1. Introduction
With the great development of the Internet of Things (IoT), short-range low-power radar sensors for smart sensing are attracting increasingly more interest mainly due to the advantages of robustness to weather and lighting conditions, penetrability of obstacles, low power consumption and protecting visual privacy [
1,
2]. IoT is treated as the future trend in the global technological development after the Internet, and it connects all things to the Internet for information sensing and exchange, and data computing [
3]. For the smart sensing function of IoT, human activity recognition and person identification are crucial steps, and they have been widely adopted in indoor real-time positioning, activity monitoring, elderly fall detection, and so forth.
Person identification and activity classification have both been investigated in prior work [
4]. Most of these systems are based on optical cameras for collecting information. However, optical devices have many limitations such as sensitivity to light or weather conditions and a high demand for computational resources, which hinders the application of such devices for human activity recognition and identification, especially with portable devices that have limited computational capabilities. Radar is considered to be a powerful approach to overcome these drawbacks. Furthermore, radar can be applied to more scenarios and effectively protect visual privacy.
Recently, radar-based person identification and activity recognition have attracted increasing attention. When a human target is moving in the line of sight of a radar, the returned signals are modulated by the movement. In addition to the main Doppler shift caused by the human torso, the movements of body parts form micro-Doppler (MD) shifts, which is commonly called a target MD signature. Generally, radar MD signatures are both target and action specific, and can hence be used to recognize targets and classify activities. For example, Vandersmissen et al. [
5] demonstrated that MD features are able to characterize individual humans in realistic scenarios, which makes radar-based person identification possible. Handcrafted features such as extreme frequency ratio, torso frequency, period of motion and total Doppler bandwidth [
6] are extracted from MD spectrograms to characterize human motions. However, the activity recognition and person identification solutions based on hand-crafted features are not reliable enough since Doppler and MD signatures are individual and action specific. In addition, professional knowledge is indispensable during the manual feature extraction process. Hence, automated and optimized feature extraction approaches are desired.
Recent trends in deep learning have led to a renewed interest in radar-based person identification and activity recognition due to its capability of automatically extracting features and encouraging precision. Furthermore, with the development of GPUs, it is possible to process vast amounts of data in a limited time via parallel computing techniques. Convolutional neural networks (CNNs) play a vital role in numerous deep-learning-based systems, and they have been successfully applied in the areas of object detection, image classification and so forth [
7,
8]. Although not as intuitive as natural images, an MD spectrogram, which is a two-dimensional representation of radar signals, could also be analyzed as an image. In this circumstance, a CNN that is adept at learning embedding from two-dimensional images is often utilized to process radar MD spectrograms [
5,
9].
Although closely related, activity recognition and person identification are generally treated as separate problems. It has recently been demonstrated that learning correlated tasks simultaneously can enhance the performance of individual tasks [
10,
11]. Joint activity recognition and person identification has two advantages. (1) Sharing the model between the two tasks accelerates the learning and converging process compared with applying it to a single task. (2) Multiple labels supply more information about the dataset, which is capable of regularizing the network during training. Furthermore, the computational complexity can be improved by sharing the feature extractor between the activity recognition and person identification tasks. Motivated by these advantages, we go one step beyond separate person identification and activity recognition by proposing a novel CNN-based multitask framework to complete the two tasks simultaneously. Multitask learning (MTL) [
12] aims at leveraging the relatedness among the tasks and learning embedding of each task synchronously to improve the generalization performance of the main task or all tasks. In this paper, our goal is to enhance both tasks with an MTL-based deep neural network.
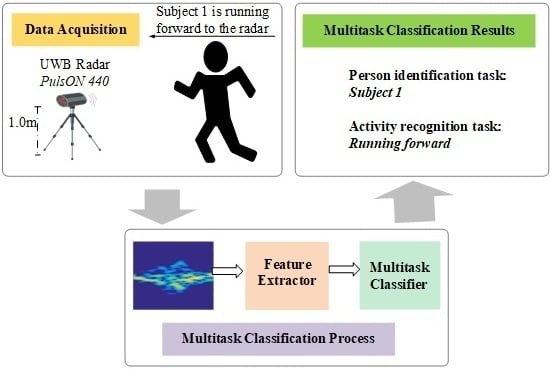
We propose a multiscale residual attention network (
MRA-Net) for joint person identification and activity recognition with radar. As shown in
Figure 1,
MRA-Net is composed of two parts: feature extractor and multitask classifier.
MRA-Net firstly extracts a common embedding from the MD signature, and then the embedding is input into fully connected (FC) layers to perform the classification of each task. In the CNN-based feature extractor, two scales of convolutional kernels are applied for extracting different-grained features from the input. The shared features entangle attributes for both activity recognition and person identification. Furthermore, the residual attention mechanism [
13] is adopted in the feature extractor to facilitate the feature learning process. Finally, a fine-grained loss weight learning (FLWL) mechanism is proposed in contrast to the methods in previous work that either treat each task equally [
14] or obtain the loss weights by greedy search [
15].
In summary, our contributions mainly include the following three aspects.
A novel multiscale residual attention network, named as MRA-Net, is proposed to jointly perform human identification and activity recognition tasks based on radar MD spectrograms. MRA-Net outperforms the state-of-the-art methods for both tasks by jointly recognizing human activities and identifying persons.
A fine-grained loss weight learning mechanism is proposed to automatically search for proper loss weights rather than equalizing or manually tuning the loss weight of each task.
Extensive experiments with state-of-the-art results have validated the feasibility of radar-based joint activity recognition and person identification, as well as the effectiveness of MRA-Net towards this issue.
The rest of this paper is organized as follows.
Section 2 briefly introduces the related work of person identification, human activity recognition and multitask learning.
Section 3 details the proposed deep multitask learning network. A measured radar micro-Doppler signature dataset is described in
Section 4. The performance metrics and implementation details are presented in
Section 5. Experimental results and analysis are provided in
Section 6.
Section 7 concludes this paper.
