1. Introduction
The Global Observing System for Climate listed snow cover as one of the 50 essential climate variables to be monitored by satellite remote sensing to support the work of the United Nations Framework Convention on Climate Change and the Intergovernmental Panel on Climate Change [
1]. Among the many variables that can be used to characterize the snow cover, the snow cover area is probably the most straightforward to retrieve from space [
2,
3]. Yet, it is one of the most important as it serves as an input to address research questions in various fields including climate science, hydrology and ecology. The snow cover area is also important to support other societal benefit areas, such as water resource management, transportation and winter recreation. A user requirements survey by the Cryoland consortium showed that snow cover area products were ranked as the most important among a list of operationally available remotely sensed snow products by the respondents [
4]. The respondents also emphasized the need for (i) short latency times in the product availability (shorter than 12 h); (ii) large spatial scale to cover entire mountain ranges like the Alps or even the whole of Europe; (iii) high spatial resolution down to 50 m resolution especially for road conditions and avalanche monitoring [
4].
While the operational monitoring of the snow cover area at global scale has been achieved since the 2000s, using wide swath optical sensors, such as MODIS [
2], the low spatial resolution of the products (typically 500 m) usually does not enable to address operational applications such as the above. Many scientific applications would also benefit from higher resolution information on the snow cover area. For instance, high resolution maps of the snow cover area were critical to explain the spatial diversity of plant communities in an alpine grassland [
5,
6]. High-resolution snow cover area is also useful in hydrology to reduce biases in the spatial distribution of the snow water equivalent through data assimilation [
7], in particular in semi-arid mountain regions [
8,
9].
The Sentinel-2 mission, which images the land surface at high resolution with a 5-day revisit time and a global coverage offers the unique opportunity to bridge this gap [
10,
11]. As part of the Copernicus program, the Sentinel-2 mission is planned to run continuously for at least two decades. Based on the above, the Theia land data center in France has supported the deployment of an operational service to generate and distribute at no cost snow cover maps derived from Sentinel-2 (20 m resolution) and Landsat-8 (30 m resolution) [
