Weakly Supervised Segmentation of SAR Imagery Using Superpixel and Hierarchically Adversarial CRF




Abstract
:1. Introduction
2. Related Work
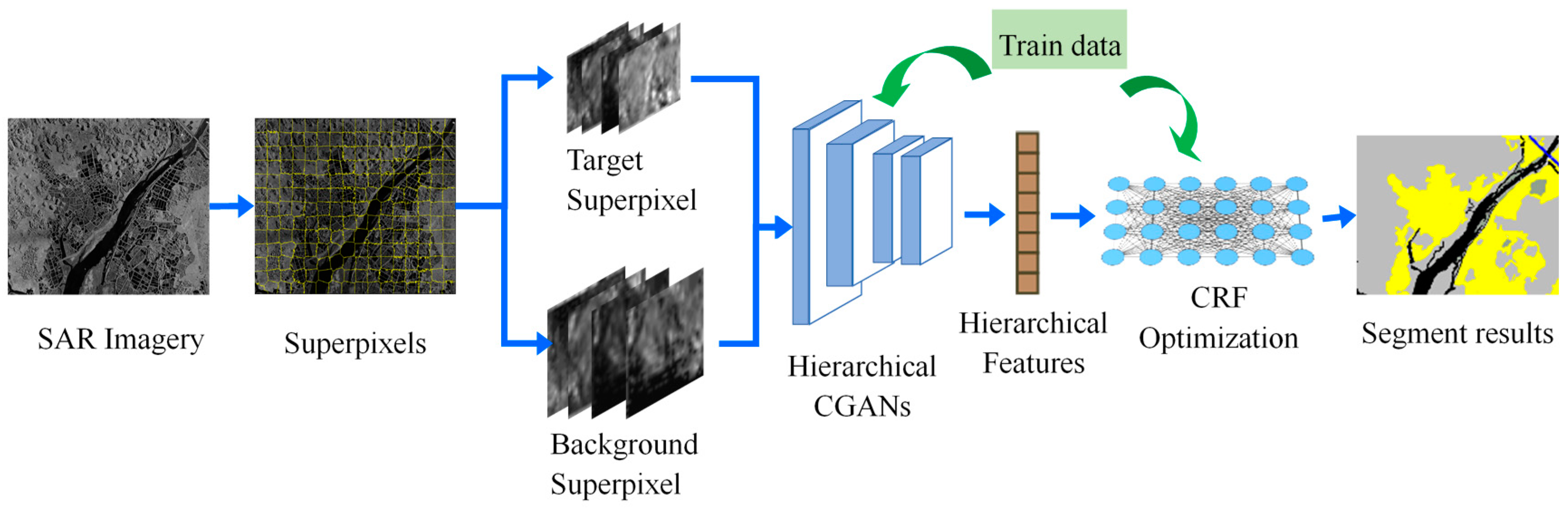
3. Hierarchically Adversarial CRF
3.1. Target Superpixels and Background Superpixels
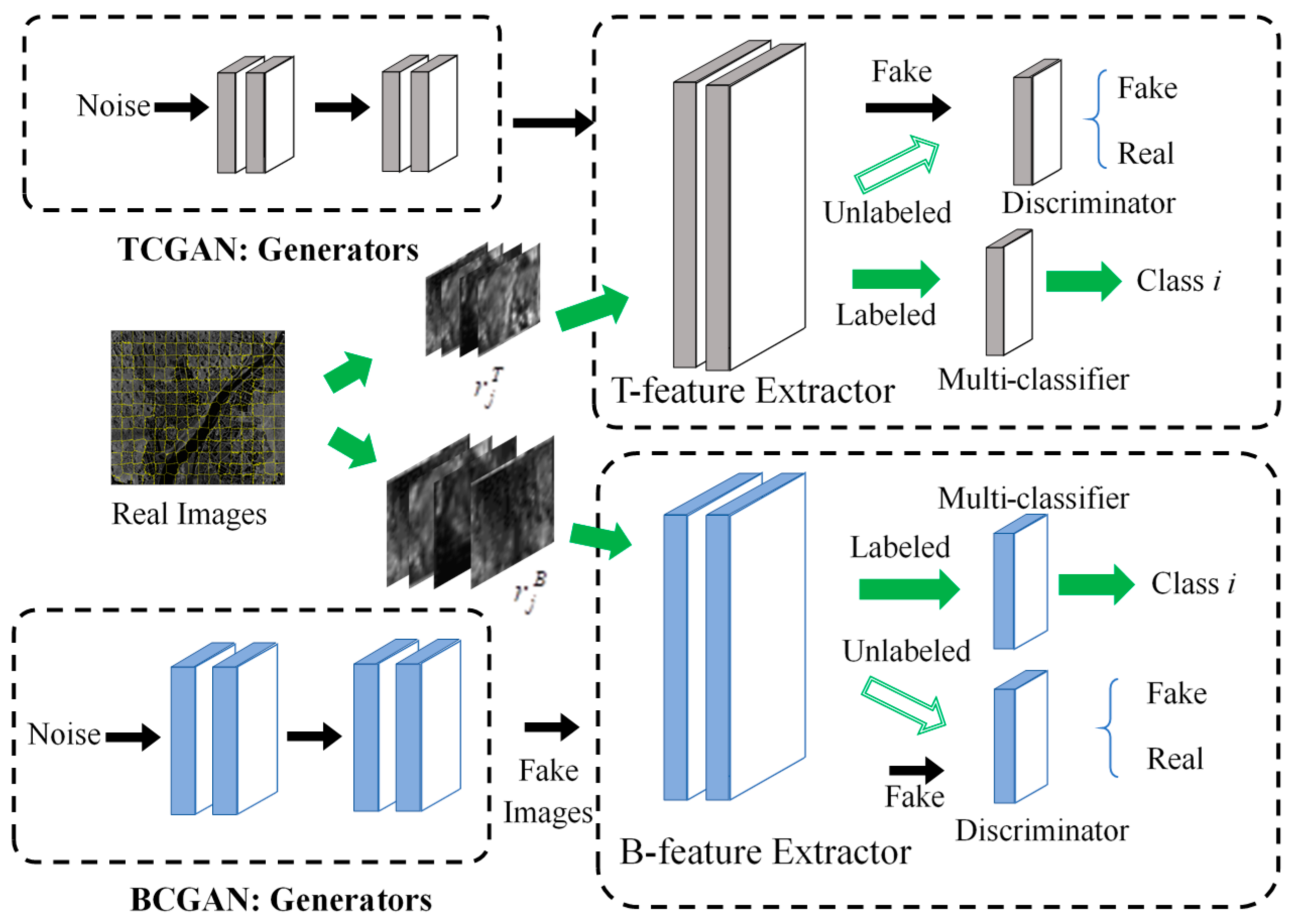
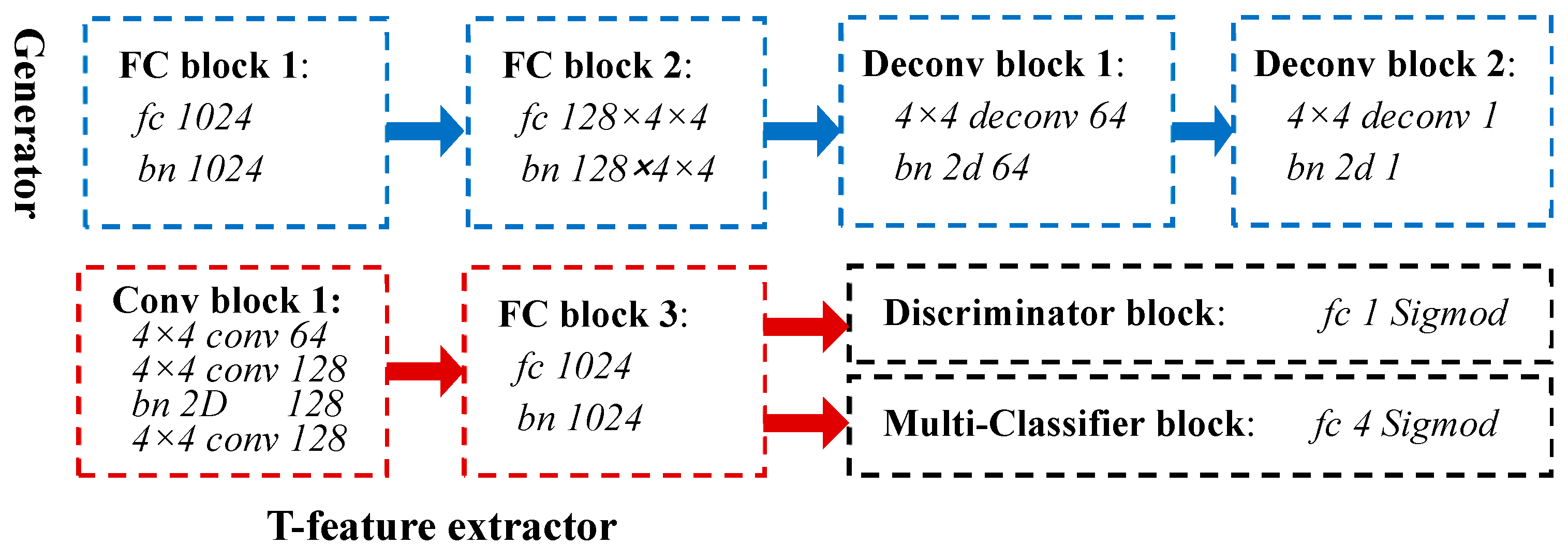
3.2. Hierachical CGANs
3.3. Superpixel-Wise Segmentation Using Conditional Random Field
| Algorithm 1: Hierarchical Adversarial CRF (HACRF) based Image Segmentation |
| Input: Training images , test images Output: Superpixel-wise segmentation of image procedure Training Hierarchical CGANs.  procedure Training CRF
|
4. Results
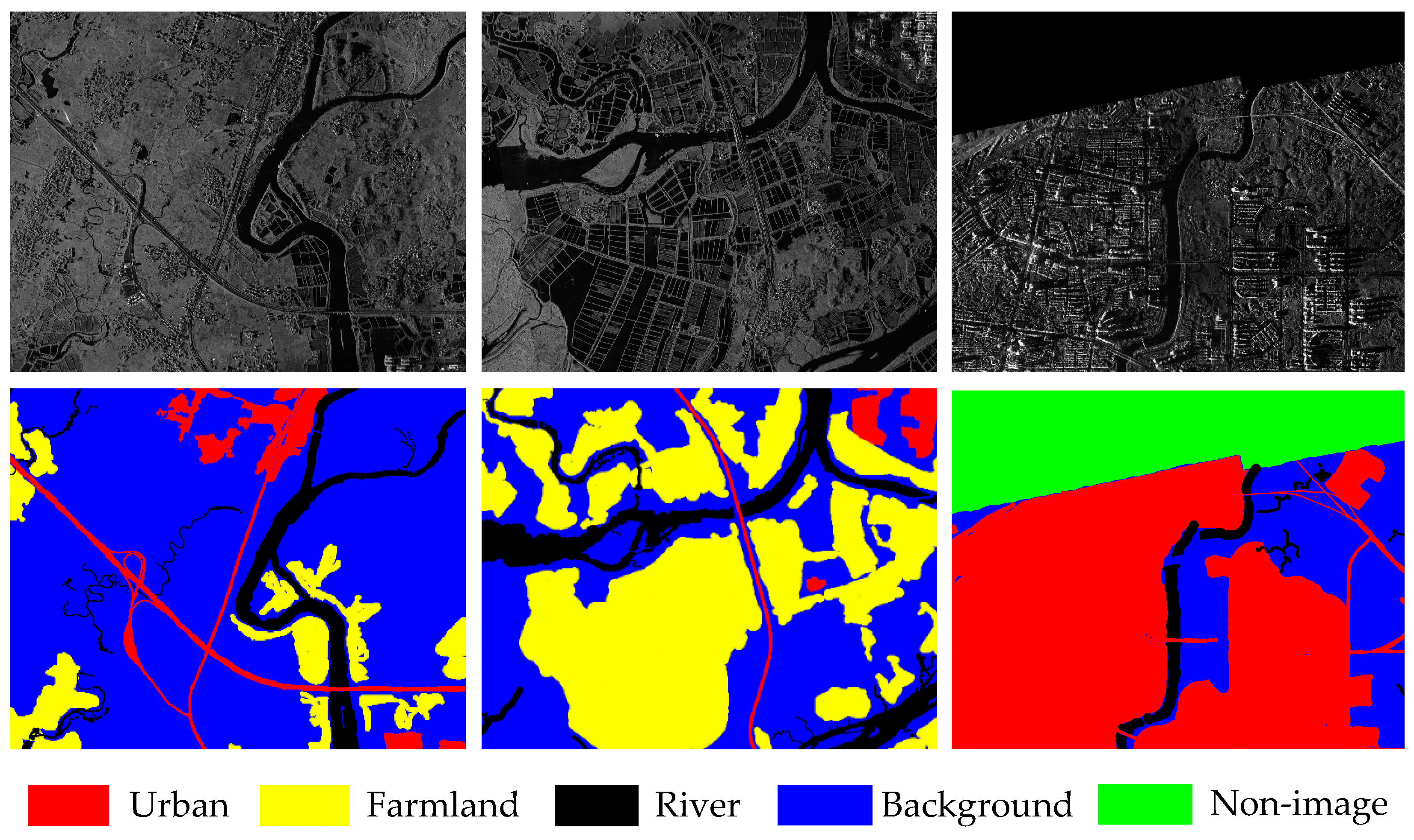
4.1. Data Description
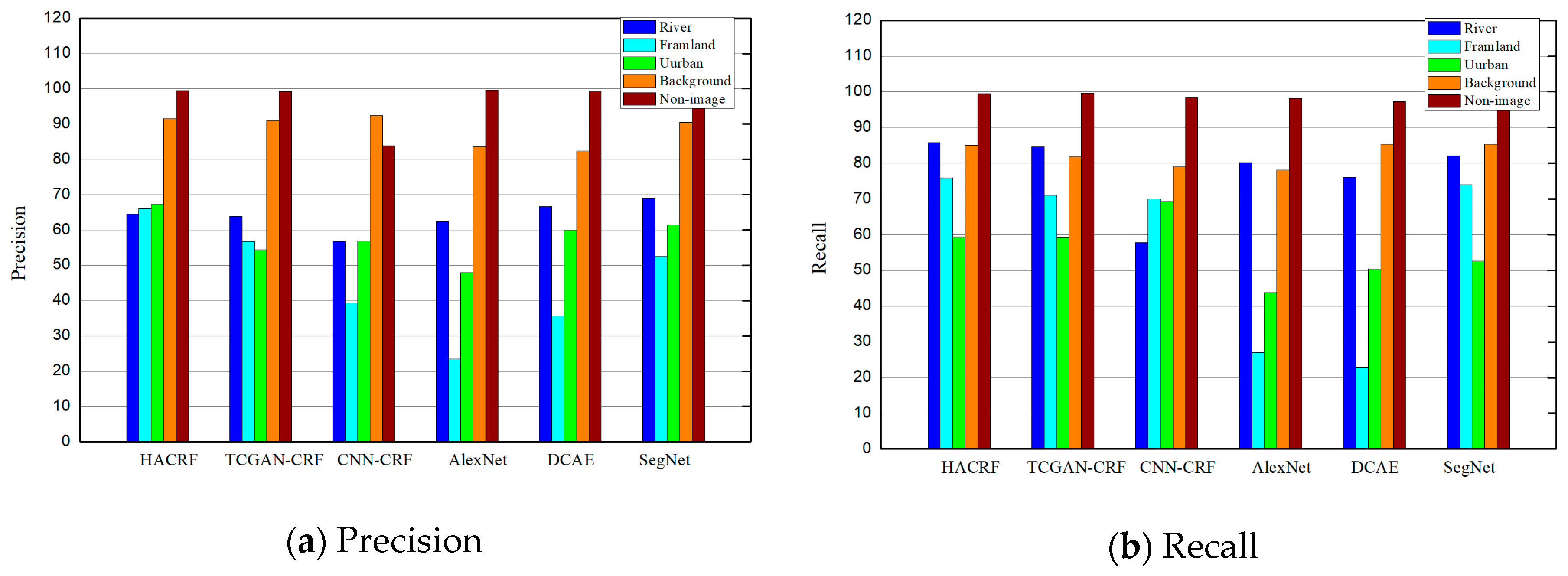
4.2. Evaluation Measures
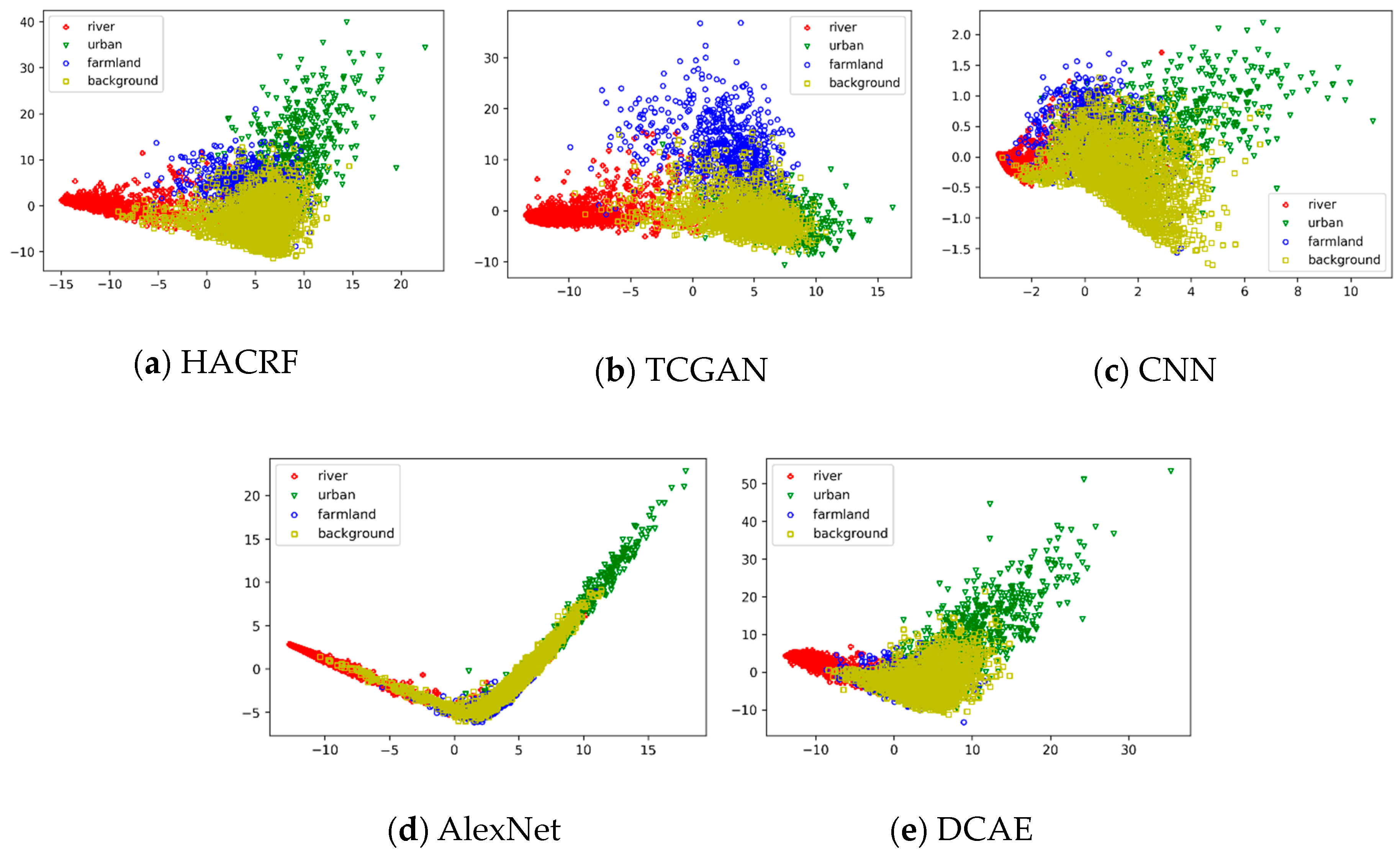
4.3. Feature Extraction Analysis
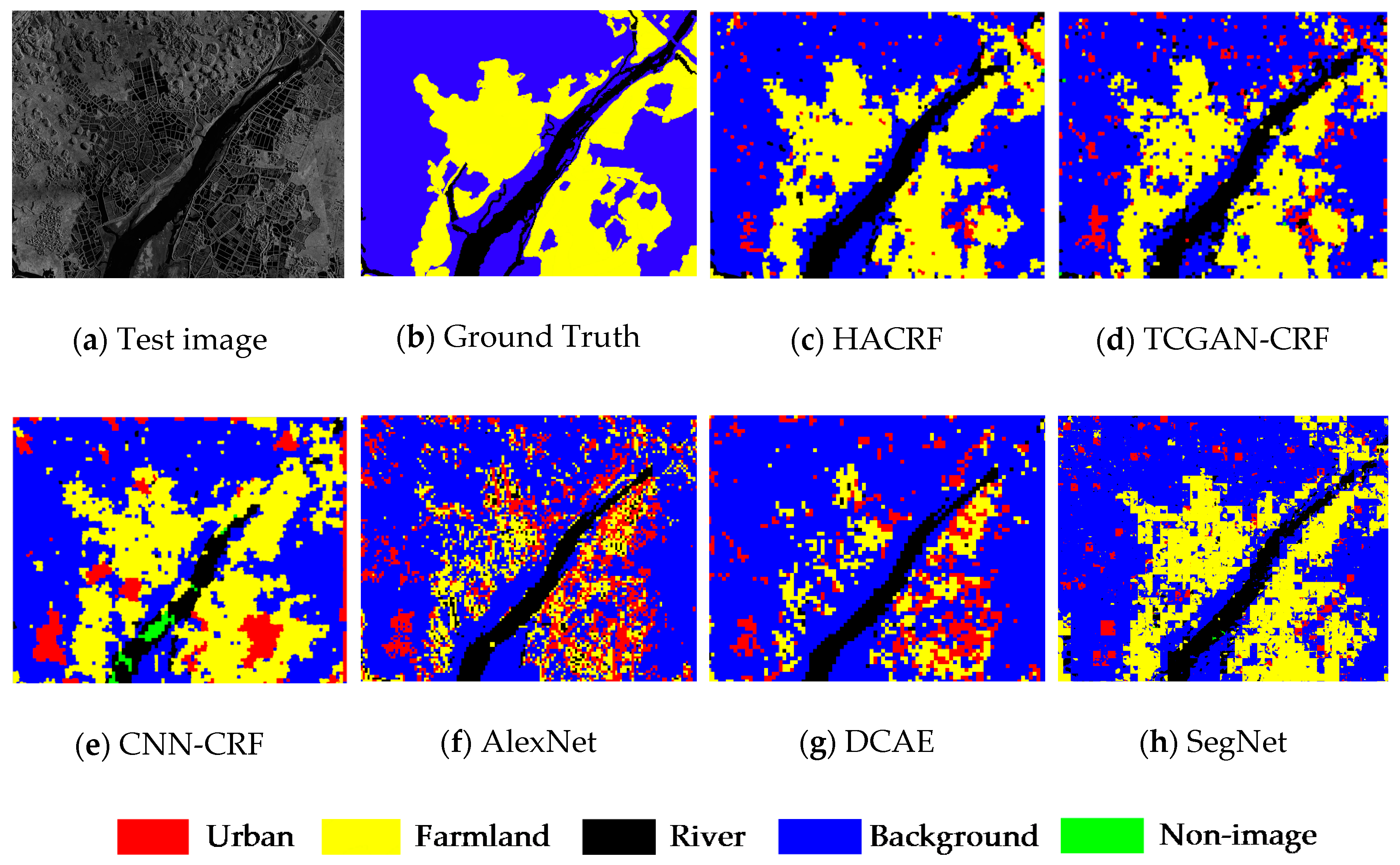
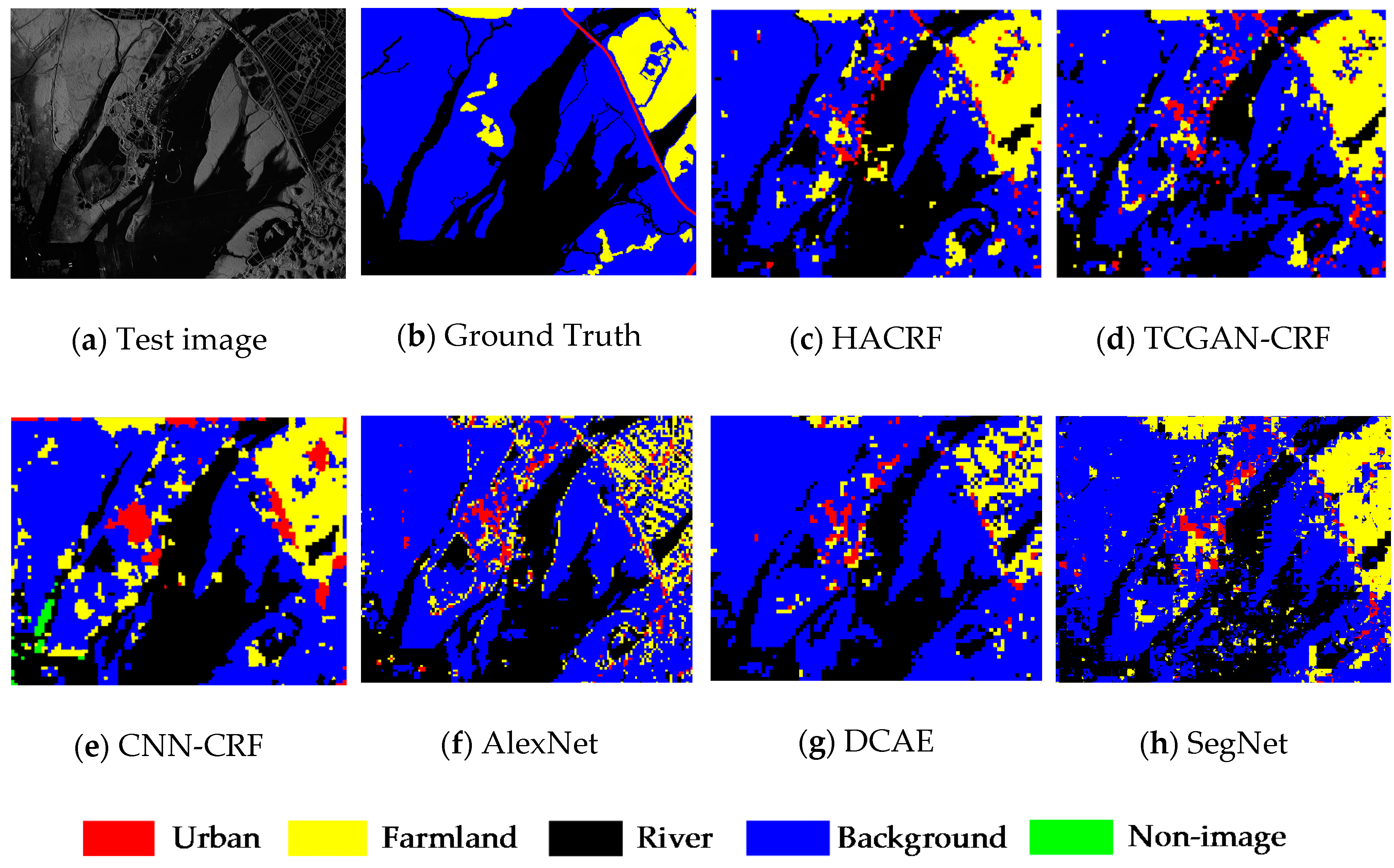
4.4. Segmentation Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Mason, D.; Davenport, I.; Neal, J.; Schumann, G.; Bates, P.D. Nearreal-time flood detection in urban and rural areas using high resolution synthetic aperture radar images. IEEE Trans. Geosci. Remote Sens. 2012, 50, 3041–3052. [Google Scholar] [CrossRef]
- Covello, F.; Battazza, F.; Coletta, A.; Lopinto, E.; Fiorentino, C.; Pietranera, L.; Valentini, G.; Zoffoli, S. COSMO-SkyMed—An existing opportunity for observing the Earth. J. Geodyn. 2010, 49, 171–180. [Google Scholar] [CrossRef]
