1. Introduction
An accurate spatial representation of population counts is important for e.g., risk assessment, policy-making, disaster management, accessibility modeling, poverty mapping, and adaptive strategies for human health [
1,
2,
3,
4]. Mapping the population distribution at a high-resolution became popular for producing high-resolution gridded population surfaces (HGPS), which have large benefits for many [
5]. Traditionally, the census has been the main data source for such mapping. Yet, the census is normally conducted every 10 years, which is insufficient to fully capture the fast dynamics of the population changes over time. Using traditional methods to update population data frequently is time-consuming, costly, and even infeasible at a large scale [
6].
Over the past decade, researchers have developed a wide range of methods for mapping the spatial distribution of the population with the aid of Geographic Information Systems (GIS) technology, which is used to create choropleth maps. As the population is not uniformly distributed over space within the administrative units [
7], GIS-based discrete and aggregated choropleth maps cannot represent the spatial distribution of the population accurately [
8]. Recently, several projects incorporated remote sensing (RS) derived datasets to model population distribution, such as Gridded Population of the World (GPW) [
9], Global Rural-Urban Mapping Project (GRUMP) [
10], LandScan Global [
11], and WorldPop (Asia, Africa, and South America) [
12]. Other studies that have been undertaken were based on the intrinsic features of RS imagery, such as image texture indices [
13]. Those products, however, were mainly generated either at country [
14] or at regional level [
15], with spatial resolutions ranging from 100 m to 1 km. Unfortunately, this resolution cannot meet the demands in some specific areas or situations, such as emergency/disaster response and resource allocation. This is especially important in low- and middle-income countries (LMICs) where resources for conducting surveys are usually limited. Moreover, the accuracy of the population distribution products in urban areas and in the outskirts is lower due to the high heterogeneity of the urban features [
16]. Given the increasing urbanization experienced worldwide, the demand for mapping and the understanding of population distribution at a high-resolution is increasing as well.
Dasymetric mapping is a particular cartographic representation of data, where census data are disaggregated into spatial units/grids with the aid of ancillary data to produce HGPS [
17]. It can incorporate a variety of ancillary data, such as parcel and building information, into the mapping of the population distribution. As population density varies across different types of land use and even across different census units within the same type of land use, it is important to model the population distribution on the basis of fine-scale ancillary data, such as generating HGPSs at the building level. This is a challenging task, as building data (e.g., footprint, height) are not always available, although very-high-resolution (VHR) satellite images may provide a solution to do so. Previous works have used medium- to coarse-resolution RS images in population modeling [
18,
19,
20,
21]. Hence, opportunities for using the information on buildings derived from VHR satellite images in dasymetric mapping have not been fully explored yet. In addition, ordinary least square (OLS) regression has mainly been used for population distribution, under the assumption of a stable relationship between population density and a certain feature of a place, derived from ancillary data. This assumption is rarely true in the real world, as even in a small study area, many unobserved factors (e.g., percentage of land use, building use, and road density) may affect its stability. Geographically Weighted Regression (GWR) has been developed to overcome the assumption of stationarity.
The main goal of this study was to develop a population disaggregation model by incorporating information on buildings extracted from VHR satellite imagery and GWR into a dasymetric model. Our model was compared with a model that combines GWR with land use data, and with a model that combines OLS with both land use and building data.
2. Materials and Methods
2.1. Study Area
Dhaka, as the capital city of Bangladesh, has a history of more than 400 years [
22]. It is located on the bank of the Buriganga river and surrounded by six rivers in total: the Balu and Sitalakhya rivers on the eastern side, the Turag and Buriganga rivers on the western side, the Tongi Khal on the northern side and the Dhaleshwari river to the south [
23]. According to the 2011 National Census, the total urban area of Bangladesh equals 8867.42 km
2, covering 6% of the total land of Bangladesh, and has a population of 35,094,684, which is 23.3% of the total population of the country. Dhaka has 6,970,105 inhabitants, with a population density of 55,169 people per km
2, whereas the national population density equals 976 people per km
2 [
24]. There are 92 wards (the smallest administrative unit) in Dhaka City Corporation (DCC), which are divided across two parts of the city. One is Dhaka North City Corporation (DNCC) and the other is Dhaka South City Corporation (DSCC).
