Deep Learning Segmentation and Classification for Urban Village Using a Worldview Satellite Image Based on U-Net



Abstract
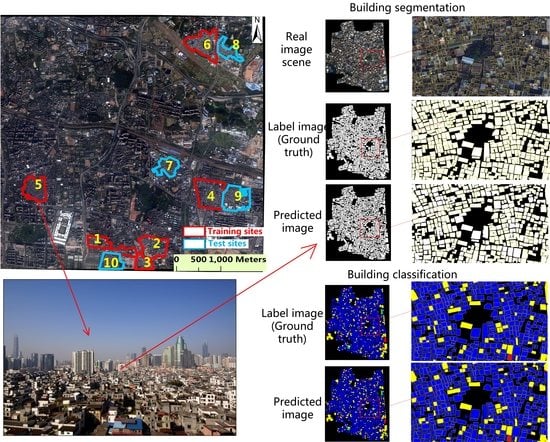
:
1. Introduction
2. Study Area and Data
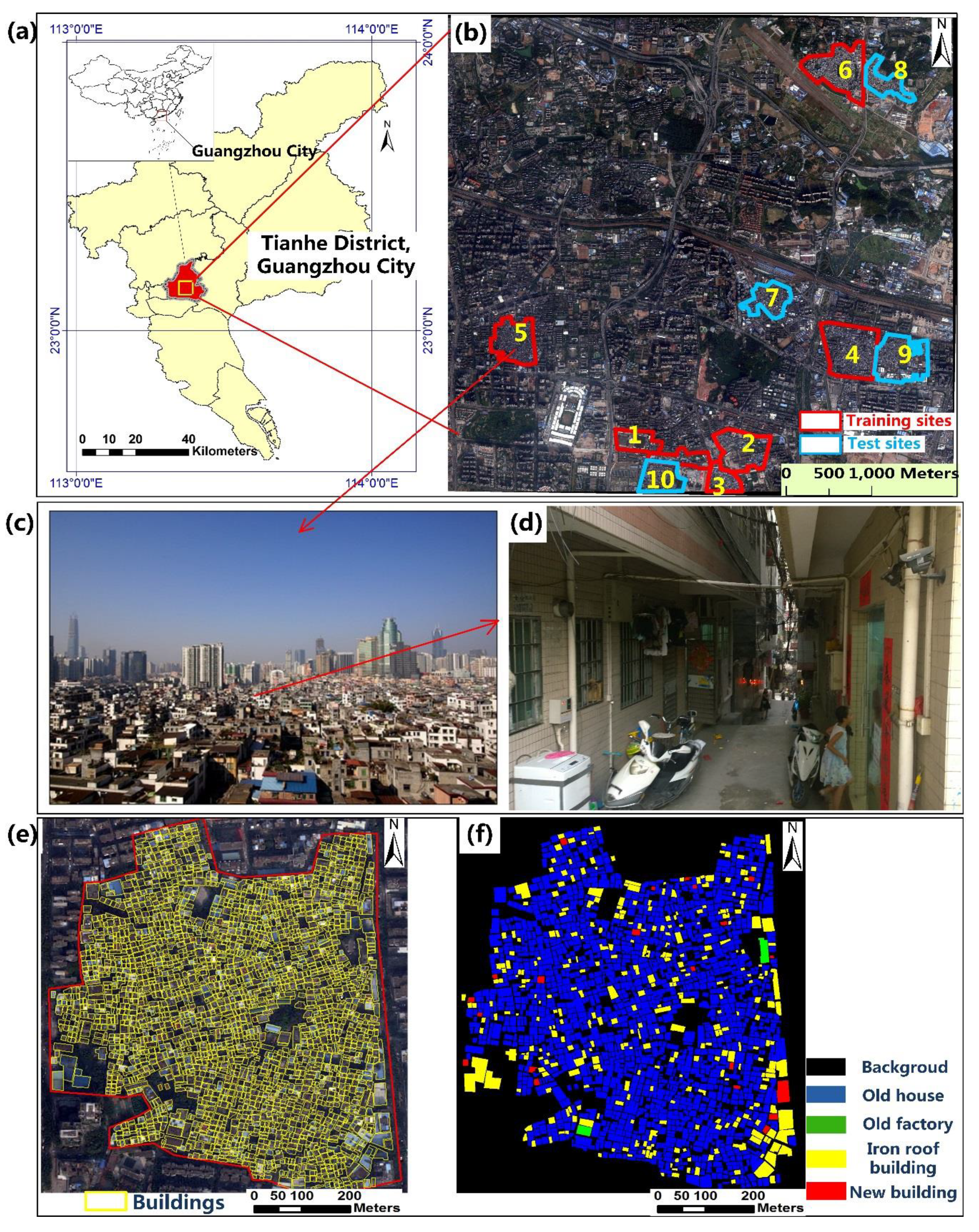
2.1. Study Area
2.2. Datasets
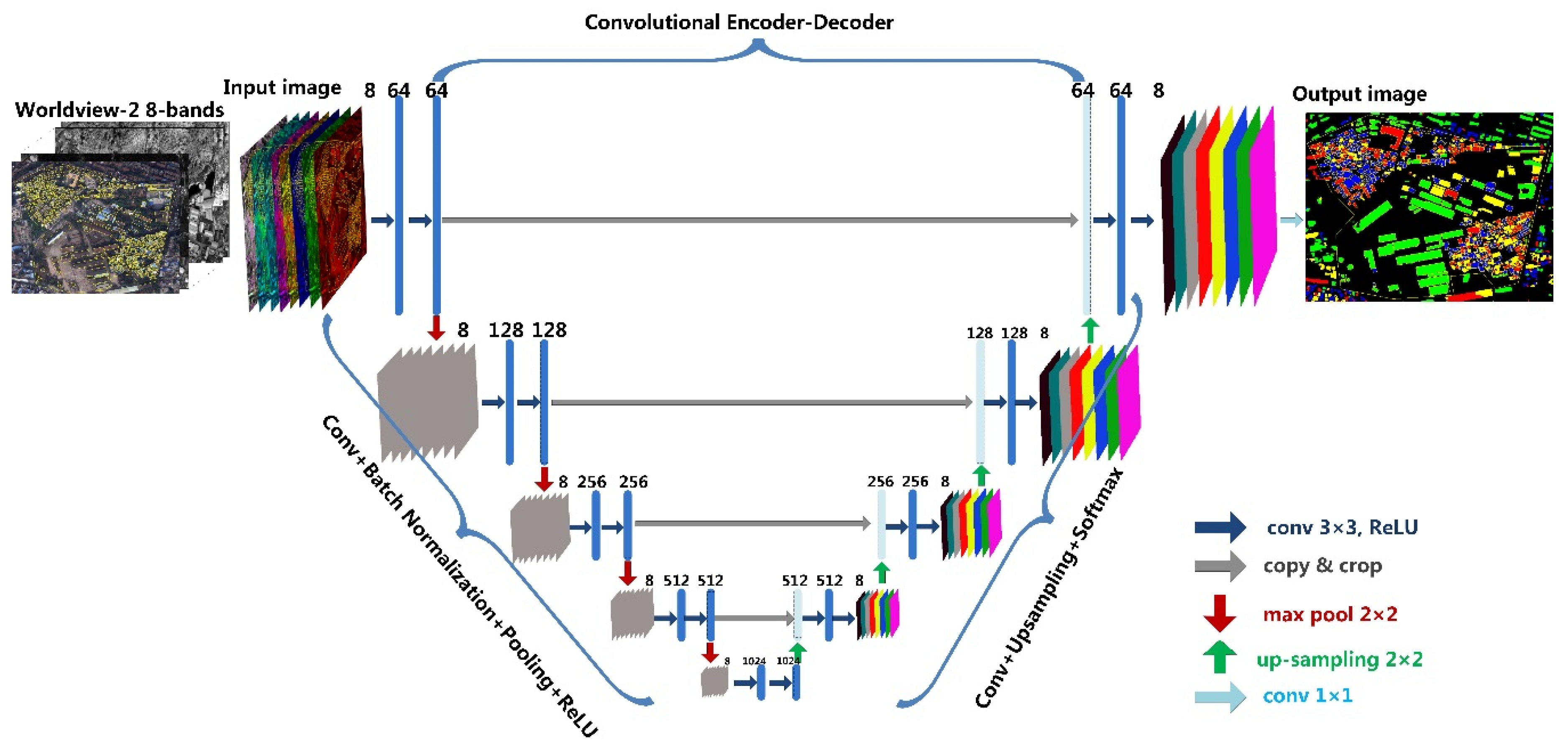
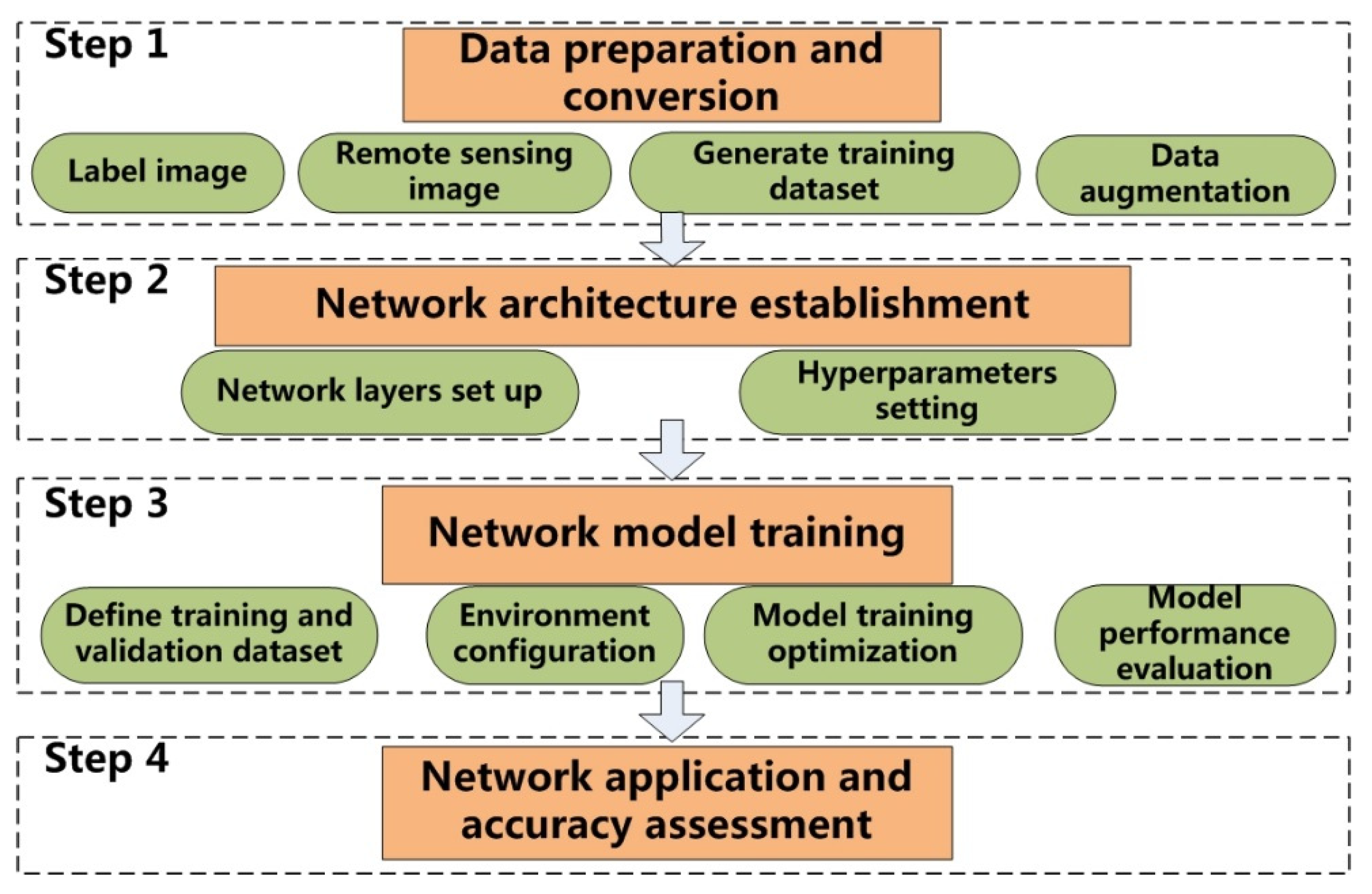
3. Deep Learning Segmentation Using U-Net
3.1. Network Architecture
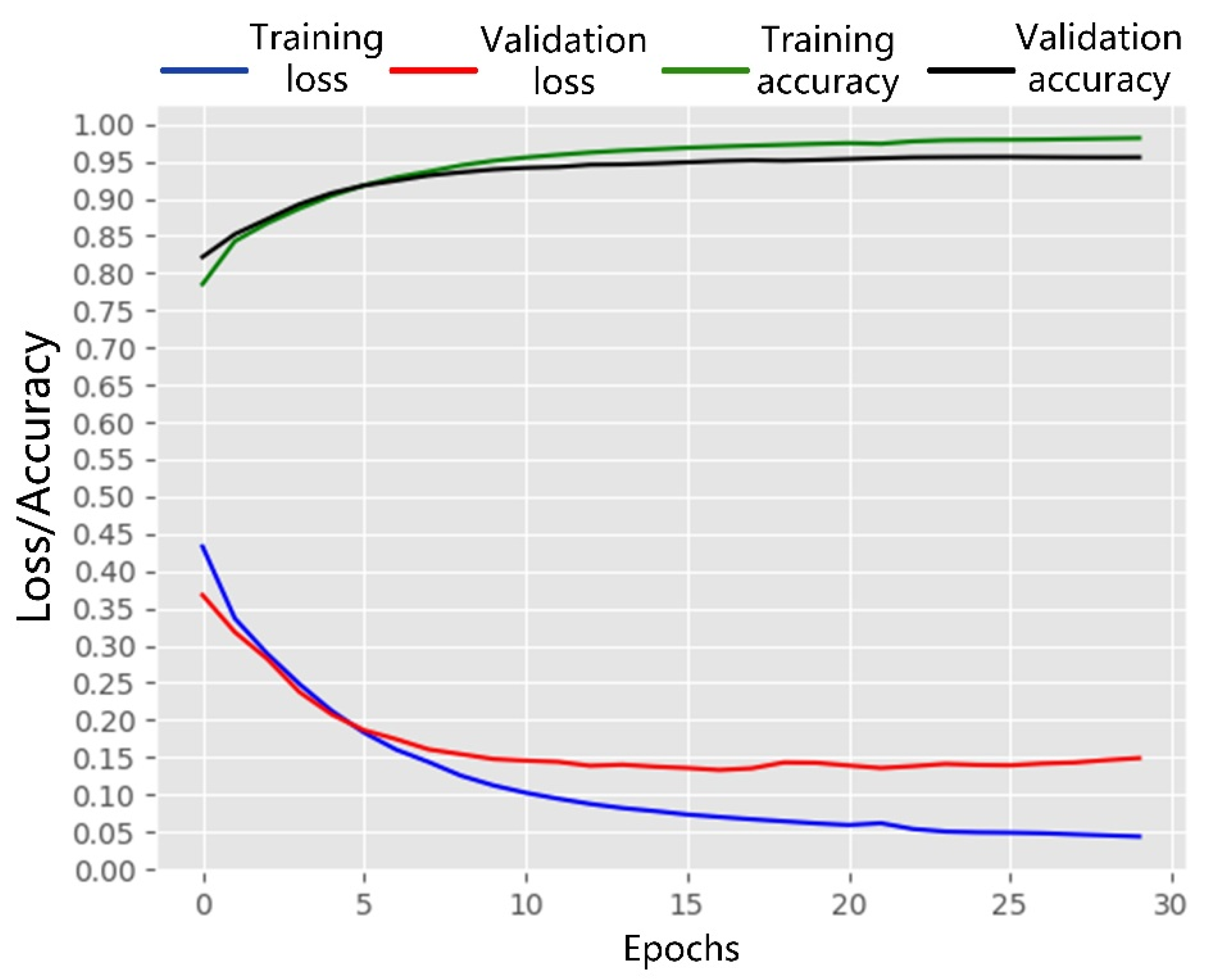
3.2. Network Model Training
3.3. Experiment Environment and Programming
3.4. Accuracy Assessment
4. Results
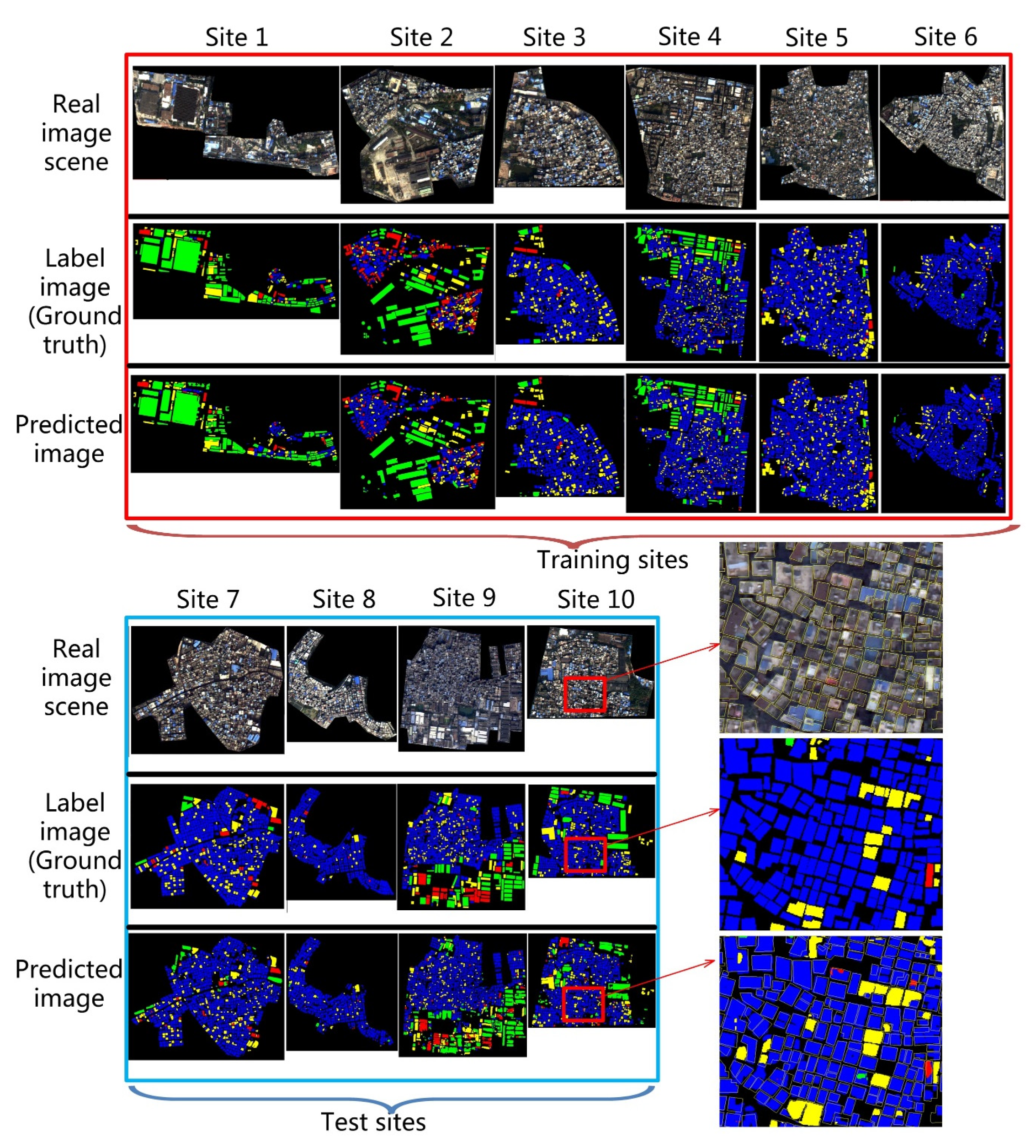
4.1. Performance of Building Segmentation
4.2. Performance of Building Classification
4.3. Comparison with Random Forest and Object-Based Image Analysis
5. Discussion
5.1. Result Interpretation
5.2. Relevant Studies and Limitations
5.3. Model Improvement
5.4. Lesson Learned
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wurm, M.; Stark, T.; Zhu, X.; Weigand, M.; Taubenböck, H. Semantic segmentation of slums in satellite images using transfer learning on fully convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2019, 150, 59–69. [Google Scholar] [CrossRef]
- Mahabir, R.; Croitoru, A.; Crooks, A.T.; Agouris, P.; Stefanidis, A. A critical review of high and very high-resolution remote sensing approaches for detecting and mapping slums: Trends, challenges and emerging opportunities. Urban Sci. 2018, 2, 8. [Google Scholar] [CrossRef] [Green Version]
