Prediction of Maize Yield at the City Level in China Using Multi-Source Data



Abstract
:
1. Introduction
2. Materials and Methods
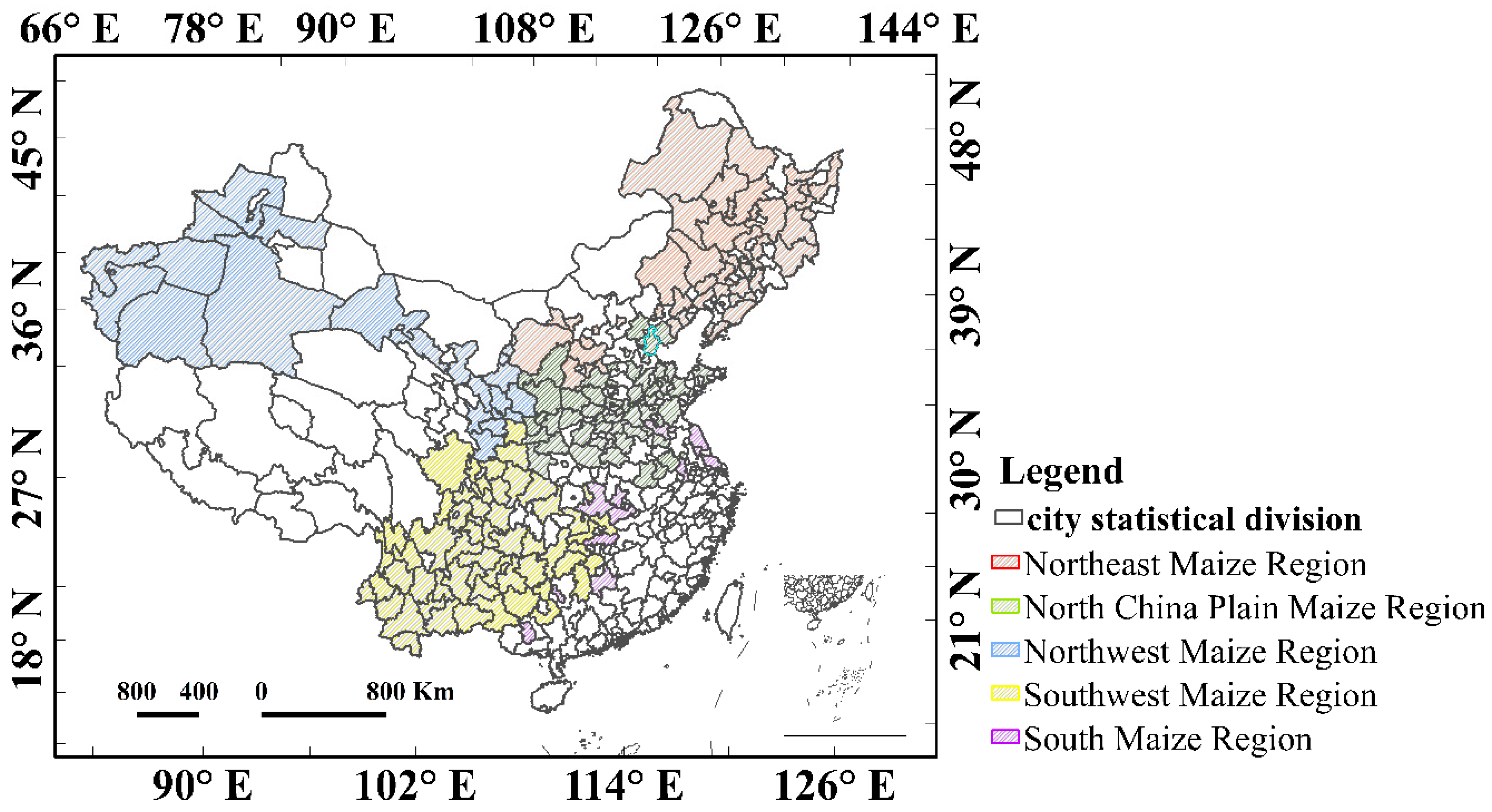
2.1. Study Area
2.2. Materials
2.2.1. Crop Yield
2.2.2. Climate, Satellite Data, and Meteorological Indices
2.3. Methods
2.3.1. Exploratory Data Analysis
2.3.2. Machine Learning Methods for Estimating Maize Yield
2.4. Experimental Design
3. Results
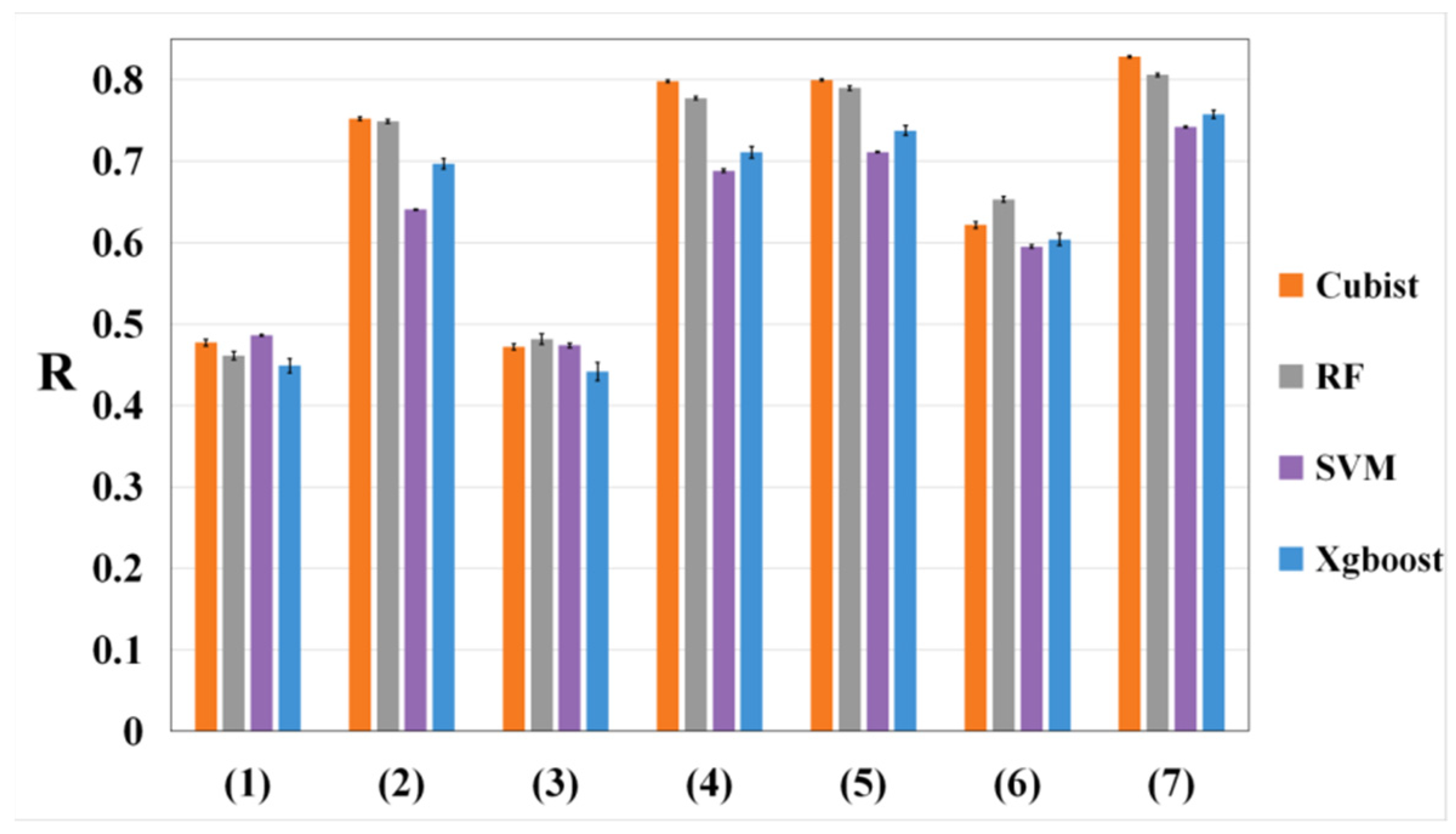
