1. Introduction
Crop classification is one of the most important agricultural applications of remote sensing [
1]. Knowing what crops are present in the fields is very useful both at a local and global scale [
2]. For instance, this information is valuable for the design and implementation of agricultural policies [
3], as well as for crop management and food security assurance [
4]. Crop classification is also a pre-requisite for implementing other remote-sensing-based applications at the field scale (e.g., biomass and yield estimation, anomaly detection, etc.). Satellite Earth observations provide information about biophysical properties of the Earth’s surface and their spatial variability with a given revisit time. This constitutes a very rich information source that can be used for identifying the crop types being cultivated and for monitoring them along their growing cycle [
5].
European farmers benefit from the Common Agricultural Policy (CAP) support of the European Union, which started back in 1962. CAP establishes different financing instruments including area-based payments and cross-compliance requirements (Regulation (EU) No 1306/2013). Competent authorities might check whether farmers’ declarations are correct (i.e., they are actually growing the crops they declare on each field and follow cross-compliance requirements). Traditionally, this has been done through field inspections on a sample of fields, constituting an expensive, inefficient and incomplete check system. On June 2018, the European Commission drafted the new modification of the CAP (Regulation (EU) 2018/746) regarding applications, payment claims and checks to be fully implemented in 2020. These modifications recommend the establishment of procedures to check and track all eligibility criteria using Copernicus Sentinels data or similar data. Therefore, several initiatives and research efforts are being conducted at present to fulfill this aim, including EU-funded projects like Sen2-Agri [
6], RECAP [
7] or SEN4CAP [
8].
Indeed, the Copernicus program has been a game changer in this field of research, with frequent observations potentially useful for crop classification (both in the microwave (Sentinel-1, S1) and optical (Sentinel-2, S2) domain), which are acquired systematically over the world and freely distributed [
9]. Their excellent compromise between spatial and spectral resolution, and above all, their enhanced revisit time, through the use of constellations of twin satellites (S1A–S1B and S2A–S2B), make them a unique solution for monitoring dynamic processes like vegetation growth at the scale of agricultural fields.
Until the Sentinels were launched, typical approaches for crop classification were mostly based on the evaluation of the spectral signature of crops obtained from multispectral imagery on key moments of the phenological cycle and their statistical (di)similarity [
10]. However, early studies [
11] already recalled that this approach might have limitations after observing that different fields of the same crop might have different spectral responses due to slight differences in the agricultural management calendar from field to field. In addition, different crops might expose a similar spectral response on a given date, thus, an examination of the multi-temporal evolution of the spectral response of a field was hypothesized as a potentially relevant information for crop recognition [
11]. Yet, the unavailability of multi-temporal datasets with the sufficient revisit time (i.e., 16 days for Landsat) precluded the further development of this type of method until sensors such as MODIS became available [
12,
13]. With the availability of S2 data, similar approaches but with a higher spatial resolution have been developed [
7,
14,
15].
In large parts of the world, remote sensing in the optical domain has been difficult to implement operationally due to persistent cloud cover limiting the number of viable observations along the agricultural season [
16]. Synthetic Aperture Radar (SAR) sensors can be an interesting alternative for those regions since they can operate in cloud-covered and poorly illuminated conditions. In addition, SAR data provide complementary information to optical sensors, reflecting geometric and dielectric properties of vegetation and soil, which have been proven relevant for crop classification [
17,
18]. The first SAR-based crop classification experiences used a few single polarization scenes and generally achieved limited results [
5], but soon after, several studies demonstrated that adding dimensionality through multi-frequency, multi-polarization or multi-temporal SAR observations increased the accuracy of crop maps [
19,
20]. Observation frequency determines the size of the scattering elements that contribute to backscatter [
21], with short wavelengths (X-band) interacting with smaller canopy constituents (e.g., leaves and fruits) than medium (C-band, e.g., small branches and stems) or longer wavelengths (L-band, e.g., larger branches and trunks). The latter might also be more sensitive to soil surface roughness and moisture conditions below the canopy. Regarding polarization, quad-polarized data provided polarimetric features which are potentially interesting for classification and other agricultural applications [
21,
22]; however, dual-polarized configurations might be more efficient for multi-temporal large-area mapping and still provide interesting information for crop monitoring [
23] and classification [
24,
25]. On the other hand, multi-temporal observations of single or dual-polarized backscatter have demonstrated a clear benefit on the accuracy of the resulting classifications [
24], since morphological differences in some particular stages of the phenological development might be key for differentiating pairs of crops that are otherwise quite similar the rest of the year [
18].
Given the actual availability of SAR constellation missions with an extremely short revisit time and high spatial resolutions, classification methods that explicitly exploit time series information have recently been developed with promising results. In effect, supervised classification schemes were developed based solely on time series information, where training data were used to obtain model time series for each class (i.e., temporal signatures) that were later compared with the elements to classify using some type of error metric. This way, Whelen and Siqueira [
26] classified alfalfa, corn and wheat fields over a 10 km × 23 km area using L-band UAVSAR observations, and obtained accuracy values higher than 75% when HV backscatter, entropy or alpha time series were used. Later, using C-band Sentinel-1 data, this approach was refined with a case study over a portion of central North Dakota considering four crops (corn, soybean, wheat and grass/pasture) and obtaining an accuracy of 85% [
27]. In a similar fashion, Xu et al. [
28] classified two corn-dominated sites using Sentinel-1 time series, and obtained accuracies ~90%. In these studies, the error metrics used to compare the temporal signatures with the time series of the elements to classify differed, but only slight differences were observed in the obtained accuracies [
28]. The performance of this classification approach was comparable to results obtained with machine learning algorithms. Yet, the simplicity and robustness of the approach makes it transparent, portable from season to season and resilient to crop growth anomalies. However, further studies were recommended to explore the performance of this approach on regions with a higher crop diversity [
27] and more heterogeneous conditions.
Indeed, the number of crop classes considered strongly impacts the accuracy of the results obtained [
24]. Typically, published crop classification studies based on SAR data considered six different crop classes or less [
17,
26,
28], although some studies had a higher number—however, this was normally below 10 [
25,
29] or 15 [
24,
30]. Furthermore, some studies did not solely address crop classification, as they considered both crop categories and other land covers such as forests, water surfaces or urban areas [
29]. Regarding the number of fields used for training and validation, the published studies differ greatly, although in many cases, they were below 100 [
26,
28] or 1000 [
24,
30]. Few published works considered near-operational applications with 10,000–100,000 fields or more and these used optical imagery [
3,
6]. In addition, the heterogeneity in terms of agro-climatic conditions of the area of interest and field sizes might impact the performance of the approach, as it has mostly been applied to rather homogeneous areas with large fields [
26,
27,
28].
