1. Introduction
With the advance of technology, unmanned aerial vehicles (UAVs) have become popular in the past two decades due to their wide and various applications. The advantages of UAVs include low cost, offering a less stressful environment, and long endurance. Most important of all, UAVs are unmanned, so they can reduce the need of manpower, and thus reduce the number of casualties caused by accidents. They also have many different applications including aerial photography, entertainment, 3D mapping [
1], object detection for different usages [
2,
3,
4], military use, and agriculture applications, such as pesticide spraying and vegetation monitoring [
5]. With the increasing amounts of UAVs, there are more and more UAVs flying in the same airspace. If there is no air traffic control and management of UAVs, it may cause accidents and mid-air collisions to happen, which is one the most significant risks that UAVs are facing [
6]. Thus, UAV sense and avoid (SAA) has become a critical issue. A comprehensive review of the substantial breadth of SAA architectures, technologies, and algorithms is presented in the tutorial [
7], which concludes with a summary of the regulatory and technical issues that continue to challenge the progress on SAA. Without a human pilot onboard, unmanned aircraft systems (UASs) have to solely rely on SAA systems when in dense UAS operations in urban environments, or they are merged into the National Airspace System (NAS) [
8]. There are many factors needed to be considered for UAS traffic management (UTM), such as cost, payload of UAV, accuracy of the senor, etc. Therefore, the determination of suitable sensors in UAV SAA of UTM for objective sensing is essential.
According to how the information is transmitted, current sensor technologies for SAA can be classified as cooperative and non-cooperative methods [
8]. For cooperative sensors, the communication devices need to be equipped to communicate with the aircrafts in the same airspace, such as the traffic alert and collision avoidance system (TCAS) and the automatic dependent surveillance-broadcast (ADS-B), which have been widely used in commercial airlines. In contrast to cooperative sensors, there is no need for non-cooperative sensors to equip the same communication devices to exchange data with the other aircrafts for sharing the same airspace. Moreover, non-cooperative sensors are able to detect not only air objects but also ground targets, such as light detection and ranging (LIDAR), radar, and optical sensors (cameras). One drawback of small-scale UAVs is the limitation of their payload capability. Therefore, the camera becomes an ideal sensor for object and target detection. The camera has many advantages, such as its light weight, low cost, the fact that it is easy to equip, and it is also widely used in different applications.
Computer vision is one of the popular studies for onboard systems of UAVs, which make the vehicles able to “see” the targets or objects. With the rapid development of computer vision, vision-based navigation is now the promising technology for detecting potential threats [
6]. For object sense/detection, there are many approaches have be proposed, such as multi-stage detection pipeline [
9,
10,
11], machine learning [
12,
13,
14,
15], and deep learning [
16]. Deep learning is widely used in machine vision for object detection, localization, and classification. In contrast to traditional object detection methods, detectors using deep learning are able to learn semantic, high-level, and deeper features to address the problems existing in traditional architectures [
17]. Detectors based on deep learning can be divided into two categories, one stage and two stage. Two-stage detectors require a region proposal network (RPN) to generate regions of interests (ROI), such as the faster region convolution neural network (R-CNN) or the mask R-CNN [
18,
19]. On the other hand, the one-stage detector considers object detection as a single regression problem by taking an image as input to learn class probabilities and bounding box coordinates, such as the single shot multi-box detector (SSD) or you only look once (YOLO) [
20,
21]. Two-stages detectors have higher accuracy when compared to one-stage detectors, but their computational cost is higher than one-stage detectors.
Vison-based object detection methods have been studied for many decades and applied in many applications. In recent years, there are many studies focused on UAV detection with vision-based methods and deep learning [
22,
23,
24,
25,
26]. These studies focus on the detection of quadrotor or multirotor UAVs, commonly known as drones, but it is difficult to obtain the detector for small fixed-wing UAVs, which have higher flight speed than multirotors and will increase the challenge of the vision-based detectors. Moreover, most of these studies emphasized the development of object detectors, and there is no vision-based distance estimation for the feasibility study of SAA and mid-air collision avoidance of UAVs using a monocular camera to detect the incoming small fixed-wing UAV. Some vison-based detection approaches for mid-air collision avoidance have been proposed for light fixed-wing aircrafts. For example, an image processing of multi-stage pipeline based on the hidden Markov model (HMM) has been utilized to detect the aircrafts with slow motion on the image plane [
10]. The key stages of multi-stage pipeline are stabilized image input, image preprocessing, temporal filtering and detection logic. The advantage of this approach is that it can detect a Cessna 182 aircraft in long distance. However, when the movement of the aircraft on the image plane is too fast, this algorithm will fail. In [
6], the proposed long-range vision-based SAA utilized the same multi-stage pipeline. Moreover, instead of using only morphological image processing in image processing stage, deep learning-based pixel-wised image segmentation is also applied to increase the detection range of a Cessna 182 whilst maintaining low false alarms. It classifies every pixel in image into two classes, aircraft and non-aircraft. Regarding to UAVs, Li et al. proposed a new method to detect and track UAVs from a monocular camera mounted on the owned aircraft [
3]. The main idea of this approach is to adopt background subtraction. The background motion is calculated via optical flow to obtain the background subtracted images and to find the moving targets. This approach is able to detect moving objects without the limitations of moving speed or visual size.