3. Multiscale Residual Attention Network
In this paper, we propose
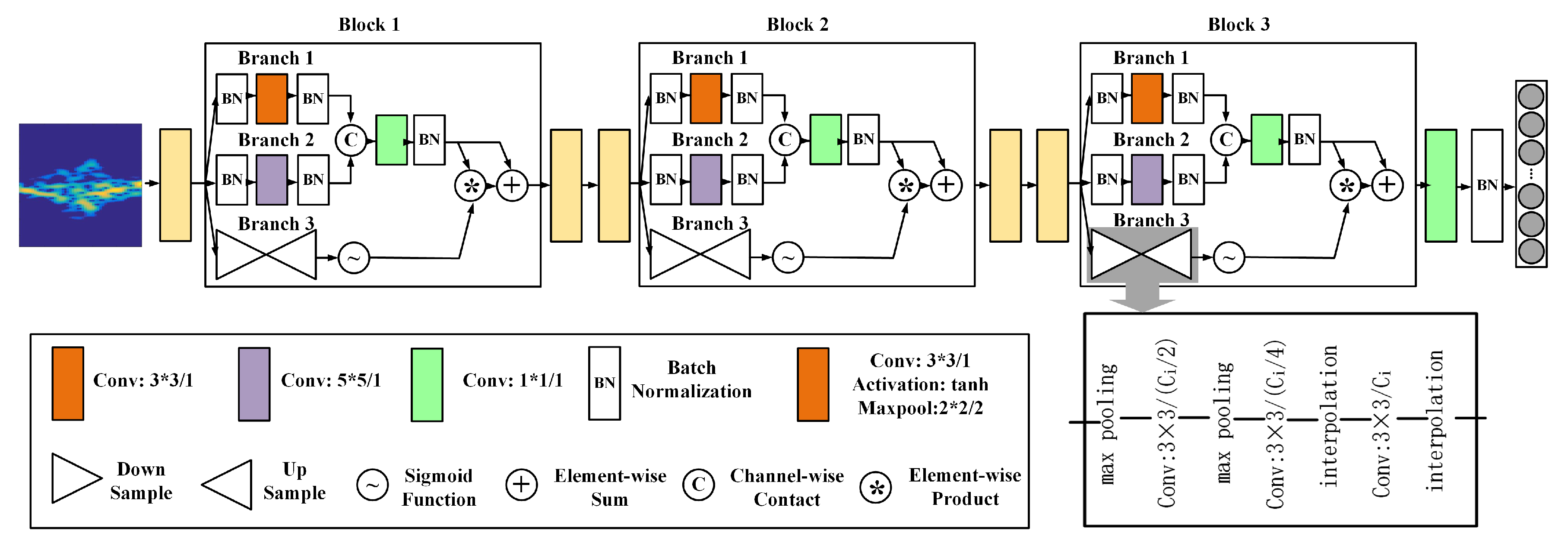
MRA-Net, which is a multiscale residual attention network for joint radar-based person identification and activity recognition. The unified network is learned end-to-end and is optimized with a multitask loss. The feature extractor part of
MRA-Net is illustrated in
Figure 2. In this part, multiscale learning and residual attention learning mechanisms are employed to facilitate the feature extracting process. Specifically, the feature extractor is composed of three blocks, and there are three branches in every block: coarse-scale learning branch, fine-scale learning branch and residual attention branch. For the multitask classifier, we propose an FLWL mechanism to automatically set the loss weights for MTL.
3.1. Multiscale Learning
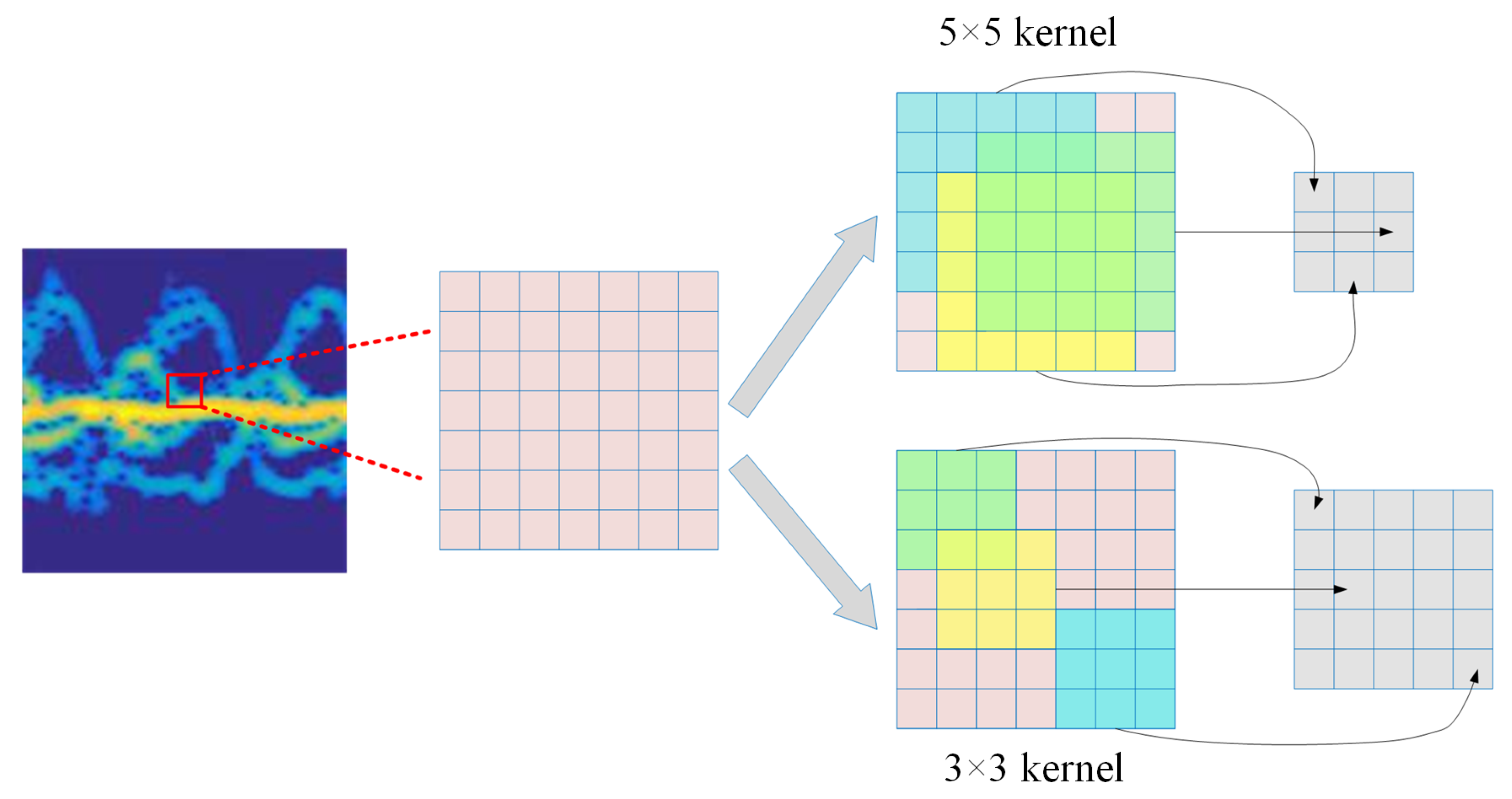
Multiscale learning mechanism is able to extract features from various granularities and learn more efficient representations [
29]. In
MRA-Net, we apply two types of convolution kernels with different receptive fields: the 3 × 3 kernel is used for fine-scale learning in Branch 1, while the 5 × 5 kernel is utilized for coarse-scale learning in Branch 2 (see
Figure 2). The intuition of employing multiscale convolution kernels is that the MD characteristics of different activities vary. For example, the MD effect of “box” is more delicate, while the MD effect of “walk” is stronger. The receptive fields of different convolution kernels match the MD features of different scales, as illustrated in
Figure 3. Due to the complementary information between different scales of convolution kernel, multiscale learning can significantly improve the performance of
MRA-Net.