Figure 1 shows the location of Dhaka City in the context of Asia.
2.2. Datasets
The population census is conducted every 10 years in Bangladesh, with the most recent one conducted in 2011. The tabular data of the population count against the smallest census unit (Ward in Bangladesh) were collected and the data are freely available on the website of the Bangladesh Bureau of Statistics (BBS). There are 92 wards in Dhaka City, divided across two parts—south and north. The land use data were collected from Rajdhani Unnayan Kartipakkha (RAJUK) and were produced in 2014. Furthermore, the data were categorized into eight types of inhabitable areas: administrative, commercial, educational, manufacturing, mixed, residential, restricted, and service areas. Remaining land areas were all categorized as non-inhabitable areas. The road network data in vector format (polygon) were also collected from RAJUK. The total road length of Dhaka is 1740 km, where Dhaka North has a road length of 1130 km and Dhaka South has a road length of 610 km. The minimum width of the road is 2.5 m and the maximum is 45 m. This road layer was used for the intersection process with the extracted buildings later, so that it moved the misclassified objects of the road to buildings. A recent multispectral WorldView 2 (WV2) image, acquired on 15 May 2017, at a high spatial resolution of 0.5 m, was obtained from DigitalGlobe and used for extracting buildings from the study area. WV2 has one panchromatic (450–800 nm) band with a resolution of 0.5 m, and eight multi-spectral bands (blue, coastal blue, green, yellow, red, red edge, NIR, NIR2) with a spatial resolution of 2 m for enhanced multispectral analyses. Together they are designed to improve the classification of land and aquatic features beyond any other space-based remote sensing platform.
2.3. Methods
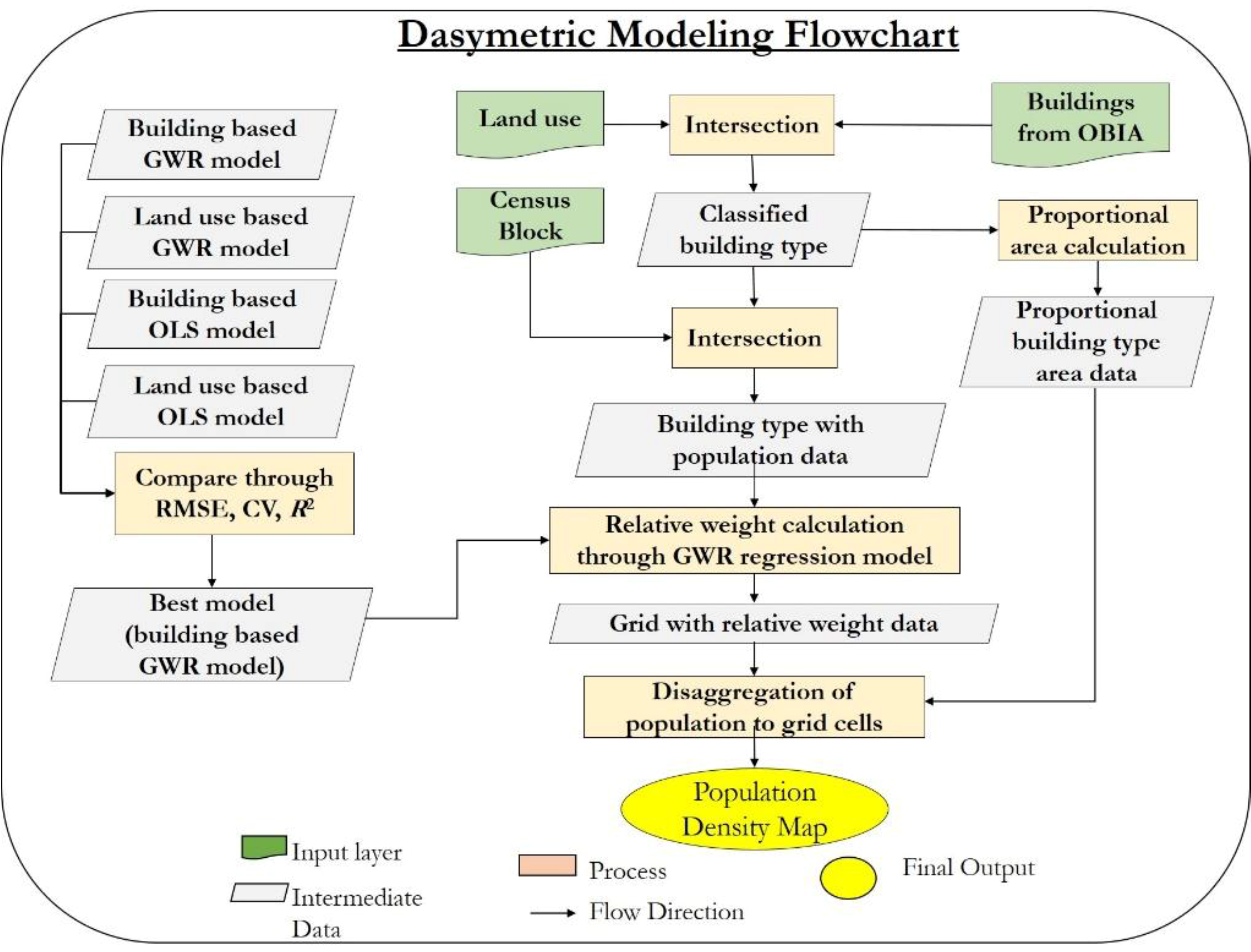
