Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review



Abstract
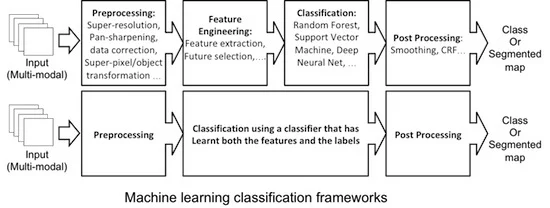
:
1. Motivation
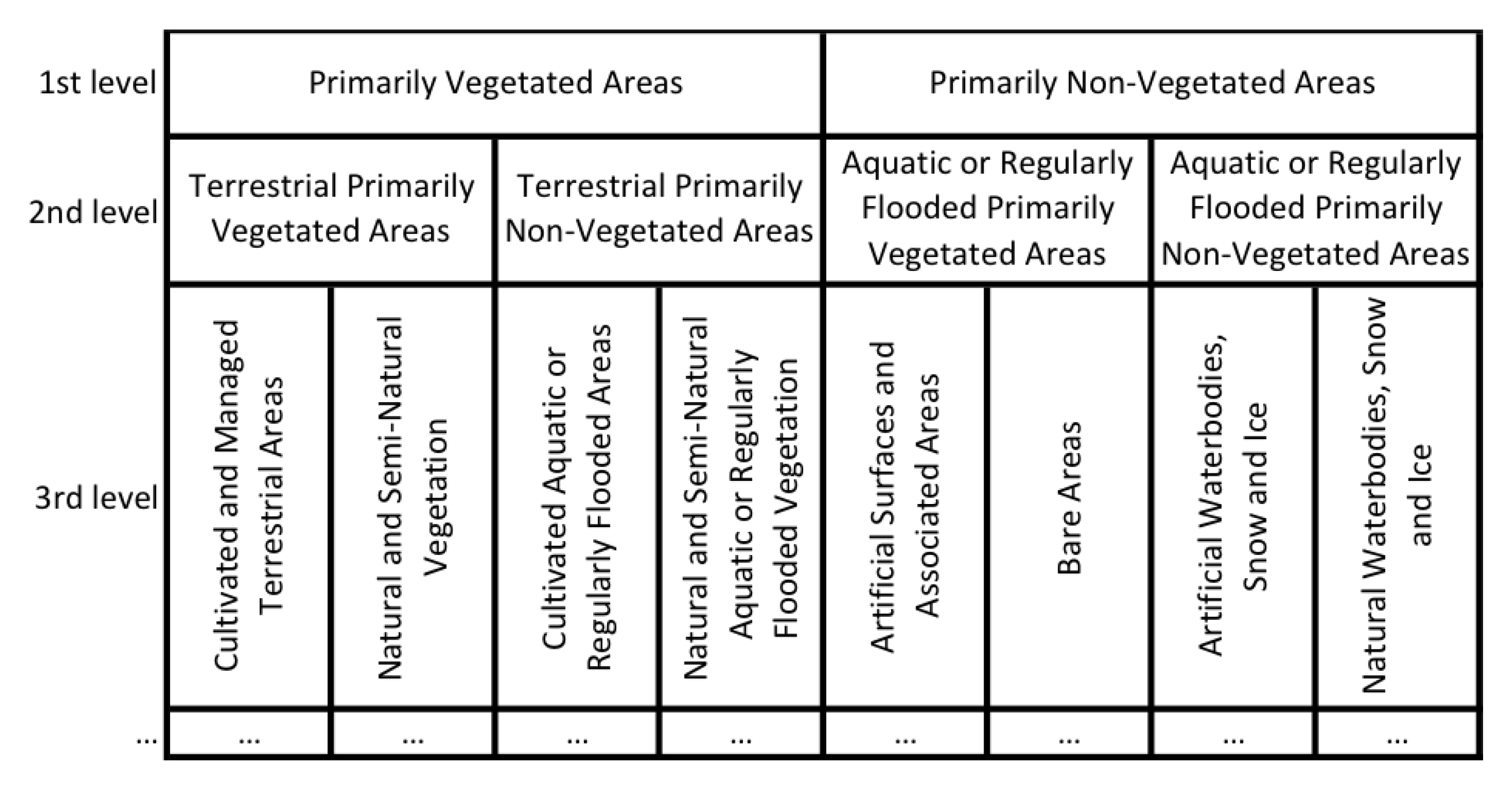
2. Land Use and Land Cover Classification
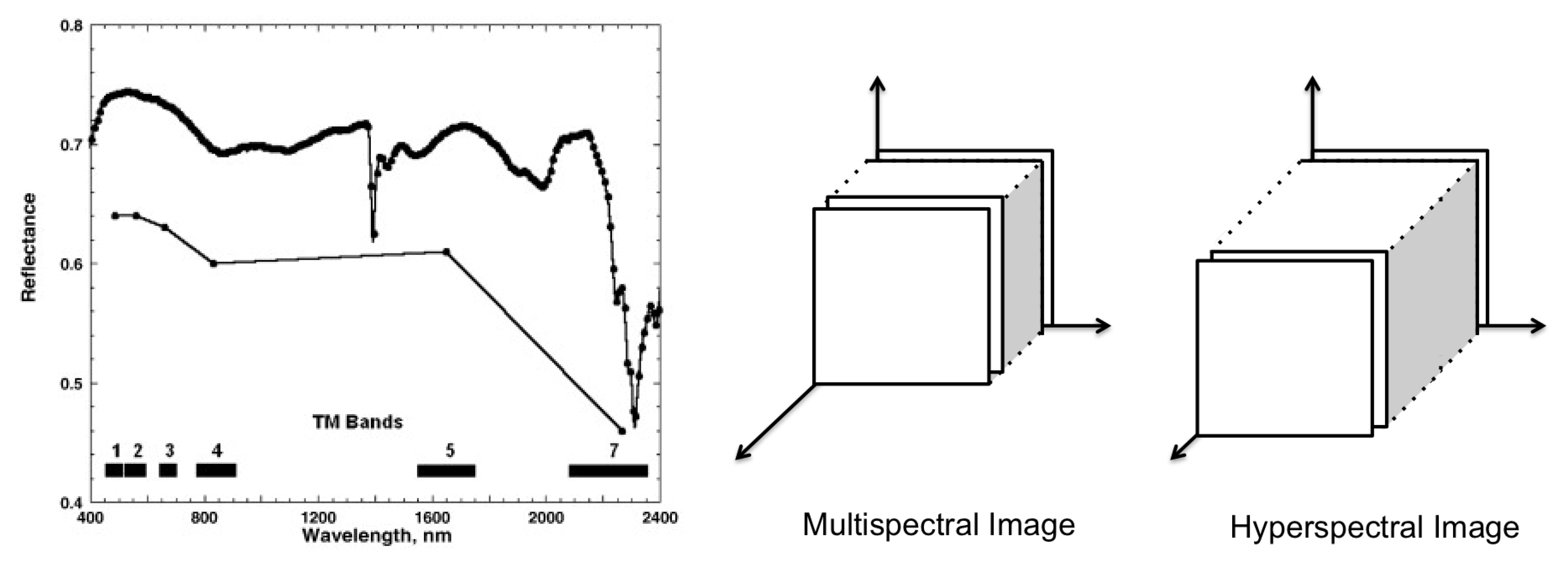
3. Multispectral and Hyperspectral Remote Sensing Data
Data Sources and Datasets
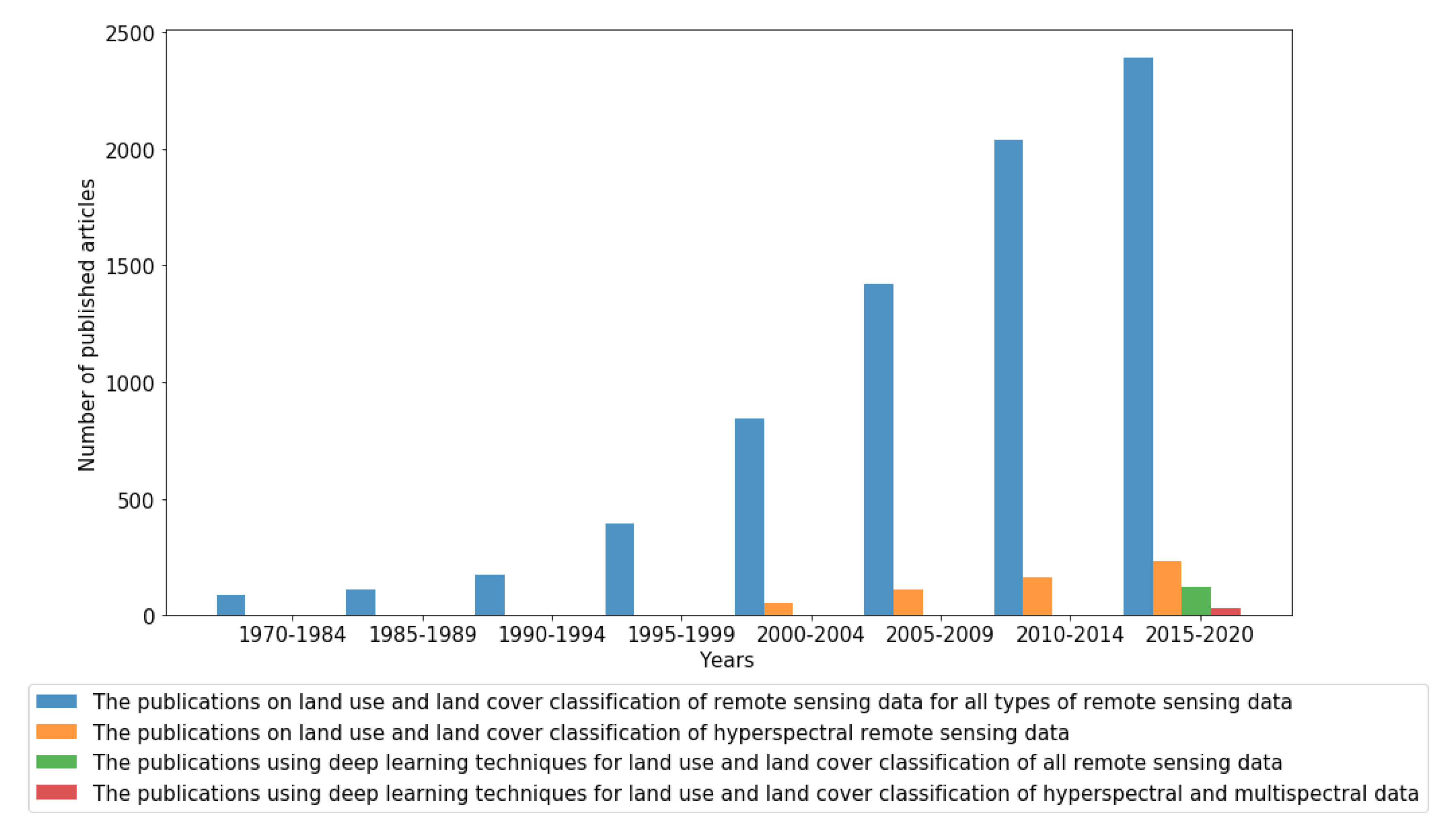
4. Machine Learning for LULC
- In Section 4.1 and Section 4.2 we explain the feature learning property of an end-to-end approach and its limitations that lead us to consider the conventional machine learning model including feature engineering steps. Then we explain the concept of feature engineering, its components, and the common methodologies, as well as deep learning techniques employed in literature to accomplish them. We also discuss the importance of defining the feature space and its direct impact on shaping the process pipeline.