Therefore, the main objective of this study is to investigate the performance of a supervised crop classification approach based on crop temporal signatures obtained from Sentinel-1 time series on a challenging case study with a large number of classes and a high heterogeneity in terms of agro-climatic conditions and field sizes. Hence, the temporal signatures of all crop categories were interpreted and the confusion with other classes was evaluated. The study is framed on a real case study of crop identification for the aid of CAP inspections focused on the Spanish province of Navarre, a region of strong agro-climatic and geographic diversity with pervasive cloud cover. The region was stratified into different agro-climatic regions and different classification models were trained to evaluate the benefits of stratification. Thus, a specific objective of this study was to test whether the differences in crop growing conditions by agricultural region had any influence on the crop classification accuracy. Furthermore, the relation between field size and classification results was investigated. Special attention was also paid to the analysis of results obtained with classification models based on different sets of input data, comparing VH and VV polarizations, but also the VH/VV ratio and implementing an ensemble approach that jointly considered VH, VV and VH/VV temporal signatures.
2. Materials and Methods
2.1. Study Area
The study area covers the agricultural areas of the province of Navarre (Northern Spain). This province has an extension of 10,391 km
2 and it is characterized by its landscape and climate diversity. The Northern area is mountainous, and wet and forests and grasslands are predominant, while the Southern area is dryer and constituted mainly by extensive plains of the Ebro basin, where the proportion of arable land is higher with both irrigated and rainfed agriculture. Between these two areas, there is a transition zone with mixed characteristics. Due to this diversity, Navarre is stratified in seven agricultural regions with distinct agro-climatic conditions [
31] (
Table 1).
Different types of crops are grown in each region. Grasslands prevail in northern regions (1 and 2). Winter cereals are found throughout the whole province, while other winter crops, such as legumes and rapeseed, are common only in central regions (3 and 4). The diversity of crops in southern regions (6 and 7) is larger, where alfalfa, corn, asparagus, horticultural crops and permanent crops are also widespread. Corn, the most common summer crop, is mainly grown under irrigation systems, except in Region 1, where the high amount of precipitation allows rainfed cultivation. Other summer crops cultivated in Navarre are sunflower, found in every region, and rice, only grown in southern regions. It is important to mention that the proportion of fallow fields varies strongly depending on the region, being particularly high in Southern Navarre, especially in region 7.
2.2. Sentinel-1 Data
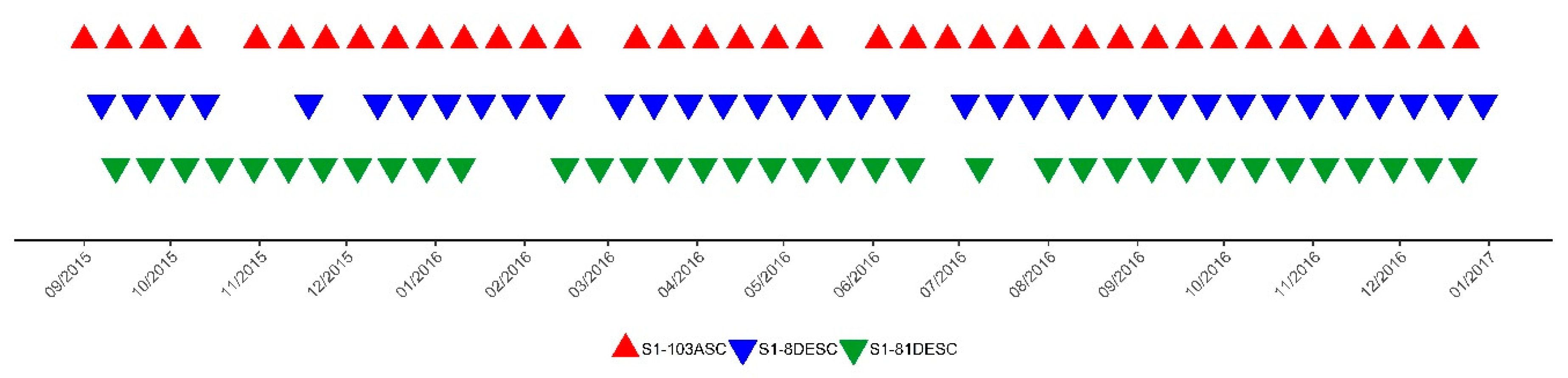
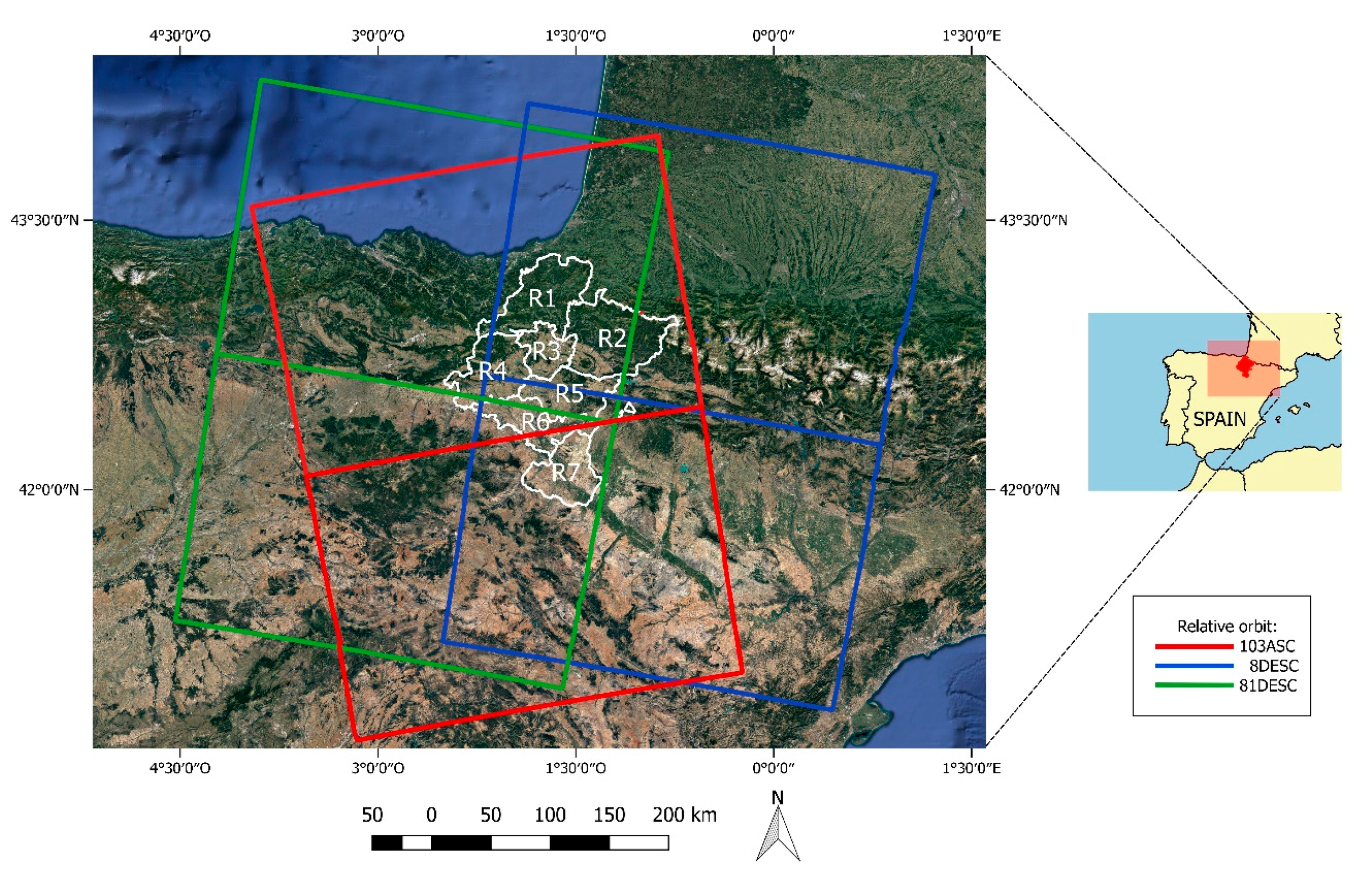
The SAR data used in this study were Sentinel-1 C-band Interferometric Wide (IW) swath mode images downloaded as level-1 Ground Range Detected (GRD) products. All available Sentinel-1 images covering the study area from 1 September 2015 to 30 December 2016 were acquired (
Figure 1). The images belonged to three relative orbits: one ascending node and two descending nodes (103ASC, 8DESC and 81DESC). Yet, only the 103ASC relative orbit covered the entire area of Navarre, whereas the descending nodes excluded a small area of the province from the image, specifically the Western part in 8DESC and the Eastern part in 81DESC (
Figure 2).
