Accelerating Haze Removal Algorithm Using CUDA



Abstract
:1. Introduction
2. An Image Haze Removal Algorithm Based on Dark Channel Prior
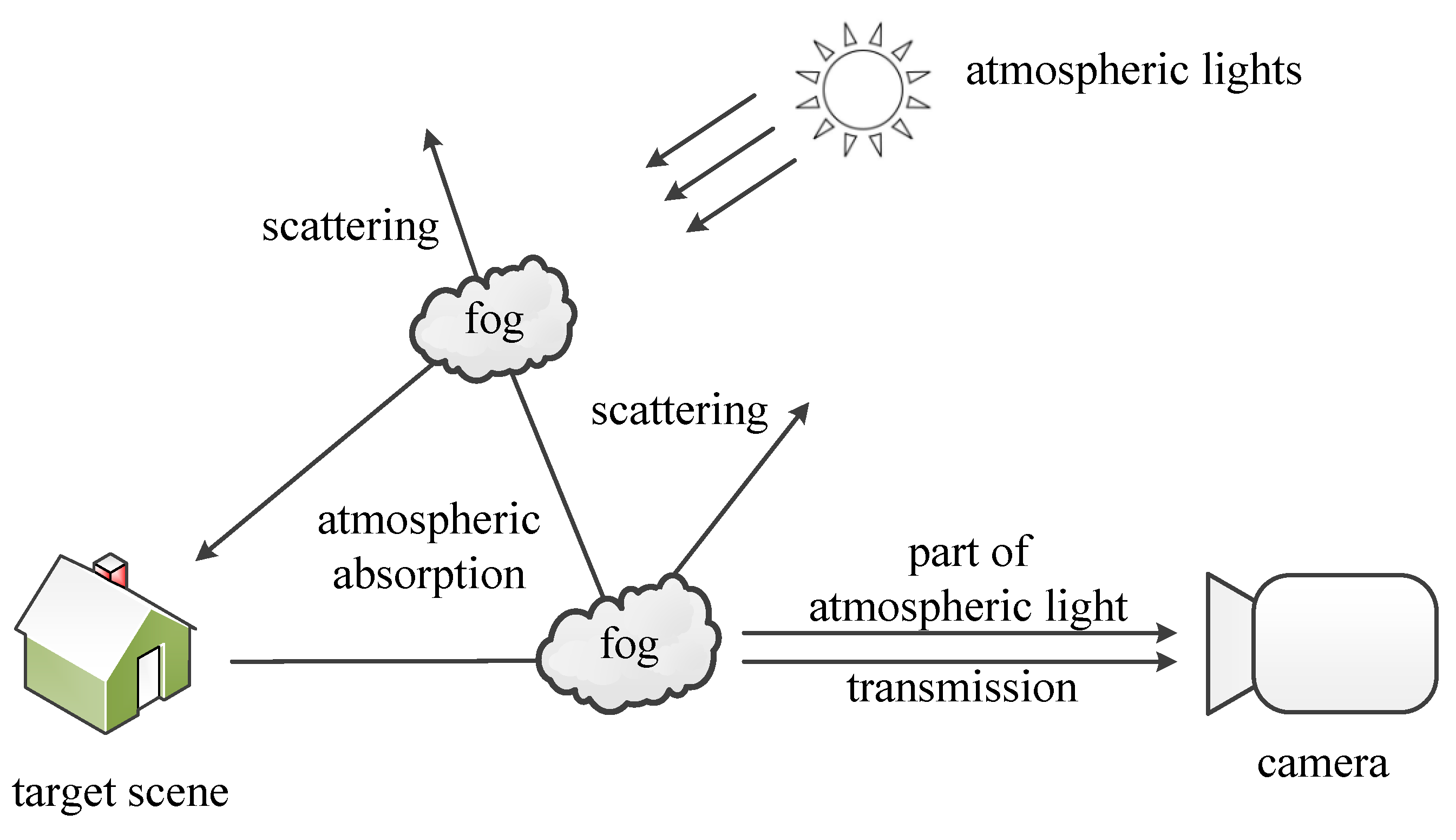
2.1. Haze Imaging Model
2.2. Dark Channel Prior
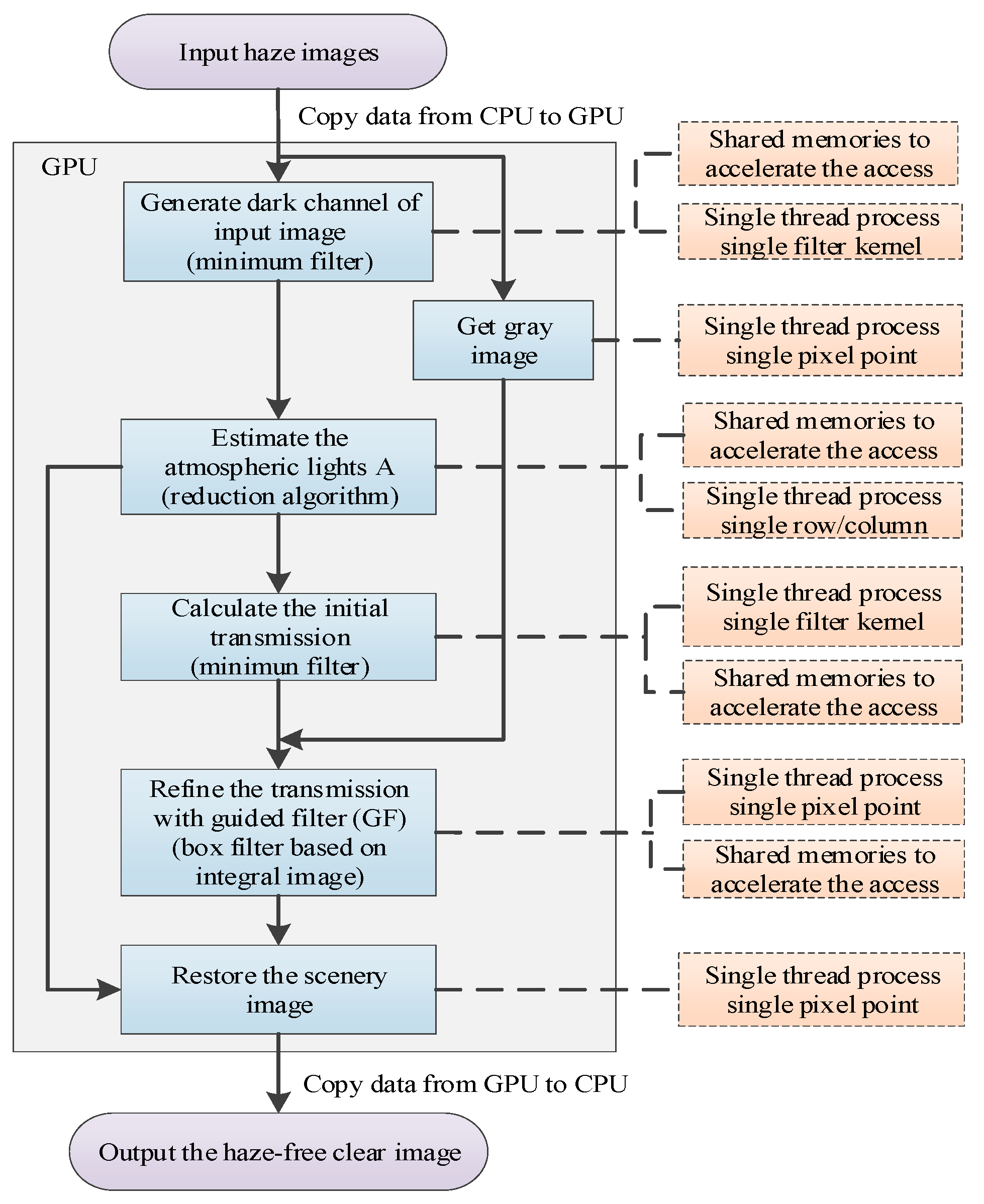
2.3. Algorithm Flow
- (1)
- Calculate the grayscale image with:
- (2)
- Calculate the dark channel by Equation (2).
- (3)
- Estimate the global atmospheric light based on the input haze image and its dark channel map. First, we index the position of the brightest 0.1% pixels in the dark channel map. Then, we calculate the average value of the pixels in these locations in as the atmospheric light .
- (4)
- Assume that the value of scenery transmission remains as a constant in a local patch and define the transmission as . According to the haze imaging model and the dark channel prior, we obtain the initial transmission with:where the patch size is typically . The variable is introduced into the transmission equation above to maintain the effect of depth and reality [3]. In order to reserve a small portion of haze for the remote scene in the image, we set to 0.95 in this paper.
- (5)
- The guided filtering is performed on the initial transmission with the gray image as the guidance image and obtain the refined transmission . The soft matting algorithm is replaced in this paper due to its computing complexity.
- (6)
- To reduce the color distortion, the transmission [25] is adjusted for the bright areas with tolerances :The value of is set to 80 in our experiments.
- (7)
- Based on the atmospheric light and transmission , we can restore the clear image by Equation (6). Given the transmission , a minimum limit .