- Kuffer, M.; Persello, C.; Pfeffer, K.; Sliuzas, R.; Rao, V. Do we underestimate the global slum population? In Proceedings of the Joint Urban Remote Sensing Event 2019, Vannes, France, 22–24 May 2019; pp. 1–4. [Google Scholar]
- Kuffer, M.; Pfeffer, K.; Sliuzas, R. Slums from space—15 years of slum mapping using remote sensing. Remote Sens. 2016, 8, 455. [Google Scholar] [CrossRef] [Green Version]
- United Nations. Habitat iii issue papers 22—Informal settlements. In United Nations Conference on Housing and Sustainable Urban Development; United Nations: New York, NY, USA, 2015. [Google Scholar]
- Mahabir, R.; Crooks, A.; Croitoru, A.; Agouris, P. The study of slums as social and physical constructs: Challenges and emerging research opportunities. Reg. Stud. Reg. Sci. 2016, 3, 399–419. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Huang, X.; Liu, H. Unsupervised deep feature learning for urban village detection from high resolution remote sensing images. Photogramm. Eng. Remote Sens. 2017, 83, 567–579. [Google Scholar] [CrossRef]
- Buchanan, T. Photogrammetry and Projective Geometry: An Historical Survey; SPIE: San Francisco, CA, USA, 1993; Volume 1944. [Google Scholar]
- Bachofer, F.; Braun, A.; Adamietz, F.; Murray, S.; Angelo, P.d.; Kyazze, E.; Mumuhire, A.P.; Bower, J. Building stock and building typology of kigali, rwanda. Data 2019, 4, 105. [Google Scholar] [CrossRef] [Green Version]
- Patino, J.E.; Duque, J.C. A review of regional science applications of satellite remote sensing in urban settings. Comput. Environ. Urban Syst. 2013, 37, 1–17. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef] [Green Version]
