1. Introduction
Remote sensing satellite images are a type of image that has been widely concerned and applied at present. They provide an important reference for applications in digital maps, disaster emergency, and geological observation [
1,
2]. In practical remote sensing image applications, the images must simultaneously have the highest spatial resolution and spectral resolution. The two most important metrics, the incident radiation energy of the sensor and the amount of data collected by the sensor, are limited by the physical structure of the satellite sensor, making it impossible to obtain remote sensing images with a high spatial resolution and spectral resolution at the same time.
To address this problem, current Earth observation satellites generally use two different types of sensors simultaneously. They are used to obtain single-band panchromatic (PAN) images with a high spatial resolution, but low spectral resolution, and multi-band spectral (MS) images with complementary characteristics. As far as possible, the information from the two images is used simultaneously, and a pansharpening algorithm is typically used to fuse the two images so as to obtain images with both a high spatial resolution and high spectral resolution.
Because of the demand for high-quality remote sensing images, much pansharpening-based work has been carried out, and various algorithms for remote sensing image fusion have been proposed, namely: (1) component substitution (CS) [
3,
4,
5,
6], (2) multi-resolution analysis (MRA) [
7,
8,
9,
10,
11], (3) hybrid methods [
12,
13], and (4) model-based algorithms [
14,
15,
16]. The core idea of the CS method is to first rely on conversion to project MS images into another space to separate the spatial structure and the spectral information. The PAN image and spatial structure component are then matched and replaced by the histogram so that the PAN image has the same mean value and equation as the replaced component, and finally, the pansharpening task is completed by an inverse transformation operation. Methods such as intensity-hue-saturation (IHS) [
3], principal component analysis (PCA) [
4], Gram–Schmidt (GS) [
5], and partial substitution (PRACS) [
6] all adopt this concept. These methods achieve good results when the PAN image and MS image are highly correlated, but because of the local differences caused by a spectral mismatch between the PAN image and MS image, there is obvious spectral distortion in the fusion results.
In the MRA method, three main steps are used to fuse the image. The first step is to use the pyramid transform or wavelet transform to process the source image and divide it into multiple scales. Then, the fusion of each scale of the source image is carried out, and the inverter operation generates the fusion result. This method provides both spatial and frequency domain localisation. Decimated wavelet transform [
7], à trous wavelet transform [
8], Laplacian Pyramid [
9], Contourlet [
10], and Curvelet [
11] are examples of this approach.
The hybrid method combines the advantages of CS and MRA methods in a combination of ways to achieve higher-performance fusion results. Model-based algorithms operate mainly by establishing the MS image, PAN image, and high-resolution multispectral (HRMS) image relationship model. They rely on prior knowledge for image fusion. A hierarchical Bayesian model to fuse many multi-band images with various spectral and spatial resolutions is proposed in [
14]. An online coupled dictionary learning (OCDL) [
15], and, in [
16], two fusion algorithms by incorporating the contextual constraints via MRF models into the fusion model, have been proposed.
In recent years, deep learning and convolutional neural networks have achieved outstanding results in all fields of image processing [
17,
18,
19,
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30,
31,
32]. Inspired by image super-resolution using deep convolutional neural networks (SRCNN) [
17,
18], Masi et al. [
19] proposed a network called pansharpening by convolutional neural networks (PNN), which adopts the same three-layer structure as the other and combines specific knowledge in the field of remote sensing to introduce nonlinear radiation indicators so as to increase the input. This was the first application of a CNN in the pansharpening field. With the remarkable effect of the residual structure, Wei et al. [
20] designed a deep residual network (DRPNN) for pansharpening. He et al. [
21] proposed two detail-based networks to clarify the role of CNN in pansharpening tasks from a theoretical perspective, and clearly explained the effectiveness of the residual structures for pansharpening.
Yang et al. [
22] proposed a deep network architecture for pansharpening (PanNet), which is different from the other methods. A hopping connection called spectral mapping was used to compensate for spectral loss caused by training in the high-pass domain. This approach has achieved remarkable results, but it still has significant limitations. It is generally accepted that PAN and MS images contain different information. The PAN image is a carrier of geometric detail (spatial) information, while the MS image preserves spectral information. PanNet is trained by directly superimposing the PAN and MS image input network, resulting in the network’s inability to fully extract the different features contained in the PAN and MS images, and results in an insufficient use of different spatial information and spectral information. It only uses a simple residual structure, which cannot fully extract the image features of different scales, and lacks the ability to recover details. The network directly outputs the fusion results through one convolutional layer, and fails to make full use of all of the features extracted by the network, affecting the final fusion effect.