2.4. Atmospheric Light Optimization
3. GPU-Accelerated Implementation for Image Haze Removal Based on Dark Channel Prior
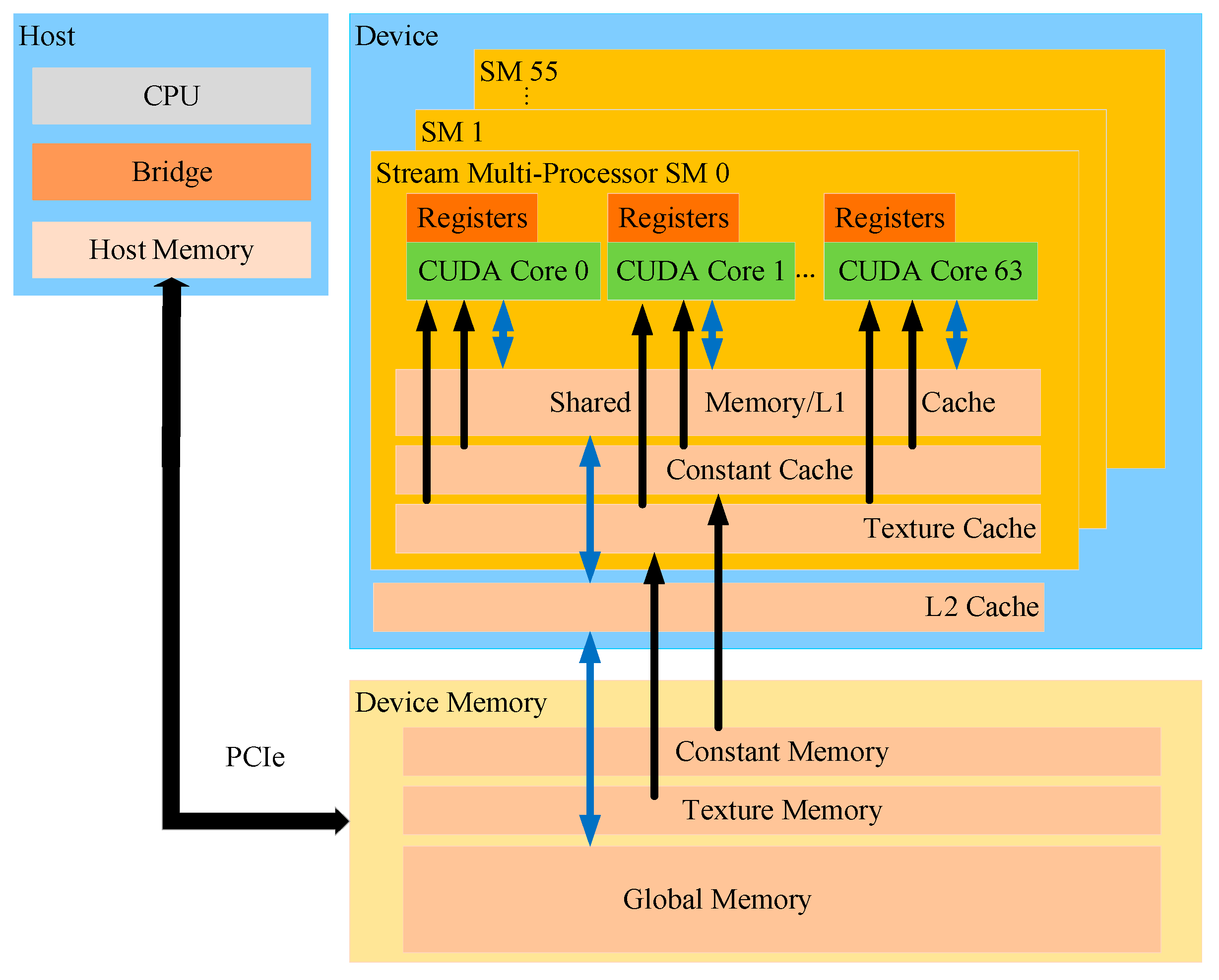
3.1. General GPU Parallel-Computing
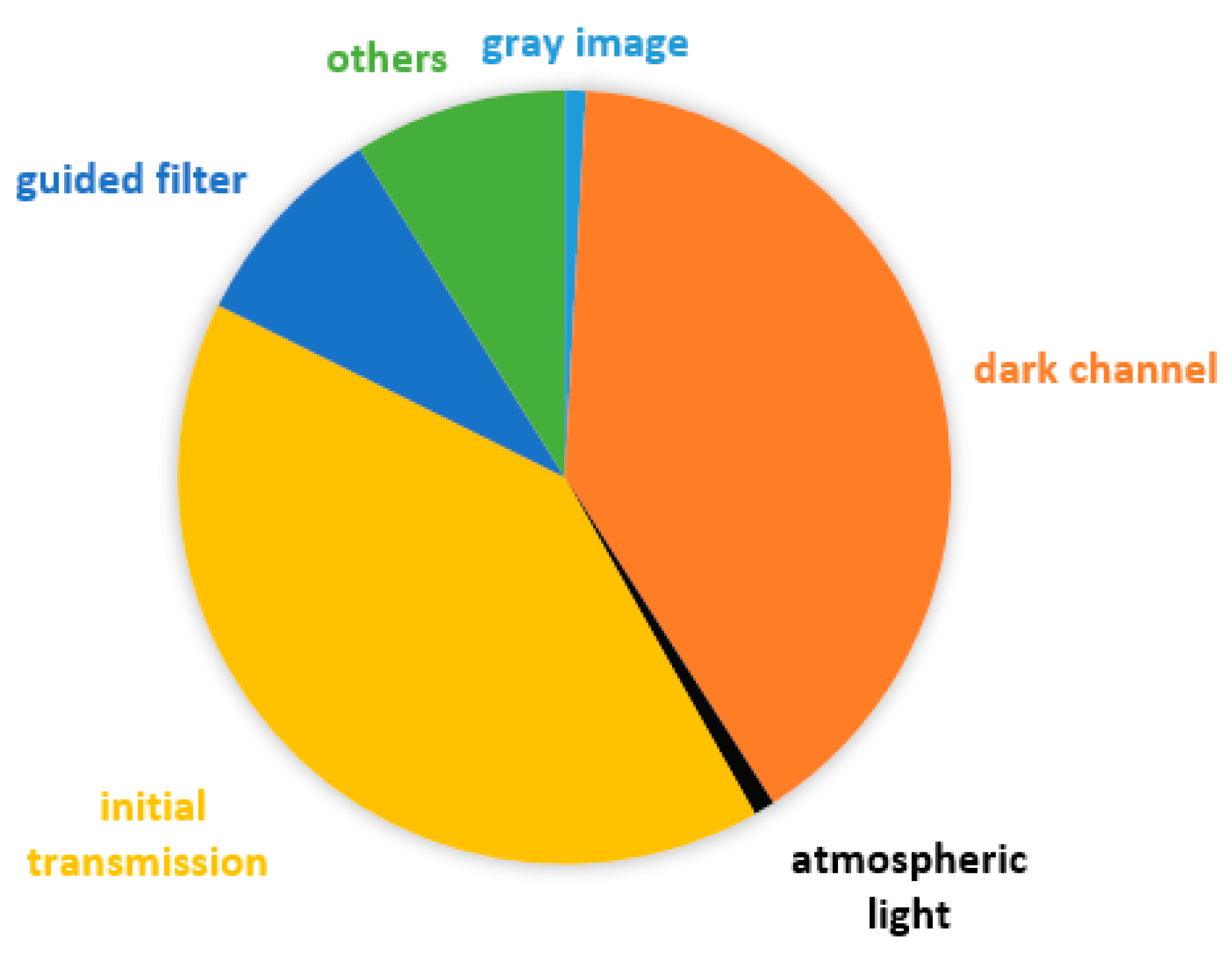
3.2. The Time-Consuming Part
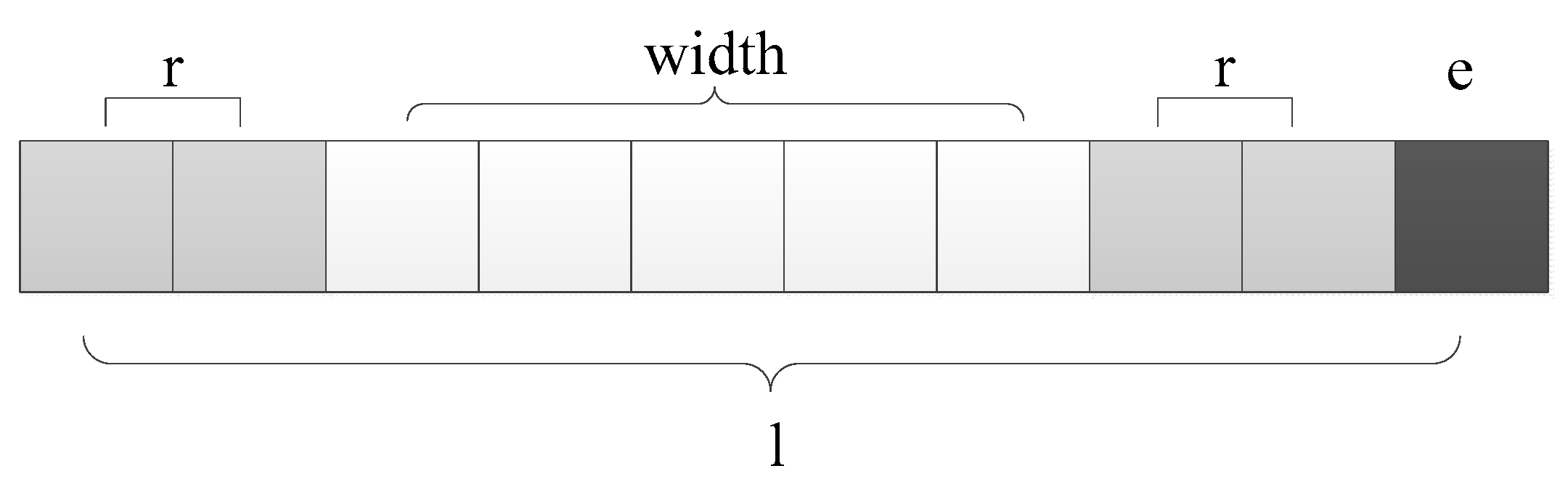
3.2.1. The Minimum Filter
3.2.2. The Mean Filter
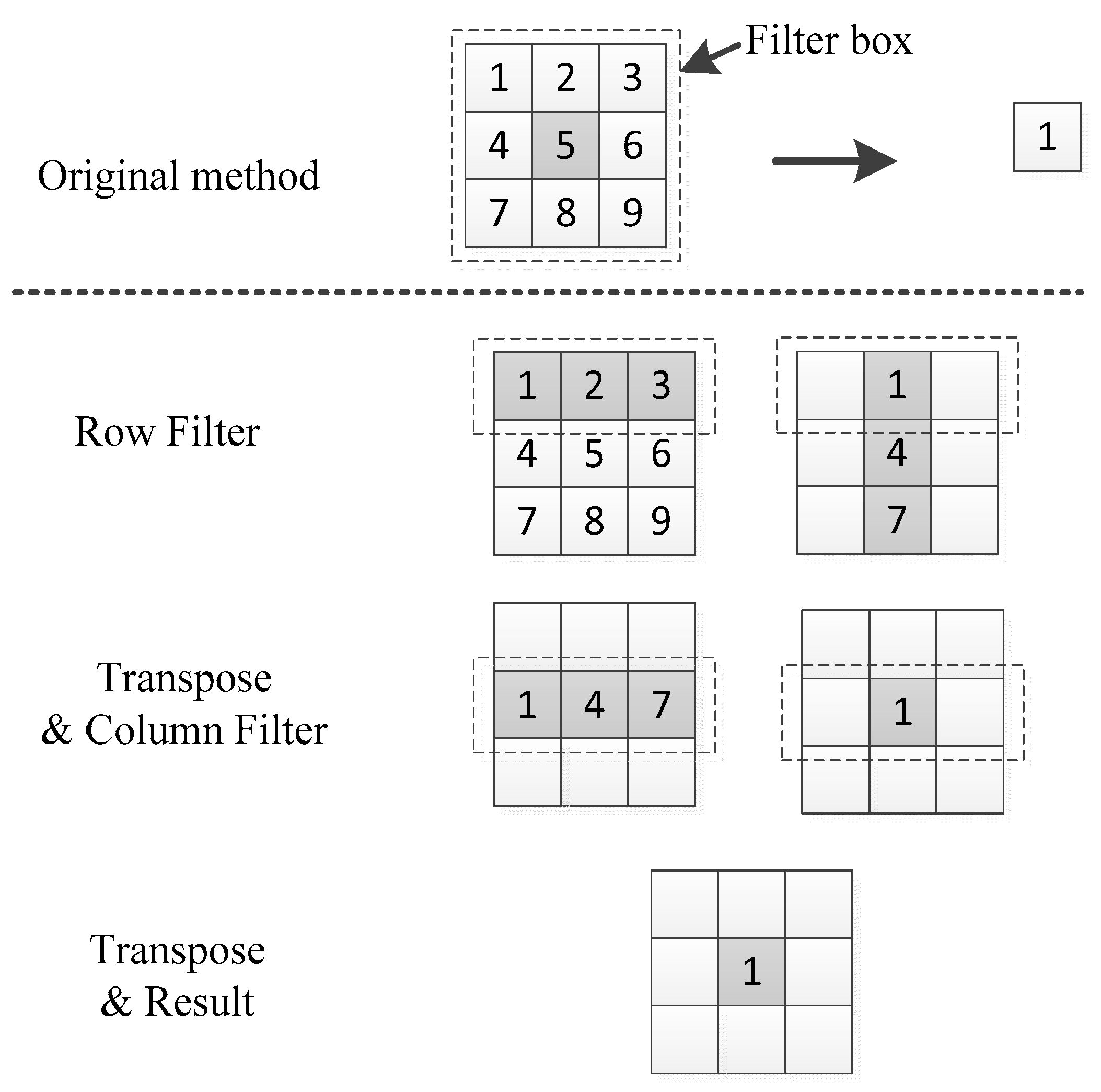
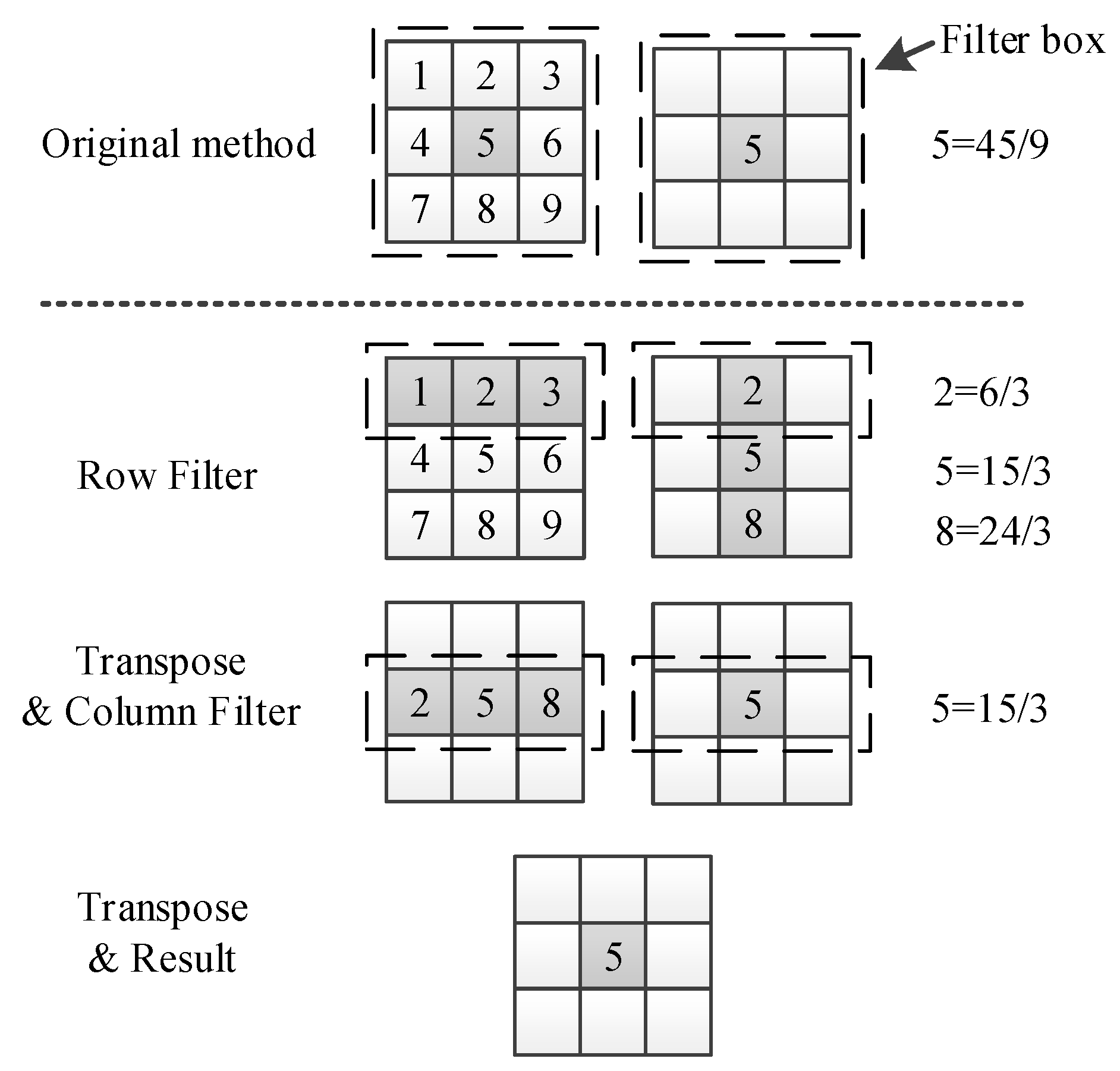
3.3. Transposed Filter Algorithm Based on GPU
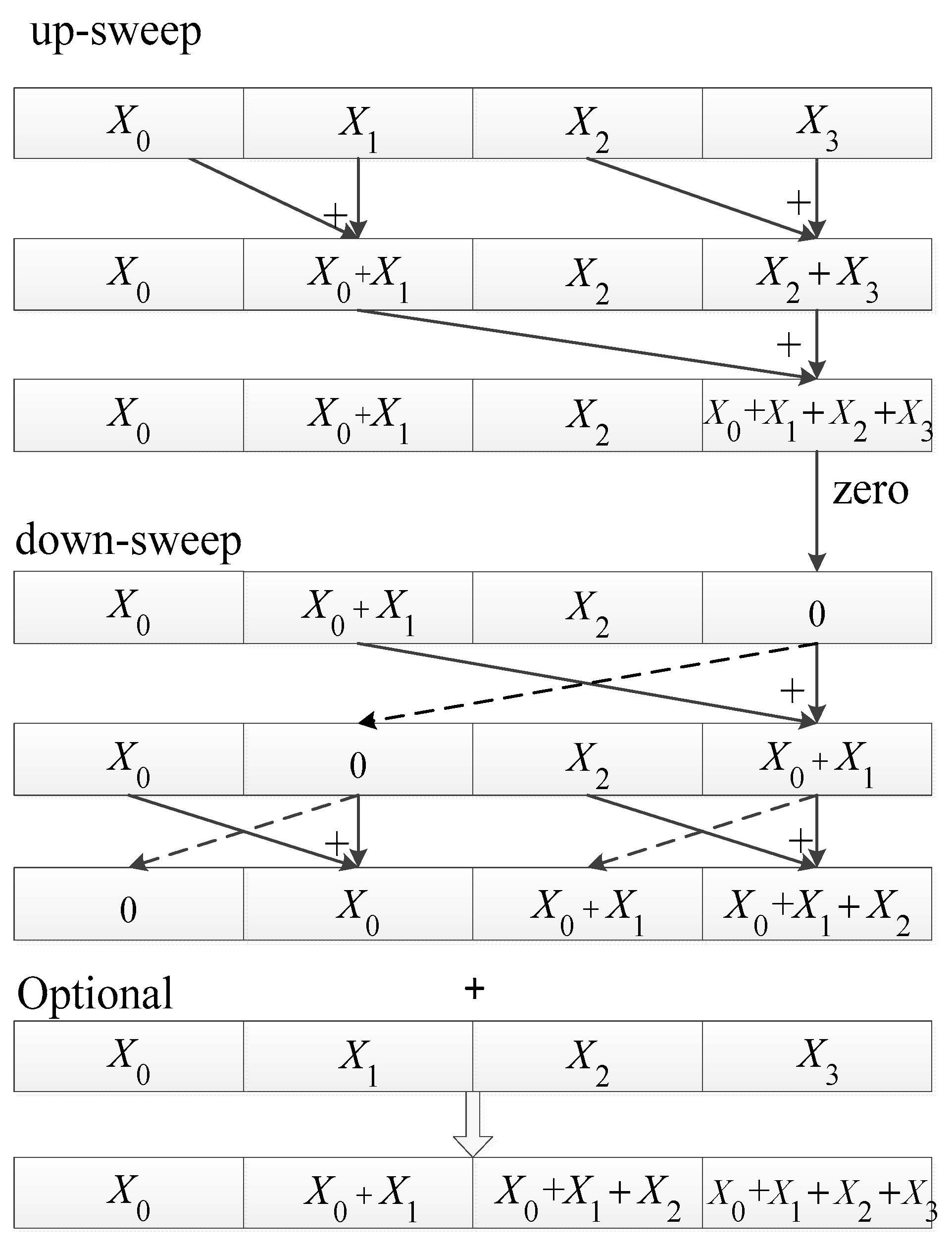
3.3.1. Transposed Filter Algorithm
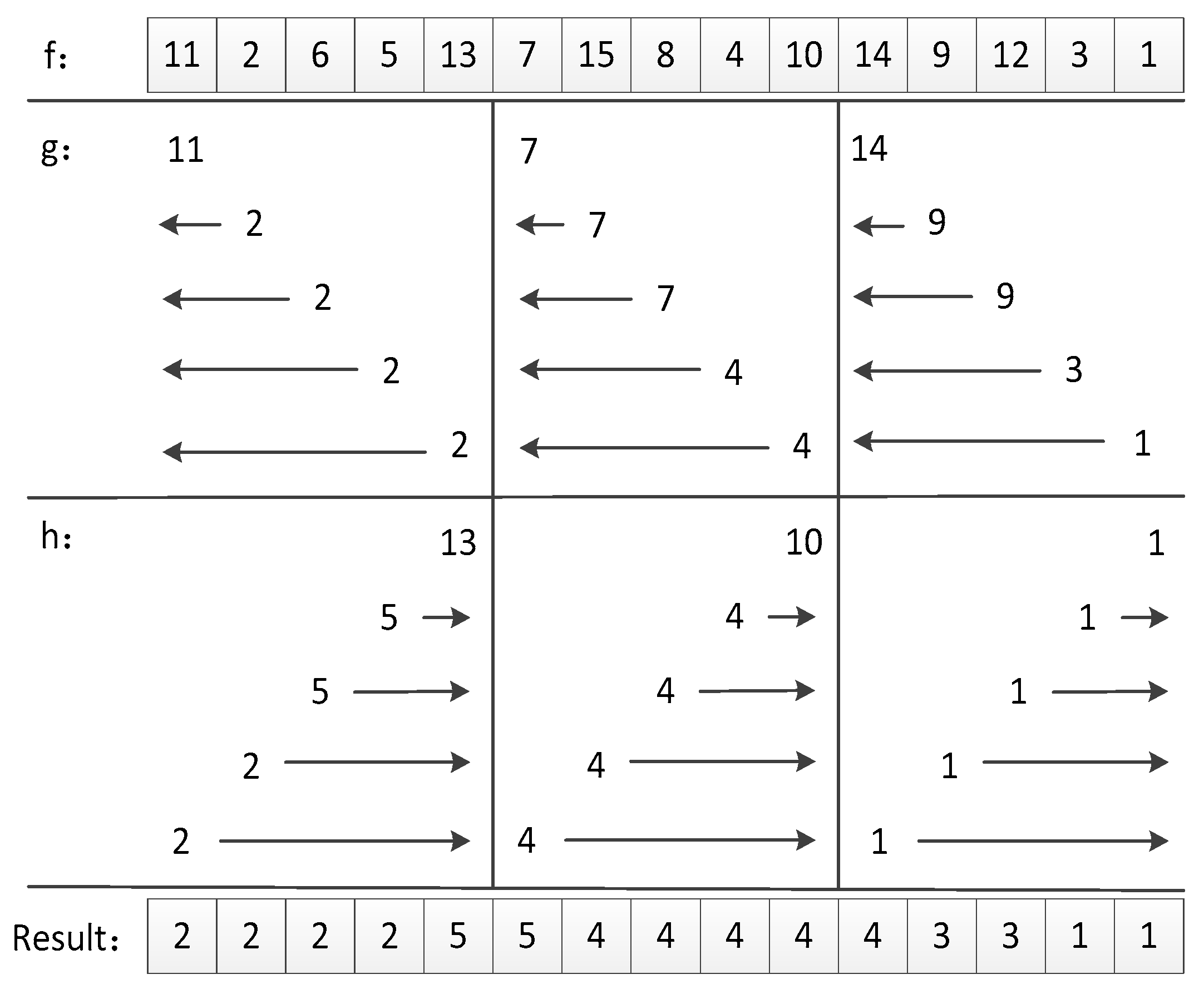
3.3.2. Parallel Minimum Filter Algorithm
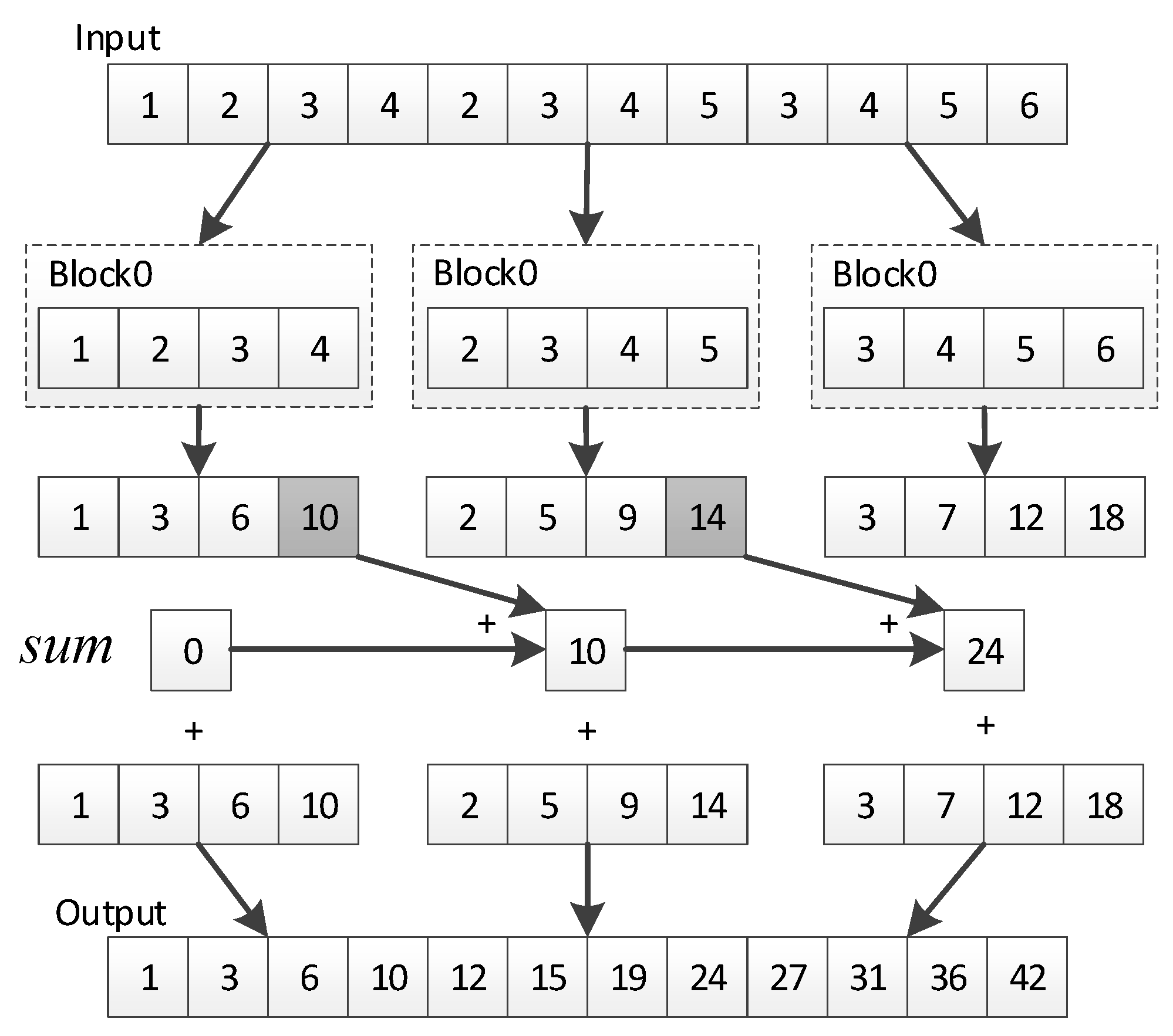
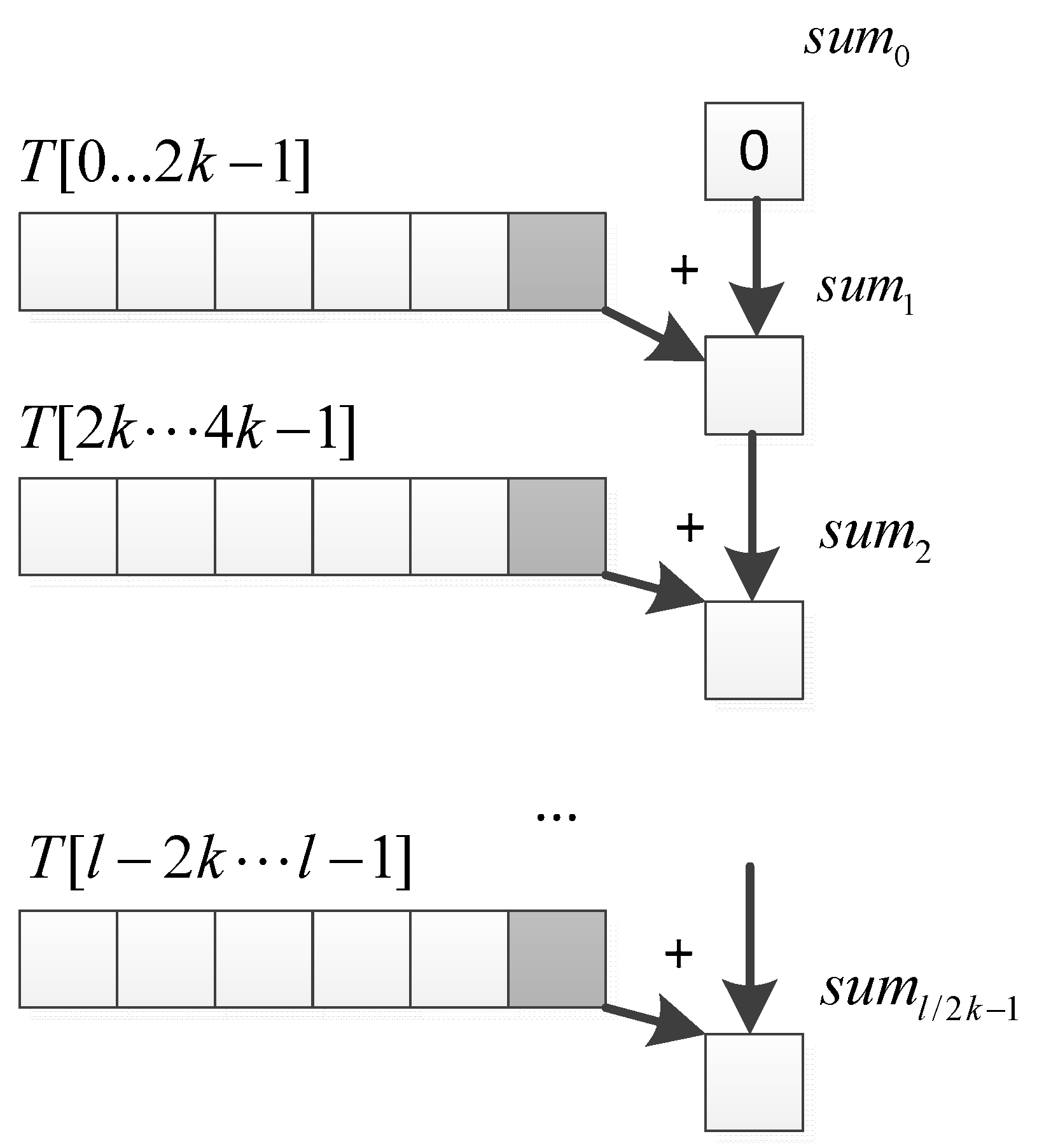
3.3.3. Parallel Mean Filter Algorithm Based on Scan
3.4. GPU Implementation of Dehazing Algorithm
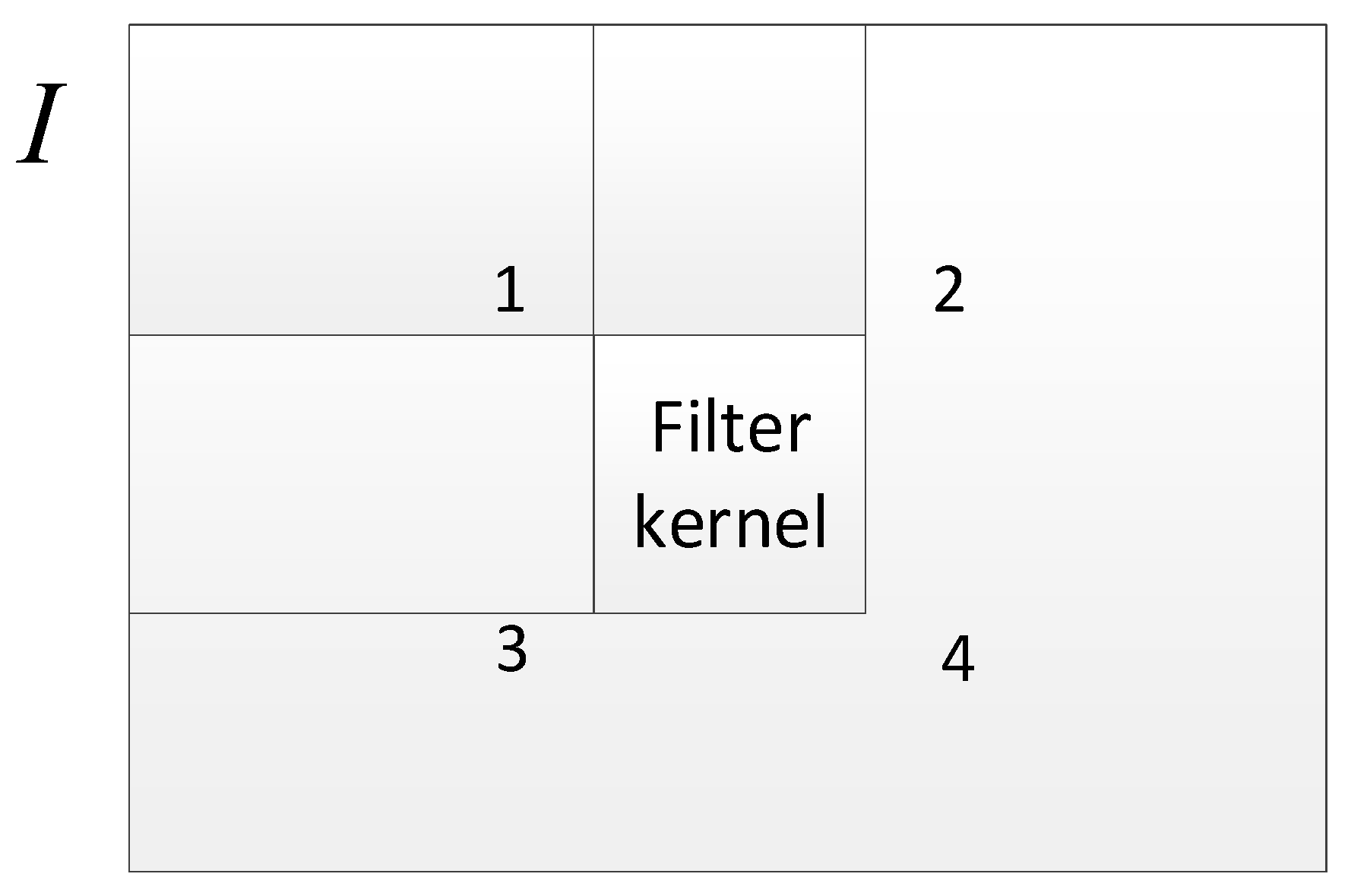
3.5. Coalesced Global Memory Access
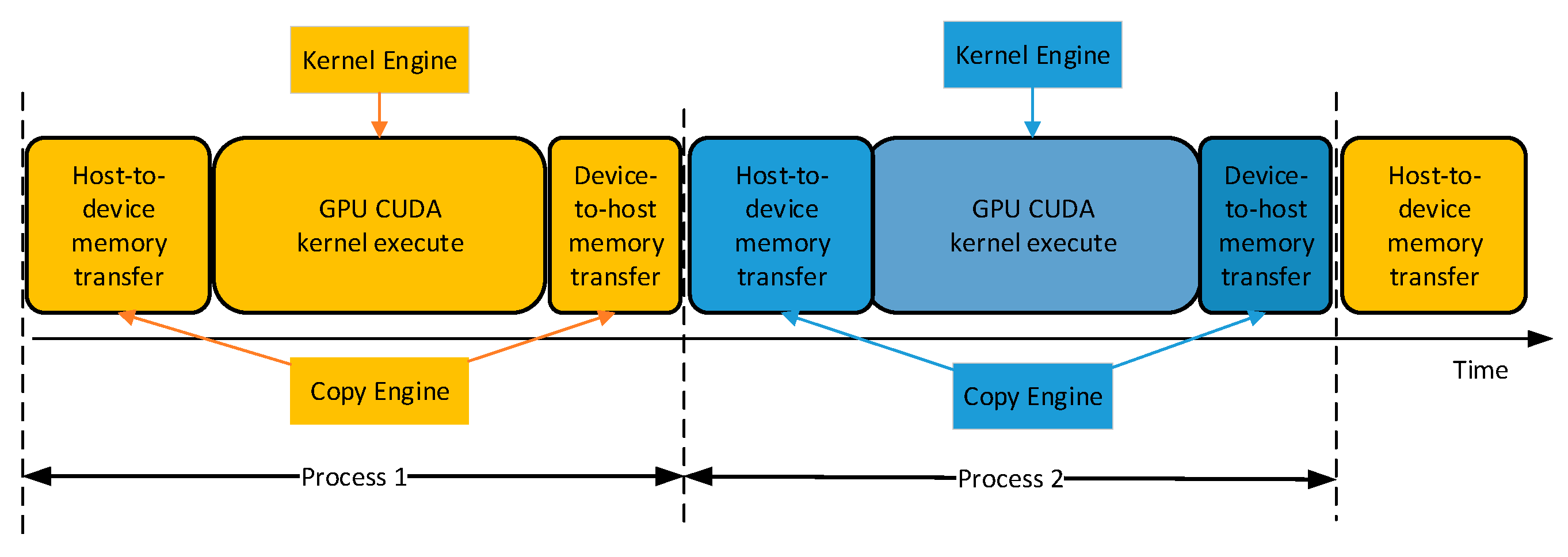
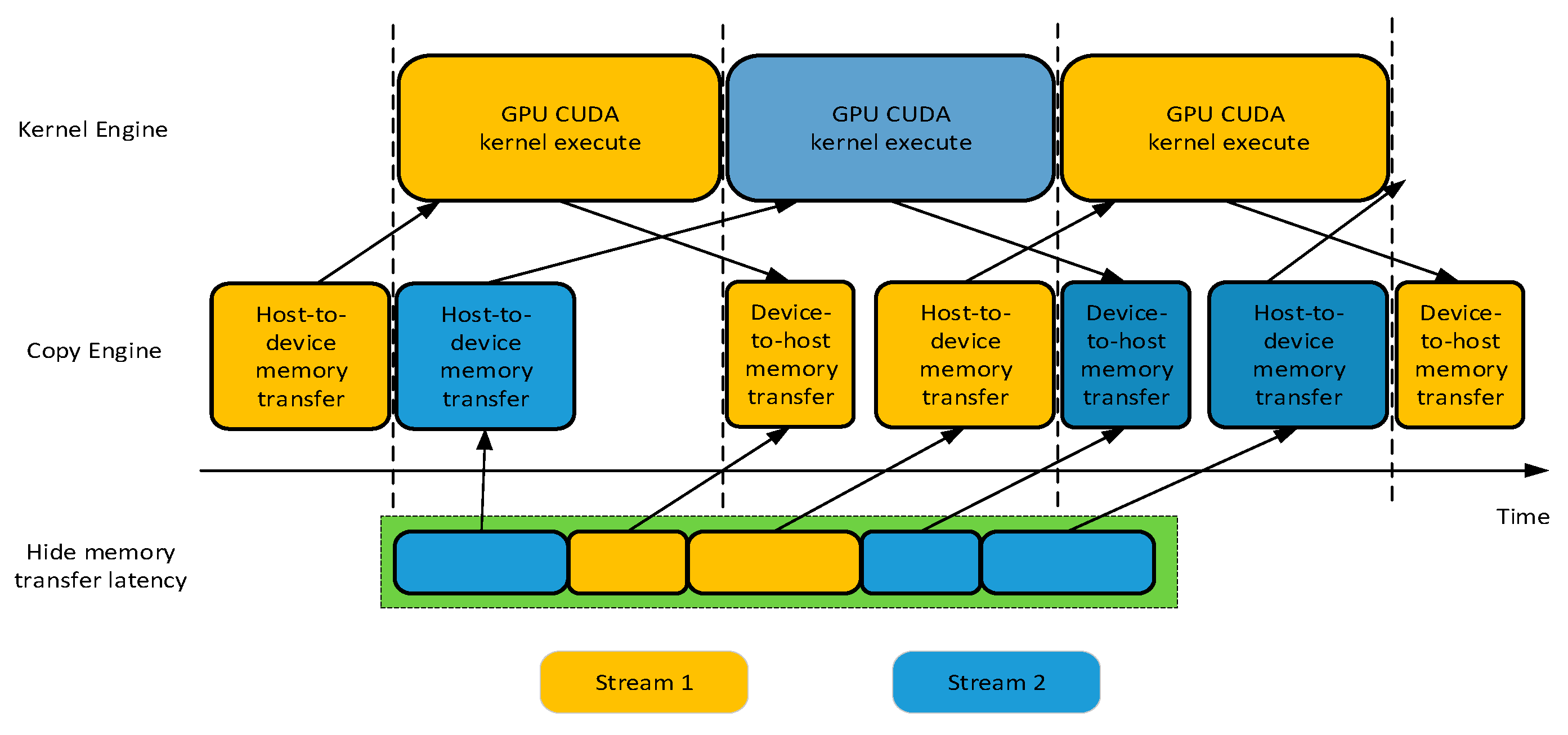
3.6. Asynchronous Memory Transfer
4. Experiments and Results Evaluation
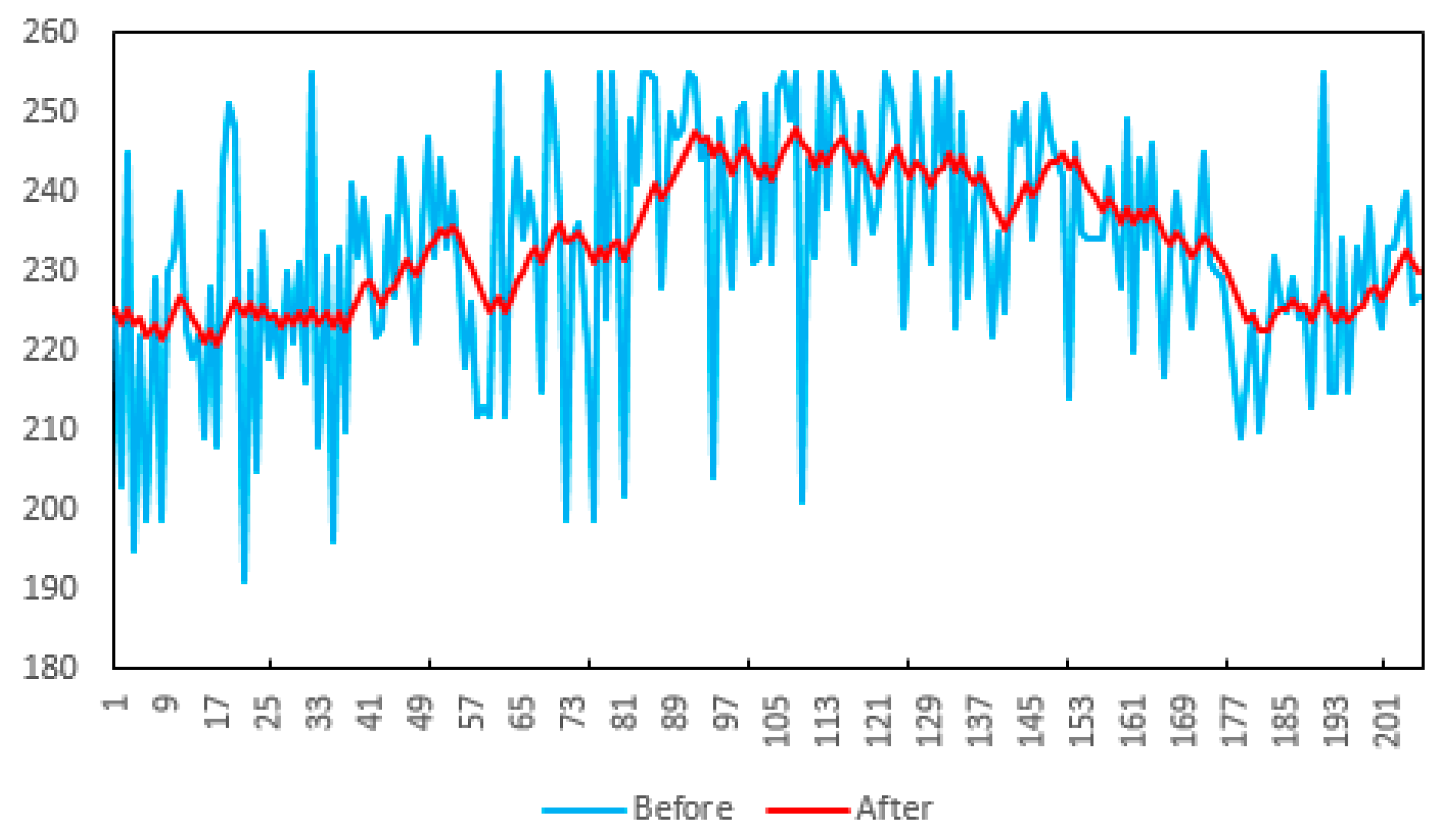
4.1. Effects of Haze Removal
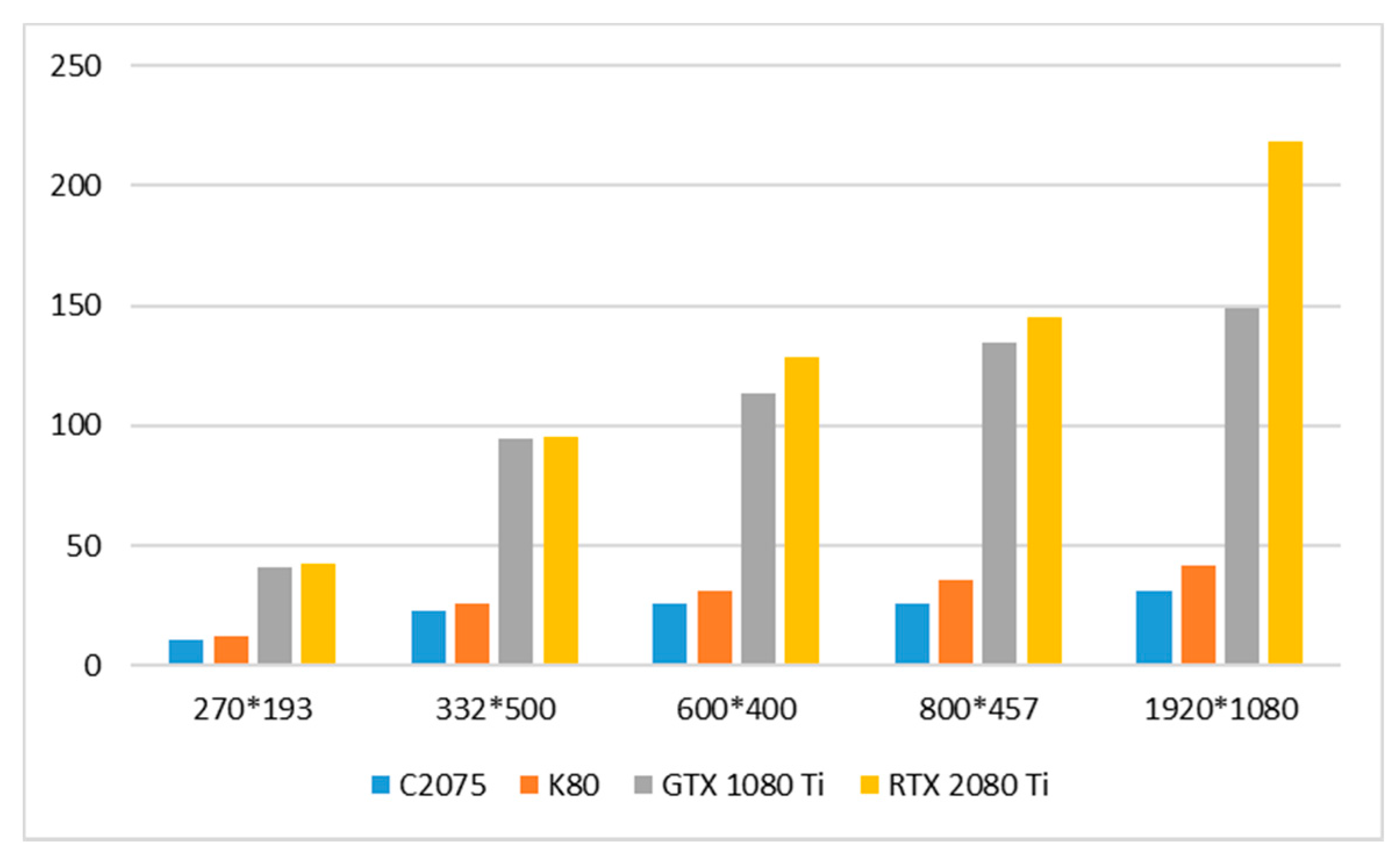
4.2. Algorithm Run Time Evaluation
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Tan, R. Visibility in bad weather from a single image C. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Fattal, R. Single image dehazing. ACM 2008, 27, 1–9. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 33, 1956–1963. [Google Scholar]
