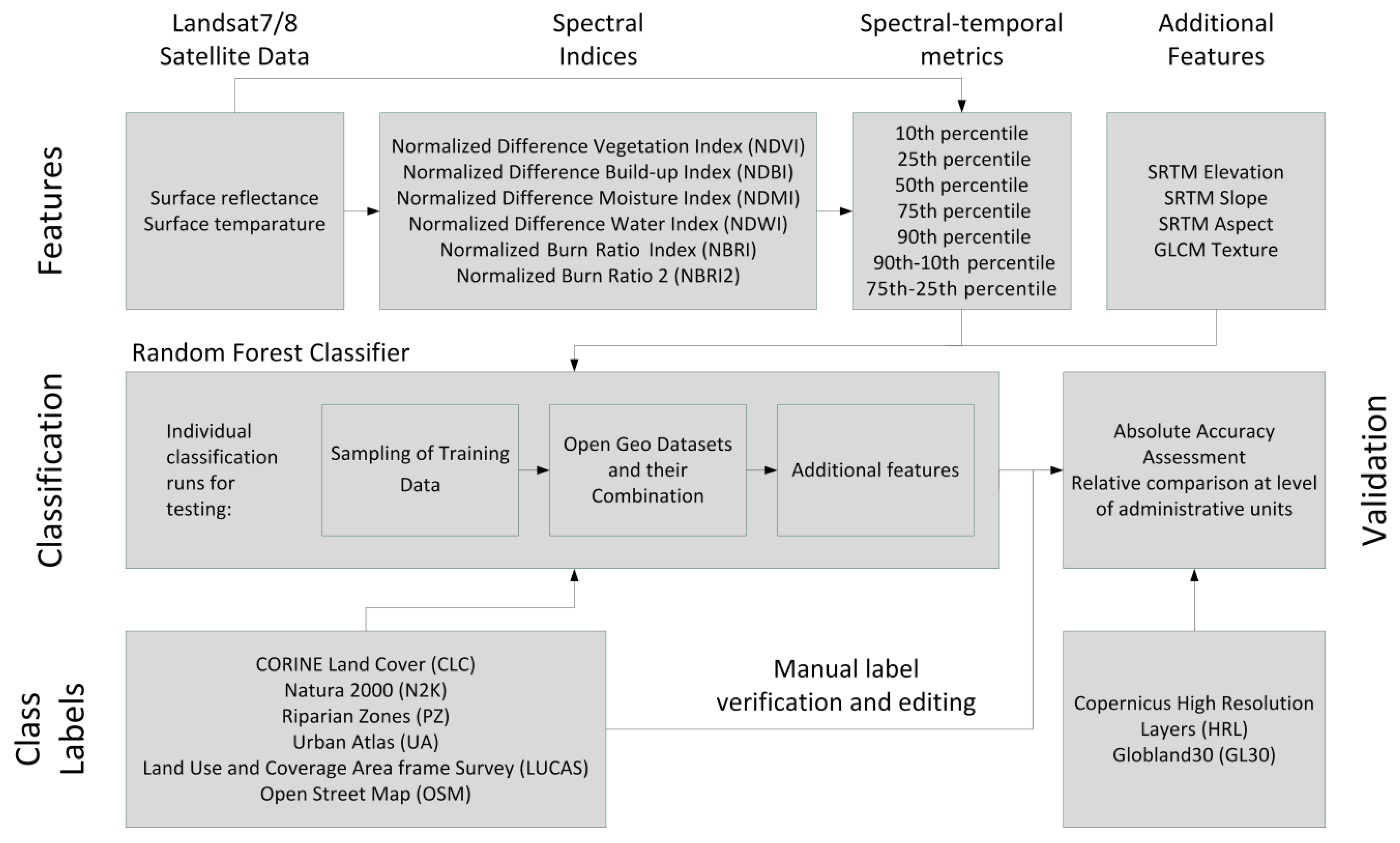
3. Methods
3.1. Preparation of Land Use and Land Cover Data Sets
3.2. Processing of Satellite Imagery
3.3. Classification
3.3.1. Sampling of Training Data
3.3.2. Data Sets for Training Data Generation and Their Combination
3.3.3. Inclusion of Additional Input Features
3.4. Accuracy Assessment
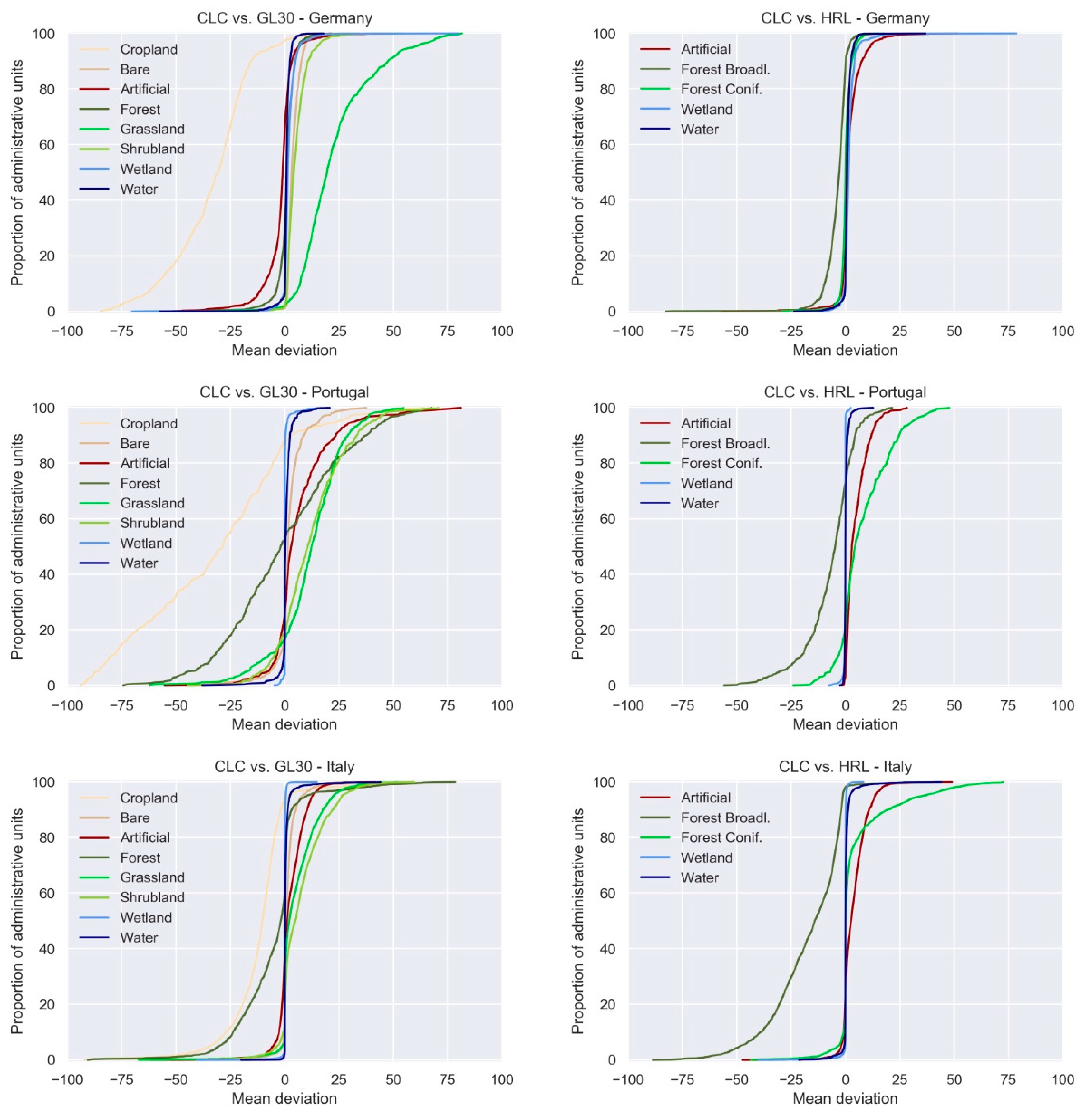
3.5. Comparison with Similar pan-European Open Land Cover Products
4. Results
4.1. Sampling of Training Data
4.2. Data Sets for Training Data Generation and Their Combination
4.3. Inclusion of Additional Input Features
4.4. Comparison with Open Land Cover Products
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A
References
- Kuenzer, C.; Leinenkugel, P.; Vollmuth, M.; Dech, S. Comparing global land-cover products—Implications for geoscience applications: An investigation for the trans-boundary Mekong Basin. Int. J. Remote Sens. 2014, 35, 2752–2779. [Google Scholar] [CrossRef]
- Herold, M.; Woodstock, C.E.; Loveland, T.R.; Townshend, J.; Brady, M.; Steenmans, C.; Schmullius, C.C. Land-cover observations as part of a global earth observation system of systems (GEOSS): Progress, activities, and prospects. IEEE Syst. J. 2008, 2, 414–423. [Google Scholar] [CrossRef]
- Global Earth Observation System of Systems GEOSS: 10-Year Implementation Plan Reference Document. 2005. Available online: http://earthobservations.org/documents/10-Year%20Implementation%20Plan.pdf (accessed on 24 June 2018).
