EMCM: A Novel Binary Edge-Feature-Based Maximum Clique Framework for Multispectral Image Matching

Abstract
:
1. Introduction
2. Methods
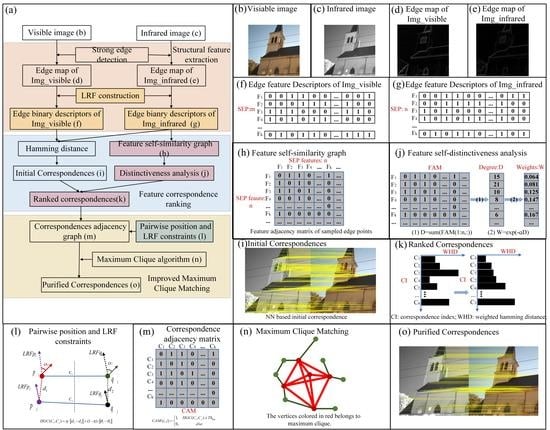
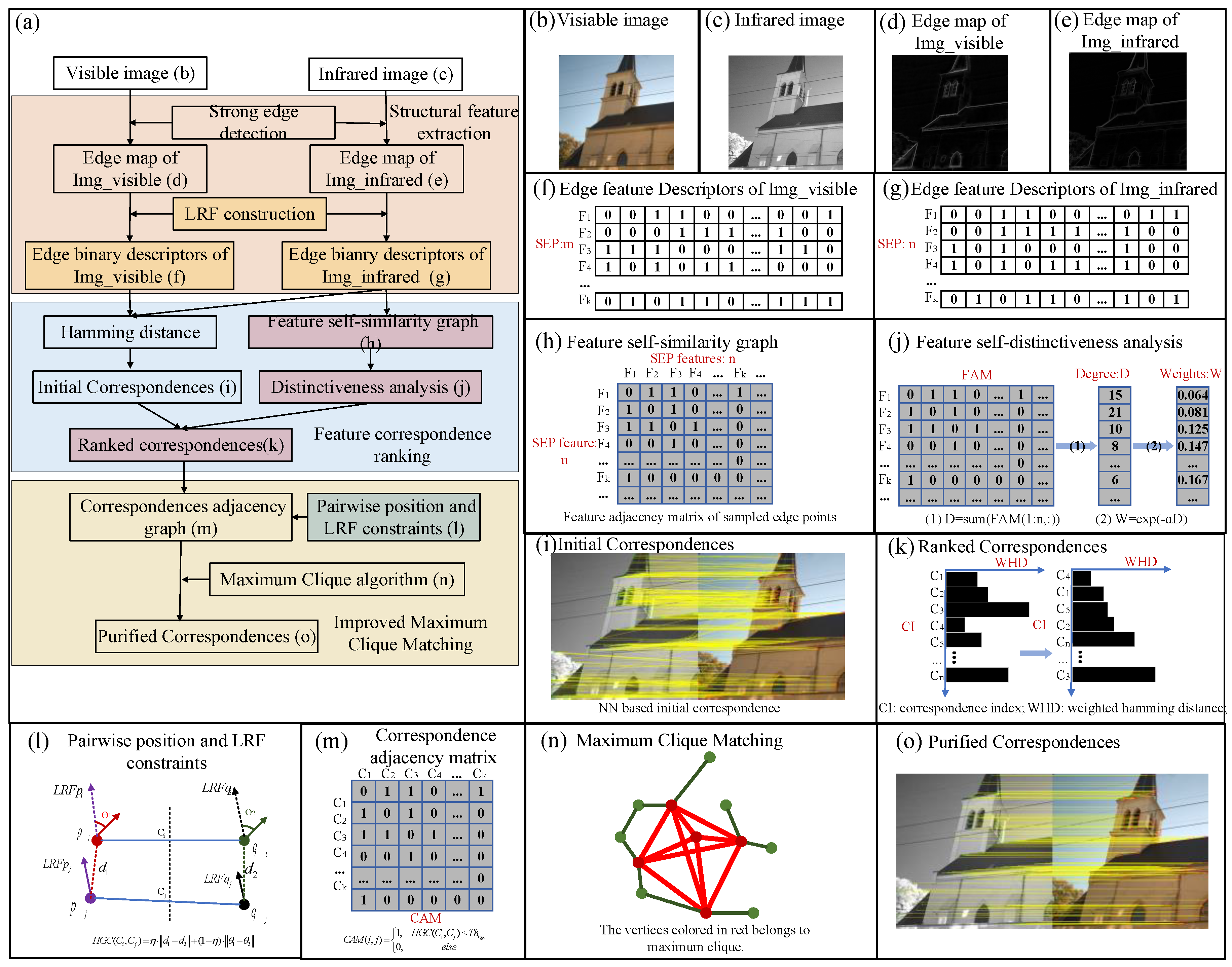
2.1. Edge-Feature-Based Maximum Clique-Matching Framework (EMCM)
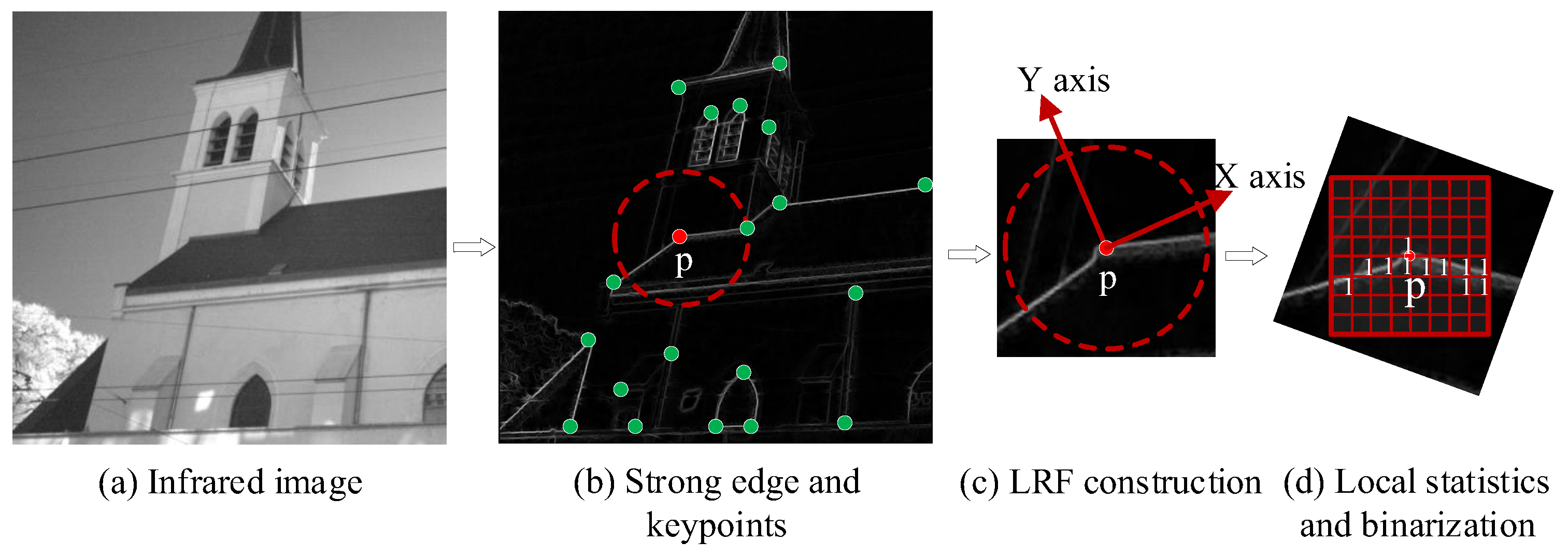
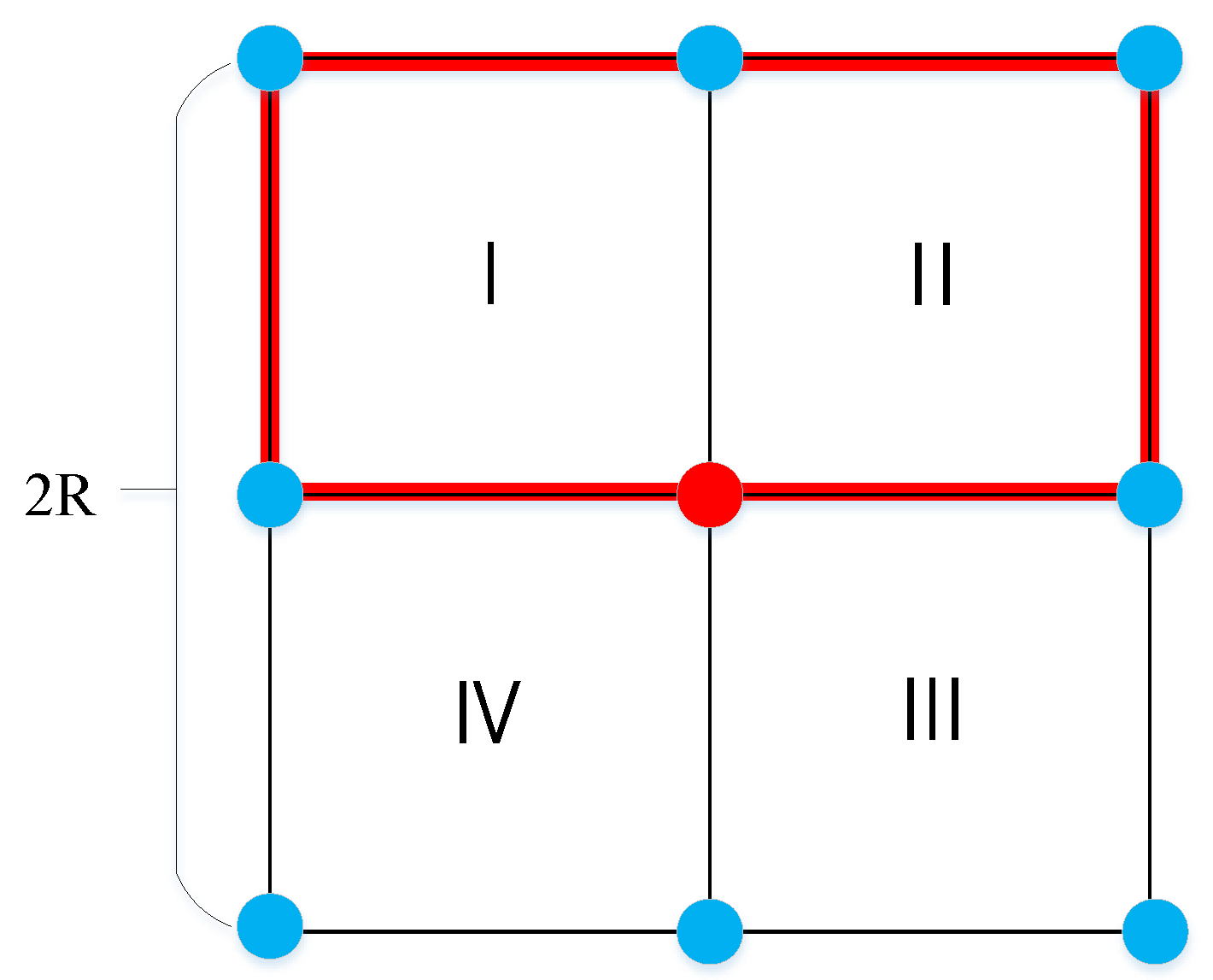
2.2. EBSC Descriptor
| Algorithm 1: S-GWW edge algorithm |
| Input: input image patch , window radius , iteration number , Whiledo |
| for do end for |
| end while If else |
| Output: |
2.3. Edge Feature Correspondence Ranking
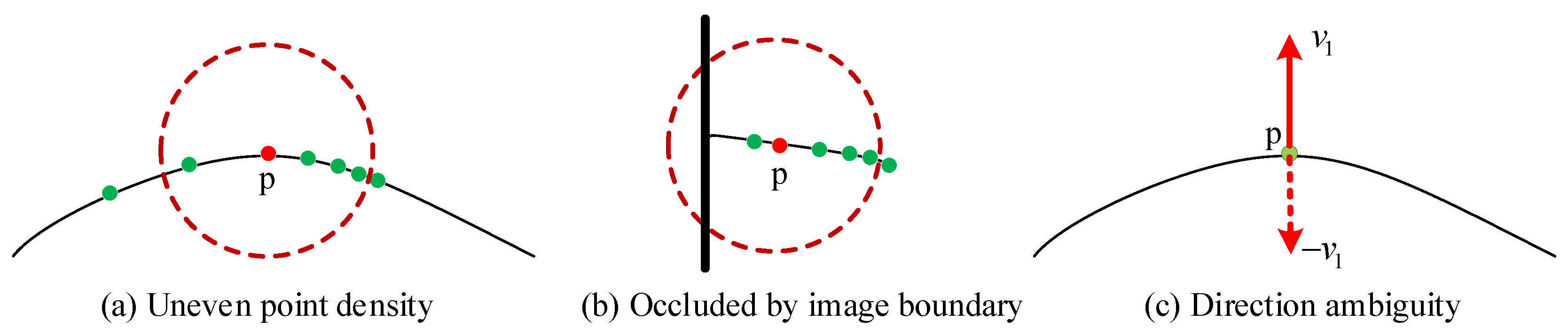
2.3.1. Keypoint Distinctiveness Analysis
2.3.2. Reweighted Hamming Distance and Ranking
2.4. Maximum Clique-Based Consistency Matching
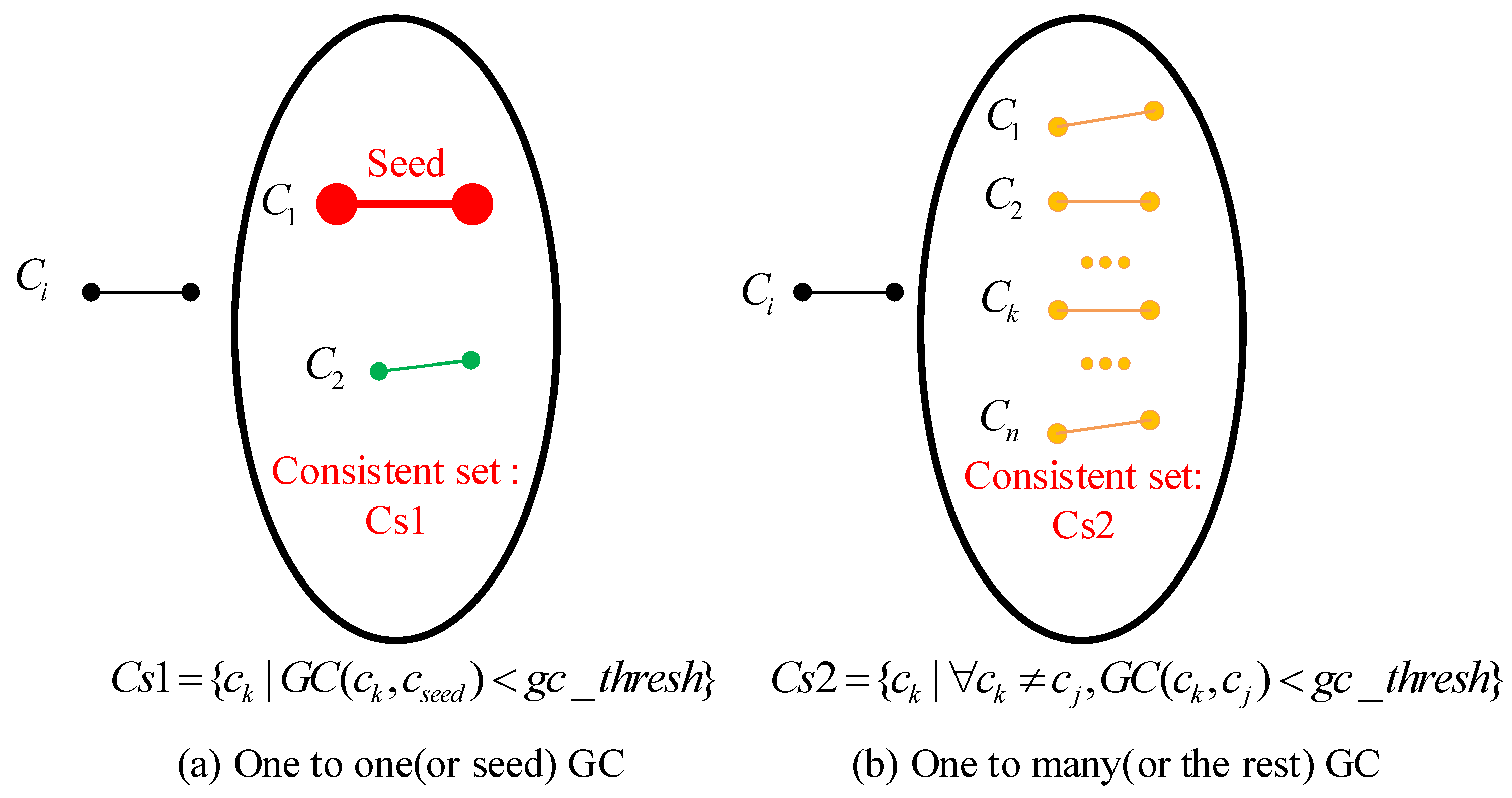
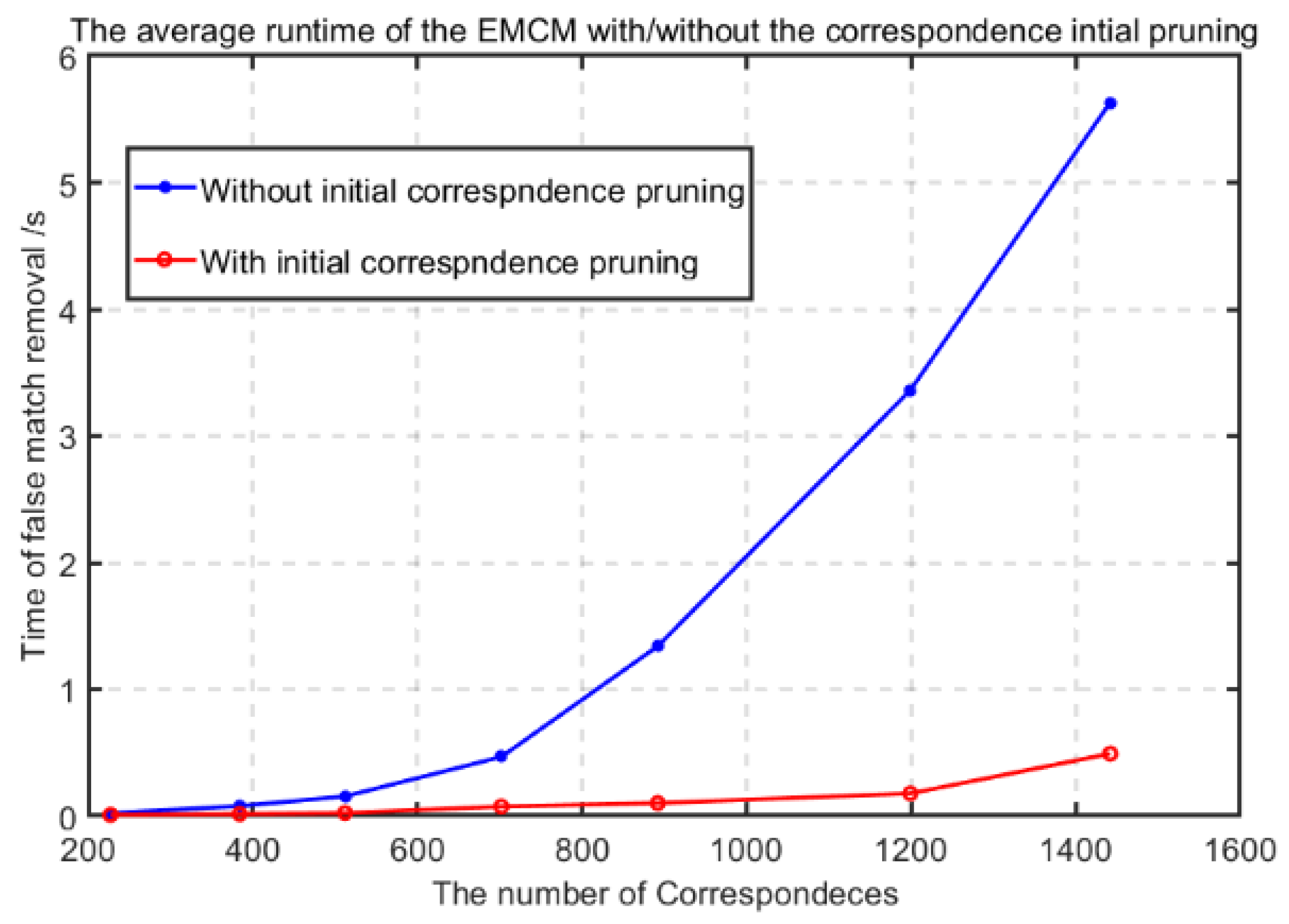
2.4.1. Correspondence Initial Pruning
2.4.2. Pairwise Position and Angle Consistency
2.4.3. Graph Construction and Maximum Clique Algorithm
3. Experiments and Analyses
3.1. Datasets and Settings
3.2. Evaluation Criteria
3.2.1. Criteria for Feature-Matching Experiments
3.2.2. Criteria for the Correspondence Ranking Experiments
3.2.3. Criteria for the Multispectral Image-Matching Experiments
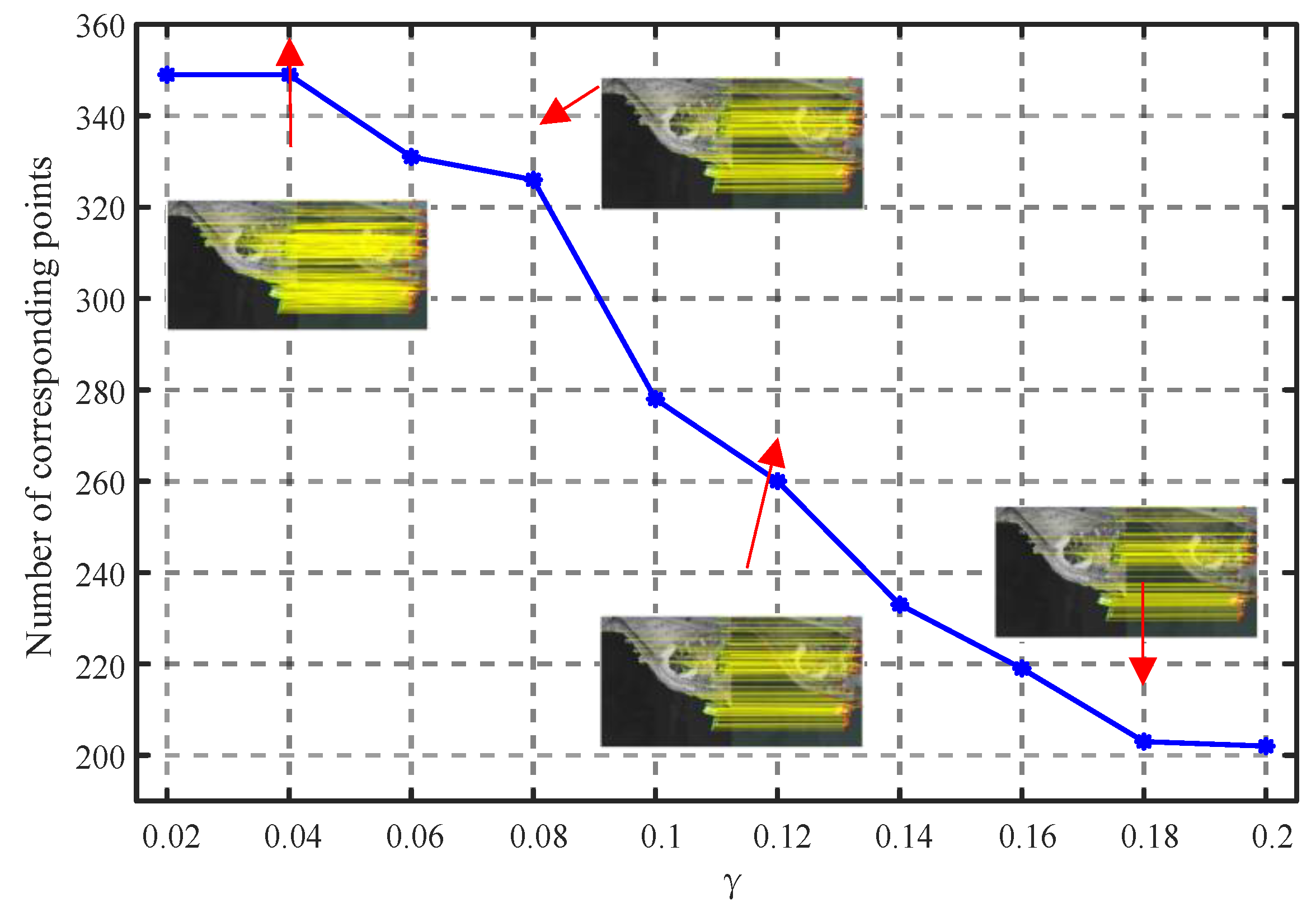
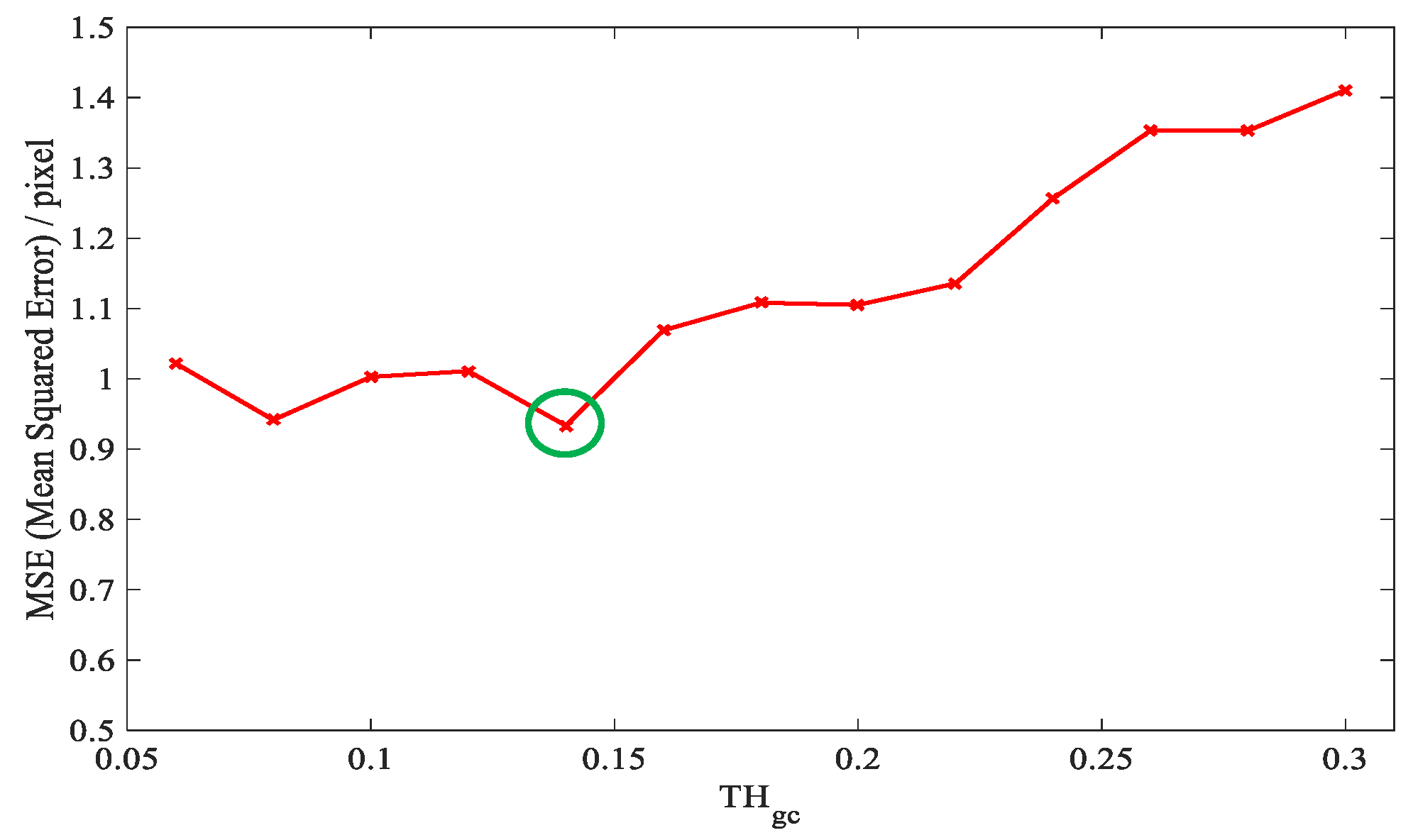
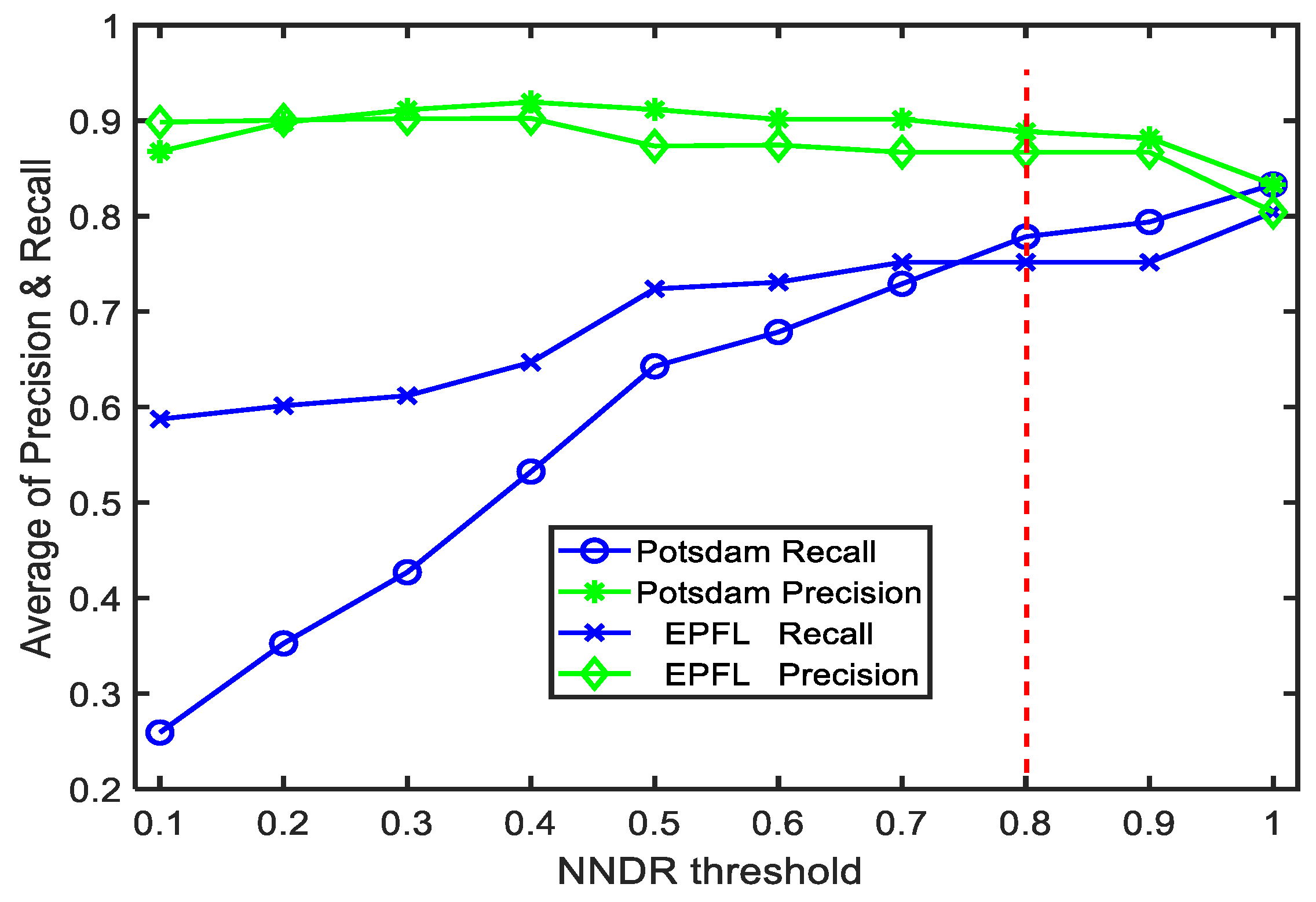
3.3. Parameter Analyses
3.4. Qualitative Evaluation of Multispectral Image Matching
3.5. Quantitative Evaluation of Feature Matching