- Wu, X.; Wang, R.; Li, Y.; Liu, K. Parallel computing implementation for real-time image dehazing based on dark channel. In Proceedings of the 2018 IEEE 20th International Conference on High Performance Computing and Communications; IEEE 16th International Conference on Smart City; IEEE 4th International Conference on Data Science and Systems (HPCC/SmartCity/DSS), Exeter, UK, 28–30 June 2018; IEEE Computer Society: Piscataway, NJ, USA, 2018. [Google Scholar]
- Xiaoxu, H.; Hongwei, F.; Qirong, B.; Jun, F.; Xiaoning, L. Image dehazing base on two-peak channel prior. In Proceedings of the IEEE International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016; pp. 2236–2240. [Google Scholar]
- Hsieh, C.H.; Lin, Y.S.; Chang, C.H. Haze removal without transmission map refinement based on dual dark channels. In Proceedings of the International Conference on Machine Learning and Cybernetics, Lanzhou, China, 13–16 July 2014; pp. 512–516. [Google Scholar]
- Yu, T.; Riaz, I.; Piao, J.; Shin, H. Real-time single image dehazing using block-to-pixel interpolation and adaptive dark channel prior. Image Process. Lett. 2015, 9, 725–734. [Google Scholar] [CrossRef]
- Alharbi, E.M.; Ge, P.; Wang, H. A research on single image dehazing algorithms based on dark channel prior. J. Comput. Commun. 2016, 4, 47–55. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Sun, J.; Tang, X. Guided image filtering. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1397–1409. [Google Scholar] [CrossRef]
- Wang, W.; Yuan, X. Recent advances in image dehazing. IEEE/CAA J. Autom. Sin. 2017, 4, 410–436. [Google Scholar] [CrossRef]
- Xue, Y.; Ren, J.; Su, H.; Wen, M.; Zhang, C. Parallel Implementation and optimization of haze removal using dark channel prior based on CUDA. In High Performance Computing; Springer: Berlin/Heidelberg, Germany, 2013; pp. 99–109. [Google Scholar]
- Gu, Y.; Zhang, X. Research of parallel dehazing using temporal coherence algorithm based on CUDA. In Proceedings of the 2016 IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 3–5 October 2016; pp. 56–61. [Google Scholar] [CrossRef]
- Lv, X.; Chen, W.; Shen, I. Real-time dehazing for image and video. In Proceedings of the Pacific Conference on Computer Graphics and Applications IEEE Computer Society, Hangzhou, China, 25–27 September 2010; pp. 62–69. [Google Scholar]
- Huang, F.; Lan, S.; Wu, J.; Liu, D. Haze removal in real-time based on CUDA. J. Comput. Appl. 2013, 33, 183–186. [Google Scholar]
- Pettersson, N. GPU-Accelerated Real-Time Surveillance De-Weathering. Master’s Thesis, Linköping University, Linköping, Sweden, 2013. [Google Scholar]