In addition, the 1 × 1 kernel is also adopted for fusing the features in every block. By flexibly adjusting the number of channels, the 1 × 1 convolution kernel is capable of significantly increasing the nonlinear characteristics of the network without a loss of resolution and realizing cross-channel interaction and information integration.
3.2. Residual Attention Learning
We introduce the residual attention learning mechanism into our model to make
MRA-Net learn more attention-aware representations from the input MD signatures. The output of every block in
Figure 2 can be denoted as:
where
x represents the input of the block;
M(
x) represents the residual attention mask;
and
represent the outputs of the coarse-scale and fine-scale learning branches, respectively;
f represents the convolutional operation with a kernel size of 1 × 1; and
represents the output of the block.
In this paper, we tend to learn discriminative embedding from MD signatures for both radar-based activity recognition and person identification tasks. In a CNN, the convolution operation is achieved by sliding the convolution kernel over the feature map. Thus, the feature learning process treats each area of the input equally. However, it is obvious that the MD frequency parts in an MD signature are more representative of the corresponding activity, and thus should receive greater attention. To this end, the elaborate residual attention learning is adopted to make
MRA-Net focused, as shown in Branch 3 in
Figure 2. Residual attention learning is composed of two components: residual learning mechanism and mixed attention mechanism [
13]. The bottom-up, top-down feedforward residual attention mechanism is realized by multiple stacked attention modules that generate attention-aware features and aim at guiding more discriminative feature representations. The stacked structure is the basis of mixed attention mechanism, where different types of attention can be obtained from different attention modules. Due to the obvious performance drop caused by module stacking, residual learning mechanism is adopted for optimizing the deep model.
3.3. Fine-Grained Loss Weight Learning
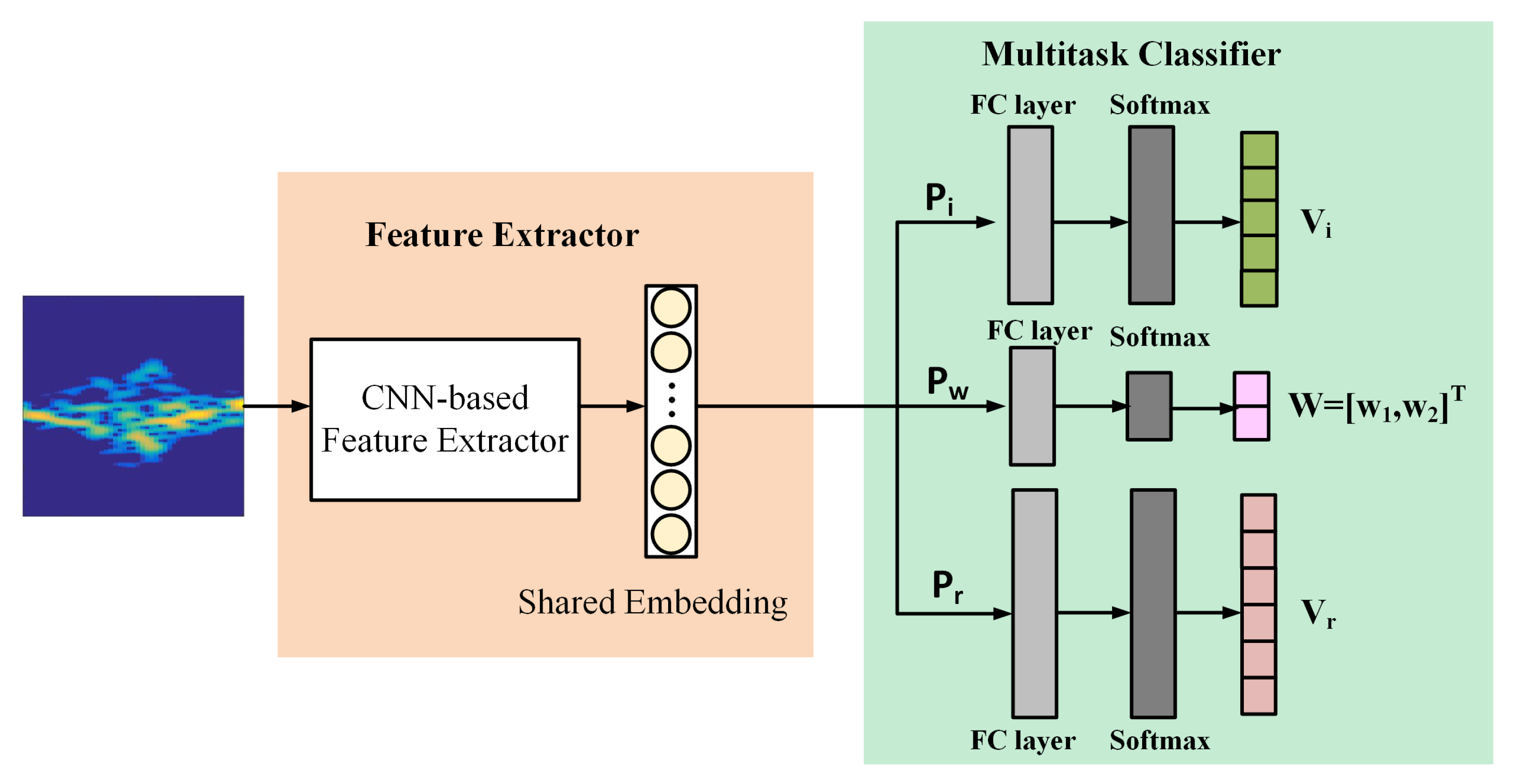
To make the multitask classifier recognize activities and identify persons more accurately, we present the FLWL mechanism in the multitask classifier, aiming to automatically assign a proper loss weight to each task and to simultaneously retain good multitask classification performance.
Given a training set
T composed of
N MD signatures and their labels:
, where
denotes the
nth input MD signature,
denotes the corresponding label of human activity, and
represents the corresponding label of person identification.
represents the high-level embedding vector of
:
where Θ denotes all parameters to be optimized in the feature extractor layers of
MRA-Net, and
g denotes the nonlinear mapping from the input signature to the shared embedding.
