SPMF-Net: Weakly Supervised Building Segmentation by Combining Superpixel Pooling and Multi-Scale Feature Fusion

Abstract
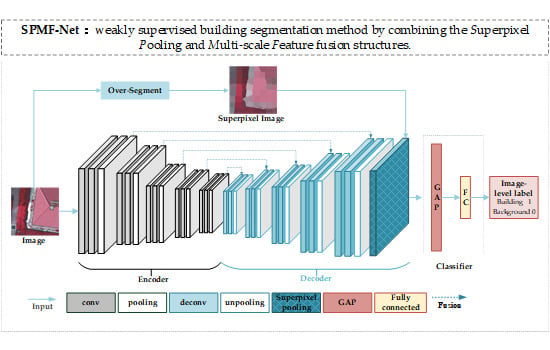
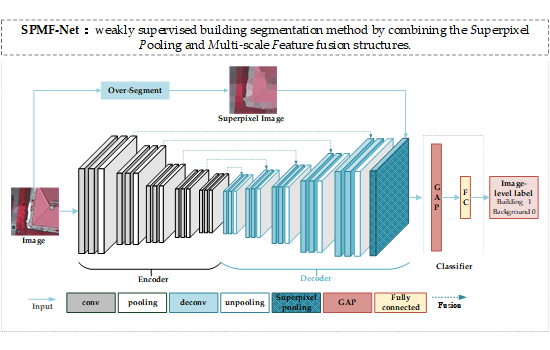
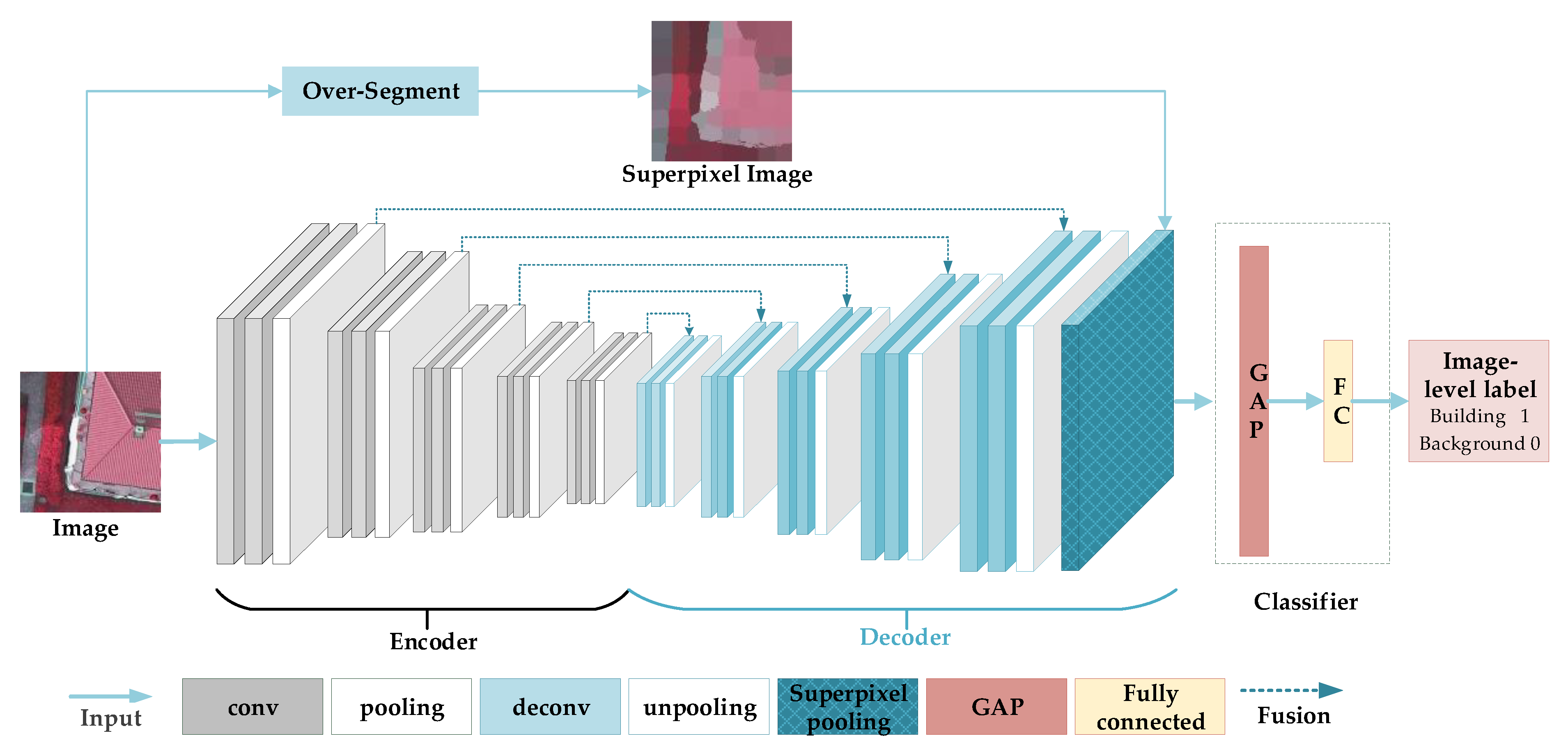
:
1. Introduction
2. Methodology
2.1. Weak Supervision Label Generation
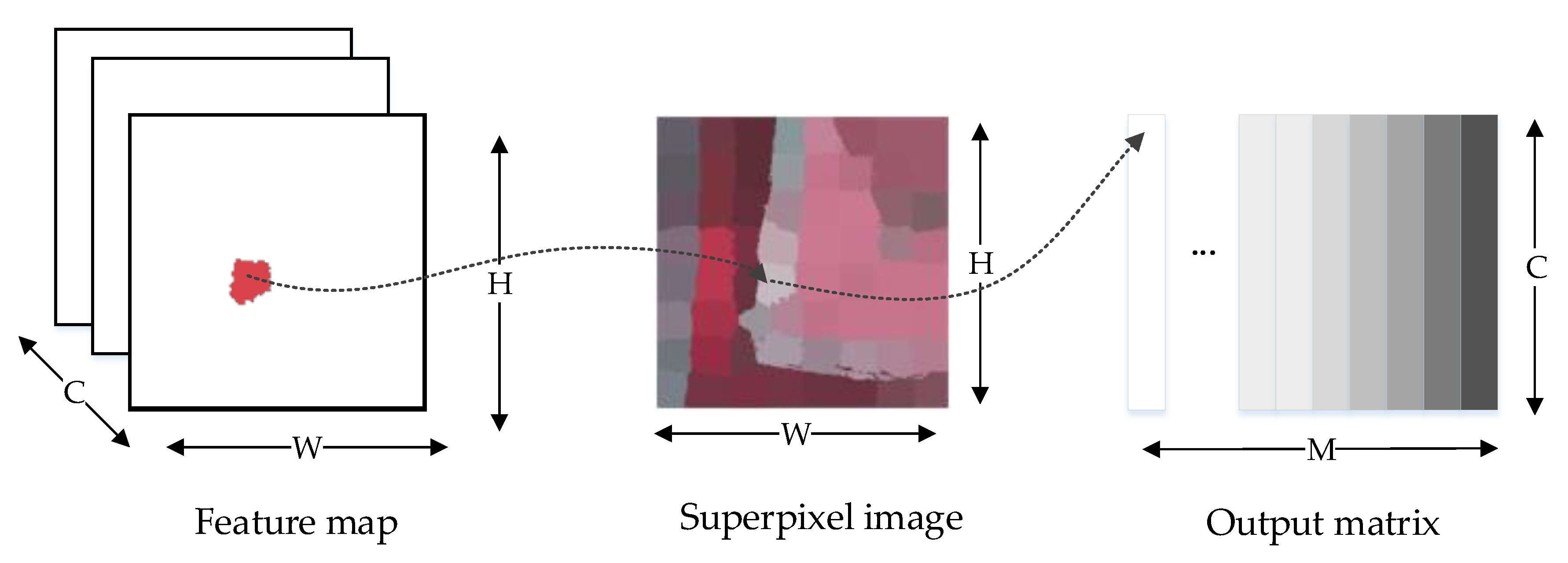
2.1.1. Superpixel Pooling
2.1.2. Multi-Scale Feature Fusion
2.1.3. CAM Calculation
2.2. Building Extraction
3. Results and Analysis
3.1. Dataset
3.2. Data Processing
3.3. Parameter Settings
3.4. Evaluation Metrics and Comparisons
3.5. Quantitative Analysis
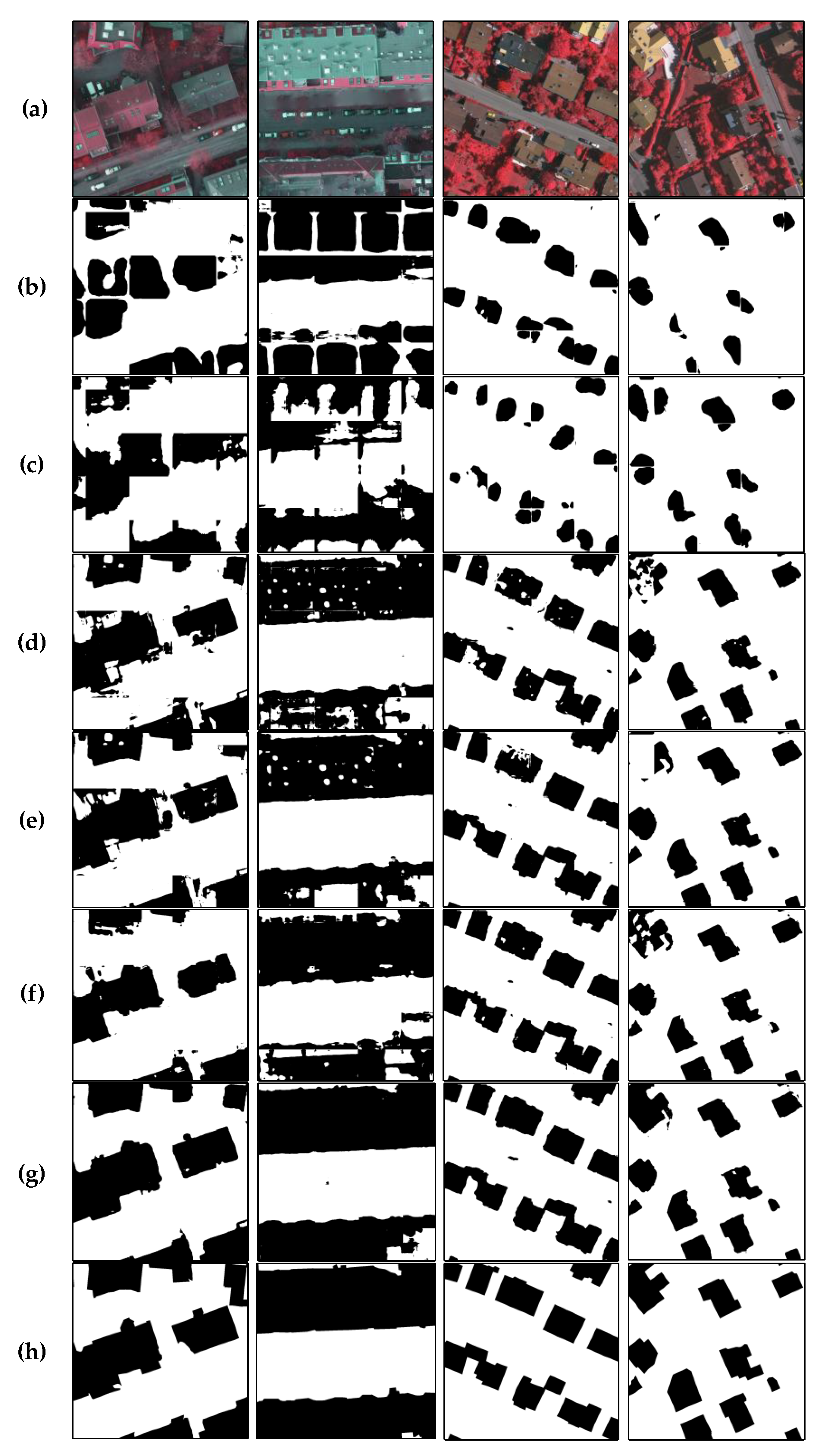
3.6. Qualitative Analysis
4. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Cui, S.; Yan, Q.; Reinartz, P. Complex building description and extraction based on Hough transformation and cycle detection. Remote Sens. Lett. 2012, 3, 151–159. [Google Scholar] [CrossRef]
- Tian, J.; Chen, D.M. Optimization in multi-scale segmentation of high-resolution satellite images for artificial feature recognition. Int. J. Remote Sens. 2007, 28, 4625–4644. [Google Scholar] [CrossRef]
- Brunn, A.; Weidner, U. Hierarchical Bayesian nets for building extraction using dense digital surface models. ISPRS J. Photogramm. Remote Sens. 1998, 53, 296–307. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet Classification with Deep Convolutional Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3 December 2012; pp. 1097–1105. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 7263–7271. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 9 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5 October 2015; pp. 234–241. [Google Scholar]