- Zhang, J.; Hu, S. A GPU-accelerated real-time single image de-hazing method using pixel-level optimal de-hazing criterion. J. Real Time Image Process. 2014, 9, 661–672. [Google Scholar] [CrossRef]
- Van Herk, M. A fast algorithm for local minimum and maximum filters on rectangular and octagonal kernels. Pattern Recognit. Lett. 1992, 13, 517–521. [Google Scholar] [CrossRef]
- Kirk, D.B.; Hwu, W. Programming Massively Parallel Processors: A Hands-On Approach; Tsinghua University Press: Beijing, China, 2012. [Google Scholar]
- Li, C.; Guo, J.; Porikli, F.; Guo, C.; Fu, H.; Li, X. DR-Net: Transmission steered single image dehazing network with weakly supervised refinement. arXiv 2017, arXiv:1712.00621v1. [Google Scholar]
- Yang, H.; Pan, J.; Yan, Q.; Sun, W.; Ren, J.; Tai, Y.W. Image dehazing using bilinear composition loss function. arXiv 2017, arXiv:1710.00279. [Google Scholar]
- Liu, R.; Fan, X.; Hou, M.; Jiang, Z.; Luo, Z.; Zhang, L. Learning aggregated transmission propagation networks for haze removal and beyond. IEEE Trans. Neural Netw. Learn. Syst. 2017, 30, 2973–2986. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhang, H.; Sindagi, V.; Patel, V.M. Joint transmission map estimation and dehazing using deep networks. IEEE Transactions on Circuits and Systems for Video Technology. arXiv 2017, arXiv:1708.00581. [Google Scholar]