For a multitask classifier, the loss weight setting for the tasks are vital to the classification performance. During the multitask training process, suppose that the training losses of the activity recognition task and person identification task are represented as
and
, respectively. Then, the overall loss is computed as the weighted sum of the two individual losses, which is written as,
where
represents the overall loss of the model,
represents the loss weight parameter of the activity recognition task, and
represents the loss weight parameter of the person identification task.
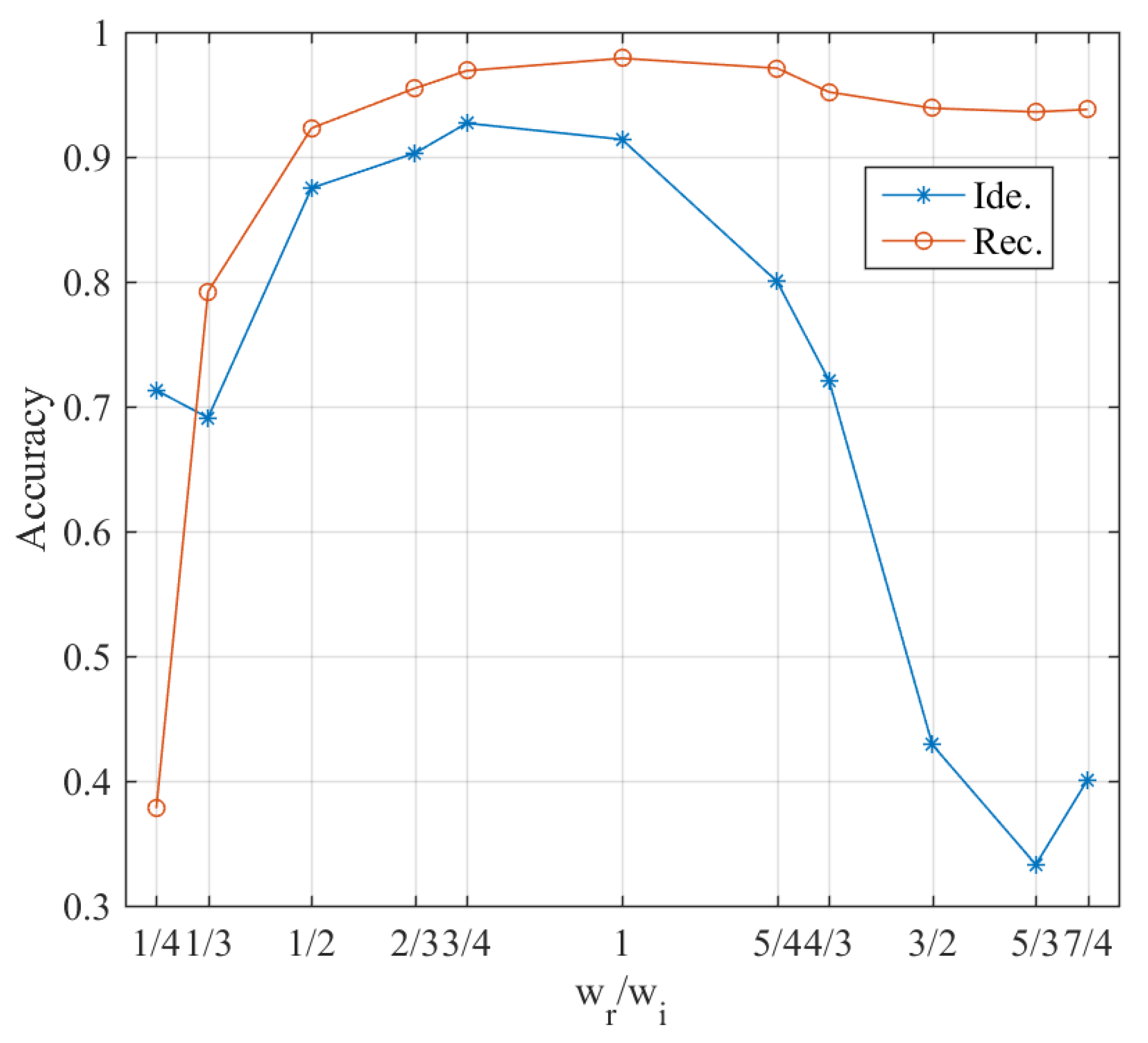
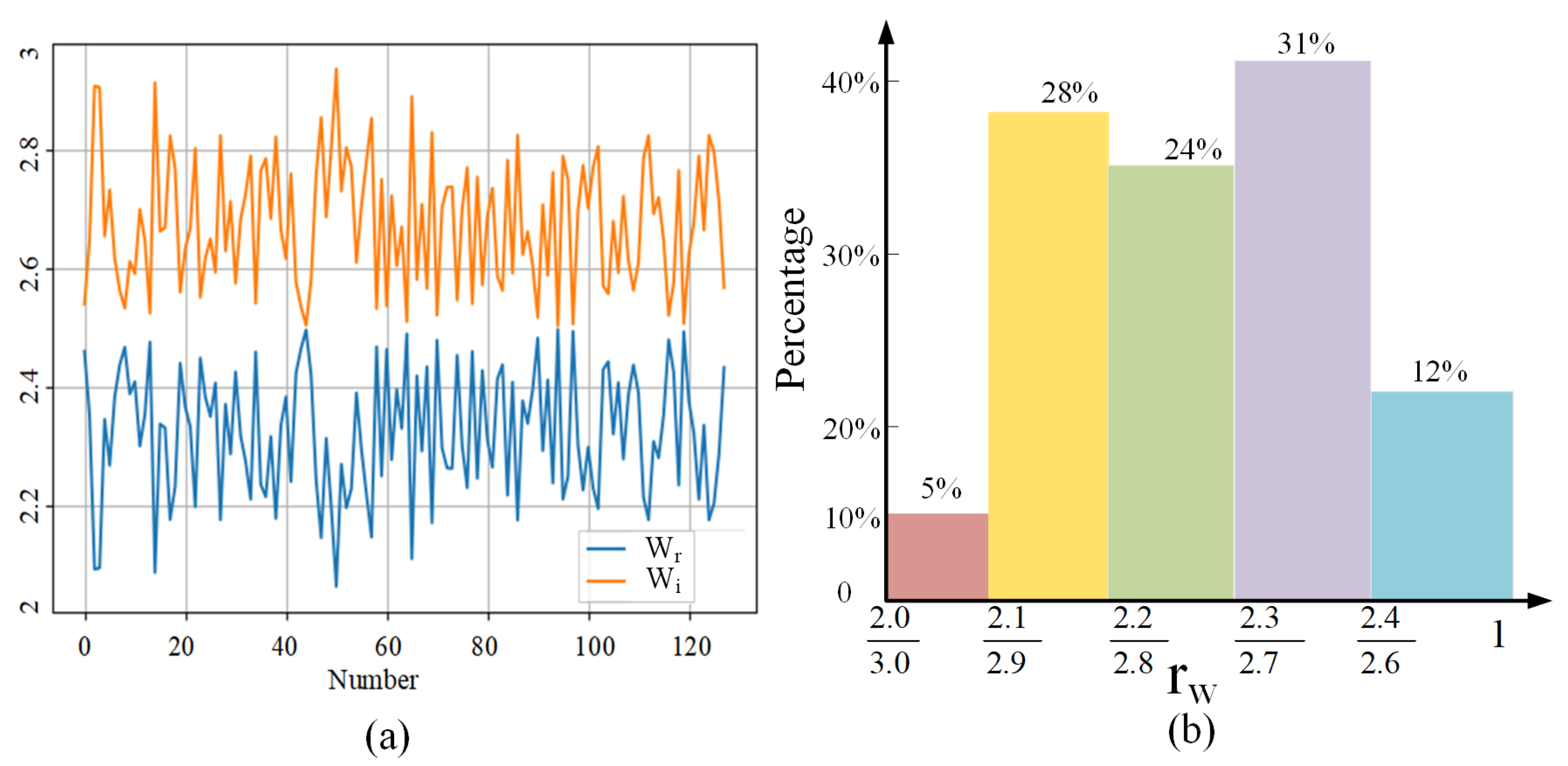
The conventional approach to set the loss weights is the greedy search algorithm, which is affected by the search step size. A large step size causes the search process difficulty in converging, while a small step size is time-consuming. Under this circumstance, we first utilize a greedy search algorithm for initialization and locate the rough ratio range of the two loss weights. Several typical ratio values
are adopted for the experiment and the results are illustrated in
Figure 4. As shown in this figure, the person identification task is more sensitive to
compared with the activity classification task. Furthermore, when
is between
and 1, the accuracies of person identification and activity classification both retain at a high level.