- Liu, J.; Li, P.; Wang, X. A new segmentation method for very high resolution imagery using spectral and morphological information. ISPRS J. Photogramm. Remote Sens. 2015, 101, 145–162. [Google Scholar] [CrossRef]
- Jin, X. Segmentation-Based Image Processing System. U.S. Patent 20,090,123,070, 14 May 2009. [Google Scholar]
- Emmanuel, M.; Yuliya, T.; Guillaume, C.; Pierre, A. Convolutional neural networks for large-scale remote sensing image classifcation. IEEE Trans. Geosci. Remote Sens. 2017, 55, 645–675. [Google Scholar]
- Rodriguez-Galiano, V.F.; Chica-Olmo, M.; Abarca-Hernandez, F.; Atkinson, P.M.; Jeganathan, C. Random forest classification of mediterranean land cover using multi-seasonal imagery and multi-seasonal texture. Remote Sens. Environ. 2012, 121, 93–107. [Google Scholar] [CrossRef]
- Duque, J.C.; Patino, J.E.; Betancourt, A. Exploring the potential of machine learning for automatic slum identification from vhr imagery. Remote Sens. 2017, 9, 895. [Google Scholar] [CrossRef] [Green Version]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Chen, R.; Li, X.; Li, J. Object-based features for house detection from rgb high-resolution images. Remote Sens. 2018, 10, 451. [Google Scholar] [CrossRef] [Green Version]
- Li, W.; He, C.; Fang, J.; Zheng, J.; Fu, H.; Yu, L. Semantic segmentation-based building footprint extraction using very high-resolution satellite images and multi-source gis data. Remote Sens. 2019, 11, 403. [Google Scholar] [CrossRef] [Green Version]
