1. Introduction
Object detection on very-high-resolution (VHR) optical remote sensing imagery has attracted more and more attention. It not only needs to identify the category of the object, but also needs to give the precise location of the object [
1]. The improvements of earth observation technology and diversity of remote sensing platforms have seen a sharp increase in the amount of remote sensing images, which promotes the research of object detection. However, the problems of the complex backgrounds, the overlarge images, the uneven size and quantity distribution of training samples, illumination and shadows make the detection tasks more challenging and meaningful [
2,
3,
4].
The optical remote sensing image object detection has made great progress in recent years [
5]. The existing detection methods can be divided into four main categories, namely, template matching-based methods, knowledge-based methods, object image analysis-based (OBIA-based) methods and machine learning-based methods [
2]. The template matching-based methods [
6,
7,
8] mainly contain rigid template matching and deformable template matching, which includes two steps, specifically, template generation and similarity measure. Geometric information and context information are the two most common knowledge for knowledge-based object detection algorithm [
9,
10,
11]. The key of the algorithm is effectively transforming the implicit connotative information into established rules. OBIA-based image analysis [
12] principally contains image segmentation and object classification. Notably, the appropriate segmentation parameters are the key factors, which will affect the effectiveness of the object detection. In order to more comprehensively and effectively characterize the object, machine learning-based methods [
13,
14] are applied. They first extract the features (e.g., histogram of oriented gradients (HOG) [
15], bag of words (BoW) [
16], Sparse representation (SR)-based features [
17], etc.) of the object, then perform feature fusion and dimension reduction to concisely extract features. Finally, those features are fed into a classifier (e.g., Support vector machine (SVM) [
18], AdaBoost [
19], Conditional random field (CRF) [
20], etc.) trained with a large amount of data for object detection. In conclusion, those methods rely on the hand-engineered features, however, they are difficult to efficiently process remote sensing images in the context of big data. In addition, the hand-engineered features can only detect specific targets, when applying them to other objects, the detection results are unsatisfactory [
1].
In recent years, the deep learning algorithms emerging in the field of artificial intelligence (AI) are a new kind of computing model, which can extract advanced features from massive data and perform efficient information classification, interpretation and understanding. It has been successfully applied to the fields of machine translation, speech recognition, reinforcement learning, image classification, object detection and other fields [
21,
22,
23,
24,
25]. Even in some applications, it has exceeded the human level [
26]. Compared with the traditional object detection and localization methods, the deep learning-based methods have stronger generalization and features expression ability [
2]. It learns effective representation of features by a large amount of data, and establishes relatively complex network structure, which fully exploits the association among data and builds powerful detectors and locators. Convolutional neural network (CNN) is a kind of deep learning model specially designed for two-dimensional structure images inspired by biological visual cognition (local receptive field) and it can learn the deep features of images layer by layer. The local receptive field of CNN can effectively capture the spatial relationship of the objects. The characteristics of weight sharing greatly reduces the training parameters of the network and the computational cost. Therefore, the CNN-based methods are being widely used when automatically interpreting images [