12]. However, this product only provides a binary description of the snow cover area in the pixel (snow or no-snow, hereafter referred to as SCA). The SCA mapping may be insufficient to characterize the snow distribution in areas where partially snow-covered (mixed) pixels are prevalent [
13,
14,
15]. Using 0.5 m resolution satellite imagery, Selkowitz et al. [
14] quantified the frequency of occurrence of mixed pixels over five dates at two study areas in the western U.S. Their results show that, in the study area with maritime climate, the fraction of mixed pixels at the typical Sentinel-2 resolution (20 m) is below 40%, whereas it can reach 80% in a more continental mountain area. Binarizing pixels in snow or no-snow in areas where mixed pixels are prevalent can introduce an error in the spatial integration of snow cover area—e.g., when the snow cover area is computed over a watershed [
14].
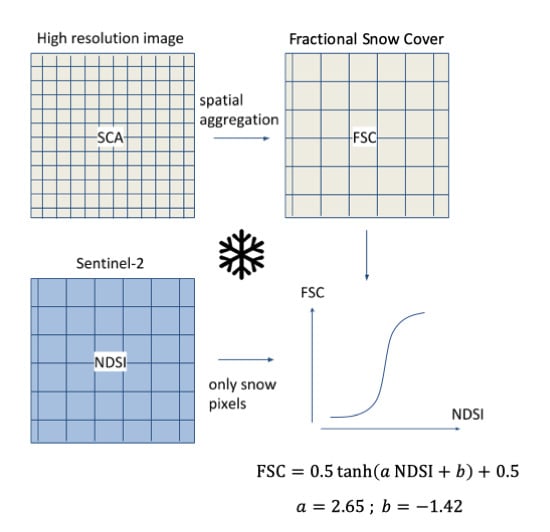
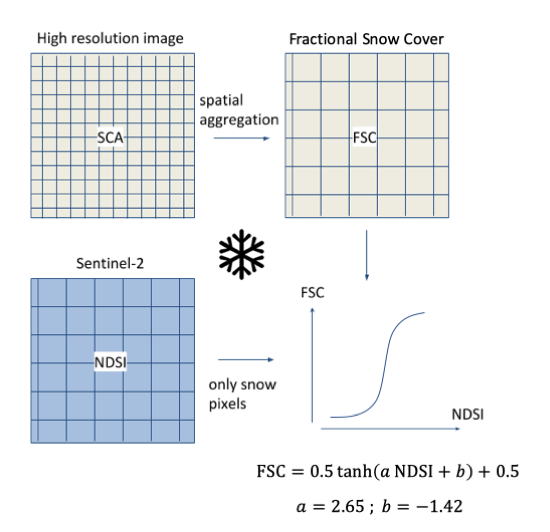
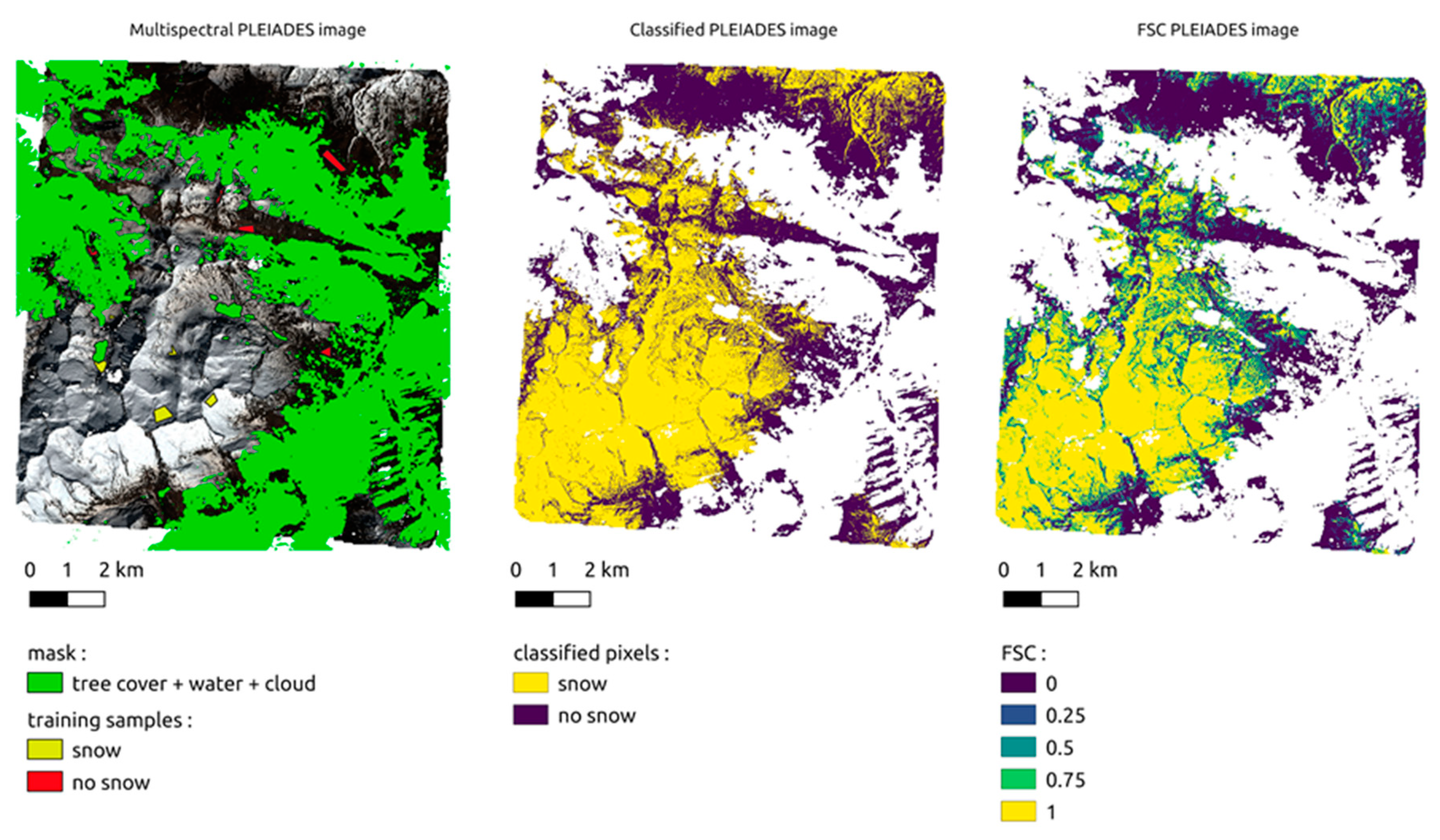
The Fractional Snow Cover (FSC)—i.e., the snow-covered fraction of the pixel area, naturally provides finer information than the binary SCA. However, it does not necessarily mean that it provides more accurate information. The estimation of the FSC from multi-spectral images is challenging due to the confounding effects of the snow, rocks and vegetation surfaces on the spectral signature of pixel reflectance [
16]. Therefore, it is important to evaluate the accuracy of the retrieved FSC by comparing with independent observations to make sure that the gain in precision is worth the additional cost of computing and storage.
The spectral signature of a pixel can be modelled as a linear combination of the spectra of the pure surface materials, or endmembers thought to be present in it [
17,
18,
19]. However, the spectral unmixing approach is challenging to use in an operational context: (i) it amounts to an ill-posed problem which requires a computationally intensive inversion step to estimate the relative abundance of each endmember; (ii) it requires prior knowledge of a collection of endmembers that covers the range of natural surfaces to be observed (geology, vegetation). Such requirements are hardly compatible with those of the users (timeliness, high resolution, large spatial scale).