- Lamine, S.; Petropoulos, G.P.; Kumar Singh, S.; Szabó, S.; Bachari, N.; Srivastava, P.K.; Suman, S. Quantifying Land Use/Land Cover Spatio-Temporal Landscape Pattern Dynamics From Hyperion Using SVMs Classifier and FRAGSTATS®. Geocarto Int. 2017, 1–47. [Google Scholar] [CrossRef]
- Breger, P.; Malacarne, M.; Podaire, A.; Campbell, G.; Doherty, M.; Bruzzi, S. Global Monitoring for Environment and Security (GMES): The Services Establishing an Initial GMES Capacity. In Proceedings of the 31st International Symposium on Remote Sensing of Environment, Saint Petersburg, Russia, 20–24 June 2005. [Google Scholar]
- Pérez-Hoyos, A.; García-Haro, F.J.; San-Miguel-Ayanz, J. Conventional and fuzzy comparisons of large scale land cover products: Application to CORINE, GLC2000, MODIS and GlobCover in Europe. ISPRS J. Photogramm. Remote Sens. 2012, 74, 185–201. [Google Scholar] [CrossRef]
- Rogan, J.; Chen, D. Remote sensing technology for mapping and monitoring land-cover and land-use change. Prog. Plan. 2004, 61, 301–325. [Google Scholar] [CrossRef]
- Lee, C.; Gasster, S.D.; Plaza, A.; Chang, C.-I.; Huang, B. Recent Developments in High Performance Computing for Remote Sensing: A Review. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 508–527. [Google Scholar] [CrossRef]
- Cihlar, J. Land cover mapping of large areas from satellites: Status and research priorities. Int. J. Remote Sens. 2000, 21, 1093–1114. [Google Scholar] [CrossRef]
- Mack, B.; Leinenkugel, P.; Kuenzer, C.; Dech, S. A semi-automated approach for the generation of a new land use and land cover product for Germany based on Landsat time-series and Lucas in-situ data. Remote Sens. Lett. 2017, 8, 244–253. [Google Scholar] [CrossRef]
- Kobrick, M. On the Toes of Gianst—How SRTM was Born. Photogramm. Eng. Remote Sens. 2006, 72, 206–210. [Google Scholar]
- European Environment Agency. The Thematic Accuracy of Corine Land Cover 2000—Assessment Using LUCAS; 2006; ISBN 978-92-9167-844-0. Available online: https://www.eea.europa.eu/publications/technical_report_2006_7 (accessed on 12 March 2018).
- Komp, K.-U. High Resolution Land Cover/Land Use Mapping of Large Areas Current Status and Upcoming Trends. Photogramm.-Fernerkund.-Geoinf. 2015, 2015, 395–410. [Google Scholar] [CrossRef]
- Manakos, I.; Braun, M. (Eds.) Land Use and Land Cover Mapping in Europe: Practices & Trends; Remote Sensing and Digital Image Processing; Springer: Dordrecht, The Netherlands, 2014; ISBN 978-94-007-7969-3. [Google Scholar]
- Eurostat LUCAS 2012 (Land Use/Cover Area Frame Survey), Technical Reference Document C3. 2013, p. 79. Available online: https://ec.europa.eu/eurostat/documents/205002/208012/LUCAS2012_C3-Classification_20131004_0.pdf (accessed on 11 June 2018).