- Yuan, J. Learning Building Extraction in Aerial Scenes with Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2793–2798. [Google Scholar] [CrossRef] [PubMed]
- Yang, H.L.; Jiangye, Y.; Dalton, L.; Melanie, L.; Amy, R.; Budhendra, B. Building Extraction at Scale Using Convolutional Neural Network: Mapping of the United States. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 2600–2614. [Google Scholar] [CrossRef] [Green Version]
- Zhao, K.; Kang, J.; Jung, J.; Sohn, G. Building Extraction From Satellite Images Using Mask R-CNN With Building Boundary Regularization. In Proceedings of the CVPR Workshops, Salt Lake City, UT, USA, 18 June 2018; pp. 247–251. [Google Scholar]
- Zuo, T.; Feng, J.; Chen, X. HF-FCN: Hierarchically fused fully convolutional network for robust building extraction. In Proceedings of the Asian Conference on Computer Vision, Taipei, Taiwan, 24 November 2016; pp. 291–302. [Google Scholar]
- Papadopoulos, G.; Vassilas, N.; Kesidis, A. Convolutional Neural Network for Detection of Building Contours Using Multisource Spatial Data. In Proceedings of the International Conference on Engineering Applications of Neural Networks, Crete, Greece, 24 May 2019; pp. 335–346. [Google Scholar]
