Examining the Roles of Spectral, Spatial, and Topographic Features in Improving Land-Cover and Forest Classifications in a Subtropical Region

 , ,
, ,
Abstract
:
1. Introduction
2. Materials and Methods
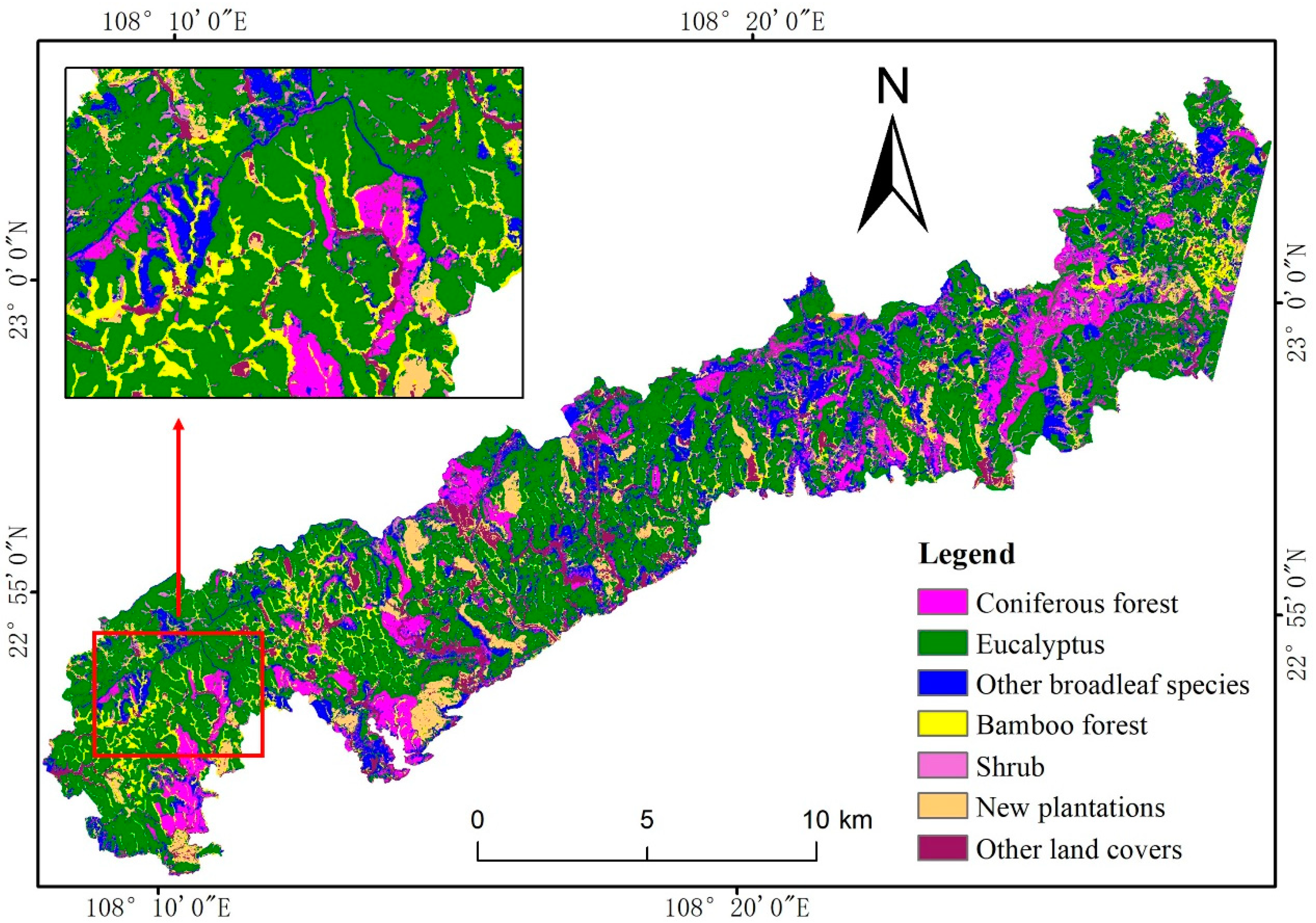
2.1. Study Area
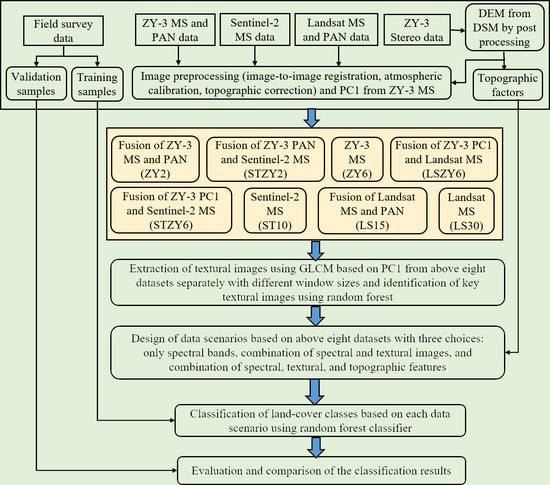
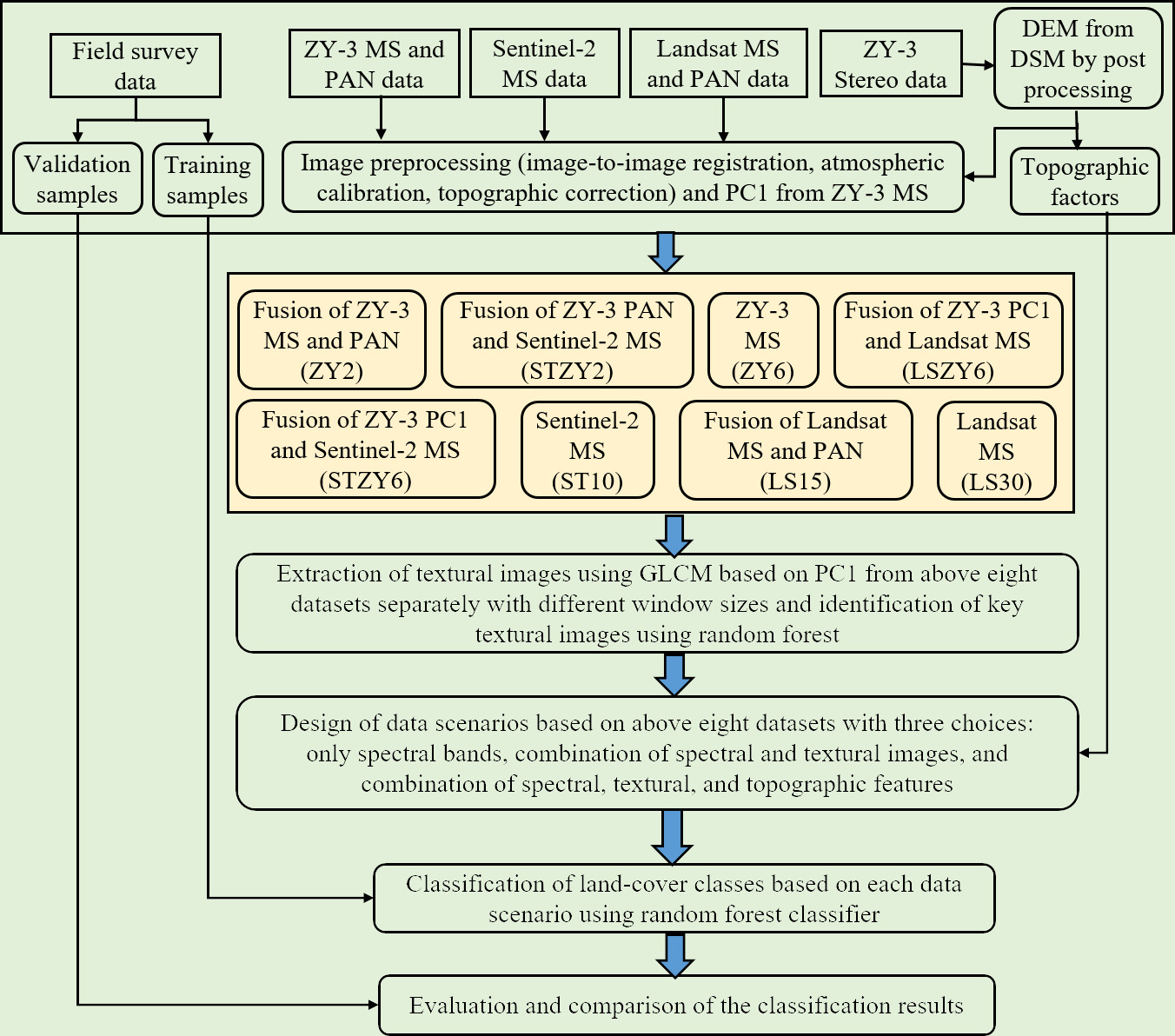
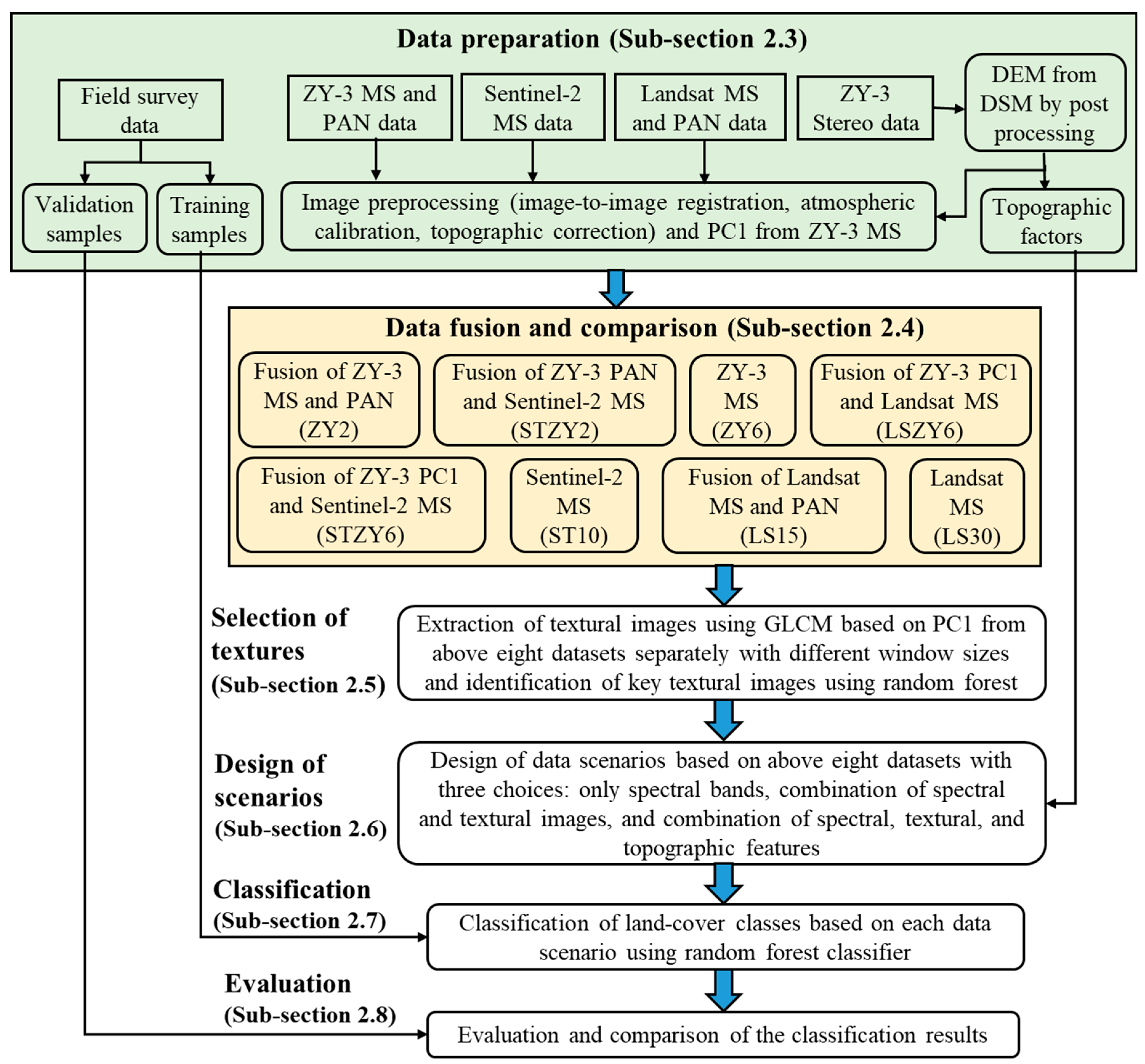
2.2. The Proposed Framework
2.3. Data Preparations
2.3.1. Collection of Field Survey Data and Design of a Land-Cover Classification System
2.3.2. Collection and Preprocessing of Different Remotely Sensed Data
2.4. Multisensor/Multiresolution Data Fusion
- (1)
- Scenarios at 2-m spatial resolution: (1a) ZY2: Fusion of ZY-3 PAN (2 m) and MS (6 m) data—four multispectral bands with 2-m spatial resolution; (1b) STZY2: Fusion of ZY-3 PAN (2 m) and Sentinel-2 MS (10 m) data—10 multispectral bands with 2-m spatial resolution;
- (2)
- Scenarios at 6-m spatial resolution: (2a) STZY6: Fusion of ZY-3 PC1 from ZY-3 multispectral image (6 m) and Sentinel-2 MS (10 m) data—10 multispectral bands with 6-m spatial resolution; (2b) LSZY6: Fusion of ZY-3 PC1 from ZY-3 multispectral image (6 m) and Landsat8 OLI MS (30 m) data—six multispectral bands with 6-m spatial resolution;
- (3)
- Scenarios at 15-m spatial resolution: LS15: Fusion of Landsat PAN (15 m) and MS (30 m) data—six multispectral bands with 15-m spatial resolution.
2.5. Extraction and Selection of Textural Images
2.6. Design of Data Scenarios
2.7. Land-Cover Classification Using the Random Forest Classifier
2.8. Comparative Analysis of Classification Results
3. Results
3.1. Comparative Analysis of Classification Results Based on Overall Accuracies