3.1. Selection of Climate Variables
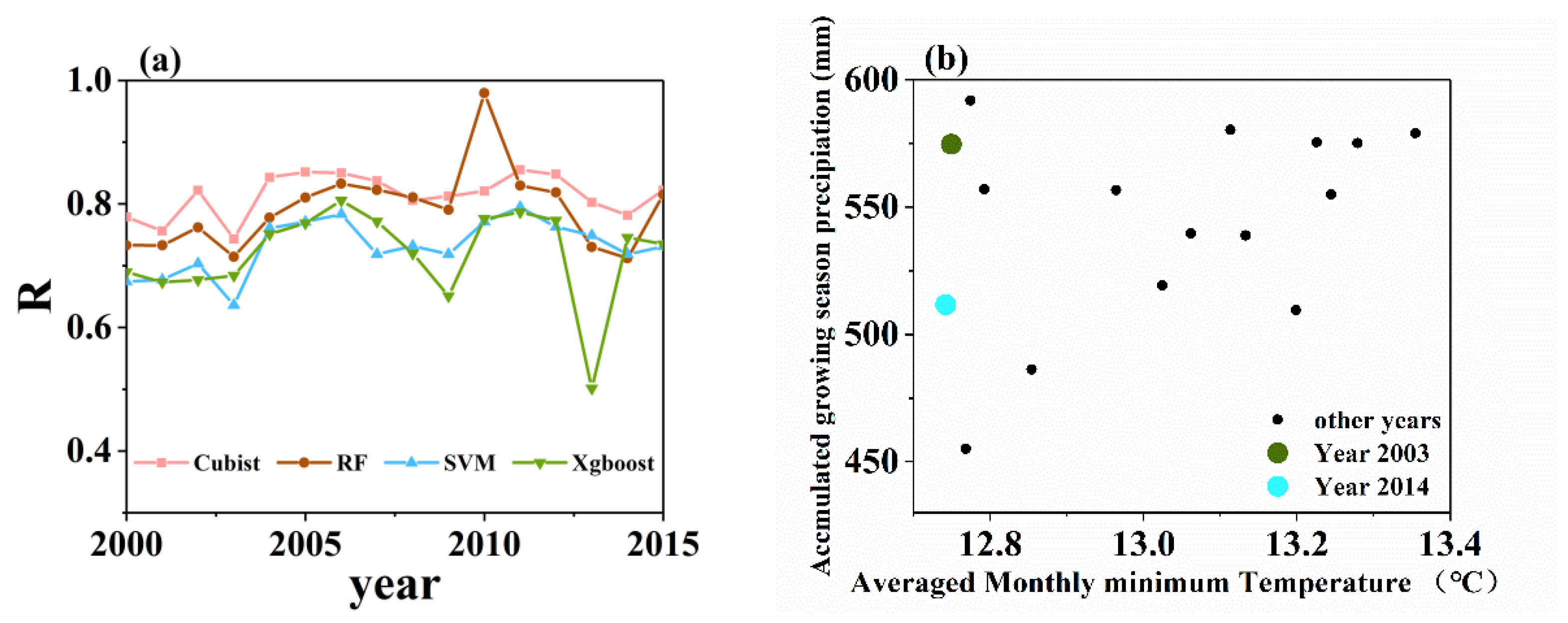
3.2. Multi-Model Performances When Estimating Maize Yield
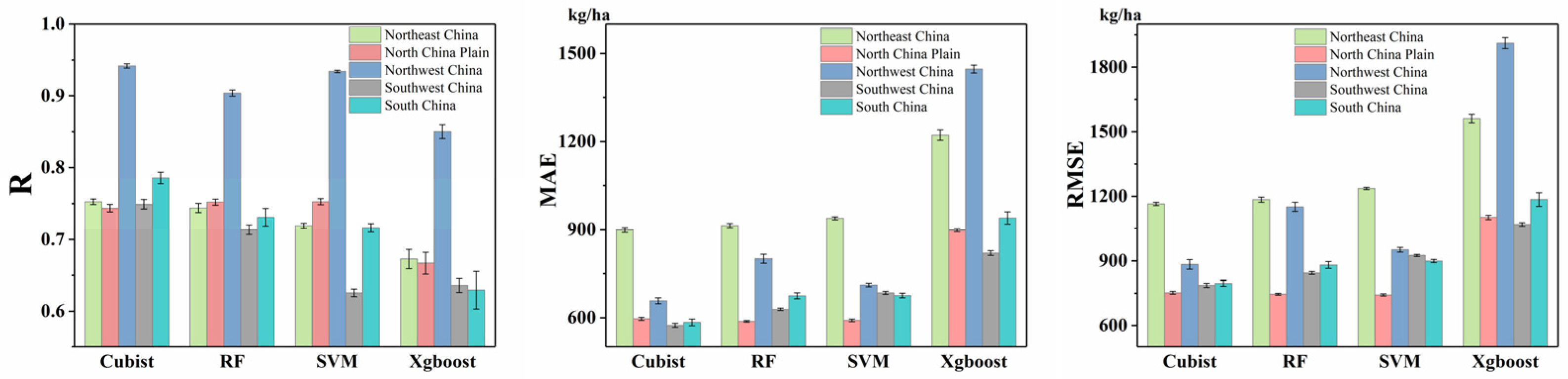
3.3. The Divergences of Model Performances between Different Growth Stages and Maize-Growing Regions
4. Discussion
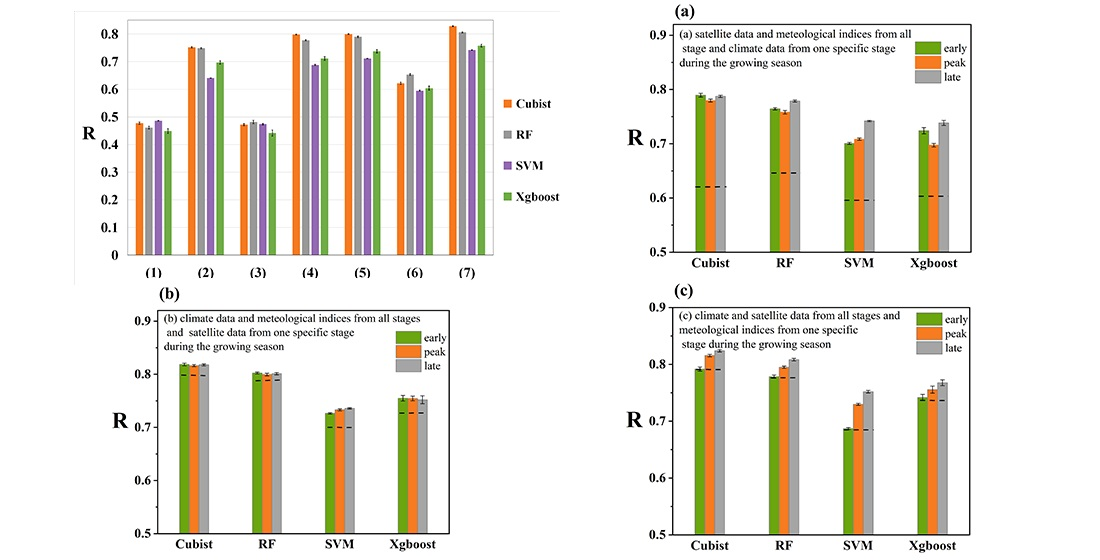
4.1. Quantifying the Contributions of Climate, Satellite Data, and Meteorological Indices in Different Growth Stages to Maize Yield
4.2. Quantifying the Divergences of Model Performances Between Five Maize-Growing Regions
4.3. Uncertainty and Limitations
5. Conclusions
- (1)
- The performance of climate data, with R ranging from 0.641 to 0.752, was better than that of satellite data and meteorological indices, with the lowest R ranging from 0.449 to 0.486 and 0.442 to 0.481, respectively. Integrating all climate, satellite data, and meteorological indices could achieve the highest accuracy.