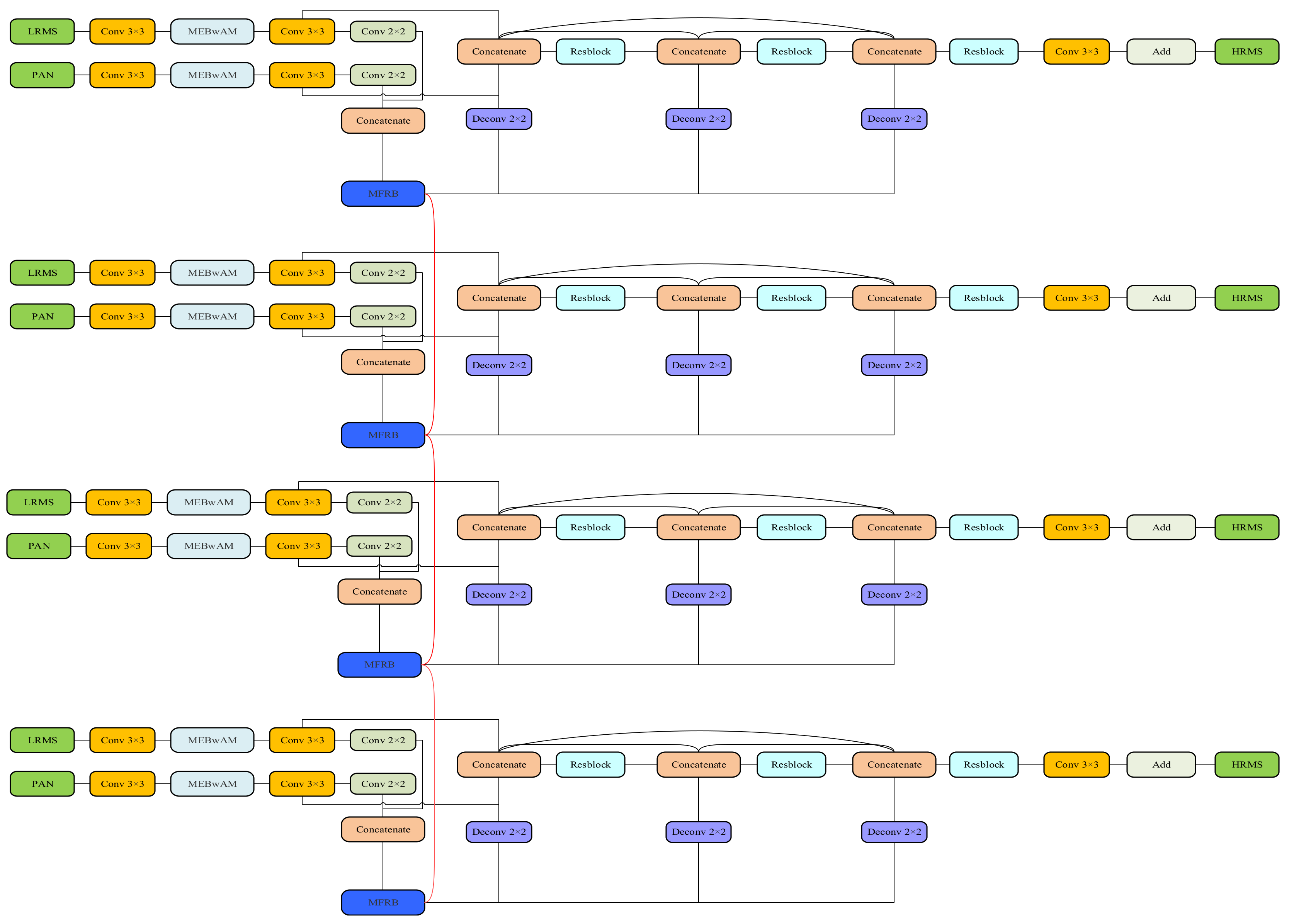
In this paper, we propose a multilevel dense connection network with feedback connections (MDCwFB), including two branches, a detail branch, and an approximate branch, based on the idea of detail injection and super-resolution work. Different spatial and spectral information are extracted from PAN images and MS images by the dual-stream structure. Multi-scale blocks with attention mechanisms are used on both lines to extract more abundant and effective multi-scale features from the image. The image fusion and reconstruction work are carried out in the feature domain. The fused features are encoded and decoded based on the idea of a dense connection. The shallow network is limited by the size of the receptive field, and can only extract rough features; however, these features are repeatedly used in the subsequent network, which further limits the learning ability of the network. Therefore, we introduce the feedback connection mechanism to transfer the deep features back to the shallow network through a long jump connection, which is used to optimise the rough low-level features and enhance the early reconstruction ability of the network. Through the interaction between the PAN image and MS image features, the detail branch can fully extract the details of the low-resolution multispectral (LRMS) image supplemented as an approximate branch, and the two can help each other obtain an excellent HRMS image.