For the obstacle avoidance, the distance information of the target object usually plays an important role. However, it is difficult to estimate distance with only a monocular camera. Some approaches exploit the known information, such as camera focal length and height of the object, to calculate distance via the pinhole model, and usually assume that the height or width of objects are known [
27,
28]. The distance estimation of the objects on the ground based on deep learning has been proposed in many studies, but the deep learning-based object detection of UAVs for mid-air collision avoidance is rare according to paper survey results. There are some studies focused on the monocular vision-based SAA of UAVs [
29,
30]. In the study [
29], an approach to deal with monocular image-based SAA assuming constant aircraft velocities and straight flight paths was proposed and simulated in software-in-the-loop simulation test runs. A nonlinear model predictive control scheme for a UAV SAA scenario, which assumes that the intruder’s position is already confirmed as a real threat and the host UAV is on the predefined trajectory at the beginning of the SAA process, was proposed and verified through simulations [
30]. However, in these two studies, there is no object detection method and real image data acquiring from a monocular camera. For the deep learning-based object detection, most of the studies utilize the images acquired from UAVs or a satellite to detect and track the objects on the ground, such as an automatic vehicle, airplane, and vessel [
31,
32,
33]. For ground vehicles, Li et al. proposed a monocular distance estimation system for neuro-robotics by using CNN to concatenate horizontal and vertical motion of images estimated via optical flow as inputs to the trained CNN model and the distance information from the ultrasonic sensors [
34]. The distance estimation is successfully estimated using only a camera, but the distance estimation results become worse when the velocity of robotics increases. In [
