1. Introduction
High-resolution remote sensing images can describe the geometric features, spatial features and texture features of ground objects more precisely than traditional ones, which are widely used in various fields. In remote sensing images, buildings are a major part of ground objects and the main component of topographic map mapping [
1]. The recognition and extraction of buildings are of great significance to feature extraction, feature matching, image understanding, mapping and serving as the reference body of other targets. Moreover, the identification and extraction of buildings can provide assistance for mapping, geographic information system data acquisition and automatic updates [
2].
The unique shape of landmark buildings will leave a good impression on people. Furthermore, landmark buildings in the city have the following functions:
(i) Spatial identification. It is used to calibrate the distance, height and azimuth and determines the spatial relationship between the location and the landmark building.
(ii) Spatial identification and space guide. From the orientation and orientation of the landmark, people can determine where they are and where they will move next.
(iii) Cultural meanings. The unique style and the historical background of the landmark building make them stand out from the surrounding buildings and show the area’s unique charm.
In the city, landmarks are the heritage of the history and culture, as well as an effective means of attracting tourists. However, the appearance of more and more landmarks also brings some trouble to this recognition; people need to be able identify these different landmarks to know the cities. Image recognition technology is an effective way to solve these problems. With the advent of the era of big data and the substantial improvement of computer computing power, image recognition technology based on deep learning can not only identify the content of images but also distinguish the scenes in images. For image recognition applications, the most important network structure in the deep learning algorithm is the CNN (Convolutional Neural Network) structure, which has the advantage of enabling the computer to automatically extract feature information [
3]. New York University proposed a convolutional neural network structure for the first time in 1998, which was a milestone in the history of deep learning, and Lenet-5 network laid the foundation for the following structure of deep learning convolutional neural network [
4]. In 2006, Hinton put forward the concept of deep learning [
5]. The emergence of big data improves the size of the data set and alleviates the problem of over-fitting by training. The rapid development of computer hardware greatly improves the performance of computers, and the training speed of neural network is accelerated [
6]. With the great improvement of computer performance and the rapid development of the algorithm, deep learning has achieved excellent results in image recognition. Various kinds of convolutional neural networks have emerged successively—AlexNet (Alex Network) [
7], VGG (Visual Geometry Group) [
8], InceptionNet (Inception Network) [
9], ResNet (Residual Network ) [
10] and DenseNet (Dense Network) [
11]—proving that the change of network structure can affect the final performance of the network to a certain extent. Moreover, the deep learning model with increasingly better performance has been widely applied in image recognition.
Deep learning has been studied extensively by scholars, who have realized the importance and influence of this field. Zeiler et al. introduced a novel visualization technology, which can deeply understand the functions of the intermediate feature layer and the operation of the classifier. This technology is particularly sensitive to the local information in the image [
12]. Ma et al. used features extracted from the deep convolutional neural network trained on the object recognition data set to improve tracking accuracy and robustness [
13]. Cinbis et al. proposed a window refinement method to prevent the training from locking the wrong object position too early and improve the positioning accuracy [
14]. Dai et al. proposed a position-sensitive score graph to solve the dilemma between translation invariance in image classification and translation variance in object detection [
15]. Bell et al. used spatial repetition to integrate contextual information outside the region of interest [
16]. Zhang et al. designed a transmission link block to predict the location, size and category labels of objects in the object detection module by features in the transmission anchor frame module [
17]. Wang et al. proposed an alternative solution by learning a kind of adversarial network to generate examples of occlusion and deformation, while the adversarial target generates the examples that the object detector found difficult to classify [
18].
In 1990s, Irvin and Liow put forward a new idea of building extraction with shadow [
19,
20]. Furthermore, some scholars put forward methods based on artificial intelligence in recent years. The image was segmented and the regional features were extracted by a method combining multi-scale segmentation and Canny edge detection, and buildings were extracted by combining the Bayesian network and other imaging conditions in paper [
21]. In one paper [
22], the image edges were firstly extracted and the spatial relation diagram was constructed, then the Markov model was introduced to construct a Markov random field, and finally, the buildings were extracted by calculating the minimum energy function to set the threshold.
