Mixed 2D/3D Convolutional Network for Hyperspectral Image Super-Resolution




Abstract
:
1. Introduction
- The novel mixed convolutional module (MCM) is proposed to mine the potential features. Using the correlation between 3D and 2D feature maps, 3D and 2D convolution share spatial information by reshaping. Compared with using only 3D convolution, it not only reduce the parameters of the network, but also makes the network learning relatively easy.
- Spatial and spectral separable 3D convolution is employed to extract spatial and spectral features in each 3D unit. It can effectively reduce unaffordable memory usage and training time.
- The local feature fusion is designed to adaptively preserve the accumulated features for 2D unit. It makes full use of all the hierarchical features in each 2D unit after changing the size of feature maps.
- Extensive experiments on three benchmark datasets demonstrate that the proposed approach achieves superior performance in comparison to existing state-of-the-art methods.
2. Related Work
2.1. Deep Learning-Based Methods
2.2. 3D Convolution
3. Proposed Method
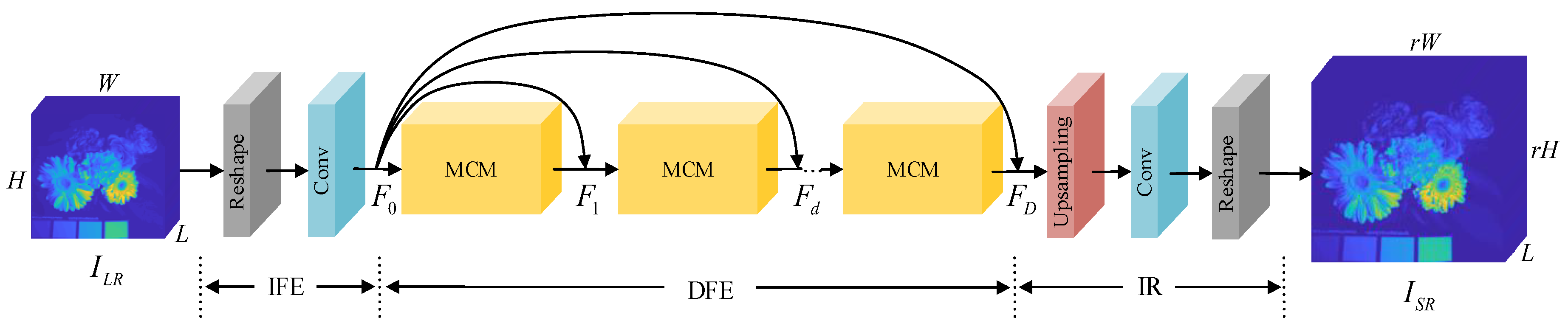
3.1. Network Structure
3.2. Mixed Convolutional Module
3.2.1. 3D Unit
3.2.2. 2D Unit
3.2.3. Local Feature Fusion
3.3. Skip Connections
3.4. Network Learning
4. Results
4.1. Datasets
4.2. Implementation Details
4.3. Evaluation Metrics
4.4. Model Analysis
4.4.1. Study of D Module
4.4.2. Ablation Study Analysis
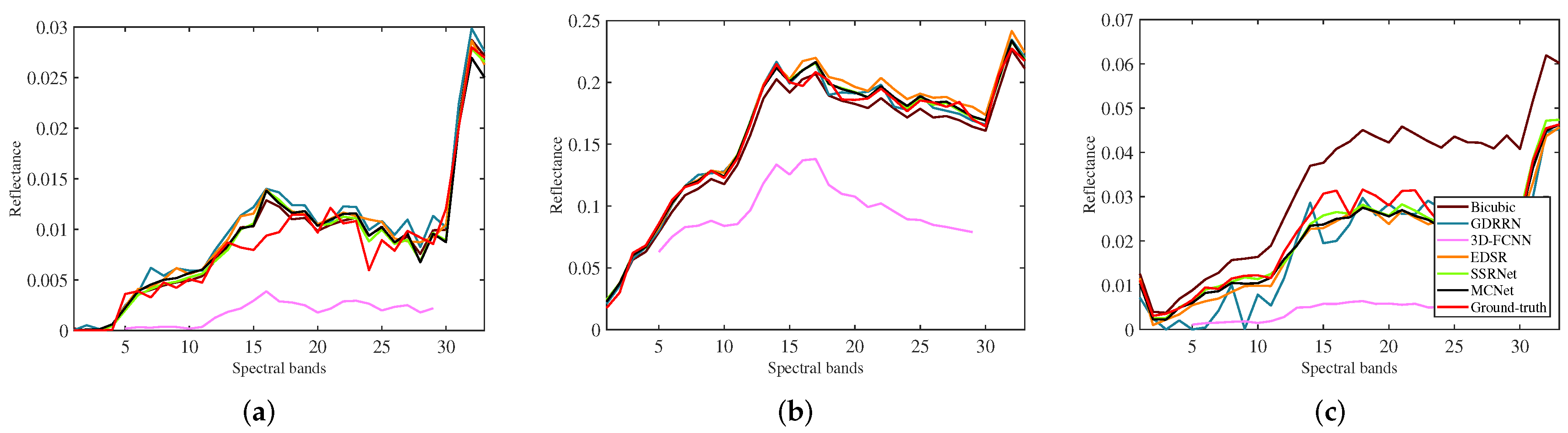
4.5. Comparisons with the State-of-the-Art Methods
4.6. Application on Real Hyperspectral Image
5. Discussions
5.1. Loss Function Analysis
5.2. Efficiency Study of 3D Unit
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Li, Q.; Wang, Q.; Li, X. An Efficient Clustering Method for Hyperspectral Optimal Band selection via Shared Nearest Neighbor. Remote Sens. 2019, 11, 350. [Google Scholar] [CrossRef] [Green Version]
- Sabins, F.F. Remote Sensing for Mineral Exploration. Ore Geol. Rev. 1999, 14, 157–183. [Google Scholar] [CrossRef]
- Lin, J.; Clancy, N.T.; Qi, J.; Hu, Y.; Tatla, T.; Stoyanov, D.; Maier-Hein, L.; Elson, D.S. Dual-modality Endoscopic Probe for Tissue Surface Shape Reconstruction and Hyperspectral Imaging Enabled by Deep Neural Networks. Med. Image Anal. 2018, 48, 162–176. [Google Scholar] [CrossRef] [PubMed]
- Lowe, A.; Harrison, N.; French, A.P. Hyperspectral Image Analysis Techniques for the Detection and Classification of the Early Onset of Plant Disease and Stress. Plant Methods 2017, 13, 80. [Google Scholar] [CrossRef] [PubMed]