The proposed method is a combination of Object based Image Analysis (OBIA) on VHR images, and GWR of the population distribution in the study area. Here, the extracted buildings of VHR were categorized according to land use. The areas of the buildings were used to calculate the proportion of building use, which were used in dasymetric methods later on. A framework of the proposed study is shown below (
Figure 2).
2.3.1. Satellite Image Pre-Processing
The WorldView image was ortho-rectified and radiometrically corrected by the DigitalGlobe. The image included one single panchromatic band with a spatial resolution of 0.5 m and eight multi-spectral bands with a resolution of 2 m. A high pass filter (HPF) method was used for pan sharpening the multi-spectral bands [
25].
2.3.2. OBIA for Building Extraction
OBIA is an interactive image analysis method, successfully used to extract information from VHR imagery [
26]. It starts with the segmentation of imagery into homogeneous, meaningful objects. These objects are then further assigned to the classes of interest through classification. One of the main advantages of OBIA consists of its ability to incorporate not only spectral, but also textural and spatial information during the classification process. In this way, it can contribute to distinguishing objects that have the same spectral reflectance (e.g., buildings, roads, etc.). Considering these advantages, a segmentation process and a set of rules were defined in this study to extract the roofs of buildings. The entire building extraction process was performed in Trimble eCognition software. A multi-resolution segmentation [
27] algorithm was used to segment WorldView 2 images into homogeneous objects. This algorithm relies on the following user-defined parameters: scale, shape and compactness. The shape parameter was set to 0.2 and the compactness parameter was set to 0.8. Different scale parameters were tried for segmentation, including 10, 20, 30, 40, and 50. In the end, a scale parameter of 30 was selected through visual interpretation of the segmentation results.