- (2)
- The climate data or satellite data inputs from all growth stages were essential for maize yield prediction, especially in late growth stages.
- (3)
- The spatial analysis found that the spatial divergences were large, and the R-value in the Northwest region reached 0.942, 0.904, 0.934, and 0.850 for the Cubist, RF, SVM, and Xgboost, respectively. Additionally, unprecedented extreme climate events could cause large prediction biases.
Author Contributions
Funding
Conflicts of Interest
References
- Kuwata, K.; Shibasaki, R. Estimating corn yield in the United States with modis evi and machine learning methods. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, III-8, 131–136. [Google Scholar] [CrossRef]
- Pantazi, X.E.; Moshou, D.; Alexandridis, T.; Whetton, R.L.; Mouazen, A.M. Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 2016, 121, 57–65. [Google Scholar] [CrossRef]
- Morell, F.J.; Yang, H.S.; Cassman, K.G.; Wart, J.V.; Elmore, R.W.; Licht, M.; Coulter, J.A.; Ciampitti, I.A.; Pittelkow, C.M.; Brouder, S.M.; et al. Can crop simulation models be used to predict local to regional maize yields and total production in the U.S. Corn Belt? Field Crops Res. 2016, 192, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Everingham, Y.L.; Smyth, C.W.; Inman-Bamber, N.G. Ensemble data mining approaches to forecast regional sugarcane crop production. Agric. For. Meteorol. 2009, 149, 689–696. [Google Scholar] [CrossRef]
- Lecerf, R.; Ceglar, A.; López-Lozano, R.; Van Der Velde, M.; Baruth, B. Assessing the information in crop model and meteorological indicators to forecast crop yield over Europe. Agric. Syst. 2019, 168, 191–202. [Google Scholar] [CrossRef]
- Maharjan, G.R.; Hoffmann, H.; Webber, H.; Srivastava, A.K.; Weihermüller, L.; Villa, A.; Coucheney, E.; Lewan, E.; Trombi, G.; Moriondo, M.; et al. Effects of input data aggregation on simulated crop yields in temperate and Mediterranean climates. Eur. J. Agron. 2019, 103, 32–46. [Google Scholar] [CrossRef]
- Gilardelli, C.; Stella, T.; Confalonieri, R.; Ranghetti, L.; Campos-Taberner, M.; García-Haro, F.J.; Boschetti, M. Downscaling rice yield simulation at sub-field scale using remotely sensed LAI data. Eur. J. Agron. 2019, 103, 108–116. [Google Scholar] [CrossRef]
- Leroux, L.; Castets, M.; Baron, C.; Escorihuela, M.; Bégué, A.; Lo Seen, D. Maize yield estimation in West Africa from crop process-induced combinations of multi-domain remote sensing indices. Eur. J. Agron. 2019, 108, 11–26. [Google Scholar] [CrossRef]
- Pagani, V.; Guarneri, T.; Fumagalli, D.; Movedi, E.; Testi, L.; Klein, T.; Calanca, P.; Villalobos, F.; Lopez-Bernal, A.; Niemeyer, S.; et al. Improving cereal yield forecasts in Europe—The impact of weather extremes. Eur. J. Agron. 2017, 89, 97–106. [Google Scholar] [CrossRef]
- Balaghi, R.; Tychon, B.; Eerens, H.; Jlibene, M. Empirical regression models using NDVI, rainfall and temperature data for the early prediction of wheat grain yields in Morocco. Int. J. Appl. Earth Obs. 2008, 10, 438–452. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Guan, K.; Yu, A.; Peng, B.; Zhao, L.; Li, B.; Peng, J. Toward building a transparent statistical model for improving crop yield prediction: Modeling rainfed corn in the U.S. Field Crops Res. 2019, 234, 55–65. [Google Scholar] [CrossRef]
- Bussay, A.; van der Velde, M.; Fumagalli, D.; Seguini, L. Improving operational maize yield forecasting in Hungary. Agric. Syst. 2015, 141, 94–106. [Google Scholar] [CrossRef]
- Peng, B.; Guan, K.; Pan, M.; Li, Y. Benefits of Seasonal Climate Prediction and Satellite Data for Forecasting U.S. Maize Yield. Geophys. Res. Lett. 2018, 45, 9662–9671. [Google Scholar] [CrossRef]
- Mathieu, J.A.; Aires, F. Statistical Weather-Impact Models: An Application of Neural Networks and Mixed Effects for Corn Production over the United States. J. Appl. Meteorol. Clim. 2016, 55, 2509–2527. [Google Scholar] [CrossRef]