- Prati, C.M.; Rocca, F.; Asaro, F.; Belletti, B.; Bizzi, S. Use of cross-POL multi-temporal SAR data for image segmentation. In Proceedings of the 2018 IEEE International Conference on Environmental Engineering, Milan, Italy, 12–14 March 2018; pp. 1–6. [Google Scholar]
- Zhou, L.; Guo, C.; Li, Y.; Shang, Y. Change Detection Based on Conditional Random Field with Region Connection Constraints in High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 9, 3478–3488. [Google Scholar] [CrossRef]
- Suykens, J.A.K.; Vandewalle, J. Least squares support vector machine classifiers. Neural Process. Lett. 1999, 9, 293–300. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by random Forest. R News 2002, 2, 18–22. [Google Scholar]
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Lang, F.; Yang, J.; Yan, S.; Qin, F. Superpixel Segmentation of Polarimetric Synthetic Aperture Radar (SAR) Images Based on Generalized Mean Shift. Remote Sens. 2018, 10, 1592. [Google Scholar] [CrossRef]
- Stutz, D.; Hermans, A.; Leibe, B. Superpixels: An Evaluation of the State-of-the-Art. Comput. Vis. Image Underst. 2018, 166, 1–27. [Google Scholar] [CrossRef]
- Ciecholewski, M. River channel segmentation in polarimetric SAR images. Expert Syst. Appl. 2017, 82, 196–215. [Google Scholar] [CrossRef]
- Cousty, J.; Bertrand, G.; Najman, L.; Couprie, M. Watershed cuts: Thinnings, shortest path forests, and topological watersheds. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 925–939. [Google Scholar] [CrossRef] [PubMed]
- Braga, A.M.; Marques, R.C.P.; Rodrigues, F.A.A.; Medeiros, F.N.S. A Median Regularized Level Set for Hierarchical Segmentation of SAR Images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1171–1175. [Google Scholar] [CrossRef]