- Yi, Y.; Zhang, Z.; Zhang, W.; Zhang, C.; Li, W.; Zhao, T. Semantic segmentation of urban buildings from vhr remote sensing imagery using a deep convolutional neural network. Remote Sens. 2019, 11, 1174. [Google Scholar] [CrossRef] [Green Version]
- Carleer, A.P.; Debeir, O.; Wolf, E. Assessment of very high spatial resolution satellite image segmentations. Photogramm. Eng. Remote Sens. 2004, 71, 1285–1294. [Google Scholar] [CrossRef] [Green Version]
- Hui, E.C.M.; Dong, Z.; Jia, S.H.; Lam, C.H.L. How does sentiment affect returns of urban housing? Habitat Int. 2017, 64, 71–84. [Google Scholar] [CrossRef]
- Loures, L.; Vaz, E. Exploring expert perception towards brownfield redevelopment benefits according to their typology. Habitat Int. 2018, 72, 66–76. [Google Scholar] [CrossRef]
- Ball, J.E.; Anderson, D.T.; Chan, C.S. Comprehensive survey of deep learning in remote sensing: Theories, tools, and challenges for the community. J. Appl. Remote Sens. 2017, 11, 042609. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 6, 22–40. [Google Scholar] [CrossRef]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Garcia-Rodriguez, J. A review on deep learning techniques applied to semantic segmentation. arXiv 2017, arXiv:1704.06857. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Yang, H.L.; Yuan, J.; Lunga, D.; Laverdiere, M.; Rose, A.; Bhaduri, B. Building extraction at scale using convolutional neural network. J. Latex Cl. Files 2015, 14, 1–15. [Google Scholar]