In summary, the main contributions of this study are as follows:
We propose a multi-scale feature extraction block with an attention mechanism (MEBwAM) to solve the problems of insufficient feature extraction and the lack of multi-scale feature extraction ability of PAN images and MS images using multiple depth cascaded networks. The spatial information and channel information are compressed separately to obtain an importance index.
We use multilevel coding and decoding combined with densely connected structures to fuse and reconstruct the extracted spatial and spectral information in the feature domain. Deep networks encode the language and abstract information of the images, making it difficult to recover the texture, boundary, and color information from the advanced features; however, shallow structures are very good at identifying these details. We inject low-level features into high-level features through long jump connections, which can more easily recover fine realistic images, and dense connections to make the feature graph semantic level in the encoder closer to the feature graph in the decoder.
We propose using multiple subnetworks. We iterate the deep structure in the subnetwork to inject the deep features from the previous subnetwork, that is, the HRMS that completes rough reconstruction, into the shallow structure of the latter subnetwork. This is done by way of a feedback connection to optimize the shallow features of the latter, enabling the network to obtain a better reconstruction ability earlier.
We use the L1 loss function to optimise the network and attach the loss function to each subnet to monitor its output in order to ensure that useful information can be transmitted backwards in each iteration.
The remainder of this paper is arranged as follows. We present the CNN background knowledge and work that has achieved remarkable results in other areas and other related work based on CNN pansharpening in
Section 2.
Section 3 introduces the motivation of our proposed multilevel dense connected network with a feedback connection, and explains the structure of each part of the network in detail. In
Section 4, we show the experimental results and compare them with the other methods. We discuss the effectiveness of the network structure in
Section 5, and we summarise the paper in
Section 6.
3. Proposed Network
In this section, we will introduce in detail the specific structure of the MDCwFB model proposed in this study, which not only has a clear interpretability, but also has an excellent ability to prevent overfitting and to reconstruct images early. We will introduce the algorithm solution for the proposed model and give a detailed description of each part of the network framework. The schematic framework of our proposed network is shown in
Figure 1 and
Figure 2. It can be seen that our model includes two branches: one, the merely approximate branch of the LRMS graph, enhances the retention of spectral information, and the other is the detail branch for extracting spatial details. Such a structure has a clear physical interpretability and reduces uncertainty in the network training. The detail branch, which has a structure similar to the encoder–decoder system, consists of four parts: feature extraction, feature fusion and recovery, feedback connection, and image reconstruction.
3.1. Feature Extraction Networks
A PAN image is considered the carrier of spatial detail in the pansharpening task, and the MS image is the carrier of spectral information. Spatial and spectral information are combined to generate high-resolution images through the PAN and MS image interaction. Based on the ideas described previously, we rely on a CNN to fully extract the different spatial and spectral information and to complete the feature fusion reconstruction and image restoration in the feature domain.
We use two networks with the same structure to extract features from the PAN and MS images, respectively. One network takes a single-band PAN image (size H × W) as the input, and the other takes a multi-band MS image (size H×W×N) as the input. Before entering the network, we upsampled the MS image to the same size as the PAN image via transposing convolution. Each feature extraction subnet consists of two separate convolution layers, followed by a parameter rectified linear unit (PReLU).