- Jin, R.; Yin, J.; Zhou, W.; Jian, Y. Level Set Segmentation Algorithm for High-Resolution Polarimetric SAR Images Based on a Heterogeneous Clutter Model. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4565–4579. [Google Scholar] [CrossRef]
- Lafferty, J.D.; Mccallum, A.; Pereira, F.C.N. Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data. In Proceedings of the 18th International Conference on Machine Learning 2001 (ICML 2001), Williamstown, WA, USA, 28 June–1 July 2001; Volume 3, pp. 282–289. [Google Scholar]
- Liu, F.; Lin, G.; Shen, C. CRF learning with CNN features for image segmentation. Pattern Recognit. 2015, 48, 2983–2992. [Google Scholar] [CrossRef]
- Szummer, M.; Kohli, P.; Hoiem, D. Learning CRFs Using Graph Cuts. In Proceedings of the European Conference on Computer Vision, Marseille, France, 12–18 October 2008. [Google Scholar]
- Zhong, P.; Wang, R. Learning conditional random fields for classification of hyperspectral images. IEEE Trans. Image Process. 2010, 19, 1890–1907. [Google Scholar] [CrossRef] [PubMed]
- Xu, L.; Clausi, D.A.; Li, F.; Wong, A. Weakly Supervised Classification of Remotely Sensed Imagery Using Label Constraint and Edge Penalty. IEEE Trans. Geosci. Remote Sens. 2017, 55, 1424–1436. [Google Scholar] [CrossRef]
- Sultani, W.; Mokhtari, S.; Yun, H.B. Automatic Pavement Object Detection Using Superpixel Segmentation Combined with Conditional Random Field. IEEE Trans. Intell. Transp. Syst. 2018, 19, 2076–2085. [Google Scholar] [CrossRef]