3.1.1. The Role of Spectral Features in Land-Cover Classification
3.1.2. The Role of Textures in Land-Cover Classification
3.1.3. The Role of Topographic Factors in Land-Cover Classification
3.1.4. The Comprehensive Roles of Textures and Topographic Factors in Land-Cover Classification
3.2. Comparative Analysis of Classification Results Based on Individual Forest Classes
3.2.1. The Role of Spectral Features in Individual Forest Classification
3.2.2. The Role of Textures in Individual Forest Classification
3.2.3. The Role of Topographic Features in Individual Forest Classification
3.2.4. The Comprehensive Roles of Textures and Topographic Factors in Individual Forest Classification
3.2.5. Design of Different Forest Classification Systems
4. Discussion
4.1. Increasing the Number of Spectral Bands to Improve Land-Cover and Forest Classification
4.2. Incorporating Textures into Spectral Data to Improve Land-Cover and Forest Classification
4.3. Using Ancillary Data to Improve Land-Cover and Forest Classification
4.4. The Importance of Using Multiple Data Sources to Improve Land-Cover and Forest Classification
5. Conclusions
- (1)
- Spectral signature is more important than spatial resolution in land-cover and forest classification. High spatial resolution images with a limited number of spectral bands (i.e., only visible and NIR) cannot produce accurate classifications, but increasing the number of spectral bands in high spatial resolution images through data fusion can considerably improve classification accuracy. For instance, increasing the number of spectral bands from 4 to 10 increased overall land-cover classification accuracy by 14.2% based on 2-m spatial resolution and by 11.1% based on 6-m spatial resolution.