The images were processed using SNAP Sentinel-1 Toolbox following these steps: (1) thermal noise removal; (2) slice assembly; (3) apply orbit file operator; (4) calibration to β0; (5) speckle filtering; (6) terrain-flattening; (7) range-doppler terrain correction and (8) subset to the extent of Navarre. The speckle reduction was performed using a 3 × 3 window Gamma-MAP filter. The SRTM 1sec HGT DEM was used for terrain-flattening and terrain correction. After these corrections, terrain-flattened γ0 backscatter coefficient values were obtained. The results of this process were 110 images with three channels each: two backscatter coefficients (VH and VV) and their ratio (VH/VV) in dB units. The pixel size of the final products was set to 20 m. All the images corresponding to the three relative orbits were stacked according to their time.
2.3. Ground Truth and Data Extraction
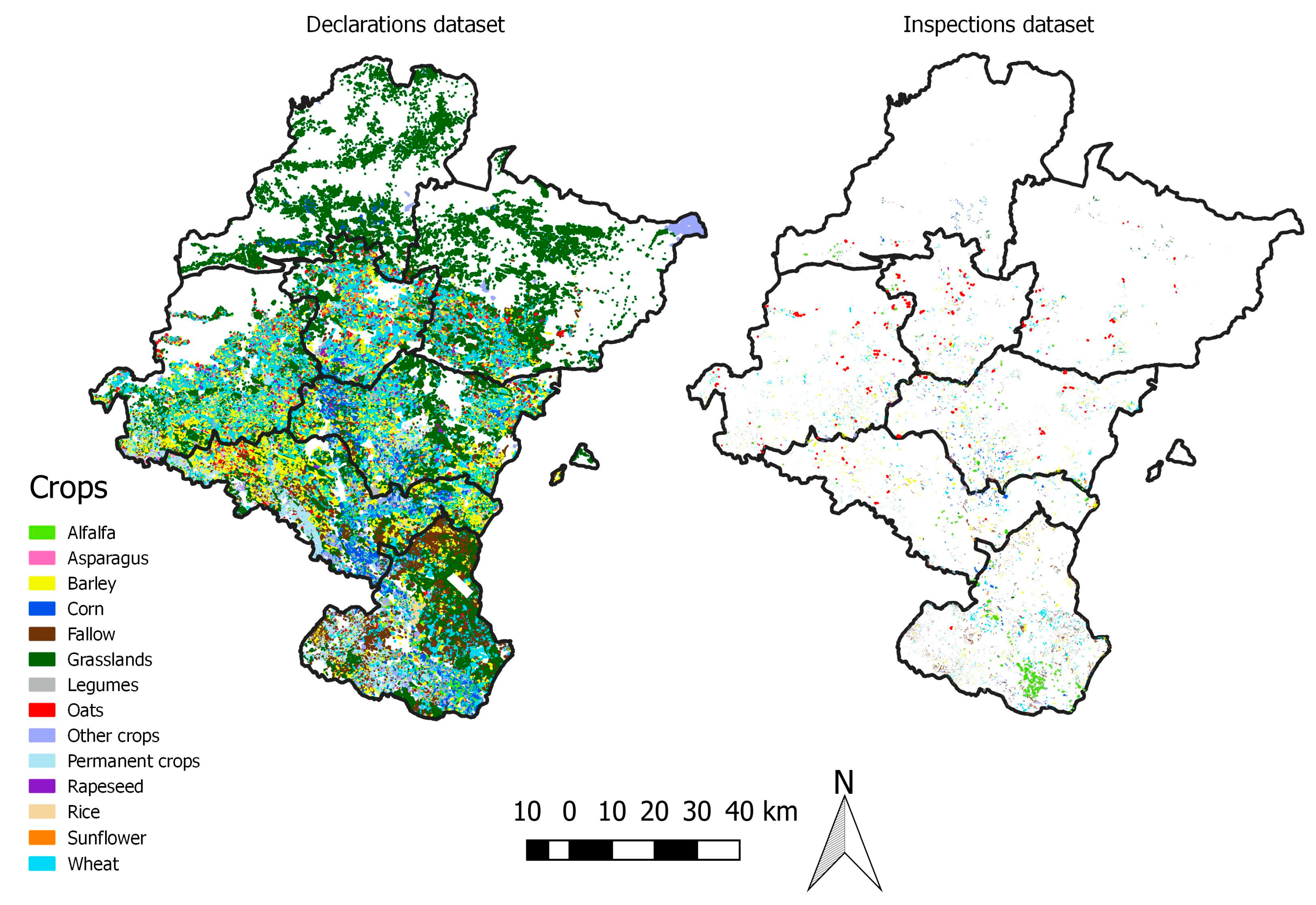
Ground truth information for training and validation was extracted from a geographical database containing field boundary polygons for EU Common Agricultural Policy (CAP) declarations (335,094 polygons) and inspections (21,850 polygons) for the agricultural year 2016. This database was provided by the Agriculture Department of the Government of Navarre (information not publicly available). Field inspections were carried out from June to August 2016, as part of the verifications of CAP subsidy declarations.
The geographical database was refined as follows. A 5 m inside buffer was applied to the agricultural field boundaries in order to avoid mixed pixels that could contain information from different crops. Fields smaller than 0.5 ha were masked out in the declarations dataset. In the inspections dataset, the mask was less restrictive, leaving out fields that contained less than 6 pixels. Then, field statistics were computed, obtaining the median, mean, minimum, maximum and standard deviation backscatters values for the S-1 channels. For each field, a temporal signature with the information of the three relative orbits was obtained. Fields not covered in one of the descending orbits had missing values for those specific dates. Finally, the crops were grouped into 14 classes: alfalfa, asparagus, barley, corn, fallow, grasslands, legumes, oats, other crops, permanent crops, rapeseed, rice, sunflower and wheat.