- Jones, J.W.; Antle, J.M.; Basso, B.; Boote, K.J.; Conant, R.T.; Foster, I.; Godfray, H.C.J.; Herrero, M.; Howitt, R.E.; Janssen, S.; et al. Brief history of agricultural systems modeling. Agric. Syst. 2017, 155, 240–254. [Google Scholar] [CrossRef]
- Johnson, M.D.; Hsieh, W.W.; Cannon, A.J.; Davidson, A.; Bédard, F. Crop yield forecasting on the Canadian Prairies by remotely sensed vegetation indices and machine learning methods. Agric. Forest Meteorol. 2016, 218–219, 74–84. [Google Scholar] [CrossRef]
- Schwalbert, R.A.; Amado, T.; Corassa, G.; Pott, L.P.; Prasad, P.V.V.; Ciampitti, I.A. Satellite-based soybean yield forecast: Integrating machine learning and weather data for improving crop yield prediction in southern Brazil. Agric. Forest Meteorol. 2020, 284, 107886. [Google Scholar] [CrossRef]
- Crane-Droesch, A. Machine learning methods for crop yield prediction and climate change impact assessment in agriculture. Environ. Res. Lett. 2018, 13, 1–12. [Google Scholar] [CrossRef] [Green Version]
- Alvarez, R. Predicting average regional yield and production of wheat in the Argentine Pampas by an artificial neural network approach. Eur. J. Agron. 2009, 30, 70–77. [Google Scholar] [CrossRef]
- Chlingaryan, A.; Sukkarieh, S.; Whelan, B. Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: A review. Comput. Electron. Agric. 2018, 151, 61–69. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Peng, J.; Wang, S.; Seifert, C.; Wardlow, B.; Li, Z. A high-performance and in-season classification system of field-level crop types using time-series Landsat data and a machine learning approach. Remote Sens. Environ. 2018, 210, 35–47. [Google Scholar] [CrossRef]
- Peiris, T.S.G.; Hansen, J.W.; Zubair, L. Use of seasonal climate information to predict coconut production in Sri Lanka. Int. J. Climatol. 2008, 28, 103–110. [Google Scholar] [CrossRef] [Green Version]
- Martinez, C.J.; Baigorria, G.A.; Jones, J.W. Use of climate indices to predict corn yields in southeast USA. Int. J. Climatol. 2009, 29, 1680–1691. [Google Scholar] [CrossRef]
- Holzman, M.E.; Carmona, F.; Rivas, R.; Niclòs, R. Early assessment of crop yield from remotely sensed water stress and solar radiation data. ISPRS J. Photogramm. 2018, 145, 297–308. [Google Scholar] [CrossRef]
- Holzman, M.E.; Rivas, R.E. Early Maize Yield Forecasting From Remotely Sensed Temperature/Vegetation Index Measurements. IEEE J. STARS 2016, 9, 507–519. [Google Scholar] [CrossRef]
- Wang, L.; Tian, Y.; Yao, X.; Zhu, Y.; Cao, W. Predicting grain yield and protein content in wheat by fusing multi-sensor and multi-temporal remote-sensing images. Field Crops Res. 2014, 164, 178–188. [Google Scholar] [CrossRef]
- Bolton, D.K.; Friedl, M.A. Forecasting crop yield using remotely sensed vegetation indices and crop phenology metrics. Agric. Forest Meteorol. 2013, 173, 74–84. [Google Scholar] [CrossRef]
- Franch, B.; Vermote, E.F.; Becker-Reshef, I.; Claverie, M.; Huang, J.; Zhang, J.; Justice, C.; Sobrino, J.A. Improving the timeliness of winter wheat production forecast in the United States of America, Ukraine and China using MODIS data and NCAR Growing Degree Day information. Remote Sens. Environ. 2015, 161, 131–148. [Google Scholar] [CrossRef]
- Cai, Y.; Guan, K.; Lobell, D.; Potgieter, A.B.; Wang, S.; Peng, J.; Xu, T.; Asseng, S.; Zhang, Y.; You, L.; et al. Integrating satellite and climate data to predict wheat yield in Australia using machine learning approaches. Agric. Forest Meteorol. 2019, 274, 144–159. [Google Scholar] [CrossRef]
- Chen, C.F.; Son, N.T.; Chen, C.R.; Chiang, S.H.; Chang, L.Y.; Valdez, M. Drought monitoring in cultivated areas of Central America using multi-temporal MODIS data. Geomat. Nat. Hazards Risk 2017, 8, 402–417. [Google Scholar] [CrossRef] [Green Version]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Minh, V.Q.; Trung, N.H. A comparative analysis of multitemporal MODIS EVI and NDVI data for large-scale rice yield estimation. Agric. For. Meteorol. 2014, 197, 52–64. [Google Scholar] [CrossRef]