- Wang, Q.; Yuan, Z.; Li, X. GETNET: A General End-to-end Two-dimensional CNN Framework for Hyperspectral Image Change Detection. IEEE Trans. Geosci. Remote Sens. 2019, 57, 3–13. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; He, X.; Li, X. Locality and Structure Regularized Low Rank Representation for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 911–923. [Google Scholar] [CrossRef] [Green Version]
- Xie, W.; Jia, X.; Li, Y.; Lei, J. Hyperspectral Image Super-Resolution Using Deep Feature Matrix Factorizationk. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6055–6067. [Google Scholar] [CrossRef]
- Dong, W.; Fu, F.; Shi, G.; Gao, X.; Wu, J.; Li, G.; Li, X. Hyperspectral Image Super-Resolution via Non-Negative Structured Sparse Representation. IEEE Trans. Image Process. 2016, 25, 2337–2352. [Google Scholar] [CrossRef]
- Akgun, T.; Altunbasak, Y.; Mersereau, R.M. Super-resolution Reconstruction of Hyperspectral Images. IEEE Trans. Image Process. 2005, 14, 1860–1875. [Google Scholar] [CrossRef]
- Hu, Y.; Li, J.; Huang, Y.; Gao, X. Channel-wise and Spatial Feature Modulation Network for Single Image Super-Resolution. IEEE Trans. Circuits Syst. Video Technol. 2019. [Google Scholar] [CrossRef] [Green Version]
- Qu, Y.; Qi, H.; Kwan, C. Unsupervised Sparse Dirichlet-Net for Hyperspectral Image Super-Resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 2511–2520. [Google Scholar] [CrossRef] [Green Version]
- Kwon, H.; Tai, Y. RGB-guided Hyperspectral Image Upsampling. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 307–315. [Google Scholar] [CrossRef]
- Akhtar, N.; Shafait, F.; Mian, A.S. Hierarchical Beta Process with Gaussian Process Prior for Hyperspectral Image Super Resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 103–120. [Google Scholar] [CrossRef]
- Wycoff, E.; Chan, T.; Jia, K.; Ma, W.; Ma, Y. A Non-negative Sparse Promoting Algorithm for High Resolution Hyperspectral Imaging. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 1409–1413. [Google Scholar] [CrossRef]
- Boyd, S.; Parikh, N.; Chu, E.; Peleato, B.; Eckstein, J. Distributed Optimization and Statistical Learning via Alternating Direction Method of Multipliers. Found. Trends Mach. Learn. 2011, 3, 1–122. [Google Scholar]
- Fu, Y.; Zhang, T.; Zheng, Y.; Zhang, D.; Huang, H. Hyperspectral Image Super-Resolution with Optimized RGB Guidance. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar] [CrossRef]
- Anwar, S.; Khan, S.; Barnes, N. A Deep Journey into Super-Resolution: A survey. arXiv 2019, arXiv:1904.07523. [Google Scholar]
