In the experiments, we first introduce the experimental setup, then do ablation study of different super parameter, finally compare our method with the state-of-the-art methods.
4.1. Experimental Setup
In experimental setup, we introduce dataset, evaluation method and implementation details of our experiments.
Dataset: In our experiments, two aerial images dataset are used: iSAID [
44] dataset and mapping challenge dataset [
45]. We use iSAID [
44] dataset, which is a further semantic labeled version for DOTA [
46] dataset. It contains 15 classes of different objects and 1 background class. The spatial resolution of images ranges from 800 pixels to 13000 pixels, which exceed resolution of natural images by far. We train our method with 1,411 high-resolution images, eval with 458 high-resolution images. We use the mapping challenge dataset [
45]. It contains 1 building class and 1 background class. We train our method with 280,741 images, eval with 60,317 images of size 300x300 pixels. We only exploit bounding boxes annotations when training. While the dataset contains labels for semantic segmentation, we only exploit box-level labels.
Evaluation: To evaluate the performance of our method and compare our results to other state-of-the-art methods, we calculate mean pixel Intersection-over-Union(mIoU), overall accuracy (OA), true positive rate (TPR) and true negative rate (TNR) as common practice [
22,
47]. IoU is defined as:
and mIoU is defined as:
and OA is defined as:
and TPR is defined as:
and TNR is defined as:
where
,
,
,
are the number of true positives, false positives, true negatives and false negatives.
C indicates the number of classes.
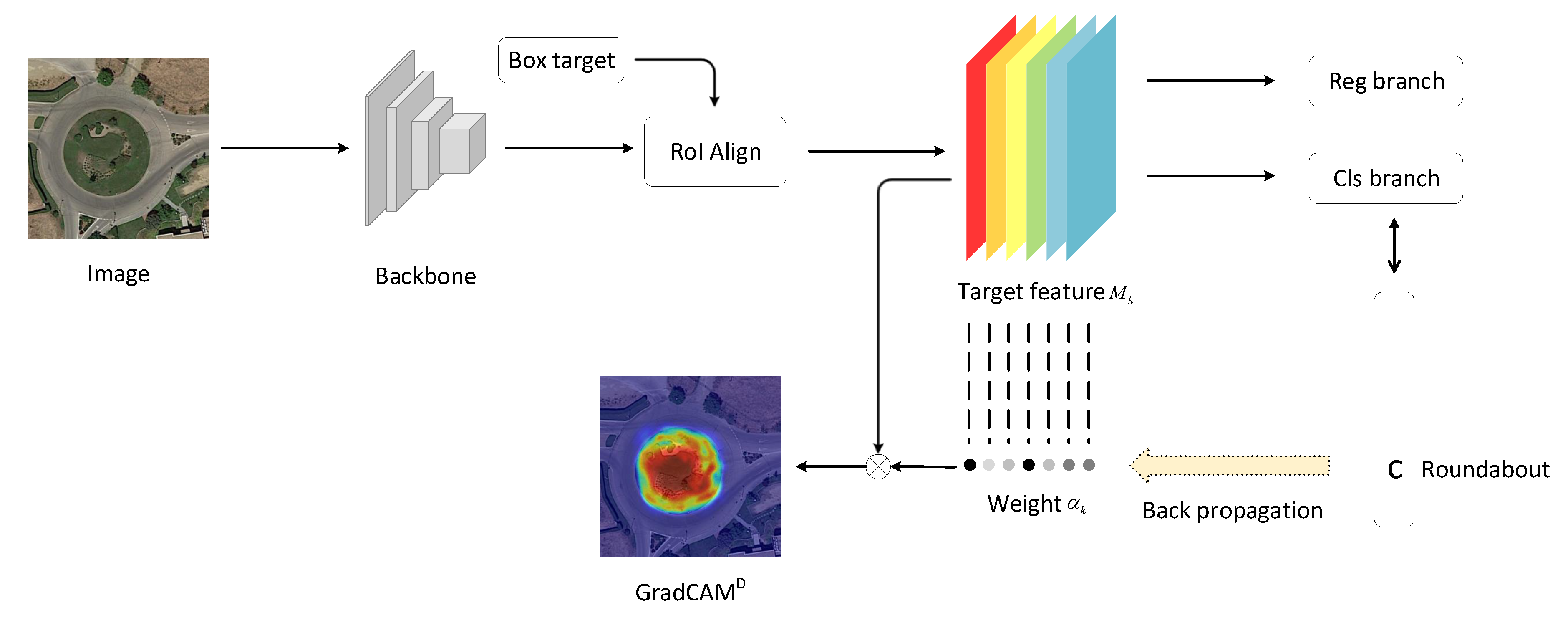
Implementation Details: For iSAID dataset, we crop the high-resolution images to 512 × 512 patches. We adopt the classical Deeplab v3 [
43] model for our experiments, which takes widely used ResNet-50 [
48] as backbone. Firstly, we train a detection model Faster-RCNN [
42] with box-level labels of iSAID [
44]. Using the proposed GradCAM
and GrabCut
methods, we generate pseudo segmentation proposals for train set. Secondly, we train the Deeplab v3 model with the GrabCut
