1. Introduction
Detecting atmospheric water vapor with Global Navigation Satellite System (GNSS) has been paid more attention than traditional techniques (such as water vapor radiometer, radiosonde etc.), because it has the advantages of low-cost, all-weather, high-precision and high-resolution in space and time [
1,
2,
3,
4,
5]. The key to realize real-time conversion from zenith wet delay (ZWD) to precipitable water vapor (PWV) when using GNSS for remote sense water vapor is to obtain accurate weighted mean temperature (
) in time. However, the
needs to be calculated by numerical integration based on the measured atmospheric profiles [
6,
7]; for example, the atmospheric profile data collected by radiosonde and GNSS radio occultation are the closest to the actual conditions and can be used to compute
[
8,
9,
10], but they are rarely applied in the real-time retrieval of GNSS-PWV, because the cost of collecting such data is very high, which is difficult for general users to afford. The reanalysis data derived from the numerical weather models (NWMs) have very high spatiotemporal resolutions, they generally contain the values of various meteorological elements at different heights from the ground to the tropopause and can also be used to compute
[
10,
11,
12]. The reanalysis data have in fact been widely used for climatological studies of PWV rather than for real-time GNSS-PWV retrieval, because these data are produced using the assimilation system and there is a time lag from generation to release. The establishment of the empirical
model is an alternative way to obtain
values in real time, and the study on
modeling has become one of the most important topics in GNSS meteorology.
A large number of empirical
models have been developed in recent decades, and they can be divided into two categories according to their application conditions: one is the models without measured meteorological elements (NMTm models); and the other one is called MMTm model, which requires the measured meteorological elements in the
estimation. The NMTm models do not need the measured meteorological elements as input, and they use the trigonometric functions to simulate the periodicities (include annual, semi-annual and diurnal variation) of
in different locations [
13,
14,
15,
16]. The reanalysis data generated by NWMs are usually used as the data source in the development of NMTm models, and one of the most representative NMTm models is the Global Pressure and Temperature 2 wet (GPT2w) model, which is an empirical model providing empirical values of various meteorological elements near the Earth’s surface including
[
17]. In recent years, the research focus of NMTm models has shifted to the study on the impact of height differences on the model accuracy, and a series of NMTm models such as the GTm_R model [
18], IGPT2w model [
19,
20], GWMT-D model [
11] and GTrop-Tm model [
21] have been developed. The application scope of NMTm models has even been extended from the ground to the tropopause [
22]. The GWMT-D model and GTrop-Tm model, for example, can be used to globally compute
values at different heights in the near-Earth space (from the ground to a 10 km altitude) in real time.
The MMTm models, however, are usually established based upon the relations between
and measured meteorological elements such as the temperature (
) and water vapor pressure (
) of the site. The Bevis formula (
) was first used to calculate
[
6], its coefficients were fitted from the radiosonde data distributed in the North America, but it was found that the relation between
and
varies with the locations and seasons, so a Bevis formula with constant coefficients
a and
b would result in poor accuracy when estimating
in different locations and seasons. Many scholars have conducted the localization research on the Bevis formula and found that the model coefficients tailored to the specific locations and seasons can better fit the local conditions [
15,
23,
24,
25,
26]. Some MMTm models for global GNSS-PWV retrieval have also been developed, such as the GTm-I model, PTm-I model [
8] and the TVGG model [
27]. The fundamental aim of these models is to use the Bevis formula to model the main part of
(
), and the trigonometric function to simulate the periodicity of the residual caused by the Bevis formula (
). Ding [
9] first tried to develop the MMTm model with the neural network (NN) technique, and established the first-generation neural network
model (named NN-I model), the inputs of which contain the
value calculated by the GPT2w model, the latitude and measured
of the site. However, these MMTm models can only be used to estimate the
values near the Earth’s surface, and the complexity of the topography is not considered in the modeling, so their application scope needs to be further extended. Yao et al. [
28] first studied the applicability of Bevis formula at different altitudes and established an MMTm model based on the near-Earth atmospheric temperature. Ding [
10] released the second-generation neural network
model (named NN-II model), where the altitude of the site is introduced as an additional input, and the
value derived from the GPT2w model is replaced by that from the GTrop-Tm model. NN-II model extends the
calculation from the Earth’s surface to 10 km altitude, which greatly expanded the application scope of MMTm models.
The NN-I model and NN-II model all show better performance compared with other published
models on the global scale, which has been proved in the literature studies [
9,
10]. However, the studies on neural network-based
modeling can be further deepened. Firstly, the NN-I/NN-II models are all developed based on the neural network technique, but the results of neural network training may be greatly affected by the disturbance of training samples [
29]. The NN-I/NN-II models only use the adjusted weight and bias values after one certain training mission as the final model parameters, and their generalization abilities need to be discussed and strengthened. Secondly, the global distribution of data samples used for developing NN-I and NN-II models is extremely uneven, and the sample size in the Northern Hemisphere is much larger than that in the Southern Hemisphere, which would inevitably affect the application of the neural network-based model on the global scale. Thirdly, the measured
is required when calculating
with the NN-I/NN-II models, but it is not applicable in some cases where the meteorological elements of the site are difficult to measure, so the development of neural network-based
models without measured meteorological elements can be taken as a direction of further study. Fourthly, many studies have demonstrated that the introduction of water vapor pressure as input into
modeling can help to improve the model accuracy [
8,
15,
18], which is also a study idea worth trying.
