The T Index: Measuring the Reliability of Accuracy Estimates Obtained from Non-Probability Samples


Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
2. The Index
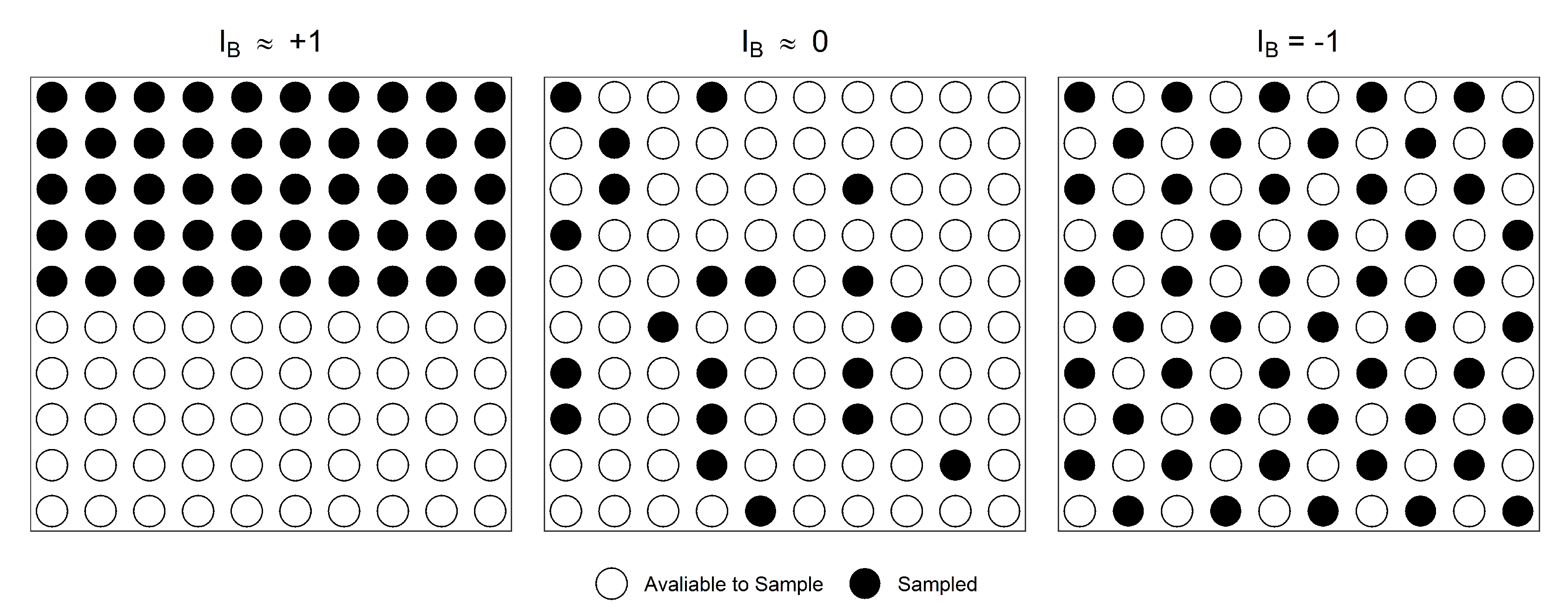
- The normalised Moran’s I index measures the spread of (both labelled and unlabelled) sample sets in the feature space with respect to their populations.
- The normalised Moran’s I index of random samples takes on average the value of zero.
- Remote sensing provides an exhaustive coverage map population in the feature space so that random unlabelled samples can be generated at no cost.
