1. Introduction
With the fast development of remote sensing technology, hyperspectral sensors are now able to capture high spatial resolution images with hundreds of spectral bands, such as those on the recently launched satellites Zhuhai and Gaofen-5. With narrow and contiguous spectral bands, it is now possible to identify land cover targets at high accuracy. Therefore, hyperspectral images have been widely used in crop monitoring, mineral exploration, and urban planning. To achieve such applications, the primary task for hyperspectral data application is image classification. Due to the high-dimensionality of hyperspectral data, it is difficult to find representative features to discriminate between different classes. To explore robust features in the spectral domain, the principal component analysis (PCA), locally linear embedding, and neighborhood-preserving embedding have been widely used for efficient unsupervised feature extraction [
1,
2]. Meanwhile, the supervised dimension reduction strategies also have been intensively studied to find discrimination features. For instance, non-parametric weighted feature extraction (NWFE), linear discriminant analysis (LDA), and local discriminant embedding (LDE) are efficient in discriminative feature exploration. In contrast to unsupervised feature learning methods, the supervised dimension reduction strategies can explore class-dependent features that could be used for image classification. However, instead of using features in the spectral domain, the spatial features also play an important role in hyperspectral image classification. Therefore, series of spectral-spatial classification methods were proposed, such as the 3D Gabor filters and the Extended Morphological Profiles (EMPs). Although the elaborated spectral-spatial features have demonstrated their capability in hyperspectral image classification, it is still difficult to capture the most effective features while considering the variety of intra-class data. Instead of relying on hand-crafted image features, deep learning has shown its great power in feature learning and image classification. Deep learning frameworks can generate robust and representative features automatically by using hierarchical structures. Consequently, deep learning-based methods have been widely used for hyperspectral image classification. For example, the deep belief network (DBN) and stacked auto-encoder (SAE) are investigated to extract non-linear invariant features. Complementary, the convolutional neural network (CNN) uses receptive fields to explore effective features from both spectral and spatial domains. To enhance this capability, derivative deep models such as ResNet, VGG, FCN, and U-Net also have successfully applied in hyperspectral image classification. However, deep learning frameworks require a large number of training samples, in order to efficiently classify hyperspectral images.
However, the labeled data are quite scarce in hyperspectral datasets, since the label collection involves expensive and time-consuming field investigation. Thus, labeled data shortage is one of the biggest challenges for the task of hyperspectral image classification. According to the Hughes effect, when the dimensionality of hyperspectral data is high, the limited number of labeled samples will result in low classification accuracy. Besides, deep learning frameworks also face the over-fitting problem when feeding with insufficient training samples. To compensate for the effects of labeled sample shortage, the semi-supervised learning and domain adaptation techniques are developed to increase the number of samples. In particular, the semi-supervised learning considers both the unlabeled samples and labeled ones to be integrated for model training. Furthermore, the domain adaptation aims to transfer existing labeled data to be used in new classification tasks. Meanwhile, some works were devoted to generating high-quality samples based on the standard spectral database by considering the correlations between spectral bands [
3,
4]. However, due to the impact of the atmosphere, bidirectional reflectance distribution function (BRDF) effect, and even the intra-class variation, it is difficult to generate realistic samples from the standard spectral library by considering such corrupted conditions when referring to physical models, such as the radiative transfer model [
5].
Following a different strategy, the generative adversarial networks (GANs) aims to mimic and produce high-quality realistic data to increase the number of training samples. Standard GANs consist of two adversarial modules: a generator that captures the original data distribution and a discriminator that tries to make a discrimination between the generated data and the original ones [
6]. To enrich the training samples for hyperspectral image classification, an unsupervised 1D GAN was proposed to capture the spectral distribution [
7]. It is trained by feeding unlabeled samples, which are further transformed as a classifier in a semisupervised manner. Thus, the generator cannot learn class-specific features during the training process. To consider the label information, modified GANs have included the label information, such as conditional GAN (CGAN) [
8], InfoGAN [
9], deep convolutional GAN (DCGAN) [
10], auxiliary GAN (AXGAN),and categorical GAN (CatGAN). Consequently, the conditional GANs have been widely used in remote sensing image processing [
11,
12,
13,
14]. For example, the conditional GAN has been used for data fill in cloud masked area. Meanwhile, for high-resolution remote sensing imagery, a DCGAN-based model was proposed to classify image scenes. In addition, the GAN-based semisupervised model has been utilized for hyperspectral image classification by exploring the information from unlabeled samples [
15,
16]. However, the training of GANs can easily collapse due to the contradictory nature of two-player games. To improve the stability of GANs, a triple GAN was proposed to achieve better performances in discriminative ability [
17]. However, to generate additional labeled spectral profiles, the current GANs are sensitive to noises and neglect the relationships between spectral bands. Besides, the generated samples are often alienated from the original ones which, inevitably fail in boosting classification results.