supervision for 50k iterations, further finetune it with proposed loss function for 10k iterations. We choose SGD as default optimizer. Mini-batch size is seted to 20. We set initial learning rate to 0.007 and multiply by
and
is set to 0.9. We apply random horizontal flipping and random cropping to augment the diversity of dataset. We implement our method with the PyTorch [
49] framework. For mapping challenge dataset, we follow the same basic setting as Rafique et al. [
41] for fair comparison. We choose Adam optimizer with learning rate of
,
= 0.9, and
= 0.999. Mini-batch size is seted to 16. We train the network for 3 epochs.
4.2. Ablation Study
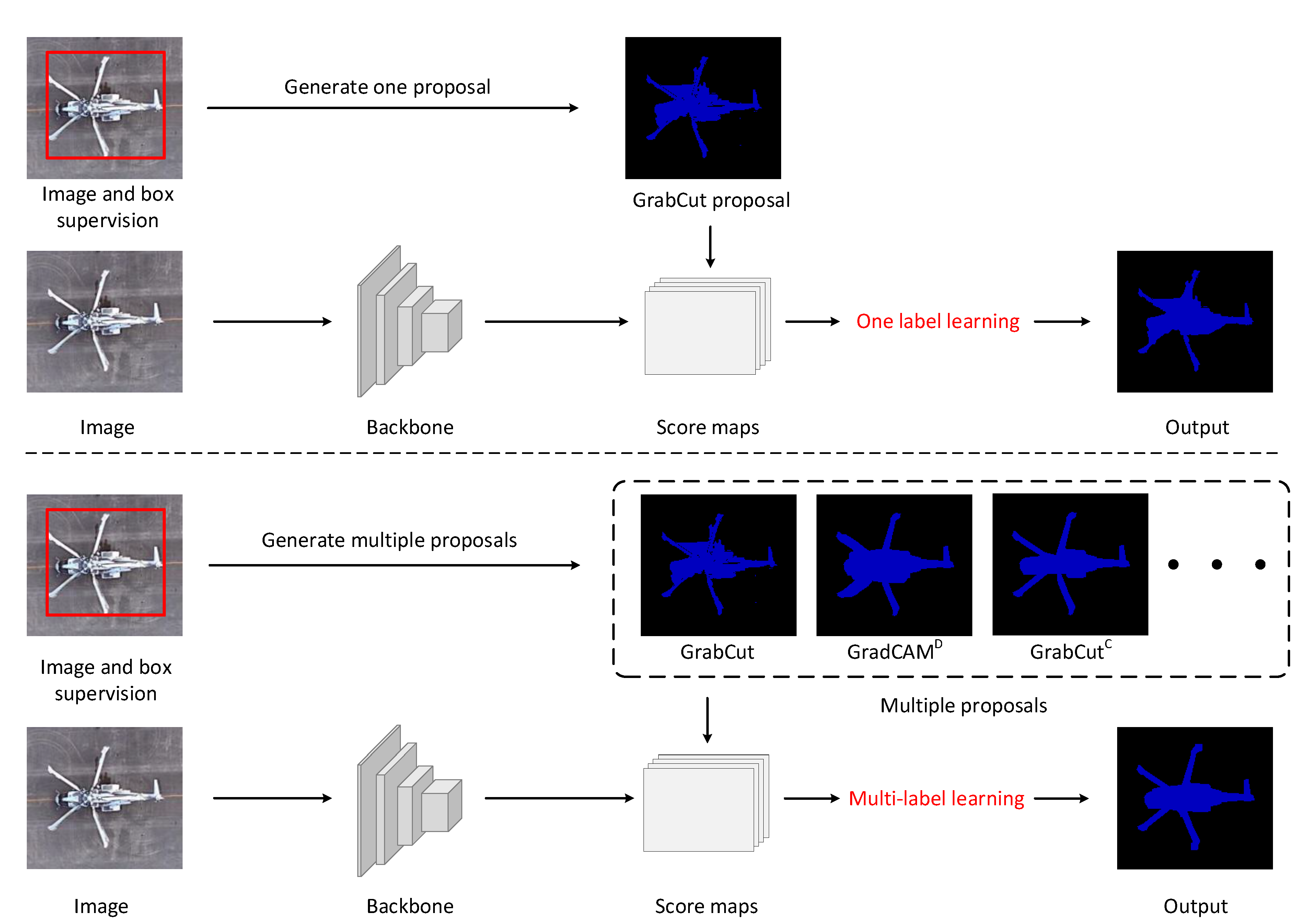
We conduct two types of ablation studies, including the analysis of the contribution of proposed loss functions and the performance of the proposal with different thresholds.
Proposals quality. We do experiments on different proposals and loss functions. As shown in
Table 1, experimental results show that our proposed GradCAM
and GrabCut
proposals perform better than traditional proposals. We train the Deeplab v3 model with different proposals as pseudo labels, including rectangle proposals, CRF proposals, GrabCut proposals, our proposed GradCAM