In our study area, the buildings vary in size and have different textural characteristics, due to the different construction materials. To address this challenge, a hierarchical classification process was designed and implemented. First, we classified the image into vegetation and non-vegetation classes. Second, we classified the non-vegetation class further into water, buildings and others classes (the remaining unclassified area). Various indices were used to define the classification rulesets, including the Normalized Difference Vegetation Index (NDVI), the Normalized Difference Water Index (NDWI) [
28], the Green Band Ration (RatioG), image brightness value or mean spectral reflectance value of the green spectral band (Mean B3). Besides these indices, we also used spatial information, such as proximity, i.e., closeness to previously classified buildings. The threshold values for all input variables were set based on the trial and error method. Once the buildings were extracted from the image, they were further classified into eight building types, using the land use classes mentioned in
Section 2.2.
2.3.3. Population Modeling
A modified dasymetric model was proposed to disaggregate the ward-level population onto 5x5 m grid cells. Initially, a GWR model was constructed to explore the relationship between the population density and each building type in each ward (i.e., variable population density for each building type across wards). GWR addresses the exact spatial regression as spatial non-stationarity and develops a relationship over space, which could be measured and mapped [
29,
30]. A generic regression equation [
31], also applied to OLS-based models described in Equation (1), was used to illustrate this process:
where
pi is the census population of a ward
i;
βj is the population density for the building type
j (or land use type
j for OLS-based models);
Aij is the area of the building type
j (or land use type
j for OLS-based models) within ward
i;
β0 and
εi are the intercept and residual of the regression, respectively.
In each ward, the population density of each building type was multiplied by the area of each building, to calculate the absolute weight of each building. The absolute weight of each building was transformed into a relative weight by dividing it by the sum of the absolute weights of all buildings in the ward. The population of each ward was distributed onto each building based on relative weights. Finally, an areal weighting interpolator (AWI) method [
