A Single Shot Framework with Multi-Scale Feature Fusion for Geospatial Object Detection


Abstract
:1. Introduction
- (1)
- We produce and release a large-scale RSD-GOD with handcrafted annotations, which can be used for further geospatial object detection development especially in martial applications.
- (2)
- We apply a single shot detection framework with the multi-scale feature fusion module for detection on three different scales. The different feature maps in different layers are merged to make object predictions, which means more abundant information is explored together. The proposed method achieves a good tradeoff between superior detection accuracy and computation efficiency. In addition, the designed network shows an effective performance at detecting small targets.
- (3)
- The soft-NMS algorithm is applied through reassigning the neighboring bounding box a decayed score, which improves the detection performance of dense objects.
2. Materials and Methods
2.1. Annotation and Construction of Remote-Sensing Dataset for Geospatial Object Detection (RSD-GOD)
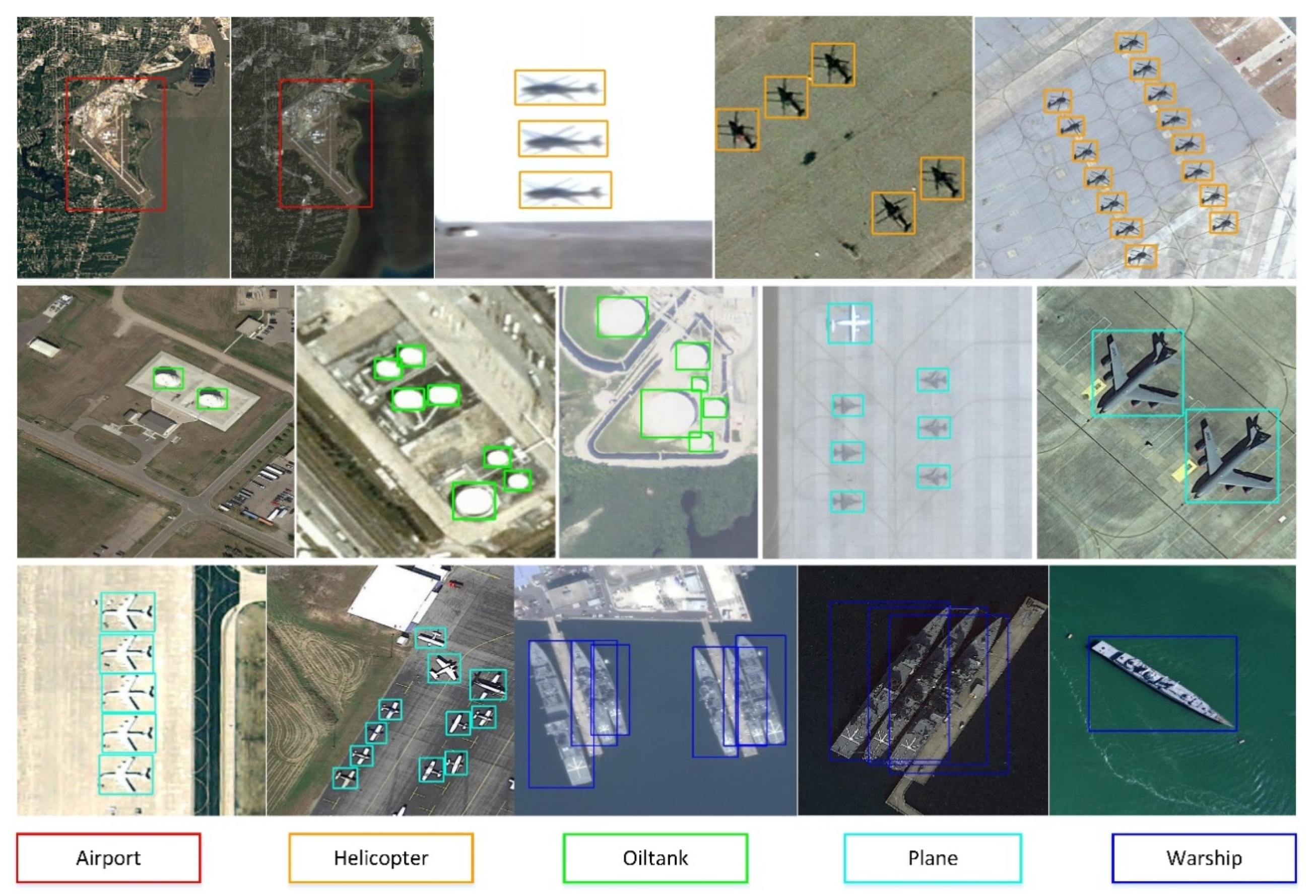
2.1.1. Category Selection and Image Collection
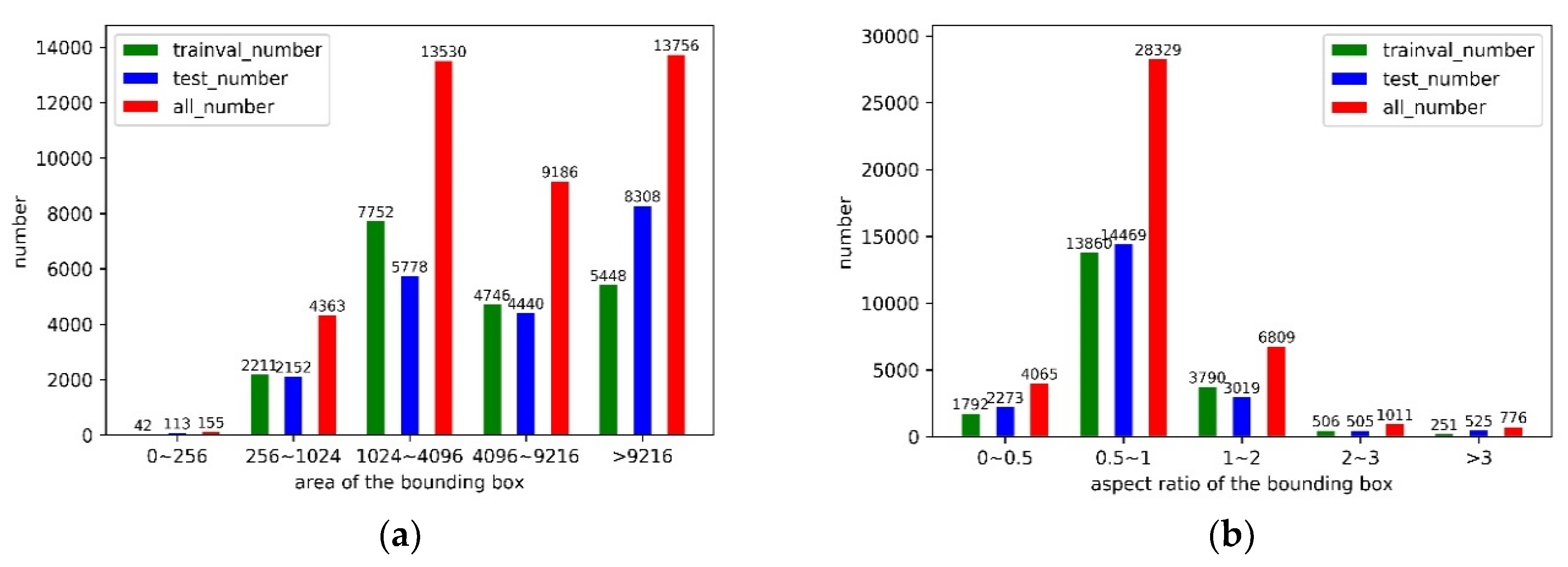
2.1.2. Dataset Analysis and Division
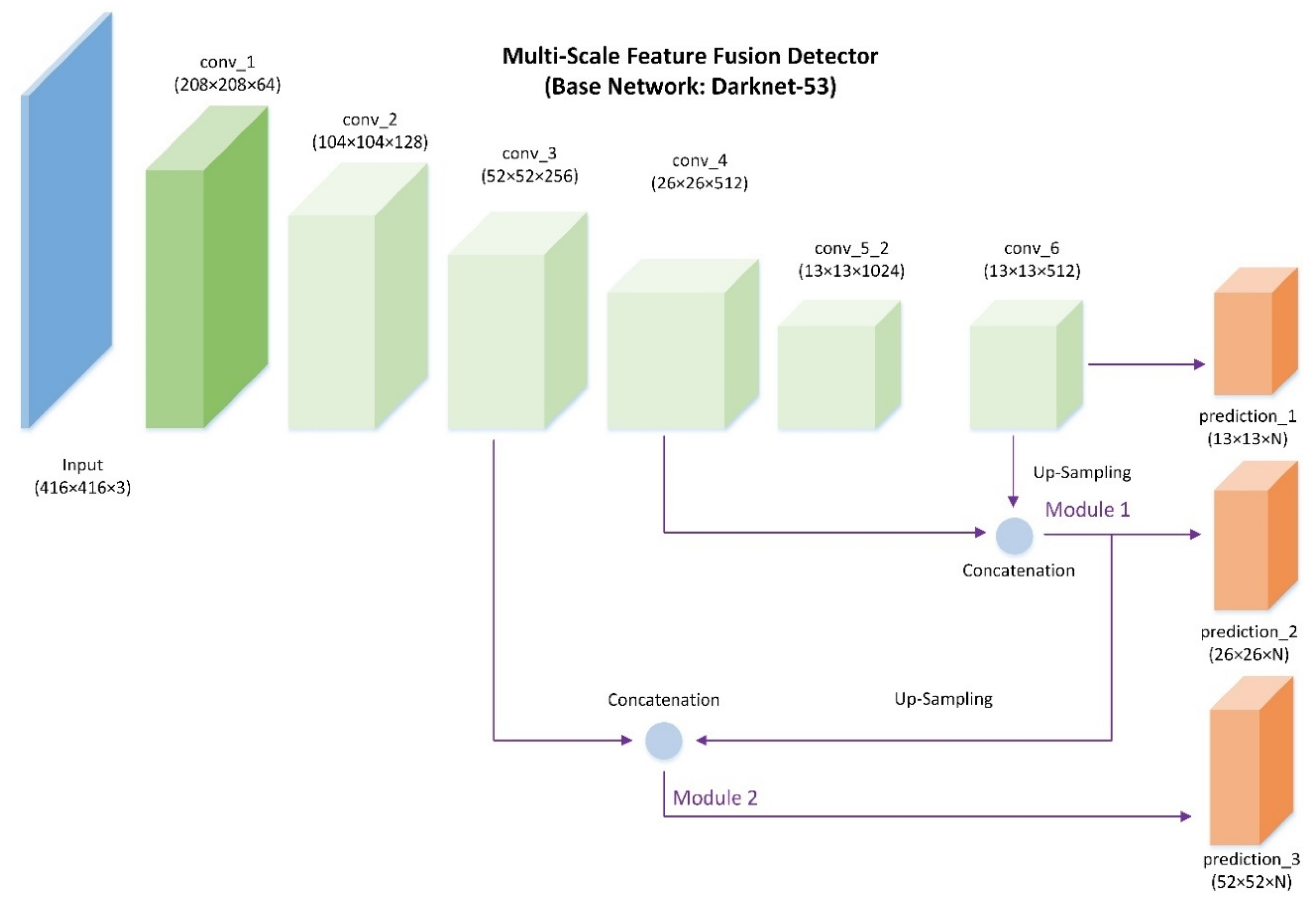
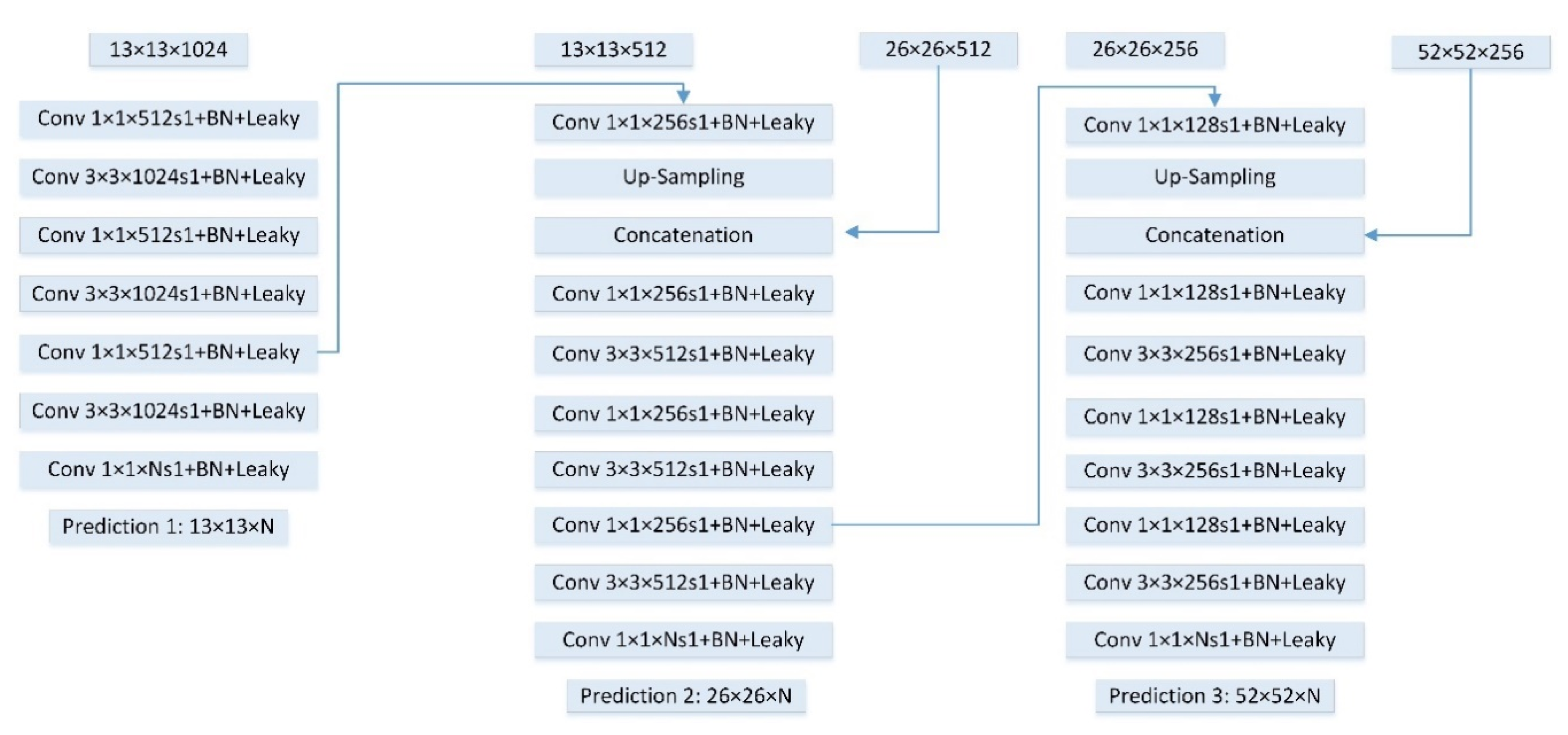
2.2. Single Shot Framework with Multi-Scale Feature Fusion
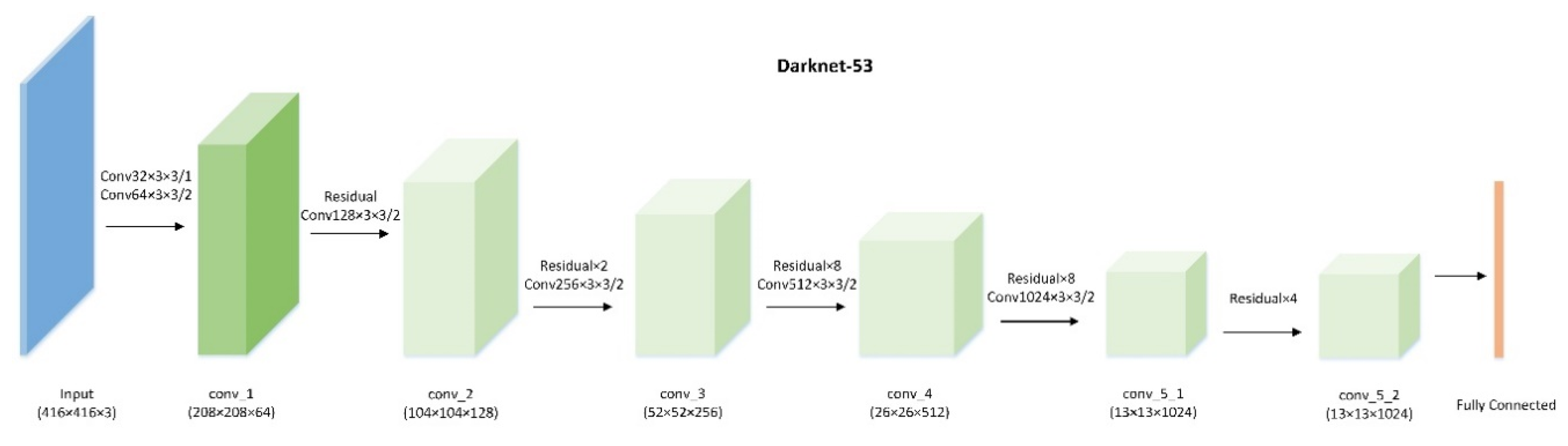
2.2.1. Darknet and Single Shot Framework
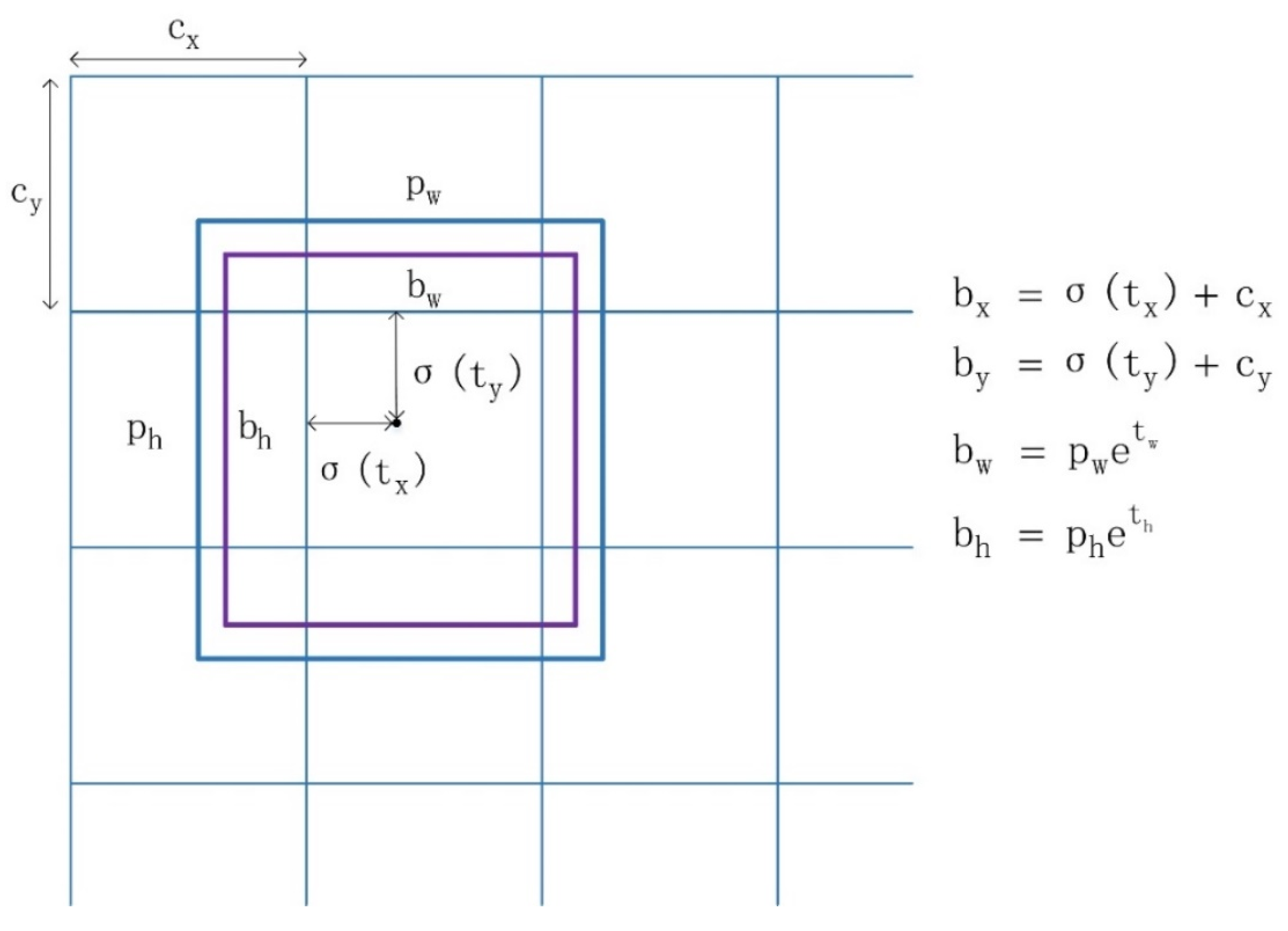
2.2.2. Loss Function
2.3. Soft Non-Maximum Suppression
3. Results and Discussion
3.1. Experimental Settings
3.1.1. Dataset
3.1.2. Evaluation Metrics
3.1.3. Compared Methods
3.1.4. Implementation Details
3.2. Results on RSD-GOD Dataset