- Bai, Y.; Mas, E.; Koshimura, S. Towards operational satellite-based damage-mapping using u-net convolutional network: A case study of 2011 tohoku earthquake-tsunami. Remote Sens. 2018, 10, 1626. [Google Scholar] [CrossRef] [Green Version]
- Wagner, F.H.; Sanchez, A.; Tarabalka, Y.; Lotte, R.G.; Ferreira, M.P.; Aidar, M.P.M.; Gloor, E.; Phillips, O.L.; Aragão, L.E.O.C. Using the u-net convolutional network to map forest types and disturbance in the atlantic rainforest with very high resolution images. Remote Sens. Ecol. Conserv. 2019. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.; Osindero, S.; Teh, Y. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention 2015, Munich, Germany, 5–9 October 2015; Volume 9351. [Google Scholar]
- Peng, D.; Zhang, Y.; Guan, H. End-to-end change detection for high resolution satellite images using improved unet++. Remote Sens. 2019, 11, 1382. [Google Scholar] [CrossRef] [Green Version]
- Xiong, Y.; Huang, S.; Chen, F.; Ye, H.; Wang, C.; Zhu, C. The impacts of rapid urbanization on the thermal environment: A remote sensing study of Guangzhou, south china. Remote Sens. 2012, 4, 2033–2056. [Google Scholar] [CrossRef] [Green Version]
- Li, L.H.; Lin, J.; Li, X.; Wu, F. Redevelopment of urban village in china – a step towards an effective urban policy? A case study of liede village in Guangzhou. Habitat Int. 2014, 43, 299–308. [Google Scholar] [CrossRef]