32] was used to transform the population within buildings into the population within 5x5 m grid cells. Implementation started with intersecting grid cells and buildings. Some buildings were located entirely within one grid cell, but some were divided into two or more intersected zones by grid cell boundaries. The AWI method assumes that the population is uniformly distributed within a building. Thus, the population in each divided building was apportioned to each intersected zone on the basis of the areal proportion of that intersected zone over the building. The estimated population in all intersected zones and buildings completely located within each grid cell was then added to yield the total population in that grid cell. A detailed flowchart of dasymetric modeling is given in
Figure 3. Spatial analyses were conducted in ArcGIS (version 10.5, ESRI).
2.3.4. Accuracy Assessment
The accuracy assessment was undertaken in two phases: one during the image classification and the other one during the population modeling. The accuracy assessment of the extracted buildings was performed by comparing the classification results with the reference data, which were collected from the visual interpretation of the study’s high-resolution image, using a random sampling method. Congalton suggested to have 75 to 100 samples for each class if the image covers a large area or if the classified image has a large number of Land use land cover (LULC) categories, such as more than 12 classes [
33]. Hashemian et al. (2004) found that the accuracy results were stable for the large study area if the sample size was approximately 70 for each class [
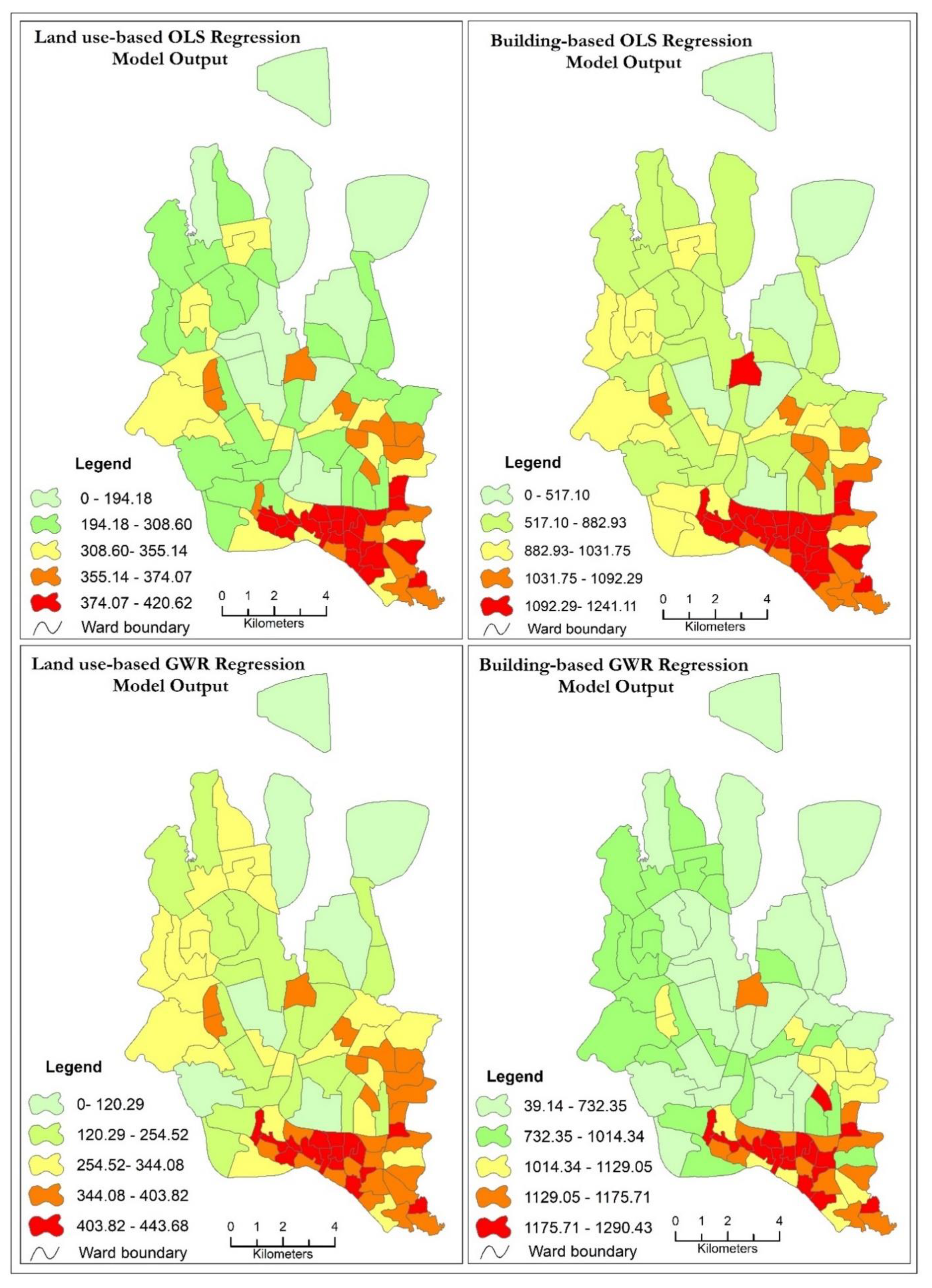
34]. However, this study area covers a very large area (136 sq. km) and the image was classified into four classes (i.e., buildings, water, vegetation, and others), so the reference sample size was fixed at 400 in total and 100 for each class. To assess the accuracy of the estimated population by the GWR model on the basis of building data, three regression models were constructed to estimate the population density over each building type or land use, including 1) using GWR based on land use data (i.e., variable density for each land use class across wards), 2) using OLS based on land use data (i.e., invariable density for each land use class across wards), and 3) using OLS based on building data (i.e., invariable density for each building type across wards). The root means square error (RMSE) and the coefficient of variance (CV) were calculated to compare the performance of the four models [
5]:
where,
Pi is the population within ward
i;
is the estimated population within ward
i; and
n is the number of wards. The CV was computed by dividing RMSE by the average building population within that ward.
To compare the variability among the different population models, we used another method: the coefficient of variance (CV). The CV is computed by dividing the RMSE with the average areal unit. In this research, the CV is calculated by dividing the RMSE by the ward-specific average population within that specific ward. This CV was calculated for each model by using the following equation (Equation (3)).