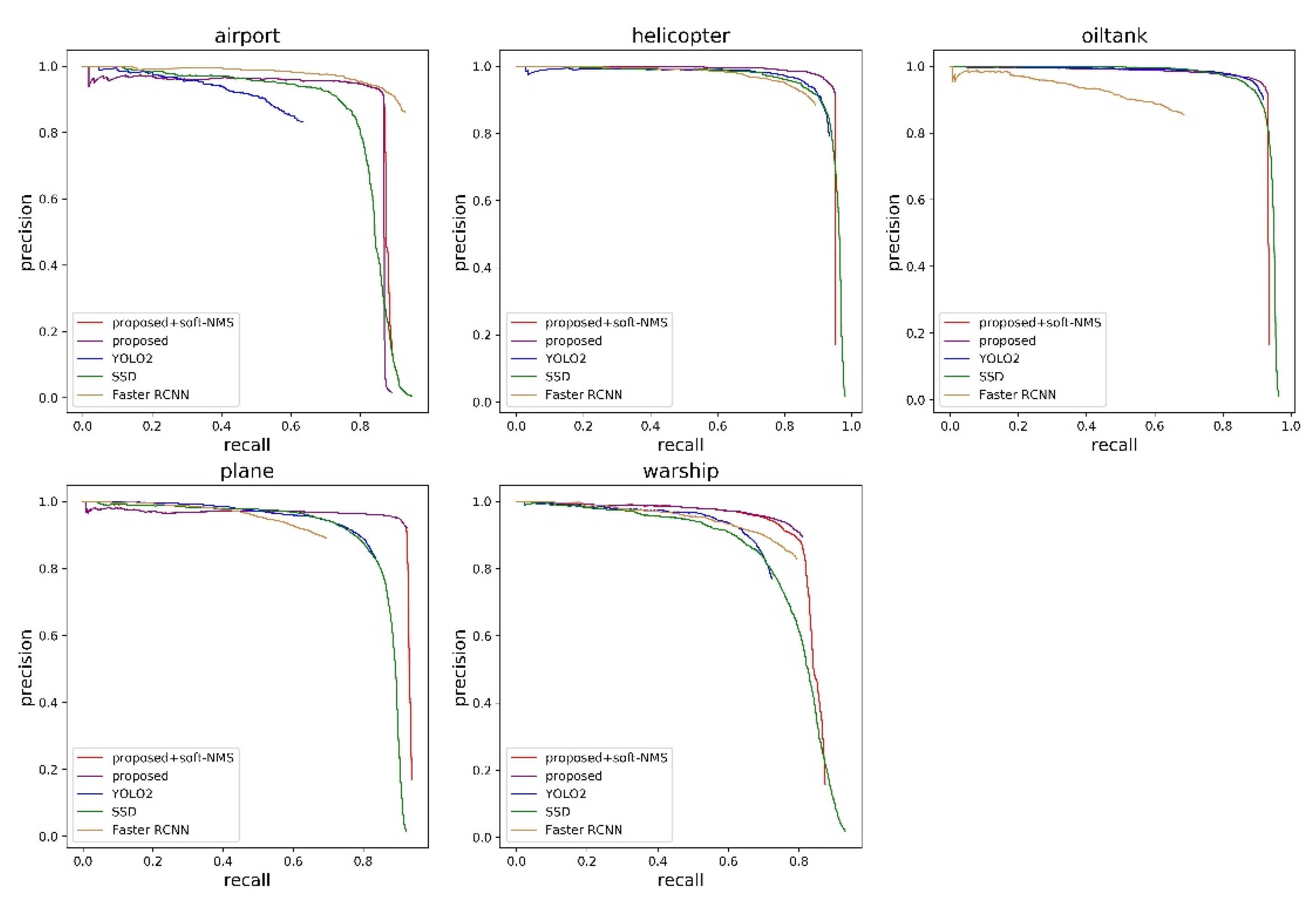
3.2.1. Quantitative Comparisons
3.2.2. Qualitative Analysis
3.3. Results on NWPU VHR-10 Dataset
3.4. Efficiency Analysis of Proposed Model
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, Z.; Zhang, T.; Ouyang, C. End-to-End Airplane Detection Using Transfer Learning in Remote Sensing Images. Remote Sens. 2018, 10, 139. [Google Scholar] [CrossRef]
- Kembhavi, A.; Harwood, D.; Davis, L.S. Vehicle Detection Using Partial Least Squares. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1250–1265. [Google Scholar] [CrossRef]
- Tuermer, S.; Kurz, F.; Reinartz, P.; Stilla, U. Airborne Vehicle Detection in Dense Urban Areas Using HoG Features and Disparity Maps. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2327–2337. [Google Scholar] [CrossRef]
- Grabner, H.; Nguyen, T.T.; Gruber, B.; Bischof, H. On-line boosting-based car detection from aerial images. ISPRS J. Photogramm. Remote Sens. 2008, 63, 382–396. [Google Scholar] [CrossRef]
- Han, X.; Zhong, Y.; Zhang, L. An Efficient and Robust Integrated Geospatial Object Detection Framework for High Spatial Resolution Remote Sensing Imagery. Remote Sens. 2017, 9, 666. [Google Scholar] [CrossRef]
- Zhang, F.; Du, B.; Zhang, L.; Xu, M. Weakly Supervised Learning Based on Coupled Convolutional Neural Networks for Aircraft Detection. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5553–5563. [Google Scholar] [CrossRef]
- Liu, K.; Mattyus, G. Fast Multiclass Vehicle Detection on Aerial Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar]