- Deng, F.; Su, G.; Liu, C. Seasonal Variation of MODIS Vegetation Indexes and Their Statistical Relationship with Climate Over the Subtropic Evergreen Forest in Zhejiang, China. IEEE Geosci. Remote S 2007, 4, 236–240. [Google Scholar] [CrossRef]
- Gontia, N.K.; Tiwari, K.N. Yield Estimation Model and Water Productivity of Wheat Crop (Triticum aestivum) in an Irrigation Command Using Remote Sensing and GIS. J. Indian Soc. Remote 2011, 39, 27–37. [Google Scholar] [CrossRef]
- Guo, C.; Tang, Y.; Lu, J.; Zhu, Y.; Cao, W.; Cheng, T.; Zhang, L.; Tian, Y. Predicting wheat productivity: Integrating time series of vegetation indices into crop modeling via sequential assimilation. Agric. For. Meteorol. 2019, 272–273, 69–80. [Google Scholar] [CrossRef]
- Panda, S.S.; Ames, D.P.; Panigrahi, S. Application of Vegetation Indices for Agricultural Crop Yield Prediction Using Neural Network Techniques. Remote Sens. 2010, 2, 673–696. [Google Scholar] [CrossRef] [Green Version]
- Pede, T.; Mountrakis, G.; Shaw, S.B. Improving corn yield prediction across the US Corn Belt by replacing air temperature with daily MODIS land surface temperature. Agric. For. Meteorol. 2019, 276–277, 107615. [Google Scholar] [CrossRef]
- Feng, P.; Wang, B.; Liu, D.; Waters, C.; Xiao, D.; Shi, L.; Yu, Q. Dynamic wheat yield forecasts are improved by a hybrid approach using a biophysical model and machine learning technique. Agric. For. Meteorol. 2020, 285–286, 107922. [Google Scholar] [CrossRef]
- Mo, X.; Liu, S.; Lin, Z.; Xu, Y.; Xiang, Y.; McVicar, T.R. Prediction of crop yield, water consumption and water use efficiency with a SVAT-crop growth model using remotely sensed data on the North China Plain. Ecol. Model. 2005, 183, 301–322. [Google Scholar] [CrossRef]
- Huang, J.; Wang, X.; Li, X.; Tian, H.; Pan, Z. Remotely sensed rice yield prediction using multi-temporal NDVI data derived from NOAA’s-AVHRR. PLoS ONE 2013, 8, e70816. [Google Scholar] [CrossRef]
- Yao, F.; Tang, Y.; Wang, P.; Zhang, J. Estimation of maize yield by using a process-based model and remote sensing data in the Northeast China Plain. Phys. Chem. Earth Parts A/B/C 2015, 87–88, 142–152. [Google Scholar] [CrossRef]
- Yao, R.; Wang, L.; Huang, X.; Li, L.; Sun, J.; Wu, X.; Jiang, W. Developing a temporally accurate air temperature dataset for Mainland China. Sci. Total Environ. 2020, 706, 136037. [Google Scholar] [CrossRef] [PubMed]
- Karimi, Y.; Prasher, S.O.; Madani, A.; Kim, S. Application of support vector machine technology for the estimation of crop biophysical parameters using aerial hyperspectral observations. Can. Biosyst. Eng. 2008, 50, 13–20. [Google Scholar]
- Becker-Reshef, I.; Vermote, E.; Lindeman, M.; Justice, C. A generalized regression-based model for forecasting winter wheat yields in Kansas and Ukraine using MODIS data. Remote Sens. Environ. 2010, 114, 1312–1323. [Google Scholar] [CrossRef]
- FOASTAT. Food and Agriculture Organization; FOASTAT Database: New York, NY, USA, 2017. [Google Scholar]
- You, L.; Wood, S.; Wood-sichra, U. Generating global crop distribution maps: From census to grid. Agric. Syst. 2014, 127, 53–60. [Google Scholar] [CrossRef] [Green Version]
- Jones, P.D.; Harris, I.C. Climatic Research Unit (CRU): Time-Series (TS) Datasets of Variations in Climate with Variations in Other Phenomena v3; University of East Anglia Climatic Research Unit, NCAS British Atmospheric Data Centre: Leeds, UK, 2008. [Google Scholar]
- Jiang, H.; Hu, H.; Zhong, R.; Xu, J.; Xu, J.; Huang, J.; Wang, S.; Ying, Y.; Lin, T. A deep learning approach to conflating heterogeneous geospatial data for corn yield estimation: A case study of the US Corn Belt at the county level. Glob. Chang. Biol. 2020, 26, 1754–1766. [Google Scholar] [CrossRef] [PubMed]