4. Discussion
4.1. OBIA-Based Classification Results
OBIA performed well at detecting the vegetation class. However, it obtained less satisfactory classification results for other classes, such as water and buildings. The water class was confused with other urban features, such as buildings. The reason behind this confusion was the construction materials used for the roofs of buildings. For example, every building has a water tank on top of the roof, which sometimes overflows. In addition, the shadows casted on different buildings also caused confusion between water and buildings.
The producer’s accuracy achieved for buildings was 73.91% and the user’s accuracy was 85%. The value of the producer’s accuracy metric is relatively low due to several reasons. First, the spectral reflectance of the roofs of buildings is similar to those of roads. Second, Dhaka city has a practice of roof gardening which increased the challenge of the buildings’ roof identification, leading to misclassification of the buildings class as a vegetation area. Furthermore, the accuracy of building detection depends on the segmentation results. The segmentation parameters such as scale, shape, and compactness were defined through trial and error and applied over the entire study area at once. Given the complexity of the study areas, the buildings were either over- or under-segmented during the segmentation process (
Figure 12). Third, the classification rulesets in OBIA worked very well with identifying buildings in some less complex urban areas, yet, it performed worse in very complex areas (e.g., city center), where segmentation errors such as over-and under-segmentation occurred. Furthermore, the geometrical shape of the building varies across the investigated urban area. The buildings do not have a regular shape and size due to unplanned urbanization over the last four hundred years. Finally, the trees beside the buildings challenge the proper detection of the building shape.
4.2. Dasymetric Mapping
Population density is highly correlated with building type [
6]. In developing countries, the urban area has different combinations of building use, which has an effect on population distribution. In addition, sometimes, there is no clear boundary for residential areas or they are all in mixed land classes, as the city grows in an unplanned way (e.g., Dhaka city). Consequently, population density may vary between residential areas and other areas, such as mixed or commercial building types, as we found in this study.