- Eurostat LUCAS 2012 (Land Use/Cover Area Frame Survey), Technical Reference Document C1. 2013, p. 74. Available online: https://ec.europa.eu/eurostat/documents/205002/208012/LUCAS2012_C1-InstructionsRevised_20130110b.pdf/10f750e5-5ea0-4084-a0e7-2ca36c8f400c (accessed on 11 June 2018).
- Buck, O.; Haub, C.; Woditsch, S.; Lindemann, D.; Kleinewillinghöfer, L.; Hazeu, G.; Kosztra, B.; Kleeschulte, S.; Arnold, S.; Hölzl, M. Analysis of the LUCAS Nomenclature and Proposal for Adaptation of the Nomenclature in View of Its Use by the Copernicus Land Monitoring Services; European Environment Agency: Copenhagen, Denmark, 2015; p. 142. [Google Scholar]
- Martino, L.; Fritz, M. New Insight into land Cover and Land Use in Europe. Stat. Focus 2008, 33, 1–8. [Google Scholar]
- Eurostat LUCAS 2015 (Land Use/Cover Area Frame Survey), Technical Reference Document C3. 2015, p. 93. Available online: https://ec.europa.eu/eurostat/documents/205002/6786255/LUCAS2015-C3-Classification-20150227.pdf/969ca853-e325-48b3-9d59-7e86023b2b27 (accessed on 11 June 2018).
- European Environment Agency Copernicus Initial Operations 2011–2013–Land Monitoring Service Local Component: LC/LU Mapping of a Selection of Natura2000 (N2K) Sites; Natura2000 Product Specifications; European Environment Agency: Copenhagen, Denmark, 2015; p. 10.
- Naiman, R.J.; Decamps, H. The Ecology of Interfaces: Riparian Zones. Annu. Rev. Ecol. Syst. 1997, 28, 621–658. [Google Scholar] [CrossRef] [Green Version]
- O’Reilly, T. What Is Web 2.0: Design Patterns and Business Models for the Next Generation of Software; University Library of Munich: Munich, Germany, 2007. [Google Scholar]
- Goodchild, M.F. Citizens as Voluntary Sensors: Spatial Data Infrastrcuture in the World of Web 2.0. Int. J. Spat. Data Infrastruct. Res. 2007, 2, 24–32. [Google Scholar]
- Haklay, M. How Good is Volunteered Geographical Information? A Comparative Study of OpenStreetMap and Ordnance Survey Datasets. Environ. Plan. B Plan. Des. 2010, 37, 682–703. [Google Scholar] [CrossRef] [Green Version]
- Haklay, M.; Weber, P. OpenStreetMap: User-Generated Street Maps. IEEE Pervasive Comput. 2008, 7, 12–18. [Google Scholar] [CrossRef]
- Congedo, L.; Sallustio, L.; Munafò, M.; Ottaviano, M.; Tonti, D.; Marchetti, M. Copernicus high-resolution layers for land cover classification in Italy. J. Maps 2016, 12, 1195–1205. [Google Scholar] [CrossRef] [Green Version]
- National Geomatics Center of China (NGCC). 30-m Global Land Cover Dataset—GlobeLand30; NGCC: Bejing, China, 2014; p. 25. [Google Scholar]
- Ran, Y.; Li, X. First comprehensive fine-resolution global land cover map in the world from China—Comments on global land cover map at 30-m resolution. Sci. China Earth Sci. 2015, 58, 1677–1678. [Google Scholar] [CrossRef]
- Copernicus Copernicus Land Monitoring Service. Available online: https://land.copernicus.eu/ (accessed on 19 June 2018).
- Geofabrik GmbH Geofabrik Downloads—OpenStreetMap Data. Available online: http://download.geofabrik.de/ (accessed on 24 August 2016).
- Eurostat Eurostat Land Cover/Use Statistics (LUCAS). Available online: https://ec.europa.eu/eurostat/web/lucas/ (accessed on 29 March 2018).