- Zhang, Y.; Tian, Y.; Kong, Y.; Zhong, B.; Fu, Y. Residual Dense Network for Image Super-Resolution. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2472–2481. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Learning A Deep Convolutional Network for Image Super-Resolution. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2014; pp. 184–199. [Google Scholar] [CrossRef]
- Lim, B.; Son, S.; Kim, H.; Nah, S.; Lee, K.M. Enhanced Deep Residual Networks for Single Image Super-Resolution. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Honolulu, HI, USA, 21–26 July 2017; pp. 1132–1140. [Google Scholar] [CrossRef] [Green Version]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z. Photo-realistic Single Image Super-Resolution Using A Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4681–4690. [Google Scholar]
- Li, Y.; Zhang, L.; Ding, C.; Wei, W.; Zhang, Y. Single Hyperspectral Image Super-Resolution with Grouped Deep Recursive Residual Network. In Proceedings of the 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Yuan, Y.; Zheng, X.; Lu, X. Hyperspectral Image Superresolution by Transfer Learning. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2017, 10, 1963–1974. [Google Scholar] [CrossRef]
- Jia, J.; Ji, L.; Zhao, Y.; Geng, X. Hyperspectral Image Super-Resolution with Spectral–Spatial Network. Proc. Int. J. Remote Sens. 2018, 39, 7806–7829. [Google Scholar] [CrossRef]
- Li, R.; Hu, J.; Zhao, X.; Xie, W.; Li, J. Hyperspectral Image Super-Resolution Using Deep Convolutional Neural Network. Neurocomputing 2017, 266, 29–41. [Google Scholar] [CrossRef]
- Mei, S.; Yuan, X.; Ji, J.; Zhang, Y.; Wan, S.; Du, Q. Hyperspectral Image Spatial Super-Resolution via 3D Full Convolutional Neural Network. Remote Sens. 2017, 9, 1139. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Zhao, Y.; Chan, J.C.; Xiao, L. A Multi-Scale Wavelet 3D-CNN for Hyperspectral Image Super-Resolution. Remote Sens. 2019, 11, 1557. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Cui, R.; Li, Y.; Li, B.; Du, Q.; Ge, C. Multitemporal Hyperspectral Image Super-Resolution through 3D Generative Adversarial Network. In Proceedings of the 2019 10th International Workshop on the Analysis of Multitemporal Remote Sensing Images (MultiTemp), Shanghai, China, 5–7 August 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Q.; Li, X. Spatial-Spectral Residual Network for Hyperspectral Image Super-Resolution. arXiv 2020, arXiv:2001.04609. [Google Scholar]
- Li, J.; Cui, R.; Li, B.; Li, Y.; Du, S.M.Q. Dual 1D-2D Spatial-Spectral CNN for Hyperspectral Image Super-Resolution. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2019), Yokohama, Japan, 28 July–2 August 2019; pp. 3113–3116. [Google Scholar] [CrossRef]