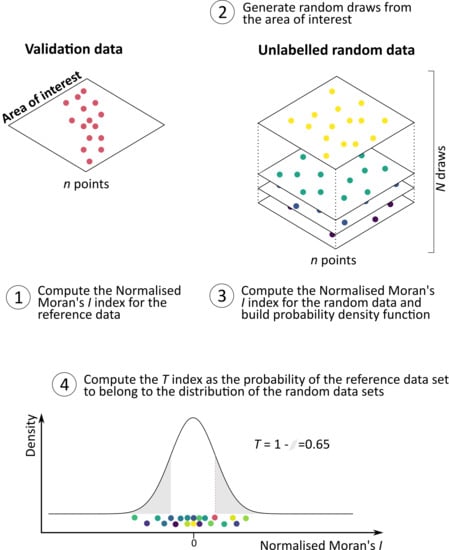
- The probability of the hold-out set being randomly-distributed can be computed by comparing its normalised Moran’s I index to those of random unlabelled samples of the same size.
2.1. The Normalised Moran’s I Index: Characterising the Spread of Data in the Feature Space
2.2. The T Index: How Reliable Are Accuracy Estimates Obtained from Non-Probability Samples?
3. Case Study
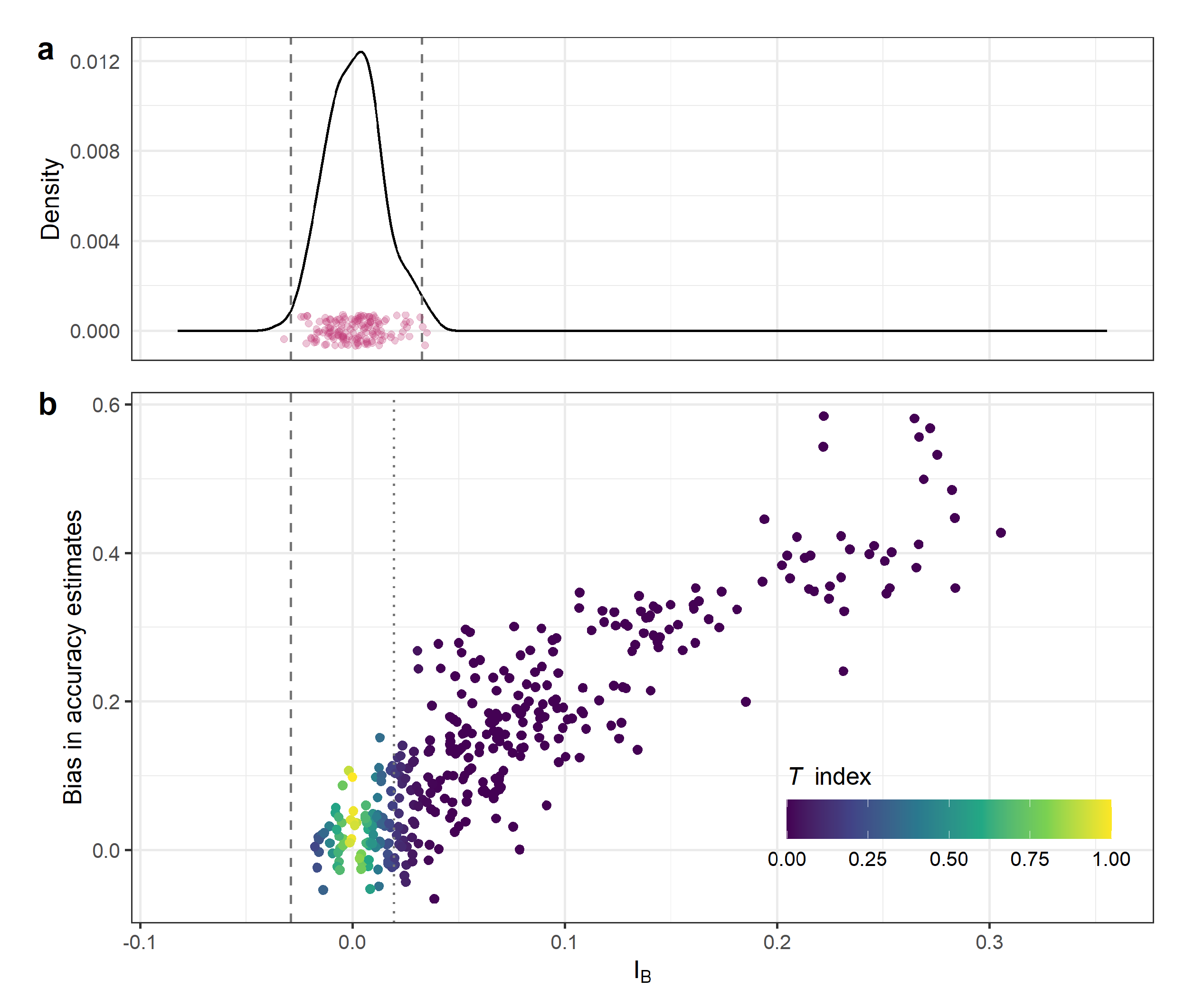
- the normalised Moran’s I index correlates with the bias of accuracy estimates obtained from the reference data, and
- the T index indicates when cross-validated accuracy estimates can be trusted and generalised to the area of interest.