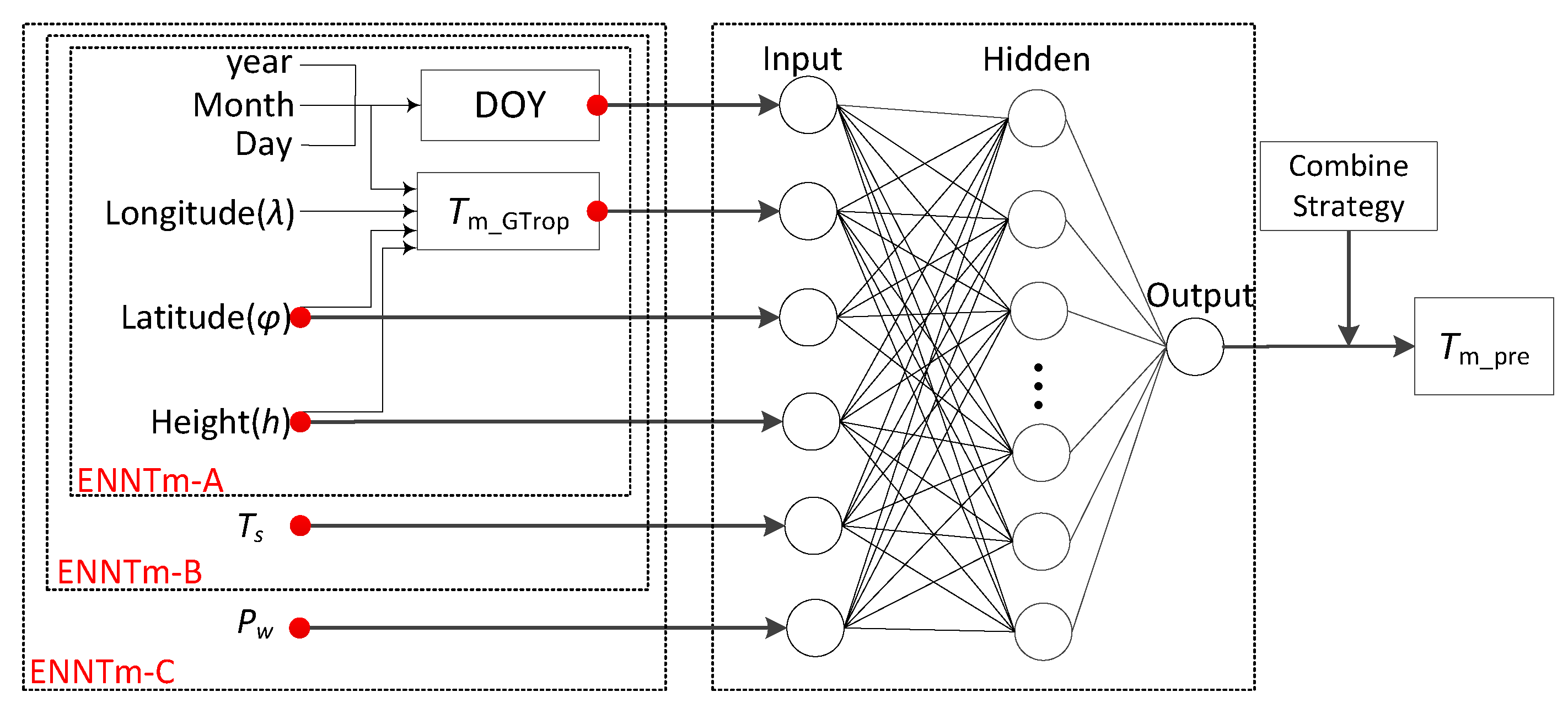
In this work, modeling based on neural network is further studied. An enhanced neural network model (namely ENNTm for short) is developed with the help of the ensemble learning method within the framework of machine learning. The ENNTm provides three sets of model parameters corresponding to three empirical models, the ENNTm-A model, ENNTm-B model and ENNTm-C model, which can meet the needs of estimation under three different application conditions, i.e., no measured meteorological element is needed (ENNTm-A model), only the air temperature of the site is required (ENNTm-B model) and both air temperature and water vapor pressure are needed (ENNTm-C model). In the following sections, the modeling process are introduced, their generalization ability of ENNTm is discussed, and the comparisons of model performance with those of other published models are also carried out.
4. Results
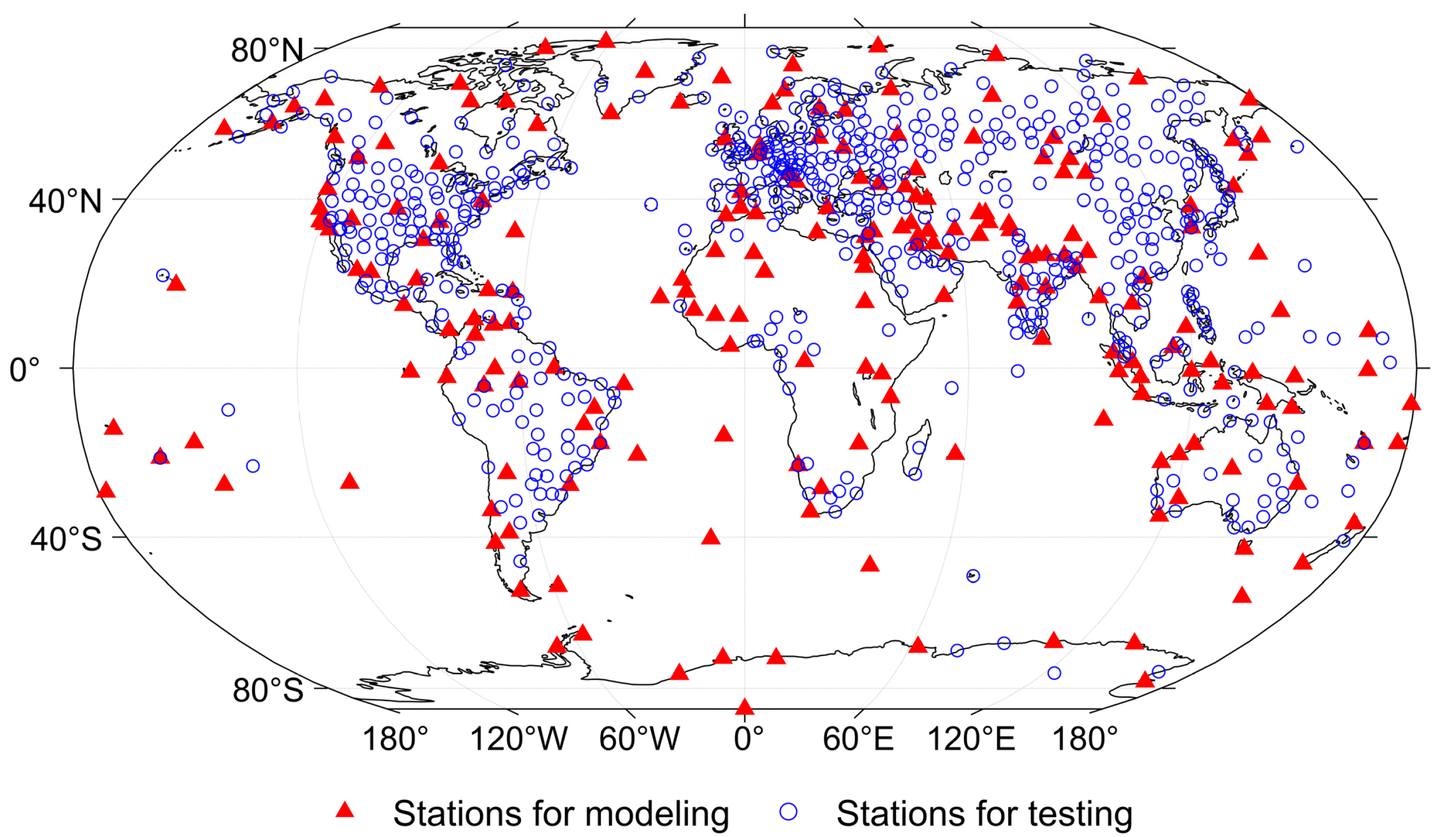
Atmospheric profiles measured from 2016 to 2018 by 569 IGRA stations were utilized to verify the performance of the ENNTm proposed in this work. The mean deviation (MD), mean absolute deviation (MAD), root-mean-square error (RMSE), standard deviation (STD) and Pearson correlation coefficient (R) were used to evaluate the model accuracies:
where
n is the number of the test samples,
and
are the
i-th
value computed with the empirical model and the
value derived from the radiosonde measurements, respectively.
and
are, respectively, the mean values of
and
.
In this section, the generalization abilities of different modeling schemes were discussed, and the performance of the proposed models were evaluated in comparison with three published empirical models: the GTrop-Tm model, NN-I model and NN-II model. The features and operation conditions of different competing models are shown in
Table 2.
4.1. The Generalization Ability of ENNTm
We first examined the generalization abilities of different modeling schemes, the atmospheric profiles of 569 radiosonde stations distributed globally measured in 2016 (a total of 8,065,535 samples) were employed in this subsection. The MD, MAD, RMSE, STD and R are shown in
Figure 3,
Figure 4,
Figure 5,
Figure 6 and
Figure 7. The ensemble size of different modeling schemes are all of 50.