- Liu, Z.; Wang, H.; Weng, L.; Yang, Y. Ship Rotated Bounding Box Space for Ship Extraction from High-Resolution Optical Satellite Images With Complex Backgrounds. IEEE Geosci. Remote Sens. Lett. 2016, 13, 1074–1078. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Zhou, P.; Guo, L. Multi-class geospatial object detection and geographic image classification based on collection of part detectors. ISPRS J. Photogramm. Remote Sens. 2014, 98, 119–132. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J. A survey on object detection in optical remote sensing images. ISPRS J. Photogramm. Remote Sens. 2016, 117, 11–28. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of Oriented Gradients for Human Detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: San Diego, CA, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Li, F.; Perona, P. A Bayesian Hierarchical Model for Learning Natural Scene Categories. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; IEEE: San Diego, CA, USA, 2005; Volume 2, pp. 524–531. [Google Scholar]
- Tao, C.; Tan, Y.; Cai, H.; Tian, J. Airport Detection From Large IKONOS Images Using Clustered SIFT Keypoints and Region Information. IEEE Geosci. Remote Sens. Lett. 2011, 8, 128–132. [Google Scholar] [CrossRef]
- Aytekin, Ö.; Zongur, U.; Halici, U. Texture-Based Airport Runway Detection. IEEE Geosci. Remote Sens. Lett. 2013, 10, 471–475. [Google Scholar] [CrossRef]
- Zhang, D.; Han, J.; Cheng, G.; Liu, Z.; Bu, S.; Guo, L. Weakly Supervised Learning for Target Detection in Remote Sensing Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 701–705. [Google Scholar] [CrossRef]
- Han, J.; Zhang, D.; Cheng, G.; Guo, L.; Ren, J. Object Detection in Optical Remote Sensing Images Based on Weakly Supervised Learning and High-Level Feature Learning. IEEE Trans. Geosci. Remote Sens. 2015, 53, 3325–3337. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Guo, L.; Qian, X.; Zhou, P.; Yao, X.; Hu, X. Object detection in remote sensing imagery using a discriminatively trained mixture model. ISPRS J. Photogramm. Remote Sens. 2013, 85, 32–43. [Google Scholar] [CrossRef]