35], a deep neural network (DNN) named DisNet is proposed to detect the distance of a ground vehicle to objects, and it applied the bounding box of the objects detected by YOLO and image information, such as width and height, as inputs to train DisNet. The results show that DisNet is able to estimate the distance between objects and camera without either explicit camera parameters or a prior knowledge about the scene. However, the accuracy of the estimated distance may be directly affected due to the width and height of the bounding box.
With the rapid development in technology, UAVs have become an off-the-shelf consumer product. However, if there is no traffic control or UTM system to manage UAVs when they fly in the same airspace, it may cause mid-air collision, property loss, or causalities. Therefore, SAA and mid-air collision avoidance for UAVs have become an important issue. The goal of this study is to develop the detection of a moving UAV based on deep learning distance estimation to conduct the feasibility study of SAA and mid-air collision avoidance of UAVs. The adopted sensor for the detection of the moving object is a monocular camera, and DNN and CNN were applied to estimate the distance between the intruder and the owned UAV.
The rest of study is organized as follows: In
Section 2, the overview of this study is presented, including the architecture of the proposed detection scheme and the methods to accomplish object detection. The methods of the proposed distance estimation using deep learning are presented in
Section 3, and the introduction to model architecture and a proposed procedure to synthesize the dataset for training the model are also presented.
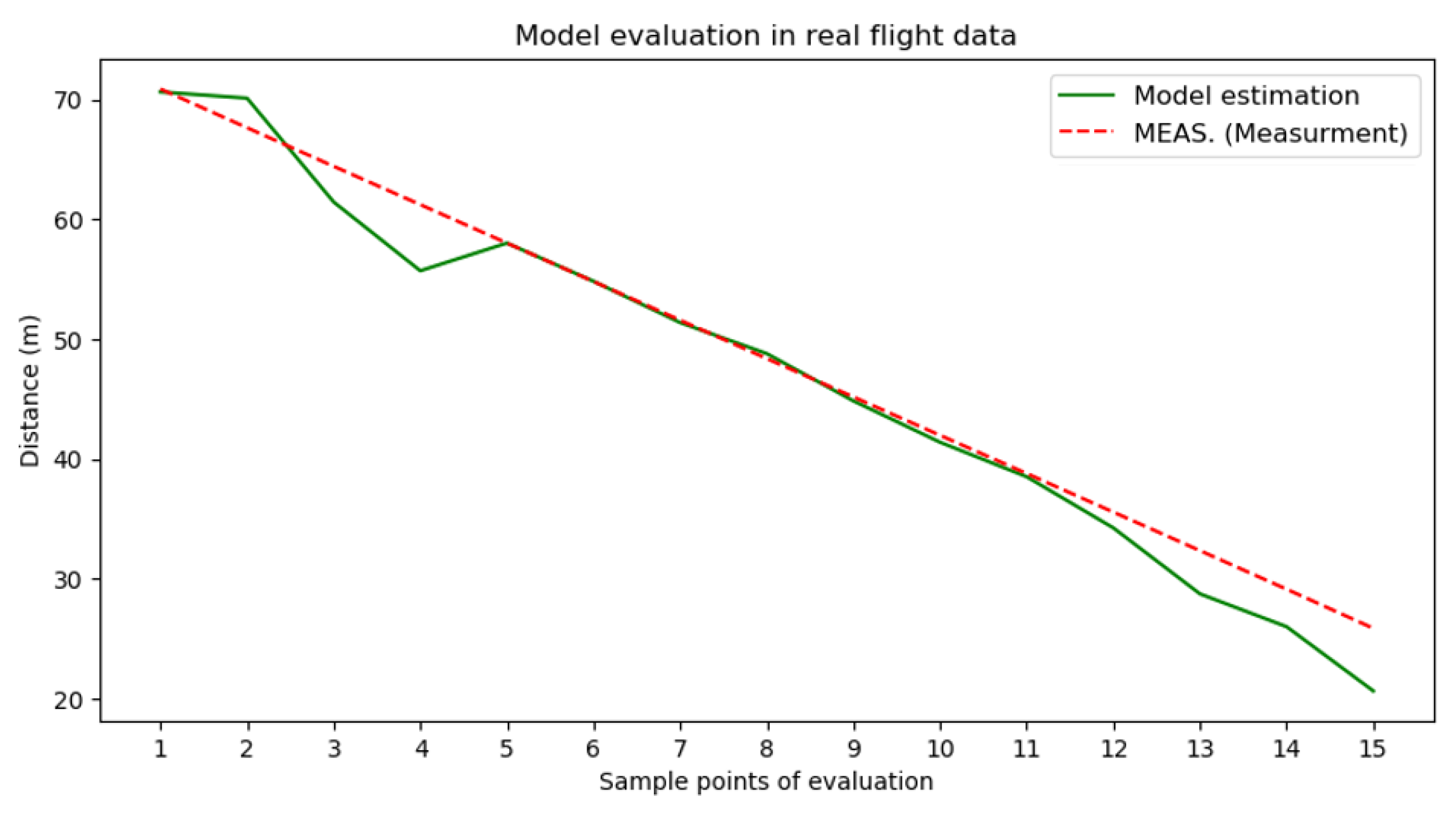
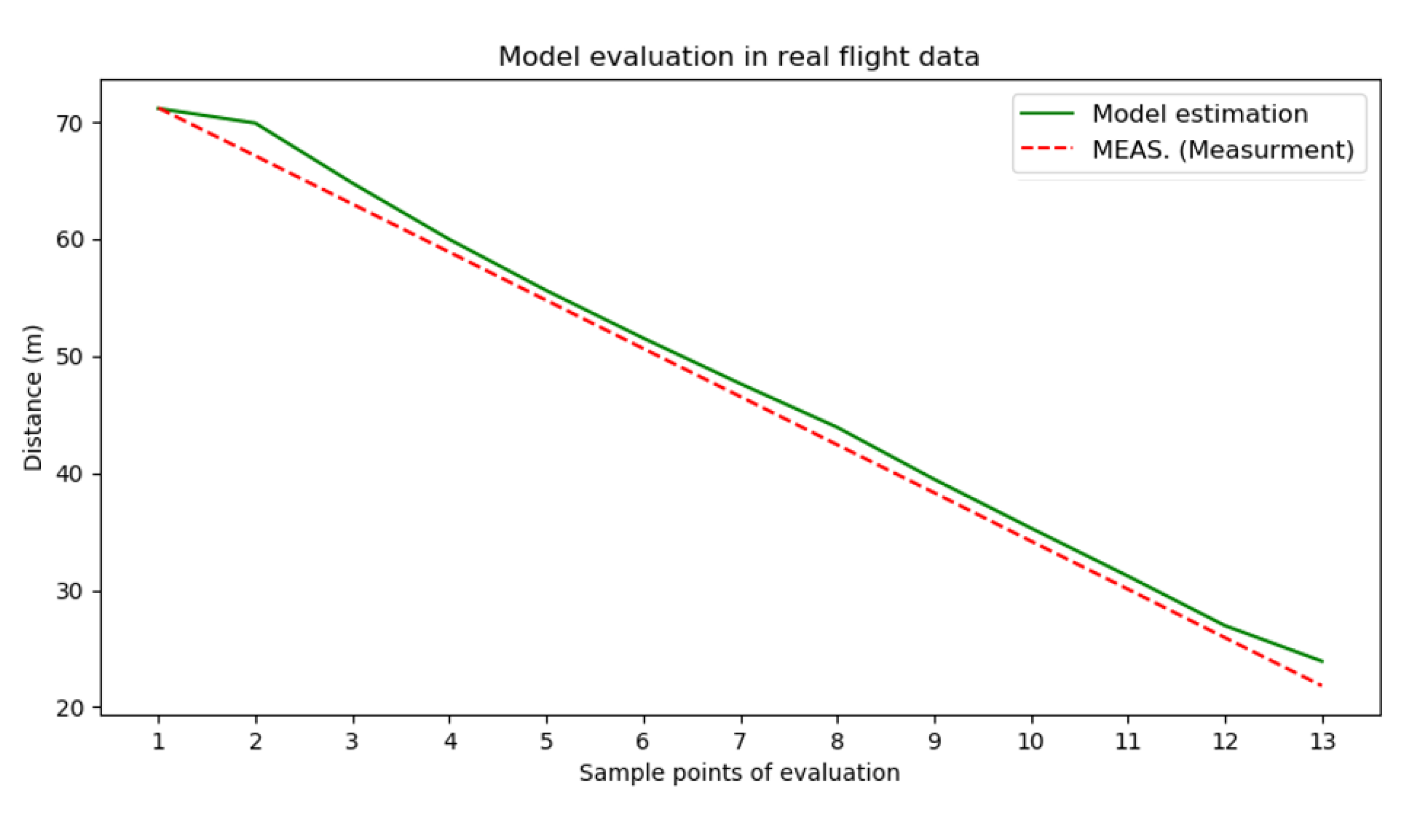
Section 4 presents the performance evaluation of the proposed methods by using synthetic videos and real flight experiments. Results and discussions of model evaluation and experiments are shown in
Section 5. Finally, the conclusion of this study is addressed in
Section 6.





