- (2)
- The best classification scenario was STZY2(10) with SPTXTP, with overall land-cover classification accuracy of 83.5% and kappa coefficient of 0.8, indicating the comprehensive roles of high spatial and spectral resolutions and topographic factors. Overall, incorporation of both textures and topographic factors into spectral data can improve land-cover classification accuracy by 3.9–11.8%. In particular, overall accuracy increased by 11.4–11.6% in high spatial resolution images (2 m) compared to medium spatial resolution images (10–30 m) yielding only 5.6–7.2% improvement.
- (3)
- Textures from high spatial resolution imagery play more important roles in improving land-cover classification than textures from medium spatial resolution images. The incorporation of textural images into spectral data in the 2-m spatial resolution imagery raised overall accuracy by 6.0–7.7% compared to 10-m to 30-m spatial resolution images with improved accuracy of only 1.1–1.7%. Incorporation of topographic factors into spectral and textural imagery can further improve overall land-cover classification accuracy by 1.2–5.5%, especially for the medium spatial resolution imagery (10–30 m) with improved accuracy of 4.3–5.5%.
- (4)
- Integration of spectral, textural, and topographic factors is effective in improving forest classification accuracy in the subtropical region, but their roles vary, depending on the spatial and spectral data used and specific forest types. Increasing the number of spectral bands in high spatial resolution images through data fusion is especially valuable for improving forest classification. Incorporation of textures into spectral bands can further improve forest classification, but textures from high spatial resolution images work better than those from medium spatial resolution images.
- (5)
- Forest classification with detailed plantation types was still difficult even using the best data scenario (i.e., STZY2(10) with SPTXTP) in this research. The classification accuracies for Masson pine, Chinese fir, Chinese anise, and Castanopsis hystrix were only 64.8–70.7%, while the accuracies for coniferous forest, eucalyptus, other broadleaf forest, and bamboo forest could reach 85.3–91.1%, indicating the necessity to design suitable forest classification system. The roles of textures and topographic factors in improving forest classification vary, depending on specific forest types.
- (6)
- More research is needed on selection of the proper combination of textural images and topographic factors corresponding to specific forest types, instead of overall land-cover or forest classes. A hierarchically based classification procedure that can effectively identify optimal variables for each class could be a new research direction for further improving forest classification based on the use of multiple data sources covering spectral, spatial, and topographic features and forest stand structures (e.g., from Lidar-derived height features).
Author Contributions
Funding
Conflicts of Interest
References
- Yu, G.; Chen, Z.; Piao, S.; Peng, C.; Ciais, P.; Wang, Q.; Lia, X.; Zhu, X. High carbon dioxide uptake by subtropical forest ecosystems in the East Asian monsoon region. Proc. Natl. Acad. Sci. USA 2014, 111, 4910–4915. [Google Scholar] [CrossRef] [Green Version]
- Piao, S.; Fang, J.; Ciais, P.; Peylin, P.; Huang, Y.; Sitch, S.; Wang, T. The carbon balance of terrestrial ecosystems in China. Nature 2009, 458, 1009–1013. [Google Scholar] [CrossRef]
- Wen, X.F.; Wang, H.M.; Wang, J.L.; Yu, G.R.; Sun, X.M. Ecosystem carbon exchanges of a subtropical evergreen coniferous plantation subjected to seasonal drought, 2003–2007. Biogeosciences 2010, 7, 357–369. [Google Scholar] [CrossRef] [Green Version]
- Böttcher, H.; Lindner, M. Managing forest plantations for carbon sequestration today and in the future. In Ecosystem Goods and Services from Plantation Forests; Bauhus, J., van der Meer, P.J., Kanninen, M., Eds.; Earthscan Ltd.: London, UK, 2010. [Google Scholar]
- Fassnacht, F.E.; Latifi, H.; Stereńczak, K.; Modzelewska, A.; Lefsky, M.; Waser, L.T.; Straub, C.; Ghosh, A. Review of studies on tree species classification from remotely sensed data. Remote Sens. Environ. 2016, 186, 64–87. [Google Scholar] [CrossRef]
- Gómez, C.; White, J.C.; Wulder, M.A. Optical remotely sensed time series data for land cover classification: A review. ISPRS J. Photogramm. Remote Sens. 2016, 116, 55–72. [Google Scholar] [CrossRef] [Green Version]
- Wulder, M.A.; Loveland, T.R.; Roy, D.P.; Crawford, C.J.; Masek, J.G.; Woodcock, C.E.; Allen, R.G.; Anderson, M.C.; Belward, A.S.; Cohen, W.B.; et al. Current status of Landsat program, science, and applications. Remote Sens. Environ. 2019, 225, 127–147. [Google Scholar] [CrossRef]
- Pax-Lenney, M.; Woodcock, C.E.; Macomber, S.A.; Gopal, S.; Song, C. Forest mapping with a generalized classifier and Landsat TM data. Remote Sens. Environ. 2001, 77, 241–250. [Google Scholar] [CrossRef]
- Eva, H.; Carboni, S.; Achard, F.; Stach, N.; Durieux, L.; Faure, J.F.; Mollicone, D. Monitoring forest areas from continental to territorial levels using a sample of medium spatial resolution satellite imagery. ISPRS J. Photogramm. Remote Sens. 2010, 65, 191–197. [Google Scholar] [CrossRef]
- Lu, D.; Batistella, M.; Li, G.; Moran, E.; Hetrick, S.; da Costa Freitas, C.; Vieira Dutra, L.; João Siqueira Sant, S. Land use/cover classification in the Brazilian Amazon using satellite images. Pesqui. Agropecuária Bras. 2012, 47, 1185–1208. [Google Scholar] [CrossRef] [PubMed]
- Li, M.; Im, J.; Beier, C. Machine learning approaches for forest classification and change analysis using multi-temporal Landsat TM images over Huntington Wildlife Forest. GIScience Remote Sens. 2013, 50, 361–384. [Google Scholar] [CrossRef]
- Gong, P.; Wang, J.; Yu, L.; Zhao, Y.; Zhao, Y.; Liang, L.; Niu, Z.; Huang, X.; Fu, H.; Liu, S.; et al. Finer resolution observation and monitoring of global land cover: First mapping results with Landsat TM and ETM+ data. Int. J. Remote Sens. 2013, 34, 2607–2654. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Chen, J.; Liao, A.; Cao, X.; Chen, L.; Chen, X.; He, C.; Han, G.; Peng, S.; Lu, M.; et al. Global land cover mapping at 30 m resolution: A POK-based operational approach. ISPRS J. Photogramm. Remote Sens. 2015, 103, 7–27. [Google Scholar] [CrossRef] [Green Version]