3.1. Data Sources
3.2. Sampling and Classification
3.3. Statistical Analysis
4. Results and Discussion
5. Conclusions
Funding
Acknowledgments
Conflicts of Interest
Code Availability
References
- Stehman, S.V.; Foody, G.M. Key issues in rigorous accuracy assessment of land cover products. Remote Sens. Environ. 2019, 231, 111199. [Google Scholar] [CrossRef]
- Stehman, S.V. Basic probability sampling designs for thematic map accuracy assessment. Int. J. Remote Sens. 1999, 20, 2423–2441. [Google Scholar] [CrossRef]
- Liu, C.; Frazier, P.; Kumar, L. Comparative assessment of the measures of thematic classification accuracy. Remote Sens. Environ. 2007, 107, 606–616. [Google Scholar] [CrossRef]
- Stehman, S.V. Sampling designs for accuracy assessment of land cover. Int. J. Remote Sens. 2009, 30, 5243–5272. [Google Scholar] [CrossRef]
- Pontius, R.G., Jr.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011, 32, 4407–4429. [Google Scholar] [CrossRef]
- Olofsson, P.; Foody, G.M.; Herold, M.; Stehman, S.V.; Woodcock, C.E.; Wulder, M.A. Good practices for estimating area and assessing accuracy of land change. Remote Sens. Environ. 2014, 148, 42–57. [Google Scholar] [CrossRef]
- Zhu, Z.; Gallant, A.L.; Woodcock, C.E.; Pengra, B.; Olofsson, P.; Loveland, T.R.; Jin, S.; Dahal, D.; Yang, L.; Auch, R.F. Optimizing selection of training and auxiliary data for operational land cover classification for the LCMAP initiative. ISPRS J. Photogramm. Remote Sens. 2016, 122, 206–221. [Google Scholar] [CrossRef] [Green Version]
- Heydari, S.S.; Mountrakis, G. Effect of classifier selection, reference sample size, reference class distribution and scene heterogeneity in per-pixel classification accuracy using 26 Landsat sites. Remote Sens. Environ. 2018, 204, 648–658. [Google Scholar] [CrossRef]
- Waldner, F.; Chen, Y.; Lawes, R.; Hochman, Z. Needle in a haystack: Mapping rare and infrequent crops using satellite imagery and data balancing methods. Remote Sens. Environ. 2019, 233, 111375. [Google Scholar] [CrossRef]
- Foody, G.M.; Mathur, A. Toward intelligent training of supervised image classifications: Directing training data acquisition for SVM classification. Remote Sens. Environ. 2004, 93, 107–117. [Google Scholar] [CrossRef]
- Fowler, J.; Waldner, F.; Hochman, Z. All pixels are useful, but some are more useful: Efficient in situ data collection for crop-type mapping using sequential exploration methods. Int. J. Appl. Earth Obs. Geoinf. 2020, 91, 102114. [Google Scholar] [CrossRef]
- Morales-Barquero, L.; Lyons, M.B.; Phinn, S.R.; Roelfsema, C.M. Trends in remote sensing accuracy assessment approaches in the context of natural resources. Remote Sens. 2019, 11, 2305. [Google Scholar] [CrossRef] [Green Version]
- Lyons, M.B.; Keith, D.A.; Phinn, S.R.; Mason, T.J.; Elith, J. A comparison of resampling methods for remote sensing classification and accuracy assessment. Remote Sens. Environ. 2018, 208, 145–153. [Google Scholar] [CrossRef]