- Li, Y.; Tan, Y. Cauchy Graph Embedding Optimization for Built-Up Areas Detection from High-Resolution Remote Sensing Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2078–2096. [Google Scholar] [CrossRef]
- Guo, E.; Bai, L.; Zhang, Y.; Han, J. Vehicle Detection Based on Superpixel and Improved HOG in Aerial Images. In International Conference on Image and Graphics; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Xiang, D.; Tang, T.; Zhao, L.; Su, Y. Superpixel Generating Algorithm Based on Pixel Intensity and Location Similarity for SAR Image Classification. IEEE Geosci. Remote Sens. Lett. 2013, 10, 1414–1418. [Google Scholar] [CrossRef]
- Micusik, B.; Kosecka, J. Semantic segmentation of street scenes by superpixel co-occurrence and 3D geometry. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Kyoto, Japan, 27 September–4 October 2009. [Google Scholar]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed]
- Chen, H.; Zhang, F.; Tang, B.; Yin, Q.; Sun, X. Slim and Efficient Neural Network Design for Resource-Constrained SAR Target Recognition. Remote Sens. 2018, 10, 1618. [Google Scholar] [CrossRef]
- Gao, F.; Ma, F.; Wang, J.; Sun, J.; Zhou, H. Visual Saliency Modeling for River Detection in High-resolution SAR Imagery. IEEE Access 2018, 6, 1000–1014. [Google Scholar] [CrossRef]
- Liu, F.; Lin, G.; Shen, C. Discriminative Training of Deep Fully-connected Continuous CRFs with Task-specific Loss. IEEE Trans. Image Process. 2017, 26, 2127–2136. [Google Scholar] [CrossRef] [PubMed]