- Sun, H.; Sun, X.; Wang, H.; Li, Y.; Li, X. Automatic Target Detection in High-Resolution Remote Sensing Images Using Spatial Sparse Coding Bag-of-Words Model. IEEE Geosci. Remote Sens. Lett. 2012, 9, 109–113. [Google Scholar] [CrossRef]
- Zhang, W.; Sun, X.; Fu, K.; Wang, C.; Wang, H. Object Detection in High-Resolution Remote Sensing Images Using Rotation Invariant Parts Based Model. IEEE Geosci. Remote Sens. Lett. 2014, 11, 74–78. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Bi, F.; Zhu, B.; Gao, L.; Bian, M. A Visual Search Inspired Computational Model for Ship Detection in Optical Satellite Images. IEEE Geosci. Remote Sens. Lett. 2012, 9, 749–753. [Google Scholar]
- Leitloff, J.; Hinz, S.; Stilla, U. Vehicle Detection in Very High Resolution Satellite Images of City Areas. IEEE Trans. Geosci. Remote Sens. 2010, 48, 2795–2806. [Google Scholar] [CrossRef]
- Shi, Z.; Yu, X.; Jiang, Z.; Li, B. Ship Detection in High-Resolution Optical Imagery Based on Anomaly Detector and Local Shape Feature. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4511–4523. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. arXiv, 2013; arXiv:1311.2524. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 13–16 December 2015; IEEE: Santiago, Chile, 2015; pp. 1440–1448. [Google Scholar]
- Uijlings, J.R.R.; van de Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. arXiv, 2015; arXiv:1506.02640. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv, 2016; arXiv:1612.08242. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9905, pp. 21–37. ISBN 978-3-319-46447-3. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-based Fully Convolutional Networks. arXiv, 2016; arXiv:1605.06409. [Google Scholar]