To solve the above problems, in this paper, we propose the self-attention generative adversarial adaptation network (SaGAAN) to generate high quality labeled samples in the spectral domain for hyperspectral image classification. In general, two modifications have been made in this framework: the self-attention mechanism is included to formulate long-range dependencies [
18] and reduce unintentional noises to stabilize GAN models and the cross-domain loss term is added to increase the similarity between generated samples and the original ones. Therefore, the SaGAAN is able to generate high-quality realistic samples by considering band dependencies and cross-domain loss. Based on the generated samples, better classification results can be achieved.
The rest of this paper is constructed as follows.
Section 2 describes the background of relevant studies.
Section 3 gives the detailed information about the proposed SaGAAN.
Section 4 details the experimental results and comparisons with other methods. Finally, the conclusion is given in
Section 5.
3. Self-Attention Generative Adversarial Adaptation Network
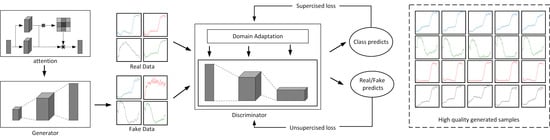
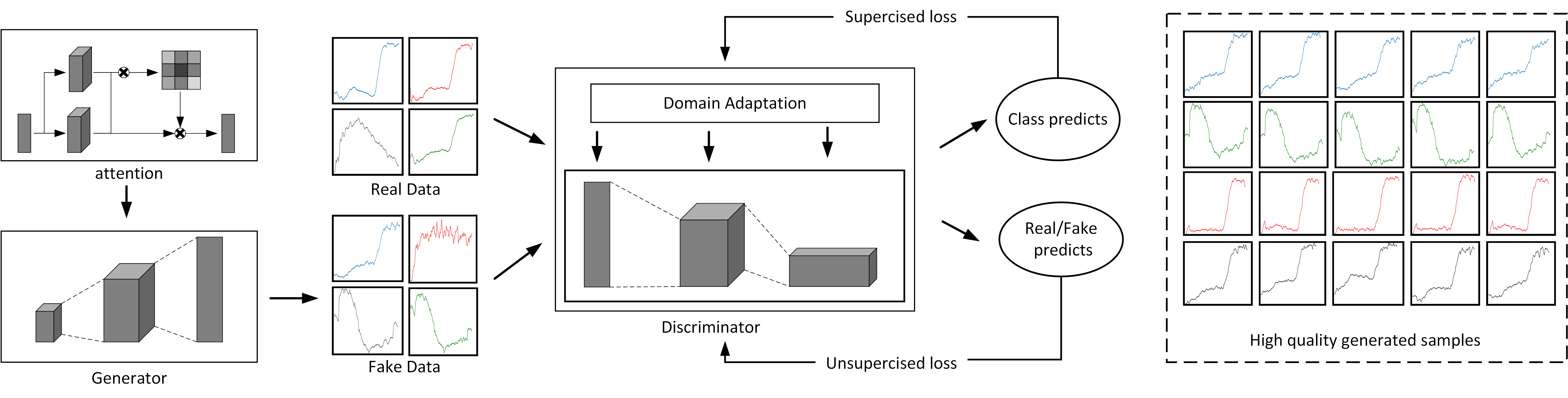
To improve the stability of the traditional GANs and increase the quality of generated samples, we propose the Self-attention Generative Adversarial Adaptation Network (SaGAAN) for hyperspectral sample generation and classification, as shown in
Figure 1. SaGAAN considers both self-attention and domain adaptation to improve the quality of generated samples. Specifically, it is difficult to stabilize the traditional GANs during the training process. Furthermore, the generated samples are often alienated from the original ones. Therefore, to ensure that the generated samples are similar to the input original ones, we introduce the domain adaptation technique to constrain the similarity between generated and original samples. Suppose the generated samples are
and the original ones are
O. To construct the domain adaptation term, for a
N-layer discriminator
D, we have
where
represents the deep features from the discriminator by middle layer activation. To better measure the divergence between generated samples and the reference ones, the maximum mean discrepancy (MMD) loss function applied in this study measures the distances between two probability distributions. The MMD attains its minimum zero if the original data and generated samples are equal.