- Pan, Z.; Wang, G.; Hu, Y.; Cao, B. Characterizing urban redevelopment process by quantifying thermal dynamic and landscape analysis. Habitat Int. 2019, 86, 61–70. [Google Scholar] [CrossRef]
- Pan, Z.; Hu, Y.; Wang, G. Detection of short-term urban land use changes by combining sar time series images and spectral angle mapping. Front. Earth Sci. 2019, 13, 495–509. [Google Scholar] [CrossRef]
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective, 4th ed.; Pearson Prentice Hall: Upper Saddle River, NJ, USA, 2016; pp. 234–235. [Google Scholar]
- Sun, W.; Chen, B.; Messinger, D. Nearest neighbor diffusion based pan sharpening algorithm for spectral images. Opt. Eng. 2014, 53, 013107. [Google Scholar] [CrossRef] [Green Version]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Springenberg, J.T.; Dosovitskiy, A.; Brox, T.; Riedmiller, M. Striving for simplicity: The all convolutional net. arXiv 2014, arXiv:1412.6806. [Google Scholar]
- Xu, B.; Wang, N.; Chen, T.; Li, M. Empirical evaluation of rectified activations in convolutional network. arXiv 2015, arXiv:1505.00853. [Google Scholar]
- Bottou, L. Large-scale machine learning with stochastic gradient descent. In Proceedings of the 19th International Conference on Computational Statistics, Paris, France, 22–27 August 2010. [Google Scholar]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Van der Linden, S.; Rabe, A.; Held, M.; Jakimow, B.; Leitão, P.; Okujeni, A.; Schwieder, M.; Suess, S.; Hostert, P. The enmap-box—A toolbox and application programming interface for enmap data processing. Remote Sens. 2015, 7, 11249–11266. [Google Scholar] [CrossRef] [Green Version]