- Vega Isuhuaylas, L.A.; Hirata, Y.; Santos, L.C.V.; Torobeo, N.S. Natural forest mapping in the Andes (Peru): A comparison of the performance of machine-learning algorithms. Remote Sens. 2018, 10, 782. [Google Scholar] [CrossRef] [Green Version]
- Vali, A.; Comai, S.; Matteucci, M. Deep learning for land use and land cover classification based on hyperspectral and multispectral earth observation data: A review. Remote Sens. 2020, 12, 2495. [Google Scholar] [CrossRef]
- Schäfer, E.; Heiskanen, J.; Heikinheimo, V.; Pellikka, P. Mapping tree species diversity of a tropical montane forest by unsupervised clustering of airborne imaging spectroscopy data. Ecol. Indic. 2016, 64, 49–58. [Google Scholar] [CrossRef]
- Abdollahnejad, A.; Panagiotidis, D.; Joybari, S.S.; Surovỳ, P. Prediction of dominant forest tree species using Quickbird and environmental data. Forests 2017, 8, 42. [Google Scholar] [CrossRef]
- Ferreira, M.P.; Wagner, F.H.; Aragão, L.E.O.C.; Shimabukuro, Y.E.; de Souza Filho, C.R. Tree species classification in tropical forests using visible to shortwave infrared WorldView-3 images and texture analysis. ISPRS J. Photogramm. Remote Sens. 2019, 149, 119–131. [Google Scholar] [CrossRef]
- Xie, Z.; Chen, Y.; Lu, D.; Li, G.; Chen, E. Classification of land cover, forest, and tree species classes with Ziyuan-3 multispectral and stereo data. Remote Sens. 2019, 11, 164. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Zhao, S.; Xie, Z.; Lu, D.; Chen, E. Mapping multiple tree species classes using a hierarchical procedure with optimized node variables and thresholds based on high spatial resolution satellite data. GIScience Remote Sens. 2020, 57, 526–542. [Google Scholar] [CrossRef]
- Gong, P.; Yu, L.; Li, C.; Wang, J.; Liang, L.; Li, X.; Ji, L.; Bai, Y.; Cheng, Y.; Zhu, Z. A new research paradigm for global land cover mapping. Ann. GIS 2016, 22, 87–102. [Google Scholar] [CrossRef] [Green Version]
- Chen, J.; Chen, J. GlobeLand30: Operational global land cover mapping and big-data analysis. Sci. China Earth Sci. 2018, 61, 1533–1534. [Google Scholar] [CrossRef]
- Midekisa, A.; Holl, F.; Savory, D.J.; Andrade-Pacheco, R.; Gething, P.W.; Bennett, A.; Sturrock, H.J.W. Mapping land cover change over continental Africa using Landsat and Google Earth Engine cloud computing. PLoS ONE 2017, 12, e0184929. [Google Scholar] [CrossRef] [PubMed]
- Carrasco, L.; O’Neil, A.W.; Daniel Morton, R.; Rowland, C.S. Evaluating combinations of temporally aggregated Sentinel-1, Sentinel-2 and Landsat 8 for land cover mapping with Google Earth Engine. Remote Sens. 2019, 11, 288. [Google Scholar] [CrossRef] [Green Version]
- Koskinen, J.; Leinonen, U.; Vollrath, A.; Ortmann, A.; Lindquist, E.; D’Annunzio, R.; Pekkarinen, A.; Käyhkö, N. Participatory mapping of forest plantations with Open Foris and Google Earth Engine. ISPRS J. Photogramm. Remote Sens. 2019, 12, 3966–3979. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, L.; Wu, C.; Chen, X.; Gao, Y.; Xie, S.; Zhang, B. Development of a global 30 m impervious surface map using multisource and multitemporal remote sensing datasets with the Google Earth Engine platform. Earth Syst. Sci. Data 2020, 12, 1625–1648. [Google Scholar] [CrossRef]
- Lu, D.; Li, G.; Moran, E.; Dutra, L.; Batistella, M. A Comparison of multisensor integration methods for land cover classification in the Brazilian Amazon. GIScience Remote Sens. 2011, 48, 345–370. [Google Scholar] [CrossRef] [Green Version]
- Chen, B.; Huang, B.; Xu, B. Multi-source remotely sensed data fusion for improving land cover classification. ISPRS J. Photogramm. Remote Sens. 2017, 124, 27–39. [Google Scholar] [CrossRef]
- Mishra, V.N.; Prasad, R.; Rai, P.K.; Vishwakarma, A.K.; Arora, A. Performance evaluation of textural features in improving land use/land cover classification accuracy of heterogeneous landscape using multi-sensor remote sensing data. Earth Sci. Inform. 2019, 12, 71–86. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, L.; Peng, D.; Zhao, J.; Cheng, Y.; Liu, X.; Li, W.; Meng, R.; Xu, X.; Gong, P. Annual 30-m land use/land cover maps of China for 1980–2015 from the integration of AVHRR, MODIS and Landsat data using the BFAST algorithm. Sci. China Earth Sci. 2020, 63, 1390–1407. [Google Scholar] [CrossRef]
- Nguyen, T.T.H.; Pham, T.T.T. Incorporating ancillary data into Landsat 8 image classification process: A case study in Hoa Binh, Vietnam. Environ. Earth Sci. 2016, 75, 430. [Google Scholar] [CrossRef]
- Hurskainen, P.; Adhikari, H.; Siljander, M.; Pellikka, P.K.E.; Hemp, A. Auxiliary datasets improve accuracy of object-based land use/land cover classification in heterogeneous savanna landscapes. Remote Sens. Environ. 2019, 233, 111354. [Google Scholar] [CrossRef]
- Li, G.; Lu, D.; Moran, E.; Sant’Anna, S.J.S. Comparative analysis of classification algorithms and multiple sensor data for land use/land cover classification in the Brazilian Amazon. J. Appl. Remote Sens. 2012, 6, 061706. [Google Scholar] [CrossRef]
- Phiri, D.; Morgenroth, J. Developments in Landsat land cover classification methods: A review. Remote Sens. 2017, 9, 967. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Cheng, K.; Wang, J. Forest type classification based on integrated spectral-spatial-temporal features and random forest algorithm-A case study in the Qinling Mountains. Forests 2019, 10, 559. [Google Scholar] [CrossRef]
- Lu, D.; Li, G.; Moran, E.; Dutra, L.; Batistella, M. The roles of textural images in improving land-cover classification in the Brazilian Amazon. Int. J. Remote Sens. 2014, 35, 8188–8207. [Google Scholar] [CrossRef] [Green Version]
- Almeida, D.R.A.; Stark, S.C.; Chazdon, R.; Nelson, B.W.; Cesar, R.G.; Meli, P.; Gorgens, E.B.; Duarte, M.M.; Valbuena, R.; Moreno, V.S.; et al. The effectiveness of lidar remote sensing for monitoring forest cover attributes and landscape restoration. For. Ecol. Manag. 2019, 438, 34–43. [Google Scholar] [CrossRef]