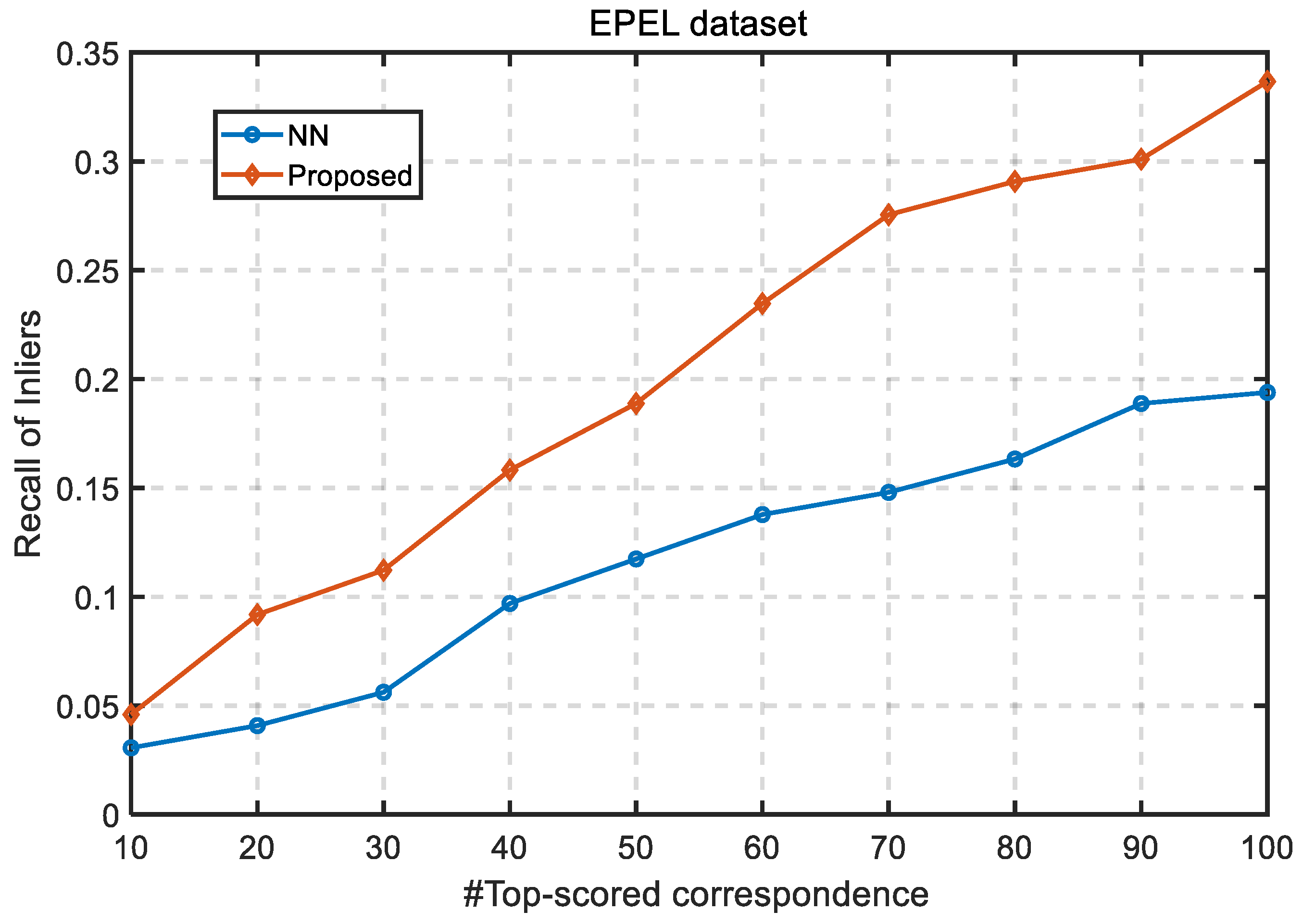
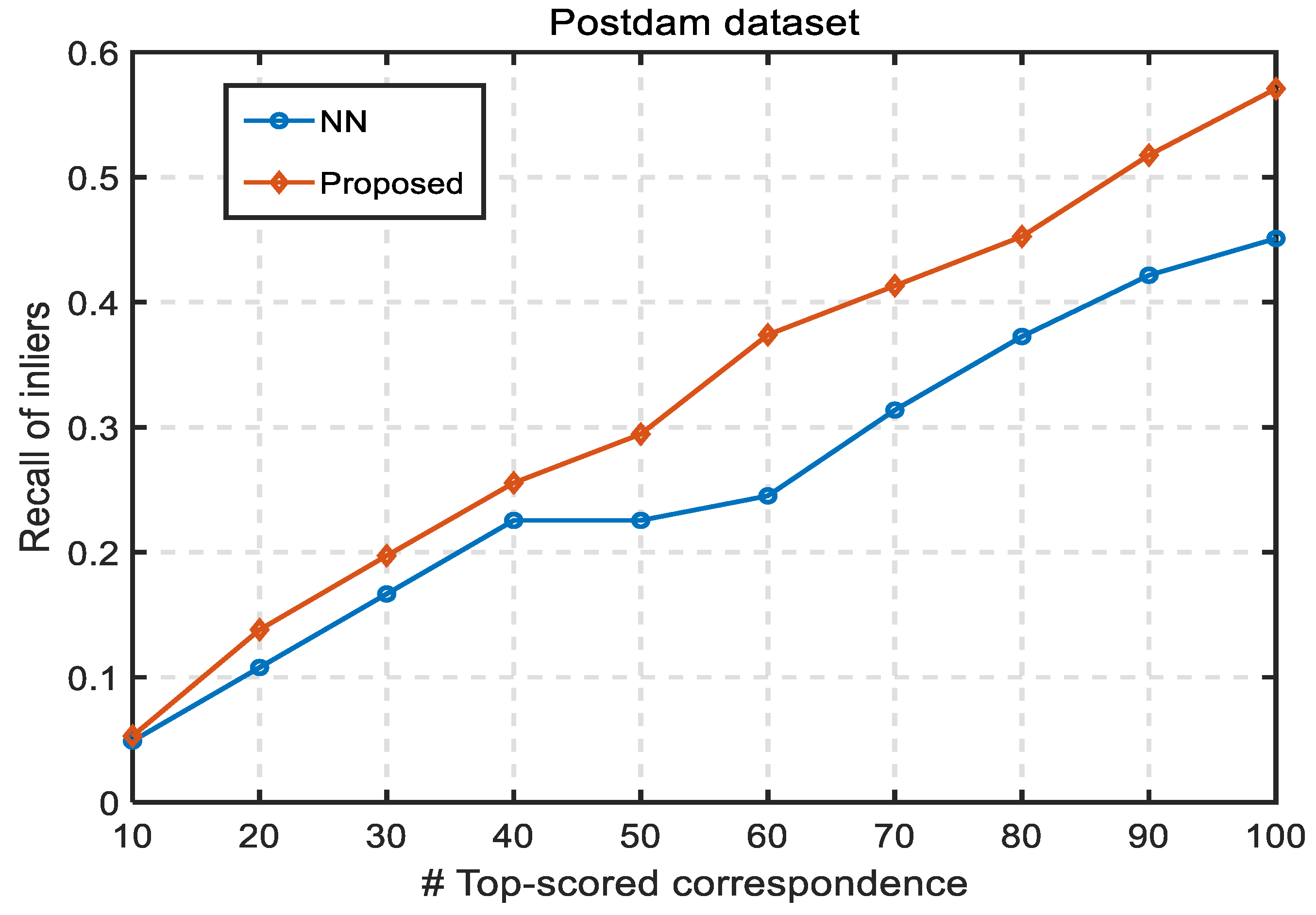
3.6. Quantitative Evaluation of Correspondences Ranking
3.7. Quantitative Evaluation of Multispectral Image Matching
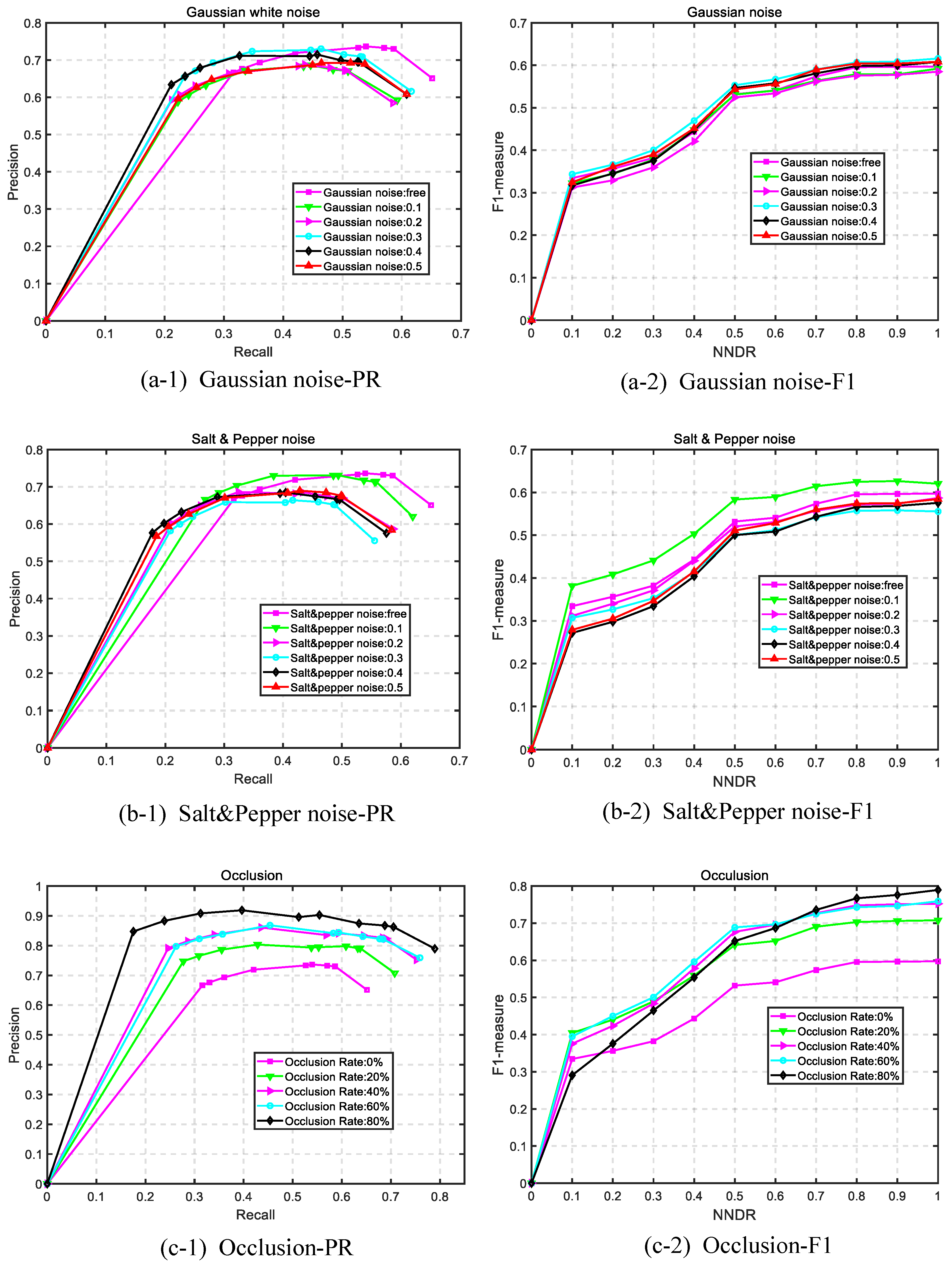
3.7.1. Robustness to Gaussian Noise
3.7.2. Robustness to Salt and Pepper Noise
3.7.3. Robustness to Occlusion
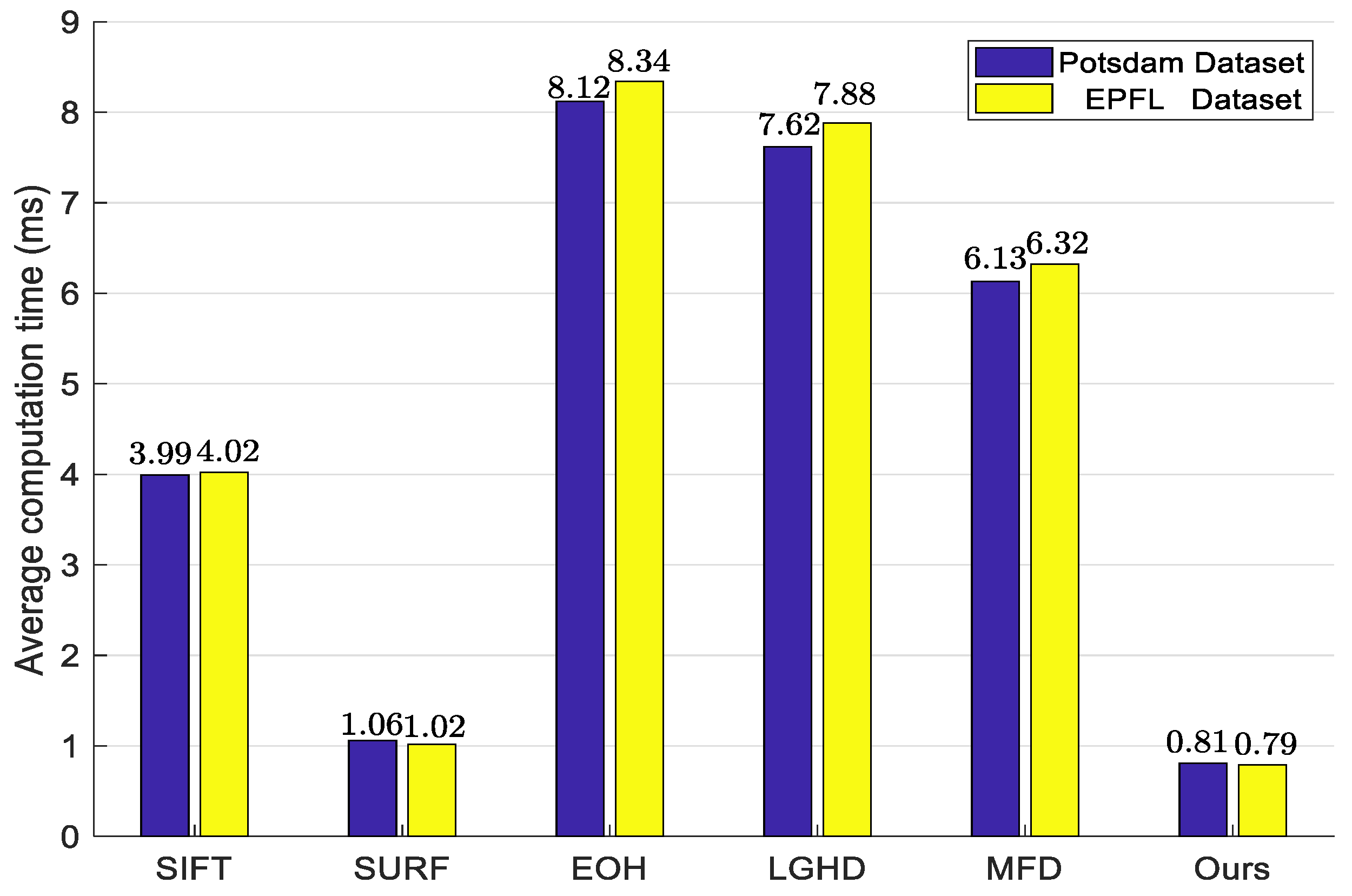
3.8. Runtime Analysis
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ma, J.; Ma, Y.; Li, C. Infrared and visible image fusion methods and applications: A survey. Inf. Fusion 2019, 45, 153–178. [Google Scholar] [CrossRef]
- Li, H.; Manjunath, B.S.; Mitra, S.K. Multisensor Image Fusion Using the Wavelet Transform. Graph. Models Image Process. 1995, 57, 235–245. [Google Scholar] [CrossRef]
- Jiang, X.; Ma, J.; Jiang, J.; Guo, X. Robust Feature Matching Using Spatial Clustering With Heavy Outliers. IEEE Trans. Image Process. 2020, 29, 736–746. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Jiang, X.; Jiang, J.; Zhao, J.; Guo, X. LMR: Learning a Two-Class Classifier for Mismatch Removal. IEEE Trans. Image Process. 2019, 28, 4045–4059. [Google Scholar] [CrossRef] [PubMed]
- Chen, X.; Zhai, G.; Wang, J.; Hu, C.; Chen, Y. Color guided thermal image super resolution. In Proceedings of the Visual Communications and Image Processing (VCIP), Chengdu, China, 27–30 November 2016; pp. 1–4. [Google Scholar]