At most, 10% of farmers’ declarations are expected to be wrong due to errors, fraud etc. [
32]. These wrongly declared fields could affect the training phase by introducing erroneous information in the learning process of supervised classification algorithms. In order to minimize the impact of wrongly declared parcels in the declarations dataset, the 10% of fields whose median backscatter temporal signature differed the most with the median signature of its declared class in each region was discarded. The median was chosen to further reduce the effect of speckle inside the field. The comparison between the temporal signature of the crop and that of each field was based on the R
2 metric. The final number of fields in Navarre is shown in
Table 2 and
Figure 3 (see
Supplementary Materials for the number of fields per region:
Table S1).
2.4. Separability Analysis
As a preliminary step, a feature importance analysis was conducted comparing the statistical features calculated for the different polarizations. For this analysis, the Jeffries–Matusita (JM) distance was evaluated [
33], which provides a measure of separability between pairs of classes and has been identified as a good indicator of crop separability [
34]. The JM distance between a pair of probability distributions is given by the following:
where
JMij is the JM distance between a pair of classes
ωi and
ωj,
x is the feature observed (field backscatter statistics) and
p (
x|
ωi) and
p (
x|
ωj) are the conditional probability functions for
x given
ωi and
ωj, respectively. JM distance values range between 0 and 2, with higher values indicating higher separabilities between pairs of crops.
The JM distances were calculated per date for each pair of crops, for the different polarizations and for the different statistical features. A mean JM distance value was calculated for the whole period of study, averaging the distances obtained for each date. This mean JM-distance was used to compare the importance of the different polarizations and statistical features calculated. Two statistical features obtained the highest separabilities: the mean and the median. The median was chosen for the classification because of its higher robustness to outliers.
2.5. Classification
A supervised classification algorithm based on the temporal signatures of crops was applied. The algorithm is similar in concept to the one used in Whelen and Siqueira [
26,
27] and Xu et al. [
28]. However, there are some significant differences in the way similarity is measured (see below). The basic concept behind this classification algorithm is that crops exhibit physical differences during the growing season due to their phenological development, which leads to different backscatter time series. Thus, the characteristic time series of each crop, as observed by Sentinel-1, is referred to as its temporal signature. This concept of temporal signature somehow mimics the idea of the spectral signature of a crop, i.e., the typical reflectance response of a crop with respect to wavelength. Therefore, we could define the temporal signature as the typical backscatter response of a crop with respect to time. The basic hypothesis is that these temporal signatures are representative of each crop and can be used to identify whether an unknown field belongs to one class or another. In the training phase, the temporal signatures of each crop class were obtained following a three-fold cross-validation scheme using the declarations dataset, where 2/3 of the ground truth samples were used for training and the remaining 1/3 for validation, in three successive random folds. Backscatter time series were formed by adding the information obtained at the three relative orbits used. After this training phase, each field was classified by comparing its temporal signature one by one with the different crop temporal signatures. In fact, each field was assigned to the class providing the best fit between its temporal signature and the crop temporal signature. To quantify the best fit, two variants were explored, the first variant assumed the best fit as the one with the lowest root mean squared error (RMSE), and the second as the one with the highest determination coefficient (R
2). This differed from related studies; Whelen and Siqueira [
26,
27] used a normalized error metric and Xu et al. [
28] used a spectral similarity measure. Here, an error metric (RMSE) and a correlation metric (R