This study would have had better results if the following issues had been considered. Firstly, the height of the buildings was not considered in this model. As a result, the population density seemed very high in some cases as it assumed a horizontal distribution of pixels. Secondly, the geometric accuracy was not perfect, affecting the calculation of the total building area and consequently that of the population density. Thirdly, in this study, a generalized land use was used, where small segments of land use were merged within a big segment of land use. This may cause an inaccuracy in the area distribution of building types and in the distribution of population within the ward. Fourthly, the GWR model was used to calculate the proportional population among the building types within the ward.
The temporal variation in population and LULC data might impact the reported results. The population census was conducted in 2011, and was published in 2015 by the government. The LULC data was produced by another governmental organization (SoB) in 2008, and the VHR images of the study area were captured in May 2017.
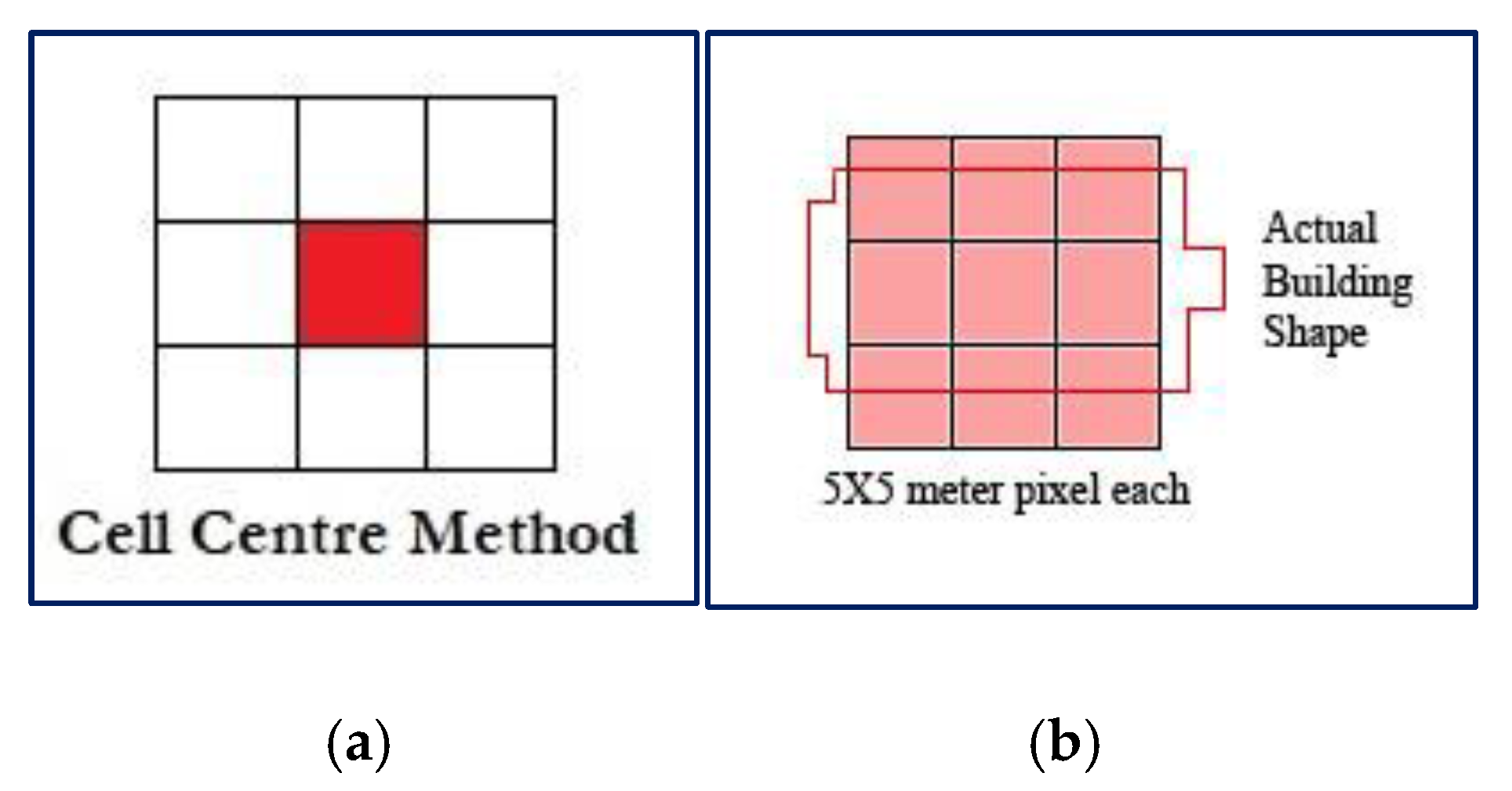
The conversion of the irregular vector shape file into a regular pixel may also impact the population disaggregation data. The cell center option (
Figure 9) was selected as the cell assignment method during the pixel conversion. Cell assignment defines how the pixel will be assigned if more than one polygon falls within a pixel. Sometimes the 25 sq. m pixel did not fit the actual building shape, which affected the area calculation of the building.
Figure 13 shows how the pixel conversion affects the area calculation of the actual building shape. The 5 m resolution may reduce this error, but not completely.
5. Conclusions
Studying population distribution in an appropriate and accurate way has become an important research area. The Geographic Information System, remote sensing, and geo-statistics are being used to support these population studies. Consequently, various techniques have been developed based upon resource availability, such as time, labor, data, and money and on fit to purpose as well. In this study, a dasymetric model containing the GWR model as well as building data, was developed to create a detailed dynamic population distribution model. This model was compared with three other different models incorporating GWR and OLS, based on building and land use data. The GWR demonstrated a high degree of probability of population density distribution using spatial non-stationarity from WorldView 2 imagery of Dhaka city. GWR appears to be an appropriate technique to improve the certainty of the population density distribution from images, taking the buildings’ characteristics of the urban environment into account. The developed model generated a gridded population distribution product with a resolution of 5 m for Dhaka city. In addition, the OBIA method was successfully used for building extraction from heterogeneous and complex urban areas. In the future, building height will be used in order to produce a more accurate population distribution.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}