- Ma, J.; Zhao, J.; Jiang, J.; Zhou, H.; Guo, X. Locality Preserving Matching. Int. J. Comput. Vis. 2019, 127, 512–531. [Google Scholar] [CrossRef]
- Yu, Y.; Huang, K.; Chen, W.; Tan, T. A Novel Algorithm for View and Illumination Invariant Image Matching. IEEE Trans. Image Process. 2012, 21, 229–240. [Google Scholar]
- Feng, Z.; Qingming, H.; Wen, G. Image Matching by Normalized Cross-Correlation. In Proceedings of the IEEE International Conference on Acoustics Speech and Signal Processing (ICASSP), Toulouse, France, 14–19 May 2006; pp. 729–732. [Google Scholar]
- Bracewell, R.N. The Fourier Transform and Its Applications, 2nd ed.; McGraw-Hill: New York, NY, USA, 1986. [Google Scholar]
- Viola, P.; Wells, W.M., III. Alignment by Maximization of Mutual Information. Int. J. Comput. Vis. 1997, 24, 137–154. [Google Scholar] [CrossRef]
- Ma, J.; Zhao, J.; Ma, Y.; Tian, J. Non-rigid visible and infrared face registration via regularized Gaussian fields criterion. Pattern Recognit. 2015, 48, 772–784. [Google Scholar] [CrossRef]
- Yang, W.; Wang, X.; Moran, B.; Wheaton, A.; Cooley, N. Efficient registration of optical and infrared images via modified Sobel edging for plant canopy temperature estimation. Comput. Electr. Eng. 2012, 38, 1213–1221. [Google Scholar] [CrossRef]
- Hu, N.; Huang, Q.; Thibert, B.; Guibas, L.J. Distributable consistent multi-object matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 2463–2471. [Google Scholar]