- Alshehhi, R.; Marpu, P.R. Hierarchical graph-based segmentation for extracting road networks from high-resolution satellite images. ISPRS J. Photogramm. Remote Sens. 2017, 126, 245–260. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked Denoising Autoencoders: Learning Useful Representations in a Deep Network with a Local Denoising Criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Bengio, Y.; Lamblin, P.; Dan, P.; Larochelle, H. Greedy layer-wise training of deep networks. Adv. Neural Inf. Process. Syst. 2007, 19, 153–160. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Bing, X.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Varia, N.; Dokania, A.; Senthilnath, J. DeepExt: A Convolution Neural Network for Road Extraction using RGB images captured by UAV. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1890–1895. [Google Scholar]
- Fei, G.; Fei, M.; Wang, J.; Sun, J.; Yang, E.; Zhou, H. Semi-Supervised Generative Adversarial Nets with Multiple Generators for SAR Image Recognition. Sensors 2018, 18, 2706. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. Comput. Sci. 2014, 4, 357–361. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Kenduiywo, B.K.; Bargiel, D.; Soergel, U. Higher Order Dynamic Conditional Random Fields Ensemble for Crop Type Classification in Radar Images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4638–4654. [Google Scholar] [CrossRef]
- Geng, J.; Fan, J.; Wang, H.; Ma, X.; Li, B.; Chen, F. High-Resolution SAR Image Classification via Deep Convolutional Autoencoders. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1–5. [Google Scholar] [CrossRef]
- Csillik, O. Fast Segmentation and Classification of Very High Resolution Remote Sensing Data Using SLIC Superpixels. Remote Sens. 2017, 9, 243. [Google Scholar] [CrossRef]