- Song, Y.; Li, J.; Wang, X.; Chen, X. Single image dehazing using ranking convolutional neural network. IEEE Trans. Multimed. 2017, 20, 1548–1560. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Wang, K.; Li, Y.; Li, J. Deep fully convolutional regression networks for single image haze removal. In Proceedings of the Visual Communications and Image Processing (VCIP), St. Petersburg, FL, USA, 10–13 December 2017; pp. 1–4. [Google Scholar]
- Goldstein, E.B.; Brockmole, J. Sensation and Perception; Cengage Learning: Boston, MA, USA, 2016. [Google Scholar]
- Xie, W.; Yu, J.; Tu, Z.; Long, X.; Hu, H. Fast algorithm for image defogging by eliminating halo effect and preserving details. Appl. Res. Comput. 2019, 36, 1228–1231. [Google Scholar]
- Cai, B.; Xu, X.; Jia, K.; Qing, C.; Tao, D. DehazeNet: An end-to-end system for single image haze removal. IEEE Trans. Image Process. 2016, 25, 5187–5198. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. AOD-Net: All-in-one dehazing network. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV) IEEE Computer Society, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Wierzbicki, D.; Kedzierski, M.; Sekrecka, A. A Method for dehazing images obtained from low altitudes during high-pressure fronts. Remote Sens. 2020, 12, 25. [Google Scholar] [CrossRef] [Green Version]
- Gu, Z.; Zhan, Z.; Yuan, Q.; Yan, L. Single remote sensing image dehazing using a prior-based dense attentive network. Remote Sens. 2019, 11, 3008. [Google Scholar] [CrossRef] [Green Version]