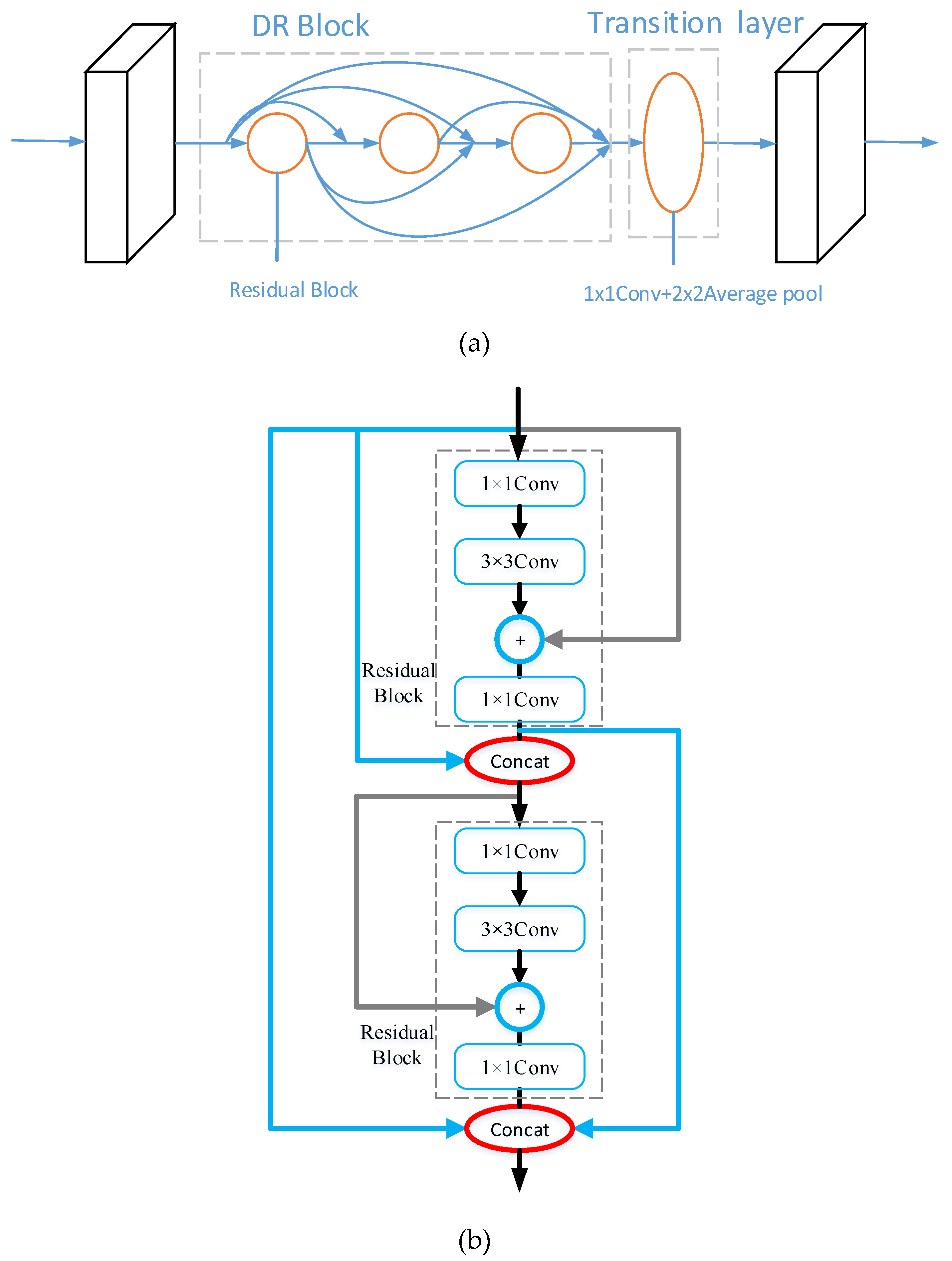
In view of the shortcomings of the original algorithm in building recognition, this paper makes the following two improvements: Firstly, this paper replaces the basic network in the original algorithm with DRNet (Dense Residual Network), which effectively utilizes the edge texture information between the target building and the backgrounds of the lower layer, realizes the repeated use of features and improves the accuracy of feature block; secondly, this paper replaces the original RoI Pooling layer with the RoI Align layer, which reduces the error caused by integer quantization and solves the problem of region mismatch in the original algorithm.