- In Section 4.3 we explore the choices of MSI and HSI classifiers for the LULC classifications and discuss the effectiveness of deep learning techniques for this task. We also explain different types of deep learning approaches in classifying MSI and HSI used in the state-of-the-art.
- Focusing on the well-know challenge of limited ground-truth, in Section 4.4 we explain how it impacts the performance of deep learning models for HSI and MSI. Then, we report the research works facing this challenge.
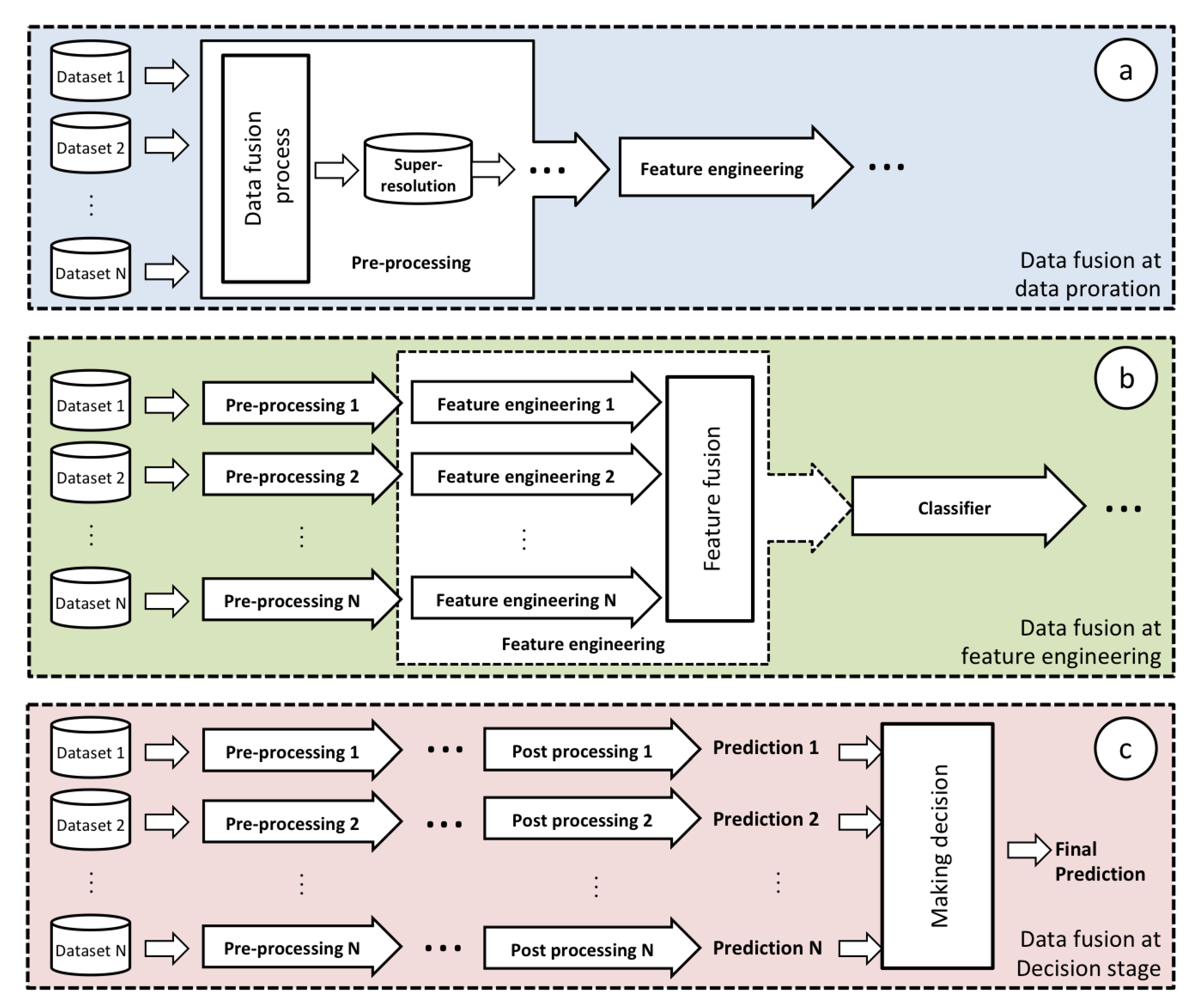
- In Section 4.5 we discuss the challenge of data fusion as faced by many state-of-the-art studies. We explain the main concerns in data fusion and how deep learning is facilitating their accomplishments.
- Finally, in Section 4.6 we discuss other potential pre-processing and post-processing techniques in literature that can improve the LULC classification performance.