2,
27,
28,
29,
30].
In the field of object detection, with the development of the large public natural image datasets (e.g., Pascal VOC [
31], ImageNet [
32]), and the significantly improved graphics processing units (GPUs), the CNN-based detection frameworks have achieved outstanding achievements [
33]. The existing CNN-based detection methods can be roughly divided into two groups: the region-based methods and the region-free methods. The region-based methods first generate candidate regions and then accurately classify and locate the objects existing in these regions, and these methods have higher detection accuracy but slower speed. Conversely, the region-free methods directly regress the object coordinates and object categories in multiple positions of the image, and the whole detection process is one-stage. These region-free methods have faster detection speed but relatively poor accuracy [
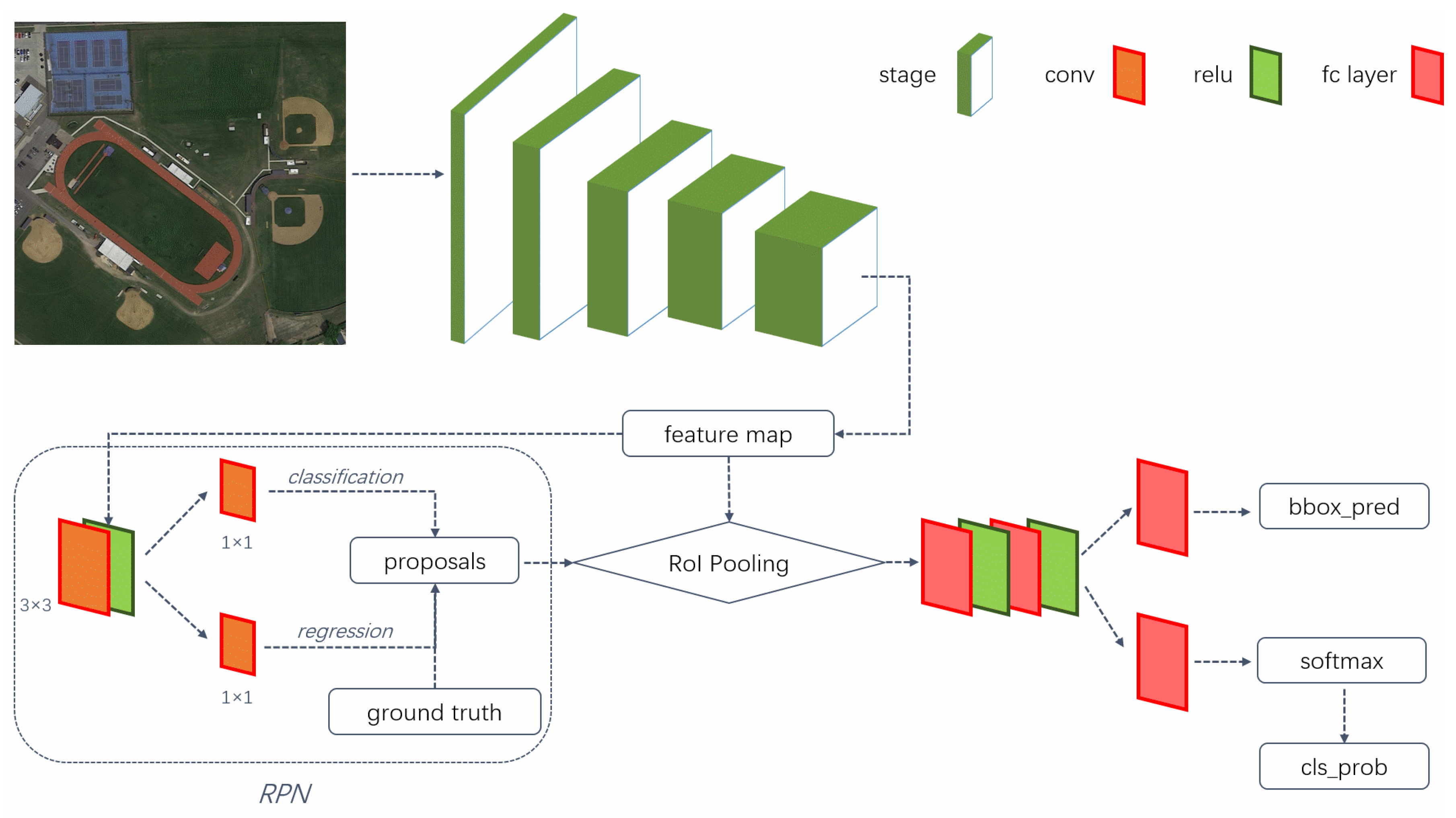
34]. Among numerous region-based methods, Region-based CNN (R-CNN) [
35] is a pioneering work. It utilizes the selective search algorithm [
36] to generate the region proposals, and then extracts features via CNN on these regions. The extracted features are fed into a trained SVM classifier, which classifies the category of the object. Finally, bounding box regression is used to correct the initial extracted coordinates and non-maximum uppression (NMS) is used to delete highly redundant bounding boxes to obtain accurate detection results. R-CNN [
35] demands to perform feature extraction at each region proposal, so the process is time-consuming [
37]. Besides, the forced image resizing process on the candidate regions before they are fed into the CNN also caused information loss. To solve the above problems, He et al. proposed Spatial Pyramid Pooling Network (SPP-Net) [
38], which adds a spatial pyramid layer, namely, Region-of-Interest (RoI) pooling layer, on the top of the last convolutional layer. The RoI pooling layer divides the features and generates fixed-length outputs, therefore it can deal with the arbitrary-size input images. SPP-Net [
38] performs one-time features extraction to obtain an entire-image feature map, and the region proposals share the entire-image feature map, which greatly speeds up the detection. On the basis of R-CNN, Fast-RCNN [
39] adopts the multi-task loss function to carry out classification and regression simultaneously, which improves the detection, positioning accuracy and greatly improves the detection efficiency. However, using the selective search algorithm to generate region proposals is still very time-consuming because the algorithm implements on the central processing unit (CPU). In order to take advantage of the GPUs, Faster R-CNN [
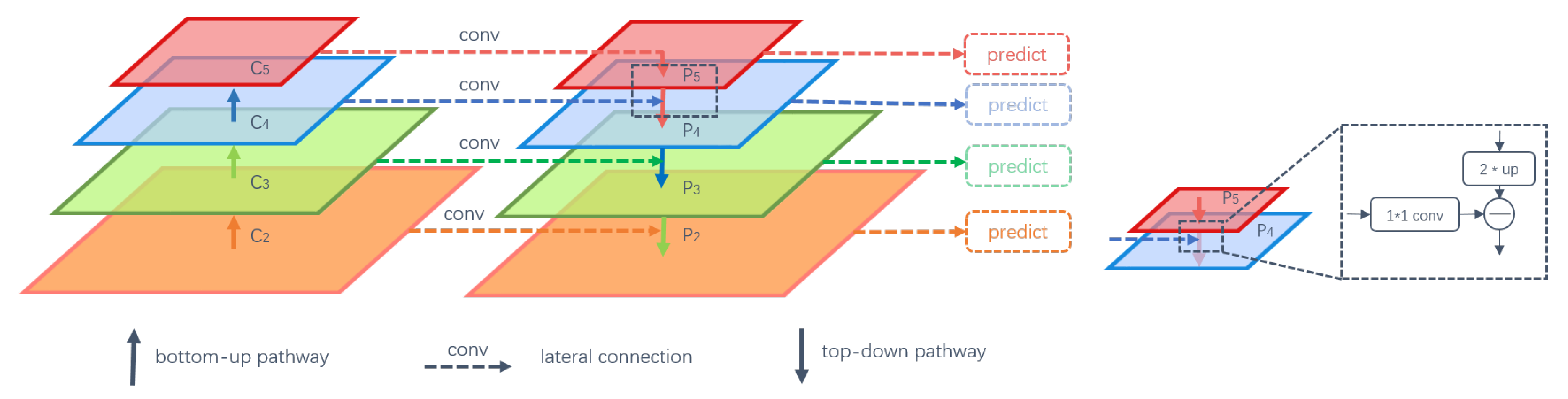
37], consisting of a region proposal network (RPN) and Fast R-CNN, was proposed. The two networks share convolution parameters, and they have been integrated into a unified network. Thus, the region-based object detection network achieves end-to-end operation. Feature pyramids play a crucial role in multi-scale object detection system, which combine resolution and semantic information over multiple scales. Feature pyramid network (FPN) [
40] was proposed to simultaneously utilize low-resolution, semantically strong features and high-resolution, semantically weak features, it is superior to single-scale features for a region-based object detector and shows significant improvements in detecting small objects. In addition to the region-based object detection frameworks, there are many region-free object detection networks, including Over-Feat [
41], you only look once (YOLO) [
42] and single shot multi-box detector (SSD) [
43], etc. These one-stage networks consider object detection as a regression problem, they do not generate region proposals and predict the class confidence and coordinates directly. They greatly improve the detection speed, although sacrificing some precision.