The remainder of this paper is organized as follows:
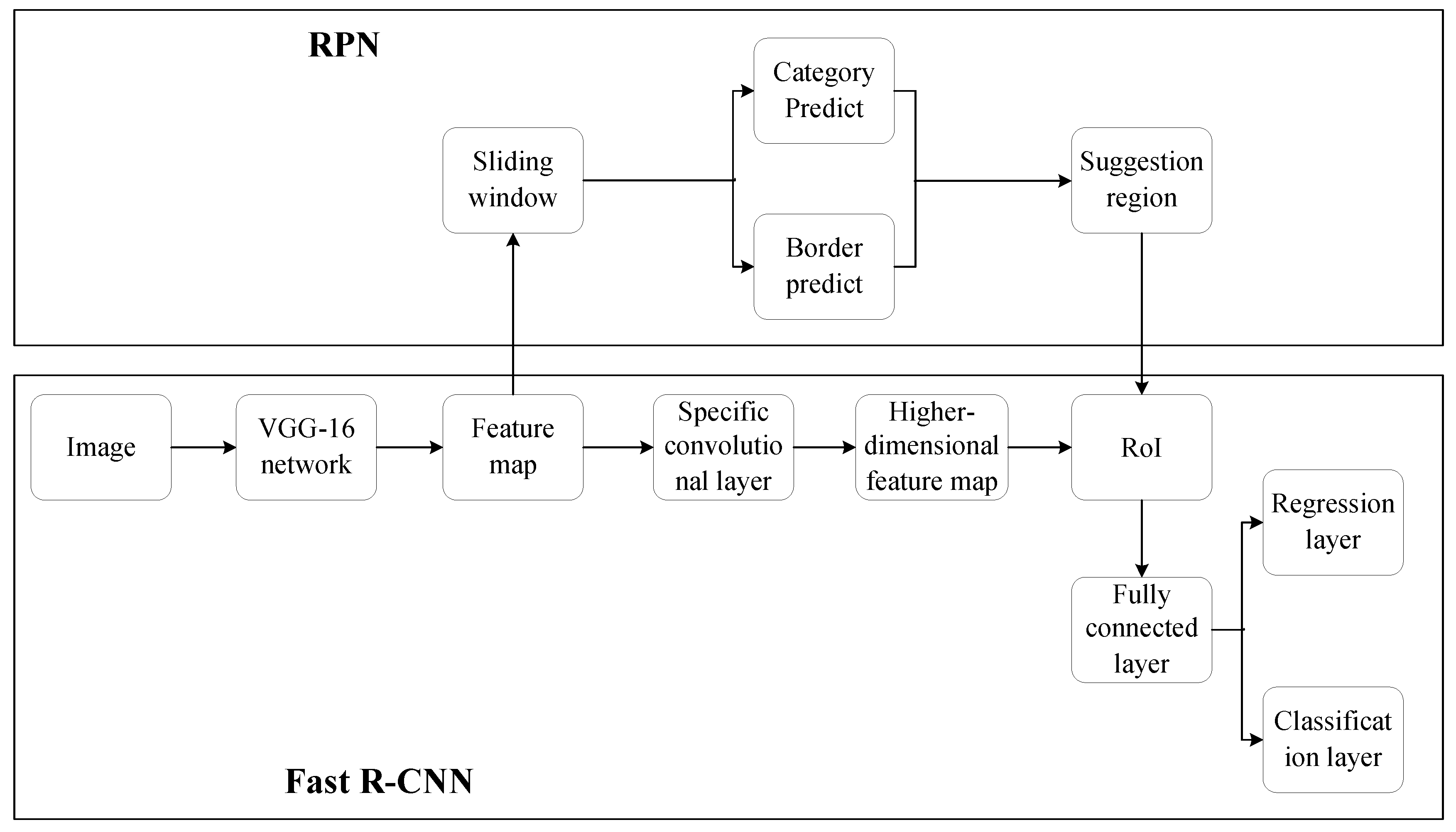
Section 2 introduces the Faster R-CNN.
Section 3 presents the design of the DRNet and the description of RoI Align layer. The simulations and experimental results are validated in
Section 4, and the numerical results are analyzed. Finally,
Section 5 concludes the paper.