- Xu, M.; Cui, L.; Lv, P.; Jiang, X.; Niu, J.; Zhou, B.; Wang, M. MDSSD: Multi-scale Deconvolutional Single Shot Detector for Small Objects. arXiv, 2018; arXiv:1805.07009. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv, 2017; arXiv:1701.06659. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv, 2018; arXiv:1804.02767. [Google Scholar]
- Xie, H.; Wang, T.; Qiao, M.; Zhang, M.; Shan, G.; Snoussi, H. Robust object detection for tiny and dense targets in VHR aerial images. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; IEEE: Jinan, China, 2017; pp. 6397–6401. [Google Scholar]
- Long, Y.; Gong, Y.; Xiao, Z.; Liu, Q. Accurate Object Localization in Remote Sensing Images Based on Convolutional Neural Networks. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2486–2498. [Google Scholar] [CrossRef]
- Zhong, Y.; Han, X.; Zhang, L. Multi-class geospatial object detection based on a position-sensitive balancing framework for high spatial resolution remote sensing imagery. ISPRS J. Photogramm. Remote Sens. 2018, 138, 281–294. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Ship Detection in Spaceborne Optical Image With SVD Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection in Remote Sensing Images from Google Earth of Complex Scenes Based on Multiscale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef]
- Miao, K.; Ji, K.; Leng, X.; Lin, Z. Contextual Region-Based Convolutional Neural Network with Multilayer Fusion for SAR Ship Detection. Remote Sens. 2017, 9, 860. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Object Detection in VHR Optical Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Cai, B.; Jiang, Z.; Zhang, H.; Zhao, D.; Yao, Y. Airport Detection Using End-to-End Convolutional Neural Network with Hard Example Mining. Remote Sens. 2017, 9, 1198. [Google Scholar] [CrossRef]