- Zheng, S.; Jayasumana, S.; Romera-Paredes, B.; Vineet, V.; Su, Z.; Du, D.; Huang, C.; Torr, P.H. Conditional Random Fields as Recurrent Neural Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015. [Google Scholar]
- Lin, G.; Shen, C.; Hengel, A.V.D.; Reid, I. Efficient Piecewise Training of Deep Structured Models for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3194–3203. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved Techniques for Training GANs. In Proceedings of the Advances in Neural Information Processing Systems (NIPS 2016), Barcelona, Spain, 5–10 December 2016; pp. 2234–2242. [Google Scholar]
- Martins, A.F.T.; Figueiredo, M.A.T.; Aguiar, P.M.Q.; Smith, N.A.; Xing, E.P. AD3: Alternating directions dual decomposition for map inference in graphical models. J. Mach. Learn. Res. 2015, 16, 495–545. [Google Scholar]
- Zhang, F.; Yao, X.; Tang, H.; Yin, Q.; Hu, Y.; Lei, B. Multiple Mode SAR Raw Data Simulation and Parallel Acceleration for Gaofen-3 Mission. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2115–2126. [Google Scholar] [CrossRef]
- Martha, T.R.; Kerle, N.; Westen, C.J.V.; Jetten, V.; Kumar, K.V. Segment Optimization and Data-Driven Thresholding for Knowledge-Based Landslide Detection by Object-Based Image Analysis. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4928–4943. [Google Scholar] [CrossRef]
- Jie, G.; Wang, H.; Fan, J.; Ma, X. SAR Image Classification via Deep Recurrent Encoding Neural Networks. IEEE Trans. Geosci. Remote Sens. 2018, 56, 2255–2269. [Google Scholar]
- Sasaki, Y. The truth of the F-measure. Teach. Tutor Mater. 2007, 1, 1–5. [Google Scholar]