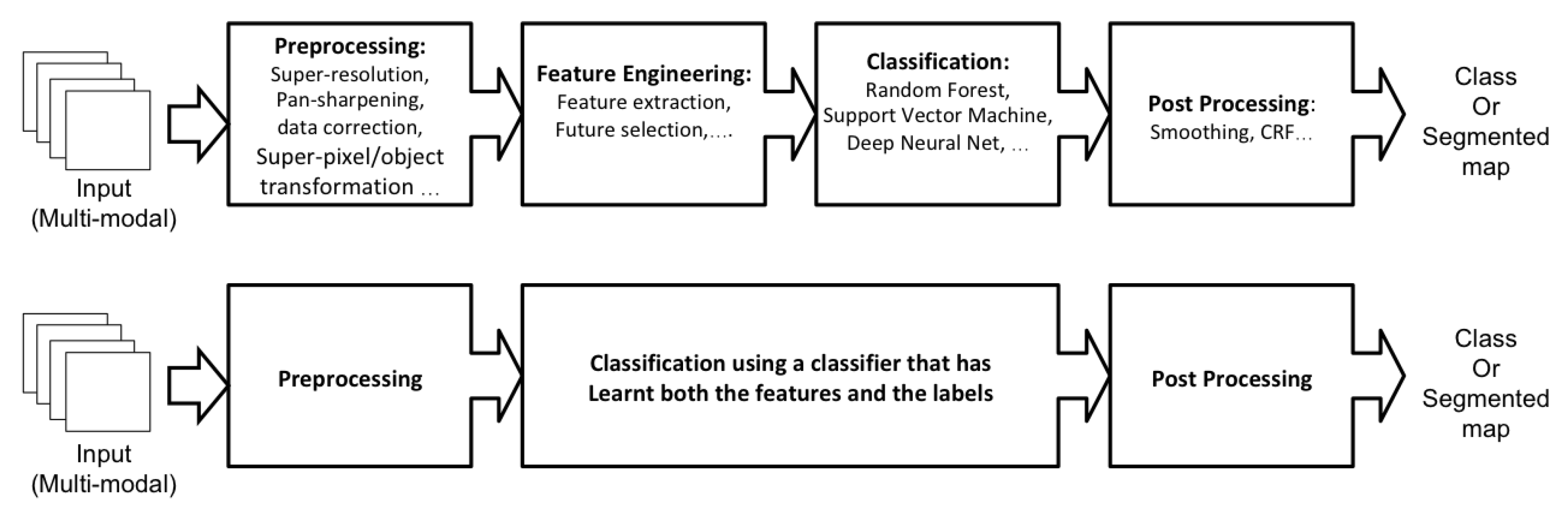
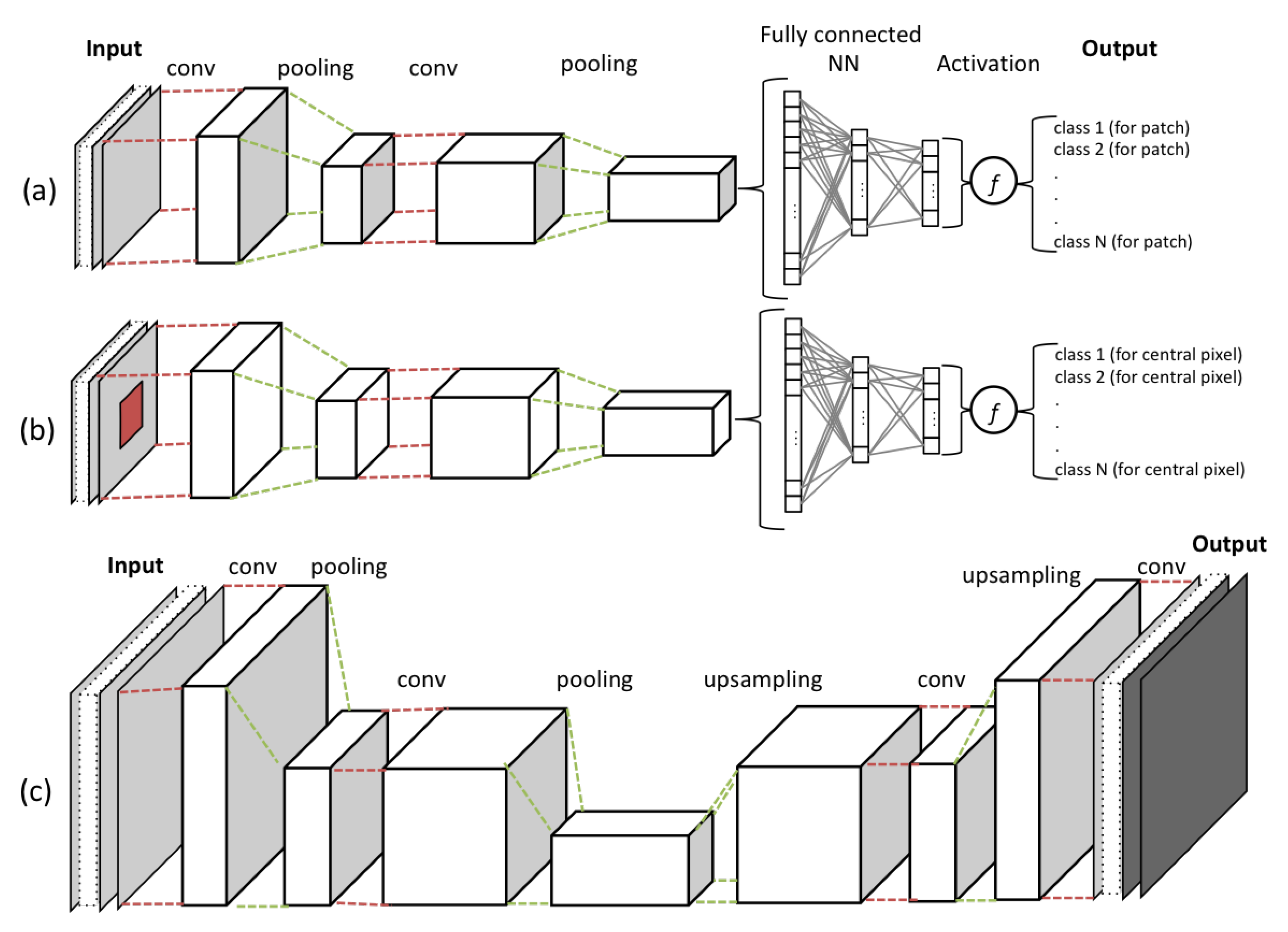
4.1. End-To-End Deep Learning
4.2. Feature Engineering
4.2.1. Feature Selection and Transformation
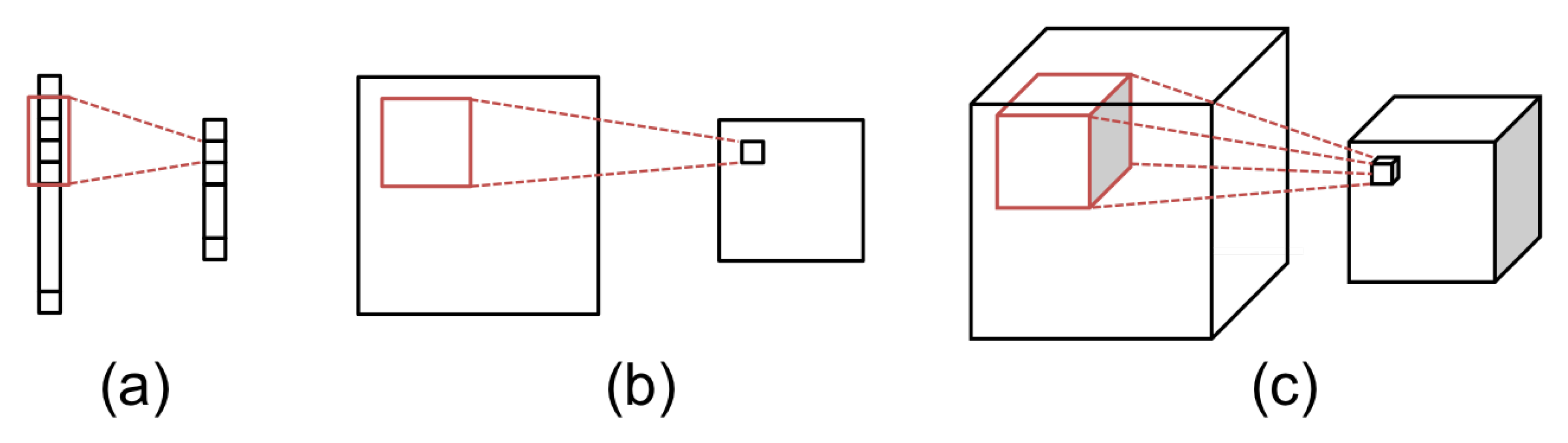
4.2.2. Feature Extraction
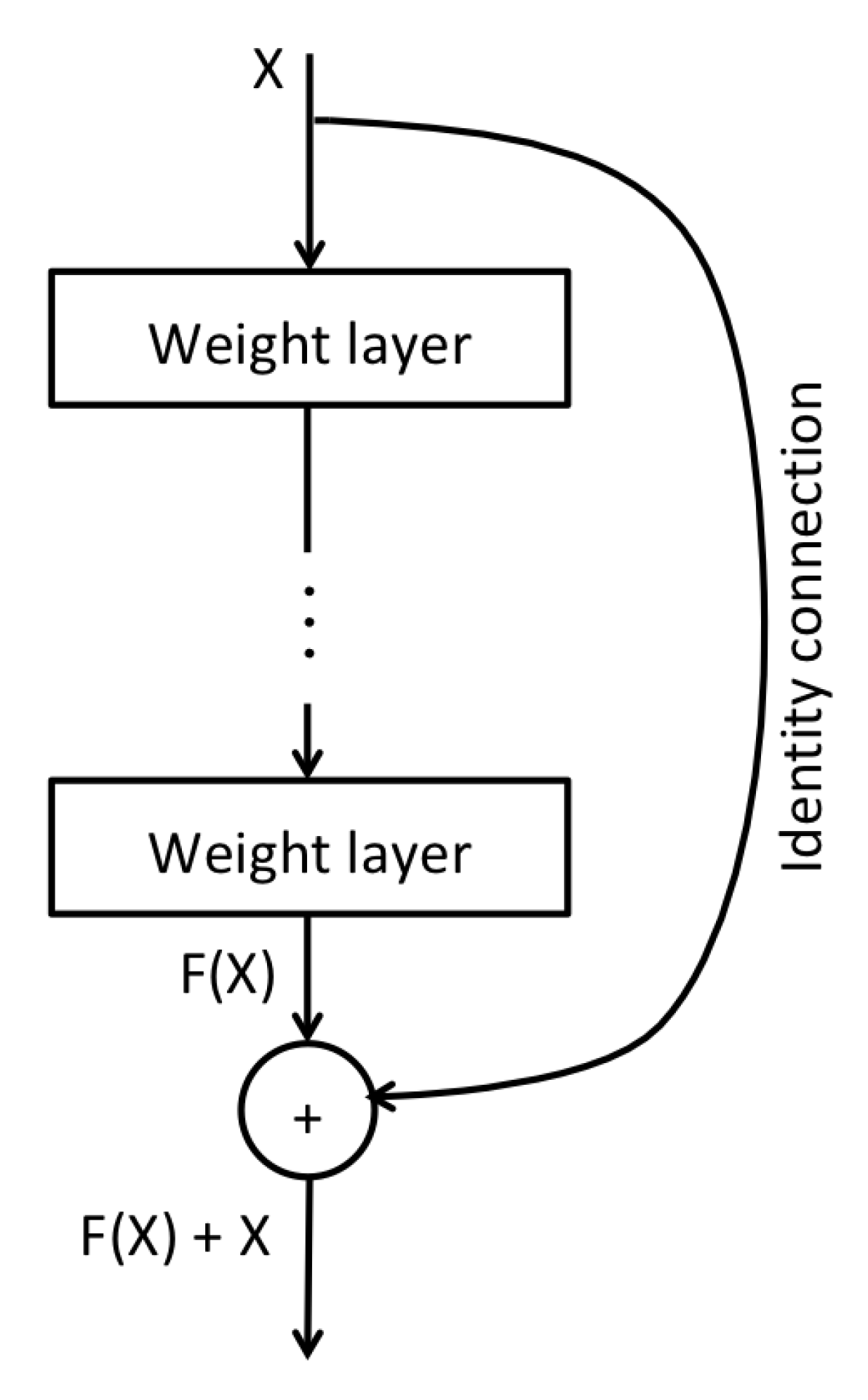
4.3. Classifier
4.4. The Challenge of Limited Ground-Truth
4.5. Multi-Modal Data Fusion
4.6. Pre and Post-Processing
5. Conclusions
- For the majority of the commercially viable applications, the spatial resolution of remote sensing images is required to be higher than what any satellite can provide. Therefore, aerial remote sensing images are more popular due to their higher spatial resolution. Yet, the limited coverage and low temporal resolution of such aerial images come with some challenges for many applications that leave room for the use of satellite images as well. Therefore, the trade-off between temporal and spatial resolution lays the ground for further discussion on this matter.
- The ground-truth scarcity is yet a challenge. An accurate annotated data set could open the doors to new opportunities for researchers. Most of the available solutions suffer from lack of funding and difficulty in assessment of their accuracy. Indeed, the use of IoT and the open science framework that supports the integration of citizen science, gamification, incentives and competitions, is still to be explored.
- Despite the constant increase in the number of geospatial data providers, for many years there has been no standardised way to release and to get hold of the data. Commonly, processing and analysis of data are carried out on local machines, on the locally replicated instance of data. With the fast growth of data in volume and the limitation in memory, relying on conventional infrastructures appear not to be feasible and efficient anymore. Recently, data providers have introduced the cloud platform to access and analyse data directly, which offers the possibility of integration of data from different sources in the near future. Certainly, getting aligned with the advances in infrastructure opens up new opportunities to be investigated.
- The recent idea of on-board data processing could introduce new challenges: as announced by NASA and ESA, the future satellites are planned to carry more powerful processors that can process data before transferring them to the Earth. However, the power-scale and energy management is a crucial problem for the on-board processes. Therefore, reducing the complexity of the models is a crucial matter to be considered for future works. The recent study by [181], which proposes the Firefly Harmony Search (FHS) tuning algorithm for its Deep Belief Network model, also proves that simplifying the models can also improve the accuracy of classifications.
Author Contributions
Funding
Conflicts of Interest
References
- ESA. Towards a European AI4EO R&I Agenda. 2018. Available online: https://eo4society.esa.int/wp-content/uploads/2018/09/ai4eo_v1.0.pdf (accessed on 15 January 2019).
- Newbold, T.; Hudson, L.N.; Hill, S.L.; Contu, S.; Lysenko, I.; Senior, R.A.; Börger, L.; Bennett, D.J.; Choimes, A.; Collen, B.; et al. Global effects of land use on local terrestrial biodiversity. Nature 2015, 520, 45. [Google Scholar] [CrossRef] [Green Version]