The CNN-based natural imagery object detection has made great progress, but high-precision and high-efficiency object detection for remote sensing images still has a long way to go. Different from natural images, remote sensing images usually show the following characteristics:
The perspective of view. Remote sensing images are usually obtained from a top-down view while natural images can be obtained from different perspectives, which greatly affects how objects are rendered on the images [
1].
Overlarge image size. Remote sensing images are usually larger in size and range than natural images. Compared with natural image processing, remote sensing image processing is more time-consuming and memory-consuming.
Class imbalances. The imbalances mainly include category quantity and object size. Objects in natural scene images are generally uniformly distributed and not particularly numerous, but a single remote sensing image may contain one object or hundreds of objects and it may also simultaneously include large objects such as playgrounds and small objects like cars.
Additional influence factors. Compared with natural scene image, remote sensing image object detections are affected by illumination condition, image resolution, occlusion, shadow, background and border sharpness [
33].
Therefore, constructing a robust and accurate object detection framework for remote sensing images is very challenging, but it is also of much significance. To overcome the size restrictions of the input images, the problem of small objects loss and retain the resolution of the objects, Chen et al. [
1] put forward MultiBlock layer and MapBlock layer based on SSD [
43]. The MultiBlock layer divides the input image into multiple blocks, the MapBlock layer maps the prediction results of each block to the original image. The network achieves a good effect on airplane detection. Considering the complex distribution of geospatial objects and the low efficiency for remote sensing imagery, Han et al. [
33] proposed the P-R-Faster R-CNN, which achieves multi-class geospatial object detection by combining the robust properties of transfer mechanism and the sharable properties of Faster R-CNN. Guo et al. [
3] proposed a unified multi-scale CNN for multi-scale geospatial object detection, which consists of a multi-scale object proposal network and a multi-scale object detection network. The network achieves the best precision on the Northwestern Polytechnical University very high spatial resolution-10 (NWPU VHR-10) [
44] dataset. However, for small and dense objects detection on remote sensing images, they did not propose an effective solution, and did not make full use of the resolution and semantic information simultaneously, which may lead to unsatisfactory results in the case of more complex backgrounds, numerous data and overlarge image size [
4,
40]. Some frameworks [
1,
45,
46,
47] only have effects for certain types of objects. Besides, RoI pooling layer in these networks will cause misalignments between the inputs and their corresponding final feature maps, these misalignments affect the object detection accuracy, especially for small objects.