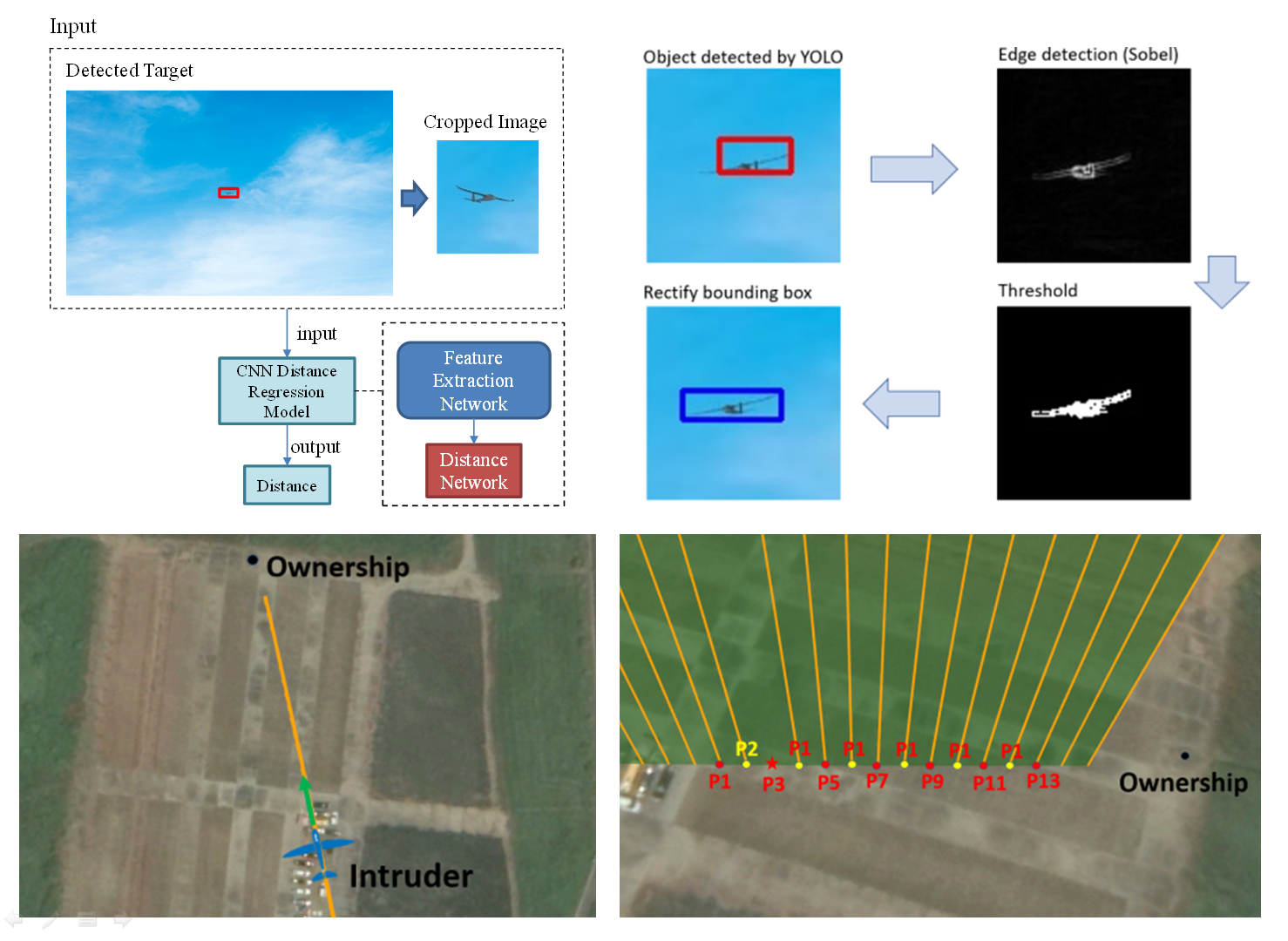{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