- Vitousek, P.M.; Mooney, H.A.; Lubchenco, J.; Melillo, J.M. Human domination of Earth’s ecosystems. Science 1997, 277, 494–499. [Google Scholar] [CrossRef] [Green Version]
- Feddema, J.J.; Oleson, K.W.; Bonan, G.B.; Mearns, L.O.; Buja, L.E.; Meehl, G.A.; Washington, W.M. The importance of land-cover change in simulating future climates. Science 2005, 310, 1674–1678. [Google Scholar] [CrossRef] [Green Version]
- Turner, B.L.; Moss, R.H.; Skole, D. Relating Land Use and Global Land-Cover Change; IGBP Report 24, HDP Report 5; IGDP Report No. 24; HDP Report No. 5; International Geosphere-Biosphere Programme: Stockholm, Sweden, 1993. [Google Scholar]
- United Nations Office for Disaster Risk Reduction. Sendai framework for disaster risk reduction 2015–2030. In Proceedings of the 3rd United Nations World Conference on Disaster Risk Reduction (WCDRR), Sendai, Japan, 14–18 March 2015; pp. 14–18. [Google Scholar]
- Zikopoulos, P.; Eaton, C. Understanding Big Data: Analytics for Enterprise Class Hadoop and Streaming Data; McGraw-Hill Osborne Media: New York, NY, USA, 2011. [Google Scholar]
- Zhu, X.X.; Tuia, D.; Mou, L.; Xia, G.S.; Zhang, L.; Xu, F.; Fraundorfer, F. Deep learning in remote sensing: A comprehensive review and list of resources. IEEE Geosci. Remote Sens. Mag. 2017, 5, 8–36. [Google Scholar] [CrossRef] [Green Version]
- Fisher, P.; Comber, A.J.; Wadsworth, R. Land use and land cover: Contradiction or complement. In Re-Presenting GIS; Wiley: New York, NY, USA, 2005; pp. 85–98. [Google Scholar]
- Food and Agriculture Organization of the United Nations. 2019. Available online: http://www.fao.org/faostat (accessed on 29 July 2020).
- Di Gregorio, A. Land Cover Classification System: Classification Concepts and User Manual: LCCS; Food & Agriculture Org.: Rome, Italy, 2005; Volume 2. [Google Scholar]
- Isikdogan, F.; Bovik, A.C.; Passalacqua, P. Surface water mapping by deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 4909–4918. [Google Scholar] [CrossRef]
- Rezaee, M.; Mahdianpari, M.; Zhang, Y.; Salehi, B. Deep convolutional neural network for complex wetland classification using optical remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3030–3039. [Google Scholar] [CrossRef]
- Huang, B.; Zhao, B.; Song, Y. Urban land-use mapping using a deep convolutional neural network with high spatial resolution multispectral remote sensing imagery. Remote Sens. Environ. 2018, 214, 73–86. [Google Scholar] [CrossRef]
- Hu, J.; Mou, L.; Schmitt, A.; Zhu, X.X. FusioNet: A two-stream convolutional neural network for urban scene classification using PolSAR and hyperspectral data. In Proceedings of the 2017 Joint Urban Remote Sensing Event (JURSE), Dubai, UAE, 6–8 March 2017; pp. 1–4. [Google Scholar]
- Kussul, N.; Lavreniuk, M.; Skakun, S.; Shelestov, A. Deep learning classification of land cover and crop types using remote sensing data. IEEE Geosci. Remote Sens. Lett. 2017, 14, 778–782. [Google Scholar] [CrossRef]
- Awad, M.; Jomaa, I.; Arab, F. Improved capability in stone pine forest mapping and management in Lebanon using hyperspectral CHRIS-Proba data relative to Landsat ETM+. Photogramm. Eng. Remote Sens. 2014, 80, 725–731. [Google Scholar] [CrossRef]
- Marschner, F. Major Land Uses in the United States (Map Scale 1:5,000,000); USDA Agricultural Research Service: Washington, DC, USA, 1950; Volume 252.