Many studies on the CNN framework indicate that the depth and width of the network significantly affect the quality of the results. A deeper and wider network structure can help the network learn richer feature information and can capture the mapping between the semantic information and context information in features. He et al. [
26] proposed a residual network structure, and Szegedy et al. [
27] proposed an inception network structure that significantly increased the depth and width of the network. The jump connection proposed by the former reduces the training difficulty after the network deepens. The latter points out the direction for the network to extract multi-scale features.
Inspired by the multi-scale expansion blocks proposed by the above work and Yang et al. [
33] in PanNet, and the spatial and channel extrusion and excitation blocks proposed by Roy et al. [
38] to extract more fully the different-scale features in the image and enhance the more important parts of the features for pansharpening tasks, we propose an MEBwAM to use different receptive fields on a monolayer network and to add to the middle of two convolution layers. The first 3 × 3 convolution layer preliminarily extracts the image features. The second 3 × 3 convolution layer preliminarily fuses the enhanced features of the two branches.
This MEBwAM structure is shown in
Figure 3. We did not use cavity convolution to extract multi-scale features, even if it can arbitrarily expand the receptive field without introducing additional parameters. Because of the grid effect, cavity convolution is a sparse sampling method. The superposition of the cavity convolution with multiple different scales causes some features to be unused. Thus, the extracted features will also lose their correlation and continuity of information, which will affect the feature fusion reconstruction. We use convolution kernels of size 3 × 3, 5 × 5, 7 × 7, and 9 × 9 in four branches, respectively. To reduce the high computational cost, we used multiple cascading size 3 × 3 convolution layers to replace the large-size convolution kernels in the other three branches. Each convolution layer is followed by a PReLU. Finally, the results after the four path cascades are fused through one 1 × 1 convolution layer. We then extract the spatial attention and channel attention through two branches and recalibrate the extracted multi-scale features using the obtained indexes to measure the importance. The information that is more important to the fusion results is enhanced, and the relatively invalid parts are suppressed. The channel attention branch uses the global average pooling layer to compress the spatial characteristics, and it combines the 1 × 1 convolution layer and PReLU function to obtain more nonlinearity and better fit the complex correlation between channels. The spatial attention branches use 1 × 1 convolutional layers to compress the channel features. At the end, the two branches use the sigmoid function to obtain an index to measure the spatial information and the importance of the channel, and the jump connection of the whole module effectively reduces the training difficulty and the possible degradation problem, as follows:
