Object Detection in Remote Sensing Images Based on a Scene-Contextual Feature Pyramid Network

Abstract
:1. Introduction
- We propose the scene-contextual feature pyramid network, which is based on a multi-scale detection framework, to enhance the relationship between scene and target and ensure the effectiveness of the detection of multi-scale objects.
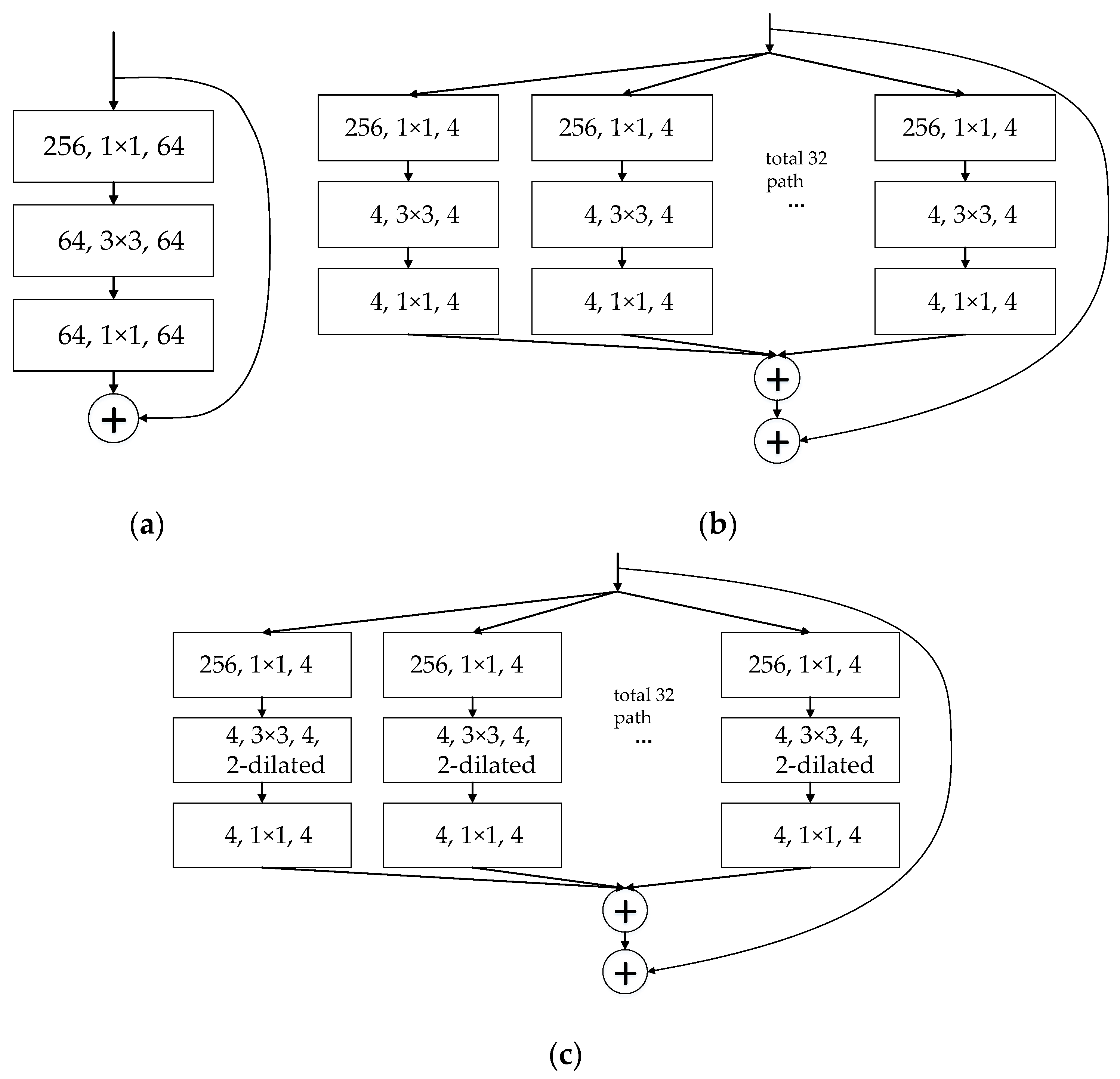
- We apply a combination structure called ResNeXt-d as the block structure of the backbone network, which can increase the receptive field and extract richer information for small targets.