proposals and GrabCut
proposals. As shown in
Table 1, our proposed GradCAM
and GrabCut
proposals achieve 53.88% and 54.24% mIoU, outperforming all the compared methods. As shown in
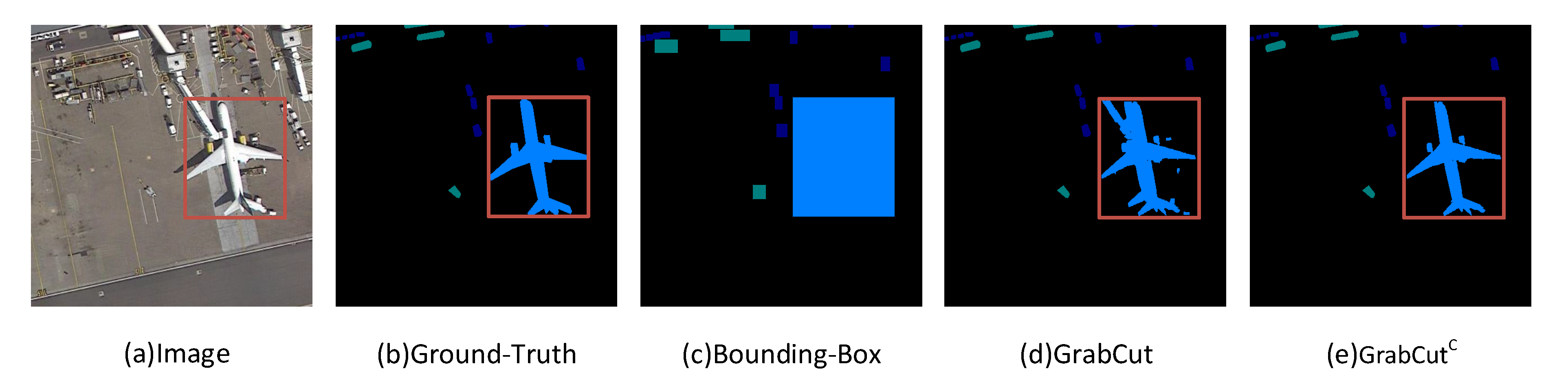
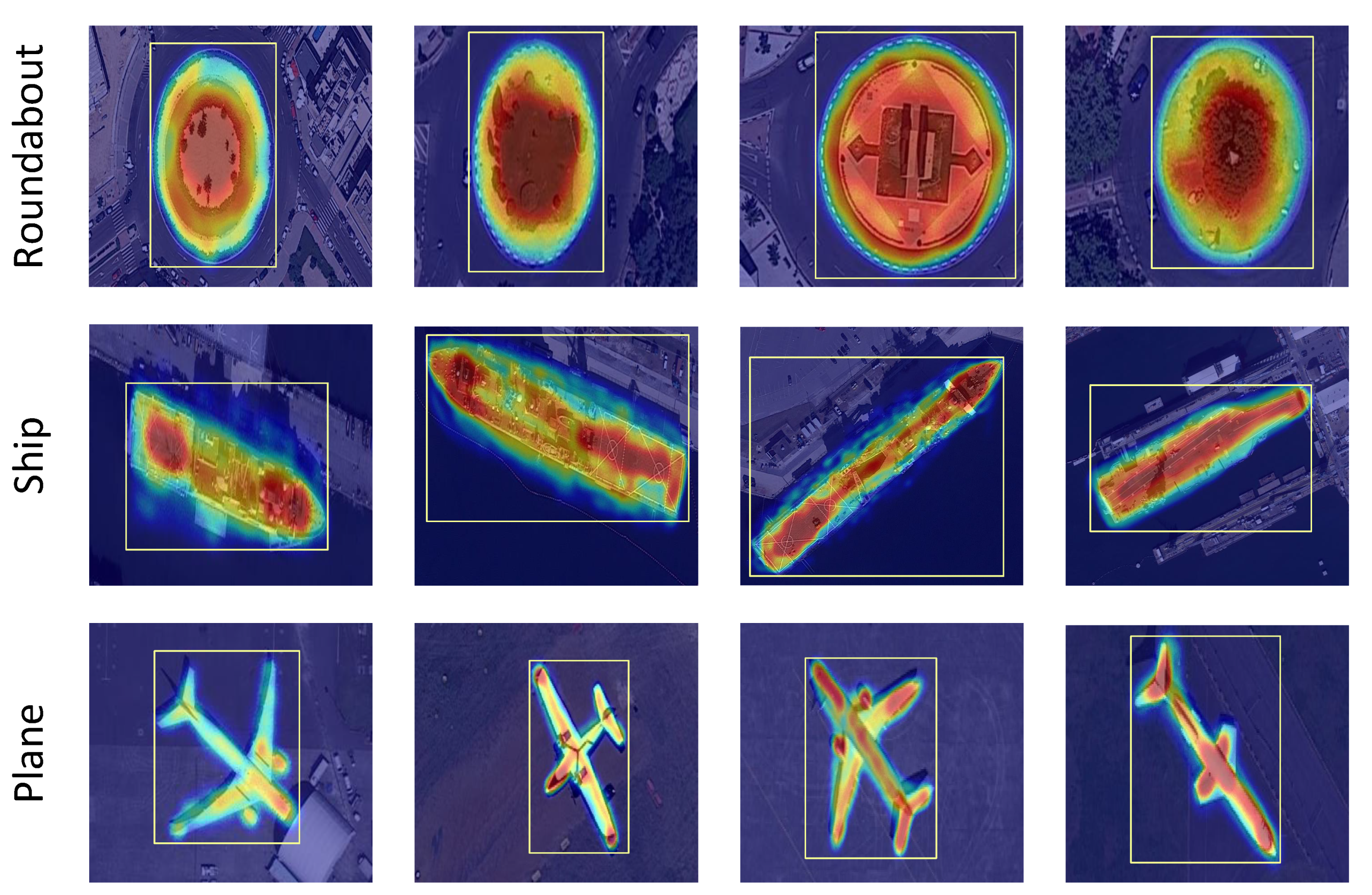
Figure 7, the main difference between GrabCut and our proposed GradCAM
and GrabCut
proposals is edge predictions. Using GrabCut as label, segmentation model will tend to do predictions based on low level features, including color and edge. In hard cases, low level features can not represent precise information of target features, which lead to wrong predictions. GradCAM
and GrabCut
proposals perform better because they are of high level features obtained from object detector. As shown in
Table 2, we evaluate the effectiveness of GradCAM
proposals on iSAID validation set. Our GradCAM
can be seen as a detection-based GradCAM. So we make a comparison between GradCAM
and standard GradCAM proposals within bounding box. Experimental results show that our proposed GradCAM
outperforms standard GradCAM.