We use to represent convolution layers with size f × f convolution kernels and n channels, and , , and represent the sigmoid activation functions, PReLU activation function, and global average pooling layer, respectively. LRMS and PAN represent the images as the input, represents the multi-scale feature extraction layer, and x refers to the feature fused together by four branches. fMS and fPan represent the extracted MS and PAN image features, respectively, and represents the concatenation operation.
3.2. Multistage Feature Fusion and Recovery Network
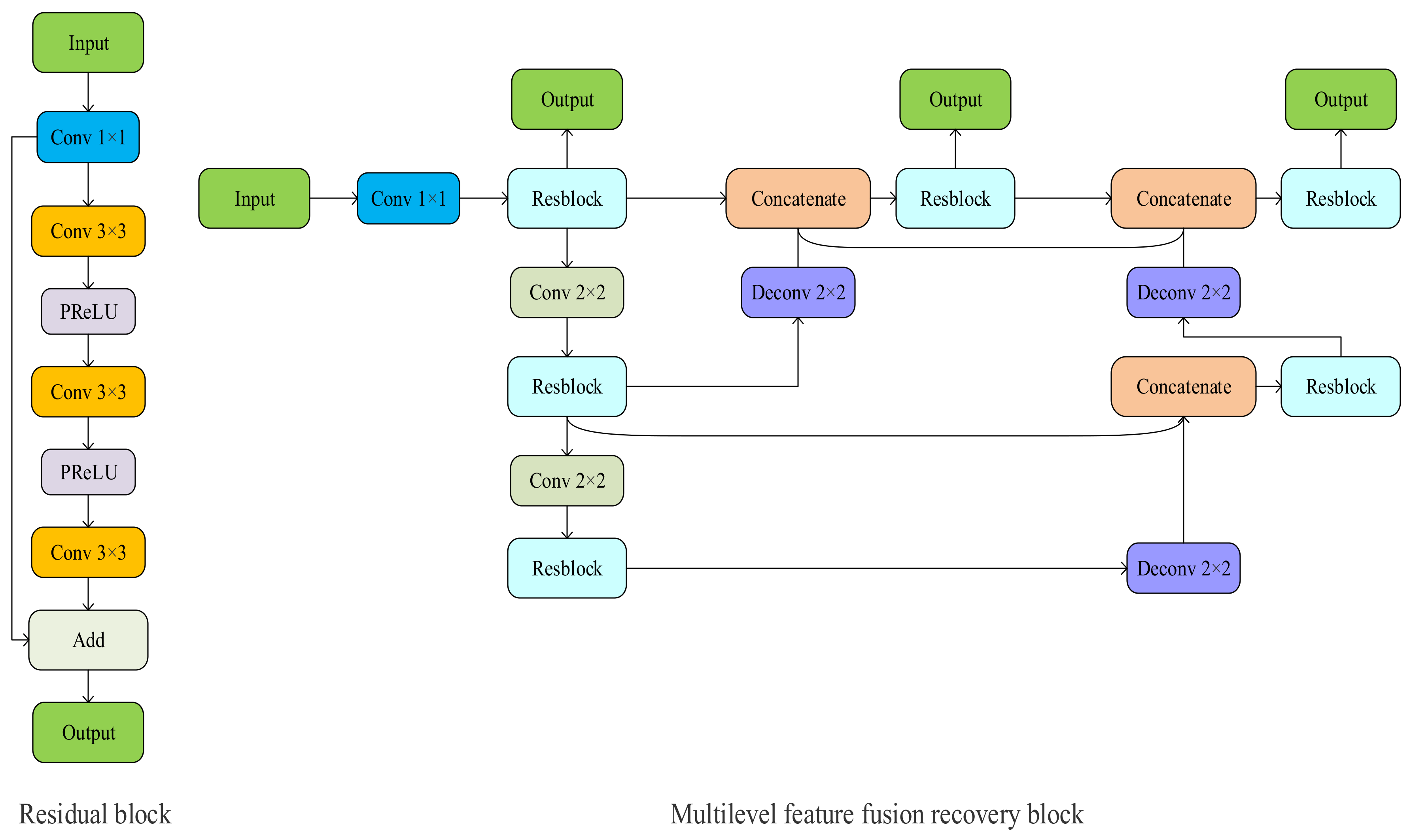
For the encoder–decoder architecture in our proposed network, we propose a multilevel feature fusion recovery block (MFRB) to implement the encoding and decoding operations and subsequent feedback connections. The concrete structures of the MFRB and residual block are shown in
Figure 4. We use three residual blocks and two downsampling operations to form the encoder structure. Unlike the symmetric structure of traditional encoder and decoder networks, our decoder structure includes three residual blocks and three upsampling operations. The downsampling operation increases the robustness to some interference of the input image, while obtaining the features of translation invariance, rotation invariance, and scale invariance and reducing the risk of overfitting. Continuous downsampling can increase the size of the receptive field and help the network fully capture multi-scale features. In this study, we choose to use a convolution layer with a step size of two to complete the downsampling operation. The two feature extraction subnets are downsampled after two convolution layers and multi-scale feature extraction blocks.
The structure shown in
Figure 4 is inspired by Zhou et al. [
39], who proposed the U-Net++ structure for a multilevel feature fusion recovery module. Many studies have shown that because of the different size of the receptive field, the shallow structure focuses on some simple features of the captured image, such as boundary, colour, and texture information. After many convolution operations, the deep structure captures the contextual language information and abstract features of the image. Downsampling operations help the encoder fuse and encode features at different levels, and the features are recovered through upsampling operations and decoders. However, edge information and small parts of large objects are easily lost during multiple downsampling and upsampling operations. It is very difficult to recover detailed texture information from encoded image semantics and abstract information, which seriously affects the quality of the pansharpening. Adding jump connections between encoders and decoders with the same feature map size and using shallow features to help the decoder complete the feature recovery solves this problem to some extent.
