RSCNN: A CNN-Based Method to Enhance Low-Light Remote-Sensing Images


Abstract
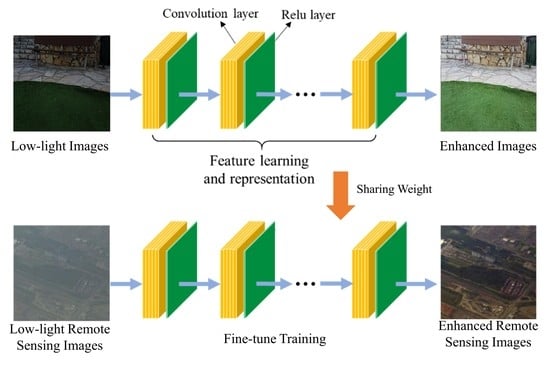
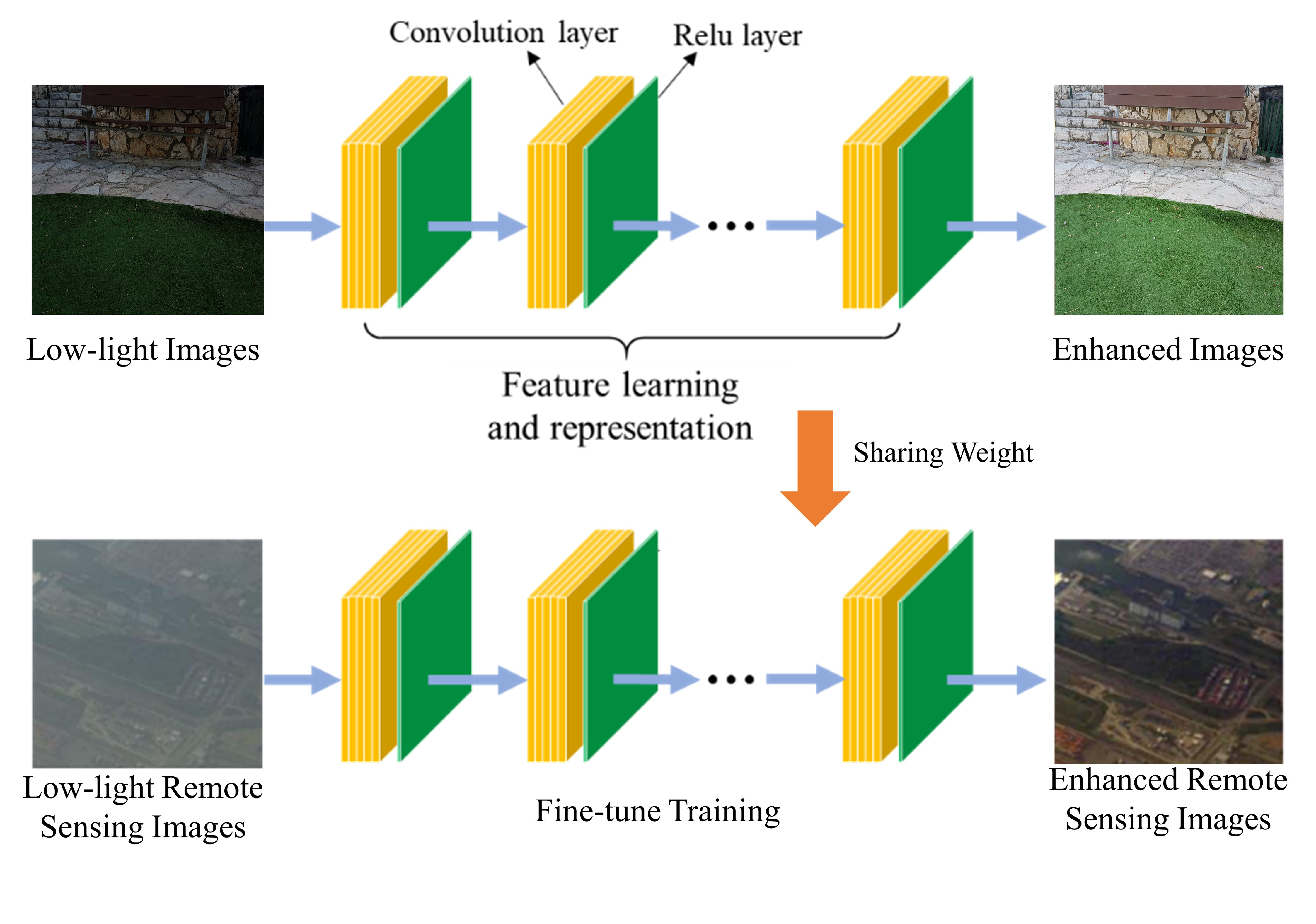
:
1. Introduction
2. Materials and Methods
2.1. Formatting of Mathematical Components
- (1)
- Convolution layer
- (2)
- Activation layer
- (3)
- Upsampling operation
- (4)
- Max-pooling operation
2.2. Loss Function
2.3. Training
- (1)
- Datasets
- (2)
- Evaluation criteria
2.4. Implementation Details
2.5. Baselines
3. Results and Discussion
3.1. Comparison Results on Dataset1
3.2. Comparison Results on Dataset2
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Yang, J.; Gong, P.; Fu, R.; Zhang, M.; Chen, J.; Liang, S. Dickinson, R. The role of satellite remote sensing in climate change studies. Nat. Clim. Chang. 2013, 3, 875–883. [Google Scholar] [CrossRef]
- Gastellu-Etchegorry, J.P. 3D modeling of satellite spectral images, radiation budget and energy budget of urban landscapes. Meteorol. Atmos. Phys. 2008, 102, 187–207. [Google Scholar] [CrossRef] [Green Version]
- Jones, M.O.; Jones, L.A.; Kimball, J.S.; McDonald, K.C. Satellite passive microwave remote sensing for monitoring global land surface phenology. Remote Sens. Environ. 2011, 115, 1102–1114. [Google Scholar] [CrossRef]
- Liu, C.; Cheng, I.; Zhang, Y.; Basu, A. Enhancement of low visibility aerial images using histogram truncation and an explicit Retinex representation for balancing contrast and color consistency. ISPRS J. Photogramm. Remote Sens. 2017, 128, 16–26. [Google Scholar] [CrossRef]
- Zollini, S.; Alicandro, M.; Cuevas-González, M.; Baiocchi, V.; Dominici, D.; Buscema, P.M. Shoreline extraction based on an active connection matrix (ACM) image enhancement strategy. J. Mar. Sci. Eng. 2020, 8, 9. [Google Scholar] [CrossRef] [Green Version]
- Dominici, D.; Zollini, S.; Alicandro, M.; della Torre, F.; Buscema, P.M.; Baiocchi, V. High resolution satellite images for instantaneous shoreline extraction using new enhancement algorithms. Geosciences 2019, 9, 123. [Google Scholar] [CrossRef] [Green Version]
- Gonzalez, R.C.; Woods, R.E.; Masters, B.R. Digital Image Processing, Third Edition. J. Biomed. Opt. 2009, 14, 029901. [Google Scholar] [CrossRef]
- Abdullah-Al-Wadud, M.; Kabir, M.; Dewan, M.A.; Chae, O. A Dynamic Histogram Equalization for Image Contrast Enhancement. IEEE Trans. Consum. Electron. 2007, 53, 593–600. [Google Scholar] [CrossRef]
- Ibrahim, H.; Kong, N.S.P. Brightness preserving dynamic histogram equalization for image contrast enhancement. IEEE Trans. Consum. Electron. 2007, 53, 1752–1758. [Google Scholar] [CrossRef]
- Asha, S.; Sreenivasulu, G. Satellite Image Enhancement Using Contrast Limited Adaptive Histogram Equalization. Int. J. Sci. Res. Sci. Eng. Technol. 2018, 4, 1070–1075. [Google Scholar]
- Zhou, W. Image quality assessment: From error measurement to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–613. [Google Scholar]