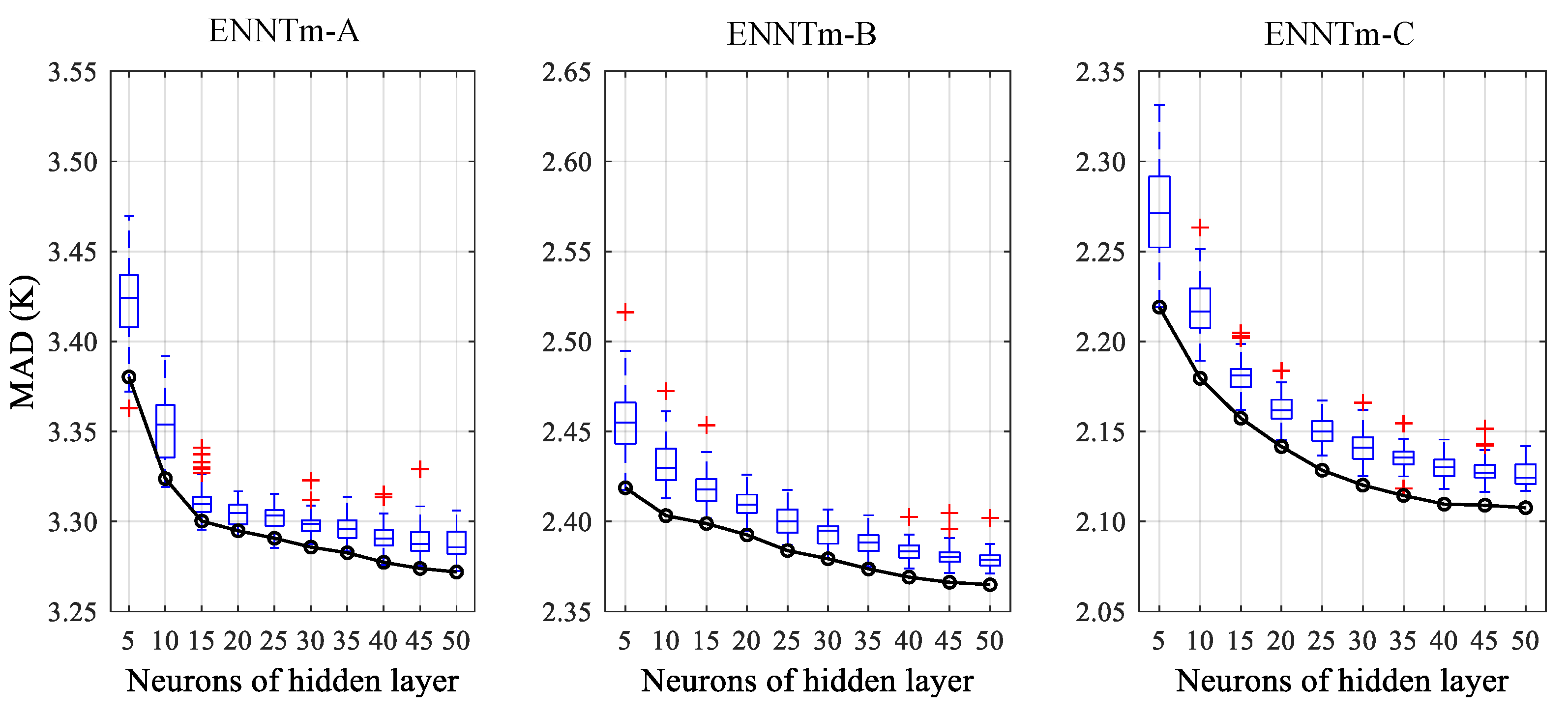
From
Figure 3, one can see that the MDs of different modeling schemes become smaller as the number of neurons in the hidden layer (
N) increases. The MD changes greatly when
N is not exceeding 10, and many more outliers could be found for the ENNTm-C model when
N is 5, and with
N rising, the MDs of different modeling schemes tend to be stable. The effect of ensemble learning is not obvious from the perspective of MD, since the ensemble learning pays more attention to reducing variance rather than expectation of when it is used for regression tasks, but we can verify the effect of ensemble learning through some other indicators such as MAD, RMSE, STD and R.
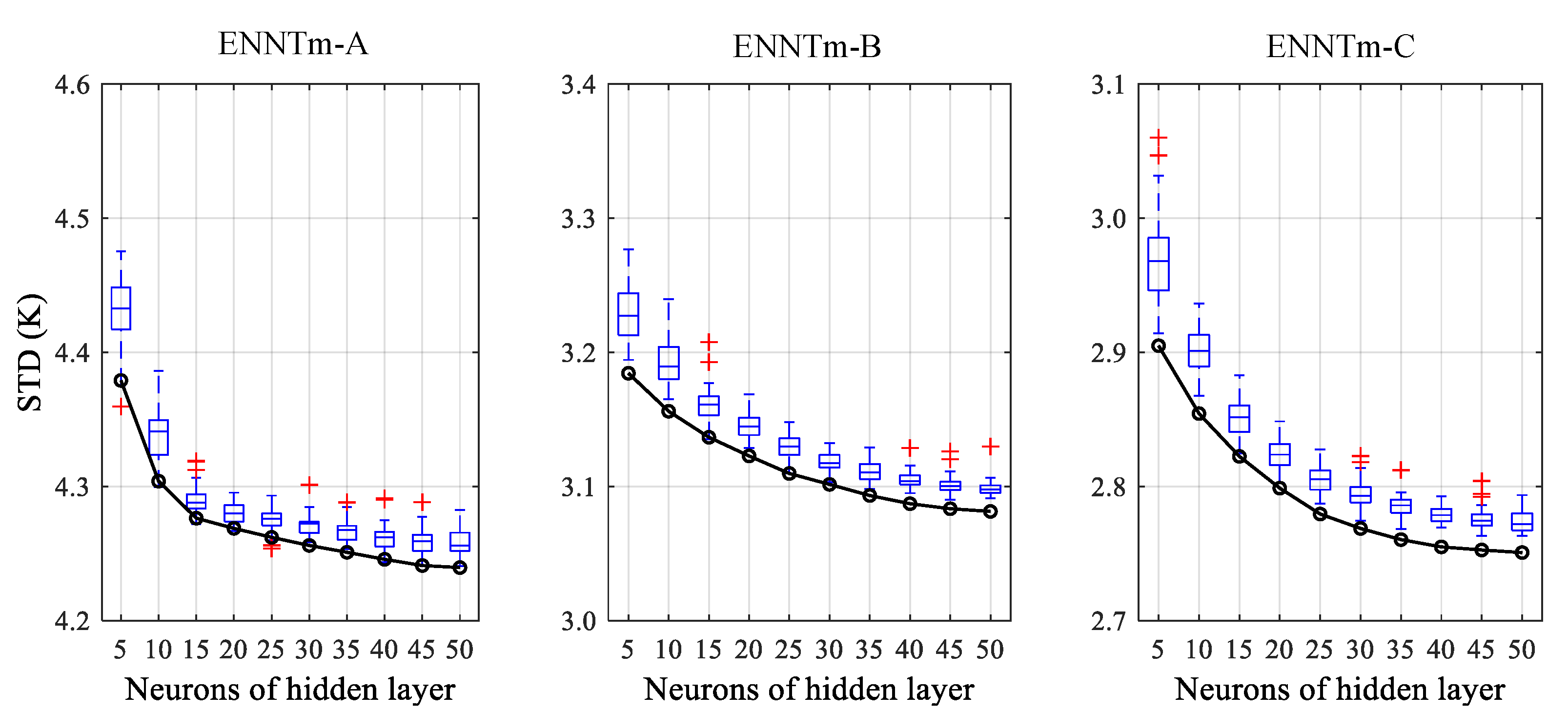
As can be seen in
Figure 4,
Figure 5 and
Figure 6, the MAD, RMSE and STD decrease with the increase in
N, however, when
N is greater than 20, the downward trends of these indicators gradually slow down. Another significant and common phenomenon is that the performances of ENNTm models become stronger after combination, the MAD, RMSE and STD of different modeling schemes can even be better than the individual BPNN with the best performance. It can be concluded that the ensemble learning method can help the BPNN model achieve better generalization ability.