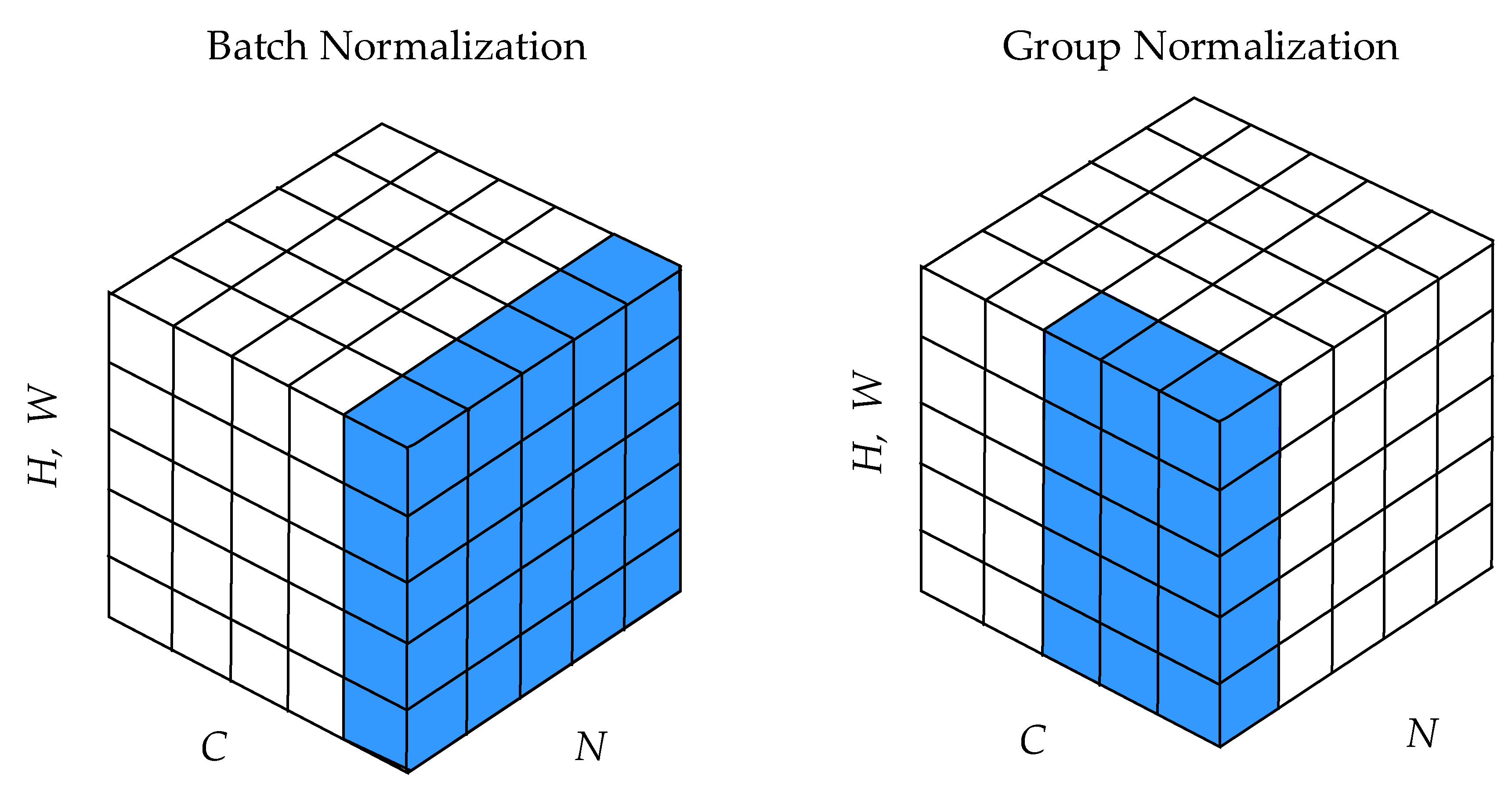
- We use the group normalization layer into the backbone network, which divides the channels into groups and computes within each group the mean and the variance for normalization, to solve the limitation of the batch normalization layer, and eventually get a better performance.