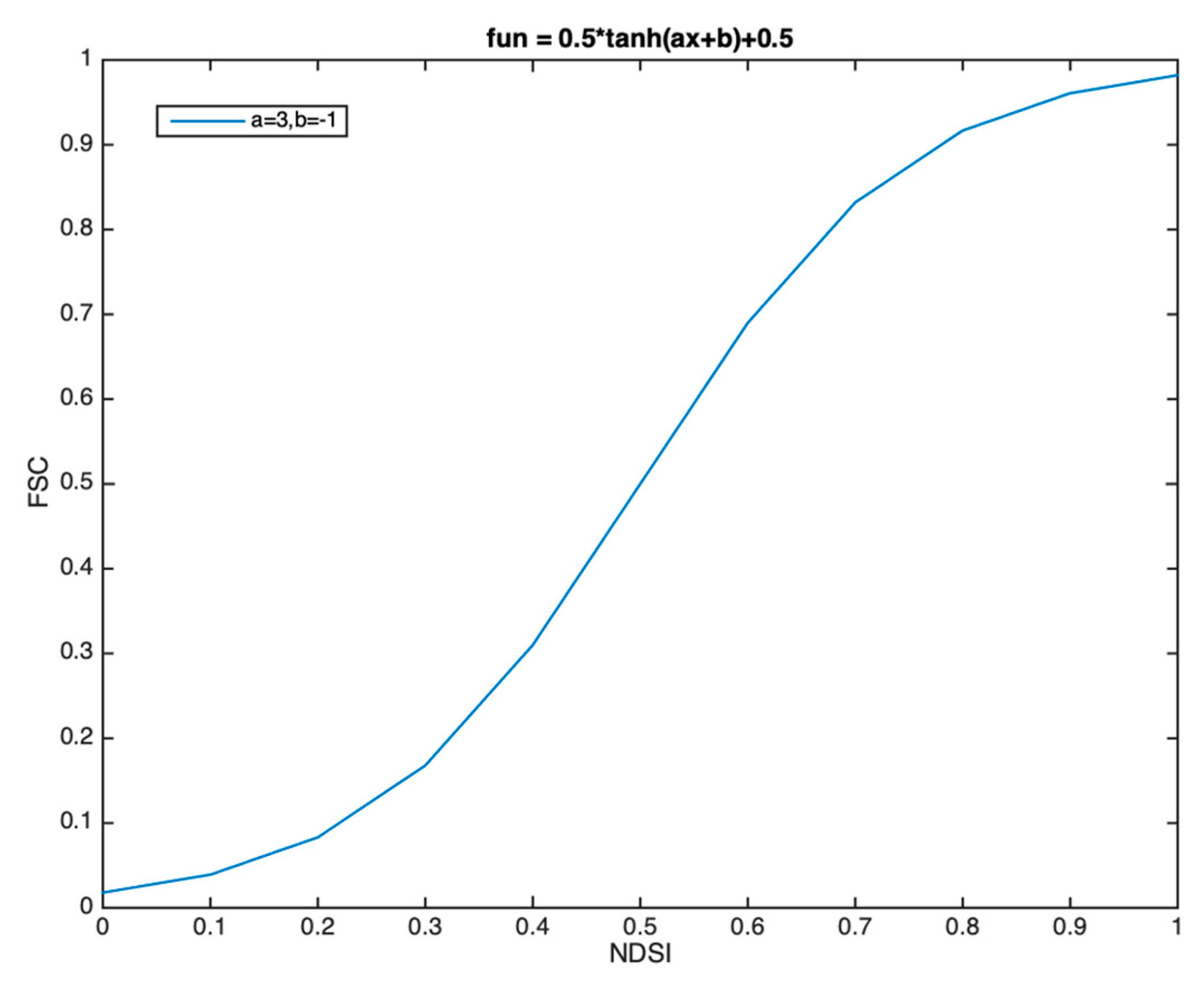
Another option is to use the Normalized Difference Snow Index (NDSI) [
20] as a means to retrieve the FSC through empirical regression. Previous studies involving lower-resolution sensors, such as MODIS and SPOT VEGETATION, have shown positive results using a linear function or a generalized logistic function to estimate the FSC from the NDSI [
21,
22]. A linear function was used by NASA in an operational context to generate the FSC from a collection of five MODIS surface reflectance products (MOD10A1.005 and MYD10A1.005) [
23]. The current operational MODIS snow product does not provide for the FSC anymore but still provides the NDSI as a means to retrieve the FSC using custom equations [
24]. A recent comparison of spectral unmixing and NDSI regression methods to estimate FSC with Sentinel-2 data showed that even an uncalibrated linear regression can yield nearly similar performance to the spectral unmixing [
15]. This result was obtained despite the fact that endmembers for the spectral unmixing algorithm were chosen to match the characteristics of the study area (a high Arctic site). Apart from this study, to our best knowledge, there is no previous evaluation of the NDSI–FSC relationship from Sentinel-2 data.