We also examined the Pearson correlation coefficients (R) between the model values and
values derived from the radiosonde measurements. It can be seen from
Figure 7 that the R becomes larger with the increase in
N for different modeling schemes, and many more outliers can be found when
N does not exceed 20. The effect of ensemble learning is also remarkable for all the modeling schemes, which is consistent with the results shown in
Figure 4,
Figure 5 and
Figure 6.
According to the analysis above, we found that the performances of BPNN models become stronger as the number of neurons in the hidden layer (N) increases. However, for a BPNN model with only a three-layer network structure, the improvement of model performance was limited with the increase in model complexity. For example, the reduction rate of RMSE slows down as N is greater than 20. In addition, the model performances can be further improved and better generalization ability can be achieved by combining different training tasks. In conclusion, we believe that the model with N greater than 20 and enhanced by ensemble learning would achieve better performance, so we also provide all the weight and bias values after training for the user’s reference.
4.2. The Overall Performances of Different Models
We investigated the overall performances of ENNTm models in comparison with three published empirical models: the GTrop-Tm model, NN-I model and NN-II model. The atmospheric profile data measured from 2017 to 2018 were utilized in this subsection. The results of ENNTm models all correspond to the results when the number of neurons in the hidden layer (N) is 25.
We first evaluated the model accuracies of different models with the data near the Earth’s surface (below 100 m above the Earth’s surface), a total of 1,687,098 samples were used to compute the MD, MAD, RMSE, STD and R, and the results are shown in
Table 3.
From
Table 3, one can see that the GTrop-Tm model and NN-I model have a larger negative MD on the global scale, while the NN-II model and ENNTm models perform better, and the ENNTm-C model has the smallest MD (−0.07 K) among them. In terms of the MAD, STD and RMSE, the GTrop-Tm model and ENNTm-A model perform poorer than the other competing models since they are all NMTm models, but since others belong to MMTm models, numerous studies have demonstrated that the model accuracies of MMTm models are better than those of NMTm models. Among the published models, the NN-II model was designed for computing
from the Earth’s surface to 10 km altitude, but its performance is not as good as that of the NN-I model in computing
near the Earth’s surface. A tiny improvement can be found for the ENNTm-B model compared to the NN-I model. The ENNTm-C model, however, performs the best, since its MAD, STD and RMSE are significantly reduced compared to other competing models, which is consistent with the conclusions of the literature study [
15]. We can also obtain similar conclusions from the perspective of R.
Since the ENNTm models are all designed for calculating
values in near-Earth space, we conducted the model accuracy comparisons with the data from the Earth’s surface to 10 km altitude (a total of 25,373,469 samples), the results are shown in
Table 4.
In
Table 4, one can see that the MD, MAD, STD and RMSE of NN-I model are far larger than those of other models. The NN-I model is only designed for the
estimation near the Earth’s surface, and the comparisons between the NN-I model and NN-II model were carried out in the literature study [
10], in which it was concluded that the NN-II model is far superior to the NN-I model in all aspects when validated with the data from the Earth’s surface to the tropopause, so we did not consider the NN-I model in the following analysis. Among other competing models, the GTrop-Tm model has the largest positive MD, while marked negative MD could be found for the NN-II model and ENNTm-A model. The ENNTm-B model and ENNTm-C model all performed better than other models in terms of MD. In the MAD, STD and RMSE cases, significant improvement can be seen for ENNTm-A model compared to GTrop-Tm model, with an improvement of about 10% in MAD, STD and RMSE, respectively. The ENNTm-B model also improves much in MAD, STD and RMSE compared with the NN-II model, by 8%, 7% and 8%, respectively. The ENNTm-C model performs the best, improves by 12% over ENNTm-B model and 21% over NN-II model in RMSE, respectively. A similar phenomenon can be found in the case of R, but their R values are much larger than those shown in
Table 3, since the models shown in
Table 4 (except for the NN-I model) are all designed for near-Earth space. In general, the performances of MMTm models are much better than those of NMTm models, and the improvements of ENNTm models in comparison with other published models under the same application conditions are remarkable.
From the comparison and analysis above, we can obtain similar conclusions from the perspectives of MAD, STD, RMSE and R in the evaluation of model accuracy. Therefore, in the following analysis, we only consider the MD and RMSE as the performance indicators.
4.3. The Spatial Performances of Different Models
We further conducted the spatial performance comparisons for different models on the global scale. The testing dataset was divided into five groups according to the geographical zones, the definitions of different geographical zones are shown in
Table 5.
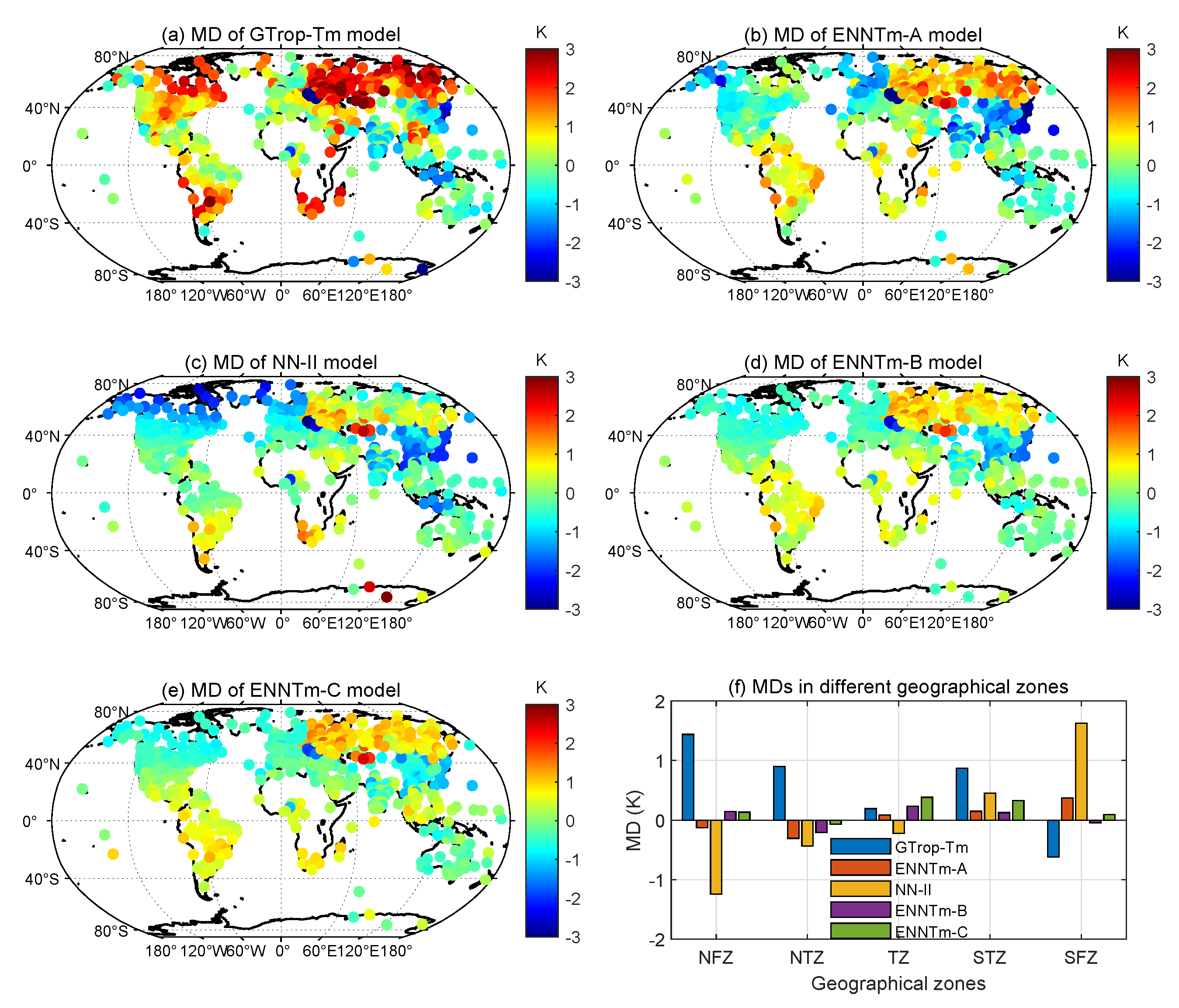
The MD and RMSE for different models at each test IGRA station are calculated and shown in
Figure 8 and
Figure 9, and the statistics of MD and RMSE for each model in different geographical zones are also shown in the figure.