- Pohl, C.; Van Genderen, J.L. Review article Multisensor image fusion in remote sensing: Concepts, methods and applications. Int. J. Remote Sens. 1998, 19, 823–854. [Google Scholar] [CrossRef] [Green Version]
- Zhang, J. Multi-source remote sensing data fusion: Status and trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar] [CrossRef] [Green Version]
- Gärtner, P.; Förster, M.; Kleinschmit, B. The benefit of synthetically generated RapidEye and Landsat 8 data fusion time series for riparian forest disturbance monitoring. Remote Sens. Environ. 2016, 177, 237–247. [Google Scholar] [CrossRef] [Green Version]
- Iervolino, P.; Guida, R.; Riccio, D.; Rea, R. A novel multispectral, panchromatic and SAR Data fusion for land classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3966–3979. [Google Scholar] [CrossRef]
- Immitzer, M.; Atzberger, C.; Koukal, T. Tree species classification with Random forest using very high spatial resolution 8-band worldView-2 satellite data. Remote Sens. 2012, 4, 2661–2693. [Google Scholar] [CrossRef] [Green Version]
- Momeni, R.; Aplin, P.; Boyd, D.S. Mapping complex urban land cover from spaceborne imagery: The influence of spatial resolution, spectral band set and classification approach. Remote Sens. 2016, 8, 88. [Google Scholar] [CrossRef] [Green Version]
- Li, N.; Lu, D.; Wu, M.; Zhang, Y.; Lu, L. Coastal wetland classification with multiseasonal high-spatial resolution satellite imagery. Int. J. Remote Sens. 2018, 39, 8963–8983. [Google Scholar] [CrossRef]
- Ma, L.; Li, M.; Ma, X.; Cheng, L.; Du, P.; Liu, Y. A review of supervised object-based land-cover image classification. ISPRS J. Photogramm. Remote Sens. 2017, 130, 277–293. [Google Scholar] [CrossRef]
- Chen, Y.; Ming, D.; Zhao, L.; Lv, B.; Zhou, K.; Qing, Y. Review on high spatial resolution remote sensing image segmentation evaluation. Photogramm. Eng. Remote Sens. 2018, 84, 629–646. [Google Scholar] [CrossRef]
- Wu, Y.; Zhang, W.; Zhang, L.; Wu, J. Analysis of correlation between terrain and forest spatial distribution based on DEM. J. North-East For. Univ. 2012, 40, 96–98. [Google Scholar]
- Hościło, A.; Lewandowska, A. Mapping forest type and tree species on a regional scale using multi-temporal Sentinel-2 data. Remote Sens. 2019, 11, 929. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Gong, W.; Hu, X.; Gong, J. Forest type identification with random forest using Sentinel-1A, Sentinel-2A, multi-temporal Landsat-8 and DEM data. Remote Sens. 2018, 10, 946. [Google Scholar] [CrossRef] [Green Version]
- Florinsky, I.V.; Kuryakova, G.A. Influence of topography on some vegetation cover properties. Catena 1996, 27, 123–141. [Google Scholar] [CrossRef]
- Sebastiá, M.T. Role of topography and soils in grassland structuring at the landscape and community scales. Basic Appl. Ecol. 2004, 5, 331–346. [Google Scholar] [CrossRef]
- Ridolfi, L.; Laio, F.; D’Odorico, P. Fertility island formation and evolution in dryland ecosystems. Ecol. Soc. 2008, 13, 439–461. [Google Scholar] [CrossRef] [Green Version]
- Grzyl, A.; Kiedrzyński, M.; Zielińska, K.M.; Rewicz, A. The relationship between climatic conditions and generative reproduction of a lowland population of Pulsatilla vernalis: The last breath of a relict plant or a fluctuating cycle of regeneration? Plant Ecol. 2014, 215, 457–466. [Google Scholar] [CrossRef] [Green Version]
- Zhu, X.; Liu, D. Accurate mapping of forest types using dense seasonal landsat time-series. ISPRS J. Photogramm. Remote Sens. 2014, 96, 1–11. [Google Scholar] [CrossRef]
- Chiang, S.H.; Valdez, M. Tree species classification by integrating satellite imagery and topographic variables using maximum entropy method in a Mongolian forest. Forests 2019, 10, 961. [Google Scholar] [CrossRef] [Green Version]
- Teillet, P.M.; Guindon, B.; Goodenough, D.G. On the slope-aspect correction of multispectral scanner data. Can. J. Remote Sens. 1982, 8, 84–106. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.; Ge, H.; He, S.; Xu, A.; Zhou, G.; Du, H. Pixel-based Minnaert correction method for reducing topographic effects on a landsat 7 ETM+ image. Photogramm. Eng. Remote Sens. 2008, 74, 1343–1350. [Google Scholar] [CrossRef] [Green Version]
- Soenen, S.A.; Peddle, D.R.; Coburn, C.A. SCS+C: A modified sun-canopy-sensor topographic correction in forested terrain. IEEE Trans. Geosci. Remote Sens. 2005, 43, 2148–2159. [Google Scholar] [CrossRef]
- Reinartz, P.; Müller, R.; Lehner, M.; Schroeder, M. Accuracy analysis for DSM and orthoimages derived from SPOT HRS stereo data using direct georeferencing. ISPRS J. Photogramm. Remote Sens. 2006, 60, 160–169. [Google Scholar] [CrossRef]
- Louis, J.; Debaecker, V.; Pflug, B.; Main-Knorn, M.; Bieniarz, J.; Mueller-Wilm, U.; Cadau, E.; Gascon, F. Sentinel-2 SEN2COR: L2A processor for users. In Proceedings of the Living Planet Symposium, Prague, Czech Republic, 9–13 May 2016. [Google Scholar]
- Brodu, N. Super-resolving multiresolution images with band-independent geometry of multispectral pixels. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4610–4617. [Google Scholar] [CrossRef] [Green Version]
- Vermote, E.; Justice, C.; Claverie, M.; Franch, B. Preliminary analysis of the performance of the Landsat 8/OLI land surface reflectance product. Remote Sens. Environ. 2016, 185, 46–56. [Google Scholar] [CrossRef] [PubMed]
- Johansen, K.; Coops, N.C.; Gergel, S.E.; Stange, Y. Application of high spatial resolution satellite imagery for riparian and forest ecosystem classification. Remote Sens. Environ. 2007, 110, 29–44. [Google Scholar] [CrossRef]
- Agüera, F.; Aguilar, F.J.; Aguilar, M.A. Using texture analysis to improve per-pixel classification of very high resolution images for mapping plastic greenhouses. ISPRS J. Photogramm. Remote Sens. 2008, 63, 635–646. [Google Scholar] [CrossRef]