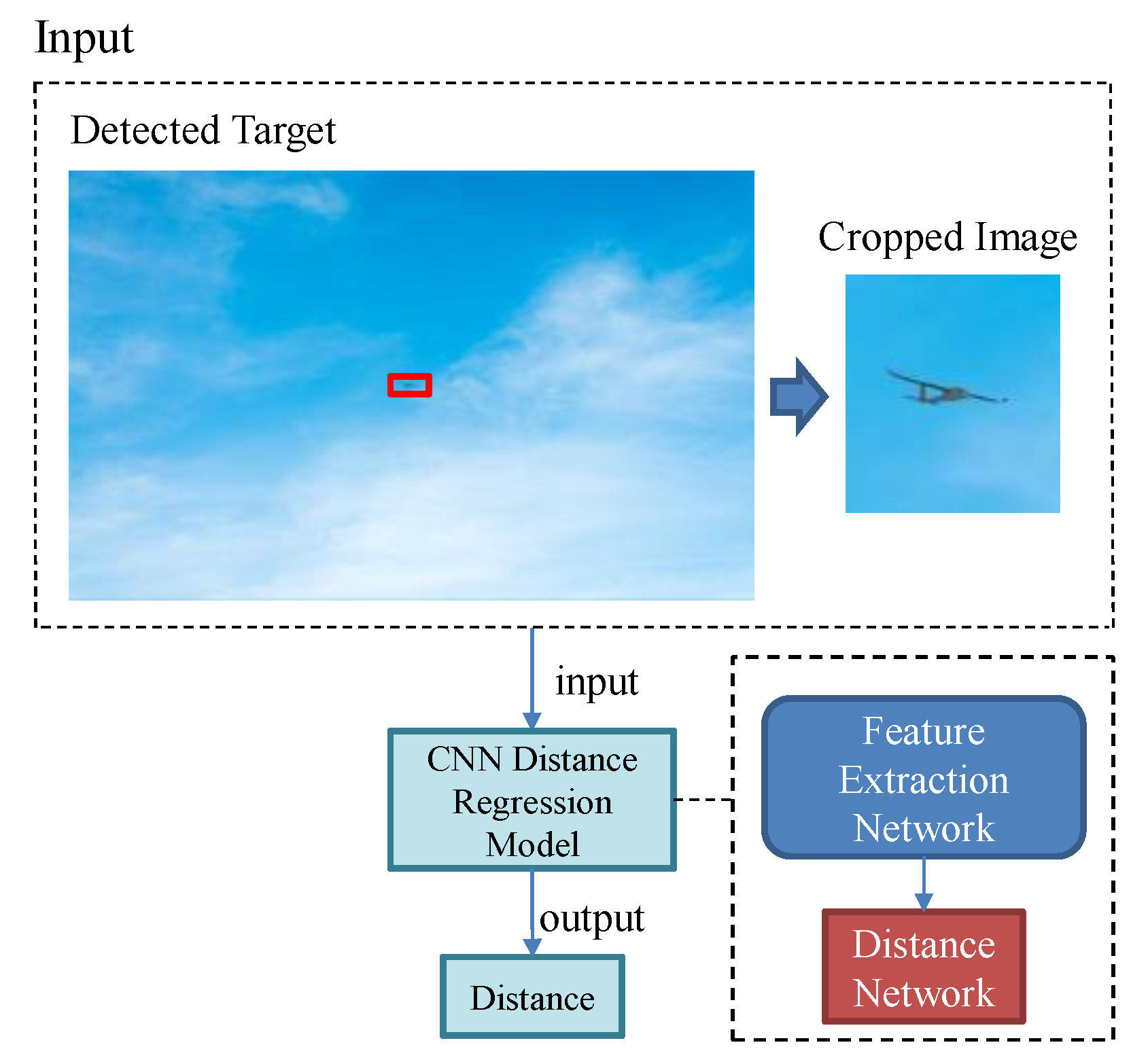{kind=link}
{kind=link}
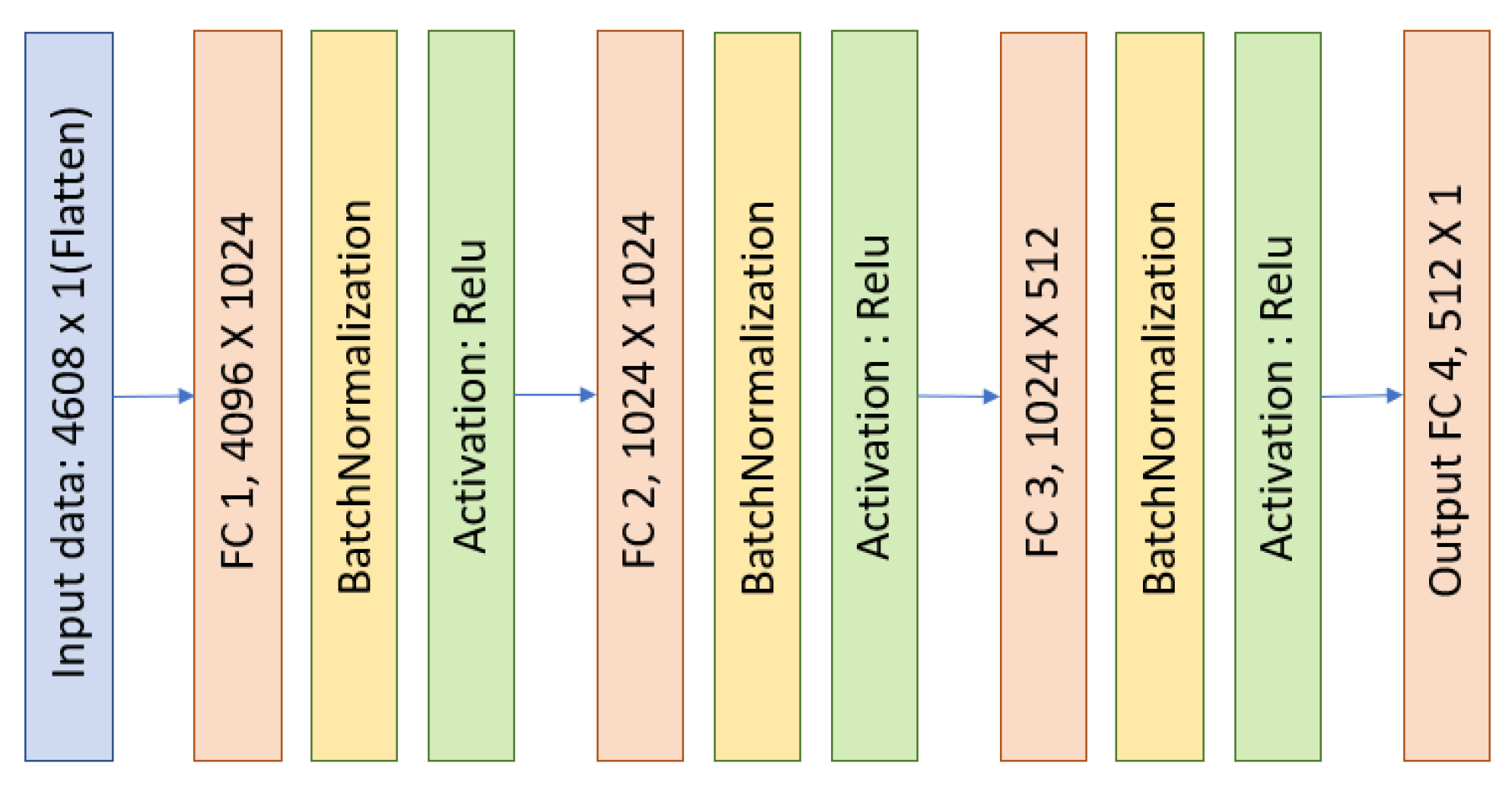{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