- Anderson, J.R. A Land Use and Land Cover Classification System for Use with Remote Sensor Data; US Government Printing Office: Washington, DC, USA, 1976; Volume 964.
- Cowardin, L.M.; Carter, V.; Golet, F.C.; LaRoe, E.T. Classification of Wetlands and Deepwater Habitats of the United States; Technical Report; US Department of the Interior, US Fish and Wildlife Service: Washington, DC, USA, 1979.
- Pohl, C.; Van Genderen, J.L. Review article multisensor image fusion in remote sensing: Concepts, methods and applications. Int. J. Remote Sens. 1998, 19, 823–854. [Google Scholar] [CrossRef] [Green Version]
- Congalton, R.G. A review of assessing the accuracy of classifications of remotely sensed data. Remote Sens. Environ. 1991, 37, 35–46. [Google Scholar] [CrossRef]
- Singh, A. Review article digital change detection techniques using remotely-sensed data. Int. J. Remote Sens. 1989, 10, 989–1003. [Google Scholar] [CrossRef] [Green Version]
- Kasischke, E.S.; Melack, J.M.; Dobson, M.C. The use of imaging radars for ecological applications—A review. Remote Sens. Environ. 1997, 59, 141–156. [Google Scholar] [CrossRef]
- Li, S.; Kang, X.; Fang, L.; Hu, J.; Yin, H. Pixel-level image fusion: A survey of the state of the art. Inf. Fusion 2017, 33, 100–112. [Google Scholar] [CrossRef]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Paoletti, M.; Haut, J.; Plaza, J.; Plaza, A. Deep learning classifiers for hyperspectral imaging: A review. ISPRS J. Photogramm. Remote Sens. 2019, 158, 279–317. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep learning for hyperspectral image classification: An overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Goetz, A.F. Three decades of hyperspectral remote sensing of the Earth: A personal view. Remote Sens. Environ. 2009, 113, S5–S16. [Google Scholar] [CrossRef]
- Ghamisi, P.; Maggiori, E.; Li, S.; Souza, R.; Tarablaka, Y.; Moser, G.; De Giorgi, A.; Fang, L.; Chen, Y.; Chi, M.; et al. New frontiers in spectral-spatial hyperspectral image classification: The latest advances based on mathematical morphology, Markov random fields, segmentation, sparse representation, and deep learning. IEEE Geosci. Remote Sens. Mag. 2018, 6, 10–43. [Google Scholar] [CrossRef]
- Imani, M.; Ghassemian, H. An overview on spectral and spatial information fusion for hyperspectral image classification: Current trends and challenges. Inf. Fusion 2020, 59, 59–83. [Google Scholar] [CrossRef]
- USGS. USGS Earth Explorer. 2019. Available online: https://earthexplorer.usgs.gov/ (accessed on 29 July 2020).
- USGS. USGS Global Visualization Viewer. 2019. Available online: https://glovis.usgs.gov/app (accessed on 29 July 2020).
- NASA. NASA Earth Observation—NEO. 2019. Available online: https://neo.sci.gsfc.nasa.gov/ (accessed on 29 July 2020).
- ESA. The Copernicus Open Access Hub. 2019. Available online: https://scihub.copernicus.eu/dhus/ (accessed on 29 July 2020).
- NASA. NASA Earth Data Search. 2019. Available online: https://search.earthdata.nasa.gov/search (accessed on 29 July 2020).
- NOAA. NOAA Data Access. 2019. Available online: https://www.ncdc.noaa.gov/data-access (accessed on 29 July 2020).
- NOAA. NOAA Digital Coast. 2019. Available online: https://coast.noaa.gov/digitalcoast/ (accessed on 29 July 2020).
- IPUMS. IPUMS Terra Integrates Population and Environmental Data. 2018. Available online: https://terra.ipums.org/ (accessed on 29 July 2020).
- Penatti, O.A.; Nogueira, K.; Dos Santos, J.A. Do deep features generalize from everyday objects to remote sensing and aerial scenes domains? In Proceedings of the IEEE conference on computer vision and pattern recognition workshops (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 44–51. [Google Scholar]
- Demir, I.; Koperski, K.; Lindenbaum, D.; Pang, G.; Huang, J.; Basu, S.; Hughes, F.; Tuia, D.; Raska, R. Deepglobe 2018: A challenge to parse the earth through satellite images. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 172–17209. [Google Scholar]
- Basu, S.; Ganguly, S.; Mukhopadhyay, S.; DiBiano, R.; Karki, M.; Nemani, R. Deepsat: A learning framework for satellite imagery. In Proceedings of the 23rd SIGSPATIAL International Conference on Advances in Geographic Information Systems, Washington, DC, USA, 3–6 November 2015; p. 37. [Google Scholar]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- GIC. Hyperspectral Remote Sensing Scenes. 2020. Available online: http://www.ehu.eus/ccwintco/index.php/Hyperspectral_Remote_Sensing_Scenes (accessed on 29 July 2020).
- Geoscience. 2013 IEEE GRSS Data Fusion Contest; GRSS: Piscataway, NJ, USA, 2013. [Google Scholar]
- Codalab. DeepGlobe Land Cover Classification Challenge; DeepGlobe: Salt Lake City, UT, USA, 2018. [Google Scholar]
- Basu, S. SAT-4 and SAT-6 Airborne Datasets; Louisiana State University: Baton Rouge, LA, USA, 2015. [Google Scholar]
- University of California, Merced. UC Merced Land Use Dataset; University of California, Merced: Merced, CA, USA, 2010. [Google Scholar]
- Patrero. Brazilian Coffee Scenes Dataset; Patrero: San Francisco, CA, USA, 2015. [Google Scholar]
- System(EOS). Crop Monitoring. 2020. Available online: https://eos.com/eos-crop-monitoring/ (accessed on 29 July 2020).
- Awad, M.M.; Alawar, B.; Jbeily, R. A new crop spectral signatures database interactive tool (CSSIT). Data 2019, 4, 77. [Google Scholar] [CrossRef] [Green Version]
- Global Forest Watch. Developer Tools. 2020. Available online: https://developers.globalforestwatch.org/ (accessed on 29 July 2020).
- SERVIR-Mekong. Surface Water Mapping Tool. 2020. Available online: http://surface-water-servir.adpc.net/ (accessed on 29 July 2020).
- Wolpert, D.H. The lack of a priori distinctions between learning algorithms. Neural Comput. 1996, 8, 1341–1390. [Google Scholar] [CrossRef]
- Wolpert, D.H.; Macready, W.G. Coevolutionary free lunches. IEEE Trans. Evol. Comput. 2005, 9, 721–735. [Google Scholar] [CrossRef]
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning requires rethinking generalization. arXiv 2016, arXiv:1611.03530. [Google Scholar]
- Kawaguchi, K.; Kaelbling, L.P.; Bengio, Y. Generalization in deep learning. arXiv 2017, arXiv:1710.05468. [Google Scholar]
- Saxe, A.M.; Bansal, Y.; Dapello, J.; Advani, M.; Kolchinsky, A.; Tracey, B.D.; Cox, D.D. On the information bottleneck theory of deep learning. J. Stat. Mech. Theory Exp. 2019, 2019, 124020. [Google Scholar] [CrossRef]
- Dinh, L.; Pascanu, R.; Bengio, S.; Bengio, Y. Sharp minima can generalize for deep nets. In Proceedings of the 34th International Conference on Machine Learning (ICML), Sydney, Australia, 10–15 July 2017; pp. 1019–1028. [Google Scholar]
- Zou, Q.; Ni, L.; Zhang, T.; Wang, Q. Deep learning based feature selection for remote sensing scene classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2321–2325. [Google Scholar] [CrossRef]
- Han, W.; Feng, R.; Wang, L.; Cheng, Y. A semi-supervised generative framework with deep learning features for high-resolution remote sensing image scene classification. ISPRS J. Photogramm. Remote Sens. 2018, 145, 23–43. [Google Scholar] [CrossRef]
- IBM. Removing the Hunch in Data Science with AI-Based Automated Feature Engineering. 2017. Available online: https://www.ibm.com/blogs/research/2017/08/ai-based-automated-feature-engineering/ (accessed on 29 July 2020).