- Maucha, G.; Büttner, G.; Kosztra, B. European Validation of GMES FTS Soil Sealing Enhancement Data. In Proceedings of the 32nd EARSeL Symposium, Remote Sensing and Geoinformation, Mikonos, Greece, 21–24 May 2011; pp. 223–238. [Google Scholar]
- Jansen, L.J.M. Harmonization of land use class sets to facilitate compatibility and comparability of data across space and time. J. Land Use Sci. 2006, 1, 127–156. [Google Scholar] [CrossRef]
- Batista e Silva, F.; Lavalle, C.; Koomen, E. A procedure to obtain a refined European land use/cover map. J. Land Use Sci. 2013, 8, 255–283. [Google Scholar] [CrossRef]
- Estima, J.; Painho, M. Exploratory Analysis of OpenStreetMap for Land Use Classification. In Proceedings of the Second ACM SIGSPATIAL International Workshop on Crowdsourced and Volunteered Geographic Information, Orlando, FL, USA, 5–8 November 2013; ACM: New York, NY, USA, 2013; pp. 39–46. [Google Scholar]
- Zhu, Z.; Woodcock, C.E. Object-based cloud and cloud shadow detection in Landsat imagery. Remote Sens. Environ. 2012, 118, 83–94. [Google Scholar] [CrossRef]
- Zhu, Z.; Wang, S.; Woodcock, C.E. Improvement and expansion of the Fmask algorithm: Cloud, cloud shadow, and snow detection for Landsats 4-7, 8, and Sentinel 2 images. Remote Sens. Environ. 2015, 159, 269–277. [Google Scholar] [CrossRef]
- Richter, R.; Schläpfer, D. Atmospheric/Topographic Correction for satellite Imagery, ATCOR-2/3 User Guide, version 6.3; DLR and ReSe Applications: Wessling, Germany; Wil, Switzerland, 2016; p. 263. [Google Scholar]
- Richter, R.; Kellenberger, T.; Kaufmann, H. Comparison of Topographic Correction Methods. Remote Sens. 2009, 1, 184–196. [Google Scholar] [CrossRef] [Green Version]
- Griffiths, P.; Müller, D.; Kuemmerle, T.; Hostert, P. Agricultural land change in the Carpathian ecoregion after the breakdown of socialism and expansion of the European Union. Environ. Res. Lett. 2013, 8, 045024. [Google Scholar] [CrossRef]
- Griffiths, P.; Kuemmerle, T.; Baumann, M.; Radeloff, V.C.; Abrudan, I.V.; Lieskovsky, J.; Munteanu, C.; Ostapowicz, K.; Hostert, P. Forest disturbances, forest recovery, and changes in forest types across the Carpathian ecoregion from 1985 to 2010 based on Landsat image composites. Remote Sens. Environ. 2014, 151, 72–88. [Google Scholar] [CrossRef]
- Hansen, M.; Potapov, P.; Margono, B.; Stehman, S.; Turubanova, S.; Tyukavina, A. Response to Comment on “High-resolution global maps of 21st-century forest cover change.”. Science 2014, 344, 981. [Google Scholar] [CrossRef]
- Müller, H.; Rufin, P.; Griffiths, P.; Barros Siqueira, A.J.; Hostert, P. Mining dense Landsat time series for separating cropland and pasture in a heterogeneous Brazilian savanna landscape. Remote Sens. Environ. 2015, 156, 490–499. [Google Scholar] [CrossRef] [Green Version]
- Rufin, P.; Müller, H.; Pflugmacher, D.; Hostert, P. Land use intensity trajectories on Amazonian pastures derived from Landsat time series. Int. J. Appl. Earth Obs. Geoinf. 2015, 41, 1–10. [Google Scholar] [CrossRef]
- Balzter, H.; Cole, B.; Thiel, C.; Schmullius, C. Mapping CORINE Land Cover from Sentinel-1A SAR and SRTM Digital Elevation Model Data using Random Forests. Remote Sens. 2015, 7, 14876–14898. [Google Scholar] [CrossRef] [Green Version]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabelling on random forest performance for large area land cover classification using the ensemble margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Japkowicz, N.; Stephen, S. The Class Imbalance Problem: A Systematic Study. Intell. Data Anal. 2002, 6, 429–449. [Google Scholar] [CrossRef]
- Freeman, E.A.; Moisen, G.G.; Frescino, T.S. Evaluating effectiveness of down-sampling for stratified designs and unbalanced prevalence in Random Forest models of tree species distributions in Nevada. Ecol. Model. 2012, 233, 1–10. [Google Scholar] [CrossRef]
- Lu, D.; Batistella, M. Exploring TM image texture and its relationships with biomass estimation in Rondônia, Brazilian Amazon. Acta Amaz. 2005, 35, 249–257. [Google Scholar] [CrossRef]
- Van Rijsbergen, C.J. Information Retrieval, 2nd ed.; Butterworths: London, UK, 1979. [Google Scholar]
- Bilenko, M.; Mooney, R.; Cohen, W.; Ravikumar, P.; Fienberg, S. Adaptive name matching in information integration. IEEE Intell. Syst. 2003, 18, 16–23. [Google Scholar] [CrossRef]
- Hijmans, R.; Garcia, N.; Wieczorek, J. Global Administrative Areas Database (GADM), Version 2.8. Available online: https://gadm.org/ (accessed on 14 July 2018).