2) were evaluated, as they provide a complementary way to quantitatively compare two curves. Since the crops can have different calendars, the duration of the curves to be compared was adjusted to each crop type (
Table 3). In addition, each crop could be characterized by three different temporal signatures depending on the channel used: VH, VV and VH/VV. Thus, three different classification schemes were applied by considering these channels individually. One additional scheme was explored by considering the similarity to the three polarizations conjointly and named as the ensemble scheme (Ens). Therefore, in total, eight variants were explored (four input features × two goodness-of-fit measures).
In order to test whether the differences in crop growing conditions by agricultural region had any influence on the crop classification accuracy, the supervised classification algorithm was fitted at different spatial extents: first, for the whole province of Navarre, and second, stratified for each of the seven agricultural regions. In the first case, the temporal signatures were obtained for the whole province, whereas in the second, specific temporal signatures per region were obtained.
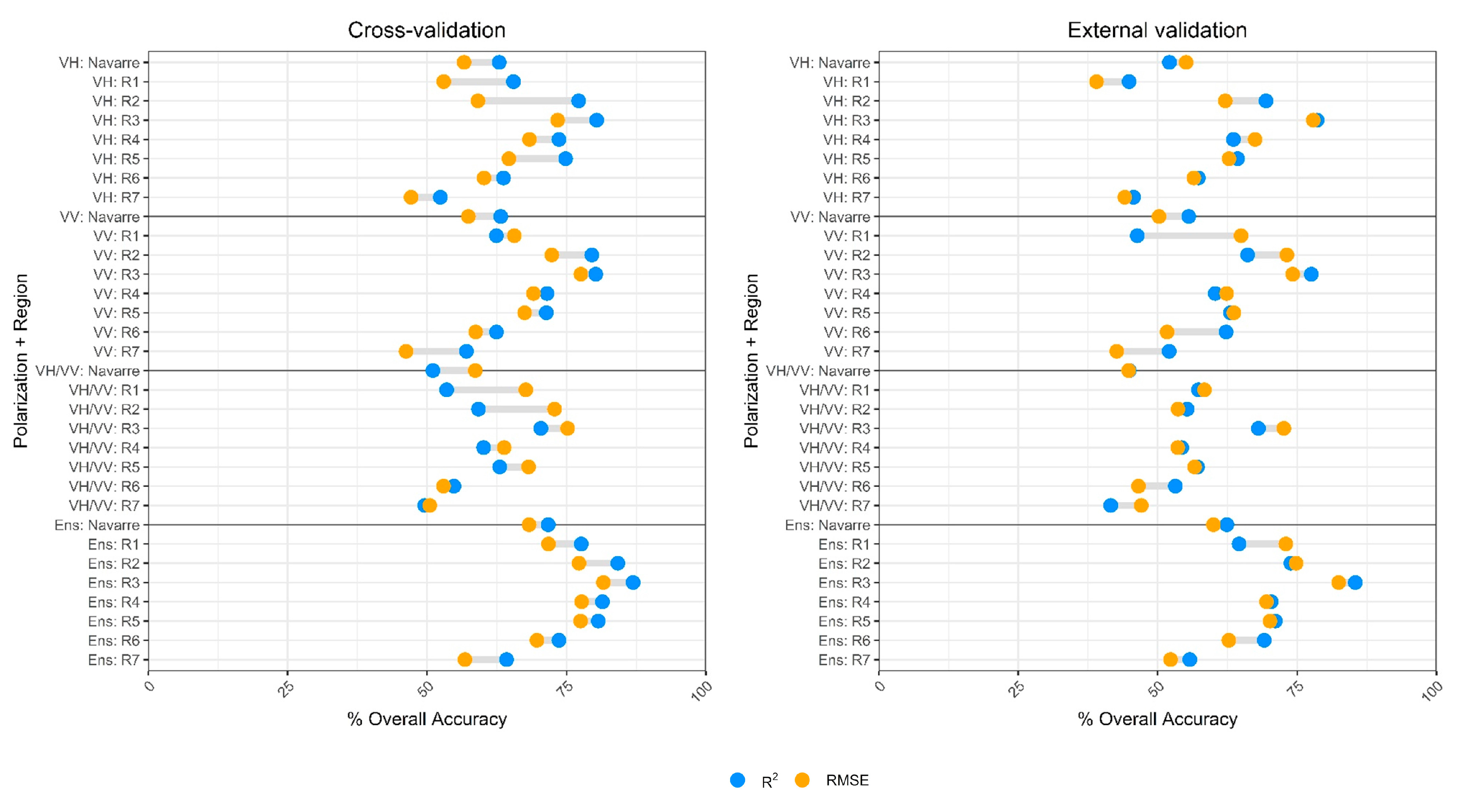
For each classification scheme, the accuracy was assessed through a confusion matrix whereby the Overall Accuracy (OA) was calculated, as well as each crop’s Producer’s Accuracy (PA), User’s Accuracy (UA) and F1-score (the harmonic mean between PA and UA). In fact, a two-level accuracy assessment was implemented. The first level corresponded to the three-fold cross-validation and used the 1/3 ground truth data set left out for validation on each of the three-folds. Additionally, a more rigorous second level validation was performed based on the field inspections dataset available, called external validation. This second dataset was obtained through field visits, thus, its reliability is believed to be higher. However, the sampling did not follow the standard recommendations for accuracy evaluation [
35], and had a higher proportion of fallow, permanent crops and other crop classes (
Table 2), categories that can be more difficult to classify than others such as grasslands with a much lower number of samples. This might negatively impact the OA values obtained. In addition, the size of fields was smaller compared to the declarations dataset (
Table 2). Therefore, the results should be interpreted bearing this point in mind. The accuracy metrics for these two validation levels were reported in the results. Due to the small size of several fields in the external validation dataset, accuracy results were also reported and analyzed by field size considering three size groups: (1) <0.5 ha; (2) 0.5 ha–1 ha; (3) ≥1 ha.
4. Discussion
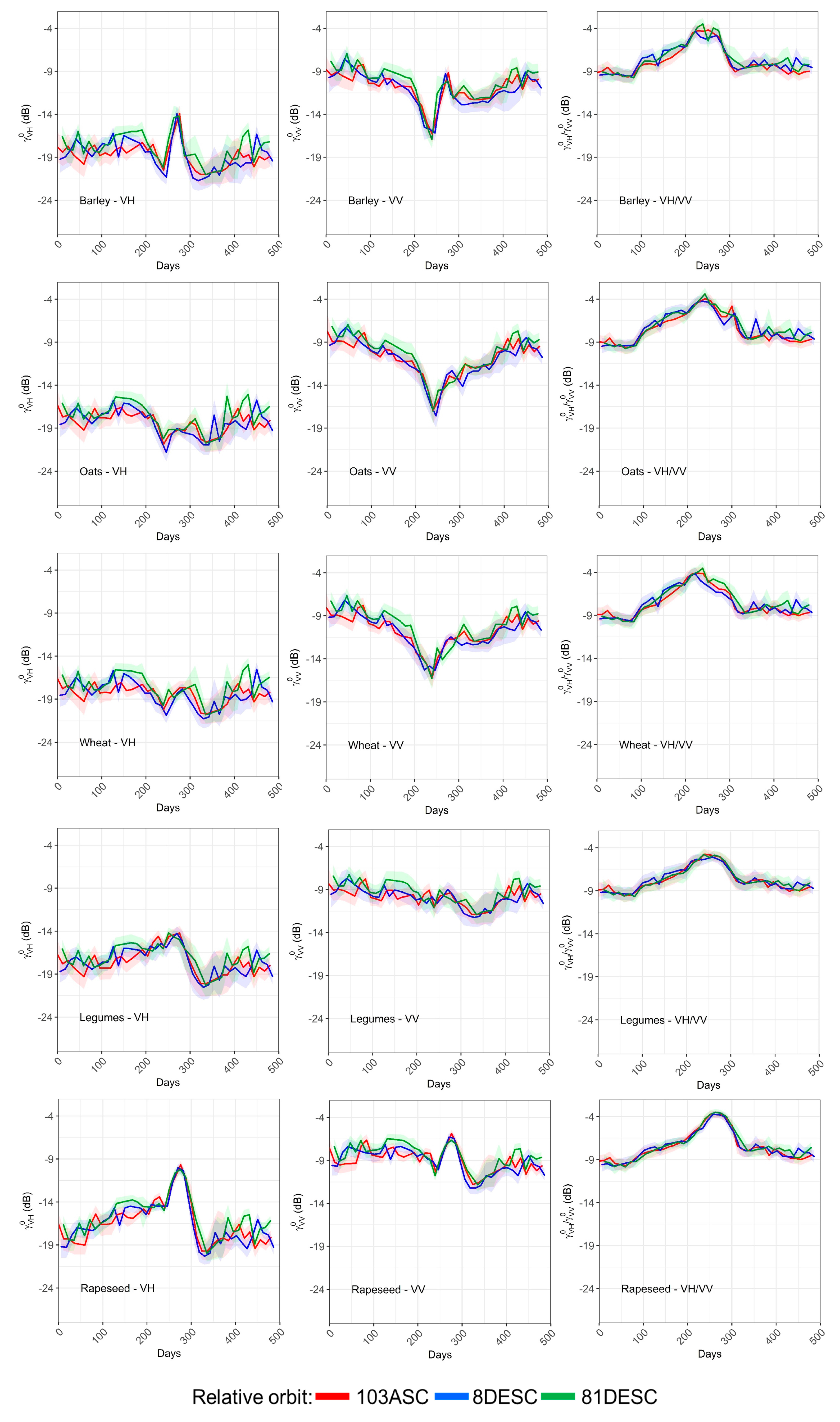
4.1. Crop Classification Results with Regard to Its Temporal Signatures
This study implemented a supervised classification technique based on the temporal signature of crops to a CAP inspection case study on a region with strong agro-climatic diversity. The results obtained varied significantly from crop to crop, with the crops that exhibited any singularities in their time series being the best classified. Cereals, and in particular, wheat and barley, are the most common crops in the region, and showed quite a distinctive temporal signature with a strong decay in backscatter in the stem elongation phase, where surface scattering from the soil was progressively attenuated by growing cereal stems [
36]. This decay was particularly strong in VV, due to the vertical arrangement of stems through the so-called differential attenuation mechanism [
37,
38]. This characteristic decay was followed by an increase in backscatter due to the structural changes experienced by the canopy during the heading stage [
23,
37,
39,
40]. At this moment, a strong and well-defined peak occurred in VH and VV barley time series, probably due to the bending of barley spikes at this phase [
38,
39], which did not occur in wheat and oats that maintained a vertical geometry. From ripening to senescence and harvest, cereal canopies dried-out and a greater penetration [
41] and a higher influence of the soil surface [
37] was observed. The unique backscatter pattern of barley allowed a successful identification with F1-scores of ~85%. Wheat was also adequately identified (F1-score of ~76%), although was sometimes confused with oats, which was the cereal crop with the poorest results (F1-score of ~50%).