From
Figure 8a,b, remarkable positive MD in the middle-to-high latitudes can be found for the GTrop-Tm model, but the IGRA stations from Australia to southern China show obvious negative MDs. The ENNTm-A model performs similarly but is a great improvement over the GTrop-Tm model in most regions. In
Figure 8c–e, the NN-II model shows marked negative MDs in the Northern Hemisphere, such as in North America and southern China, but positive MDs could be found in north Asia, South Africa and South America, etc. The ENNTm-B model and ENNTm-C model, however, both show improvement compared to the NN-II model, especially in the middle-to-high latitudes. From
Figure 8f, the detailed statistics of MDs for different models seem to be consistent with the results shown in
Figure 8a–e. The GTrop-Tm model shows a large positive MD in the NFZ, the NT and the STZ, but a smaller negative MD can be found in the SFZ. In the TZ, there are no marked MDs for any of the competing models. The NN-II model shows a large positive MD in the SFZ and a marked negative MD in the NFZ, but it performs well in other geographical zones. The ENNTm models, however, all show very small MDs in each geographical zone.
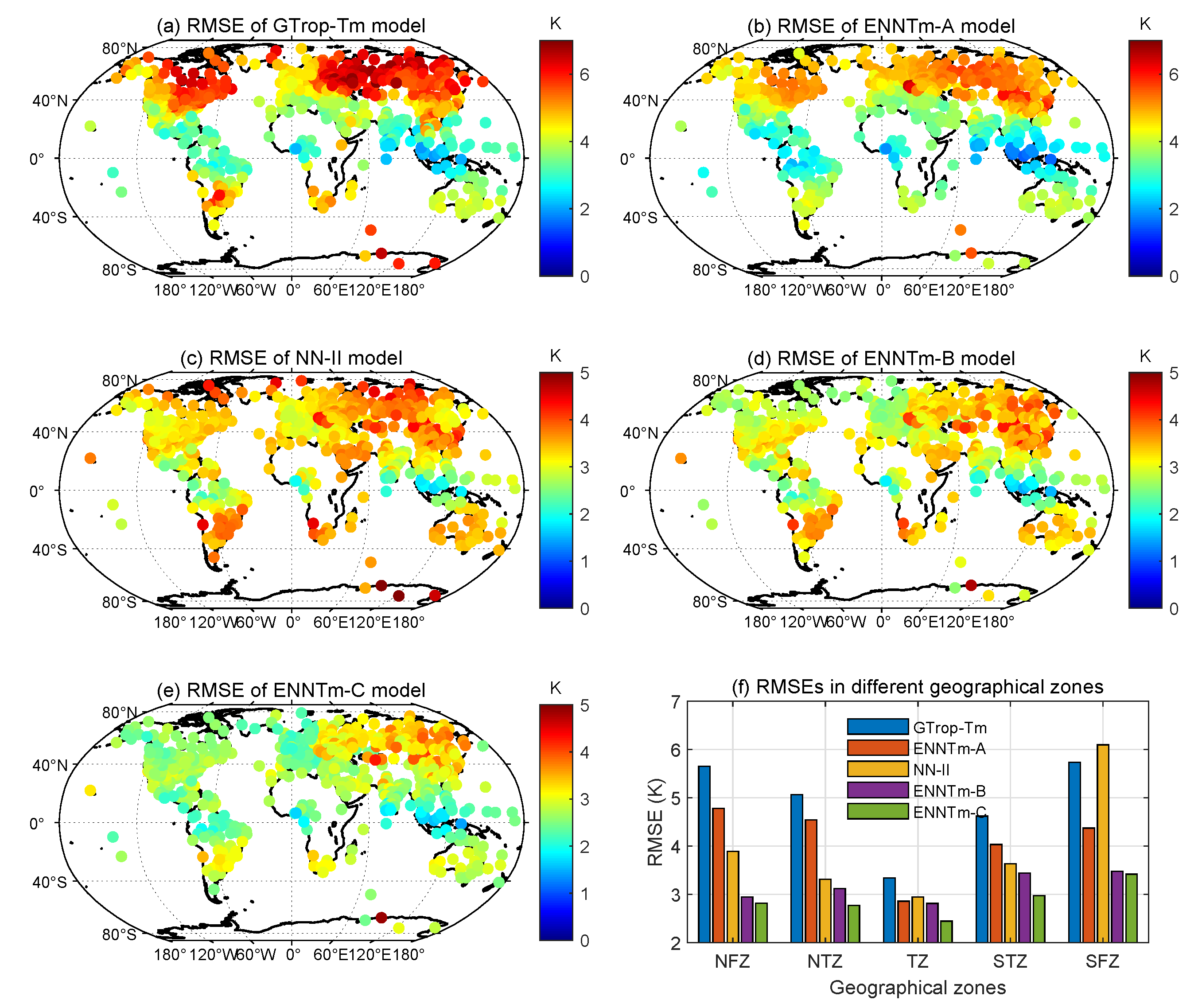
With regard to the RMSE, one can see from
Figure 9a,b,f that the GTrop-Tm model shows a larger RMSE on the global scale than other competing models, especially in the middle to high latitudes. However, significant improvement can be found for the ENNTm-A model in all of the geographical zones compared to the GTrop-Tm model, especially in the SFZ (reduced by 1.4 K) and NFZ (by 0.8 K). From
Figure 9c–f, one can see that the values of RMSE for the NN-II model are almost all from 3.0 K to 5.0 K, except for a few IGRA stations distributed near the equator, where it is even inferior to that of the NMTm models (GTrop-Tm model and ENNTm-A model) in the SFZ. The ENNTm-B model and ENNTm-C model have greatly improved this defect, and the improvement in RMSE is very significant in the SFZ (by 2.6 K) and the NFZ (by 0.9 K). We can also see that the RMSEs of ENNTm-C model are smaller than those of the ENNTm-B model in the tropical zone and the temperate zones, even though the improvement is not significant.