- Hofmann, P.; Taubenböck, H.; Werthmann, C. In Monitoring and Modelling of Informal Settlements—A Review on Recent Developments and Challenges. In Proceedings of the Joint Urban Remote Sensing Event 2015, Lausanne, Switzerland, 30 March–1 April 2015. [Google Scholar]
- Rhinane, H.; Hilali, A.; Berrada, A.; Hakdaoui, M. Detecting slums from spot data in casablanca morocco using an object based approach. J. Geogr. Inf. Syst. 2011, 3, 217–224. [Google Scholar] [CrossRef] [Green Version]
- Kuffer, M.; Pfeffer, K.; Sliuzas, R.; Baud, I. Extraction of slum areas from vhr imagery using glcm variance. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 1830–1840. [Google Scholar] [CrossRef]
- Tan, Y.; Xiong, S.; Yan, P. Multi-branch convolutional neural network for built-up area extraction from remote sensing image. Neurocomputing 2019. [Google Scholar] [CrossRef]
- Zhang, P.; Ke, Y.; Zhang, Z.; Wang, M.; Li, P.; Zhang, S. Urban land use and land cover classification using novel deep learning models based on high spatial resolution satellite imagery. Sensor 2018, 18, 3717. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ground Truth | |||
|---|---|---|---|
| Prediction | Buildings | Non Buildings | |
| Buildings | TP | FP | |
| Non Buildings | FN | TN | |
| Training Sites | Test Sites | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Overall accuracy (%) | 98.97 | 97.59 | 96.03 | 93.28 | 95.15 | 97.24 | 87.70 | 95.17 | 96.92 | 86.88 |