- Haralick, R.M.; Dinstein, I.; Shanmugam, K. Textural features for image classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Marceau, D.J.; Howarth, P.J.; Dubois, J.M.M.; Gratton, D.J. Evaluation of the grey-level co-occurrence matrix method for land-cover classification using SPOT imagery. IEEE Trans. Geosci. Remote Sens. 1990, 28, 513–519. [Google Scholar] [CrossRef]
- Rodriguez-Galiano, V.F.; Chica-Olmo, M.; Abarca-Hernandez, F.; Atkinson, P.M.; Jeganathan, C. Random Forest classification of Mediterranean land cover using multi-seasonal imagery and multi-seasonal texture. Remote Sens. Environ. 2012, 121, 93–107. [Google Scholar] [CrossRef]
- Pal, M. Random forest classifier for remote sensing classification. Int. J. Remote Sens. 2005, 26, 217–222. [Google Scholar] [CrossRef]
- Gislason, P.O.; Benediktsson, J.A.; Sveinsson, J.R. Random forests for land cover classification. Pattern Recognit. Lett. 2006, 27, 294–300. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Wessel, M.; Brandmeier, M.; Tiede, D. Evaluation of different machine learning algorithms for scalable classification of tree types and tree species based on Sentinel-2 data. Remote Sens. 2018, 10, 1419. [Google Scholar] [CrossRef] [Green Version]
- Belgiu, M.; Drăgu, L. Random forest in remote sensing: A review of applications and future directions. ISPRS J. Photogramm. Remote Sens. 2016, 114, 24–31. [Google Scholar] [CrossRef]
- Ghimire, B.; Rogan, J.; Galiano, V.; Panday, P.; Neeti, N. An evaluation of bagging, boosting, and random forests for land-cover classification in Cape Cod, Massachusetts, USA. GIScience Remote Sens. 2012, 49, 623–643. [Google Scholar] [CrossRef]
- Shi, D.; Yang, X. An assessment of algorithmic parameters affecting image classification accuracy by random forests. Photogramm. Eng. Remote Sens. 2016, 82, 407–417. [Google Scholar] [CrossRef]
- Foody, G.M. Status of land cover classification accuracy assessment. Remote Sens. Environ. 2002, 80, 185–201. [Google Scholar] [CrossRef]
- Congalton, R.G.; Green, K. Assessing the Accuracy of Remotely Sensed Data: Principles and Practices, 3rd ed.; CRC Press: Boca Ratón, FL, USA, 2019. [Google Scholar]
- Pu, R.; Gong, P. Hyperspectral Remote Sensing and Its Application (Chinese); High Education Press: Beijing, China, 2000. [Google Scholar]
- Tong, Q.X.; Zhang, B.; Zheng, L.F. Hyperspectral Remote Sensing: The Principle, Technology and Application (Chinese); Higher Education Press: Beijing, China, 2006. [Google Scholar]
- Du, P.J.; Xia, J.S.; Xue, Z.H.; Tan, K.; Su, H.J.; Bao, R. Review of hyperspectral remote sensing image classification. J. Remote Sens. 2016, 20, 236–256. [Google Scholar]
- Lu, D.; Hetrick, S.; Moran, E. Land cover classification in a complex urban-rural landscape with QuickBird imagery. Photogramm. Eng. Remote Sens. 2010, 76, 1159–1168. [Google Scholar] [CrossRef] [Green Version]
- Xi, Z.; Lu, D.; Liu, L.; Ge, H. Detection of drought-induced hickory disturbances in western Lin’An county, China, using multitemporal Landsat imagery. Remote Sens. 2016, 8, 345. [Google Scholar] [CrossRef] [Green Version]
- Puttonen, E.; Suomalainen, J.; Hakala, T.; Räikkönen, E.; Kaartinen, H.; Kaasalainen, S.; Litkey, P. Tree species classification from fused active hyperspectral reflectance and LIDAR measurements. For. Ecol. Manag. 2010, 260, 1843–1852. [Google Scholar] [CrossRef]
- Ke, Y.; Quackenbush, L.J.; Im, J. Synergistic use of QuickBird multispectral imagery and LIDAR data for object-based forest species classification. Remote Sens. Environ. 2010, 114, 1141–1154. [Google Scholar] [CrossRef]
- Zou, X.; Cheng, M.; Wang, C.; Xia, Y.; Li, J. Tree classification in complex forest point clouds based on deep learning. IEEE Geosci. Remote Sens. Lett. 2017, 14, 2360–2364. [Google Scholar] [CrossRef]
- Johnson, B.A.; Iizuka, K. Integrating OpenStreetMap crowdsourced data and Landsat time-series imagery for rapid land use/land cover (LULC) mapping: Case study of the Laguna de Bay area of the Philippines. Appl. Geogr. 2016, 67, 140–149. [Google Scholar] [CrossRef]
- Vahidi, H.; Klinkenberg, B.; Johnson, B.A.; Moskal, L.M.; Yan, W. Mapping the individual trees in urban orchards by incorporating Volunteered Geographic Information and very high resolution optical remotely sensed data: A template matching-based approach. Remote Sens. 2018, 10, 1134. [Google Scholar] [CrossRef] [Green Version]
- Adagbasa, E.G.; Adelabu, S.A.; Okello, T.W. Application of deep learning with stratified K-fold for vegetation species discrimation in a protected mountainous region using Sentinel-2 image. Geocarto Int. 2019, 1–21. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Description | Acquisition Date |
|---|---|---|
| ZiYuan–3 (ZY-3) (L1C) | Four multispectral bands (blue, green, red, and near infrared (NIR)) with 5.8-m spatial resolution and stereo imagery (panchromatic band—nadir-view image with 2.1-m, backward and forward views with 3.5-m spatial resolution) were used. | 10 March 2018 (Solar zenith angle of 35.68° and solar azimuth angle of 136.74°) |
| Sentinel-2 (L1C) | Four multispectral bands (three visible bands and one NIR band) with 10-m spatial resolution and six multispectral bands (three red-edge bands, one narrow NIR band, and two SWIR bands) with 20-m spatial resolution were used. | 17 December 2017 (Solar zenith angle of 49.37° and solar azimuth angle of 158.68°) |
| Landsat 8 OLI (L2) | Six multispectral bands (three visible bands, one NIR band, and two SWIR bands) with 30-m spatial resolution and one panchromatic band with 15-m spatial resolution were used. | 1 February 2017 (Solar zenith angle of 48.02° and solar azimuth angle of 144.59°) |
| Field survey | A total of 2166 samples covering different land covers were collected during fieldwork and digitized in the lab. | December 2017 and September 2019 |
| Digital elevation model (DEM) | The DEM data with 2-m spatial resolution were produced from digital surface model (DSM) data which were extracted from the ZY-3 stereo data. | 10 March 2018 |
| Land-Cover Type | Number of Training Samples | Number of Validation Samples |
|---|---|---|
| Masson pine (MP) | 168 | 36 |
| Chinese fir (CF) | 118 | 41 |
| Eucalyptus (EU) | 232 | 194 |