Based on the result of the rough greedy search, we elaborate the multitask classifier illustrated in
Figure 1. Specifically, in addition to the two branches
and
for activity recognition and person identification, we propose another branch
for automatic weight learning. Suppose that
and
are the weight matrix and bias vector in the FC layer of
, respectively. Then, the output is fed into a
Softmax layer,
Consequently, the output of is , where and 0 .
Then, we design an overall loss function
for
MRA-Net as follows:
where
denotes the cross-entropy loss function of the person identification task and
denotes the cross-entropy loss function of the activity classification task. Therefore, the weight ratio
can be expressed as:
where
represents the loss weight for activity recognition and
represents the loss weight for person identification. In this way,
MRA-Net is optimized under the limit of
, which is between
and 1. Then, the fine-grained and optimal weights are automatically assigned for both tasks. With the proposed FLWL algorithm, the multitask classifier is able to automatically assign the loss weights and learn discriminative features for both tasks subsequently.
4. Dataset Description
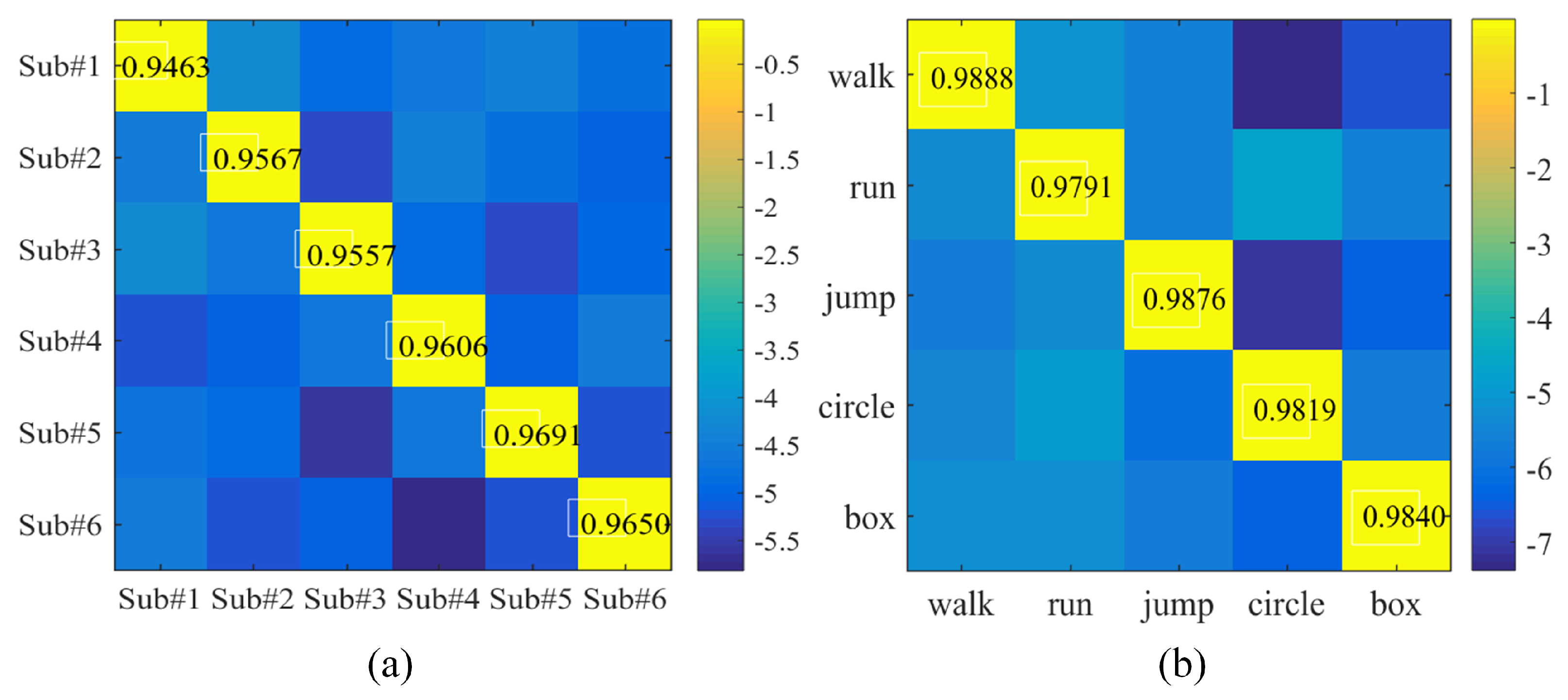
In this work, we construct a measured radar MD signature dataset and verify the performance of
MRA-Net with an FLWL mechanism. The measured MD signature data are collected with a UWB radar module named
PulsON 440 (see
Figure 5a), and the recording parameters are given in
Table 1. The experiment is performed in an indoor environment. The radar is placed at a height of 1 m, and activities are performed in the line of sight of the radar. The measurement range of the radar is between 1.5 m and 7.5 m. The experimental deployment diagram is illustrated in
Figure 5b. In each experimental scenario, a subject performs a specified activity continuously for approximately 1.5 s. Thirty scenarios corresponding to five activities performed by six subjects are included in this dataset. Basic characteristics of the six subjects are recorded in
Table 2, and the five activities are listed as follows: (a) directly walking towards/away from the radar (walk); (b) boxing while standing in place (box); (c) directly running towards/away from the radar (run); (d) jumping forward (jump); and (e) running in circle (circle).