The architecture of legumes and rapeseed canopies is completely different from cereals, with heterogeneous shrub-like structures that produce volume backscatter [
39]. This is the reason why VH and VV time series were so different from cereals, although the period of cultivation was the same. Unlike cereals, rapeseed and legumes’ curves in VH started increasing right after the germination of the crop, due to the volume scattering produced by plants [
38,
42,
43,
44]. This behavior changed suddenly for rapeseed at the period of pod formation after flowering, producing a strong peak in VH (and to a lesser extent in VV). In VV, just before this peak, a small backscatter decrease was observed coinciding with the start of flowering, as also reported by Wiseman et al. [
45] and Veloso et al. [
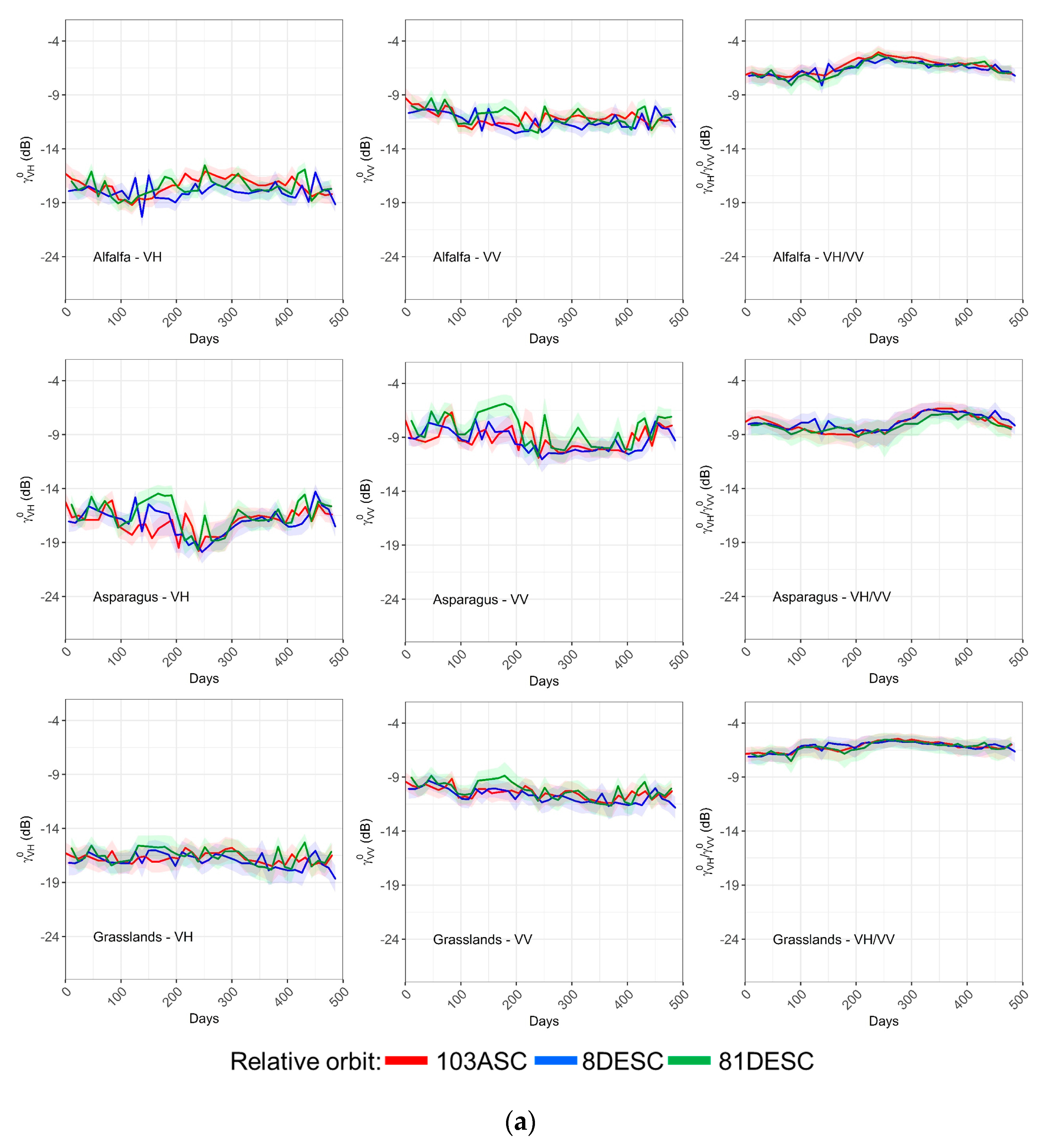
23]. Ripening and senescence produced a strong decrease in VH backscatter (and to a lesser extent in VV) due to canopy drying and a reduction of the volume scattering component. This decrease occurred for both rapeseed and legumes, although it was much greater for the former. Accordingly, classification results were successful for rapeseed (F1-score of ~75%) but worse for legumes (F1-score of ~50%), whose temporal signature was confounded with other crop classes.
Summer crops also achieved good classification results. Corn, with an F1-score of ~75%, was characterized by a rather insensitive VV curve, and on the contrary, a clear increase in VH due to volume scattering during the vegetative growth phase (250–300 days) until the plants reached their maximum height [
46], after which it remained rather constant. Rice achieved an F1-score of ~85%, mainly due to its characteristic time signature due to flooding at the time of sowing, which led to very low backscatter due to specular reflection [
47]. After rice emergence, VV increased rapidly due to double-bounce scattering, followed by a subsequent increase in VH polarization caused by volume scattering from the rice canopy that went on until the end of the season. Sunflower was the summer crop with the poorest F1-score (~60%), but this was not expected due to its rather unique temporal signatures exhibiting both VH and VV sensitivity to crop growth in the stem elongation phase where most vegetative growth occurred (250–400 days). The structure of sunflower, with broad leaves and thick stems with large open spaces between plants, caused both volume and double-bounce backscatter [
48]. Sunflower fields were mostly correctly classified (PA > 85%), but a significant number of grasslands, fallow and other crops fields were incorrectly assigned to sunflower, leading to low UA values.
Asparagus, although having a biannual cycle, had a backscatter behavior similar to summer crops, with an increase in VH in summer (250–400 days) coinciding with the period of vegetative growth. Bargiel et al. [
49] observed an increase in VV backscatter at X-band for this crop during summer, but our data at C-band showed a rather constant VV response. Classification results for asparagus were poor (F1-score of ~25%), mainly due to the incorrect assignment of corn and grasslands fields to asparagus (UA ~20%).