4. Image Acquisition and Recognition
The building data set images produced in this paper are from low-altitude remote sensing images taken by UAVs. The size of the images varies from tens to hundreds of kb. In the production of the data set, images of different weather, different illumination and different angles were collected, which adds a certain difficulty to the identification of buildings and ensures the applicability and diversity of the data set. The weather blurs the image of the building and filters out some edge information. The lighting ensures that the building can be clearly seen, and part of the characteristic information of the building will be retained at night. The angle ensures that the deformation of the building is within a certain range. For the collected data set, we adopted the same format as VOC2007 (Visual Object Classes 2007) to annotate.
For the improved faster R-CNN algorithm, since the collected building images are all compressed, the algorithm will resize the building images when inputting the images. Then, the algorithm set the shortest side short_size = 600. If the height of the input image h is larger than the width w, the value of short_size/h = scale is the reference scale. After modification, the value of the height is
h =
h ×
scale and the value of width is
w =
w ×
scale. The advantage of this approach is that the input image is a little larger than the original image, and it has some improvement on the target of small scale due the upsampling of the images [
27].
RPN does not need uniform size of the input feature diagrams; thus, the final output size of candidate diagrams is different. RPN adopts the sliding window to traverse the feature diagram, and the feature pixels on the sliding window correspond to nine kinds of anchor frames. The short side of the input image was adjusted to 600 pixels in the actual processing of the network, and then, the long side of the input image was adjusted in the same proportion. Due to the different sizes of anchor frames, the training process of the RPN can be regarded as multi-scale training in a sense. Then, the traversal result and anchor frame were sent into the full connection layer for classification and regression. The classification and regression, respectively, predict the probability and coordinates of the building in the image. In order to get a high-quality prediction box, this paper filters the redundant prediction boxes base on faster R-CNN, and compares the mark box with the boxes predicted by RPN; the proportion of the overlapped area and the union area of the two boxes is the contact ratio. The contact ratio higher than 0.7 in the image is the positive sample, which contains a clear image of the building, and the contact ratio lower than 0.3 in the image is the negative sample, which is the background image, excluding the building. The buildings and backgrounds are intermingled in the rest of the anchor box; the training model without any contribution should not be used. The rest of the anchor boxes are not being used, due to the fact that buildings and backgrounds were intermingled in the rest of the anchor boxes and they did not contribute to the model training.