- Ma, J.; Jiang, J.; Zhou, H.; Zhao, J.; Guo, X. Guided Locality Preserving Feature Matching for Remote Sensing Image Registration. IEEE Trans. Geosci. Remote Sens. 2018, 56, 4435–4447. [Google Scholar] [CrossRef]
- Almasi, S.; Lauric, A.; Malek, A.M.; Miller, E.L. Cerebrovascular network registration via an efficient attributed graph matching technique. Med. Image Anal. 2018, 46, 118–129. [Google Scholar] [CrossRef] [PubMed]
- Shi, Q.; Ma, G.; Zhang, F.; Chen, W.; Qin, Q.; Duo, H. Robust Image Registration Using Structure Features. IEEE Geosci. Remote Sens. Lett. 2014, 11, 2045–2049. [Google Scholar]
- Guislain, M.; Digne, J.; Chaine, R.; Monnier, G. Fine scale image registration in large-scale urban LIDAR point sets. Comput. Vis. Image Underst. 2017, 157, 90–102. [Google Scholar] [CrossRef] [Green Version]
- Song, J.; Liu, L.; Huang, W.; Li, Y.; Chen, X.; Zhang, Z. Target detection via HSV color model and edge gradient information in infrared and visible image sequences under complicated background. Opt. Quantum Electron. 2018, 50, 171–175. [Google Scholar] [CrossRef]
- Li, Y.; Tao, C.; Tan, Y.; Shang, K.; Tian, J. Unsupervised Multilayer Feature Learning for Satellite Image Scene Classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 157–161. [Google Scholar] [CrossRef]
- Sun, K.; Li, P.; Tao, W.; Tang, Y. Feature Guided Biased Gaussian Mixture Model for image matching. Inf. Sci. 2015, 295, 323–336. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, J.; Liu, C.; Li, Y.J.I.S. Feature guided Gaussian mixture model with semi-supervised EM and local geometric constraint for retinal image registration. Inf. Sci. 2017, 417, 128–142. [Google Scholar] [CrossRef]