| Chinese anise (CA) | 33 | 33 |
| Castanopsis hystrix (CH) | 53 | 30 |
| Schima (SC) | 50 | 32 |
| Other broadleaf trees (OBT) | 37 | 46 |
| Bamboo forest (BBF) | 141 | 71 |
| Shrub (SH) | 105 | 35 |
| New plantation (NP) | 85 | 42 |
| Other land covers (OLC) | 246 | 88 |
| Total classes: 11 | Total training samples: 1268 | Total validation samples: 648 |
| Dataset | Data Scenario | Selected Variables |
|---|---|---|
| ZY-3 PAN & MS fused data (2 m) | ZY2(4)SP | Blue, Green, Red, NIR |
| ZY2(4)SPTX | ZY2(4)SP & (cor_31, cor_9, sec_9, me_31, cor_15, var_13) | |
| ZY2(4)SPTXTP | ZY2(4)SPTX & (Elevation, Slope, Aspect) | |
| ZY-3 PAN & Sentinel-2 MS fused data (2 m) | STZY2(10)SP | Blue, Green, Red, RedEdge(1–3), NIR, NNIR, SWIR1, SWIR2 |
| STZY2(10)SPTX | STZY2(10)SP & (cor_31, var_31, cor_9, var_11, sec_5, hom_31) | |
| STZY2(10)SPTXTP | STZY2(10)SPTX & (Elevation, Slope, Aspect) | |
| ZY-3 MS (6 m) | ZY6(4)SP | Blue, Green, Red, NIR |
| ZY6(4)SPTX | ZY6(4)SP & (sec_5, cor_5, cor_7, con_5, hom_21, me_21) | |
| ZY6(4)SPTXTP | ZY6(4)SPTX & (Elevation, Slope, Aspect) | |
| ZY-3 PC1 and Sentinel-2 MS fused data (6 m) | STZY6(10)SP | Blue, Green, Red, RedEdge(1–3), NIR, NNIR, SWIR1, SWIR2 |
| STZY6(10)SPTX | STZY6(10)SP & (cor_7, cor_15, cor_5, hom_5, var_5, var_13) | |
| STZY6(10)SPTXTP | STZY6(10)SPTX & (Elevation, Slope, Aspect) | |
| ZY-3 PC1 and Landsat MS fused data (6 m) | LSZY6(6)SP | Blue, Green, Red, NIR, SWIR1, SWIR2 |
| LSZY6(6)SPTX | LSZY6(6)SP & (cor_21, cor_7, cor_5, me_21, hom_5, con_5) | |
| LSZY6(6)SPTXTP | LSZY6(6)SPTX & (Elevation, Slope, Aspect) | |
| Sentinel-2 MS data (10 m) | ST10(10)SP | Blue, Green, Red, RedEdge(1–3), NIR, NNIR, SWIR1, SWIR2 |
| ST10(10)SPTX | ST10(10)SP & (cor_15, cor_5, cor_9, var_15, hom_15, var_3) | |
| ST10(10)SPTXTP | ST10(10)SPTX & (Elevation, Slope, Aspect) | |
| Landsat PAN and MS fused data (15 m) | LS15(6)SP | Blue, Green, Red, NIR, SWIR1, SWIR2 |
| LS15(6)SPTX | LS15(6)SP & (cor_9, me_15, cor_13, cor_5, con_15, cor_3) | |
| LS15(6)SPTXTP | LS15(6)SPTX & (Elevation, Slope, Aspect) | |
| Landsat MS data (30 m) | LS30(6)SP | Blue, Green, Red, NIR, SWIR1, SWIR2 |
| LS30(6)SPTX | LS30(6)SP & (me_11, cor_11, con_11, me_3, var_5, cor_7) | |
| LS30(6)SPTXTP | LS30(6)SPTX & (Elevation, Slope, Aspect) |
| Dataset | Overall Accuracy (%) | Improvement Roles of TX, TP, TXTP (%) | Kappa Coefficient | ||||||
|---|---|---|---|---|---|---|---|---|---|
| SP | SPTX | SPTXTP | TX | TP | TXTP | SP | SPTX | SPTXTP | |
| ZY2(4) | 57.87 | 65.59 | 69.44 | 7.72 | 3.85 | 11.57 | 0.50 | 0.59 | 0.64 |
| STZY2(10) | 72.07 | 78.09 | 83.49 | 6.02 | 5.40 | 11.42 | 0.67 | 0.74 | 0.80 |
| Role of Sentinel bands | 14.20 | 12.50 | 14.05 | 0.17 | 0.15 | 0.16 | |||
| ZY6(4) | 62.44 | 68.78 | 74.19 | 6.34 | 5.41 | 11.75 | 0.56 | 0.63 | 0.69 |
| STZY6(10) | 73.57 | 76.20 | 77.43 | 2.63 | 1.23 | 3.86 | 0.69 | 0.71 | 0.73 |
| LSZY6(6) | 66.15 | 68.93 | 71.72 | 2.78 | 2.79 | 5.57 | 0.60 | 0.63 | 0.67 |
| Role of Sentinel bands | 11.13 | 7.42 | 3.24 | 0.13 | 0.08 | 0.04 | |||
| Role of Landsat bands | 3.71 | 0.15 | −2.47 | 0.04 | 0 | −0.02 | |||
| ST10(10) | 68.21 | 69.44 | 73.77 | 1.23 | 4.33 | 5.56 | 0.63 | 0.64 | 0.69 |
| LS15(6) | 61.80 | 63.51 | 68.99 | 1.71 | 5.48 | 7.19 | 0.55 | 0.57 | 0.64 |
| LS30(6) | 59.88 | 60.96 | 65.99 | 1.08 | 5.03 | 6.11 | 0.54 | 0.55 | 0.60 |
| Data Scenarios | Classification Accuracies (%) for Individual Classes | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MP | CF | EU | CA | CH | SC | OBT | BBF | SH | NP | OLC | ||
| ZY2(4) | SP | 46.38 | 52.17 | 72.48 | 41.80 | 13.81 | 74.78 | 33.60 | 33.94 | 60.33 | 55.03 | 83.64 |
| SPTX | 49.92 | 58.43 | 76.97 | 59.53 | 40.00 | 80.59 | 35.87 | 42.42 | 68.57 | 66.72 | 88.14 | |
| SPTXTP | 53.24 | 65.21 | 80.49 | 64.94 | 51.58 | 78.75 | 41.22 | 50.02 | 68.89 | 68.29 | 89.27 | |
| Role of TX, TP, TXTP | TX | 3.54 | 6.26 | 4.49 | 17.73 | 26.19 | 5.81 | 2.27 | 8.48 | 8.24 | 11.69 | 4.50 |
| TP | 3.32 | 6.78 | 3.52 | 5.41 | 11.58 | −1.84 | 5.35 | 7.60 | 0.32 | 1.57 | 1.13 | |
| TXTP | 6.86 | 13.04 | 8.01 | 23.14 | 37.77 | 3.97 | 7.62 | 16.08 | 8.56 | 13.26 | 5.63 | |
| STZY2(10) | SP | 50.93 | 49.07 | 83.12 | 68.68 | 56.67 | 80.36 | 43.68 | 78.29 | 62.82 | 71.33 | 88.30 |
| SPTX | 64.05 | 62.85 | 85.62 | 71.66 | 58.67 | 78.88 | 59.85 | 80.22 | 66.92 | 86.54 | 94.39 | |
| SPTXTP | 66.65 | 69.36 | 90.13 | 70.65 | 64.76 | 87.06 | 76.49 | 91.08 | 73.74 | 89.01 | 94.39 | |
| Role of TX, TP, TXTP | TX | 13.12 | 13.78 | 2.50 | 2.98 | 2.00 | −1.48 | 16.17 | 1.93 | 4.10 | 15.21 | 6.09 |
| TP | 2.60 | 6.51 | 4.51 | −1.01 | 6.09 | 8.18 | 16.64 | 10.86 | 6.82 | 2.47 | 0.00 | |
| TXTP | 15.72 | 20.29 | 7.01 | 1.97 | 8.09 | 6.70 | 32.81 | 12.79 | 10.92 | 17.68 | 6.09 | |
| ZY6(4) | SP | 54.50 | 60.91 | 74.63 | 58.34 | 33.05 | 85.27 | 29.60 | 46.70 | 51.43 | 61.98 | 84.93 |
| SPTX | 63.30 | 65.15 | 78.27 | 64.79 | 48.89 | 77.09 | 47.56 | 48.48 | 68.10 | 67.74 | 88.64 | |
| SPTXTP | 66.67 | 70.65 | 82.45 | 64.64 | 52.78 | 83.26 | 66.58 | 69.84 | 66.92 | 68.39 | 88.14 | |
| Role of TX, TP, TXTP | TX | 8.80 | 4.24 | 3.64 | 6.45 | 15.84 | −8.18 | 17.96 | 1.78 | 16.67 | 5.76 | 3.71 |
| TP | 3.37 | 5.50 | 4.18 | −0.15 | 3.89 | 6.17 | 19.02 | 21.36 | −1.18 | 0.65 | −0.50 | |
| TXTP | 12.17 | 9.74 | 7.82 | 6.30 | 19.73 | −2.01 | 36.98 | 23.14 | 15.49 | 6.41 | 3.21 | |
| STZY6(10) | SP | 54.39 | 59.19 | 85.63 | 70.00 | 66.67 | 75.43 | 48.34 | 73.47 | 66.92 | 68.75 | 87.73 |
| SPTX | 57.45 | 67.98 | 84.21 | 79.08 | 62.23 | 76.21 | 52.37 | 78.42 | 68.89 | 77.43 | 92.05 | |
| SPTXTP | 59.63 | 61.43 | 85.45 | 72.21 | 71.88 | 80.65 | 58.97 | 84.13 | 70.72 | 78.86 | 91.97 | |
| Role of TX, TP, TXTP | TX | 3.06 | 8.79 | −1.42 | 9.08 | −4.44 | 0.78 | 4.03 | 4.95 | 1.97 | 8.68 | 4.32 |
| TP | 2.18 | −6.55 | 1.24 | −6.87 | 9.65 | 4.44 | 6.60 | 5.71 | 1.83 | 1.43 | −0.08 | |
| TXTP | 5.24 | 2.24 | −0.18 | 2.21 | 5.21 | 5.22 | 10.63 | 10.66 | 3.80 | 10.11 | 4.24 | |
| ST10(10) | SP | 50.60 | 58.93 | 78.72 | 71.97 | 72.97 | 49.45 | 54.35 | 73.30 | 55.09 | 72.86 | 88.91 |
| SPTX | 53.65 | 59.49 | 77.58 | 66.41 | 64.62 | 53.37 | 55.44 | 77.49 | 60.88 | 75.58 | 90.75 | |