- Lin, J.; Jing, W.; Song, H.; Chen, G. ESFNet: Efficient Network for Building Extraction From High-Resolution Aerial Images. IEEE Access 2019, 7, 54285–54294. [Google Scholar] [CrossRef]
- Dai, J.; He, K.; Sun, J. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 13 December 2015; pp. 1635–1643. [Google Scholar]
- Lin, D.; Dai, J.; Jia, J.; He, K.; Sun, J. Scribblesup: Scribble-supervised convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June 2016; pp. 3159–3167. [Google Scholar]
- Wei, Y.; Liang, X.; Chen, Y.; Shen, X.; Cheng, M.M.; Feng, J.; Zhao, Y.; Yan, S. STC: A Simple to Complex Framework for Weakly-supervised Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 2314–2320. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, T.; Lin, G.; Cai, J.; Shen, T.; Shen, C.; Kot, A.C. Decoupled spatial neural attention for weakly supervised semantic segmentation. IEEE Trans. Multimed. 2019, 21, 2930–2941. [Google Scholar] [CrossRef] [Green Version]
- Wei, Y.; Feng, J.; Liang, X.; Cheng, M.-M.; Zhao, Y.; Yan, S. Object region mining with adversarial erasing: A simple classification to semantic segmentation approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 1568–1576. [Google Scholar]
- Wei, Y.; Xiao, H.; Shi, H.; Jie, Z.; Feng, J.; Huang, T.S. Revisiting dilated convolution: A simple approach for weakly-and semi-supervised semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018; pp. 7268–7277. [Google Scholar]