- Xu, Y.; Zhu, M.; Li, S.; Feng, H.; Ma, S.; Che, J. End-to-End Airport Detection in Remote Sensing Images Combining Cascade Region Proposal Networks and Multi-Threshold Detection Networks. Remote Sens. 2018, 10, 1516. [Google Scholar] [CrossRef]
- Guo, W.; Yang, W.; Zhang, H.; Hua, G. Geospatial Object Detection in High Resolution Satellite Images Based on Multi-Scale Convolutional Neural Network. Remote Sens. 2018, 10, 131. [Google Scholar] [CrossRef]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale object detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Deformable Faster R-CNN with Aggregating Multi-Layer Features for Partially Occluded Object Detection in Optical Remote Sensing Images. Remote Sens. 2018, 10, 1470. [Google Scholar] [CrossRef]
- Li, Z.; Zhou, F. FSSD: Feature Fusion Single Shot Multibox Detector. arXiv, 2017; arXiv:1712.00960. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS—Improving Object Detection with One Line of Code. arXiv, 2017; arXiv:1704.04503. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv, 2015; arXiv:1502.03167v3. [Google Scholar]
Sample Availability: Computer code of the proposed method and the constructed RSD-GOD dataset is available at: https://github.com/ZhuangShuoH/geospatial-object-detection. |











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Category | Number of Instances | ||
|---|---|---|---|
| Training Set | Validation Set | Testing Set | |
| airport | 1151 | 525 | 1721 |
| helicopter | 2460 | 1763 | 2208 |
| oiltank | 2969 | 2093 | 5113 |