| F1-score | 0.993 | 0.984 | 0.972 | 0.895 | 0.957 | 0.982 | 0.909 | 0.971 | 0.976 | 0.898 |
| IoU (%) | 92.31 | 90.61 | 96.60 | 95.88 | 99.44 | 88.49 | 93.04 | 99.46 | 98.43 | 97.01 |
| Training Sites | Test Sites | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| Overall accuracy (%) | 96.5 | 93.6 | 93.7 | 94.0 | 94.5 | 93.7 | 83.4 | 87.2 | 86.4 | 84.7 |
| F1-score | 0.96 | 0.94 | 0.93 | 0.92 | 0.89 | 0.89 | 0.68 | 0.88 | 0.65 | 0.63 |
| IoU (%) | 85.52 | 98.40 | 96.11 | 92.88 | 91.87 | 96.00 | 86.20 | 93.26 | 88.78 | 86.11 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, Z.; Xu, J.; Guo, Y.; Hu, Y.; Wang, G. Deep Learning Segmentation and Classification for Urban Village Using a Worldview Satellite Image Based on U-Net. Remote Sens. 2020, 12, 1574. https://doi.org/10.3390/rs12101574
Pan Z, Xu J, Guo Y, Hu Y, Wang G. Deep Learning Segmentation and Classification for Urban Village Using a Worldview Satellite Image Based on U-Net. Remote Sensing. 2020; 12(10):1574. https://doi.org/10.3390/rs12101574
Chicago/Turabian StylePan, Zhuokun, Jiashu Xu, Yubin Guo, Yueming Hu, and Guangxing Wang. 2020. "Deep Learning Segmentation and Classification for Urban Village Using a Worldview Satellite Image Based on U-Net" Remote Sensing 12, no. 10: 1574. https://doi.org/10.3390/rs12101574
APA StylePan, Z., Xu, J., Guo, Y., Hu, Y., & Wang, G. (2020). Deep Learning Segmentation and Classification for Urban Village Using a Worldview Satellite Image Based on U-Net. Remote Sensing, 12(10), 1574. https://doi.org/10.3390/rs12101574