Different levels of characteristics focus on different informations, but the importance of the pansharpening tasks is consistent. To obtain higher-precision images, we need to make full use of different levels of features, and simultaneously, we need to solve the problem of using jump connections between the encoder and decoder because of the different feature levels. As shown in
Figure 4, we decode the features after each encoding level, which means that our MFRB produces multiple outputs, each corresponding to a feature level. We decode each level of features and then connect the same level of encoder and decoder using a dense connection, which not only makes the feature graph in the encoder and decoder want a closer semantic, level but also increases the ability of the network to resist overfitting. In the network, we double the number of feature graph channels at each downsampling layer and halve the number of feature graph channels at each upsampling layer. The residual blocks in the network include one 1 × 1 convolutional layer and two 3 × 3 convolutional layers. Each convolutional layer is followed by a PReLU. Because we double the number of channels after each downsampling, and the input and output of the residual units need to have the same size, we change the number of channels by 1 × 1 convolutional layers to create hopping connections. The input of each decoder consists of features recovered from the upper decoder and features in the same level of encoder and decoder.
3.3. Feedback Connection Structure
Feedback is the use of one set of conditions to regulate another set of conditions, which is done to increase or suppress changes in the system. The mechanism is called positive feedback when processes tend to increase system changes. Negative feedback refers to processes that try to counter changes and maintain balance. Feedback mechanisms usually exist in human visual systems. In cognitive theory, feedback connections connecting cortical visual regions can transmit response signals from higher-order regions to lower-order regions. Inspired by the work carried out by Li et al. [
32] on image super-resolution, they carefully designed a feedback block to extract powerful high-level representations for low-level computer vision tasks and transmit high-level representations to perfect low-level functions. Fu et al. [
40] added this feedback connection mechanism for super-resolution tasks to the network of pansharpening tasks. Our proposed network is similar to their network structure with four time steps in the above study, but we use different feedback blocks. We use four identical subnetworks to add feedback connections between adjacent subnetworks. The specific structure of the subnetwork is shown in
Figure 2.
Because of the feedforward connection, each network layer can only accept information from the previous layer. The dense connection structure in the subsequent network reuses these features repeatedly, which further limits the network reconstruction ability. The feedback connection solves this problem very well. We complete the initial reconstructed features through the MFRB and input them into the next subnetwork as deep information. This way of bringing high-level information back to the previous layer can supplement the semantic and abstract information lacking in the low-level features, improve the error information carried in the low-level features, and correct some of the previous states so that the network has a solid ability to rebuild early:
where
f1,
f2, and
f3 represent the three-level features extracted using MFRB, and the subscripts represent the number of downsamplings. The first subnetwork uses only the PAN image and MS image features added after one downsampling as the input to the MFRB structure. The following three subnetworks fuse the recovered feature of the previous subnet and the features of
f3 for the two feature extraction subnets
fP+M, and carry out the subsequent feature fusion recovery work in the input MFRB after the cascade operation represented by the
.
3.4. Image Reconstruction Network
For image reconstruction, we use three residual blocks and a convolution layer to process the features after the fusion and recovery operations. Each residual block corresponds to a feature recovered to the original size after upsampling. By adding dense connections between different modules, we use the decoded features from different levels of encoders. Finally, the results of the detail branch are added to the LRMS image, as follows:
We use to represent cascading operations; and represent convolutional and deconvolutional layers, respectively; and f and n represent the size and number of channels of convolutional kernels, respectively. frb1, frb2, and frb3 restore the multilevel image by reconstructing the three-level features through three residual blocks. Finally, a convolution layer is used to recover the details needed for the LRMS image from the features extracted from the two-stream branches and the reconstructed multilevel image, combined with the LRMS images, and the two branches interact to generate high-precision HRMS images.
3.5. Loss Function
The effectiveness of the network junction is an important factor affecting the final HRMS image quality, while the loss function is another important factor. Early CNN-based pansharpening methods use the L
2 loss function to optimise the network parameters, but the L
2 loss function could give rise to the local minimum value problem and cause artefacts in the flat region. Subsequent studies have proven that the L
1 loss function obtains a better minimum value. Moreover, the L
1 loss function better retains spectral information such as colour and brightness than the L
2 loss function. Hence, the L
1 loss function is chosen to optimise the parameters of the proposed network. We attach the loss function to each subnetwork to monitor the training results while ensuring that the information delivered to the latter subnet in the feedback connection is valid:
where
,
, and
represent a set of training samples;
and
mean the PAN image and low-resolution MS image, respectively;
represents high-resolution MS images;
represents the entire network; and
is the parameter in the network.