- Durand, T.; Mordan, T.; Thome, N.; Cord, M. Wildcat: Weakly supervised learning of deep convnets for image classification, pointwise localization and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 642–651. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning deep features for discriminative localization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2921–2929. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Honolulu, HI, USA, 21 July 2017; pp. 618–626. [Google Scholar]
- Fu, K.; Lu, W.; Diao, W.; Yan, M.; Sun, H.; Zhang, Y.; Sun, X. WSF-NET: Weakly supervised feature-fusion network for binary segmentation in remote sensing image. Remote Sens. 2018, 10, 1970. [Google Scholar] [CrossRef] [Green Version]
- Ma, F.; Gao, F.; Sun, J.; Zhou, H.; Hussain, A. Weakly supervised segmentation of SAR imagery using superpixel and hierarchically adversarial CRF. Remote Sens. 2019, 11, 512. [Google Scholar] [CrossRef] [Green Version]
- Kwak, S.; Hong, S.; Han, B. Weakly supervised semantic segmentation using superpixel pooling network. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4 February 2017; pp. 4111–4117. [Google Scholar]
- Pathak, D.; Krahenbuhl, P.; Darrell, T. Constrained convolutional neural networks for weakly supervised segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 1796–1804. [Google Scholar]
- Pinheiro, P.O.; Collobert, R. From image-level to pixel-level labeling with convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1713–1721. [Google Scholar]