- Machidon, A.L.; Machidon, O.M.; Ciobanu, C.B.; Ogrutan, P.L. Accelerating a geometrical approximated pca algorithm using AVX2 and CUDA. Remote Sens. 2020, 12, 1918. [Google Scholar] [CrossRef]
- Dudhane, A.; Murala, S. RYF-Net: Deep fusion network for single image haze removal. IEEE Trans. Image Process. 2020, 29, 628–640. [Google Scholar] [CrossRef]
- Yeh, C.-H.; Huang, C.-H.; Kang, L.-W. Multi-scale deep residual learning-based single image haze removal via image decomposition. IEEE Trans. Image Process. 2020, 29, 3153–3167. [Google Scholar] [CrossRef]
- Wu, Q.; Zhang, J.; Ren, W.; Zuo, W.; Cao, X. Accurate transmission estimation for removing haze and noise from a single image. IEEE Trans. Image Process. 2020, 29, 2583–2597. [Google Scholar] [CrossRef]
- Bilgic, B.; Horn, B.K.; Masaki, I. Efficient integral image computation on the GPU. In Proceedings of the Intelligent Vehicles Symposium IEEE, San Diego, CA, USA, 21–24 June 2010. [Google Scholar]
- Huang, W.; Wu, L.D.; Zhang, Y.G. GPU-based computation of the integral image. In Proceedings of the International Conference on Virtual Reality & Visualization IEEE, Beijing, China, 4–5 November 2011. [Google Scholar]
- NVIDIA: NVIDIA CUDA SDK Code Samples. Available online: https://www.nvidia.com/content/cudazone/cuda_sdk/Linear_Algebra.html#transpose (accessed on 27 November 2020).