- He, Z.; Lin, L. Hyperspectral Image Super-Resolution Inspired by Deep Laplacian Pyramid Network. Remote Sens. 2018, 10, 1939. [Google Scholar] [CrossRef] [Green Version]
- Tai, Y.; Yang, J.; Liu, X. Image Super-Resolution via Deep Recursive Residual Network. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3147–3155. [Google Scholar] [CrossRef]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar]
- Jiang, R.; Li, X.; Gao, A.; Li, L.; Meng, H.; Yue, S.; Zhang, L. Learning Spectral and Spatial Features Based on Generative Adversarial Network for Hyperspectral Image Super-Resolution. In Proceedings of the 2019 IEEE International Geoscience and Remote Sensing Symposium (IGARSS 2019), Yokohama, Japan, 28 July–2 August 2019; pp. 3161–3164. [Google Scholar] [CrossRef] [Green Version]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Kappeler, A.; Yoo, S.; Dai, Q.; Katsaggelos, A.K. Video Super-Resolution With Convolutional Neural Networks. IEEE Trans. Comput. Imaging 2016, 2, 109–122. [Google Scholar] [CrossRef]
- Wang, Q.; Li, Q.; Li, X. Hyperspectral Band Selection via Adaptive Subspace Partition Strategy. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2019. [Google Scholar] [CrossRef]
- Tran, D.; Wang, H.; Torresani, L.; Feiszli, M. Video Classification with Channel-Separated Convolutional Networks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5552–5561. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Xie, S.; Sun, C.; Huang, J.; Tu, Z.; Murphy, K. Rethinking Spatiotemporal Feature Learning: Speed-accuracy Trade-offs in Video Classification. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2018; pp. 318–335. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Huang, G.; Liu, Z.; Maaten, L.V.D.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Lee, J.K.; Lee, K.M. Accurate Image Super-Resolution Using very Deep Convolutional Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1646–1654. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Liu, Y.; Bai, X.; Tnag, W.; Lei, P.; Zhou, J. Deep Residual Convolutional Neural Network for Hyperspectral Image Super-Resolution. In International Conference on Image and Graphics; Springer: Cham, Switzerland, 2017; pp. 370–380. [Google Scholar] [CrossRef] [Green Version]
- Yasuma, F.; Mitsunaga, T.; Iso, D.; Nayar, S.K. Generalized Assorted Pixel Camera: Postcapture Control of Resolution, Dynamic Range, and Spectrum. IEEE Trans. Image Process. 2010, 19, 2241–2253. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chakrabarti, A.; Zickler, T. Statistics of Real-world Hyperspectral Images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2011), Providence, RI, USA, 20–25 June 2011; pp. 193–200. [Google Scholar] [CrossRef] [Green Version]