We also computed the RMSE reductions for ENNTm models with respect to the GTrop-Tm model and NN-II model, and the detailed statistics of RMSE reductions are shown in
Figure 10.
One can see from
Figure 10a that the RMSE of the ENNTm-A model reduces in over 80% of test IGRA stations with respect to GTrop-Tm model, and in the stations where the RMSE reduces by more than 0.5 K, this accounts for 42%. From
Figure 10b, the RMSE of more than 90% stations reduces for the ENNTm-B model with respect to the NN-II model, and even though the RMSE of over 83% stations only reduces by 0–0.5 K, this can still illustrate the advantage of the ENNTm-B model over the NN-II model in terms of model accuracy. In
Figure 10c, one can see that the RMSE reduction in the ENNTm-C model with respect to the NN-II model is significant enough that the test IGRA stations whose RMSE reduces by over 0.5 K account for 65% of the total. In the comparison between ENNTm-B model and ENNTm-C model shown in
Figure 10d, the RMSE for the ENNTm-C model at over 97% of the test IGRA stations reduces with respect to ENNTm-B model, which further indicates that the accuracy of the
model can be improved by introducing water vapor pressure into modeling.
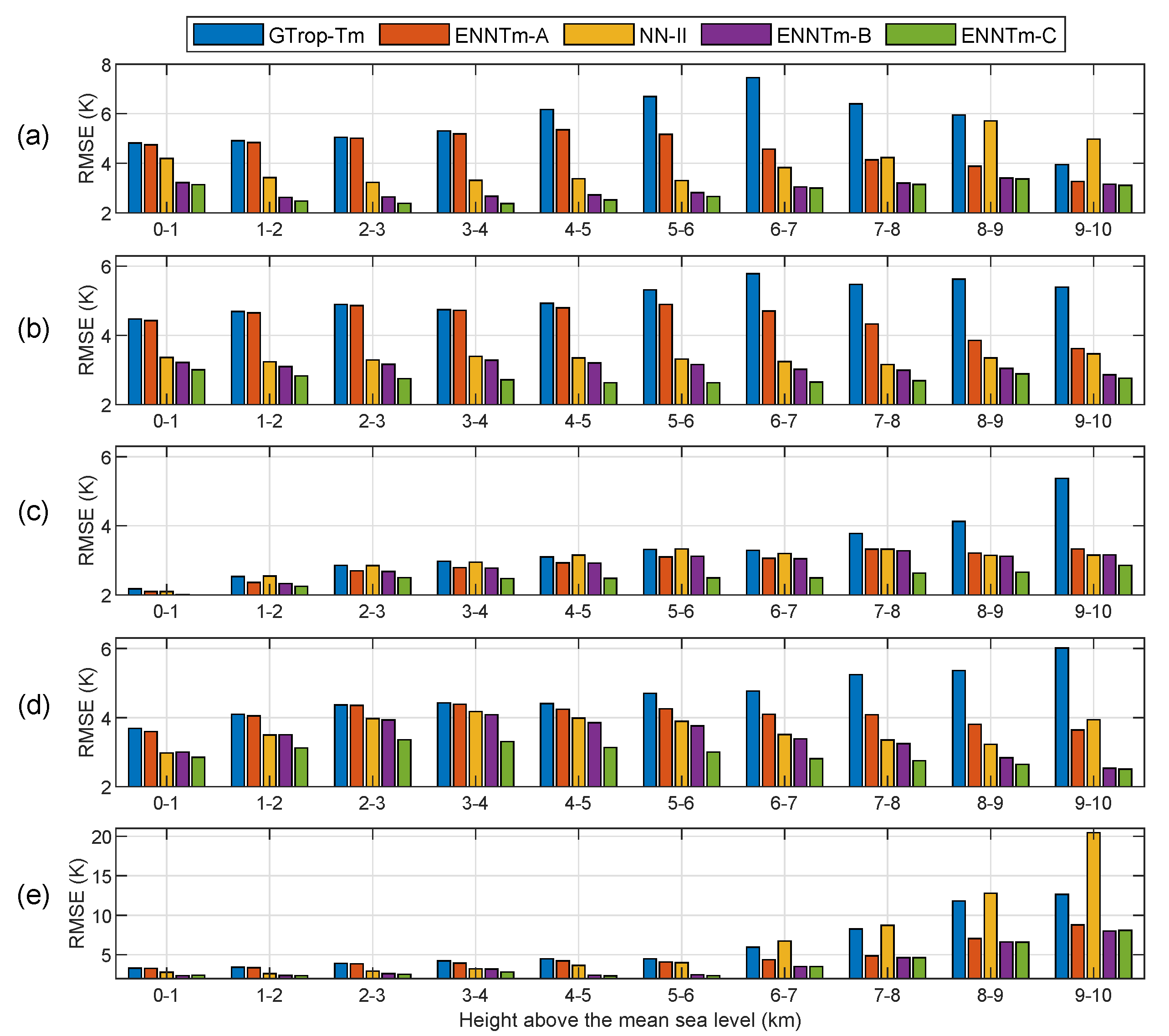
To investigate the performances of different models in the vertical direction, we divided the test samples in each geographical zone into 10 groups with an interval of 1.0 km altitude to compute the MD and RMSE. The results are shown in
Figure 11 and
Figure 12.
Figure 11 shows that the MD for each model generally shows an increasing trend with the increase in height and the GTrop-Tm model is the most prominent one, just as that shown in
Figure 11b–d. It seems that the GTrop-Tm model performs the poorest at the height layers from 4 to 10 km, except in the SFZ. The ENNTm-A model is shown to be much better than the GTrop-Tm model at any height layers, especially at the height layers above 4 km. The NN-II model has a very large positive MD at the height layers from 8 to 10 km, as shown in
Figure 11d,e, however, negative MDs could be found for it at the height layers below 6 km in the NFZ and NTZ shown in
Figure 11a,b. The ENNTm-B model and ENNTm-C model perform much better than the NN-II model at any height layers in most geographical zones, such as at the height layers below 5 km in NFZ and NTZ, as shown in
Figure 11a,b, as well as the height layers above 7 km in STZ and SFZ shown in
Figure 11d,e. Poor model performances could be found for the ENNTm-B model and ENNTm-C model at height layers over 8 km near the equator, as shown in
Figure 11c, but their MDs are not significant, and no more than 1.0 K.
With regard to the detailed statistics of vertical RMSEs in different geographical zones shown in
Figure 12, one can see that the RMSE of the GTrop-Tm model increases with the height in the Southern Hemisphere, while its RMSE first increases then decreases with the height in the Northern Hemisphere. The ENNTm-A model also has such a rule but it is better than the GTrop-Tm model, and its RMSE reduces at any height layers compared to the GTrop-Tm model. The NN-II model performs well in the RMSE at any height layers from the NTZ to STZ, as shown in
Figure 12b–d, however, in the SFZ shown in
Figure 12e, the NN-II model shows a far larger RMSE compared to other competing models at the height layers above 6 km. The RMSE of the ENNTm-B model improves compared to the NN-II model at almost any height layers, even though the improvement is not sometimes significant. The ENNTm-C model, however, improves much over the NN-II model in the near-Earth space in any geographical zones, and it performs the best among the competing models.