- Zhang, L.; Zhang, L.; Tao, D.; Huang, X. Tensor discriminative locality alignment for hyperspectral image spectral–spatial feature extraction. IEEE Trans. Geosci. Remote Sens. 2012, 51, 242–256. [Google Scholar] [CrossRef]
- Hughes, G. On the mean accuracy of statistical pattern recognizers. IEEE Trans. Inf. Theory 1968, 14, 55–63. [Google Scholar] [CrossRef] [Green Version]
- Rasti, B.; Hong, D.; Hang, R.; Ghamisi, P.; Kang, X.; Chanussot, J.; Benediktsson, J.A. Feature extraction for hyperspectral imagery: The evolution from shallow to deep. arXiv 2020, arXiv:2003.02822. [Google Scholar]
- Yu, S.; Jia, S.; Xu, C. Convolutional neural networks for hyperspectral image classification. Neurocomputing 2017, 219, 88–98. [Google Scholar] [CrossRef]
- Sun, W.; Du, Q. Graph-regularized fast and robust principal component analysis for hyperspectral band selection. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3185–3195. [Google Scholar] [CrossRef]
- Zabalza, J.; Ren, J.; Ren, J.; Liu, Z.; Marshall, S. Structured covariance principal component analysis for real-time onsite feature extraction and dimensionality reduction in hyperspectral imaging. Appl. Opt. 2014, 53, 4440–4449. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Chen, S.; Zhang, D. Semisupervised dimensionality reduction with pairwise constraints for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2010, 8, 369–373. [Google Scholar] [CrossRef]
- Archibald, R.; Fann, G. Feature selection and classification of hyperspectral images with support vector machines. IEEE Geosci. Remote Sens. Lett. 2007, 4, 674–677. [Google Scholar] [CrossRef]
- Kuo, B.C.; Ho, H.H.; Li, C.H.; Hung, C.C.; Taur, J.S. A kernel-based feature selection method for SVM with RBF kernel for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 7, 317–326. [Google Scholar]
- Zhong, Z.; Li, J.; Luo, Z.; Chapman, M. Spectral–spatial residual network for hyperspectral image classification: A 3-D deep learning framework. IEEE Trans. Geosci. Remote Sens. 2017, 56, 847–858. [Google Scholar] [CrossRef]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Unsupervised spectral–spatial feature learning via deep residual Conv–Deconv network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 56, 391–406. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Semantic segmentation of earth observation data using multimodal and multi-scale deep networks. In Proceedings of the Asian Conference on Computer Vision (ACCV), Taipei, Taiwan, 20–24 November 2016; pp. 180–196. [Google Scholar]
- Tao, C.; Pan, H.; Li, Y.; Zou, Z. Unsupervised spectral–spatial feature learning with stacked sparse autoencoder for hyperspectral imagery classification. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2438–2442. [Google Scholar]
- Ma, X.; Wang, H.; Geng, J. Spectral–spatial classification of hyperspectral image based on deep auto-encoder. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4073–4085. [Google Scholar] [CrossRef]
- Zabalza, J.; Ren, J.; Zheng, J.; Zhao, H.; Qing, C.; Yang, Z.; Du, P.; Marshall, S. Novel segmented stacked autoencoder for effective dimensionality reduction and feature extraction in hyperspectral imaging. Neurocomputing 2016, 185, 1–10. [Google Scholar] [CrossRef] [Green Version]
- Lunga, D.; Prasad, S.; Crawford, M.M.; Ersoy, O. Manifold-learning-based feature extraction for classification of hyperspectral data: A review of advances in manifold learning. IEEE Signal Process. Mag. 2013, 31, 55–66. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S. Spectral–spatial feature extraction for hyperspectral image classification: A dimension reduction and deep learning approach. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4544–4554. [Google Scholar] [CrossRef]
- Shi, Q.; Zhang, L.; Du, B. Semisupervised discriminative locally enhanced alignment for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2013, 51, 4800–4815. [Google Scholar] [CrossRef]
- Li, W.; Prasad, S.; Fowler, J.E.; Bruce, L.M. Locality-preserving dimensionality reduction and classification for hyperspectral image analysis. IEEE Trans. Geosci. Remote Sens. 2011, 50, 1185–1198. [Google Scholar] [CrossRef] [Green Version]
- Prasad, S.; Bruce, L.M. Limitations of principal components analysis for hyperspectral target recognition. IEEE Geosci. Remote Sens. Lett. 2008, 5, 625–629. [Google Scholar] [CrossRef]
- Wang, Q.; Meng, Z.; Li, X. Locality adaptive discriminant analysis for spectral–spatial classification of hyperspectral images. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2077–2081. [Google Scholar] [CrossRef]
- Zhou, Y.; Peng, J.; Chen, C.P. Dimension reduction using spatial and spectral regularized local discriminant embedding for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2014, 53, 1082–1095. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Colditz, R. An evaluation of different training sample allocation schemes for discrete and continuous land cover classification using decision tree-based algorithms. Remote Sens. 2015, 7, 9655–9681. [Google Scholar] [CrossRef] [Green Version]
- Stefanski, J.; Mack, B.; Waske, B. Optimization of object-based image analysis with random forests for land cover mapping. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 2492–2504. [Google Scholar] [CrossRef]
- Belgiu, M.; Drăguţ, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Cawley, G.C.; Talbot, N.L. Preventing over-fitting during model selection via Bayesian regularisation of the hyper-parameters. J. Mach. Learn. Res. 2007, 8, 841–861. [Google Scholar]
- Cawley, G.C.; Talbot, N.L. On over-fitting in model selection and subsequent selection bias in performance evaluation. J. Mach. Learn. Res. 2010, 11, 2079–2107. [Google Scholar]
- Melgani, F.; Bruzzone, L. Classification of hyperspectral remote sensing images with support vector machines. IEEE Trans. Geosci. Remote Sens. 2004, 42, 1778–1790. [Google Scholar] [CrossRef] [Green Version]
- Fauvel, M.; Chanussot, J.; Benediktsson, J.A.; Sveinsson, J.R. Spectral and spatial classification of hyperspectral data using SVMs and morphological profiles. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium (IGARSS2007), Barcelona, Spain, 23–27 July 2007; pp. 4834–4837. [Google Scholar]
- Mitra, P.; Shankar, B.U.; Pal, S.K. Segmentation of multispectral remote sensing images using active support vector machines. Pattern Recognit. Lett. 2004, 25, 1067–1074. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Li, Y.; Zhang, Y.; Shen, Q. Spectral-spatial classification of hyperspectral imagery using a dual-channel convolutional neural network. Remote Sens. Lett. 2017, 8, 438–447. [Google Scholar] [CrossRef] [Green Version]
- Mou, L.; Ghamisi, P.; Zhu, X.X. Fully conv-deconv network for unsupervised spectral-spatial feature extraction of hyperspectral imagery via residual learning. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 5181–5184. [Google Scholar]
- Hu, W.; Huang, Y.; Wei, L.; Zhang, F.; Li, H. Deep convolutional neural networks for hyperspectral image classification. J. Sens. 2015, 2015, 12. [Google Scholar] [CrossRef] [Green Version]
- Guidici, D.; Clark, M. One-Dimensional convolutional neural network land-cover classification of multi-seasonal hyperspectral imagery in the San Francisco Bay Area, California. Remote Sens. 2017, 9, 629. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.; Prasad, S. Convolutional recurrent neural networks for hyperspectral data classification. Remote Sens. 2017, 9, 298. [Google Scholar] [CrossRef] [Green Version]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative adversarial networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems (NIPS); ACM: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Jia, Y.; Shelhamer, E.; Donahue, J.; Karayev, S.; Long, J.; Girshick, R.; Guadarrama, S.; Darrell, T. Caffe: Convolutional architecture for fast feature embedding. In Proceedings of the 22nd ACM international conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 675–678. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Nogueira, K.; Penatti, O.A.; dos Santos, J.A. Towards better exploiting convolutional neural networks for remote sensing scene classification. Pattern Recognit. 2017, 61, 539–556. [Google Scholar] [CrossRef] [Green Version]