Suppose the original hyperspectral profiles are
with the data distribution
to be learned. For SaGAAN, the generator
G learns to map a variant
z from latent space to the original data space
with the distribution of
and conditional label
. Then, the discriminator evaluates the sample whether from the original distribution or generated ones. Different from the minimax loss or hinge loss, the MMD loss uses kernel
k to map the discrepancy between two samples. Given two distributions
and
, the square MMD distance have the following formulation
where
are two samples from the generator and
are two samples from the original dataset. The kernel
measures the similarity between two samples. When the generated samples have a distribution that is equal to the original one
,
is zero.
Instead of using MMD as the loss function for adversarial network optimization, SaGAAN calculates the MMD term for domain adaption. Thus, the discriminator
D has the ability to measure the discrepancies between two samples. The objective function for discriminator can be formulated as
To maximize the loss function, the discriminator aims to reduces
that forces generated samples away from the original ones. Meanwhile, the discriminator minimizes the intra-class variance by implementing
and
. Similarly, the loss function for the generator is
The discrepancy between generated samples and the original ones can be reduced by implementing the MMD-based domain adaptation term. However, the generator usually introduces noises from latent distribution and neglected long range dependencies. Therefore, it is still important to consider the band dependencies for hyperspectral sample generation. For SaGAAN, the self-attention mechanism is integrated to improve the quality of generated samples.
In general, the SaGAAN has two improvements compared to the traditional GAN model: the MMD-based domain adaptation for the discriminator and the self-attention mechanism for long-range dependency improvements. The final loss function can be formulated as
For SaGAAN, the conditional adversarial network has been adopted for class-specific hyperspectral data generation. Once the loss function is optimized, SaGAAN can produce high-quality class-specific hyperspectral samples. Different from the traditional GAN, SaGAAN can effectively capture the band dependencies over the spectral domain and reduce noises. Moreover, the generated samples are closer to the original ones with the help of domain adaptation and MMD penalization. With the help of generated samples, it is now able to perform hyperspectral imagery classification without much additional training samples.
4. Experiments
4.1. Hyperspectral Datasets
To demonstrate the ability of the proposed SaGAAN, two well-known hyperspectral datasets were included. These two datasets were collected by the Reflective Optics System Imaging Spectrometer (ROSIS) and the AVIRIS sensor, respectively. Due to the high dimensionality of the above datasets and lack of training samples, it is difficult to interpret them efficiently. The detailed description of these two datasets are as follow.
4.1.1. Pavia University Dataset
The Pavia University dataset was acquired by the ROSIS sensor during a flight campaign over Pavia, northern Italy. The sizes of this dataset are 610 × 340 pixels, with the ground spatial resolution of 1.3 m. There are 103 spectral bands available after removing 12 noisy bands. The spectral bands range from 430 to 860 nm. Nine types of land cover targets were labeled for identification and 10% labeled samples were used for training and another 10% for testing. The pseudo-color composite image and the reference map are shown in Figure 5.
4.1.2. Indian Pines Dataset
The Indian Pines dataset was acquired by the AVIRIS sensor over the Indian Pines test site in northwestern Indiana. The size is the images in this dataset is 145 × 145 pixels, with high dimensionality in the spectral domain. The sensor system used in this case measured pixel response in 224 bands in the 400–2500 nm region of the visible and infrared spectrum. Due to atmospheric absorption, after removing noisy bands, 200 spectral bands are left for data analysis; 10% labeled samples were used for training and another 10% for testing. The pseudo-color composite image and the reference map are shown in Figure 6.