- Butler, E.E.; Huybers, P. Adaptation of US maize to temperature variations. Nat. Clim. Chang. 2013, 3, 68–72. [Google Scholar] [CrossRef]
- Mishra, A.K.; Singh, V.P. Drought modeling—A review. J. Hydrol. 2011, 403, 157–175. [Google Scholar] [CrossRef]
- Zuo, D.; Cai, S.; Xu, Z.; Peng, D.; Kan, G.; Sun, W.; Pang, B.; Yang, H. Assessment of meteorological and agricultural droughts using in-situ observations and remote sensing data. Agric. Water Manag. 2019, 222, 125–138. [Google Scholar] [CrossRef]
- Zhang, F.; Yanan, C.; Jiquan, Z.; Enliang, G.; Wang, R.; Li, D. Dynamic drought risk assessment for maize based on crop simulation model and multi-source drought indices. J. Clean. Prod. 2019, 233, 100–114. [Google Scholar] [CrossRef]
- Fu, J.; Niu, J.; Kang, S.; Adeloye, A.J.; Du, T. Crop production in the Hexi Corridor challenged by future climate change. J. Hydrol. 2019, 579, 124197. [Google Scholar] [CrossRef]
- Quinlan, R. Learning with continuous classes. Aust. Jt. Conf. Artif. Intell. 1992, 92, 343–348. [Google Scholar]
- Houborg, R.; McCabe, M.F. A hybrid training approach for leaf area index estimation via Cubist and random forests machine-learning. ISPRS J. Photogramm. 2018, 135, 173–188. [Google Scholar] [CrossRef]
- Johnson, D.M. An assessment of pre- and within-season remotely sensed variables for forecasting corn and soybean yields in the United States. Remote Sens. Environ. 2014, 141, 116–128. [Google Scholar] [CrossRef]
- Kuhn, M.; Weston, S.; Keefer, C.; Counlter, N. Cubist Models for Regression. 2012. Available online: https://mran.microsoft.com/snapshot/2016-09-15/web/packages/Cubist/vignettes/cubist.pdf (accessed on 25 December 2020).
- LV, Y.; Le, Q.; Bui, H.; Bui, X.; Nguyen, H.; Nguyen-Thoi, T.; Dou, J.; Song, X. A Comparative Study of Different Machine Learning Algorithms in Predicting the Content of Ilmenite in Titanium Placer. Appl. Sci. 2020, 10, 635. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Adam, E.M.I.; Mutanga, O. Estimation of high density wetland biomass: Combining regression model with vegetation index developed from Worldview-2 imagery. In Proceedings of the SPIE, Edinburgh, UK, 24–27 September 2012; Volume 8531, p. 85310V. [Google Scholar]
- Tulbure, M.G.; Wimberly, M.C.; Boe, A.; Owens, V.N. Climatic and genetic controls of yields of switchgrass, a model bioenergy species. Agric. Ecosyst. Environ. 2012, 146, 121–129. [Google Scholar] [CrossRef]
- Everingham, Y.; Sexton, J.; Skocaj, D.; Inman-Bamber, G. Accurate prediction of sugarcane yield using a random forest algorithm. Agron. Sustain. Dev. 2016, 36, 27. [Google Scholar] [CrossRef] [Green Version]
- Prasad, A.M.; Iverson, L.R.; Liaw, A. Newer Classification and Regression Tree Techniques: Bagging and Random Forests for Ecological Prediction. Ecosystems 2006, 9, 181–199. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the 22nd Acm Sigkdd International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhang, L.; Ai, H.; Chen, W.; Yin, Z.; Hu, H.; Zhu, J.; Zhao, J.; Zhao, Q.; Liu, H. CarcinoPred-EL: Novel models for predicting the carcinogenicity of chemicals using molecular fingerprints and ensemble learning methods. Sci. Rep. 2017, 7, 2118. [Google Scholar] [CrossRef]
- Cortes, C.; Vapink, A. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Brdar, S.; Culibrk, D.; Marinkovic, B.; Crnobaracy, J.; Crnojevic, V. Support Vector Machines with Features Contribution Analysis for Agricultural Yield Prediction. In Proceedings of the Second International Workshop on Sensing Technologies in Agriculture, Forestry and Environment (EcoSense 2011), Belgrade, Serbia, 6–7 April 2011; pp. 43–47. [Google Scholar]
- Cai, Y.D.; Ricardo, P.W.; Jen, C.H.; Chou, K.C. Application of SVM to predict membrane protein types. J. Theor. Biol. 2004, 226, 373–376. [Google Scholar] [CrossRef] [Green Version]