- Nascimento, S.M.C.; Amano, K.; Foster, D.H. Spatial Distributions of Local Illumination Color in Natural Scenes. Vis. Res. 2016, 120, 39–44. [Google Scholar] [CrossRef] [PubMed]
- Miller, F.P.; Vandome, A.F.; Mcbrewster, J. Bicubic Interpolation; Alphascript Publishing: Riga, Latvia, 2010. [Google Scholar]
- Yu, J.; Fan, Y.; Yang, J.; Xu, N.; Wang, Z.; Wang, X.; Huang, T. Wide Activation for Efficient and Accurate Image Super-Resolution. arXiv 2018, arXiv:1808.08718v2. [Google Scholar]
- Nascimento, S.M.C.; Ferreira, F.P.; Foster, D.H. Statistics of Spatial Cone-Excitation Ratios in Natural Scenes. J. Opt. Soc. Am. A Opt. Image Sci. Vis. 2002, 19, 1484–1490. [Google Scholar] [CrossRef] [Green Version]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “Completely Blind” Image Quality Analyzer. IEEE Signal Process. Lett. 2013, 20, 209–212. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Metrics | 2 | 3 | 4 | 5 |
|---|---|---|---|---|
| PSNR | 45.013 | 45.043 | 45.102 | 45.051 |
| SSIM | 0.9734 | 0.9736 | 0.9738 | 0.9735 |
| SAM | 2.247 | 2.244 | 2.241 | 2.243 |
| Components | Different Combinations of Components | |||||
|---|---|---|---|---|---|---|
| 2D unit (2U) | × | × | × | √ | × | √ |
| Local feature fusion (LFF) | × | √ | × | √ | √ | √ |
| Global residual learning (GRL) | × | × | √ | × | √ | √ |
| PSNR | 44.068 | 44.395 | 44.533 | 44.617 | 45.014 | 45.101 |
| SSIM | 0.9727 | 0.9729 | 0.9730 | 0.9734 | 0.9735 | 0.9738 |
| SAM | 2.451 | 2.325 | 2.318 | 2.312 | 2.283 | 2.241 |
| Scale Factor | Methods | CAVE | Harvard | Foster |
|---|---|---|---|---|
| PSNR/SSIM/SAM | PSNR/SSIM /SAM | PSNR/SSIM/SAM | ||
| ×2 | Bicubic | 40.762/0.9623/2.665 | 42.833/0.9711/2.023 | 55.155/0.9981/4.391 |
| GDRRN | 41.667/0.9651/3.842 | 44.213/0.9775/2.278 | 53.527/0.9963/5.634 | |
| 3D-FCNN | 43.154/0.9686/2.305 | 44.454/0.9778/1.894 | 60.242/0.9987/5.271 | |
| EDSR | 43.869/0.9734/2.636 | 45.480/0.9824/1.921 | 57.371/0.9978/5.753 | |
| SSRNet | 44.991/0.9737/2.261 | 46.247/0.9825/1.884 | 58.852/0.9987/4.064 | |
| MCNet | 45.102/0.9738/2.241 | 46.263/0.9827/1.883 | 58.878/0.9988/4.061 | |
| ×3 | Bicubic | 37.532/0.9325/3.522 | 39.441/0.9411/2.325 | 50.964/0.9943/5.357 |
| GDRRN | 38.834/0.9401/4.537 | 40.912/0.9523/2.623 | 50.464/0.9926/6.833 | |
| 3D-FCNN | 40.219/0.9453/2.930 | 40.585/0.9480/2.239 | 55.551/0.9958/6.303 | |
| EDSR | 40.533/0.9512/3.175 | 41.674/0.9592/2.380 | 52.983/0.9956/7.716 | |
| SSRNet | 40.896/0.9524/2.814 | 42.650/0.9626/2.209 | 54.937/0.9967/5.134 | |
| MCNet | 41.031/0.9526/2.809 | 42.681/0.9627/2.214 | 55.017/0.9970/5.126 | |