- Tao, L.; Zhu, C.; Song, J.; Lu, T.; Jia, H.; Xie, X. Low-light image enhancement using CNN and bright channel prior. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3215–3219. [Google Scholar]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. Properties and performance of a center/surround retinex. IEEE Trans. Image Process. 1997, 6, 451–462. [Google Scholar] [CrossRef] [PubMed]
- Rahman, Z.; Jobson, D.J.; Woodell, G.A. Multi-scale retinex for color image enhancement. IEEE Int. Conf. Image Process. 1996, 3, 1003–1006. [Google Scholar]
- Jobson, D.J.; Rahman, Z.U.; Woodell, G.A. A multiscale retinex for bridging the gap between color images and the human observation of scenes. IEEE Trans. Image Process. 1997, 6, 965–976. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Guo, X.; Li, Y.; Ling, H. LIME: Low-Light Image Enhancement via Illumination Map Estimation. IEEE Trans. Image Process. 2017, 26, 982–993. [Google Scholar] [CrossRef] [PubMed]
- Ying, Z.; Li, G.; Gao, W. A Bio-Inspired Multi-Exposure Fusion Framework for Low-light Image Enhancement. arXiv 2017, arXiv:1711.00591. [Google Scholar]
- Lee, C.-H.; Shih, J.-L.; Lien, C.-C.; Han, C.-C. Adaptive multiscale retinex for image contrast enhancement. In Proceedings of the International Conference on Signal-Image Technology & Internet-Based Systems, Kyoto, Japan, 2–5 December 2013; pp. 43–50. [Google Scholar]
- Ying, Z.; Li, G.; Ren, Y.; Wang, R.; Wang, W. A new image contrast enhancement algorithm using exposure fusion framework. In International Conference on Computer Analysis of Images and Patterns; Springer: Cham, Germany, 2017; pp. 36–46. [Google Scholar]
- Bhandari, A.K.; Soni, V.; Kumar, A.; Singh, G.K. Cuckoo search algorithm based satellite image contrast and brightness enhancement using DWT–SVD. ISA Trans. 2014, 53, 1286–1296. [Google Scholar] [CrossRef]
- Demirel, H.; Ozcinar, C.; Anbarjafari, G. Satellite image contrast enhancement using discrete wavelet transform and singular value decomposition. IEEE Geosci. Remote Sens. Lett. 2010, 7, 333–337. [Google Scholar] [CrossRef]
- Li, C.; Guo, J.; Porikli, F.; Pang, Y. LightenNet: A Convolutional Neural Network for weakly illuminated image enhancement. Pattern Recognit. Lett. 2018, 104, 15–22. [Google Scholar] [CrossRef]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep Retinex Decomposition for Low-Light Enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef] [Green Version]
- Xie, J.; Xu, L.; Chen, E. Image denoising and inpainting with deep neural networks. Adv. Neural Inf. Process. Syst. 2012, 1, 341–349. [Google Scholar]
- Tao, L.; Zhu, C.; Xiang, G.; Li, Y.; Jia, H.; Xie, X. LLCNN: A convolutional neural network for low-light image enhancement. In Proceedings of the IEEE Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-light Image/Video Enhancement Using CNNs. In Proceedings of the British Machine Vision Conference (BMVC), Newcastle, UK, 3–6 September 2018; pp. 1–13. [Google Scholar]
- Chen, C.; Chen, Q.; Xu, J.; Koltun, V. Learning to see in the dark. arXiv 2018, arXiv:1805.01934. [Google Scholar]