- Ji, S.; Zhang, C.; Xu, A.; Shi, Y.; Duan, Y. 3D convolutional neural networks for crop classification with multi-temporal remote sensing images. Remote Sens. 2018, 10, 75. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, H.; Shen, Q. Spectral–spatial classification of hyperspectral imagery with 3D convolutional neural network. Remote Sens. 2017, 9, 67. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Jiang, H.; Li, C.; Jia, X.; Ghamisi, P. Deep feature extraction and classification of hyperspectral images based on convolutional neural networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 6232–6251. [Google Scholar] [CrossRef] [Green Version]
- Sun, H.; Zheng, X.; Lu, X.; Wu, S. Spectral-Spatial Attention Network for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote Sens. 2019. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Hu, Y.; Zhang, Q.; Zhang, Y.; Yan, H. A Deep Convolution Neural Network Method for Land Cover Mapping: A Case Study of Qinhuangdao, China. Remote Sens. 2018, 10, 2053. [Google Scholar] [CrossRef] [Green Version]
- Castelluccio, M.; Poggi, G.; Sansone, C.; Verdoliva, L. Land use classification in remote sensing images by convolutional neural networks. arXiv 2015, arXiv:1508.00092. [Google Scholar]
- Scott, G.J.; England, M.R.; Starms, W.A.; Marcum, R.A.; Davis, C.H. Training deep convolutional neural networks for land–cover classification of high-resolution imagery. IEEE Geosci. Remote Sens. Lett. 2017, 14, 549–553. [Google Scholar] [CrossRef]
- Cheng, G.; Han, J.; Lu, X. Remote sensing image scene classification: Benchmark and state of the art. Proc. IEEE 2017, 105, 1865–1883. [Google Scholar] [CrossRef] [Green Version]
- Helber, P.; Bischke, B.; Dengel, A.; Borth, D. Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019. [Google Scholar] [CrossRef] [Green Version]
- Lee, H.; Kwon, H. Going deeper with contextual CNN for hyperspectral image classification. IEEE Trans. Image Process. 2017, 26, 4843–4855. [Google Scholar] [CrossRef] [Green Version]
- Mahdianpari, M.; Salehi, B.; Rezaee, M.; Mohammadimanesh, F.; Zhang, Y. Very deep convolutional neural networks for complex land cover mapping using multispectral remote sensing imagery. Remote Sens. 2018, 10, 1119. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Liu, S.; Chanussot, J.; Li, X. Scene classification with recurrent attention of VHR remote sensing images. IEEE Trans. Geosci. Remote Sens. 2018, 57, 1155–1167. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical image computing and computer-assisted intervention (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Xu, Y.; Wu, L.; Xie, Z.; Chen, Z. Building extraction in very high resolution remote sensing imagery using deep learning and guided filters. Remote Sens. 2018, 10, 144. [Google Scholar] [CrossRef] [Green Version]
- Hamaguchi, R.; Fujita, A.; Nemoto, K.; Imaizumi, T.; Hikosaka, S. Effective use of dilated convolutions for segmenting small object instances in remote sensing imagery. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1442–1450. [Google Scholar]
- Zhang, Z.; Liu, Q.; Wang, Y. Road extraction by deep residual u-net. IEEE Geosci. Remote Sens. Lett. 2018, 15, 749–753. [Google Scholar] [CrossRef] [Green Version]
- Shi, Q.; Liu, X.; Li, X. Road detection from remote sensing images by generative adversarial networks. IEEE Access 2017, 6, 25486–25494. [Google Scholar] [CrossRef]
- Mohajerani, S.; Krammer, T.A.; Saeedi, P. Cloud Detection Algorithm for Remote Sensing Images Using Fully Convolutional Neural Networks. arXiv 2018, arXiv:1810.05782. [Google Scholar]
- Zhang, Z.; Iwasaki, A.; Xu, G.; Song, J. Cloud detection on small satellites based on lightweight U-net and image compression. J. Appl. Remote Sens. 2019, 13, 026502. [Google Scholar] [CrossRef]
- Li, R.; Liu, W.; Yang, L.; Sun, S.; Hu, W.; Zhang, F.; Li, W. DeepUNet: A deep fully convolutional network for pixel-level sea-land segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 3954–3962. [Google Scholar] [CrossRef] [Green Version]
- Papadomanolaki, M.; Vakalopoulou, M.; Karantzalos, K. A Novel Object-Based Deep Learning Framework for Semantic Segmentation of Very High-Resolution Remote Sensing Data: Comparison with Convolutional and Fully Convolutional Networks. Remote Sens. 2019, 11, 684. [Google Scholar] [CrossRef] [Green Version]
- Rakhlin, A.; Davydow, A.; Nikolenko, S.I. Land Cover Classification From Satellite Imagery With U-Net and Lovasz-Softmax Loss. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 262–266. [Google Scholar]
- Shrestha, A.; Mahmood, A. Review of deep learning algorithms and architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Liu, P.; Choo, K.K.R.; Wang, L.; Huang, F. SVM or deep learning? A comparative study on remote sensing image classification. Soft Comput. 2017, 21, 7053–7065. [Google Scholar] [CrossRef]
- Yu, X.; Wu, X.; Luo, C.; Ren, P. Deep learning in remote sensing scene classification: A data augmentation enhanced convolutional neural network framework. GIScience Remote Sens. 2017, 54, 741–758. [Google Scholar] [CrossRef] [Green Version]
- Triguero, I.; García, S.; Herrera, F. Self-labeled techniques for semi-supervised learning: Taxonomy, software and empirical study. Knowl. Inf. Syst. 2015, 42, 245–284. [Google Scholar] [CrossRef]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Hershey, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Marmanis, D.; Datcu, M.; Esch, T.; Stilla, U. Deep learning earth observation classification using ImageNet pretrained networks. IEEE Geosci. Remote Sens. Lett. 2015, 13, 105–109. [Google Scholar] [CrossRef] [Green Version]
- Zhou, W.; Newsam, S.; Li, C.; Shao, Z. Learning low dimensional convolutional neural networks for high-resolution remote sensing image retrieval. Remote Sens. 2017, 9, 489. [Google Scholar] [CrossRef] [Green Version]
- Chen, Z.; Zhang, T.; Ouyang, C. End-to-end airplane detection using transfer learning in remote sensing images. Remote Sens. 2018, 10, 139. [Google Scholar] [CrossRef] [Green Version]
- Hong, D.; Yokoya, N.; Xia, G.S.; Chanussot, J.; Zhu, X.X. X-ModalNet: A semi-supervised deep cross-modal network for classification of remote sensing data. ISPRS J. Photogramm. Remote Sens. 2020, 167, 12–23. [Google Scholar] [CrossRef]
- Nalepa, J.; Myller, M.; Imai, Y.; Honda, K.i.; Takeda, T.; Antoniak, M. Unsupervised Segmentation of Hyperspectral Images Using 3D Convolutional Autoencoders. arXiv 2019, arXiv:1907.08870. [Google Scholar]
- Guo, X.; Liu, X.; Zhu, E.; Yin, J. Deep clustering with convolutional autoencoders. In Proceedings of the International Conference on Neural Information Processing (ICONIP), Guangzhou, China, 14–18 November 2017; pp. 373–382. [Google Scholar]
- Laso Bayas, J.; See, L.; Fritz, S.; Sturn, T.; Perger, C.; Dürauer, M.; Karner, M.; Moorthy, I.; Schepaschenko, D.; Domian, D.; et al. Crowdsourcing in-situ data on land cover and land use using gamification and mobile technology. Remote Sens. 2016, 8, 905. [Google Scholar] [CrossRef] [Green Version]
- Fritz, S.; Fonte, C.; See, L. The role of citizen science in earth observation. Remote Sens. 2017, 9, 357. [Google Scholar] [CrossRef] [Green Version]
- Basiri, A.; Haklay, M.; Foody, G.; Mooney, P. Crowdsourced geospatial data quality: Challenges and future directions. Int. J. Geogr. Inf. Sci. 2019, 33, 1588–1593. [Google Scholar] [CrossRef] [Green Version]
- Li, G.; Yu, Y. Visual saliency based on multiscale deep features. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 5455–5463. [Google Scholar]
- Zhao, W.; Du, S. Learning multiscale and deep representations for classifying remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2016, 113, 155–165. [Google Scholar] [CrossRef]
- Zhang, J. Multi-source remote sensing data fusion: Status and trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar] [CrossRef] [Green Version]
- Huang, W.; Xiao, L.; Wei, Z.; Liu, H.; Tang, S. A new pan-sharpening method with deep neural networks. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1037–1041. [Google Scholar] [CrossRef]
- Yuan, Q.; Wei, Y.; Meng, X.; Shen, H.; Zhang, L. A multiscale and multidepth convolutional neural network for remote sensing imagery pan-sharpening. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 978–989. [Google Scholar] [CrossRef] [Green Version]
- Wei, Y.; Yuan, Q.; Shen, H.; Zhang, L. Boosting the accuracy of multispectral image pansharpening by learning a deep residual network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1795–1799. [Google Scholar] [CrossRef] [Green Version]
- Vitale, S.; Scarpa, G. A detail-preserving cross-scale learning strategy for CNN-based pansharpening. Remote Sens. 2020, 12, 348. [Google Scholar] [CrossRef] [Green Version]