- Tillé, Y.; Dickson, M.M.; Espa, G.; Giuliani, D. Measuring the spatial balance of a sample: A new measure based on Moran’s I index. Spat. Stat. 2018, 23, 182–192. [Google Scholar] [CrossRef] [Green Version]
- Moran, P.A. Notes on continuous stochastic phenomena. Biometrika 1950, 37, 17–23. [Google Scholar] [CrossRef]
- Efron, B. Bootstrap methods: Another look at the jackknife. In Breakthroughs in Statistics; Springer: Berlin, Germany, 1992; pp. 569–593. [Google Scholar]
- Waldner, F.; Bellemans, N.; Hochman, Z.; Newby, T.; de Abelleyra, D.; Verón, S.R.; Bartalev, S.; Lavreniuk, M.; Kussul, N.; Le Maire, G.; et al. Roadside collection of training data for cropland mapping is viable when environmental and management gradients are surveyed. Int. J. Appl. Earth Obs. Geoinf. 2019, 80, 82–93. [Google Scholar] [CrossRef]
- Sun, W.; Liang, S.; Xu, G.; Fang, H.; Dickinson, R. Mapping plant functional types from MODIS data using multisource evidential reasoning. Remote Sens. Environ. 2008, 112, 1010–1024. [Google Scholar] [CrossRef]
- Whelen, T.; Siqueira, P. Use of time-series L-band UAVSAR data for the classification of agricultural fields in the San Joaquin Valley. Remote Sens. Environ. 2017, 193, 216–224. [Google Scholar] [CrossRef]
- Claverie, M.; Ju, J.; Masek, J.; Dungan, J.; Vermote, E.; Roger, J.; Skakun, S.; Justice, C. The Harmonized Landsat and Sentinel-2 surface reflectance data set. Remote Sens. Environ. 2018, 219, 145–161. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Sugiyama, M.; Krauledat, M.; Muller, K.R. Covariate shift adaptation by importance weighted cross validation. J. Mach. Learn. Res. 2007, 8, 985–1005. [Google Scholar]
- Kouw, W.; Loog, M. Effects of sampling skewness of the importance-weighted risk estimator on model selection. In Proceedings of the 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 1468–1473. [Google Scholar]
- Kouw, W.M.; Krijthe, J.H.; Loog, M. Robust importance-weighted cross-validation under sample selection bias. In Proceedings of the IEEE 29th International Workshop on Machine Learning for Signal Processing (MLSP), Espoo, Finland, 21–24 September 2019; pp. 1–6. [Google Scholar]





© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Waldner, F. The T Index: Measuring the Reliability of Accuracy Estimates Obtained from Non-Probability Samples. Remote Sens. 2020, 12, 2483. https://doi.org/10.3390/rs12152483
Waldner F. The T Index: Measuring the Reliability of Accuracy Estimates Obtained from Non-Probability Samples. Remote Sensing. 2020; 12(15):2483. https://doi.org/10.3390/rs12152483
Chicago/Turabian StyleWaldner, François. 2020. "The T Index: Measuring the Reliability of Accuracy Estimates Obtained from Non-Probability Samples" Remote Sensing 12, no. 15: 2483. https://doi.org/10.3390/rs12152483
APA StyleWaldner, F. (2020). The T Index: Measuring the Reliability of Accuracy Estimates Obtained from Non-Probability Samples. Remote Sensing, 12(15), 2483. https://doi.org/10.3390/rs12152483