- Fu, X.; Wang, J.; Zeng, D.; Huang, Y.; Ding, X. Remote Sensing Image Enhancement Using Regularized-Histogram Equalization and DCT. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2301–2305. [Google Scholar] [CrossRef]
- Lee, E.; Kim, S.; Kang, W.; Seo, D.; Paik, J. Contrast enhancement using dominant brightness level analysis and adaptive intensity transformation for remote sensing images. IEEE Geosci. Remote Sens. Lett. 2013, 10, 62–66. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and Understanding Convolutional Networks. In Proceedings of the European Conference on Computer Vision (ECCV), Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 818–833. [Google Scholar]
- Lai, W.S.; Huang, J.B.; Ahuja, N.; Yang, M.H. Deep laplacian pyramid networks for fast and accurate super-resolution. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5835–5843. [Google Scholar]
- Zhao, Y.; Li, G.; Xie, W.; Jia, W.; Min, H.; Liu, X. GUN: Gradual Upsampling Network for Single Image Super-Resolution. IEEE Access 2018, 6, 39363–39374. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Wang, H.; Li, P. End-to-End Image Super-Resolution via Deep and Shallow Convolutional Networks. IEEE Access 2019, 7, 31959–31970. [Google Scholar] [CrossRef]
- Joshi, S.H.; Marquina, A.L.; Osher, S.J.; Dinov, I.; Toga, A.W.; van Horn, J.D. Fast edge-filtered image upsampling. In Proceedings of the 18th IEEE International Conference on Image Processing (ICIP), Brussels, Belgium, 11–14 September 2011; pp. 1165–1168. [Google Scholar]
- Schwartz, E.; Giryes, R.; Bronstein, A.M. DeepISP: Toward learning an end-to-end image processing pipeline. IEEE Trans. Image Process. 2019, 28, 912–923. [Google Scholar] [CrossRef] [Green Version]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 2–5 November 2010; pp. 270–279. [Google Scholar]
- Luo, M.R.; Cui, G.; Rigg, B. The development of the CIE 2000 colour-difference formula: CIEDE2000. Color. Res. Appl. 2001, 26, 340–350. [Google Scholar] [CrossRef]
- Dong, C.; Loy, C.C.; He, K.; Tang, X. Image Super-Resolution Using Deep Convolutional Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 295–307. [Google Scholar] [CrossRef] [Green Version]
- Shen, L.; Yue, Z.; Feng, F.; Chen, Q.; Liu, S.; Ma, J. MSR-net:Low-light Image Enhancement Using Deep Convolutional Network. arXiv 2017, arXiv:1711.02488. [Google Scholar]
- Kundeti, N.M.; Kalluri, H.K.; Krishna, S.V.R. Image enhancement using DT-CWT based cycle spinning methodology. In Proceedings of the IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Madurai, India, 26–28 December 2013; pp. 185–188. [Google Scholar]
- Rasti, P.; Lüsi, I.; Demirel, H.; Kiefer, R.; Anbarjafari, G. Wavelet transform based new interpolation technique for satellite image resolution enhancement. In Proceedings of the IEEE International Conference on Aerospace Electronics and Remote Sensing Technology, Yogyakarta, Indonesia, 13–14 November 2014; pp. 185–188. [Google Scholar]
- Sharma, G.; Wu, W.; Dalal, E.N. The CIEDE2000 color-difference formula: Implementation notes, supplementary test data, and mathematical observations. Color. Res. Appl. 2005, 30, 21–30. [Google Scholar] [CrossRef]