2. Proposed Method
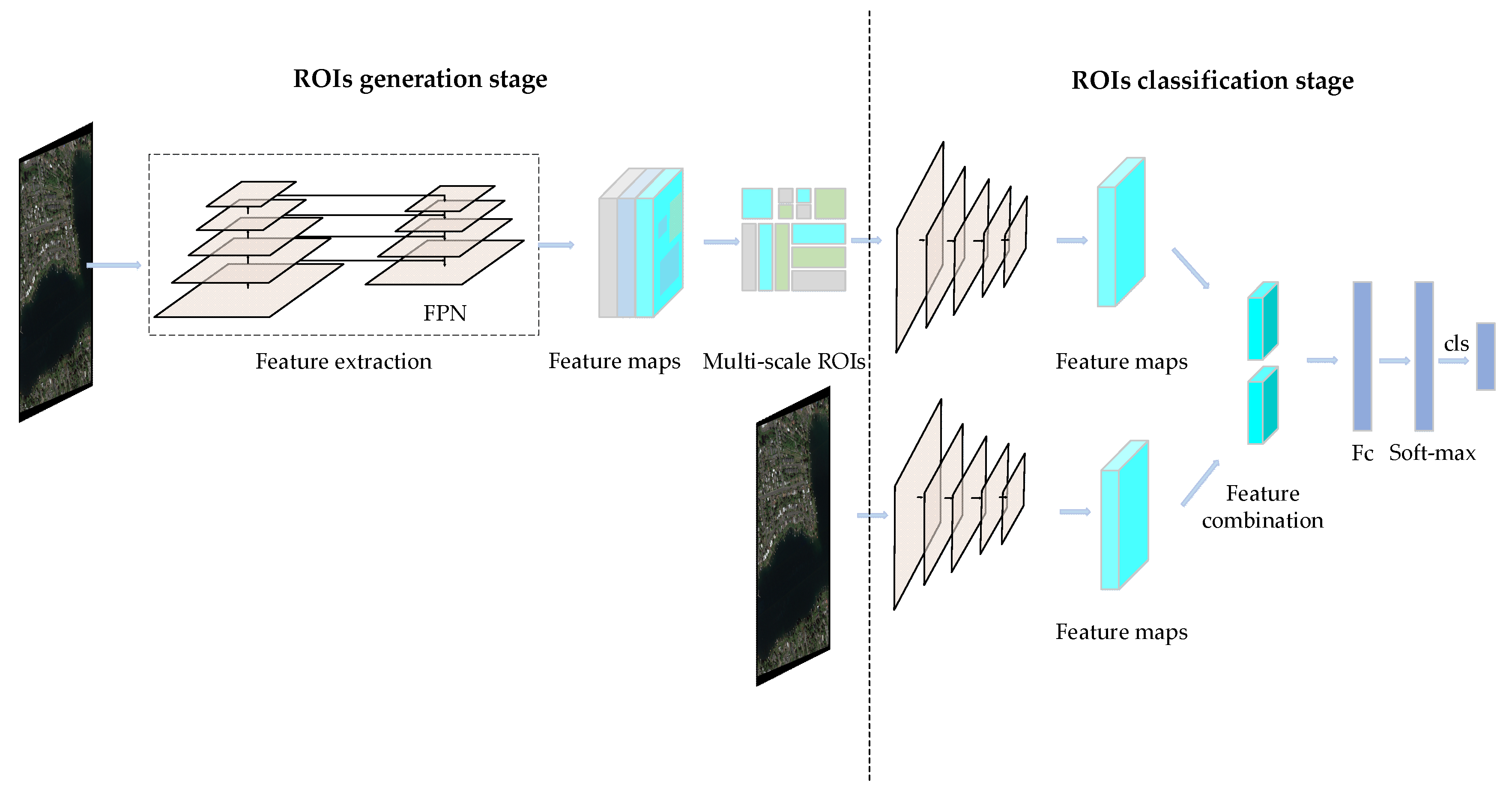
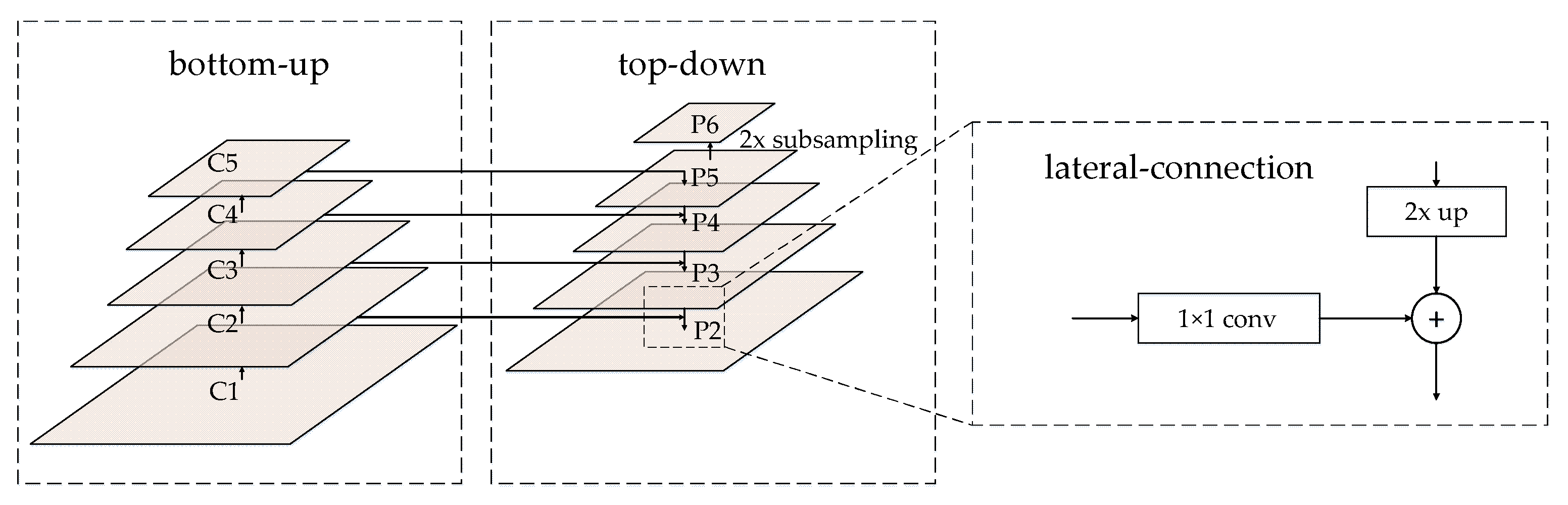
2.1. SCFPN Framework
2.2. Backbone Network
2.3. Group Normalization
3. Experiments
3.1. Dataset Description
3.2. Evaluation Metrics
3.3. Training Details
4. Results and Discussion
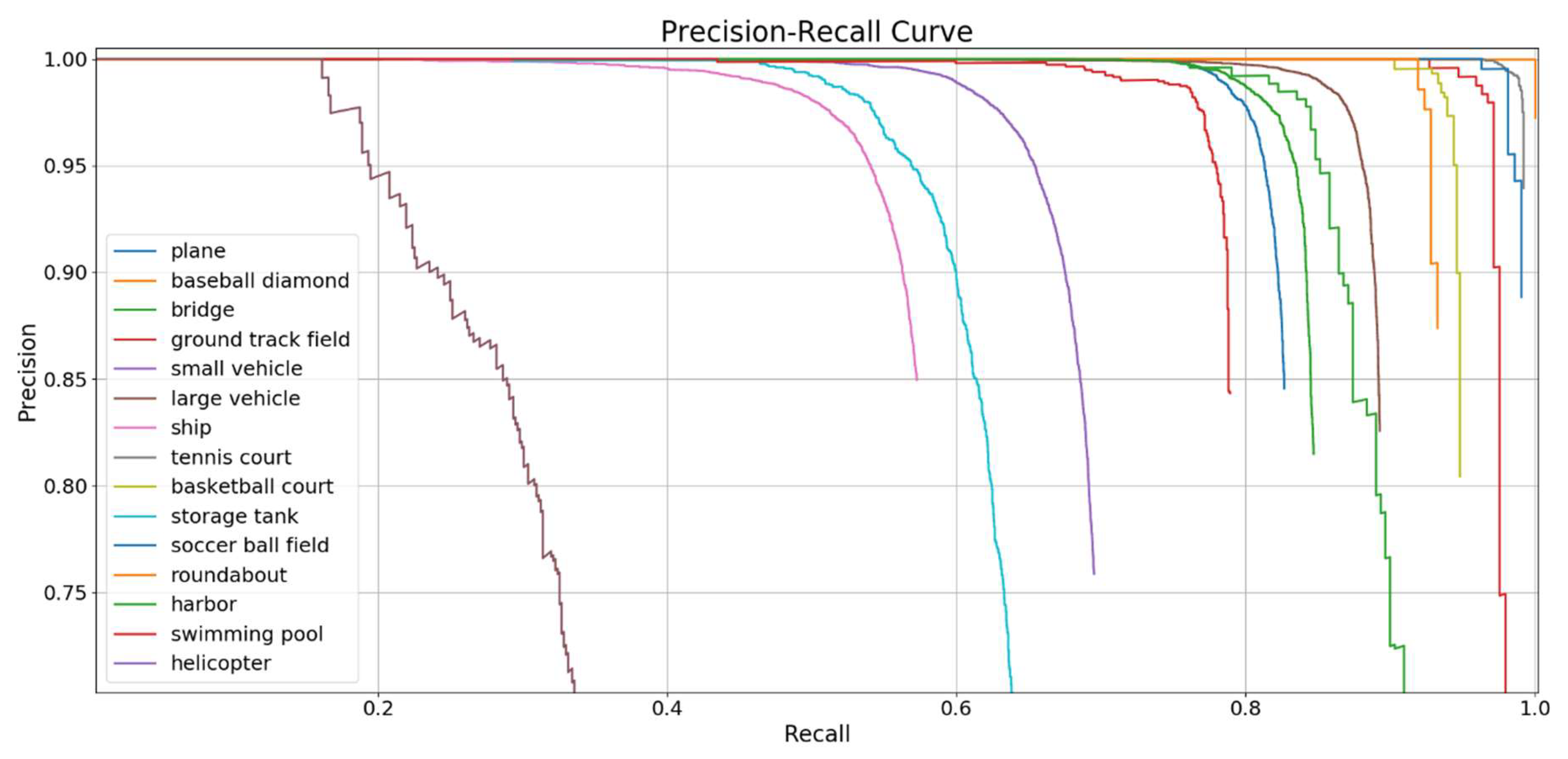
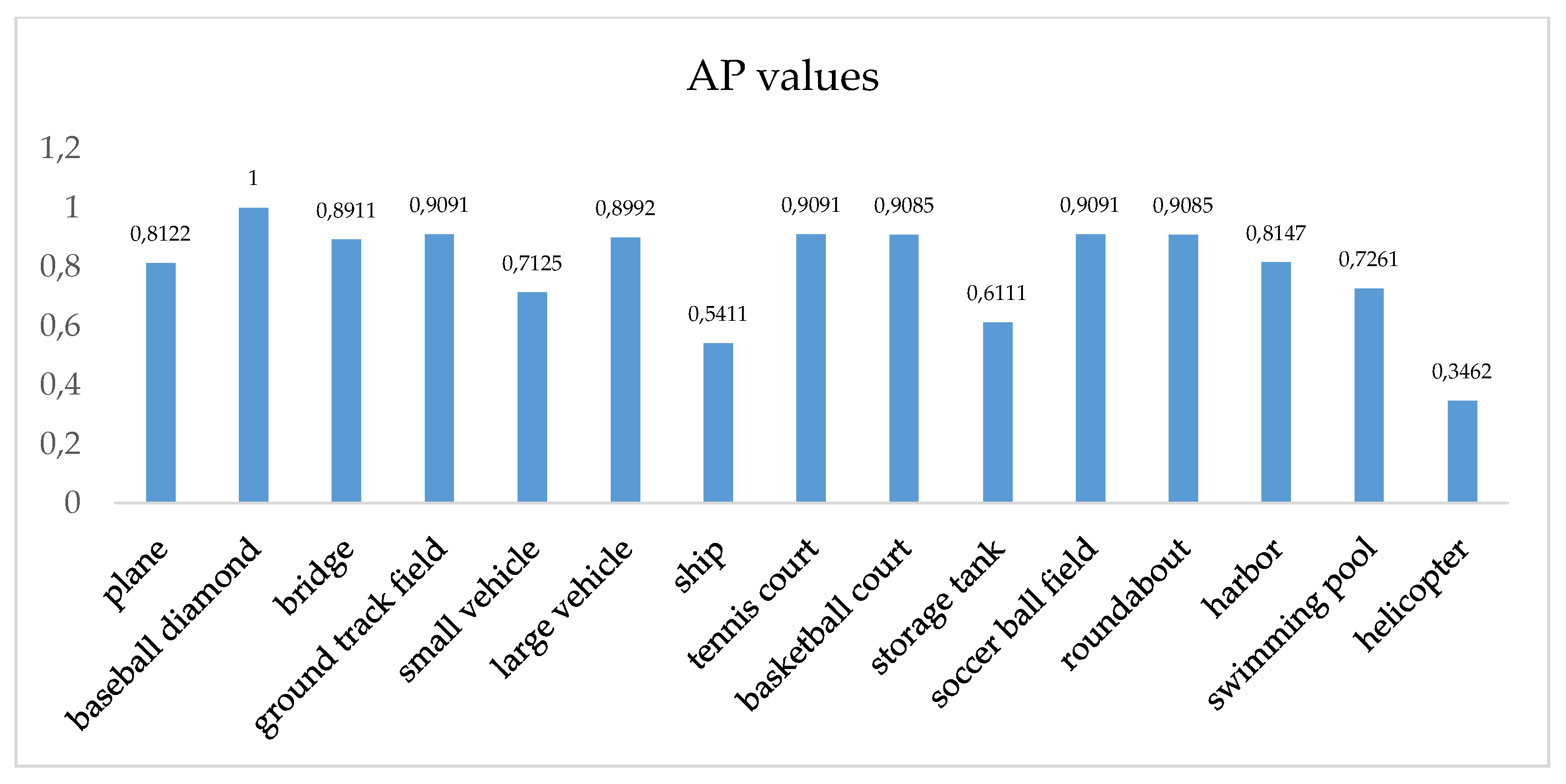
4.1. Results
4.2. Comparative Experiment
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems (NIPS), Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv, 2014; arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Jia, Y.Q.; Sermanet, P. Going deeper with convolutions. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Dai, J.F.; Li, Y.; He, K.M.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv, 2016; arXiv:1606.06409. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Wang, Q.; Wan, J.; Yuan, Y. Locality Constraint Distance Metric Learning for Traffic Congestion Detection. Pattern Recognition. 2018, 75, 272–281. [Google Scholar] [CrossRef]