- Ma, J.; Jiang, X.; Jiang, J.; Gao, Y. Feature-guided Gaussian mixture model for image matching. Pattern Recognit. 2019, 92, 231–245. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-Up Robust Features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Wang, S.; Quan, D.; Liang, X.; Ning, M.; Guo, Y.; Jiao, L. A deep learning framework for remote sensing image registration. ISPRS-J. Photogramm. Remote Sens. 2018, 145, 148–164. [Google Scholar] [CrossRef]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. TurboPixels: Fast Superpixels Using Geometric Flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Stutz, D.; Hermans, A.; Leibe, B. Superpixels: An evaluation of the state-of-the-art. Comput. Vis. Image Underst. 2018, 166, 1–27. [Google Scholar] [CrossRef] [Green Version]
- Gaetano, R.; Masi, G.; Poggi, G.; Verdoliva, L.; Scarpa, G. Marker-Controlled Watershed-Based Segmentation of Multiresolution Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2015, 53, 2987–3004. [Google Scholar] [CrossRef]
- Cousty, J.; Bertrand, G.; Najman, L.; Couprie, M. Watershed Cuts: Thinnings, Shortest Path Forests, and Topological Watersheds. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 925–939. [Google Scholar] [CrossRef] [Green Version]
- Wan, M.; Gu, G.; Sun, J.; Qian, W.; Ren, K.; Chen, Q.; Maldague, X. A Level Set Method for Infrared Image Segmentation Using Global and Local Information. Remote Sens. 2018, 10, 1039. [Google Scholar] [CrossRef] [Green Version]
- Ciecholewski, M. An edge-based active contour model using an inflation/deflation force with a damping coefficient. Expert Syst. Appl. 2016, 44, 22–36. [Google Scholar] [CrossRef]
- Tian, T.; Mei, X.; Yu, Y.; Zhang, C.; Zhang, X. Automatic visible and infrared face registration based on silhouette matching and robust transformation estimation. Infrared Phys. Technol. 2015, 69, 145–154. [Google Scholar] [CrossRef]
- Aguilera, C.; Barrera, F.; Lumbreras, F.; Sappa, A.D.; Toledo, R. Multispectral Image Feature Points. Sensors 2012, 12, 12661–12672. [Google Scholar] [CrossRef] [Green Version]
- Aguilera, C.A.; Sappa, A.D.; Toledo, R. LGHD: A feature descriptor for matching across non-linear intensity variations. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Quebec City, QC, Canada, 27–30 September 2015; pp. 178–181. [Google Scholar]
- Nunes, C.F.G.; Pádua, F.L.C. A Local Feature Descriptor Based on Log-Gabor Filters for Keypoint Matching in Multispectral Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1850–1854. [Google Scholar] [CrossRef]
- Yin, H.; Gong, Y.; Qiu, G. Side Window Filtering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 8758–8766. [Google Scholar]
- Yu, K.; Ma, J.; Hu, F.; Ma, T.; Quan, S.; Fang, B. A grayscale weight with window algorithm for infrared and visible image registration. Infrared Phys. Technol. 2019, 99, 178–186. [Google Scholar] [CrossRef]