- Haut, J.M.; Fernandez-Beltran, R.; Paoletti, M.E.; Plaza, J.; Plaza, A.; Pla, F. A new deep generative network for unsupervised remote sensing single-image super-resolution. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6792–6810. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving deep into rectifiers: Surpassing human-level performance on imagenet classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef] [Green Version]
- Cheng, G.; Zhou, P.; Han, J. Learning rotation-invariant convolutional neural networks for object detection in VHR optical remote sensing images. IEEE Trans. Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Abbreviation | Type | |
|---|---|---|---|
| 1 | Histogram Equalization [7] | HE | Histogram |
| 2 | Dynamic Histogram Equalization (DHE) [8] | DHE | Histogram |
| 3 | Contrast Limited Adaptive Histogram Equalization [10] | CLAHE | Histogram |
| 4 | Single-scale Retinex [13] | SSR | Retinex |
| 5 | Multi-scale Retinex [14] | MSR | Retinex |
| 6 | Multi-Scale Retinex with Color Restoration [15] | MSRCR | Retinex |
| 7 | Low-light image enhancement method [16] | LIME | Illumination map estimation and Retinex |
| 8 | Bio-Inspired Multi-Exposure Fusion Framework for Low-light Image Enhancement [17] | BIMEF | Illumination map estimation and camera response model |
| 9 | Discrete Wavelet Transform and Singular Value Decomposition [21] | DWT-SVD | Frequency domain |
| SSIM | PSNR | |
|---|---|---|
| HE | 0.482 | 16.774 |
| DHE | 0.546 | 18.080 |
| CLAHE | 0.548 | 14.192 |
| SSR | 0.570 | 14.529 |
| MSR | 0.585 | 13.959 |
| MSRCR | 0.610 | 16.582 |
| LIME | 0.464 | 17.152 |
| BIMEF | 0.632 | 17.646 |
| DWT-SVD | 0.617 | 17.806 |
| RSCNN | 0.825 | 28.194 |
| SSIM | PSNR | CIEDE2000 | |
|---|---|---|---|
| HE | 0.730 | 15.905 | 67.628 |
| DHE | 0.706 | 16.357 | 52.272 |
| CLAHE | 0.546 | 13.857 | 70.600 |
| SSR | 0.711 | 20.424 | 30.972 |
| MSR | 0.751 | 20.610 | 28.586 |
| MSRCR | 0.680 | 19.088 | 38.212 |
| LIME | 0.630 | 15.074 | 60.154 |
| BIMEF | 0.728 | 16.302 | 50.697 |
| DWT-SVD | 0.564 | 13.989 | 76.490 |
| RSCNN | 0.852 | 21.691 | 19.496 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, L.; Qin, M.; Zhang, F.; Du, Z.; Liu, R. RSCNN: A CNN-Based Method to Enhance Low-Light Remote-Sensing Images. Remote Sens. 2021, 13, 62. https://doi.org/10.3390/rs13010062
Hu L, Qin M, Zhang F, Du Z, Liu R. RSCNN: A CNN-Based Method to Enhance Low-Light Remote-Sensing Images. Remote Sensing. 2021; 13(1):62. https://doi.org/10.3390/rs13010062
Chicago/Turabian StyleHu, Linshu, Mengjiao Qin, Feng Zhang, Zhenhong Du, and Renyi Liu. 2021. "RSCNN: A CNN-Based Method to Enhance Low-Light Remote-Sensing Images" Remote Sensing 13, no. 1: 62. https://doi.org/10.3390/rs13010062
APA StyleHu, L., Qin, M., Zhang, F., Du, Z., & Liu, R. (2021). RSCNN: A CNN-Based Method to Enhance Low-Light Remote-Sensing Images. Remote Sensing, 13(1), 62. https://doi.org/10.3390/rs13010062