- Wang, Q.; Chen, M.; Nie, F.; Li, X. Detecting Coherent Groups in Crowd Scenes by Multiview Clustering. TPAMI 2018. [Google Scholar] [CrossRef]
- Yuan, Y.; Xiong, Z.; Wang, Q. An Incremental framework for Video-based Traffic Sign Detection, Tracking and Recognition. ITSM 2016, 18, 1918–1929. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. TRAMPI 2015, 38, 142–158. [Google Scholar] [CrossRef]
- Uijlings, J.R.R.; Sande, K.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. TRAMPI 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Zeng, D.; Zhao, F.; Ge, S.; Shen, W. Fast cascade face detection with pyramid network. Pattern Recognit. Lett. 2018. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Fu, C.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. arXiv, 2017; arXiv:1612.03144. [Google Scholar]
- Vakalopoulou, M.; Karantzalos, K.; Komodakis, N.; Paragios, N. Building detection in very high resolution multispectral data with deep learning features. In Proceedings of the IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 1873–1876. [Google Scholar]
- Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep Learning Approach for Car Detection in UAV Imagery. Remote Sens. 2017, 9, 312. [Google Scholar] [CrossRef]
- Zhang, L.; Shi, Z.; Wu, J. A Hierarchical Oil Tank Detector with Deep Surrounding Features for High-Resolution Optical Satellite Imagery. IEEE J. STARS 2017, 8, 1–15. [Google Scholar] [CrossRef]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.P.; Xu, M.Z. Weakly Supervised Learning Based on Coupled Convolutional Neural Networks for Aircraft Detection. IEEE Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Convolutional Neural Networks for Large-Scale Remote-Sensing Image Classification. IEEE Geosci. Remote Sens. 2016, 55, 645–657. [Google Scholar] [CrossRef]
- Sun, L.; Tang, Y.; Zhang, L. Rural Building Detection in High-Resolution Imagery Based on a Two-Stage CNN Model. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1998–2002. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Chen, C.Y.; Gong, W.G.; Hu, Y.; Chen, Y.L.; Ding, Y. Learning Oriented Region-based Convolutional Neural Networks for Building Detection in Satellite Remote Sensing Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-1/W1, 461–464. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Guo, W.; Yang, W.; Zhang, H.; Hua, G. Geospatial Object Detection in High Resolution Satellite Images Based on Multi-Scale Convolutional Neural Network. Remote Sens. 2018, 10, 131. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection in Remote Sensing Images from Google Earth of Complex Scenes Based on Multiscale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Yu, B.; Yang, L.; Chen, F. Semantic Segmentation for high spatial resolution remote sensing images based on convolution neural network and pyramid pooling module. IEEE J. STARS 2018, 99, 1–10. [Google Scholar] [CrossRef]
- Xia, G.S.; Bai, X.; Ding, J.; Zhu, Z.; Belongie, S.; Luo, J.; Datcu, M.; Pelillo, M.; Zhang, L. DOTA: A Large-scale Dataset for Object Detection in Aerial Images. arXiv, 2017; arXiv:1711.10398. [Google Scholar]
- He, K.; Gkioxari, G.; Dollar, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 99, 1-1. [Google Scholar] [CrossRef]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. arXiv, 2017; arXiv:1611.05431. [Google Scholar]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv, 2015; arXiv:1511.07122. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Wu, Y.X.; He, K.M. Group Normalization. arXiv, 2018; arXiv:1803.08494. [Google Scholar]
- Gao, X.; Sun, X.; Zhang, Y.; Yan, M.; Xu, G.; Sun, X.; Jiao, J.; Fu, K. An end-to-end neural network for road extraction from remote sensing imagery by multiple feature pyramid network. IEEE Access. 2018, 6, 39401–39414. [Google Scholar] [CrossRef]
- Girshick, R.; Radosavovic, I.; Gkioxari, G.; Dollar, P.; He, K. Detectron. Available online: https://github.com/facebookresearch/detectron (accessed on 22 January 2018).