Some categories have a large variability in terms of management or species compositions. For instance, grasslands, alfalfa and fallow are classes where agricultural practices can vary significantly. Grasslands can range from an intensified management (in terms of soil preparation, sowing, fertilizing and mowing) to extensive rangelands that behave more like permanent covers and are only grazed in summer season. Fallow fields can also vary significantly depending on the management applied to spontaneous vegetation, i.e., it might be left to grow or it might be removed either chemically or mechanically. Alfalfa is a forage crop that is mowed several times throughout the season. However, the exact mowing dates might vary significantly from field to field, thus, the mean temporal signature might not be informative for this crop, showing a high variability during the season (the same applies for grasslands and fallow). Surprisingly, classification results were not as poor as expected given the rather unspecific temporal signatures of these crops. The three categories achieved quite good PA values (~70% for alfalfa and grasslands and ~60% for fallow), and UA values were high for grasslands and fallow but low for alfalfa. In fact, a significant amount of grasslands and fallow fields were incorrectly assigned to alfalfa causing its UA to fall. Altogether, such high variability categories should be better addressed by designing field-specific strategies (not based on median class signatures), such as those based on the multitemporal interferometric coherence [
50].
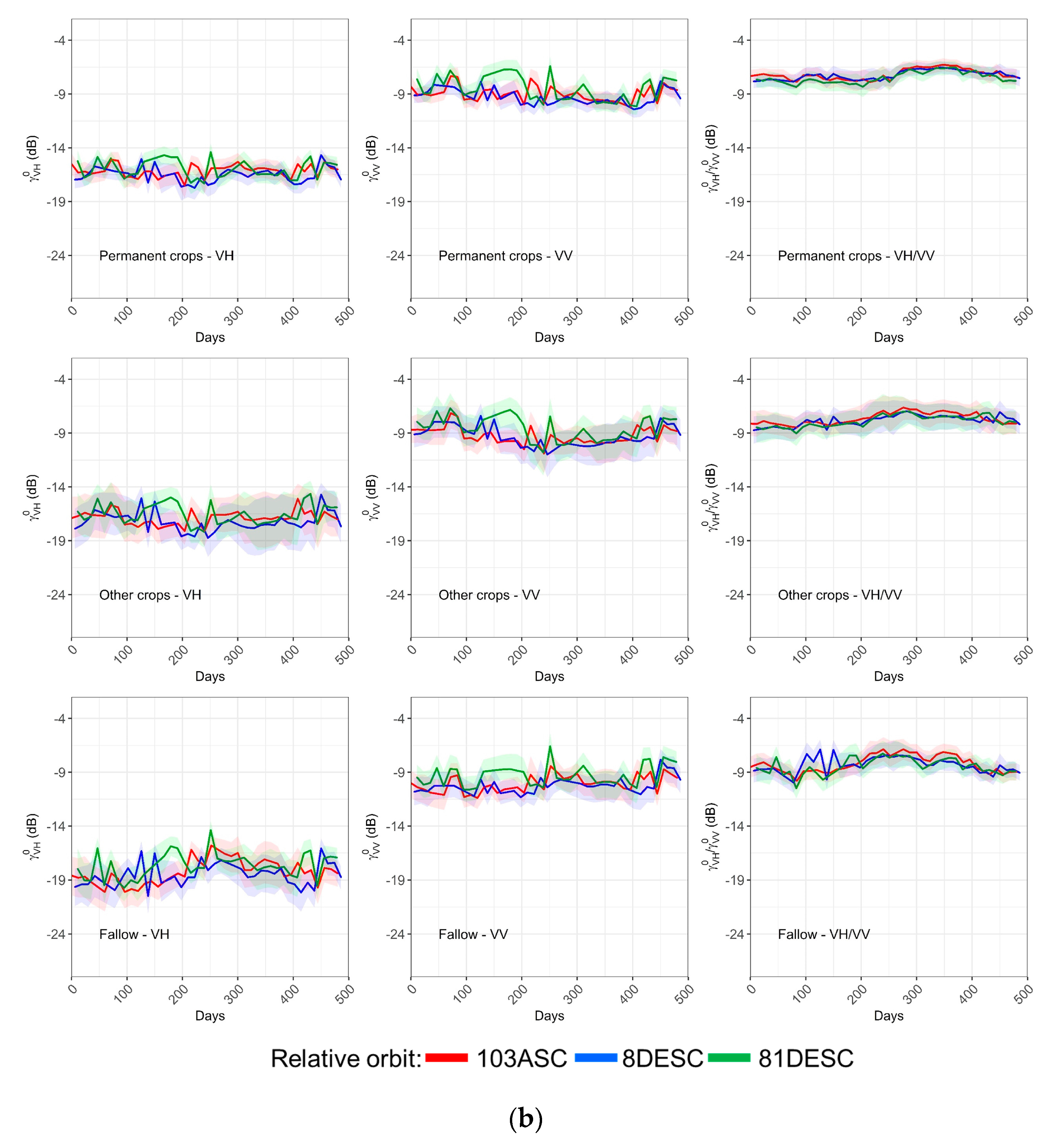
Permanent crops was another heterogeneous class including vineyards, olives and other fruit trees, yet its classification was not too bad (F1-score ~70%). In this case, soil backscatter was predominant due to the open spaces between trees. Thus, during the period of study, the backscatter values presented peaks without a clear increasing or decreasing pattern, probably responding to soil moisture dynamics. Li et al. [
51] also found a stable VH signal throughout the year in almond and walnut trees. During spring and summer, backscatter variations in VH and VV were smoothed, probably due to slower soil moisture dynamics at this time of the year, and because the growth of leaves during this period attenuated soil backscatter.
However, the worst results were obtained by the other crops class, a very heterogeneous category composed of a range of different minor crops, with both summer and winter cycles. Again, in this case, temporal signatures did not show any clear pattern, and in turn, its variability was very large, particularly in summer months. As a result, F1-scores dropped down to ~10%, and other crops fields were confounded both with summer (i.e., corn and sunflower) and winter crops (i.e., wheat and legumes). A redefinition of this class (e.g., splitting it into two more specific categories), could lead to an improved classification of this class, but also to higher UA values for other classes that were mistaken with it.
4.2. General Results
Previous research recommended multi-temporal optical data as the primary source for crop classification [
52], reporting overall accuracies ~12% higher when optical data were used instead of SAR data. Indeed, crop classification approaches based on optical data provided typically accuracies above 75%, as long as imagery acquired in key phenological stages were available [
3,
6,
15,
53]. Yet, optical and SAR data provide complementary information that when combined might result in enhanced classification results [
54]. However, when cloud conditions limit the viability of optical data, SAR observations still provide useful information [
4,
26]. The classification results obtained here were considered successful given the number of crop classes considered, the large number of fields classified and the agro-climatic diversity of the territory.