- Bustos, Á.P.; Chin, T.-J.; Neumann, F.; Friedrich, T.; Katzmann, M. A Practical Maximum Clique Algorithm for Matching with Pairwise Constraints. In Proceedings of the CVPR 2019: Progress and Challenges in the Field of Computer Vision, Long Beach, CA, USA, 16–21 June 2019. [Google Scholar]
- Huizinga, W.; Poot, D.H.J.; Guyader, J.M.; Klaassen, R.; Coolen, B.F.; van Kranenburg, M.; van Geuns, R.J.M.; Uitterdijk, A.; Polfliet, M.; Vandemeulebroucke, J.; et al. PCA-based groupwise image registration for quantitative MRI. Med. Image Anal. 2016, 29, 65–78. [Google Scholar] [CrossRef]
- Diestel, R. Graph-Theory, 3rd ed.; Springer: Berlin, Germany, 2000. [Google Scholar]
- Chen, H.; Bhanu, B. 3D free-form object recognition in range images using local surface patches. Pattern Recognit. Lett. 2007, 28, 1252–1262. [Google Scholar] [CrossRef]
- Aldoma, A.; Marton, Z.; Tombari, F.; Wohlkinger, W.; Potthast, C.; Zeisl, B.; Rusu, R.B.; Gedikli, S.; Vincze, M. Tutorial: Point Cloud Library: Three-Dimensional Object Recognition and 6 DOF Pose Estimation. IEEE Robot. Autom. Mag. 2012, 19, 80–91. [Google Scholar] [CrossRef]
- Potsdam Dataset of Remote Sensing Images, Distributed by the International Society for Photogrammetry and Remote Sensing. [Online]. Available online: http://www2.isprs.org/commissions/comm3/wg4/2d-sem-label-potsdam.html (accessed on 8 September 2018).