- Jokar Arsanjani, J.; See, L.; Tayyebi, A. Assessing the suitability of GlobeLand30 for mapping land cover in Germany. Int. J. Digit. Earth 2016, 9, 873–891. [Google Scholar] [CrossRef]
- Jokar Arsanjani, J. Openstreetmap in GIScience; Springer: New York, NY, USA, 2015; ISBN 978-3-319-14279-1. [Google Scholar]
- Hagenauer, J.; Helbich, M. Mining urban land-use patterns from volunteered geographic information by means of genetic algorithms and artificial neural networks. Int. J. Geogr. Inf. Sci. 2012, 26, 963–982. [Google Scholar] [CrossRef]
- Ali, A.L.; Schmid, F.; Al-Salman, R.; Kauppinen, T. Ambiguity and Plausibility: Managing Classification Quality in Volunteered Geographic Information. In Proceedings of the 22nd ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Dallas, TX, USA, 4–7 November 2014; ACM: New York, NY, USA, 2014; pp. 143–152. [Google Scholar]
- Rodriguez-Galiano, V.F.; Ghimire, B.; Rogan, J.; Chica-Olmo, M.; Rigol-Sanchez, J.P. An assessment of the effectiveness of a random forest classifier for land-cover classification. ISPRS J. Photogramm. Remote Sens. 2012, 67, 93–104. [Google Scholar] [CrossRef]
- Inglada, J.; Vincent, A.; Arias, M.; Tardy, B.; Morin, D.; Rodes, I. Operational High Resolution Land Cover Map Production at the Country Scale Using Satellite Image Time Series. Remote Sens. 2017, 9, 95. [Google Scholar] [CrossRef]
- Heinl, M.; Walde, J.; Tappeiner, G.; Tappeiner, U. Classifiers vs. input variables—The drivers in image classification for land cover mapping. Int. J. Appl. Earth Obs. Geoinf. 2009, 11, 423–430. [Google Scholar] [CrossRef]
- Gallego, J.; Bamps, C. Using CORINE land cover and the point survey LUCAS for area estimation. Int. J. Appl. Earth Obs. Geoinf. 2008, 10, 467–475. [Google Scholar] [CrossRef]
- Johnson, B.A.; Iizuka, K. Integrating OpenStreetMap crowdsourced data and Landsat time-series imagery for rapid land use/land cover (LULC) mapping: Case study of the Laguna de Bay area of the Philippines. Appl. Geogr. 2016, 67, 140–149. [Google Scholar] [CrossRef]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Dedieu, G. Assessing the robustness of Random Forests to map land cover with high resolution satellite image time series over large areas. Remote Sens. Environ. 2016, 187, 156–168. [Google Scholar] [CrossRef]
- Liu, X.-Y.; Wu, J.; Zhou, Z.-H. Exploratory Undersampling for Class-Imbalance Learning. IEEE Trans. Syst. Man Cybern. B 2009, 39, 539–550. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. JAIR 2002, 16, 321–357. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Study Area | CLC Samples | OSM Samples | CLC Accuracy | OSM Accuracy | ||||
|---|---|---|---|---|---|---|---|---|---|
| Buffer | 50 m | 100 m | 50 m | 100 m | 50 m | 100 m | 50 m | 100 m | |