| ×4 | Bicubic | 35.755/0.9071/3.944 | 37.227/0.9122/2.531 | 48.281/0.9880/5.993 |
| GDRRN | 36.959/0.9166/5.168 | 38.596/0.9259/2.794 | 47.836/0.9877/7.696 | |
| 3D-FCNN | 37.626/0.9195/3.360 | 38.143/0.9188/2.363 | 52.188/0.9918/7.798 | |
| EDSR | 38.587/0.9292/3.804 | 39.175/0.9324/2.560 | 50.362/0.9915/7.103 | |
| SSRNet | 38.944/0.9312/3.297 | 40.001/0.9365/2.412 | 52.210/0.9939/5.702 | |
| MCNet | 39.026/0.9319/3.292 | 40.081/0.9367/2.410 | 52.225/0.9941/5.685 |
| Image | Pixel Position | Bicubic | GDRRN | 3D-FCNN | EDSR | SSRNet | MCNet |
|---|---|---|---|---|---|---|---|
| fake_and_real_lemons | (20, 20) | 8.250 | 9.922 | 34.660 | 5.996 | 7.047 | 6.753 |
| (100, 100) | 0.220 | 0.756 | 0.246 | 0.322 | 0.227 | 0.222 | |
| (340, 340) | 3.537 | 3.530 | 6.204 | 2.942 | 3.126 | 2.777 | |
| imgd5 | (20, 20) | 0.547 | 1.120 | 0.659 | 0.517 | 0.531 | 0.545 |
| (100, 100) | 0.829 | 1.230 | 0.814 | 0.912 | 0.832 | 0.813 | |
| (340, 340) | 0.983 | 2.003 | 3.153 | 1.198 | 1.042 | 0.971 | |
| Bom_Jesus_Bush | (20, 20) | 6.810 | 8.137 | 18.503 | 8.334 | 7.846 | 8.390 |
| (100, 100) | 1.584 | 1.740 | 8.209 | 1.685 | 1.394 | 1.328 | |
| (340, 340) | 6.590 | 12.134 | 5.632 | 5.288 | 4.376 | 4.339 |
| Scale Factor | Bicubic | GDRRN | 3D-FCNN | EDSR | SSRNet | MCNet |
|---|---|---|---|---|---|---|
| 20.3403 | 20.5709 | 20.4427 | 20.8163 | 20.9145 | 20.9800 | |
| 20.1674 | 20.3097 | 20.3595 | 20.4087 | 20.3576 | 20.3797 | |
| 20.4322 | 20.5553 | 20.5113 | 20.5321 | 20.5714 | 20.5856 |
| Loss Function | PSNR | SSIM | SAM |
|---|---|---|---|
| MSE | 44.980 | 0.9731 | 2.284 |
| L1 | 45.101 | 0.9738 | 2.241 |
| 0.5 * MSE + 0.5 * SAM | 43.763 | 0.9704 | 2.346 |
| Evaluation Metrics | Standard 3D Convolution | Separable 3D Convolution |
|---|---|---|
| Parameter | 3.16 M | 1.93 M |
| PSNR | 45.083 | 45.102 |
| SSIM | 0.9738 | 0.9738 |
| SAM | 2.240 | 2.241 |
| Training Time | 28 h | 20 h |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, Q.; Wang, Q.; Li, X. Mixed 2D/3D Convolutional Network for Hyperspectral Image Super-Resolution. Remote Sens. 2020, 12, 1660. https://doi.org/10.3390/rs12101660
Li Q, Wang Q, Li X. Mixed 2D/3D Convolutional Network for Hyperspectral Image Super-Resolution. Remote Sensing. 2020; 12(10):1660. https://doi.org/10.3390/rs12101660
Chicago/Turabian StyleLi, Qiang, Qi Wang, and Xuelong Li. 2020. "Mixed 2D/3D Convolutional Network for Hyperspectral Image Super-Resolution" Remote Sensing 12, no. 10: 1660. https://doi.org/10.3390/rs12101660
APA StyleLi, Q., Wang, Q., & Li, X. (2020). Mixed 2D/3D Convolutional Network for Hyperspectral Image Super-Resolution. Remote Sensing, 12(10), 1660. https://doi.org/10.3390/rs12101660