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; SüSstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sun, Y.; Zhang, X.; Xin, Q.; Huang, J. Developing a multi-filter convolutional neural network for semantic segmentation using high-resolution aerial imagery and LiDAR data. ISPRS J. Photogramm. Remote Sens. 2018, 143, 3–14. [Google Scholar] [CrossRef]
- Fu, Z.; Sun, Y.; Fan, L.; Han, Y. Multiscale and multifeature segmentation of high-spatial resolution remote sensing images using superpixels with mutual optimal strategy. Remote Sens. 2018, 10, 1289. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; He, F.; Zhang, Y.; Sun, G.; Deng, M. SPMF-Net: Weakly Supervised Building Segmentation by Combining Superpixel Pooling and Multi-Scale Feature Fusion. Remote Sens. 2020, 12, 1049. https://doi.org/10.3390/rs12061049
Chen J, He F, Zhang Y, Sun G, Deng M. SPMF-Net: Weakly Supervised Building Segmentation by Combining Superpixel Pooling and Multi-Scale Feature Fusion. Remote Sensing. 2020; 12(6):1049. https://doi.org/10.3390/rs12061049
Chicago/Turabian StyleChen, Jie, Fen He, Yi Zhang, Geng Sun, and Min Deng. 2020. "SPMF-Net: Weakly Supervised Building Segmentation by Combining Superpixel Pooling and Multi-Scale Feature Fusion" Remote Sensing 12, no. 6: 1049. https://doi.org/10.3390/rs12061049
APA StyleChen, J., He, F., Zhang, Y., Sun, G., & Deng, M. (2020). SPMF-Net: Weakly Supervised Building Segmentation by Combining Superpixel Pooling and Multi-Scale Feature Fusion. Remote Sensing, 12(6), 1049. https://doi.org/10.3390/rs12061049