4.2. Configuration of Sagaan
To serve the purpose of hyperspectral sample generation, the SaGAAN framework is developed based on a 1D generator and a discriminator. To capture the data distribution over spectral bands, SaGAAN converts noises from latent space to realistic spectral profiles. The configuration of SaGAAN is illustrated in
Table 1. Compared to the traditional GANs, SaGAAN uniquely pays attention to long-range dependencies and domain adaptation for high-quality sample generation. For the attention term, it is integrated inside of the generator to reduce noises and consider long-range dependencies during sample generation. Meanwhile, to ensure the generated samples are equilibrium to the original ones, the domain adaptation term is added inside of the discriminator. Due to the nature of deconvolution operation, we added an additional band to make sure the number of spectral bands is an odd number. Moreover, to better illustrate the effectiveness of SaGAAN, we included other sample generation approaches (the traditional GAN, self-attention GAN (SAGAN), and adaptation GAN (ADGAN)) for comparison.
4.3. Effect of Domain Adaptation
Domain adaptation is one of the most important factors for high-quality sample generation. Due to the difficulty of adversarial network training, the generated samples are often alienated from the original ones. Therefore, how to reduce the discrepancies between generated samples and the original ones is the major challenge for successful adversarial network training. In SaGAAN, the discriminator contains an additional term to measure the feature distances between generated samples and the original spectral profiles. Specifically, the discriminator D as a 1D convolutional neural network (CNN) has L hidden layers. For each layer, the deep feature can be represented as , and the feature distance between generate samples and the original ones are . Thus, SaGAAN is able to produce realistic samples based on the similarity measurement. To better illustrate the effect of domain adaptation term for SaGAAN, we developed two separate adversarial networks for hyperspectral sample generation with/without domain adaptation.
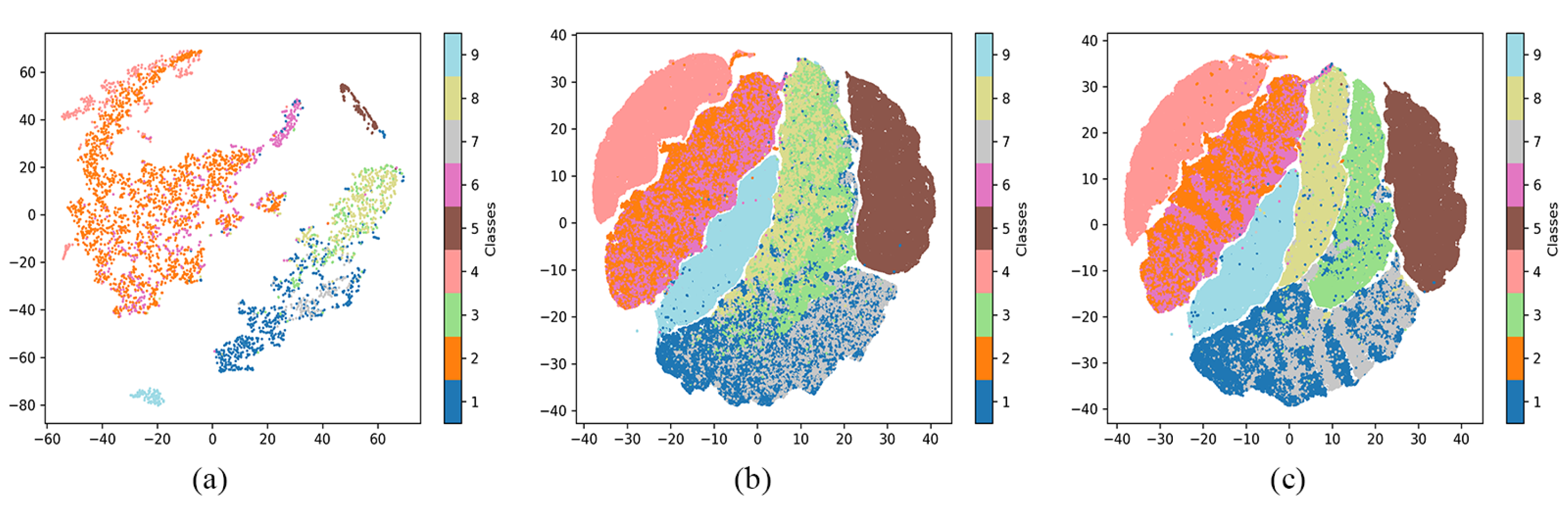
For convenience, we tested the domain adaptation term on the Pavia dataset by using the training dataset. Each network generated 0.2 million hyperspectral samples in total, which was about 22 thousand samples for each class. We mapped the generated samples into the lower dimension for better illustration, as shown in
Figure 2. We can conclude that the projection map from domain adaptation samples has clear boundaries between different classes. Without domain adaptation, the generated sample often mixed together, which failed to guide supervised classification. Especially, for Classes 8 (Bitumen) and 3 (Self-Blocking Bricks), the inter-class similarity has been significantly reduced. Meanwhile, intra-class variation such as for Classes 1 (Asphalt) and 7 (Bitumen) also has been greatly suppressed. Therefore, domain adaptation is a major improvement in generative adversarial networks since it considers the mismatches between generated samples and the original ones.