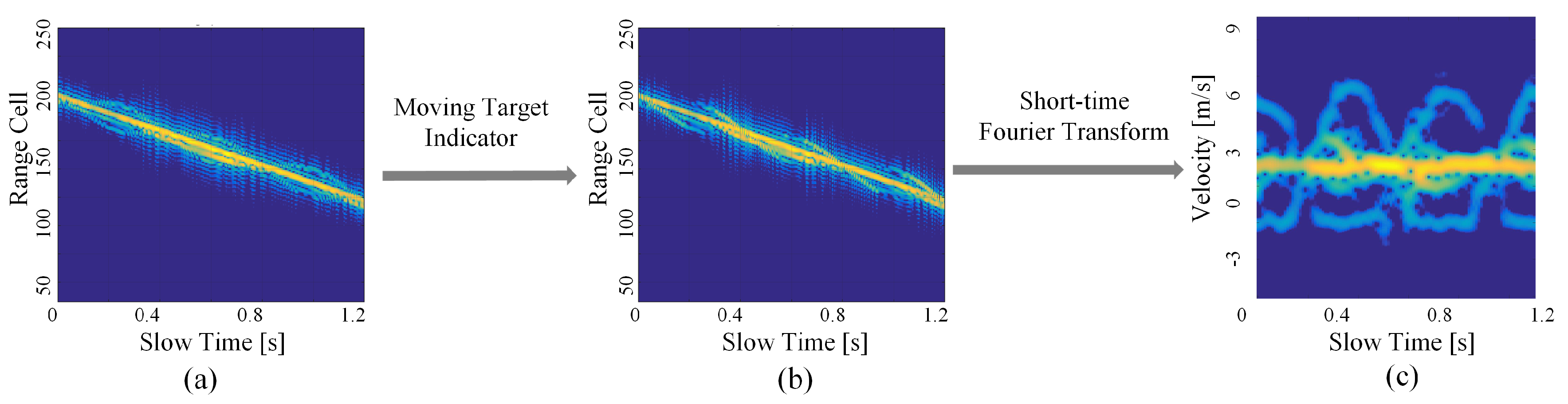
The radar data preprocessing is shown in
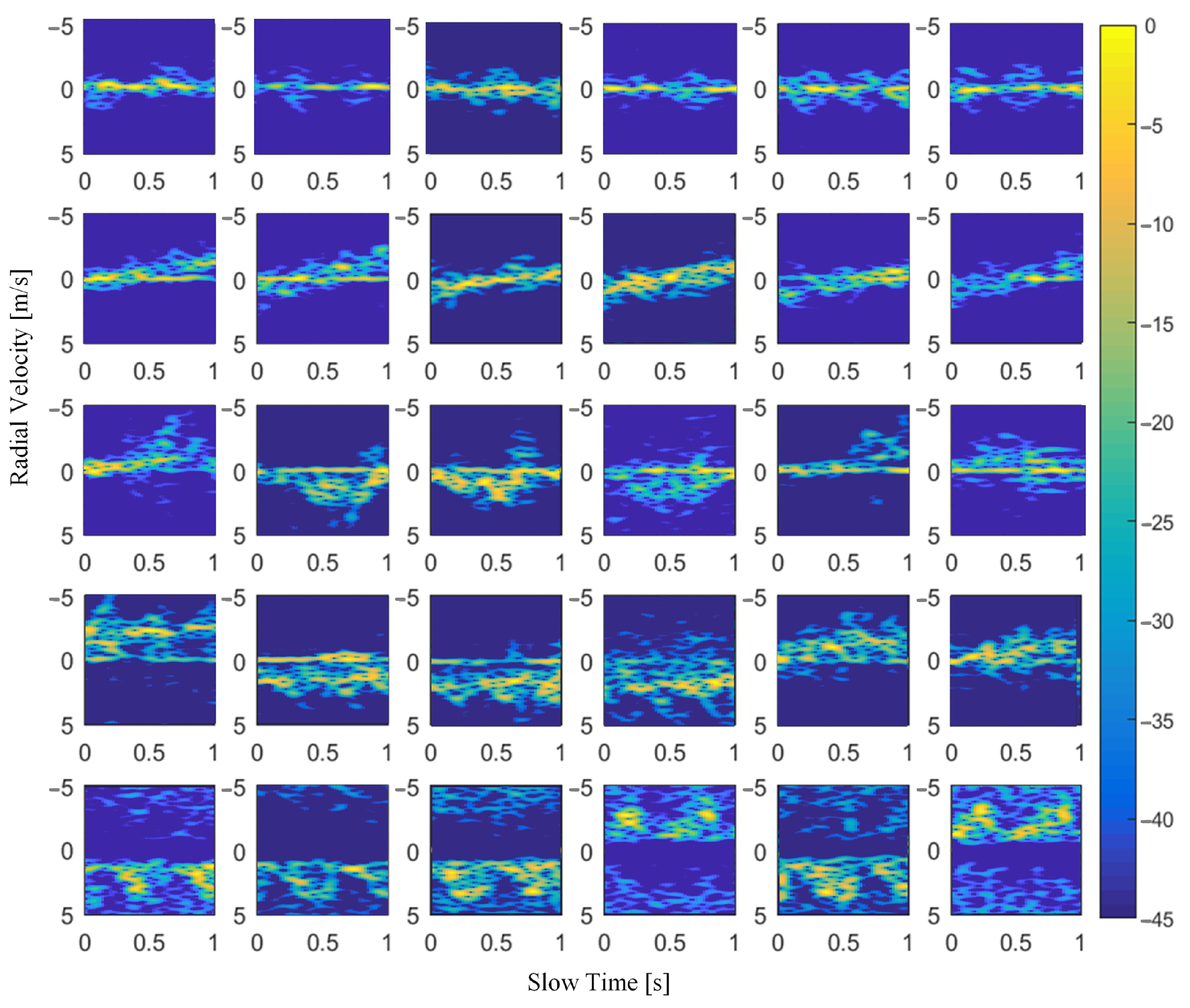
Figure 6. Background clutter suppression via the moving target indicator approach is firstly performed on the raw data, and short-time Fourier transform (STFT) with a sliding window of 1 s is conducted subsequently. To take full advantage of the continuous radar motion data acquired in each scenario, the overlap of consecutive frames when using the sliding window is 0.36 s. Then, the radar motion data acquired in a scenario are transformed into a series of MD signatures. Several typical MD signatures in the dataset are shown in
Figure 7. Each datum represents an activity that lasts 1 s, and the radical velocity ranges of all activities are between −5.14 m/s and 5.14 m/s. Consequently, a dataset composed of approximately 7498 spectrograms is obtained, and the concrete distribution is shown in
Table 3. Then, we resize the spectrograms into 100 × 150 and feed them into the models.