- Brown, M.; Süsstrunk, S. Multi-spectral SIFT for scene category recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 177–184. [Google Scholar]
- Rusinkiewicz, S.; Levoy, M. Efficient variants of the ICP algorithm. In Proceedings of the Third International Conference on 3-D Digital Imaging and Modeling (3DIMPVT), Quebec City, Quebec, Canada, 28 May–1 June 2001; pp. 145–152. [Google Scholar]
- Ma, T.; Ma, J.; Yu, K. A Local Feature Descriptor Based on Oriented Structure Maps with Guided Filtering for Multispectral Remote Sensing Image Matching. Remote Sens. 2019, 11, 951. [Google Scholar] [CrossRef] [Green Version]

























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Metrics | Descriptor Algorithm-Potsdam Dataset | |||||
| SIFT | SURF | EOH | LGHD | MFD | Ours | |
| Precision | 0.275 0.036 | 0.186 0.042 | 0.427 0.040 | 0.527 0.021 | 0.542 0.026 | 0.837 ± 0.041 |
| Recall | 0.229 0.039 | 0.147 0.034 | 0.194 0.015 | 0.315 0.018 | 0.334 0.024 | 0.781 ± 0.067 |
| F1-measure | 0.249 0.037 | 0.164 0.038 | 0.267 0.022 | 0.394 0.019 | 0.413 0.025 | 0.8080.051 |
| #True Positives | 121 | 110 | 200 | 325 | 344 | 639 |
| Metrics | Descriptor Algorithm-EPEL Dataset | |||||
| SIFT | SURF | EOH | LGHD | MFD | Ours | |
| Precision | 0.497 0.061 | 0.385 0.074 | 0.676 0.046 | 0.781 0.052 | 0.766 0.034 | 0.8720.027 |
| Recall | 0.414 0.056 | 0.267 0.038 | 0.324 0.031 | 0.477 0.033 | 0.594 0.021 | 0.7510.032 |
| F1-measure | 0.452 0.058 | 0.315 0.050 | 0.438 0.037 | 0.592 0.040 | 0.669 0.025 | 0.8070.029 |
| #True Positives | 286 | 261 | 215 | 317 | 395 | 956 |
| Gaussian Noise Levels/σ | F1-Measure Scores at Different NNDR η Values | |||||
| η = 0.5 | η = 0.6 | η = 0.7 | η = 0.8 | η = 0.9 | η = 1.0 | |
| 0.1 | 0.5834 | 0.5895 | 0.6145 | 0.6249 | 0.6265 | 0.6203 |
| 0.2 | 0.5203 | 0.5311 | 0.5573 | 0.5716 | 0.5737 | 0.5870 |
| 0.3 | 0.5004 | 0.5119 | 0.5419 | 0.5571 | 0.5581 | 0.5555 |
| 0.4 | 0.5002 | 0.5086 | 0.5432 | 0.5661 | 0.5685 | 0.5756 |
| 0.5 | 0.5109 | 0.5286 | 0.5597 | 0.5742 | 0.5745 | 0.5845 |
| Salt & Pepper Noise Levels /d | F1-Measure Scores at Different NNDR η Values | |||||
| η = 0.5 | η = 0.6 | η = 0.7 | η = 0.8 | η = 0.9 | η = 1.0 | |
| 10% | 0.5311 | 0.5408 | 0.5636 | 0.5791 | 0.5787 | 0.5923 |
| 20% | 0.5245 | 0.5341 | 0.5620 | 0.5758 | 0.5776 | 0.5851 |
| 30% | 0.5531 | 0.5672 | 0.5900 | 0.6072 | 0.6087 | 0.6161 |
| 40% | 0.5468 | 0.5578 | 0.5812 | 0.5985 | 0.5997 | 0.6082 |
| 50% | 0.5432 | 0.5558 | 0.5898 | 0.6042 | 0.6042 | 0.6083 |
| Occlusion Rate/δ | F1-Measure Scores at Different NNDR η Values | |||||
| η = 0.5 | η = 0.6 | η = 0.7 | η = 0.8 | η = 0.9 | η = 1.0 | |
| 20% | 0.6412 | 0.6521 | 0.6905 | 0.7031 | 0.7061 | 0.7078 |
| 40% | 0.6766 | 0.6959 | 0.7270 | 0.7479 | 0.7509 | 0.7524 |
| 60% | 0.6887 | 0.6969 | 0.7249 | 0.7429 | 0.7465 | 0.7591 |
| 80% | 0.6518 | 0.6870 | 0.7358 | 0.7671 | 0.7761 | 0.7895 |
| Index | Gaussian Noise Levels | |||||
|---|---|---|---|---|---|---|
| σ = 0 | σ = 0.1 | σ = 0.2 | σ = 0.3 | σ = 0.4 | σ = 0.5 | |
| 196 | 177 | 139 | 108 | 69 | 57 | |
| 1.60 | 1.91 | 2.13 | 2.43 | 2.40 | 2.42 | |
| Index | Salt & Pepper Noise Levels | |||||
|---|---|---|---|---|---|---|
| d = 0% | d = 10% | d = 20% | d = 30% | d = 40% | d = 50% | |
| 196 | 198 | 83 | 89 | 55 | 40 | |
| 1.60 | 1.7320 | 1.1077 | 1.2653 | 1.6577 | 1.5839 | |
| Index | Occlusion Rate/δ | ||||
|---|---|---|---|---|---|
| δ = 0 | δ = 20% | δ = 40% | δ = 60% | δ = 80% | |
| 196 | 78 | 71 | 44 | 16 | |
| 1.60 | 1.69 | 2.10 | 1.81 | 2.43 | |
| Method | Sub-Stages | ||||
| S-GWW & KD | EBSC | FM+KDA | IMC | Total | |
| EMCM | 1.213 s | 0.296 s | 0.047 s | 0.019 s | 1.575 s |
| Method | Sub-Stages | ||||
| KD&Guided Filter | HOSM | FM | RANSAC | Total | |
| HOSM+RANSAC | 1.106 s | 0.321 s | 0.103 s | 0.038 s | 1.658 s |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, B.; Yu, K.; Ma, J.; An, P. EMCM: A Novel Binary Edge-Feature-Based Maximum Clique Framework for Multispectral Image Matching. Remote Sens. 2019, 11, 3026. https://doi.org/10.3390/rs11243026
Fang B, Yu K, Ma J, An P. EMCM: A Novel Binary Edge-Feature-Based Maximum Clique Framework for Multispectral Image Matching. Remote Sensing. 2019; 11(24):3026. https://doi.org/10.3390/rs11243026
Chicago/Turabian StyleFang, Bin, Kun Yu, Jie Ma, and Pei An. 2019. "EMCM: A Novel Binary Edge-Feature-Based Maximum Clique Framework for Multispectral Image Matching" Remote Sensing 11, no. 24: 3026. https://doi.org/10.3390/rs11243026
APA StyleFang, B., Yu, K., Ma, J., & An, P. (2019). EMCM: A Novel Binary Edge-Feature-Based Maximum Clique Framework for Multispectral Image Matching. Remote Sensing, 11(24), 3026. https://doi.org/10.3390/rs11243026