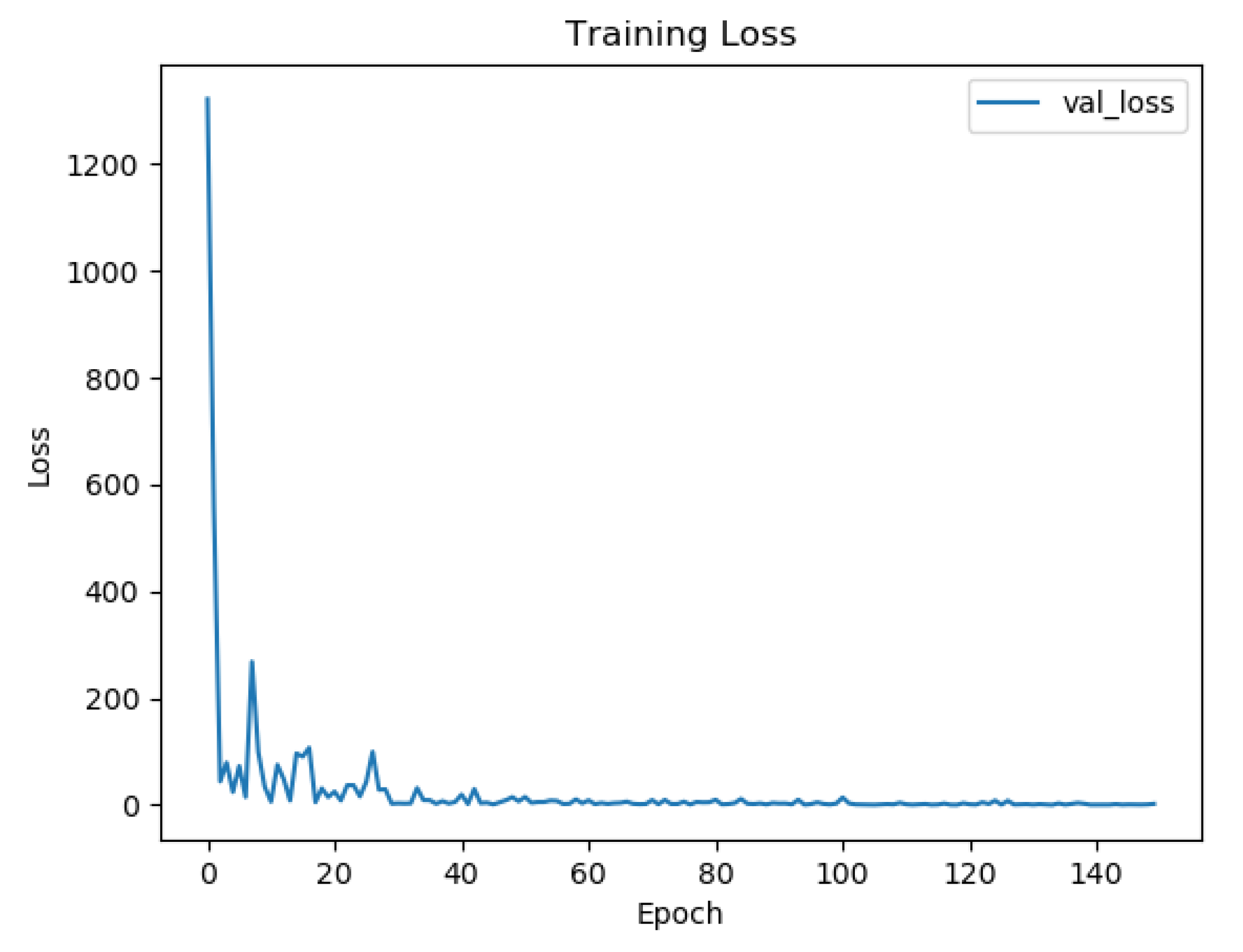{kind=link}
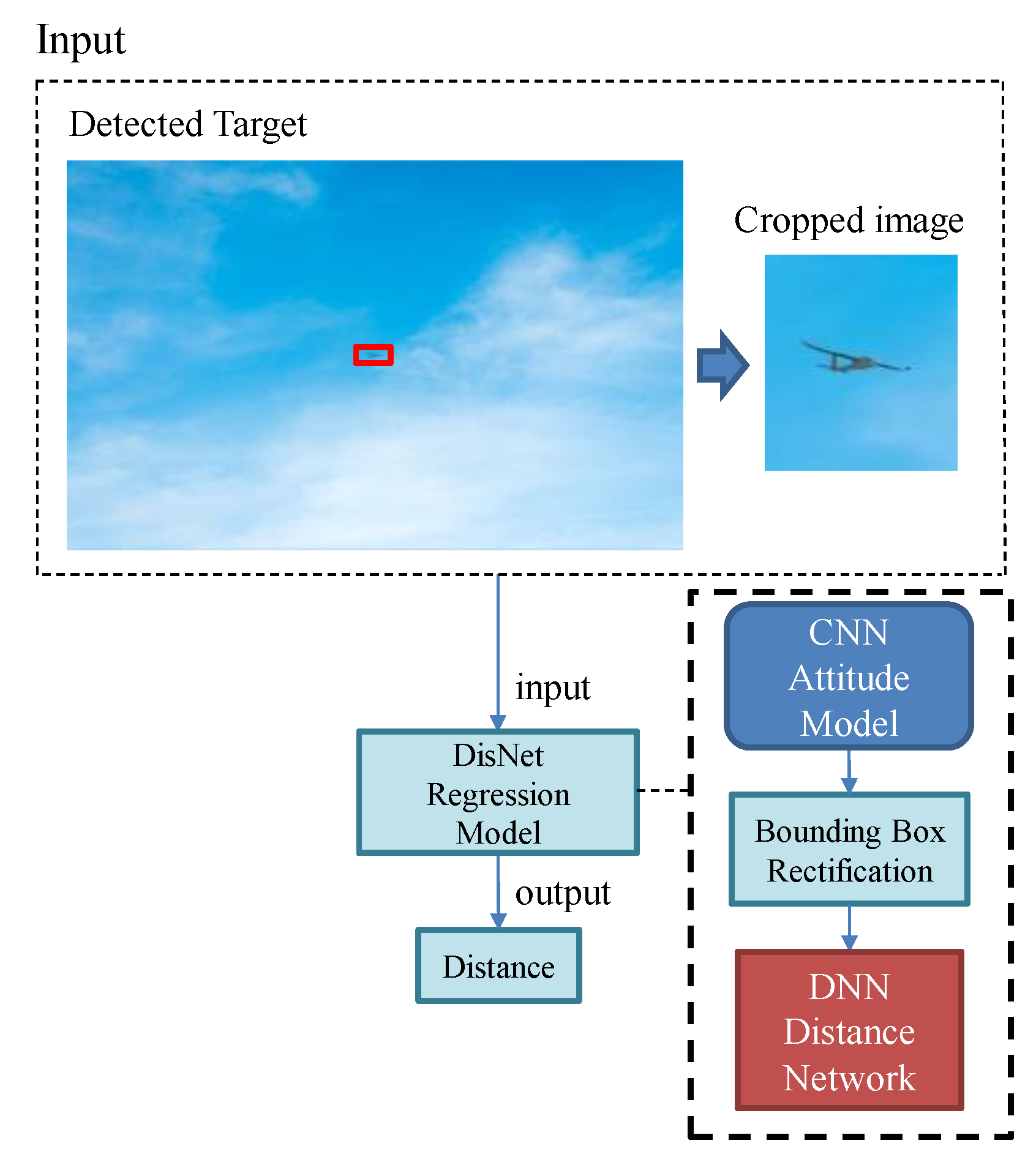{