4.4. Effect of Self-Attention
Hyperspectral data contain hundreds of spectral bands that have long-range dependencies (e.g., vegetation has high reflectances in near infrared bands compared to the red band). However, the traditional GANs only pay attention to mimic spectral reflectances at local scales which neglected the relationships across spectral bands. Moreover, traditional GANs introduce noises that also impact high-quality sample generation. Different from domain adaptation, the self-attention mechanism focuses on capturing long-range dependencies between spectral bands. Meanwhile, the self-attention reduces unwanted noises and makes the curves of generated hyperspectral samples smoother.
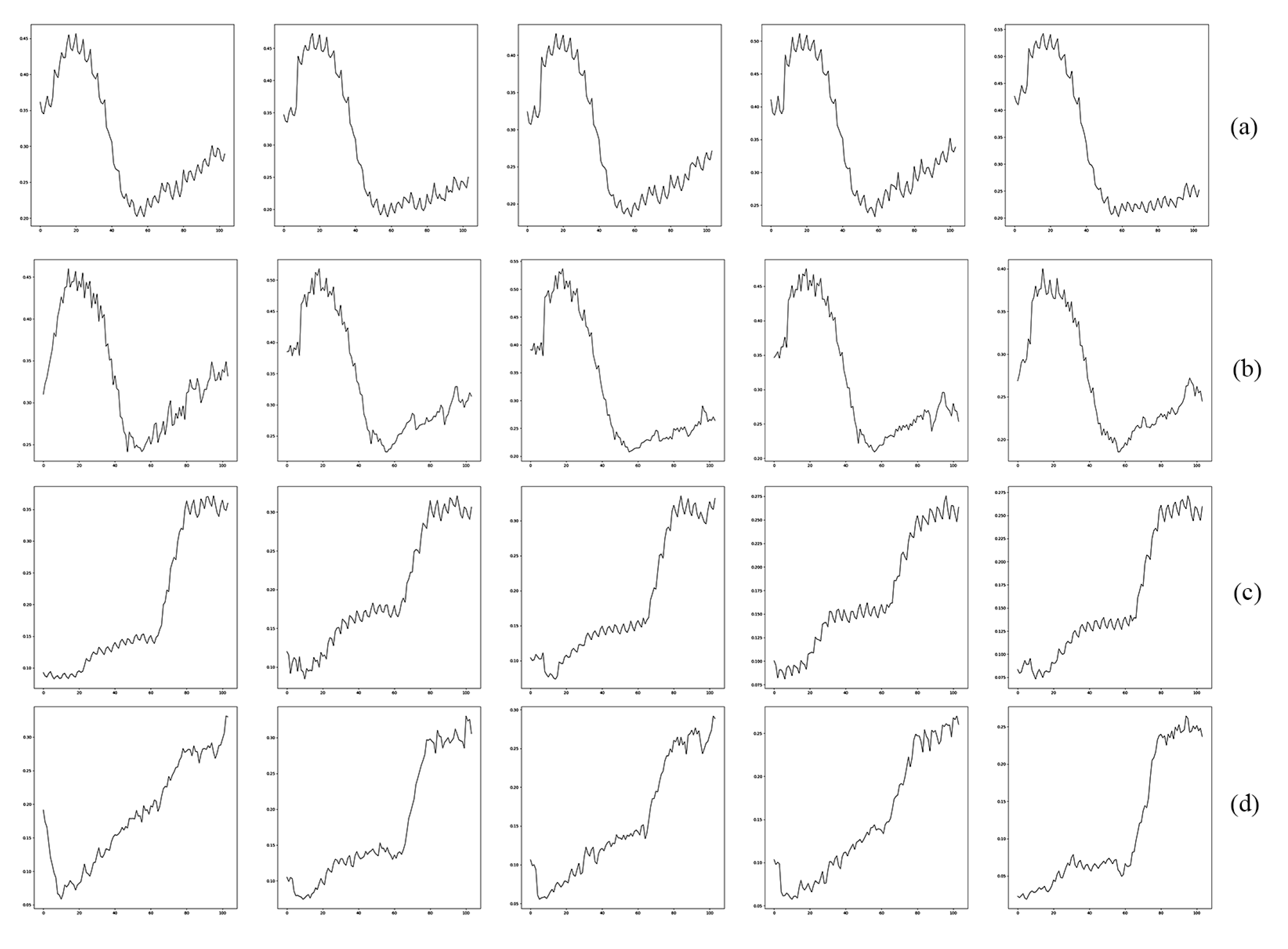
To demonstrate the effectiveness of the self-attention mechanism, we compared the generated samples by using SaGAAN with/without self-attention constraint. To better understand the impact of self-attention, we chose Classes 5 and 6 in Pavia dataset for hyperspectral data generation. The generated samples are shown in
Figure 3. The first two rows represent the spectral curves of painted metal sheets and the last two rows are bare soil reflectances. For the first two rows, we can conclude that much noise has been introduced, which resulted in spikes across the spectral bands, especially for the middle column. In addition, for the bare soil, the generated curves suffer from random noises when not using the self-attention constraint. However, the bare soil spectral profiles become much more similar to the original ones after adding the self-attention term. Moreover, long-range dependencies for spectral curves such as low points and high points have been well represented by the self-attention mechanism.