Here, we aim at evaluating the NDSI regression method to generate FSC in the perspective of an operational service. Given the empirical nature of this approach and the lack of prior knowledge on this relationship, we endeavor to use a large amount of data covering a range of environments and seasons. We wish to evaluate if the error is stable across different sites and seasons.
We built this work upon our previous efforts that led to the implementation of the Theia snow collection. Theia snow products are currently generated by the LIS software version 1.5 [
12]. The LIS algorithm already relies on the NDSI to determine the snow-covered pixels (hereinafter referred to as the LIS–SCA algorithm). The NDSI is computed from level-2A products—i.e., slope corrected surface reflectance images including a cloud and cloud shadow mask. The current configuration uses level-2A products generated by MAJA software. MAJA is an operational level-2A processor, which implements a multitemporal algorithm to estimate the aerosol optical thickness and make an accurate classification of cloud pixels [
25,
26]. The MAJA–LIS workflow was evaluated using in situ and remote sensing data [
12]. The results showed that the snow cover area was accurately detected [
12], and that the snow detection was more accurate than the Sen2Cor outputs [
27].
We proceed as follows. First, we calibrate the function
f which associates an FSC value to an NDSI value:
where
f is a continuous, monotonically increasing function. The calibration is done using a set of very high-resolution satellite images, which provide accurate reference snow maps. Then, we evaluate this function in independent sites where we have reference data from various sources.
Section 2 presents the data and methods used to perform such calibration and evaluation. In