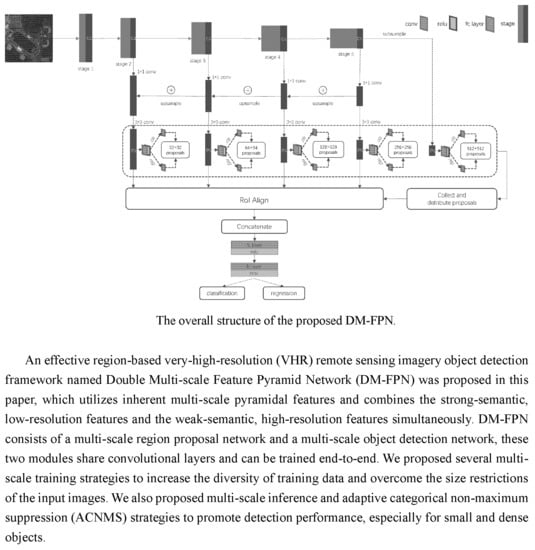
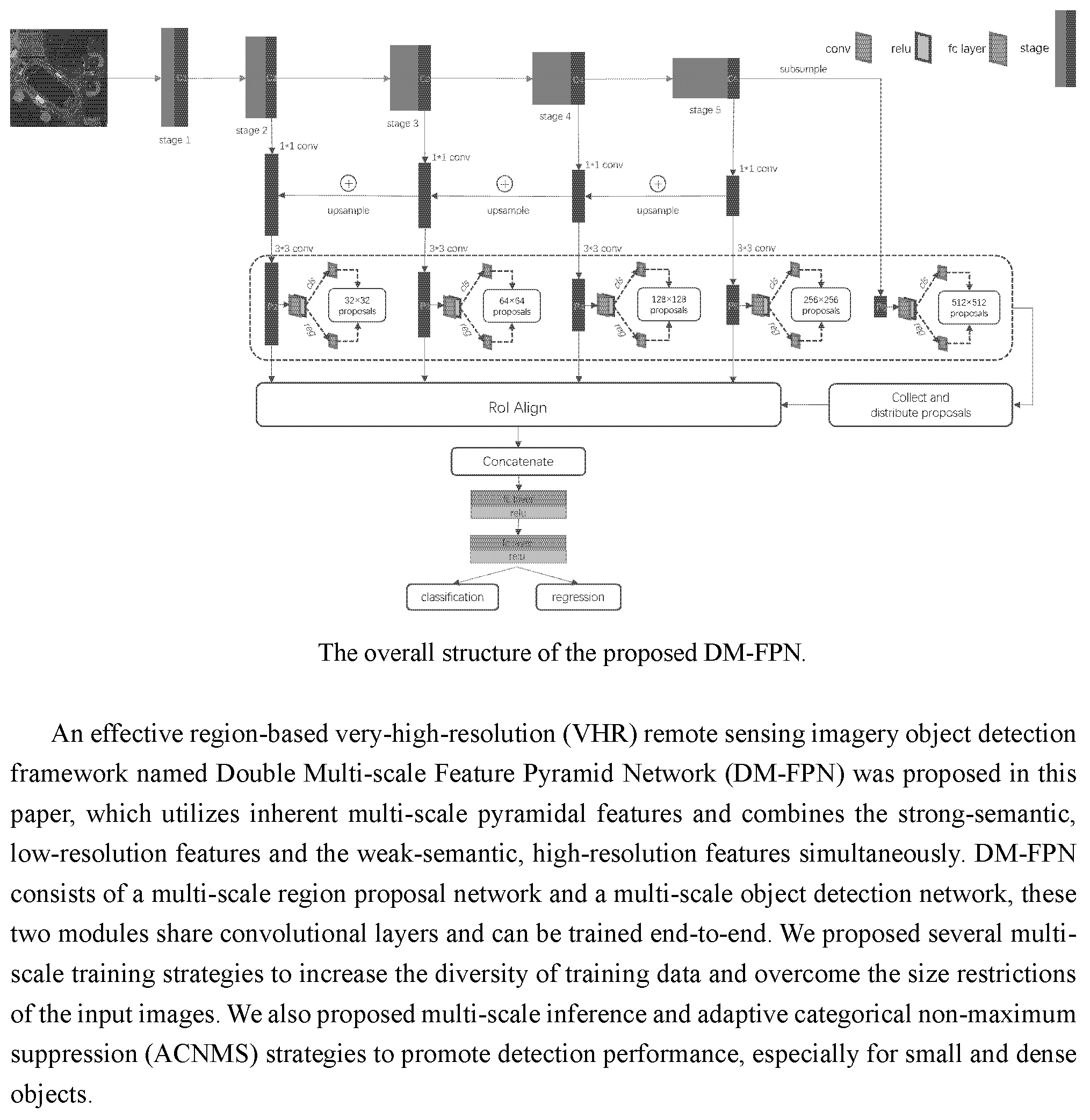
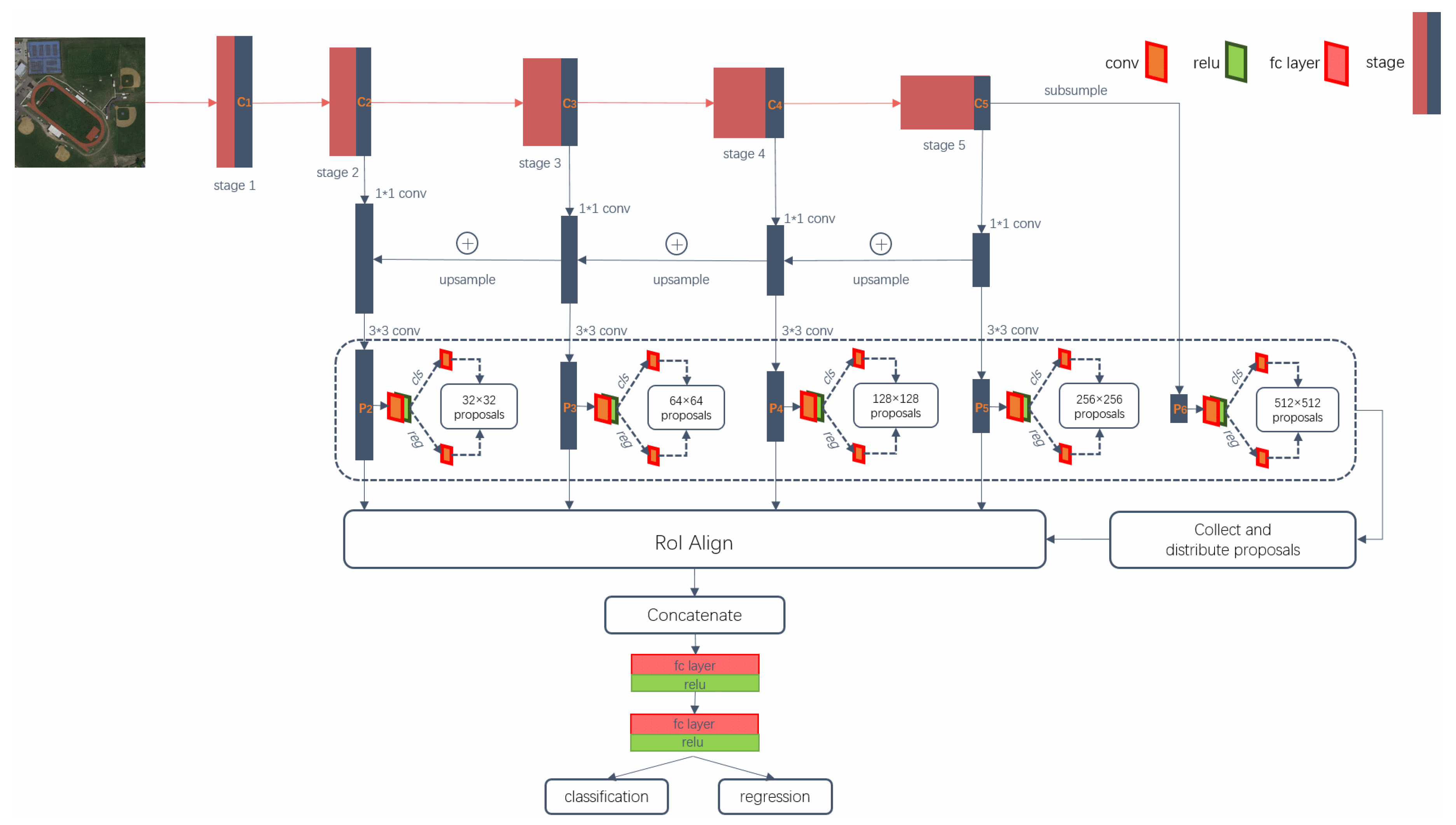
To solve the above problems, we presented an effective framework, namely, Double Multi-scale Feature Pyramid Network (DM-FPN), which makes full use of semantic and resolution features simultaneously. We also put forward some multi-scale training, inference and adaptive categorical non-maximum suppression (ACNMS) strategies. The main contributions of this paper are summarized as follows:
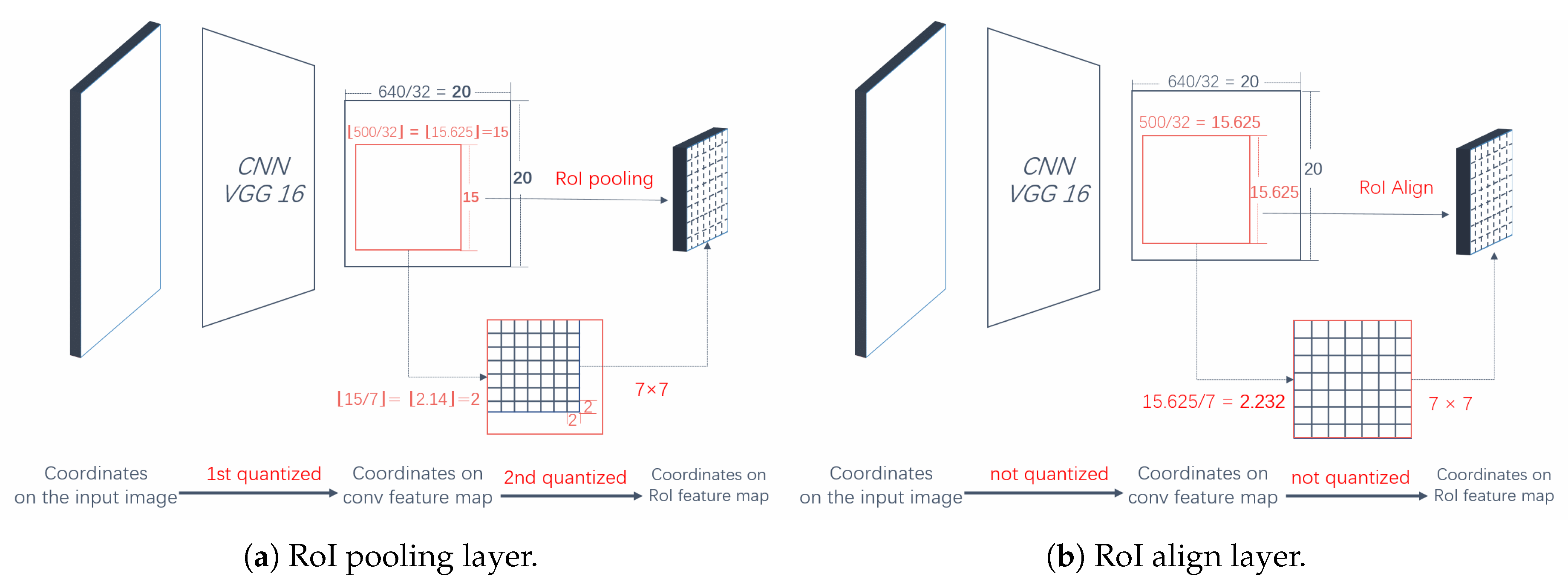
We have constructed an effective multi-scale geospatial object detection framework, which achieves good performance by simultaneously utilizing low-resolution, semantically strong features and high-resolution, semantically weak features. Accordingly, the RoI Align layer used in our framework can solve the misalignment caused by RoI pooling layer and it improves the object detection accuracy, especially for small objects.
We proposed several multi-scale training strategies, including the patch-based multi-scale training data and the multi-scale image sizes used during training. To overcome the size restrictions of the input images, we divided the image into blocks with a certain degree of overlap. The patch-based multi-scale training data strategy both enhance the resolution features of the small objects and integrally divide the large objects into a single patch for training. In order to increase the diversity of objects, we adopt multiple image sizes strategy for patches during training.