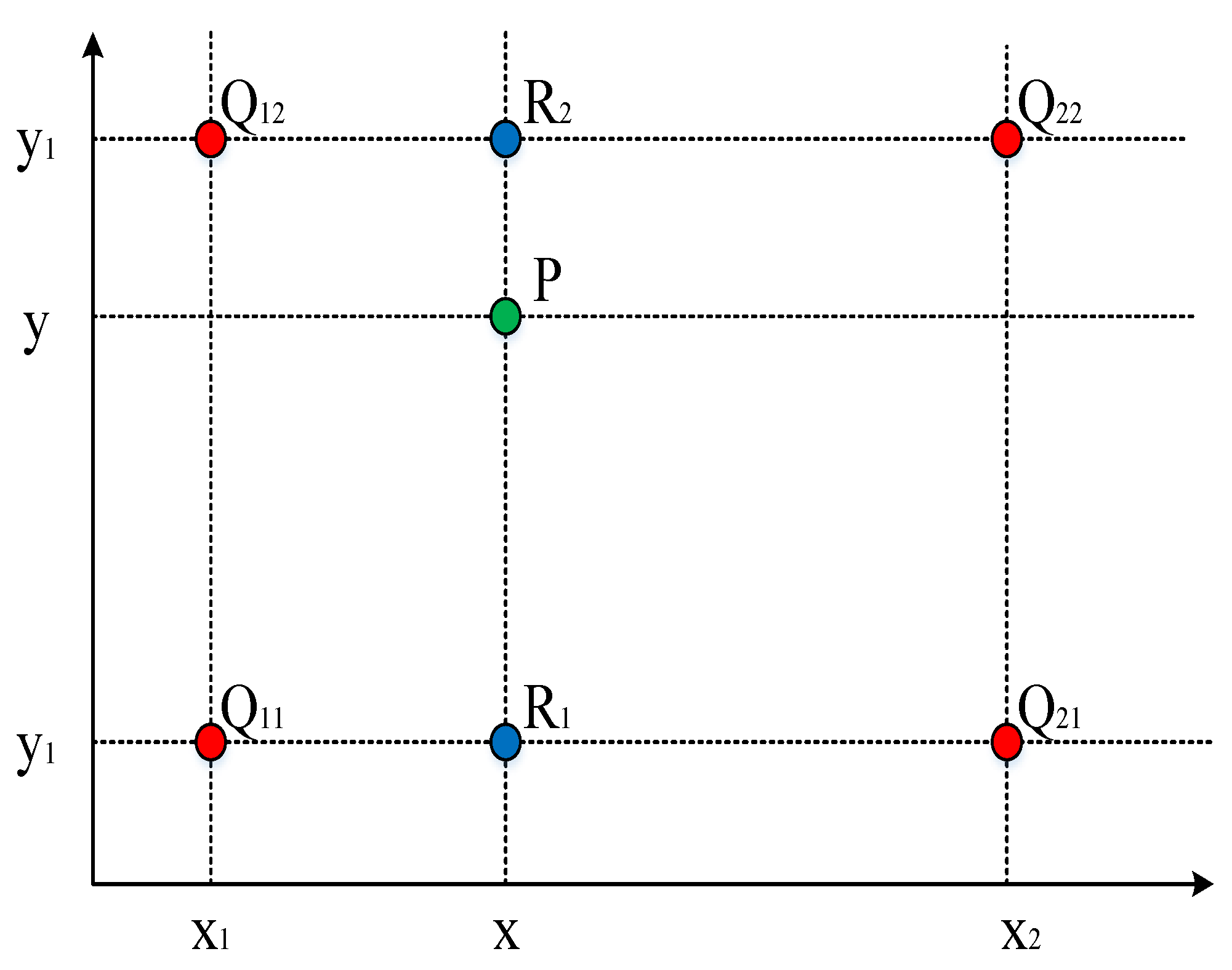
The candidate diagram extracted from the RPN is sent to the RoI Align layer as input and mapped to the previously obtained feature diagram, that is, the position of the candidate diagram is marked on the feature diagram. For these candidate diagrams, 7 × 7 RoI was also adopted. However, each 1 × 1 block was no longer fixed as an integer, and the floating point number was retained, so that the candidate diagrams can be fully presented on the feature diagram. In this way, these more accurate feature diagrams will be classified by the full connection layer and softmax to get the prediction probability of buildings. Our network conducted border regression on the feature diagram again to obtain the candidate box with higher accuracy, resulting in better identification of the coordinates of building. Then, the network eliminated the cross-repetition window by non-maximum suppression algorithm, found out the best object detection position and selected the building whose prediction probability was greater than 0.6. In this way, the network could identify the building and the area in the image.
In the field of deep learning, precision and recall [
28] are widely used to evaluate the quality of results. The precision rate is the ratio of the number of relevant samples retrieved to the total number of retrieved samples, which measures the accuracy of the retrieval system. Recall rate refers to the ratio between the number of relevant samples retrieved and all relevant samples in the sample database, which measures the recall rate of the retrieval system.
The precision rate is defined in terms of the predicted outcome, which means the proportion of the actually positive samples and the predicted positive samples. Therefore, there are two possibilities for the prediction of positive. One is to predict the positive samples as the positive (
TP), and the other is to predict the negative samples as the positive (
FP). The equation of precision rate is as follows:
The recall rate is for our original sample, which means how many positive samples were predicted correctly. There are also two possibilities. One is to predict the original positive samples to be positive (
TN), and the other is to predict the original positive samples to be negative (
FN). The equation of the recall rate is as follows:
The precision-recall (PR) curve is a performance judgment for the models of building detection. It can be judged by comparing the average precision (AP). The AP represents the area under the PR curve. The larger the area, the better the model performance. If we want to determine the performance for all types of the buildings, we can calculate the mean average precision (mAP) for all types of buildings.