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
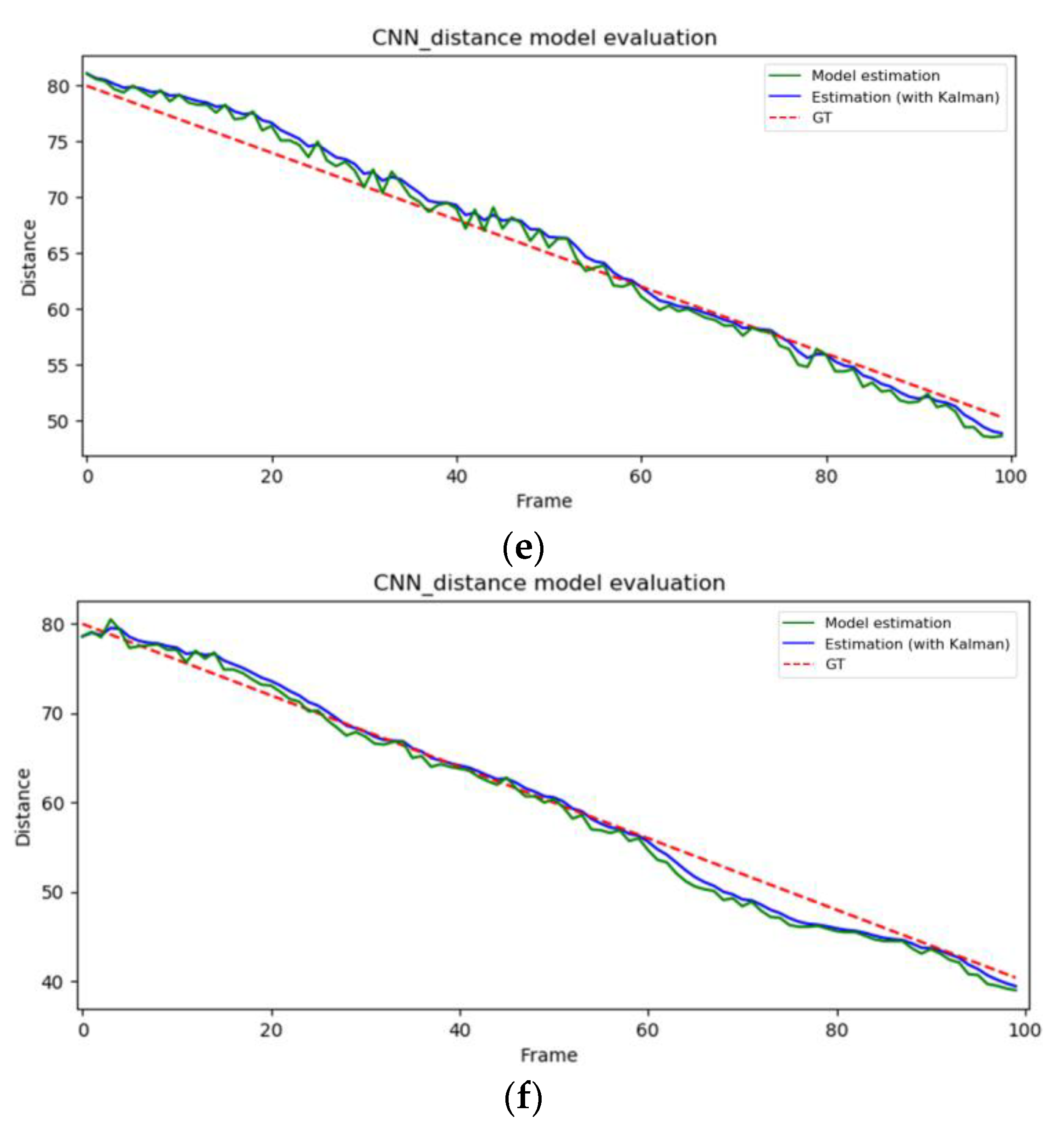{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