- Cohen, J. A coefficient of agreement for nominal scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical Evaluation of Rectified Activations in Convolutional Network. arXiv, 2015; arXiv:1505.00853. [Google Scholar]
- Wold, S. Principal component analysis. Chemom. Intell. Lab. Syst. 1987, 2, 37–52. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Miami, FL, USA, 20–25 June 2009. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. arXiv, 2015; arXiv:1505.07293. [Google Scholar]
- Tian, T.; Chang, L.; Jinkang, X.; Ma, J. Urban Area Detection in Very High Resolution Remote Sensing Images Using Deep Convolutional Neural Networks. Sensors 2018, 18, 904. [Google Scholar] [CrossRef] [PubMed]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Benefits | Defect |
|---|---|---|
| Pixel-wise CRF [16,35] | --- | Heavy calculation burden |
| Superpixel-wise + hand crafted feature + CRF [19,37] | Unsupervised; fewer calculation | Parameters designed by experiences |
| Superpixel-wise + deep feature + CRF [15,19,39] | Outstanding feature extraction ability | Supervised |
| End-to-end deep CRF [40,41] | Compact construction | Supervised |
| Urban | Farmland | River | Background | Non-Image | |
|---|---|---|---|---|---|
| Train | 6825 | 7332 | 7164 | 27,724 | 7402 |
| Test | 13,822 | 10,546 | 29,293 | 136,418 | 44,019 |
| Percent | 33.06% | 41.01% | 19.85% | 16.89% | 14.39% |
| HACRF | TCGAN-CRF | CNN-CRF | AlexNet | DCAE | SegNet | |
|---|---|---|---|---|---|---|
| OP (%) | 86.93 | 85.28 | 81.68 | 77.29 | 78.78 | 85.85 |
| OA (%) | 85.82 | 83.59 | 78.97 | 76.15 | 79.75 | 84.90 |