Section 3 we describe the results, and then discuss them in
Section 4.
4. Discussion
In both calibration or in evaluation sections, we obtained larger RMSE than previous studies using MODIS data to compute the FSC at coarser resolution for operational production. Salomonson and Appel [
21] reported RMSE ranging between 4% and 10% for test sites over Alaska, Labrador, and Siberia by comparison with Landsat SCA products. These results were obtained with a linear function, which formed the basis of the MOD10A1.005 product algorithm. Using Landsat-8 SCF products, Rittger et al. [
13] obtained an average RMSE of 10% with MODSCAG products. However, Rittger et al. [
13] reported higher RMSE of 23% for MOD101A1.005, and Masson et al. [
19] found larger RMSE for both MODSCAG and MOD10A1.005, ranging between 25–33%.
With Sentinel-2 data and a linear model of the NDSI, Aalstad et al. [
15] obtained an RMSE of 7%, which is much lower than the RMSE obtained in this study. However, this was computed at 100 m resolution, and spatial aggregation from 20 m to 100 m is expected to reduce the error variance (see below). In addition, the model was only tested over a small region of 1.77 km
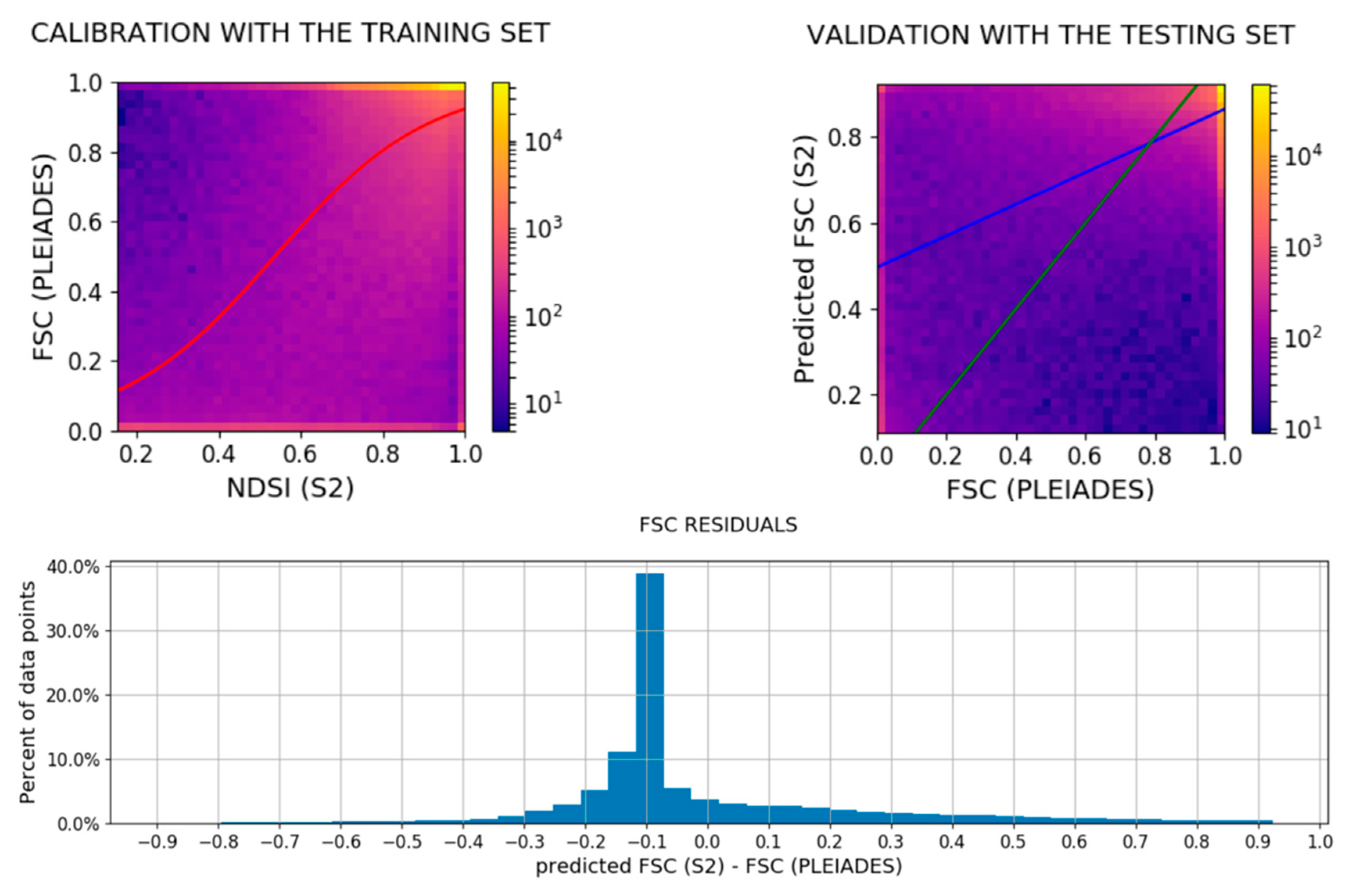
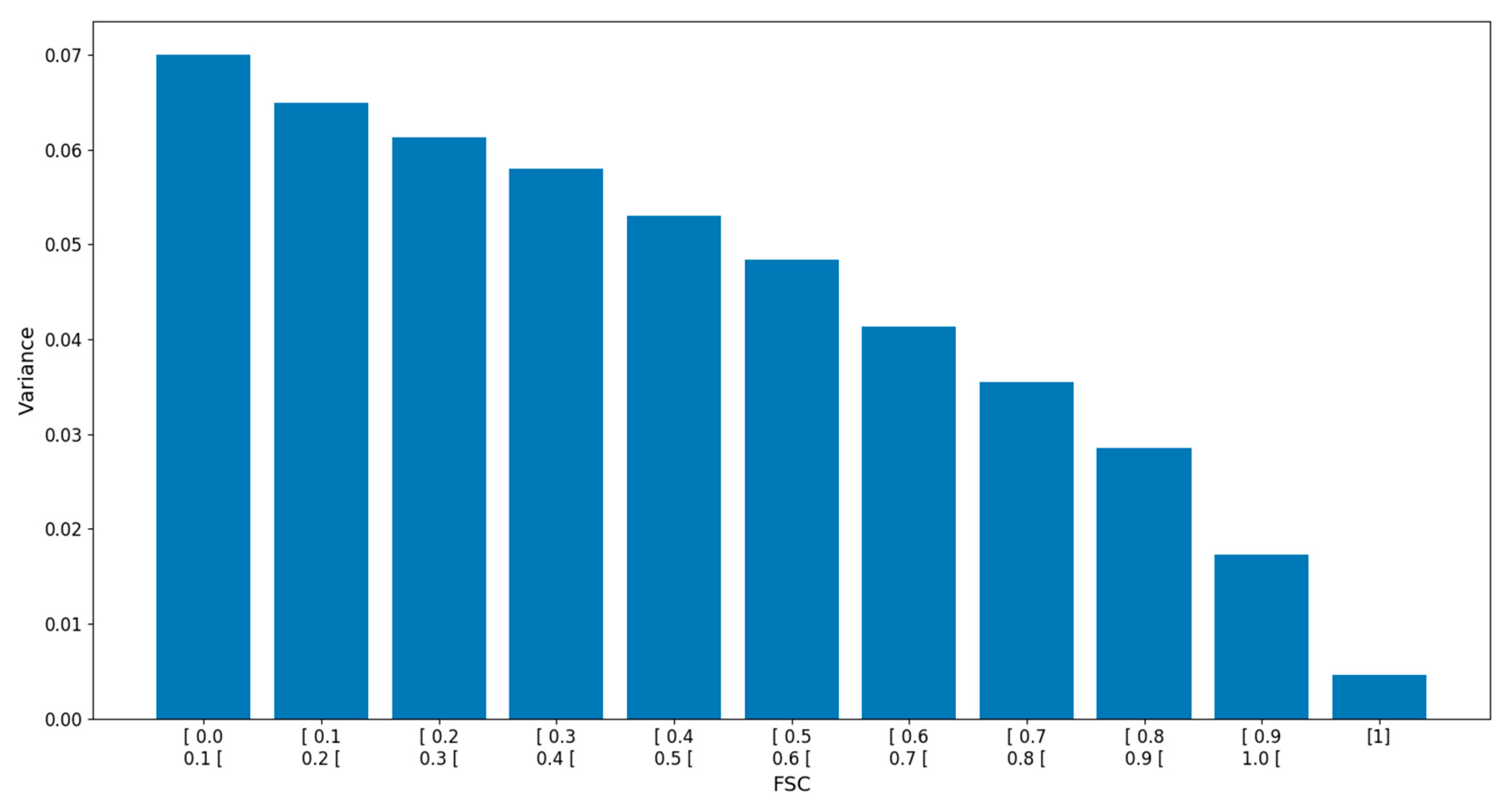
2 with a low topographic variability of (elevation range of 50 m). The same authors found that the error variance of FSC retrieved by spectral unmixing was larger for intermediate FSC and lower for high and low FSC residuals. Here we could not identify a similar behavior, although another form of heteroscedasticity is manifest in the Pléiades-derived FSC residuals from
Section 3.1 (
Figure 11). This dataset suggests that the error has a larger variability for low FSC retrievals.