| plane | 3216 | 3034 | 7884 |
| warship | 2123 | 865 | 3865 |
| total | 11,919 | 8280 | 20,791 |
| Method | Faster R-CNN | SSD | YOLO2 | Proposed | Proposed (Soft NMS) |
|---|---|---|---|---|---|
| Pretrained backbone | ResNet50 | VGG16 | Darknet-19 | Darknet-53 | Darknet-53 |
| Airport | 0.911 | 0.788 | 0.598 | 0.839 | 0.847 |
| Helicopter | 0.876 | 0.893 | 0.917 | 0.946 | 0.946 |
| Plane | 0.673 | 0.819 | 0.813 | 0.897 | 0.904 |
| Oiltank | 0.645 | 0.898 | 0.909 | 0.920 | 0.922 |
| Warship | 0.759 | 0.755 | 0.695 | 0.793 | 0.826 |
| Mean AP | 0.773 | 0.831 | 0.786 | 0.879 | 0.890 |
| Category | Number of Instances | AP Values | ||||
|---|---|---|---|---|---|---|
| Airport | 0 | 20 | 1701 | - | 0.400 | 0.895 |
| Helicopter | 121 | 819 | 1268 | 0.810 | 0.934 | 0.979 |
| Plane | 1461 | 2885 | 3538 | 0.849 | 0.959 | 0.957 |
| Oiltank | 669 | 1631 | 2813 | 0.683 | 0.946 | 0.989 |
| Warship | 21 | 429 | 3415 | - | 0.676 | 0.906 |
| Category | Number of Instances | AP Values | ||||
|---|---|---|---|---|---|---|
| Airport | 378 | 738 | 605 | 0.828 | 0.949 | 0.856 |
| Helicopter | 66 | 1835 | 307 | 0.758 | 0.967 | 0.915 |
| Plane | 299 | 6760 | 825 | 0.873 | 0.947 | 0.887 |
| Oiltank | 11 | 4811 | 291 | 0.818 | 0.942 | 0.838 |
| Warship | 1565 | 739 | 1561 | 0.919 | 0.847 | 0.845 |
| Method | COPD | R-P-Faster R-CNN | RICNN | SSD | Faster R-CNN | YOLO2 | Proposed | Proposed (Soft-NMS) |
|---|---|---|---|---|---|---|---|---|
| Airplane | 0.623 | 0.904 | 0.884 | 0.957 | 0.946 | 0.733 | 0.929 | 0.934 |
| Ship | 0.689 | 0.750 | 0.773 | 0.829 | 0.823 | 0.749 | 0.765 | 0.771 |
| Storage tank | 0.637 | 0.444 | 0.853 | 0.856 | 0.653 | 0.344 | 0.849 | 0.875 |
| Baseball diamond | 0.833 | 0.899 | 0.881 | 0.966 | 0.955 | 0.889 | 0.930 | 0.930 |