In this study, the configuration using the three S-1 features as the input (Ens) obtained the best results. For most crops, VH/VV responded positively to crop growth from emergence to senescence. Previous studies already identified VH/VV as a notable indicator of crop development correlated with fresh biomass [
23] and plant height [
55]. Yet, this information was very similar for crops of the same season and did not enable their separation. Therefore, VH/VV might differentiate when a field is vegetated or not, and even the start and end of the growing season, but crops with different morphological structures might produce very similar VH/VV temporal signatures. On the contrary, VH and VV polarizations provided diverse time series depending on different backscattering mechanisms and phenological events of the crops, and thus were more useful for crop classification. In each phenological stage, the structural characteristics of vegetation elements (size, shape, density, orientation) can vary [
51], but also their water content and dielectric properties [
41], in particular in the senescence phase [
23,
26]. VH and VV were useful to identify cereal heading [
56] and rapeseed pod filling. Regarding backscattering mechanisms, VH was sensitive to volume scattering (e.g., in legumes, rapeseed, corn and sunflower) [
26,
51], and can be used as a vegetative growth indicator for these crops [
57]. On the other hand, VV polarization was sensitive to surface scattering and its attenuation by cereals in the stem elongation phase [
17,
37], and also to double-bounce effects on sunflower [
48] and rice [
58]. Rice flooding was also easily detected in both VH and VV [
58]. During the rest of the year, the main drivers of backscatter dynamics were meteorological events, soil preparation practices and harvesting procedures [
26].
4.3. Influence of Field Size
Classification results were clearly influenced by the size of the fields, with fields >1 ha showing an OA improvement of ~14% when compared to small fields (< 0.5 ha). Similar results were already reported in the recent literature [
6], showing that the operational applicability of crop-type mapping based on imagery with a spatial resolution of ~20 m in regions with very fragmented landscapes requires further advances to address the small field issue.
4.4. Regional Stratification
In general, our results improved when the classification algorithm was trained and applied separately to the different agricultural regions, with increments of ~5% in the OA and stronger improvements (10%) in the F1-score for particular crops such as alfalfa, legumes and asparagus. In our case, small and homogenous regions with a rather reduced crop legend and a small proportion of “difficult” categories (other crops, fallow, etc.) obtained the best results (i.e., Region 3). In turn, regions with a larger crop diversity, a higher proportion of fallow fields and more variability in crop management techniques obtained poorer results. In particular, southern regions (Region 6 and Region 7), due to their dryer climate, had a mix of rainfed and irrigated agriculture leading to a larger crop variety (including a higher proportion of other crops and fallow fields), more variable temporal signatures and poorer classification results. This occurred for categories such as winter cereals or legumes, where both long and short cycle varieties coexisted, some of them were intended for forage and some for human consumption. Corn was another category that improved after regional stratification, due to its diversity, with a shorter cycle rainfed corn for fodder production in Region 1 and a longer cycle irrigated corn for grain production in the rest of the province. Altogether, the results of this study showed that in geographic areas with great agro-climatic diversity, crop temporal signatures might change significantly; therefore, operational classification approaches should be applied to stratified regions with less variability.
4.5. Methodological Aspects
Some other methodological details were found to have an influence on the results obtained. First, the use of either R2 or RMSE as the metric for finding the best matching category did not provide consistent results in all cases. In general, the best classification strategies were those using R2. However, we found that RMSE provided the best results when VH/VV was the only input feature used, whereas R2 was better for VH, VV and Ens. The different shape of their temporal signatures (with smoother dynamics for VH/VV) could be behind these differences. Analyzing the results per crop, it was found that oats, rapeseed, legumes and rice obtained significantly better results with RMSE (6–18% improvement in F1-score) when the Ens configuration was used. In contrast, alfalfa, permanent crops, grasslands and fallow had higher F1-scores with R2, and for some cases, differences were minor (e.g., asparagus, barley, corn, sunflower or wheat). R2 might be more insensitive to class variability, with fields with slightly delayed phenology still having high R2 values, as long as they show a similar trend. Furthermore, RMSE might be more sensitive to the actual backscatter values and to abrupt changes in the time series due to particular phenological events or soil moisture variations.
4.6. Future Research
In this study, the duration of the time series was adjusted to the seasonality of the crops to be compared (winter, summer and permanent crops). This aspect was crucial due to the negative influence of the periods without vegetation cover on the variability of the time series. During autumn and winter months, differences in soil preparation dates and techniques (particularly important in furrowed crops such as asparagus) and soil moisture dynamics responding to wetting and drying events [
23] are the main backscatter drivers because vegetation is still short. Furthermore, in the case of summer crops, during this period, spontaneous vegetation might show false dynamics that confound crop recognition. After harvest, some fields might exhibit regrowth of natural vegetation, while some others might be quickly tilled and prepared for the next rotation, thus, this period also introduces uncertainty into the classification. Future improvements of this classification approach might try to further adjust the duration of the growth season, attending to the periods were largest differences were observed between crop classes. Additionally, more attention should be paid in the future to the establishment of the crop legend to classify, since mixed classes such as legumes, other crops or grasslands have shown to be too heterogeneous, resulting not only in their poor identification but also in the confusion with other categories, affecting the overall results of the classification. Finally, further research is required to compare the results obtained using radar backscatter data versus optical reflectance on crop classification strategies like this based on image time series data. Furthermore, a comparison with state-of-the-art machine learning classification algorithms (e.g., Random Forests or Support Vector Machines) will provide interesting information for the selection of the best classification approach in each case study.
5. Conclusions
This paper presented a supervised crop classification technique based on the temporal signatures extracted from Sentinel-1 (VH, VV and VH/VV) time series, and applied it to a large dataset, framed in the CAP inspection process in a region with high agro-climatic diversity.
The results showed that crops whose temporal signatures depicted singularities along the growing season achieved accurate classification results (F1-score ~75%), e.g., winter cereals or rice. VH and VV temporal signatures proved to be sensitive to various phenological events where the structural characteristics or the water content of the canopy varied. In contrast, VH/VV were sensitive to vegetation growth, allowing the determination of whether a field was vegetated or not but providing poor information for crop identification. The combination of VH, VV and VH/VV time series as input features provided accurate results (OA > 70%).
A detailed analysis of the results indicated that field size strongly influenced the results with large fields (>1 ha) achieving ~14% higher accuracy than small ones (<0.5 ha) for the same class. Agro-climatic diversity was also crucial, with results improving when classifications were stratified for local agricultural regions, in particular, for legumes, alfalfa or asparagus. Additionally, crop diversity, variability in terms of management techniques and a high proportion of fallow fields negatively affected the obtained results per region. The definition of the crop legend should avoid heterogeneous crop classes (e.g., other crops or legumes) that were found to be difficult to identify, and affected the UA of some classes with good PA. Whenever possible, these classes should be divided into more homogeneous ones.
Altogether, the obtained results suggest that similar approaches based on Sentinel-1 time series could be implemented operationally in regions with frequent cloud cover, in the framework of CAP inspection, or with any other purposes like crop acreage estimation or ensuring food security. Further studies comparing these results with those obtained using optical image time series, or using state-of-the-art machine learning classification algorithms might confirm this conclusion.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