In this paper, the remote sensing image contains the target building, and the background outside the target building. Therefore, the target buildings are the positive samples and the backgrounds are the negative samples. In the experiment, the deep learning framework MXNet developed by Amazon was used as the software testing platform. It provides C++ and Python interfaces, and has as important features fast speed, memory saving and high parallel efficiency. The 64-bit Ubuntu18.04.2 LTs operating system was adopted as the test environment and the video card GeForce GTX1080ti 8G video memory was configured. During the training, the model trained 100 epochs of the training set; each Epoch completed one training of the training set, the initial learning rate of the model was set as 0.001 and the learning rate decreased by 10% every 15 epochs.
This paper improved the base network and RoI layer of Faster R-CNN algorithm for building recognition. Therefore, this chapter tests the model from these two points respectively.
Different basic networks improve the performance of the model differently. In order to verify the advantages of DRNet in feature extraction, the paper, respectively, used ResNet, DenseNet and DRNet as the basic network of Faster R-CNN for testing in this section. In order to reduce the influence of other factors, the model was trained with the same experimental data set, iterations and training parameters, completed on the same hardware platform and experimental environment. In the RoI layer, the RoI Pooling was used in this section to extract the feature diagram of a fixed size.
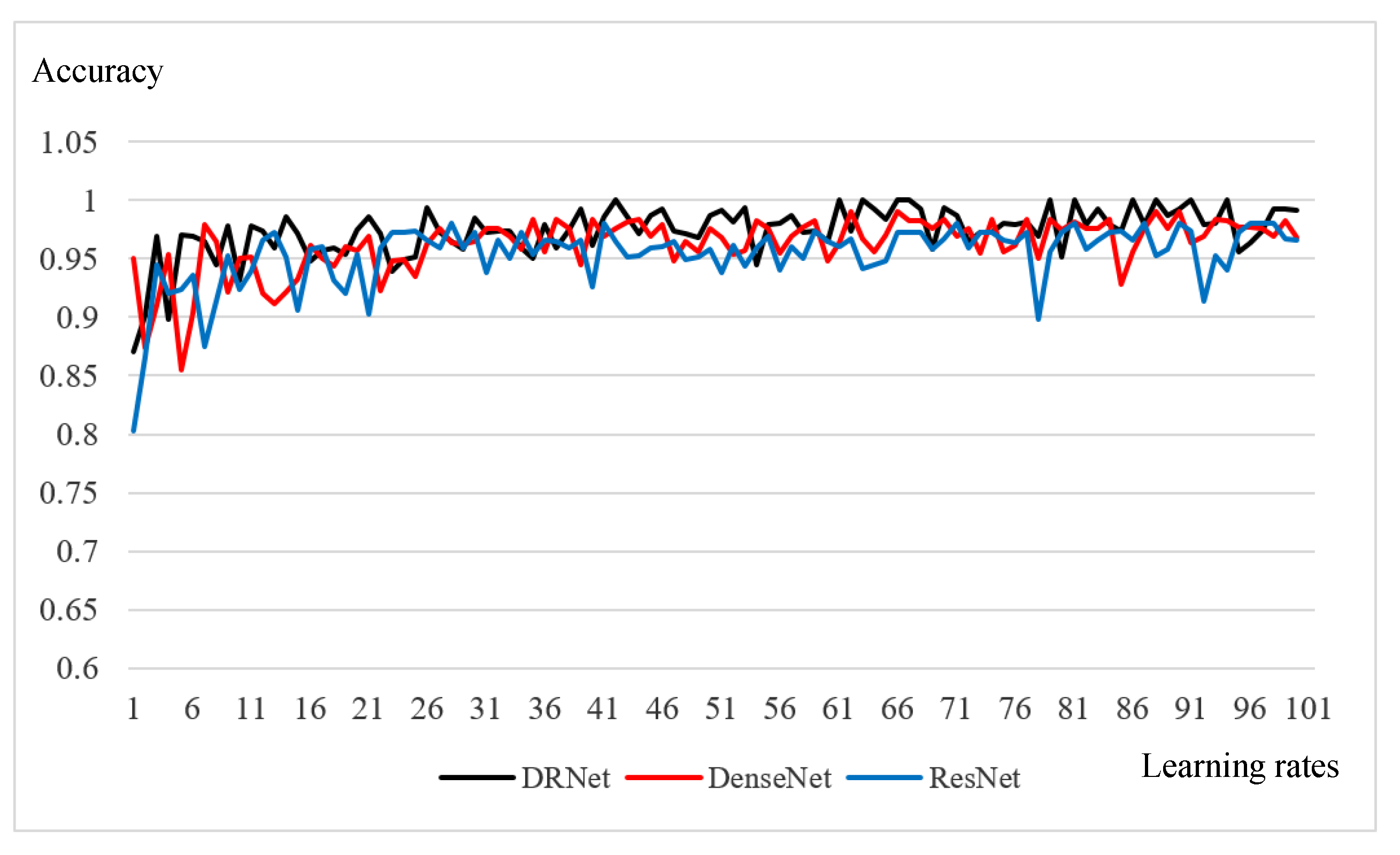
During the training, the training time of an Epoch was approximately 580.8 s for DRNet, 557.8 s for DenseNet and 517.6 s for ResNet. Although the DRNet network was relatively complex, the training time did not increase much. After the training, the accuracy curve of the three networks is shown in
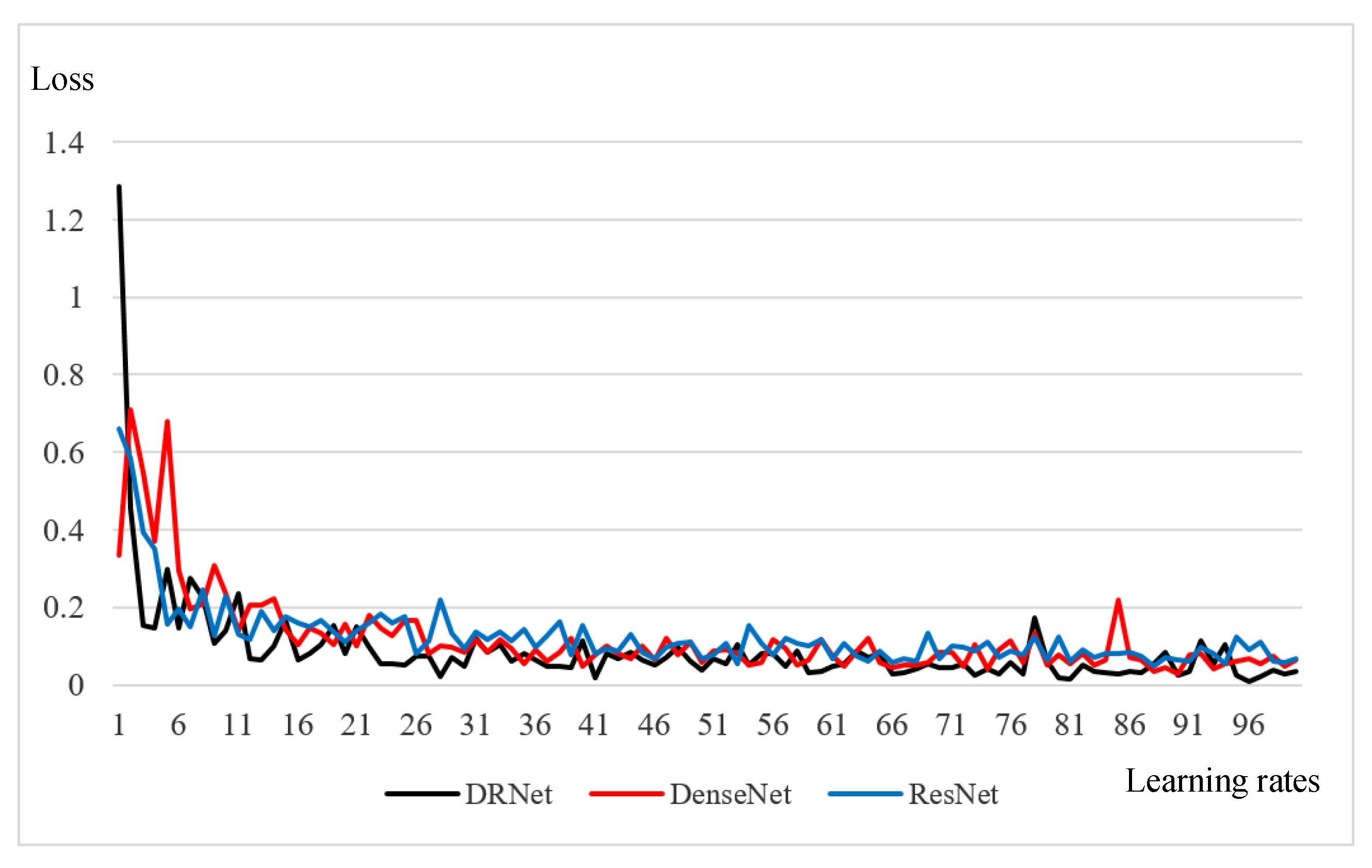
Figure 6. Obviously, the model using DRNet as the basic network has a higher accuracy, slightly better than the other two models, and with the decrease of learning rate, the image disturbance is small. The loss curve of the three networks is shown in
Figure 7. Using the DRNet network model, the loss fell faster than it did in the other two models, and the final loss value was slightly less than the other two models; thus, the training effect of DRNet model is better.