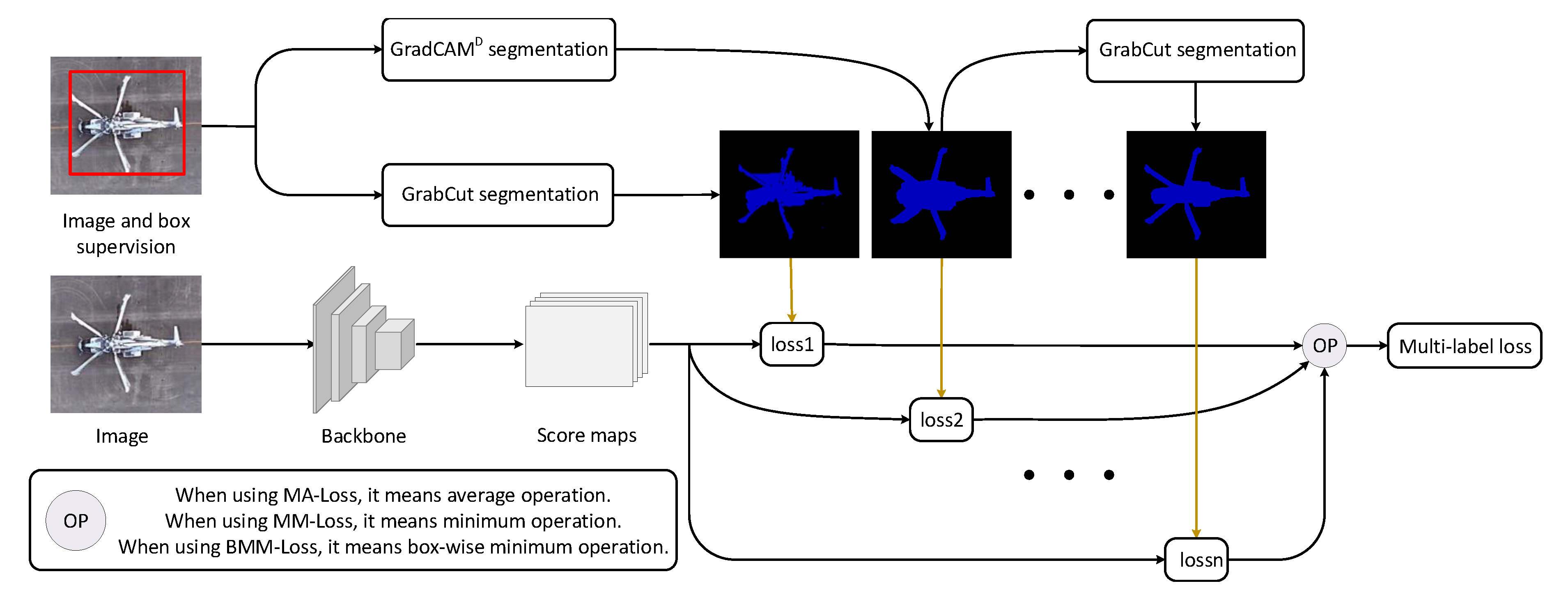
Losses selection. As shown in
Table 1, experimental results show that our proposed MA-Loss, MM-Loss and BMM-Loss all improve segmentation results, in which BMM-Loss performs best. We combine different proposals and use our proposed loss functions to train the Deeplab v3 model. As shown in
Table 1, using a combination of different proposals and our proposed loss functions, we improve segmentation results significantly. In particular, combination of
GradCAM,
GrabCut} and BMM-Loss achieve the best performance, 55.34% mIoU. We analyze that the reason why BMM-Loss performs best is BMM-Loss considers the similarity between predictions and multiple proposals in pixel-wise within boxes. The other loss functions, MA-Loss and MM-Loss, only focus on loss of the whole image. Segmentation performance will not be improved by adding rectangle proposals and CRF proposals to
GradCAM,
GrabCut}. We analyze that compared with
GradCAM,
GrabCut}, rectangle proposals and CRF proposals are quite rough and introduce more wrongly labeled pixels. Low quality of proposals will hurt the performance of segmentation model. We deal with noisy label by automatically selecting the high quality label in training process. It partly solves the problem of noisy label but adding bad pseudo-labels will hurt our performance in practice. There are still many future works that can be done to handle the bad influence of noisy label.