Neglecting heteroscedasticity and assuming that the FSC residuals follow a gaussian distribution of zero mean and standard deviation σ, we can estimate the probability that a retrieval of SCF = 0 is significantly different than SCF = 1 at the pixel level. With the Normal inverse cumulative distribution function, we can estimate that σ should not exceed 61%, otherwise a retrieval of SCF = 0 would not be significantly different than SCF = 1 at the 5% confidence level. Here, we obtained an FSC model with a standard deviation of 24% in comparison with Pléiades validation data, and the standard deviation of the residuals did not exceed 30% except for the SPOT image of 12 October 2016 (33%). Therefore, the FSC model obtained in this study represents an improvement in accuracy over the binary SCA detection. Considering all datasets for which we could perform a pixel-wise comparison at 20 m resolution in this study, the median standard deviation of the residuals is 23%. Taking this value as the true standard deviation of the error distribution following a gaussian distribution, we can conclude that the confidence interval of an FSC retrieval is ±38% at the 95% confidence level.
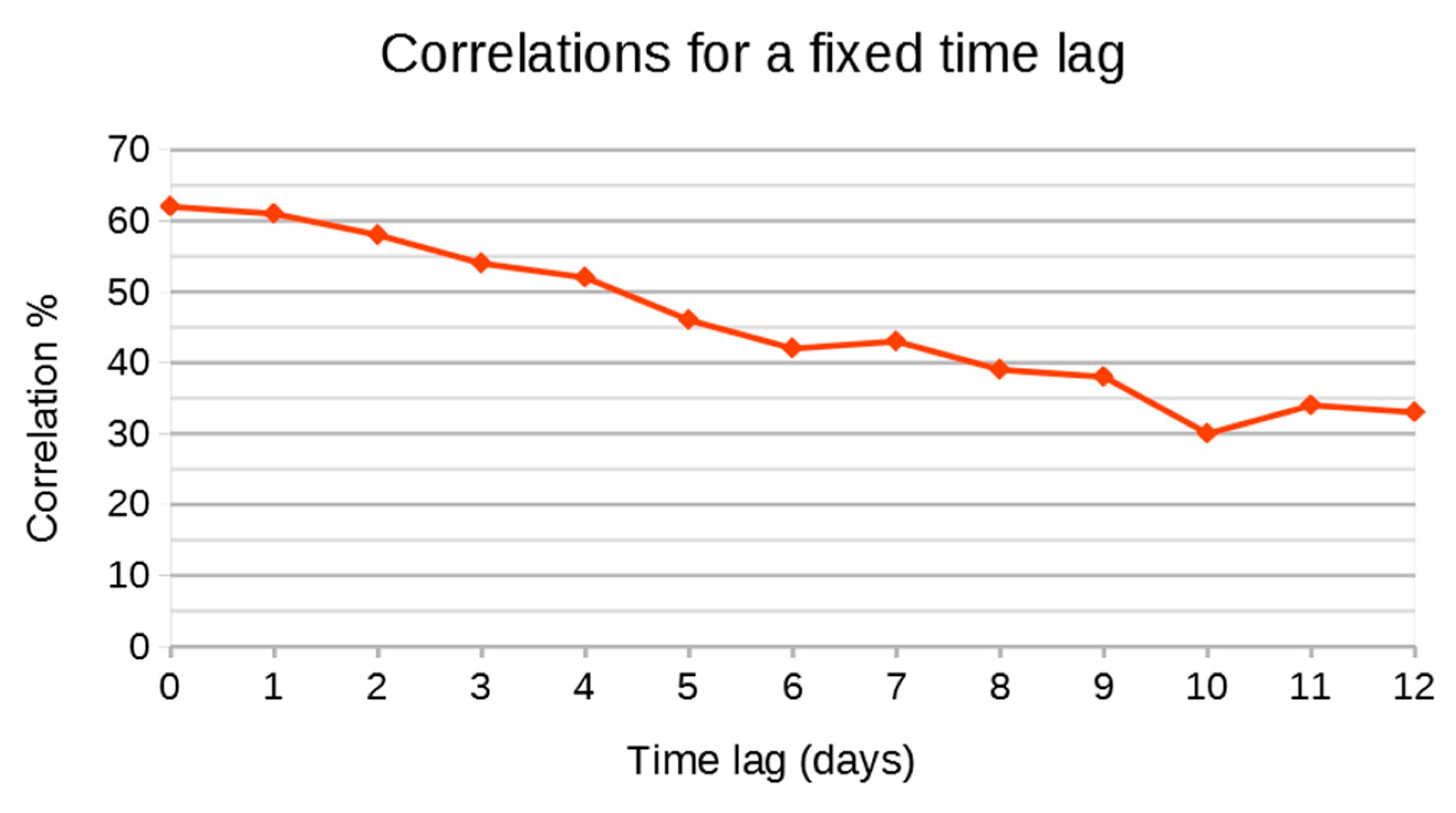
This confidence interval is large, but it is expected to decrease by spatial averaging at a coarser resolution [
37]. This can be observed in the case of Izas, since the standard deviation decreases from 18% to 16% by aggregation over the imaged area (