7. Conclusions
In this paper, a novel end-to-end neural network MRA-Net for joint activity classification and person identification with radar MD signatures was proposed. We explored the correlation between activity classification and person identification, and take advantage of the MTL mechanism to share computations between the two tasks. Multiscale learning and the residual attention mechanism were adopted in MRA-Net to learn more fully from the input MD signatures. Furthermore, instead of the conventional greedy search algorithm, we proposed an FLWL mechanism, which is also suitable for other multitask systems. We constructed a new radar MD dataset, with dual activity and identity labels for each piece of data, to optimize the proposed model.
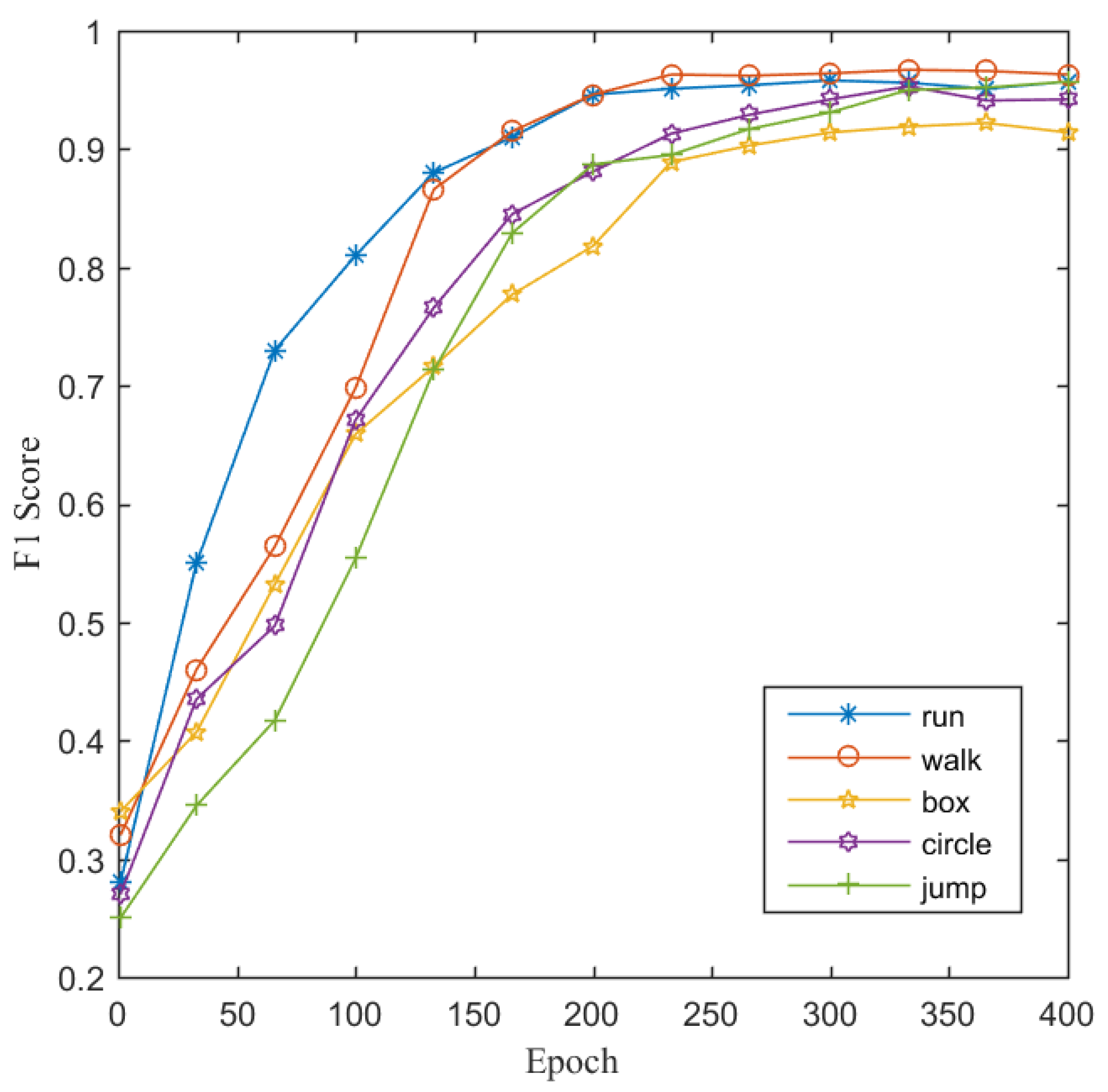
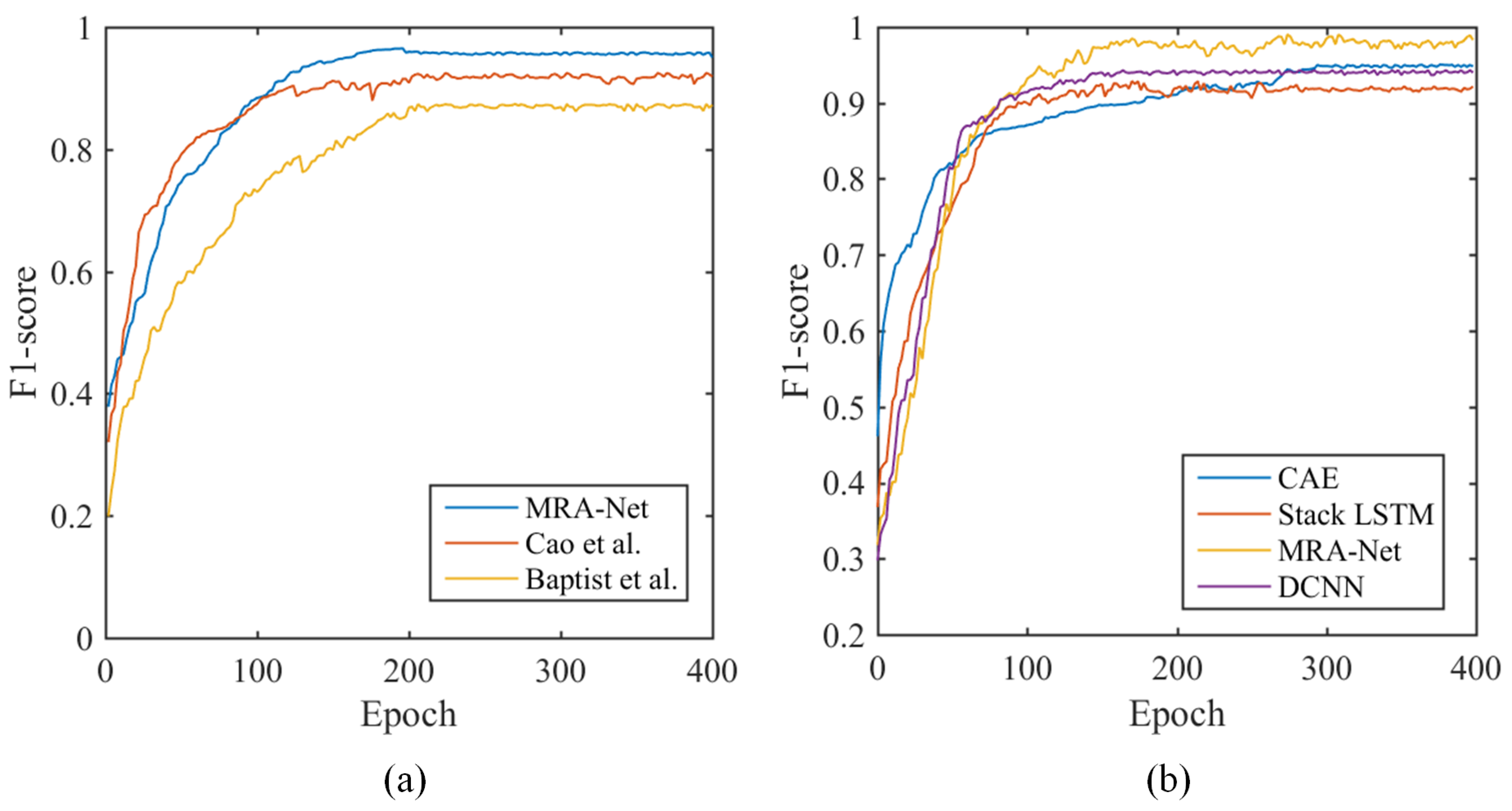
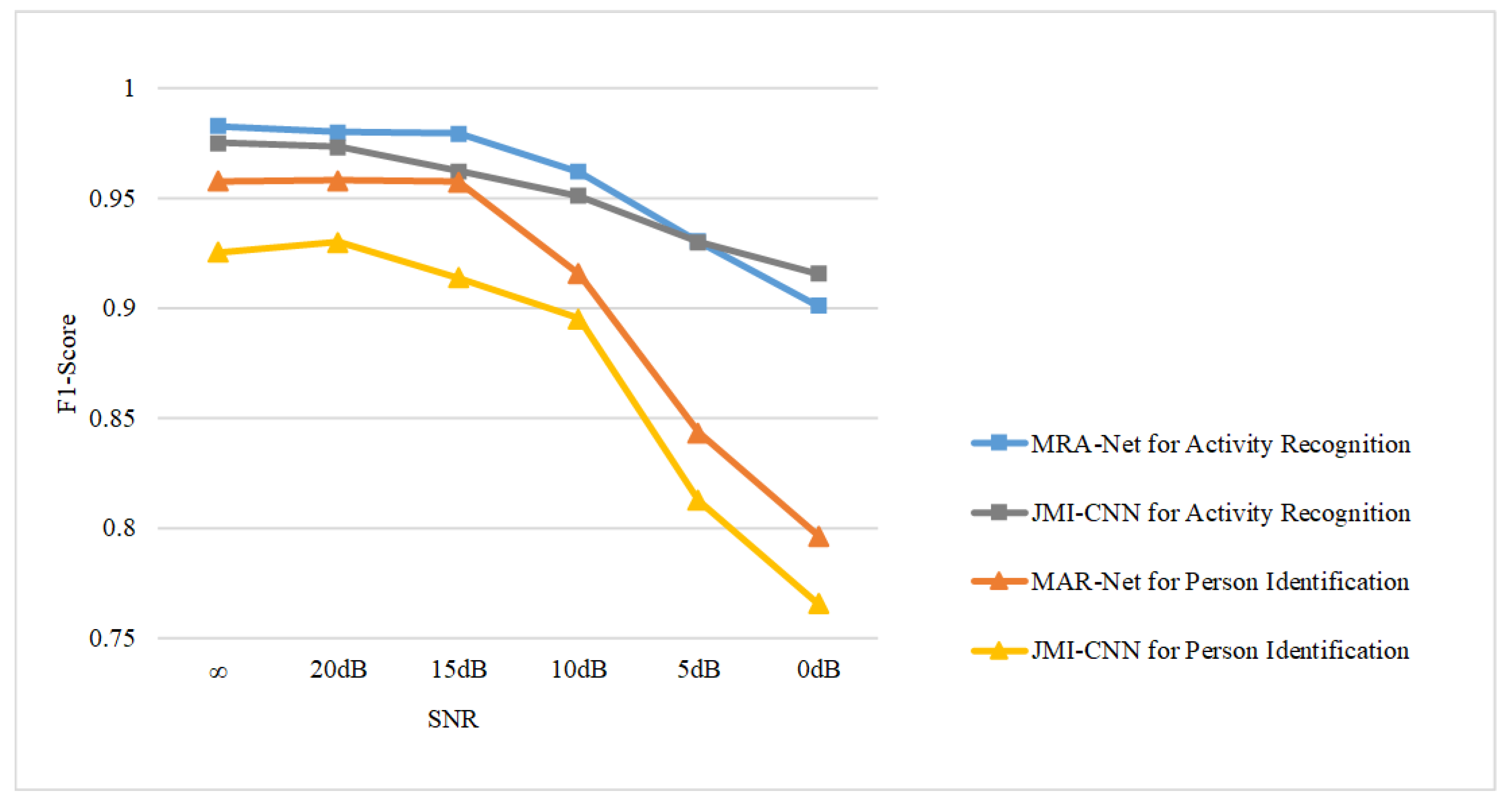
The experiments showed that the proposed MRA-Net for joint learning achieved good performance with F1-scores of 98.29% for activity recognition and 95.87% for person identification. It outperforms not only MRA-Net for single-task learning but also some state-of-the-art radar-based activity recognition and person identification methods. In addition, the proposed FLWL mechanism further improves the performance of MRA-Net. The ablation studies indicated the efficacy of the components in the feature extractor of MRA-Net. In future work, we intend to further investigate the proposed model and design more reasonable multitask architectures for joint radar-based activity recognition and person identification. Additionally, more radar applications for smart sensing in IoT will be explored.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}