- Ma, X.; Hong, Y.; Song, Y. Super resolution land cover mapping of hyperspectral images using the deep image prior-based approach. Int. J. Remote Sens. 2020, 41, 2818–2834. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image super-resolution using deep convolutional networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Kim, J.; Kwon Lee, J.; Mu Lee, K. Accurate image super-resolution using very deep convolutional networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Las Vegas, NV, USA, 27 June–30 June 2016; pp. 1646–1654. [Google Scholar]
- Lei, S.; Shi, Z.; Zou, Z. Super-resolution for remote sensing images via local–global combined network. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1243–1247. [Google Scholar] [CrossRef]
- Liebel, L.; Körner, M. Single-image super resolution for multispectral remote sensing data using convolutional neural networks. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 883–890. [Google Scholar] [CrossRef]
- Mei, S.; Yuan, X.; Ji, J.; Zhang, Y.; Wan, S.; Du, Q. Hyperspectral image spatial super-resolution via 3D full convolutional neural network. Remote Sens. 2017, 9, 1139. [Google Scholar] [CrossRef] [Green Version]
- Scarpa, G.; Gargiulo, M.; Mazza, A.; Gaetano, R. A CNN-based fusion method for feature extraction from Sentinel data. Remote Sens. 2018, 10, 236. [Google Scholar] [CrossRef] [Green Version]
- Lanaras, C.; Bioucas-Dias, J.; Galliani, S.; Baltsavias, E.; Schindler, K. Super-resolution of Sentinel-2 images: Learning a globally applicable deep neural network. ISPRS J. Photogramm. Remote Sens. 2018, 146, 305–319. [Google Scholar] [CrossRef] [Green Version]
- Xu, X.; Li, W.; Ran, Q.; Du, Q.; Gao, L.; Zhang, B. Multisource remote sensing data classification based on convolutional neural network. IEEE Trans. Geosci. Remote Sens. 2017, 56, 937–949. [Google Scholar] [CrossRef]
- Chen, Y.; Li, C.; Ghamisi, P.; Jia, X.; Gu, Y. Deep fusion of remote sensing data for accurate classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1253–1257. [Google Scholar] [CrossRef]
- Piramanayagam, S.; Saber, E.; Schwartzkopf, W.; Koehler, F. Supervised classification of multisensor remotely sensed images using a deep learning framework. Remote Sens. 2018, 10, 1429. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Joint learning from earth observation and OpenStreetMap data to get faster better semantic maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 67–75. [Google Scholar]
- Gaetano, R.; Ienco, D.; Ose, K.; Cresson, R. A two-branch CNN architecture for land cover classification of PAN and MS imagery. Remote Sens. 2018, 10, 1746. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Beyond RGB: Very high resolution urban remote sensing with multimodal deep networks. ISPRS J. Photogramm. Remote Sens. 2018, 140, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Rudner, T.G.; Rußwurm, M.; Fil, J.; Pelich, R.; Bischke, B.; Kopackova, V.; Bilinski, P. Multi3Net: Segmenting Flooded Buildings via Fusion of Multiresolution, Multisensor, and Multitemporal Satellite Imagery. arXiv 2018, arXiv:1812.01756. [Google Scholar] [CrossRef]
- Zhu, X.; Cai, F.; Tian, J.; Williams, T. Spatiotemporal fusion of multisource remote sensing data: Literature survey, taxonomy, principles, applications, and future directions. Remote Sens. 2018, 10, 527. [Google Scholar]
- Zhong, Y.; Li, W.; Wang, X.; Jin, S.; Zhang, L. Satellite-ground integrated destriping network: A new perspective for EO-1 Hyperion and Chinese hyperspectral satellite datasets. Remote Sens. Environ. 2020, 237, 111416. [Google Scholar] [CrossRef]
- Xing, C.; Ma, L.; Yang, X. Stacked denoise autoencoder based feature extraction and classification for hyperspectral images. J. Sensors 2016, 2016, 3632943. [Google Scholar] [CrossRef] [Green Version]
- Xie, W.; Li, Y. Hyperspectral imagery denoising by deep learning with trainable nonlinearity function. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1963–1967. [Google Scholar] [CrossRef]
- Xie, F.; Shi, M.; Shi, Z.; Yin, J.; Zhao, D. Multilevel cloud detection in remote sensing images based on deep learning. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3631–3640. [Google Scholar] [CrossRef]
- Shi, M.; Xie, F.; Zi, Y.; Yin, J. Cloud detection of remote sensing images by deep learning. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 701–704. [Google Scholar]
- Lin, G.; Shen, C.; Van Den Hengel, A.; Reid, I. Efficient piecewise training of deep structured models for semantic segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 3194–3203. [Google Scholar]
- Kampffmeyer, M.; Salberg, A.B.; Jenssen, R. Semantic segmentation of small objects and modeling of uncertainty in urban remote sensing images using deep convolutional neural networks. In Proceedings of the IEEE conference on computer vision and pattern recognition workshops (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 1–9. [Google Scholar]
- Kemker, R.; Salvaggio, C.; Kanan, C. Algorithms for semantic segmentation of multispectral remote sensing imagery using deep learning. ISPRS J. Photogramm. Remote Sens. 2018, 145, 60–77. [Google Scholar] [CrossRef] [Green Version]
- Gavade, A.B.; Rajpurohit, V.S. Sparse-FCM and deep learning for effective classification of land area in multi-spectral satellite images. Evol. Intell. 2020. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Launch Year | Orbital Altitude | Still Active (2019) | Image Type | Pixel Spatial Resolution | |||
|---|---|---|---|---|---|---|---|---|
| SAR | Pan | MSI | HSI | |||||
| EO-1 | 2000 | 705 km | NO | NO | NO | NO | YES | 30 m |
| LANDSAT 7 | 1999 | 705 km | YES | NO | YES | YES | NO | Panchromatic resolution: 15 m |
| MSI resolution: 30 m | ||||||||
| LANDSAT 8 | 2013 | 705 km | YES | NO | YES | YES | NO | Panchromatic resolution: 15 m |
| MSI resolution: 30 m | ||||||||
| QuickBird | 2001 | 482 km | NO | NO | YES | YES | NO | 2.44 m |
| Sentinel 1 * | 2014 | 693 km | YES | YES | NO | NO | NO | Depends on the operational mode. The best |
| resolution id for stripmap mode (5 m) | ||||||||
| Sentinel 2 * | 2015 | 785 km | YES | NO | NO | YES | NO | Depending on the band, 10 m to 60 m |
| RGB-NIR resolution is 10 m | ||||||||
| SPOT-6 | 2012 | 694 km | YES | NO | YES | YES | NO | Panchromatic resolution: 1.5 m |
| MSI resolution: 6 m | ||||||||
| WorldView-2 | 2009 | 770 km | YES | NO | YES | YES | NO | Panchromatic resolution: 0.46 m |
| MSI resolution: 1.84 m | ||||||||
| WorldView-3 | 2014 | 617 km | YES | NO | YES | YES | NO | Panchromatic resolution: 0.31 m |
| MSI resolution: 1.24 m | ||||||||
| PROBA-1 | 2001 | 615 km | YES | NO | NO | NO | YES | Visible bands resolution: 15 m |
| Other bands resolution: 30 m | ||||||||
| Dataset | Source | Mapping type | Labelling | No. Samples | Image Size (pixel) | Resolution (meter/pixel) | No. Bands | No. Classes | Ref |
|---|---|---|---|---|---|---|---|---|---|
| Botswana | EO-1 | Spaceborne | Pixel | 377,856 pixels | 30 | 242 | 14 | ||
| Brazilian coffee scenes | SPOT-5 | Spaceborne | Patch | 50,004 images | 10 | 3 | 3 | [41] | |
| DeepGlobe | (Mix) | Spaceborne | Pixel | 5,836,893,696 pixels | 0.5 | 3 | 7 | [42] | |
| Cuprite | AVIRIS | Airborne | Pixel | 314,368 pixels | 20 | 224 | 25 | ||
| GRSS 2013 | CASI | Airborne | Pixel | 15,029 pixels | 2.5 | 144 | 15 | ||
| Indian pines | AVIRIS | Airborne | Pixel | 9234 pixels | 20 | 224 | 16 | ||
| Kennedy space centre (KCS) | AVIRIS | Airborne | Pixel | 5250 pixels | 18 | 224 | 13 | ||
| Pavia centre | ROSIS | Airborne | Pixel | 103,476 pixels | 1.3 | 102 | 9 | ||
| Salinas | AVIRIS | Airborne | Pixel | 54,129 pixels | 3.7 | 224 | 16 | ||
| SAT-4 | NAIP program | Airborne | Patch | 500,000 images | 1 | 4 | 4 | [43] | |
| SAT-6 | NAIP program | Airborne | Patch | 405,000 images | 1 | 4 | 6 | [43] | |
| UCMerced | OPLS | Airborne | Patch | 2100 images | 0.3 | 4 | 21 | [44] | |
| University of Pavia | ROSIS | Airborne | Pixel | 43,923 pixels | 1.3 | 103 | 9 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vali, A.; Comai, S.; Matteucci, M. Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review. Remote Sens. 2020, 12, 2495. https://doi.org/10.3390/rs12152495
Vali A, Comai S, Matteucci M. Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review. Remote Sensing. 2020; 12(15):2495. https://doi.org/10.3390/rs12152495
Chicago/Turabian StyleVali, Ava, Sara Comai, and Matteo Matteucci. 2020. "Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review" Remote Sensing 12, no. 15: 2495. https://doi.org/10.3390/rs12152495
APA StyleVali, A., Comai, S., & Matteucci, M. (2020). Deep Learning for Land Use and Land Cover Classification Based on Hyperspectral and Multispectral Earth Observation Data: A Review. Remote Sensing, 12(15), 2495. https://doi.org/10.3390/rs12152495