Table 6). To further evaluate the effect of spatial resolution on the results, we also compared the FSC at coarser resolutions using the SPOT reference dataset. We selected SPOT because it has the largest coverage among all datasets and thus it provides a large amount of FSC values even at coarser resolutions. The FSC computed at 20 m resolution was averaged to 40 m, 80 m and 160 m resolution and the same performance metrics computed for all images. The results show increasing performances of the FSC model at coarser resolutions with a reduction in the RMSE from 25% to 21% and an increase in the correlation coefficient from 0.59 to 0.79 (
Table 9). This reduction in the FSC error may reflect the spatial misregistration of the Sentinel-2 level 1 data (geolocation accuracy is currently about 10 m (2σ) [
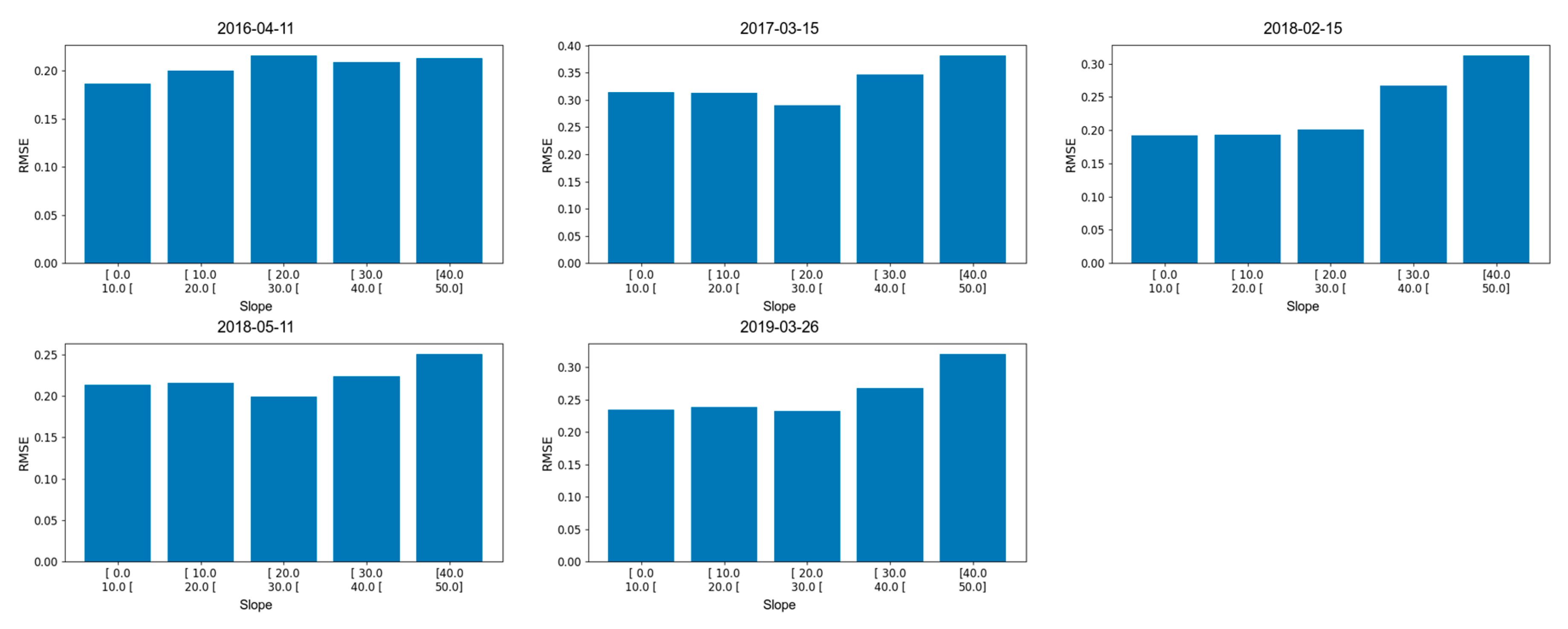
11]), an issue which should have less impact at coarser resolution. However, it may also reflect the compensation of errors due to topographic variability. We analyzed the variations in the RMSE with the topographic slope in the case of the Bassiès area where there is a large range of slopes over a small area. The slopes were computed at 20 m resolution to match the FSC data and range from 0° to over 60°. Pixels with slopes above 50° were excluded as they represented a negligible fraction of the data.