Threshold
of low GradCAM
proposals
. Low GradCAM
proposals
depends on one key hyper-parameter, threshold
. We use
as pseudo label to train segmentation model, which is vital to final performance. The threshold
balances the foreground and background pixels within boxes annotations. If
is set to 0, all pixels within boxes annotations are seen as proposals. As
increases, the area of proposals decreases and only the distinguished part of GradCAM
remained in proposals.
Table 3 shows the influence of threshold
. As
get higher, the area of foreground pixels get lower. Because foreground pixels usually take up most area within boxes annotations, so we find best
in small values. When
= 0.15, using
proposals as ground truth, we achieve the best performance.
Table 1 indicate that
reachs 53.88% mIoU on iSAID validation set. We also fix
= 0.15 in generating GrabCut
proposals.
Threshold
of high GradCAM
proposals
. High GradCAM
proposals
depends on threshold
. We use
as foreground to adjust GrabCut algorithm and generate GrabCut
.
Table 4 shows the influence of threshold
. When
= 0.8, GrabCut
achieves the best performance.
Table 1 indicates that GrabCut
reachs 54.24% mIoU in iSAID validation set.
4.3. Comparison with the State-Of-The-Art Methods
In the comparison with the state-of-the-art methods, we mainly choose SDI [
30], Song et al. [
27] and Rafique et al. [
41].
Results of weakly-supervised semantic segmentation on iSAID dataset. As shown in
Table 5, our method achieves 55.34% mIoU, 98.58% OA, 61.75% TPR and 99.63% TNR on iSAID validation set. Specific IOU for per category can be found in
Table 6.
Figure 8 shows the segmentation results of our method. Our method outperforms all compared weakly supervised semantic segmentation approaches. The results indicate that our proposed method is effective when learning common knowledge from multiple noisy labels.
Results of weakly-supervised semantic segmentation on mapping challenge dataset. We compare our proposed method with existing state-of-the-art weakly supervised semantic segmentation approaches on mapping challenge dataset. As shown in
Table 7, our method achieves 75.65% mIoU on mapping challenge dataset validation set. Our method outperforms Rafique et al. [
41], around 1.31% in mIoU, 0.64% in OA, 0.84% in TPR and 0.33% in TNR.
Figure 9 shows the segmentation results of our method. The results indicate that our proposed method is effective in different datasets.
Results of semi-supervised semantic segmentation on iSAID dataset. We also do semi-supervised semantic segmentation experiments and compare to state-of-the-art approaches. In semi-supervised task, 141 pixel-level labels, 1/10 of the training sets, are added for training. As shown in
Table 5, our proposed method outperforms all the compared methods and achieves 56.76% mIoU, 98.62% OA, 63.25% TPR and 99.64% TNR. Specific IoU for per category can be found in
Table 6. The results indicate that our method is still effective in semi-supervised condition and the performance is very close to the fully supervised model.

 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}