5. Discussion
5.1. Discussion of MFEBwAM
In this subsection, we examine the influence of each part of the model through ablation learning in order to obtain the best performance of the model. We propose a multi-scale block with an attention mechanism to fully grasp and use the multi-scale features in the model.
To verify the effectiveness of the proposed module and the effect of different receiving field parameters on the fusion results, several convolutional blocks with different receiving field sizes were cascaded to form a multi-scale feature extraction module. We compared the multi-scale blocks of different scales with test their effect. We selected the best multi-scale blocks using convolutional kernel combinations with different receptive field sizes, where the convolutional kernel sizes were K = {1,3,5,7,9}. These convolutional kernels of different sizes were combined in various ways to determine the multi-scale blocks with the highest performance experimentally. The experimental results are shown in
Table 9.
Many studies on the CNN framework indicate that the depth and width of the network significantly impact the quality of the results. A deeper and wider network structure helps the network learn richer feature information and captures the mapping between the semantic information and context information in the features. As shown in the table, the objective evaluation index clearly indicates that our proposed method is superior to the other composite multi-scale blocks. We used four branches with receptive field sizes of 3, 5, 7, and 9, separately, although if we increased the parameters and the amount of calculations, we would obtain clearly better results.
To verify the effectiveness of multi-scale modules with attention mechanisms in our overall model, we compared them using four datasets. We experimented with networks without multi-scale modules and dual branch networks with multi-scale modules and compared the fusion results. The experimental results are shown in
Table 10.
The objective evaluation index is shown in the table. Increasing the width and depth of the network made the network extract richer feature information and identify additional mapping relationships that met the expectations. Deleting multi-scale modules led to a lack of multi-scale feature learning ability and detail learning, which cannot enhance the use of more effective features in the current task, thereby decreasing the image reconstruction ability. Therefore, according to the experimental results, we choose to use a multi-scale module with an attention mechanism to extract the PAN and MS image features separately, thus improving the function of our network.
5.2. Discussion of Feedback Connections
To make full use of the deep features with powerful representation, we used multiple subnets to obtain useful information from the deep features in the middle of the subnetwork through feedback, and we refined the weak shallow features. From the application of the feedback connections in other image processing fields, we know that the number of iterations of the subnetwork significantly impacts the final results. We evaluated the network with different numbers of iterations using the QuickBird dataset. The experimental results are shown in
Table 11.
According to the experimental results, an insufficient number of iterations made the feedback connection less effective, so that the deep features could not fully refine the shallow features, whereas too many iterations led to convergence difficulties or feature explosions. This increases the computation and affects the convergence of the network. Hence, we chose to do the pansharpening task using a network that iterated the subnet three times and added feedback to the continuous network.
To demonstrate the effectiveness of the feedback connectivity mechanism using different datasets, we trained a network with the same four subnet structures and attached the loss function to each subnet, but we disconnected the feedback connection between each subnetwork to make the network unable to use valuable information to perfect the low-level function. A comparison of the resulting indexes is shown in
Table 12. We can see that the feedback connection significantly improves the network performance and gives the network a solid early reconstruction ability.
5.3. Discussion of MFRB
In contrast with other two-stream networks for pansharpening, which used encoder-decoder structures to decode only the results after the last level encoding, and we decoded the results after each level encoding. Moreover, we added dense connections among the multilevel features obtained in order to enhance the ability of the network to make full use of all of the features and to reduce the loss of information during upsampling and downsampling. To show that this further improves the network performance, we trained a network that only begins decoding operations from the features after the last level of encoding, and we compared the results with those of our proposed network using four datasets. The experimental results are shown in
Table 13.
The objective evaluation index clearly indicates that the multilevel coding features were decoded separately, and the dense connections effectively used the information of various scales to reduce the differences in the semantic feature level in the encoder and decoder, reduce the difficulty of training the network, and further improve the network image reconstruction ability.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}