The same test set was used to test the three basic network models, and an example of a PR curve for Potala Palace in Lhasa is shown in
Figure 8. As shown in the PR curve, the building detection performances of three basic network models are acceptable, but it is hard to evaluate which model is better from the curve. Therefore, this paper adopted mAP to evaluate the performances of the three models for different buildings.
As the results in
Table 2 show, the mAP value of the ResNet network is the lowest, only 76.8%, indicating that although this network solves the problem of network degradation and increases the number of network layers, the recognition effect of building images is a little behind. The mAP of the DenseNet model was improved by 1.2% compared with ResNet, because DenseNet can make the high-level network reuse the characteristic information of the low-level network, and the network model becomes more complex. The DRNet network designed in this paper can not only be repeated for low-level feature information, but each DR block can extract more feature information and prevent network degradation; the mAP is increased by 3.8% compared with DenseNet. Obviously, the stronger the ability of the basic network to extract the characteristic information of the building, the better the performance of the model; the basic network of DRNet showed the best ability to extract building features in this paper. As the layer number of network model increases and the network becomes more and more complex, the amount of computation increases, and it takes more time to identify a building; however, the recognition effect is getting better. Additionally, with the improvement of computer performance, this will no longer be a problem.
The size of the building images is not fixed in the data set. If the size of the image cannot be divisible by 16, integer quantization will be done when the RoI Pooling layer carries out feature mapping of the candidate box with fixed size, and there will be some errors between the output feature diagram and the actual feature diagram. The RoI Align layer used in this paper accurately divides the candidate diagram through bilinear difference method. Even if the image size cannot be divided by 16, an RoI Align layer will retain the floating point coordinates of these fixed size feature maps, which solves the problem of region mismatch. In this section, DRNet is used as the base network of faster R-CNN model, and other training configurations are consistent with the above section. The RoI Pooling layer and RoI Align layer are, respectively, used as the RoI layer of the original model for the experiments. After the training, the same test set was used to detect these two RoI layers, respectively, and the results are shown in
Table 3.
Experimental results in
Table 3 show that the mAP value using the RoI Pooling layer model is lower than with RoI Align. This is because the RoI Pooling layer of two integers quantitative caused an area mismatch problem, and RoI Align has some improvement on this problem The mAP values have a 0.3% improvement, so that the recognition effect of using the RoI Align layer is better for the building data sets without fixed size in this paper. Moreover, the number of network layers has not changed, and the recognition time of an image has hardly changed. Part of the test images is shown in
Figure 9.
The left column shows the test result using the RoI Pooling layer, and the right column shows the test result using RoI Align. The model using the RoI Align layer can predict the area of buildings in the image more accurately and in a wider range, and the target buildings are basically in the predicted area. Due to the problem of area mismatch, the prediction of the target building using the RoI Pooling layer has a large deviation, and only part of the target building was included in the prediction box. This also caused the different results of the building detection; the similarity results with the real building in the data set are shown in
Table 4. The RoI Align layer showed great improvement for the last two buildings, namely, 7.47% and 12.72%, respectively.
At the same time, the RoI Align layer model also has a good recognition effect on buildings in complex environments (in fog weather or at night) that are difficult to be recognized by the original model, as shown in
Figure 10.

 ,
, 












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}