Figure 12 indicates that the RMSE tends to increase with the slope; however, the relationship remains weak, suggesting that the slope is a poor predictor of the error in this case. Further work is needed to characterize the spatial structure of the FSC error and potentially relate it to the topography and the sun geometry.
A large part of the evaluation was done using binary snow products as a reference which may create a bias in the fractional snow cover obtained by aggregation in a Sentinel-2 pixel due to the thresholding effect [
13,
14,
15]. This effect was mitigated by using very-high resolution images both in calibration (2 m) and in evaluation (Izas 1 m, Weisssee 0.5 m) since the fraction of mixed snow pixels decreases at higher resolutions [
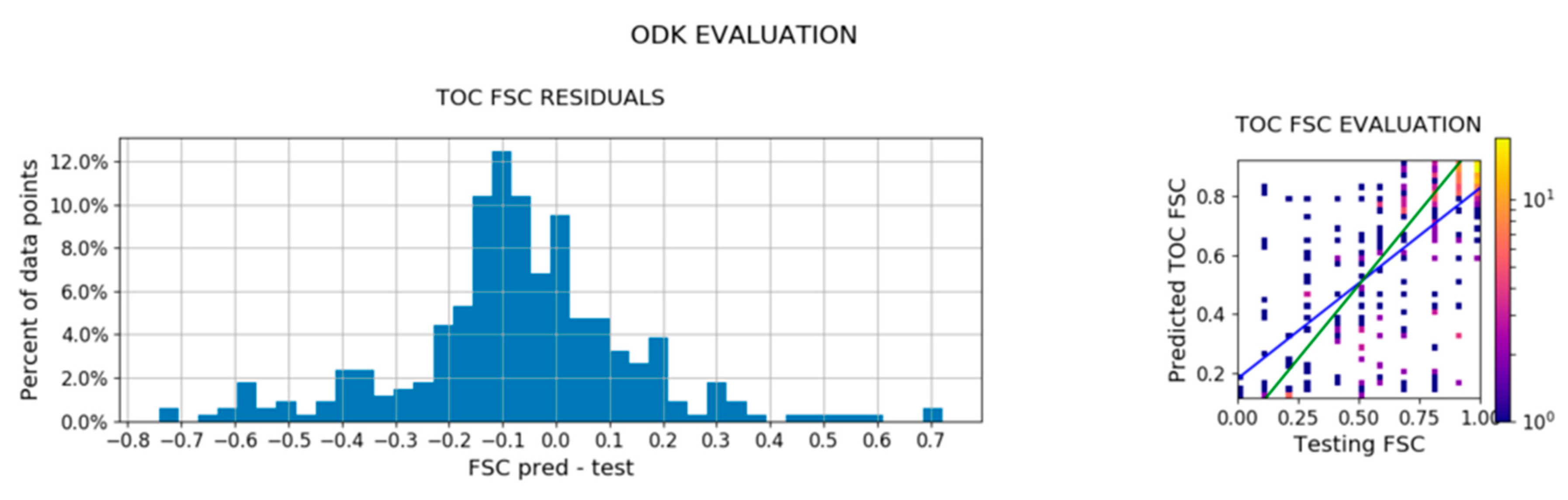
14]. However, it may be more problematic with the SPOT data (6 m resolution). There is no such issue with the ODK dataset since the participants estimated the fractional snow cover directly. However, the ODK dataset suffers from other sources of uncertainties due to the difficulty to estimate FSC within a 10 m radius area in the field. Despite this limitation, the ODK data are well correlated (correlation coefficient: 0.67) with the FSC estimates, which encourages us to continue this experiment in the future with an improved user interface. The ODK data should be particularly useful to evaluate FSC in forested areas where remote sensing data are particularly scarce.

 ,
, 














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}