| Tennis court | 0.321 | 0.797 | 0.408 | 0.821 | 0.819 | 0.291 | 0.824 | 0.827 |
| Basketball court | 0.363 | 0.776 | 0.585 | 0.860 | 0.897 | 0.276 | 0.815 | 0.838 |
| Ground track field | 0.853 | 0.877 | 0.867 | 0.582 | 0.924 | 0.988 | 0.837 | 0.837 |
| Harbor | 0.553 | 0.791 | 0.686 | 0.548 | 0.724 | 0.754 | 0.816 | 0.825 |
| Bridge | 0.148 | 0.682 | 0.615 | 0.419 | 0.575 | 0.518 | 0.702 | 0.725 |
| Vehicle | 0.440 | 0.732 | 0.711 | 0.756 | 0.778 | 0.513 | 0.819 | 0.823 |
| Mean AP | 0.546 | 0.765 | 0.726 | 0.759 | 0.809 | 0.605 | 0.829 | 0.838 |
| Methods | COPD | R-P-Faster R-CNN | RICNN | SSD | Faster R-CNN | YOLO2 | Proposed |
|---|---|---|---|---|---|---|---|
| Backbone | - | VGG16 | - | VGG16 | ResNet50 | Darknet-19 | Darknet-53 |
| Average running time (s) | 1.070 | 0.150 | 8.770 | 0.027 | 0.430 | 0.026 | 0.057 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhuang, S.; Wang, P.; Jiang, B.; Wang, G.; Wang, C. A Single Shot Framework with Multi-Scale Feature Fusion for Geospatial Object Detection. Remote Sens. 2019, 11, 594. https://doi.org/10.3390/rs11050594
Zhuang S, Wang P, Jiang B, Wang G, Wang C. A Single Shot Framework with Multi-Scale Feature Fusion for Geospatial Object Detection. Remote Sensing. 2019; 11(5):594. https://doi.org/10.3390/rs11050594
Chicago/Turabian StyleZhuang, Shuo, Ping Wang, Boran Jiang, Gang Wang, and Cong Wang. 2019. "A Single Shot Framework with Multi-Scale Feature Fusion for Geospatial Object Detection" Remote Sensing 11, no. 5: 594. https://doi.org/10.3390/rs11050594
APA StyleZhuang, S., Wang, P., Jiang, B., Wang, G., & Wang, C. (2019). A Single Shot Framework with Multi-Scale Feature Fusion for Geospatial Object Detection. Remote Sensing, 11(5), 594. https://doi.org/10.3390/rs11050594