4.4. The Temporal Performances of Different Models
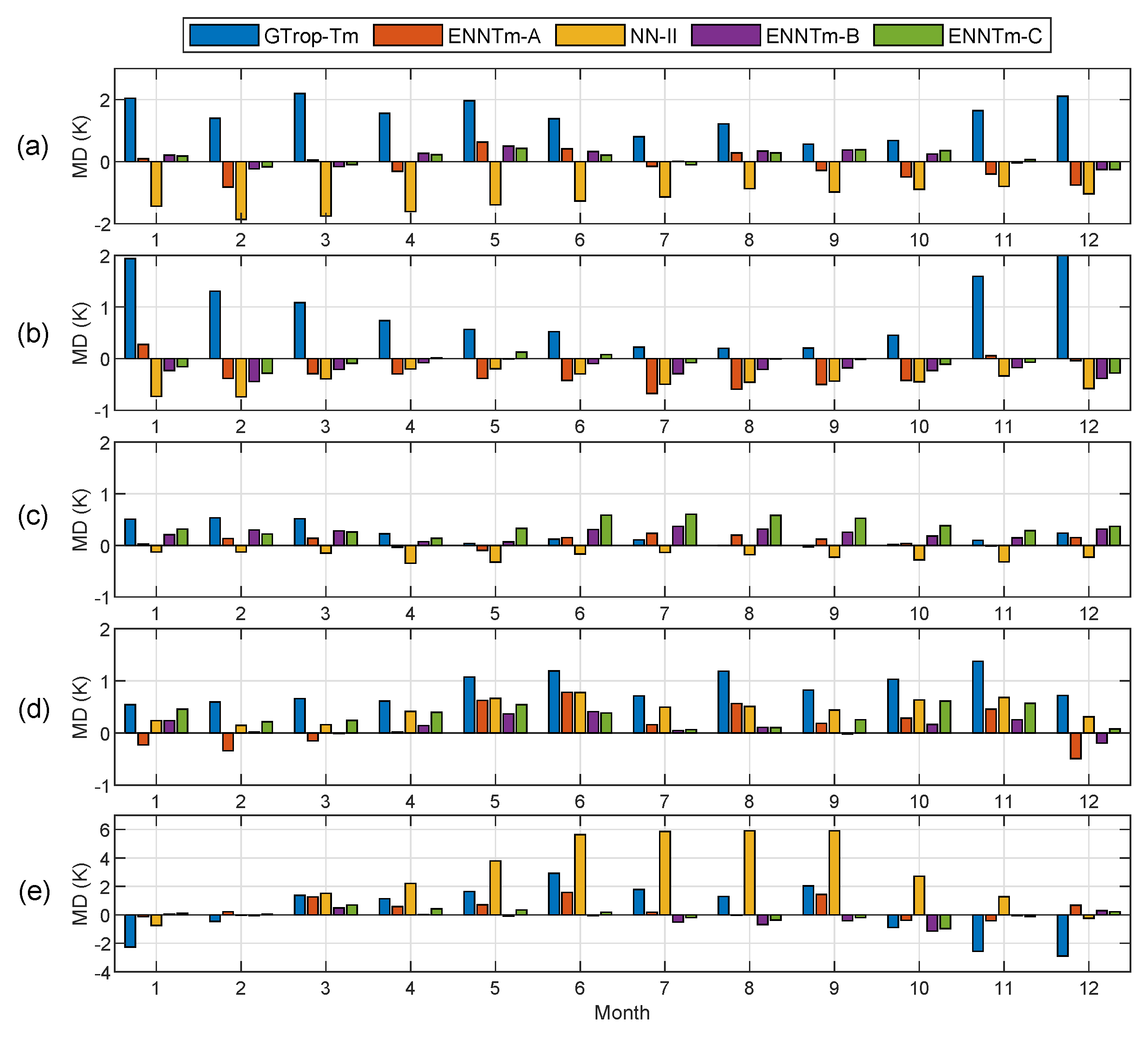
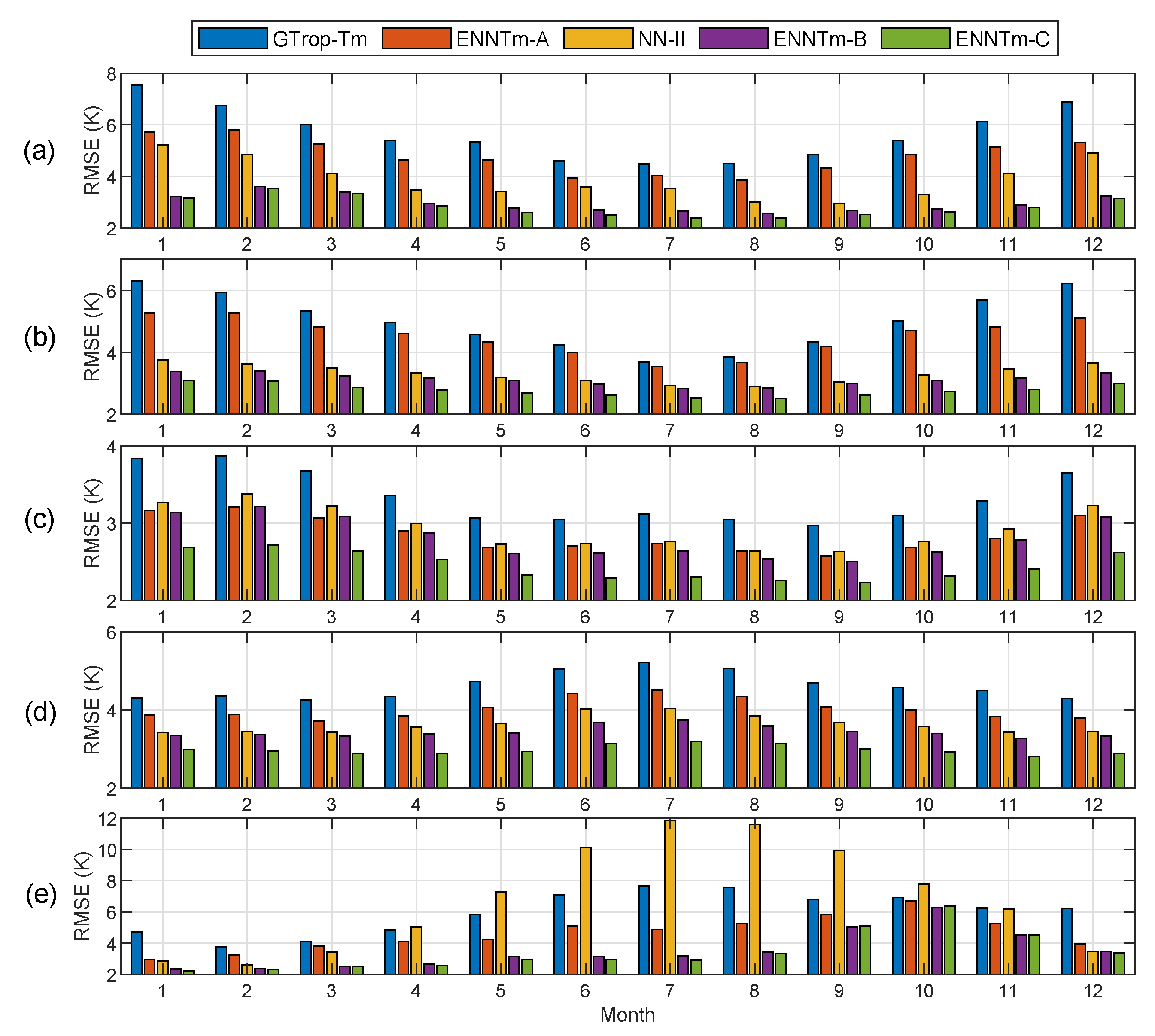
We also investigated the temporal performance of different models. The test samples were divided into six groups according to the geographical zones, and we computed the MD and RMSE in different months for each group, for which the results are shown in
Figure 13 and
Figure 14.