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition IEEE Computer Society, Kauai, HI, USA, 8–14 December 2001. [Google Scholar]
- Harris, M.; Sengupta, S.; Owens, J.D. Parallel prefix sum (scan) with CUDA. GPU Gems 2007, 3, 851–876. [Google Scholar]
- Jian-Guo, J.; Tian-Feng, H.; Mei-Bin, Q. Improved algorithm on image haze removal using dark channel prior. J. Circuits Syst. 2011, 16, 7–12. [Google Scholar]
- Fu, Z.; Yang, Y.; Shu, C.; Li, Y.; Wu, H.; Xu, J. Improved single image dehazing using dark channel prior. J. Syst. Eng. Electron. 2015, 26, 1070–1079. [Google Scholar] [CrossRef]
- Wu, X.; Huang, B.; Huang HL, A.; Goldberg, M.D. A GPU-based implementation of WRF PBL/MYNN surface layer scheme. In Proceedings of the IEEE International Conference on Parallel & Distributed Systems IEEE, Singapore, 17–19 December 2013. [Google Scholar]
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2019, 28, 492–505. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Tarel, J.P.; Hautière, N. Fast visibility restoration from a single color or gray level image. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision IEEE, Kyoto, Japan, 29 September–2 October 2010. [Google Scholar]
- Meng, G.; Wang, Y.; Duan, J.; Xiang, S.; Pan, C. Efficient image dehazing with boundary constraint and contextual regularization. In Proceedings of the 2013 IEEE International Conference on Computer Vision, Sydney, NSW, Australia, 3–6 December 2013. [Google Scholar]
- Chen, C.; Do, M.N.; Wang, J. Robust Image and Video Dehazing with Visual Artifact Suppression via Gradient Residual Minimization. Computer Vision—ECCV 2016; Springer International Publishing: New York, NY, USA, 2016. [Google Scholar]
- Zhu, Q.; Mai, J.; Shao, L. A fast single image haze removal algorithm using color attenuation prior. IEEE Trans. Image Process. 2015, 24, 3522–3533. [Google Scholar]
- Berman, D.; Treibitz, T.; Avidan, S. Non-local image dehazing. In Proceedings of the IEEE Conference on Computer Vision & Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ren, W.; Liu, S.; Zhang, H.; Pan, J.; Cao, X.; Yang, M.H. Single Image Dehazing via Multi-Scale Convolutional Neural Networks. Computer Vision—ECCV 2016; Springer International Publishing: New York, NY, USA, 2016. [Google Scholar]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Cores (MP) | Memory Size(GB) | Architecture | Capability |
|---|---|---|---|---|
| C2075 | 448 | 6 | Fermi 2.0 | 2.0 |
| K80 | 2496 | 12 | Kepler | 3.7 |
| GTX 1080 Ti | 3584 | 12 | Pascal | 6.1 |
| RTX 2080 Ti | 4352 | 12 | Turing | 7.5 |
| Mean Filter | Minimum Filter | Estimate A | Grey Image | Restore Image | Transposed Filter | ||
|---|---|---|---|---|---|---|---|
| global memory | fixed | 16 M | 16 M | 34 M | 8.4 M | 14.4 M | 8 M |
| recycle | 8 M | 16 M | 8 M | 23.6 M | 23.6 M | 8 M | |
| shared memory | 8 K | 16 K | 2 K | -- | -- | 1 k | |
| Image Resolution (Pixels) | |||||
|---|---|---|---|---|---|
| CPU run time(ms) | 15 | 62 | 93 | 141 | 780 |
| C2075 run time(ms) | 1.40 | 2.75 | 3.57 | 5.43 | 25.05 |
| K 80 run time(ms) | 1.23 | 2.40 | 2.98 | 3.95 | 18.62 |
| GTX 1080 Ti run times(ms) | 0.367 | 0.654 | 0.821 | 1.05 | 5.232 |
| RTX 2080 Ti run times(ms) | 0.353 | 0.652 | 0.722 | 0.973 | 3.569 |
| Image Resolution (Pixels) | |||||
|---|---|---|---|---|---|
| C 2075 | 10.71 | 22.55 | 26.05 | 25.97 | 31.14 |
| K 80 | 12.19 | 25.83 | 31.21 | 35.69 | 41.89 |
| GTX 1080 Ti | 40.87 | 94.80 | 113.27 | 134.29 | 149.08 |
| RTX 2080 Ti | 42.49 | 95.09 | 128.81 | 144.91 | 218.54 |
| Scheme | Box Filter | Image Transposition | Run Time (ms) | ||
|---|---|---|---|---|---|
| Row (ms) | Column (ms) | ||||
| Before optimization | 7.78 | 0.75 | ---- | 8.53 | |
| After | C2075 | 2.01 | ---- | 0.60 | 2.70 |
| K80 | 1.47 | ---- | 0.40 | 1.87 | |
| Scheme | Minimum Filter | Image Transposition | Run Time (ms) | ||
|---|---|---|---|---|---|
| Row (ms) | Column (ms) | ||||
| Before optimization | 1.52 | 1.63 | ---- | 3.19 | |
| After | C2075 | 0.72 | ---- | 0.60 | 1.32 |
| K80 | 0.56 | ---- | 0.40 | 0.96 | |
| Different Algorithms | Image Resolution | GPU Type | GPU Run Time (ms) |
|---|---|---|---|
| [10] | NVIDIA Geforce GTX 460 | 156.9 | |
| ours | NVIDIA Tesla C2075 | 9.6 | |
| [11] | NVIDIA Geforce GT 650M | 150 | |
| ours | NVIDIA Tesla C2075 | 12.3 | |
| [12] | NVIDIA Geforce 9300MGS | 90 | |
| [13] | NVIDIA GTX 680 | 37 | |
| ours | NVIDIA Tesla C2075 | 14.5 | |
| [14] | NVIDIA Geforce GTX 560 Ti | 43 | |
| ours | NVIDIA Tesla C2075 | 11.5 | |
| ours | NVIDIA Tesla C2075 | 24.3 | |
| NVDIA Tesla-K80 | 18.6 | ||
| GeForce GTX 1080 Ti | 5.2 | ||
| GeForce RTX 2080 Ti | 3.57 |
| DCP | FVR | BCCR | GRM | CAP | NLD | DehazeNet | MSCNN | AOD-Net | Our Method | |
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | 18.87 | 18.02 | 17.87 | 20.44 | 21.31 | 18.53 | 22.66 | 20.01 | 21.01 | 20.73 |
| SSIM | 0.7935 | 0.7256 | 0.7701 | 0.8233 | 0.8247 | 0.7018 | 0.8325 | 0.7907 | 0.8372 | 0.8778 |
| CPU Time (ms) | 39,810 | |
|---|---|---|
| Asynchronous Non-Coalesced | Asynchronous Coalesced | |
| GPU + I/O (ms) | 234.1 | 175.6 |
| Speedup with I/O | 170.1× | 226.7× |
| Mean Filter | Transposition | Minimun Filter | I/O | Others | Total | ||
|---|---|---|---|---|---|---|---|
| C2075 | Before optimization | 51.58 | ---- | 6.78 | 2.00 | 5.02 | 65.38 |
| After optimization | 12.62 | 3.27 | 2.64 | 2.00 | 5.02 | 25.55 | |
| K80 | Before optimization | 39.13 | ---- | 4.05 | 1.60 | 4.40 | 48.98 |
| After optimization | 8.88 | 2.08 | 1.92 | 1.60 | 4.40 | 18.88 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Wang, K.; Li, Y.; Liu, K.; Huang, B. Accelerating Haze Removal Algorithm Using CUDA. Remote Sens. 2021, 13, 85. https://doi.org/10.3390/rs13010085
Wu X, Wang K, Li Y, Liu K, Huang B. Accelerating Haze Removal Algorithm Using CUDA. Remote Sensing. 2021; 13(1):85. https://doi.org/10.3390/rs13010085
Chicago/Turabian StyleWu, Xianyun, Keyan Wang, Yunsong Li, Kai Liu, and Bormin Huang. 2021. "Accelerating Haze Removal Algorithm Using CUDA" Remote Sensing 13, no. 1: 85. https://doi.org/10.3390/rs13010085
APA StyleWu, X., Wang, K., Li, Y., Liu, K., & Huang, B. (2021). Accelerating Haze Removal Algorithm Using CUDA. Remote Sensing, 13(1), 85. https://doi.org/10.3390/rs13010085