| F1-score (%) | 86.09 | 84.07 | 79.68 | 76.51 | 79.08 | 85.16 |
| κ | 0.7736 | 0.7418 | 0.6752 | 0.6303 | 0.6725 | 0.7579 |
| Class | HACRF | TCGAN-CRF | CNN-CRF | AlexNet | DCAE | SegNet |
|---|---|---|---|---|---|---|
| Urban | 63.17 | 56.72 | 62.54 | 45.79 | 54.86 | 61.46 |
| Farmland | 70.63 | 63.08 | 50.42 | 25.12 | 27.89 | 52.56 |
| River | 73.67 | 72.76 | 57.25 | 70.15 | 71.01 | 75.00 |
| Background | 88.10 | 86.13 | 85.16 | 80.69 | 83.79 | 90.43 |
| Non-image | 99.48 | 99.42 | 90.53 | 98.92 | 98.33 | 99.04 |
| Class | HACRF | TCGAN-CRF | CNN-CRF | AlexNet | DCAE | SegNet |
|---|---|---|---|---|---|---|
| Time(s) | 2183.15 | 2207.05 | 2775.87 | 480.34 | 4219.64 | 3379.75 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, F.; Gao, F.; Sun, J.; Zhou, H.; Hussain, A. Weakly Supervised Segmentation of SAR Imagery Using Superpixel and Hierarchically Adversarial CRF. Remote Sens. 2019, 11, 512. https://doi.org/10.3390/rs11050512
Ma F, Gao F, Sun J, Zhou H, Hussain A. Weakly Supervised Segmentation of SAR Imagery Using Superpixel and Hierarchically Adversarial CRF. Remote Sensing. 2019; 11(5):512. https://doi.org/10.3390/rs11050512
Chicago/Turabian StyleMa, Fei, Fei Gao, Jinping Sun, Huiyu Zhou, and Amir Hussain. 2019. "Weakly Supervised Segmentation of SAR Imagery Using Superpixel and Hierarchically Adversarial CRF" Remote Sensing 11, no. 5: 512. https://doi.org/10.3390/rs11050512
APA StyleMa, F., Gao, F., Sun, J., Zhou, H., & Hussain, A. (2019). Weakly Supervised Segmentation of SAR Imagery Using Superpixel and Hierarchically Adversarial CRF. Remote Sensing, 11(5), 512. https://doi.org/10.3390/rs11050512