Figure 13e shows that in the south frigid zone (SFZ), the NN-II model has a far larger positive MD than other competing models in the Southern Hemisphere during winter months, and large positive MDs could be found from April to October, while there is no significant bias in other months. The GTrop-Tm model, however, shows large negative MD in summer months (such as November, December and January) but a remarkable positive MD in winter months. In the statistics of the south temperate zone (STZ) shown in
Figure 13d, a similar phenomenon can be seen for the MDs for the GTrop-Tm model and NN-II model in the winter months, which are larger than those in summer months. In the detailed statistics of MDs in the north frigid zone (NFZ) and the north temperate zone (NTZ) shown in
Figure 13a,b, this phenomenon also exists as the MDs for the GTrop-Tm model and NN-II model are larger during winter months (in the Northern Hemisphere) than those during the summer months. However, there are no significant biases which can be found for ENNTm models in any months throughout the year, except for the results in the Tropical Zone (TZ) presented in
Figure 13c, where the ENNTm-C model shows a relatively larger positive MD (not more than 0.6 K) from June to September.
In terms of the detailed statistics of RMSEs shown in
Figure 14, a common phenomenon is that the RMSEs of all the competing models are larger in winter months and smaller in summer months, it is mainly caused by the fact that the
changes are larger during winter and smaller during summer months [
41]. The RMSEs of GTrop-Tm model are always the largest among all the competing models in different months throughout the year, except for the results shown in
Figure 14e. The ENNTm-A model is of a great improvement compared to the GTrop-Tm model, but these are still less accurate than those MMTm models. The NN-II model performs the poorest in the winter months of the STZ, with the maximum RMSE of nearly 12 K, but it performs much better than the GTrop-Tm model and ENNTm-A model in other zones. The improvement of ENNTm-B model over the NN-II model is significant in STZ, while in other zones, even though the accuracy of the ENNTm-B model has been consistently improved over the NN-II model in each month, therefore the improvement is not pronounced. The performance of the ENNTm-C model is further improved on the basis of the ENNTm-B model, which indicates that the water vapor pressure is an important factor to improve the model accuracy.
5. Discussion
In this work, the data samples from the Earth’s surface to the tropopause were used to develop an enhanced neural network
model (ENNTm), which provides three sets of model parameters that can meet three different application conditions for global users (namely ENNTm-A,ENNTm-B and ENNTm-C, respectively). The BPNN shows a powerful capability and capacity to capture the spatiotemporal variations between the
and its associated factors in the development of ENNTm models. The models proposed in this study were further optimized by ensemble learning, the results presented in
Section 4.1 show that this method can efficiently strengthen the generalization abilities of BPNN models after multiple training sessions, as the BPNN model after combination showed better generalization ability than that after one certain training mission. From the comparative analysis in
Section 4, the ENNTm models proposed in this work showed better performance than other published models listed in this paper from multiple perspectives. The ENNTm-A model improved by 10% over the GTrop-Tm model in RMSE, and had smaller bias o at the global scale. The ENNTm-B model also improved much in overall MAD, STD and RMSE compared with the NN-II model, by 8%, 7% and 8%, respectively. The ENNTm-C model performed the best, as its RMSE was reduced by 21% and 12% compared to those of the NN-II model and ENNTm-B model, respectively. There are multiple reasons for the improvements of ENNTm models over other competing models (under the same application conditions), as follows.
Firstly, the data for modeling in this study were derived from the atmospheric profiles measured by the sounding balloons, while the GTrop-Tm model was developed with the data derived from the NWMs. These two data sources are different somehow, which leads to some differences between the GTrop-Tm model and ENNTm-A model. The ENNTm-A model performed better than the GTrop-Tm model at most IGRA stations for testing (account for more than 80%).
Secondly,
is assumed to have an approximately linear decrease with the increase in height in the vertical direction in the development of the GTrop-Tm model, which deviated from reality. This is exactly the reason why the MD and RMSE of the GTrop-Tm model at the higher height layers were much larger than other competing models, just as shown in
Figure 11 and
Figure 12. The ENNTm models, however, well simulated the relation between
and height with the help of the powerful nonlinear mapping ability of the neural network. The results showed that the performance of the ENNTm-A model in the vertical direction was much better than that of the GTrop-Tm model.
Thirdly, the global distribution of data samples for developing NN-I/NN-II model is extremely uneven, as there are far more samples distributed in the Northern Hemisphere than that in the Southern Hemisphere, while the training results of the neural network are extremely dependent on the training samples. As a result, the performance of the NN-II model on the global scale is also very uneven, as it can be seen from
Figure 11,
Figure 12,
Figure 13 and
Figure 14, sicne the performance of NN-II model in the frigid zones was very poor. In this study, we employed the up-sampling and down-sampling method to make the global distribution of training samples as uniform as possible. The results showed that the ENNTm-B model improved to some extent over the NN-II model, especially in the regions where the IGRA stations are rarely distributed.
Fourthly, the ENNTm-C model showed the best performance from all perspectives, as it even improved by 12% on the basis of the ENNTm-B model, which largely benefited from the introduction of water vapor pressure () into modeling. The has a strong correlation with the of the site, and the correlation coefficients between and computed by using the data in the troposphere (from the ground to the tropopause) reached 0.74. We considered the as one of the inputs of the ENNTm models to improve the model accuracy and provide users with more choices.
6. Conclusions
In this study, we developed an enhanced neural network model named ENNTm, in the aim of achieving the excellent capability of the neural network in dealing with nonlinear optimization problems of multiple input parameters. The ENNTm includes three empirical models, the ENNTm-A model, ENNTm-B model and ENNTm-C model, which provide solutions for global users to compute the weighted mean temperature under three different application conditions in real time. Their generalization abilities were enhanced with the ensemble learning method under the machine learning framework. The comparative analysis showed that the accuracies of ENNTm models are significantly improved compared with the published models under the same application conditions: The ENNTm-A model was superior to the GTrop-Tm model and its accuracy was improved by 10% in RMSE; The ENNTm-B model showed better performance than both the NN-I model and NN-II model from different perspectives, and the RMSE at over 93% test stations reduced with respect to NN-II model; The ENNTm-C model performed the best among all of the competing models from different perspectives, it was 12% and 21% better than ENNTm-B model and NN-II model in RMSE, respectively.
We concluded that the ENNTm proposed in this work performed better than other published models listed in this paper (under the same application conditions) at different perspectives. It benefited from not only the strong capability of neural networks in capturing the characteristics of variation and its relationship with the essential associated factors and the use of the ensemble learning method in strengthening the generalization abilities of new models, but also the use of the measured atmospheric profile data, as well as the reasonable pretreatment work before modeling. However, the variations of and the relationship between and meteorological elements are extremely complex at different spatial and temporal contexts, in addition to their own spatiotemporal distribution characteristics, weather and climate change of different scales can also affect this relationship, which cannot be perfectly reflected with an empirical model, so more research on the modeling under different weather conditions is needed in the following study.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}