During the inference stage, we also proposed a multi-scale strategy to detect as many objects as possible. Besides, depending on the intensity of the object, we adopt the noval ACNMS strategy, which can effectively reduce redundancy among the highly overlapped objects and slightly overcome the uneven quantity distribution of training samples, enabling the framework preferably to detect both small and dense objects.
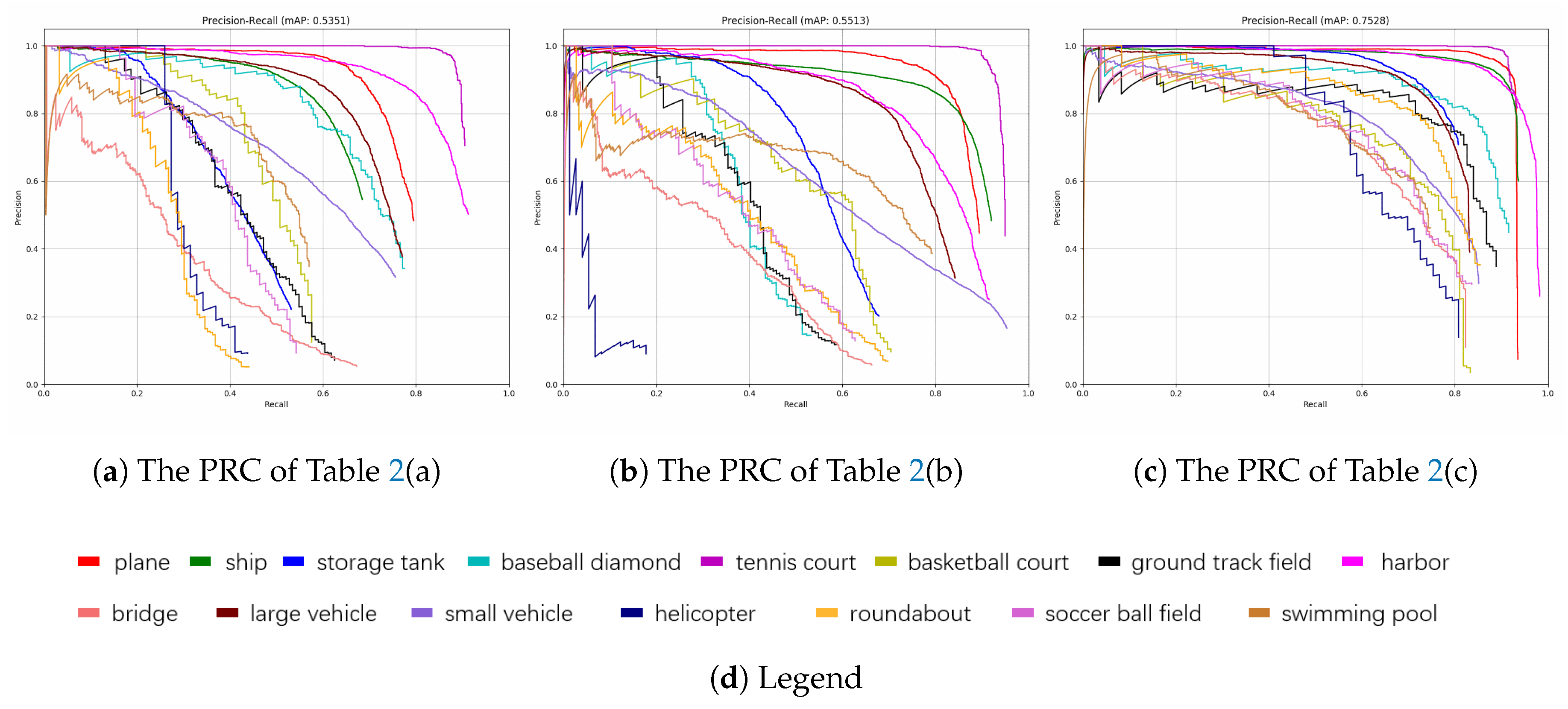
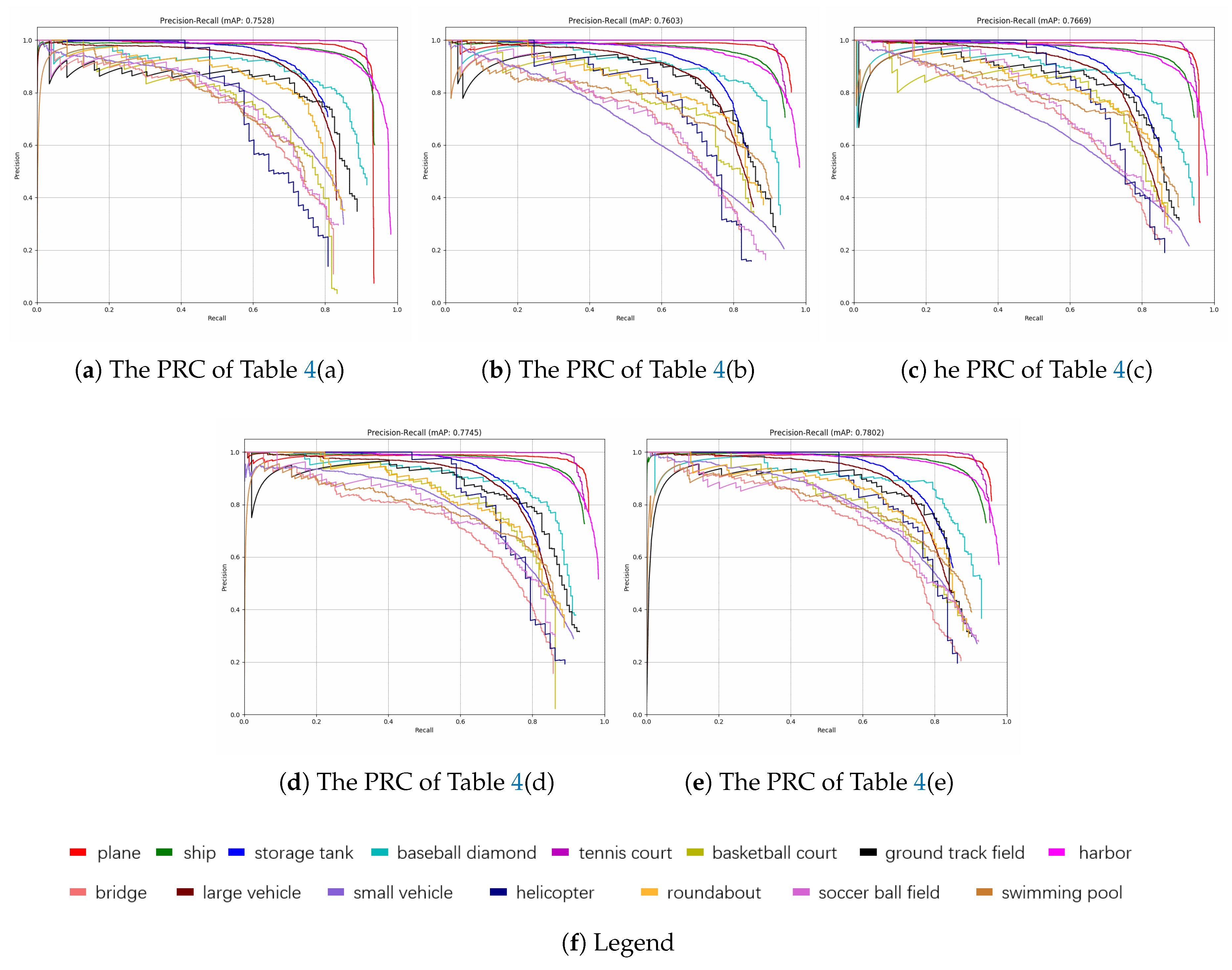
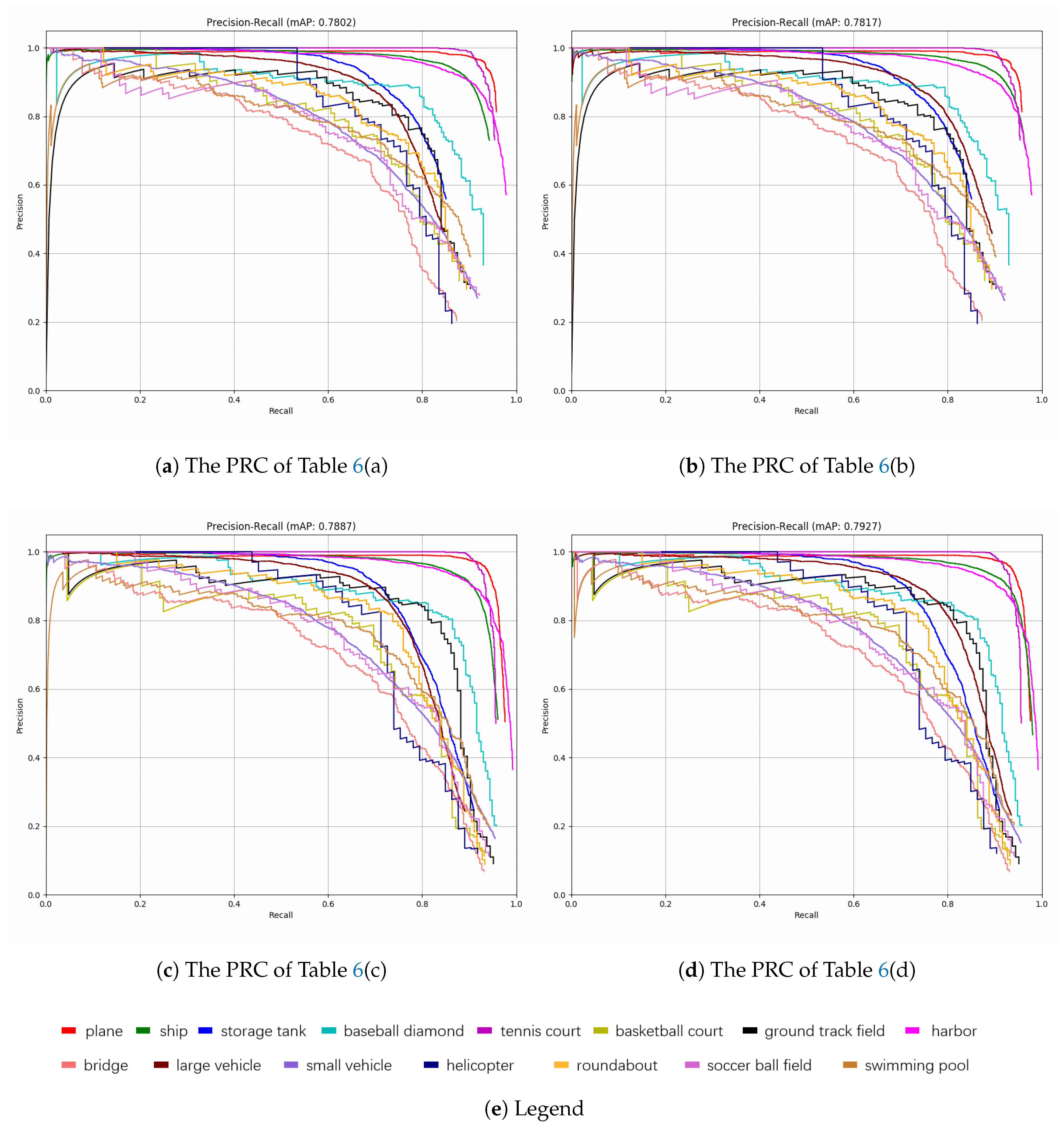
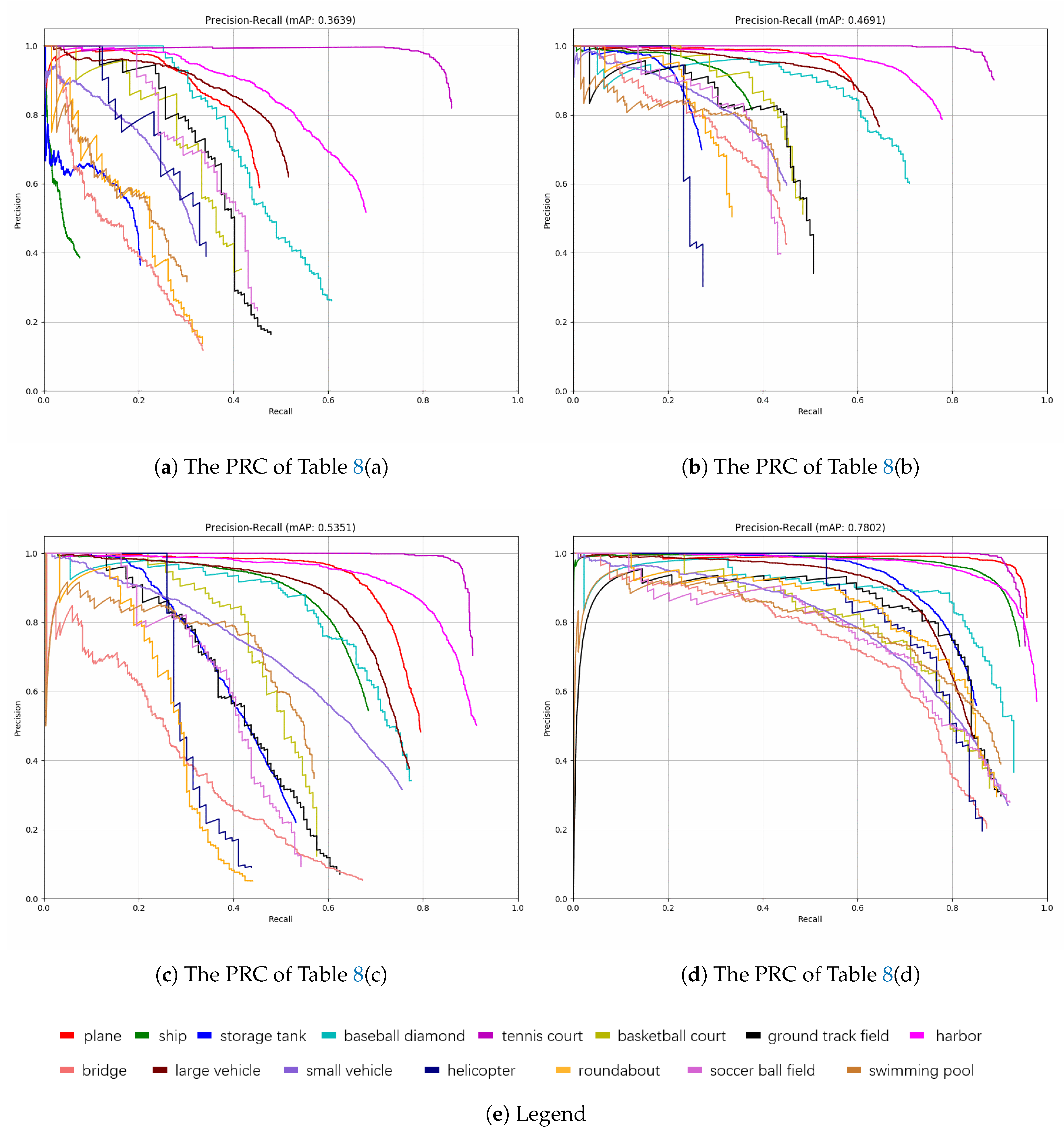
Experiment results evaluated on DOTA [
48] dataset, a large-scale dataset for object detection in aerial images, indicating the effectiveness and superiority of the proposed framework. The rest of this paper is organized as follows.
Section 2 introduces the related work involved in the paper.
Section 3 elaborates the proposed framework in detail.
Section 4 mainly includes the description of the datasets, evaluation criteria and experiment details.
Section 5 implements ablation experiments and makes reliable analyses to the results.
Section 6 discusses the proposed framework and analyzes its limitations. Finally, the conclusions are drawn in
Section 7.


 ,
, 













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}