4.5. Generated Sample Analysis
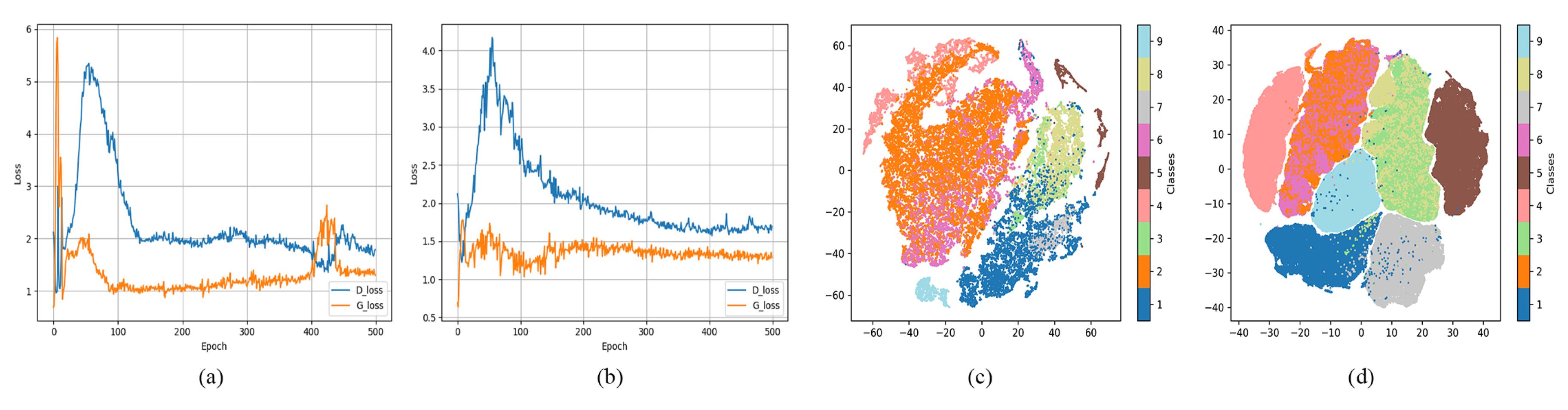
From the above, we can conclude that both domain adaptation and self-attention are crucial parts of high-quality spectral profile generation. In SaGAAN, we utilize MMD measurement to minimize the distances between the generated samples and the original ones. To calculate the MMD distance, the activation of hidden layers inside discriminator convert the generated samples and the original ones into deep feature representations. Then, the similarity of those features can be measured by implementing the MMD strategy. Meanwhile, the self-attention mechanism also enforces the generated samples to be aware of long-range dependencies across different spectral bands. In general, the domain adaptation and self-attention will strongly stabilize SaGAAN during the training process and prevent potential gradient explosion. To illustrate the effectiveness of combining domain adaptation and self-attention, the loss function values for both generator and discriminator are shown in
Figure 4. In this figure, the loss function values for generator and discriminator jitter at the beginning for SaGAAN without domain adaptation and self-attention. Moreover, the loss values can reach almost 6 and then raise again at Iteration 420 where the generator is not stable during the training process. When the domain adaptation and self-attention are involved, the loss values become much more stable through the entire training stage.