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Object Classes | Number of Images | Number of Relevant Scenes Images |
|---|---|---|
| Ground track field | 177 | 138 (scenes of sports areas) |
| Ship | 326 | 318 (scenes of rivers and seas) |
| Soccer field | 136 | 105 (scenes of sports areas) |
| Helicopter | 30 | 30 (scenes of airplanes) |
| Large vehicle | 380 | 380 (scenes of roads and parking lots) |
| Small vehicle | 486 | 480 (scenes of roads and parking lots) |
| Bridge | 210 | 210 (scenes of rivers) |
| Baseball diamond | 122 | 122 (scenes of sports areas) |
| Tennis court | 302 | 278 (scenes of sports areas) |
| Roundabout | 170 | 169 (scenes of crossroads) |
| Plane | 197 | 193 (scenes of airplanes) |
| Basketball court | 111 | 102 (scenes of sports areas) |
| Swimming pool | 144 | 143 (scenes of sports and residential areas) |
| Storage tank | 161 | 158 (scenes of country) |
| Harbor | 339 | 339 (scenes of rivers and seas) |
| Stage | Output | ResNet-50 | ResNeXt-50 | ResNeXt-d-50 |
|---|---|---|---|---|
| C1 | 112112 | 77, 64 | 77, 64 | 77, 64 |
| C2 | 56 56 | 33 max pool | 33 max pool | 33 max pool |
| C3 | 2828 | |||
| C4 | 1414 | |||
| C5 | 77 | |||
| 11 | 15-d fc, softmax | 15-d fc, softmax | 15-d fc, softmax | |
| Parameter Scale | ||||
| Detection Methods | Backbone | SC | FPN | GN | mAP (%) |
|---|---|---|---|---|---|
| R-FCN [4] | ResNet-101 | - | - | - | 45.63 |
| Faster R-CNN | ResNet-101 | - | - | - | 49.18 |
| Faster FPN | ResNet-101 | - | √ | - | 71.36 |
| Faster FPN-1 | ResNeXt-101 | - | √ | - | 72.68 |
| Faster FPN-2 | ResNeXt-d-101 | - | √ | - | 74.31 |
| Faster FPN-3 | ResNeXt-d-101 | - | √ | √ | 75.65 |
| SCFPN-1 | ResNeXt-101 | √ | √ | - | 75.22 |
| SCFPN-2 | ResNeXt-d-101 | √ | √ | - | 77.63 |
| SCFPN-3 | ResNeXt-d-101 | √ | √ | √ | 79.32 |
| Method | R-FCN | Faster RCNN | Faster FPN | SCFPN-1 | SCFPN-2 | SCFPN-3 |
|---|---|---|---|---|---|---|
| F1 (%) | 36.68 | 40.84 | 60.02 | 66.97 | 69.15 | 72.44 |
| Method | R-FCN | Faster RCNN | Faster FPN | SCFPN-1 | SCFPN-2 | SCFPN-3 |
|---|---|---|---|---|---|---|
| Testing Time | 0.18 s | 0.17 s | 0.20 s | 0.22 s | 0.22 s | 0.24 s |
| Method | R-FCN | Faster RCNN | Faster FPN | SCFPN-1 | SCFPN-2 | SCFPN-3 |
|---|---|---|---|---|---|---|
| mAP (%) | 41.26 | 46.93 | 70.11 | 74.46 | 76.52 | 78.69 |
| F1 (%) | 37.45 | 41.38 | 59.17 | 66.72 | 69.54 | 73.11 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, C.; Gong, W.; Chen, Y.; Li, W. Object Detection in Remote Sensing Images Based on a Scene-Contextual Feature Pyramid Network. Remote Sens. 2019, 11, 339. https://doi.org/10.3390/rs11030339
Chen C, Gong W, Chen Y, Li W. Object Detection in Remote Sensing Images Based on a Scene-Contextual Feature Pyramid Network. Remote Sensing. 2019; 11(3):339. https://doi.org/10.3390/rs11030339
Chicago/Turabian StyleChen, Chaoyue, Weiguo Gong, Yongliang Chen, and Weihong Li. 2019. "Object Detection in Remote Sensing Images Based on a Scene-Contextual Feature Pyramid Network" Remote Sensing 11, no. 3: 339. https://doi.org/10.3390/rs11030339
APA StyleChen, C., Gong, W., Chen, Y., & Li, W. (2019). Object Detection in Remote Sensing Images Based on a Scene-Contextual Feature Pyramid Network. Remote Sensing, 11(3), 339. https://doi.org/10.3390/rs11030339