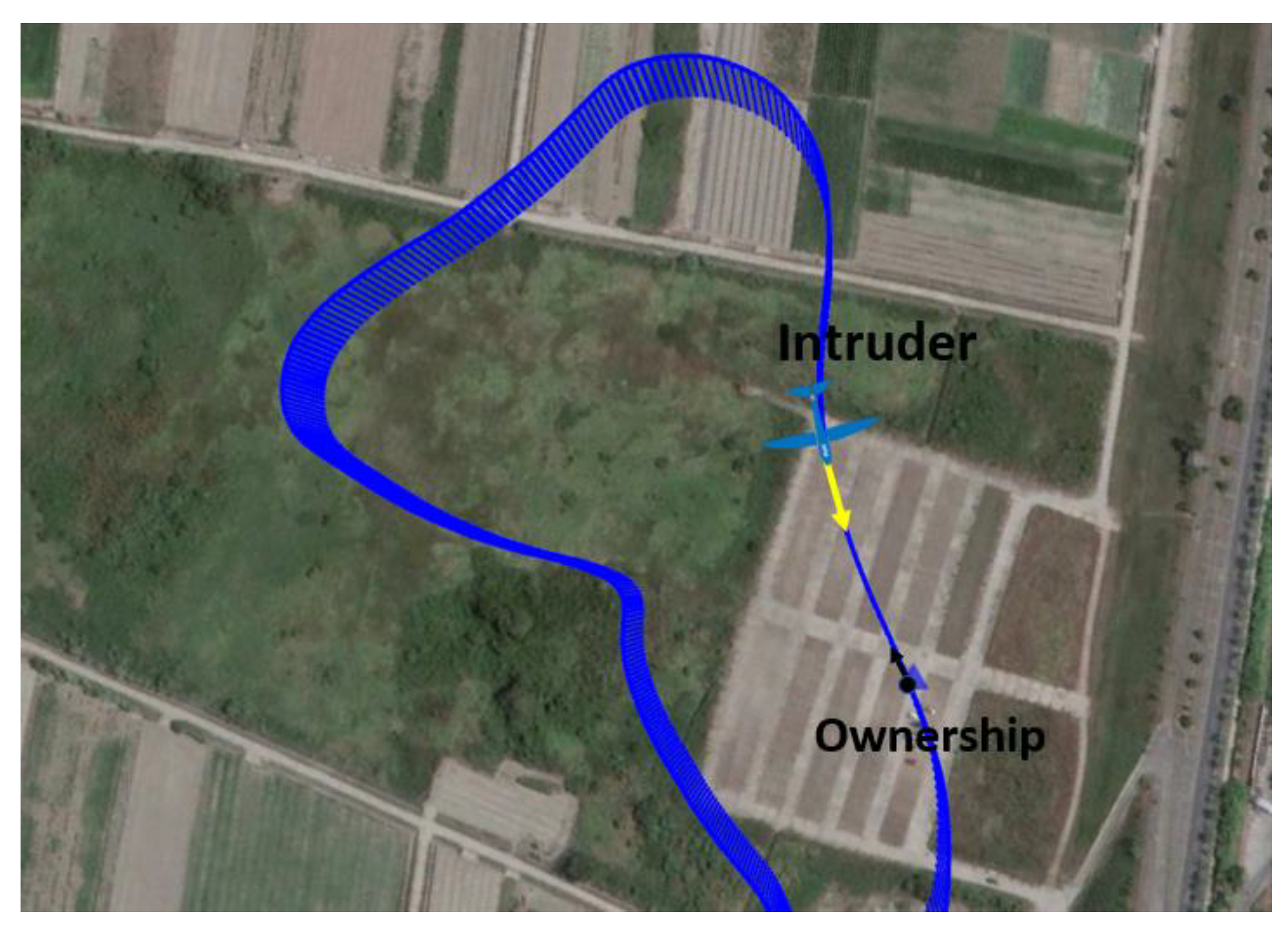
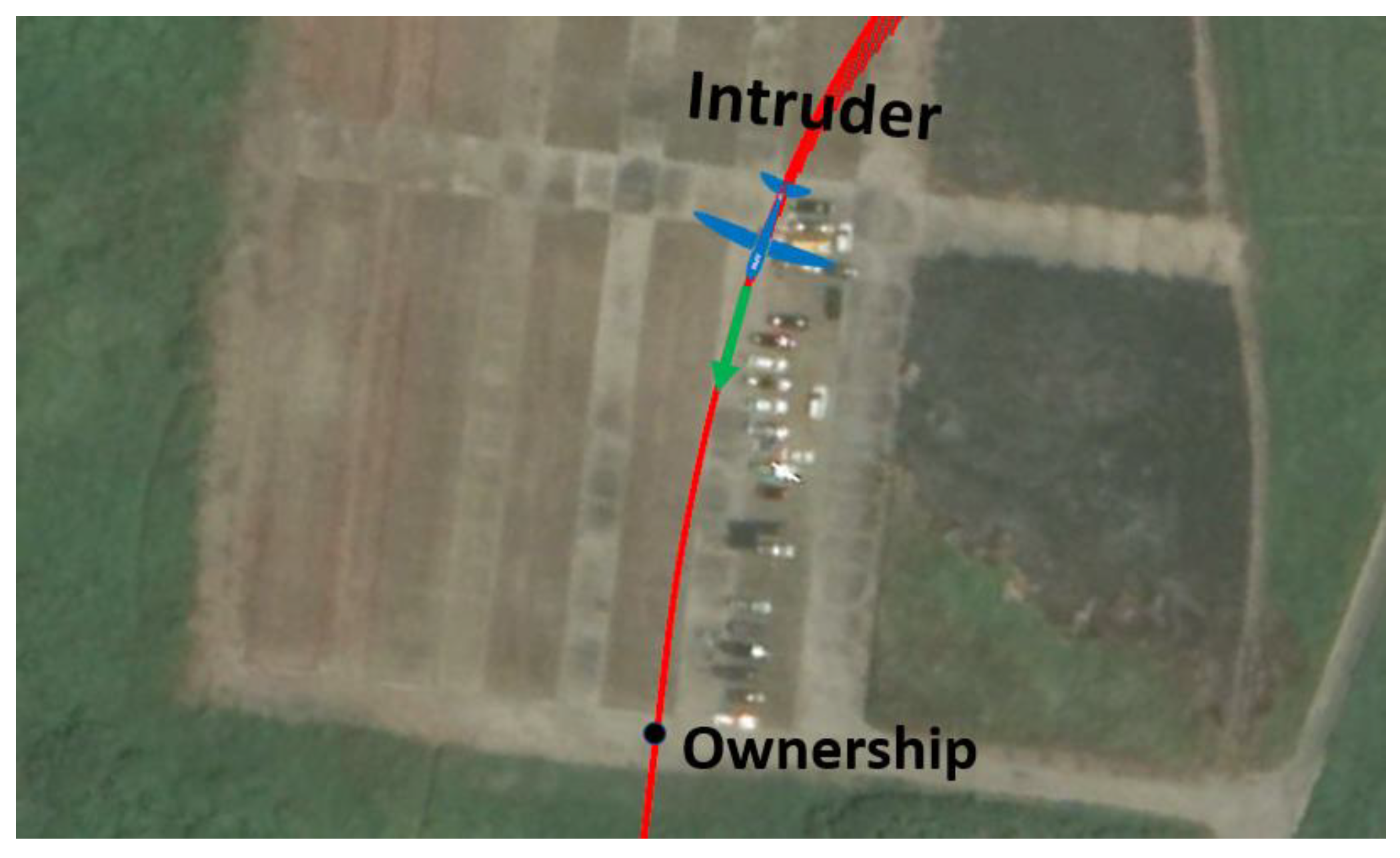{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}