To measure the quality of generated samples, we mapped all available training samples in Pavia dataset to the two-dimension space, as shown in
Figure 4c. The number of training samples is not evenly distributed, where Class 2 (Meadows) represents almost half of the total samples. In addition, samples are scattered in the feature space without significant class boundaries. Complementary, SaGAAN generated high-quality samples based on a small fraction (only 10%) of all available ones. In this experiment, SaGAAN generates 0.2 million samples and each class is equally distributed with 22 thousand samples, as shown in
Figure 4d. With the help of domain adaptation and self-attention, SaGAAN generated high-quality samples that contain rich intra-class variation and clear boundaries between different classes. Based on high quality generated samples, better classification results can be achieved.
4.6. Hyperspectral Image Classification and Comparison
To demonstrate the effectiveness of the generated samples, we combined generated samples with the original dataset for the purpose of hyperspectral image classification. Specifically, for each dataset, we selected a specific number of generated samples that have the same sizes as the original training samples. For the purpose of image classification, the 1D CNN framework was applied for hyperspectral image classification. The configuration of 1D CNN is the same as the first five layers of the discriminator illustrated in
Table 1. Finally, we tested the classification performances with or without using the additional generated samples.
4.6.1. Pavia University Dataset
In the experiment, we compared the SaGAAN-based hyperspectral image classification method with the three other image classification strategies. Specifically, the original training sample was directly fed into the 1D CNN framework for training and classification. Then, the domain adaptation-based sample generation strategy was applied to generate additional samples. Furthermore, the generated samples along with the original ones were fed into 1D CNN for training and classification. Meanwhile, the self-attention based sample generation also was applied for sample generation and 1D CNN training. During the entire experiment, each method generated 4273 additional samples for the Pavia dataset, which is as same as the original training dataset.