| Centroid | Germany | 33,835 | 30,274 | 128,297 | 24,847 | 59.4 | 59.4 | 46.6 | 45.9 |
| Portugal | 40,524 | 35,184 | 14,503 | 6811 | 56.3 | 56.4 | 50.6 | 48.8 | |
| Italy | 34,574 | 29,455 | 55,613 | 12,835 | 67.3 | 67.5 | 52.0 | 43.9 | |
| Grid | Germany | 32,467 | 28,716 | 4401 | 2899 | 50.5 | 49.3 | 37.2 | 38.6 |
| Portugal | 21,475 | 17,674 | 1705 | 1196 | 49.8 | 48.4 | 42.8 | 41.7 | |
| Italy | 25,317 | 20,979 | 1228 | 711 | 55.3 | 53.7 | 47.1 | 44.5 | |
| Grid–Centroid | Germany | 60461 | 54,852 | 129,816 | 59,874 | 58.6 | 57.3 | 45.9 | 44.1 |
| Portugal | 54,626 | 47,834 | 14,990 | 7193 | 56.7 | 57.3 | 50.7 | 48.7 | |
| Italy | 53,512 | 46,234 | 55,861 | 13,054 | 64.2 | 65.5 | 52.8 | 52.6 | |
| CLC | N2K | RPZ | UA | OSM | LUC | CLC-ext 1 | ALL | CLC-M | CLC-MC | |
|---|---|---|---|---|---|---|---|---|---|---|
| Germany | 60.8 | 53.1 | 57.4 | 53.9 | 43.9 | 48.2 | 58.8 | 60.4 | 66.8 | 70.9 |
| Portugal | 55.3 | 45.4 | 56.1 | 49.7 | 50.1 | 44.3 | 58.1 | 59.2 | 58.2 | 58.9 |
| Italy | 67.3 | 59.3 | 57.5 | 51.8 | 50.6 | 51.2 | 65.2 | 65.7 | 67.2 | 66.3 |
| Input Features | Germany | Portugal | Italy |
|---|---|---|---|
| Spectral | 70.9 | 58.9 | 66.3 |
| Spectral + texture | 71.6 | 58.8 | 67.9 |
| Spectral + topo | 72..1 | 61.3 | 68.3 |
| Spectral + texture + topo | 72.4 | 60.3 | 70.0 |
| LC Class | Germany | Portugal | Italy | |||
|---|---|---|---|---|---|---|
| CLC | Ref | CLC | Ref | CLC | Ref | |
| GL30 | 81.6 | 62.8 | 69.3 | 53.0 | 76.0 | 66.8 |
| HRL Artificial | 97.9 | 98.4 | 99.0 | 99.1 | 98.1 | 98.9 |
| HRL Forest broadleaved | 96.8 | 93.6 | 95.1 | 93.4 | 95.3 | 88.2 |
| HRL Forest coniferous | 98.0 | 98.1 | 98.2 | 96.5 | 95.3 | 97.6 |
| HRL Wetland | 90.4 | 86.1 | 86.7 | 90.4 | 88.0 | 90.2 |
| HRL Water | 98.7 | 98.5 | 91.6 | 96.3 | 97.1 | 93.7 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Leinenkugel, P.; Deck, R.; Huth, J.; Ottinger, M.; Mack, B. The Potential of Open Geodata for Automated Large-Scale Land Use and Land Cover Classification. Remote Sens. 2019, 11, 2249. https://doi.org/10.3390/rs11192249
Leinenkugel P, Deck R, Huth J, Ottinger M, Mack B. The Potential of Open Geodata for Automated Large-Scale Land Use and Land Cover Classification. Remote Sensing. 2019; 11(19):2249. https://doi.org/10.3390/rs11192249
Chicago/Turabian StyleLeinenkugel, Patrick, Ramona Deck, Juliane Huth, Marco Ottinger, and Benjamin Mack. 2019. "The Potential of Open Geodata for Automated Large-Scale Land Use and Land Cover Classification" Remote Sensing 11, no. 19: 2249. https://doi.org/10.3390/rs11192249
APA StyleLeinenkugel, P., Deck, R., Huth, J., Ottinger, M., & Mack, B. (2019). The Potential of Open Geodata for Automated Large-Scale Land Use and Land Cover Classification. Remote Sensing, 11(19), 2249. https://doi.org/10.3390/rs11192249