| SPTXTP | 57.87 | 65.14 | 80.40 | 68.38 | 65.29 | 71.58 | 59.20 | 80.22 | 60.88 | 76.82 | 89.67 | |
| Role of TX, TP, TXTP | TX | 3.05 | 0.56 | −1.14 | −5.56 | −8.35 | 3.92 | 1.09 | 4.19 | 5.79 | 2.72 | 1.84 |
| TP | 4.22 | 5.65 | 2.82 | 1.97 | 0.67 | 18.21 | 3.76 | 2.73 | 0.00 | 1.24 | −1.08 | |
| TXTP | 7.27 | 6.21 | 1.68 | −3.59 | −7.68 | 22.13 | 4.85 | 6.92 | 5.79 | 3.96 | 0.76 | |
| Data Scenarios | Classification Accuracies (%) for Individual Classes | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MP | CF | EU | CA | CH | SC | OBT | BBF | SH | NP | OLC | ||
| ZY6(4) | SP | 54.50 | 60.91 | 74.63 | 58.34 | 33.05 | 85.27 | 29.60 | 46.70 | 51.43 | 61.98 | 84.93 |
| SPTX | 63.30 | 65.15 | 78.27 | 64.79 | 48.89 | 77.09 | 47.56 | 48.48 | 68.10 | 67.74 | 88.64 | |
| SPTXTP | 66.67 | 70.65 | 82.45 | 64.64 | 52.78 | 83.26 | 66.58 | 69.84 | 66.92 | 68.39 | 88.14 | |
| Role of TX, TP, TXTP | TX | 8.80 | 4.24 | 3.64 | 6.45 | 15.84 | −8.18 | 17.96 | 1.78 | 16.67 | 5.76 | 3.71 |
| TP | 3.37 | 5.50 | 4.18 | −0.15 | 3.89 | 6.17 | 19.02 | 21.36 | −1.18 | 0.65 | −0.50 | |
| TXTP | 12.17 | 9.74 | 7.82 | 6.30 | 19.73 | −2.01 | 36.98 | 23.14 | 15.49 | 6.41 | 3.21 | |
| LSZY6(6) | SP | 42.77 | 59.97 | 80.82 | 64.64 | 70.00 | 72.38 | 18.64 | 59.91 | 50.90 | 65.68 | 80.27 |
| SPTX | 46.18 | 62.28 | 81.93 | 61.56 | 73.34 | 74.44 | 42.03 | 67.56 | 47.86 | 66.34 | 81.50 | |
| SPTXTP | 52.13 | 65.07 | 83.11 | 70.00 | 70.37 | 76.48 | 44.40 | 75.83 | 52.99 | 67.74 | 82.23 | |
| Role of TX, TP, TXTP | TX | 3.41 | 2.31 | 1.11 | −3.08 | 3.34 | 2.06 | 23.39 | 7.65 | −3.04 | 0.66 | 1.23 |
| TP | 5.95 | 2.79 | 1.18 | 8.44 | −2.97 | 2.04 | 2.37 | 8.27 | 5.13 | 1.40 | 0.73 | |
| TXTP | 9.36 | 5.10 | 2.29 | 5.36 | 0.37 | 4.10 | 25.76 | 15.92 | 2.09 | 2.06 | 1.96 | |
| LS15(6) | SP | 43.67 | 42.50 | 77.19 | 59.42 | 63.95 | 45.05 | 17.69 | 60.32 | 56.98 | 64.76 | 84.17 |
| SPTX | 43.41 | 50.64 | 77.37 | 66.41 | 62.37 | 59.67 | 30.44 | 55.35 | 56.84 | 61.38 | 83.64 | |
| SPTXTP | 51.44 | 58.24 | 80.87 | 72.62 | 72.50 | 61.82 | 44.21 | 65.81 | 52.49 | 69.05 | 84.58 | |
| Role of TX, TP, TXTP | TX | −0.26 | 8.14 | 0.18 | 6.99 | −1.58 | 14.62 | 12.75 | −4.97 | −0.14 | −3.38 | −0.53 |
| TP | 8.03 | 7.60 | 3.50 | 6.21 | 10.13 | 2.15 | 13.77 | 10.46 | −4.35 | 7.67 | 0.94 | |
| TXTP | 7.77 | 15.74 | 3.68 | 13.20 | 8.55 | 16.77 | 26.52 | 5.49 | −4.49 | 4.29 | 0.41 | |
| LS30(6) | SP | 45.33 | 41.62 | 75.39 | 66.79 | 56.73 | 50.70 | 33.94 | 62.66 | 39.54 | 59.75 | 80.77 |
| SPTX | 46.30 | 57.50 | 74.68 | 68.77 | 66.27 | 53.49 | 33.34 | 59.31 | 37.14 | 59.53 | 80.10 | |
| SPTXTP | 43.75 | 59.66 | 77.93 | 70.00 | 57.22 | 54.77 | 54.79 | 67.78 | 45.72 | 68.23 | 84.17 | |
| Role of TX, TP, TXTP | TX | 0.97 | 15.88 | −0.71 | 1.98 | 9.54 | 2.79 | −0.60 | −3.35 | −2.40 | −0.22 | −0.67 |
| TP | −2.55 | 2.16 | 3.25 | 1.23 | −9.05 | 1.28 | 21.45 | 8.47 | 8.58 | 8.70 | 4.07 | |
| TXTP | −1.58 | 18.04 | 2.54 | 3.21 | 0.49 | 4.07 | 20.85 | 5.12 | 6.18 | 8.48 | 3.40 | |
| Classification Accuracies of Individual Classes | OA | KA | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MP | CF | EU | CA | CH | SC | OBT | BBF | SH | NP | OLC | |||
| PA | 80.56 | 51.22 | 94.33 | 72.73 | 53.33 | 81.25 | 73.91 | 92.96 | 62.86 | 85.71 | 95.45 | 83.49 | 0.80 |
| UA | 52.73 | 87.50 | 85.92 | 68.57 | 76.19 | 92.86 | 79.07 | 89.19 | 84.62 | 92.31 | 93.33 | ||
| MA | 66.65 | 69.36 | 90.13 | 70.65 | 64.76 | 87.06 | 76.49 | 91.08 | 73.74 | 89.01 | 94.39 | ||
| CFF | EU | OBS | BBF | SH | NP | OLC | OA | KA | |||||
| PA | 92.21 | 94.33 | 80.85 | 92.96 | 62.86 | 85.71 | 95.45 | 88.89 | 0.86 | ||||
| UA | 89.87 | 85.92 | 89.76 | 89.19 | 84.62 | 92.31 | 93.33 | ||||||
| MA | 91.04 | 90.12 | 85.31 | 91.07 | 73.74 | 89.01 | 94.39 | ||||||
| Reference Data | Row Total | UA | PA | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MP | CF | EU | CA | CH | SC | OBT | BBF | SH | NP | OLC | ||||
| MP | 29 | 18 | 2 | 3 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 55 | 52.73 | 80.56 |
| CF | 3 | 21 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 24 | 87.50 | 51.22 |
| EU | 1 | 1 | 183 | 4 | 6 | 2 | 8 | 2 | 6 | 0 | 0 | 213 | 85.92 | 94.33 |
| CA | 2 | 0 | 0 | 24 | 6 | 0 | 2 | 0 | 1 | 0 | 0 | 35 | 68.57 | 72.73 |
| CH | 0 | 0 | 4 | 0 | 16 | 0 | 1 | 0 | 0 | 0 | 0 | 21 | 76.19 | 53.33 |
| SC | 0 | 1 | 0 | 0 | 0 | 26 | 0 | 0 | 0 | 0 | 1 | 28 | 92.86 | 81.25 |
| OBT | 1 | 0 | 1 | 1 | 1 | 3 | 34 | 1 | 1 | 0 | 0 | 43 | 79.07 | 73.91 |
| BBF | 0 | 0 | 3 | 0 | 0 | 0 | 1 | 66 | 4 | 0 | 0 | 74 | 89.19 | 92.96 |
| SH | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 2 | 22 | 0 | 0 | 26 | 84.62 | 62.86 |
| NP | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 36 | 2 | 39 | 92.31 | 85.71 |
| OLC | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 6 | 84 | 90 | 93.33 | 95.45 |
| Total | 36 | 41 | 194 | 33 | 30 | 32 | 46 | 71 | 35 | 42 | 88 | |||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yu, X.; Lu, D.; Jiang, X.; Li, G.; Chen, Y.; Li, D.; Chen, E. Examining the Roles of Spectral, Spatial, and Topographic Features in Improving Land-Cover and Forest Classifications in a Subtropical Region. Remote Sens. 2020, 12, 2907. https://doi.org/10.3390/rs12182907
Yu X, Lu D, Jiang X, Li G, Chen Y, Li D, Chen E. Examining the Roles of Spectral, Spatial, and Topographic Features in Improving Land-Cover and Forest Classifications in a Subtropical Region. Remote Sensing. 2020; 12(18):2907. https://doi.org/10.3390/rs12182907
Chicago/Turabian StyleYu, Xiaozhi, Dengsheng Lu, Xiandie Jiang, Guiying Li, Yaoliang Chen, Dengqiu Li, and Erxue Chen. 2020. "Examining the Roles of Spectral, Spatial, and Topographic Features in Improving Land-Cover and Forest Classifications in a Subtropical Region" Remote Sensing 12, no. 18: 2907. https://doi.org/10.3390/rs12182907
APA StyleYu, X., Lu, D., Jiang, X., Li, G., Chen, Y., Li, D., & Chen, E. (2020). Examining the Roles of Spectral, Spatial, and Topographic Features in Improving Land-Cover and Forest Classifications in a Subtropical Region. Remote Sensing, 12(18), 2907. https://doi.org/10.3390/rs12182907