The classification accuracies are reported in
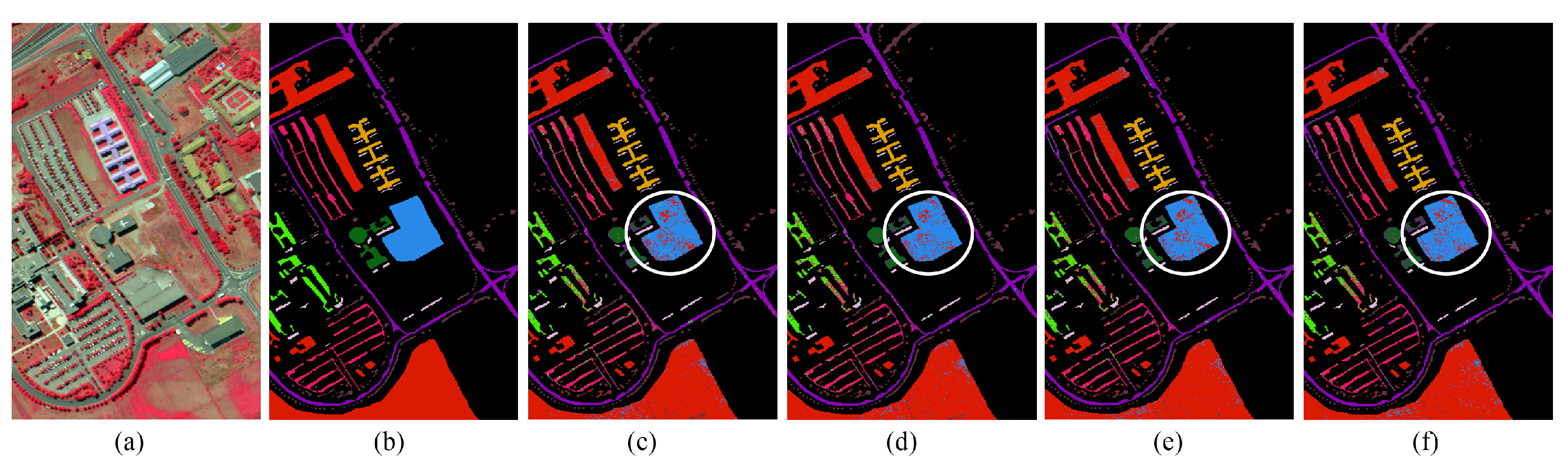
Table 2. For CNN with the original training dataset, the classification accuracy can reach 91.48%. However, due to the training sample shortage, the accuracy is relatively low for Class 7, where it is around 78%. With the help of sample generation strategy, the classification accuracies get higher with additional training samples. For the Ada-CNN, the domain adaptation has been adopted in the traditional GAN framework, and the generated samples along with the original ones were fed into CNN for classification. Therefore, the classification accuracy has increased to 92.08% with domain adaptation samples. Then, the self-attention based samples also increased the overall accuracy about 0.4%. Lastly, the SaGAAN generated high-quality samples were utilized to increase the classification accuracy. The classification maps of these four strategies are shown in
Figure 5.
4.6.2. Indian Pines Dataset
For the Indian Pines dataset, we tested the SaGAAN with the three other classification strategies. The classification accuracies are illustrated in
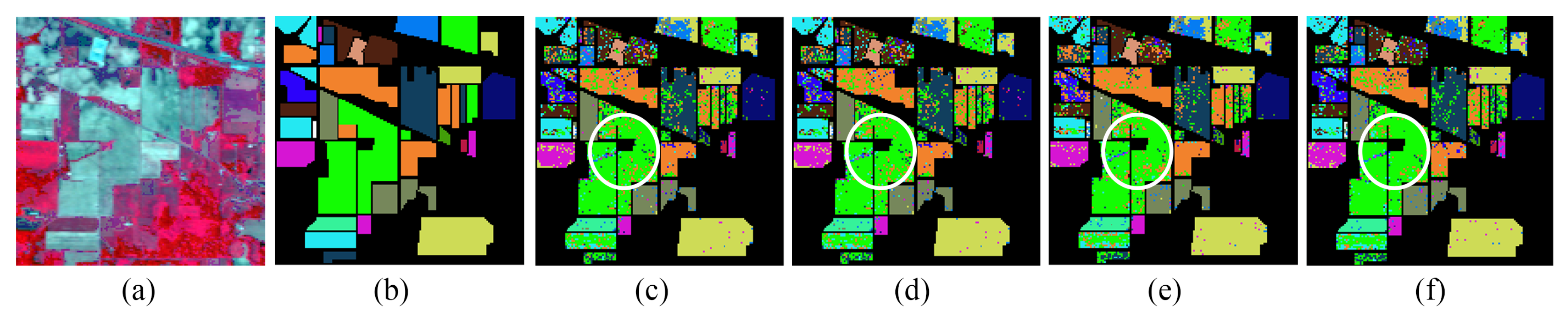
Table 3. From the results in the table, we concluded that the classification accuracy is quite low when performing the traditional CNN with a limited number of training samples. For Classes 1 and 4, the classification accuracies are 60% and 55.64%, respectively. The overall accuracy is 77.44% when only using the original samples. With the domain adaptation-based sample generation, the overall accuracy has increased to 80.58%, but still faces challenges in Classes 1 and 9 where the number of samples is relatively low. The self-attention mechanism has greatly improved the quality of generated samples; the overall accuracy is about 80.97%. However, the classification accuracies of each class are not in balance. SaGAAN considers both domain adaptation and self-attention mechanisms have significantly improved the quality of generated samples, and it improved the overall classification accuracy to 81.14%. In addition, detailed information about classification maps is shown in
Figure 6.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}