- Bermolen, P.; Rossi, D. Support vector regression for link load prediction. Comput. Netw. 2009, 53, 191–201. [Google Scholar] [CrossRef]
- Tollenaar, M.; Fridgen, J.; Tyagi, P.; Stackhouse, P.W., Jr.; Kumudini, S. The contribution of solar brightening to the US maize yield trend. Nat. Clim. Chang. 2017, 7, 275–278. [Google Scholar] [CrossRef]
- Chen, X.; Wang, L.; Niu, Z.; Zhang, M.; Li, C.; Li, J. The effects of projected climate change and extreme climate on maize and rice in the Yangtze River Basin, China. Agric. For. Meteorol. 2020, 282–283, 107867. [Google Scholar] [CrossRef]
- Son, N.T.; Chen, C.F.; Chen, C.R.; Chang, L.Y.; Duc, H.N.; Nguyen, L.D. Prediction of rice crop yield using MODIS EVI−LAI data in the Mekong Delta, Vietnam. Int. J. Remote Sens. 2013, 34, 7275–7292. [Google Scholar] [CrossRef]
- Benedetti, R.; Rossini, P. On the use of NDVI profiles as a tool for agricultural statistics: The case study of wheat yield estimate and forecast in Emilia Romagna. Remote Sens. Environ. 1993, 45, 311–326. [Google Scholar] [CrossRef]
- Sánchez, B.; Rasmussen, A.; Porter, J.R. Temperatures and the growth and development of maize and rice: A review. Glob. Chang. Biol. 2014, 20, 408–417. [Google Scholar] [CrossRef]
- Daryanto, S.; Wang, L.; Jacinthe, P. Global Synthesis of Drought Effects on Maize and Wheat Production. PLoS ONE 2016, 11, e156362. [Google Scholar] [CrossRef]
- Kern, A.; Barcza, Z.; Marjanović, H.; Árendás, T.; Fodor, N.; Bónis, P.; Bognár, P.; Lichtenberger, J. Statistical modelling of crop yield in Central Europe using climate data and remote sensing vegetation indices. Agric. For. Meteorol. 2018, 260–261, 300–320. [Google Scholar] [CrossRef]
- Wang, Q.; Adiku, S.; Tenhunen, J.; Granier, A. On the relationship of NDVI with leaf area index in a deciduous forest site. Remote sensing of environment. Remote Sens. Environ. 2005, 94, 244–255. [Google Scholar] [CrossRef]
- Cohen, W.B.; Maiersperger, T.K.; Gower, S.T.; Turner, D.P. An improved strategy for regression of biophysical variables and Landsat ETM+ data. Remote Sens. Environ. 2003, 84, 561–571. [Google Scholar] [CrossRef] [Green Version]
- Conradt, S.; Bokusheva, R.; Finger, R.; Kussaiynov, T. Yield Trend Estimation in the Presence of Farm Heterogeneity and Non-linear Technological Change. Q. J. Int. Agric. 2014, 53, 121–140. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Northeast China | North China Plain | Northwest China | Southwest China | South China | |
|---|---|---|---|---|---|
| Altitude (m) | 323.268 | 947.513 | 2358.135 | 3429.555 | 331.731 |
| Mean temperature in maize growing season (°C/day) | 14.320 | 19.912 | 15.776 | 19.523 | 21.715 |
| Precipitation (mm/month) | 67.307 | 81.762 | 29.284 | 129.170 | 137.058 |
| Potential evapotranspiration (mm/day) | 26.752 | 33.066 | 13.765 | 51.356 | 53.822 |
| Diffuse flux of photosynthetic active radiation (W m−2/day) | 59.922 | 62.902 | 62.8185 | 64.051 | 64.341 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, X.; Feng, L.; Yao, R.; Wu, X.; Sun, J.; Gong, W. Prediction of Maize Yield at the City Level in China Using Multi-Source Data. Remote Sens. 2021, 13, 146. https://doi.org/10.3390/rs13010146
Chen X, Feng L, Yao R, Wu X, Sun J, Gong W. Prediction of Maize Yield at the City Level in China Using Multi-Source Data. Remote Sensing. 2021; 13(1):146. https://doi.org/10.3390/rs13010146
Chicago/Turabian StyleChen, Xinxin, Lan Feng, Rui Yao, Xiaojun Wu, Jia Sun, and Wei Gong. 2021. "Prediction of Maize Yield at the City Level in China Using Multi-Source Data" Remote Sensing 13, no. 1: 146. https://doi.org/10.3390/rs13010146
APA StyleChen, X., Feng, L., Yao, R., Wu, X., Sun, J., & Gong, W. (2021). Prediction of Maize Yield at the City Level in China Using Multi-Source Data. Remote Sensing, 13(1), 146. https://doi.org/10.3390/rs13010146