3.1. F2F and CNN
Most P2P retrieval methods produce ambiguous solutions, requiring a post process to deal with the ambiguity, and such methods are not conducive to maintain the continuity of the wind field [
21]. In response to the above problems, we redefine a F2F retrieval method. We construct a continuous wind field from the central sampling point and multiple vector cells in the adjacent specific range, input the NRCS and observed geometric parameters of the continuous wind field into the model, and apply the spatial feature information of the continuous wind field to the retrieval process. Finally, the continuous wind field is calculated at the same time.
Figure 2 shows the basic concept of the method.
The size of the continuous wind field has a certain relationship with the retrieval accuracy. The larger the continuous wind field is, the more information it covers, and theoretically the higher the retrieval accuracy will be. However, the increase of the field size will undoubtedly increase the amount of training data. When the field size increases to a certain interval, the cost of computation is not paid off by the accuracy improvement. Therefore, it is crucial to find the most suitable field size. According to Krasnopolsky [
21], when the edge length of the wind field increases to 9 (i.e., each continuous wind field is composed of adjacent 9 × 9 square area of wind vector cells), the retrieval accuracy is already desirable.
The F2F method involves complex models, especially when dealing with a large amount of data. Therefore, a method that has a strong ability to learn complex models to complete this task. CNN makes the network easy to optimize, reduces the complexity of the model, and reduces the risk of overfitting. In particular, the continuous wind fields of a specific range can be considered to be images [
22], which can be a direct input of the network, avoiding the complicated process of feature extraction and data reconstruction in traditional recognition algorithms [
23]. CNN, with these features and advantages, can be a perfect match for our needs.
The F2F method is used to achieve the wind field retrieval with the assist of CNN, thus termed F2F-CNN. The F2F-CNN method needs only an input of the continuous wind field during the network training process, involving no post process for dealing with the ambiguity, and can derive a smooth and continuous wind field.
3.2. Data Matching
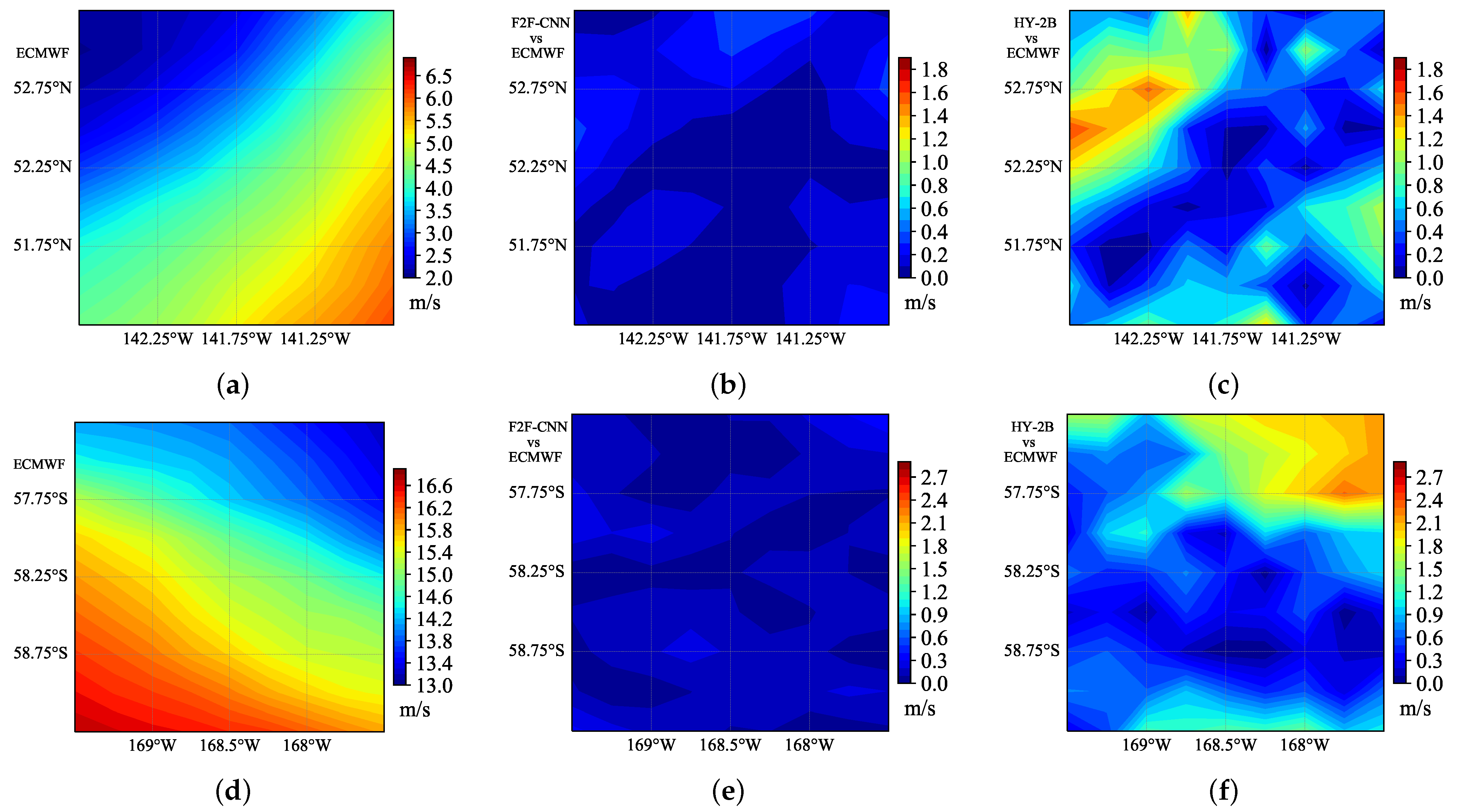
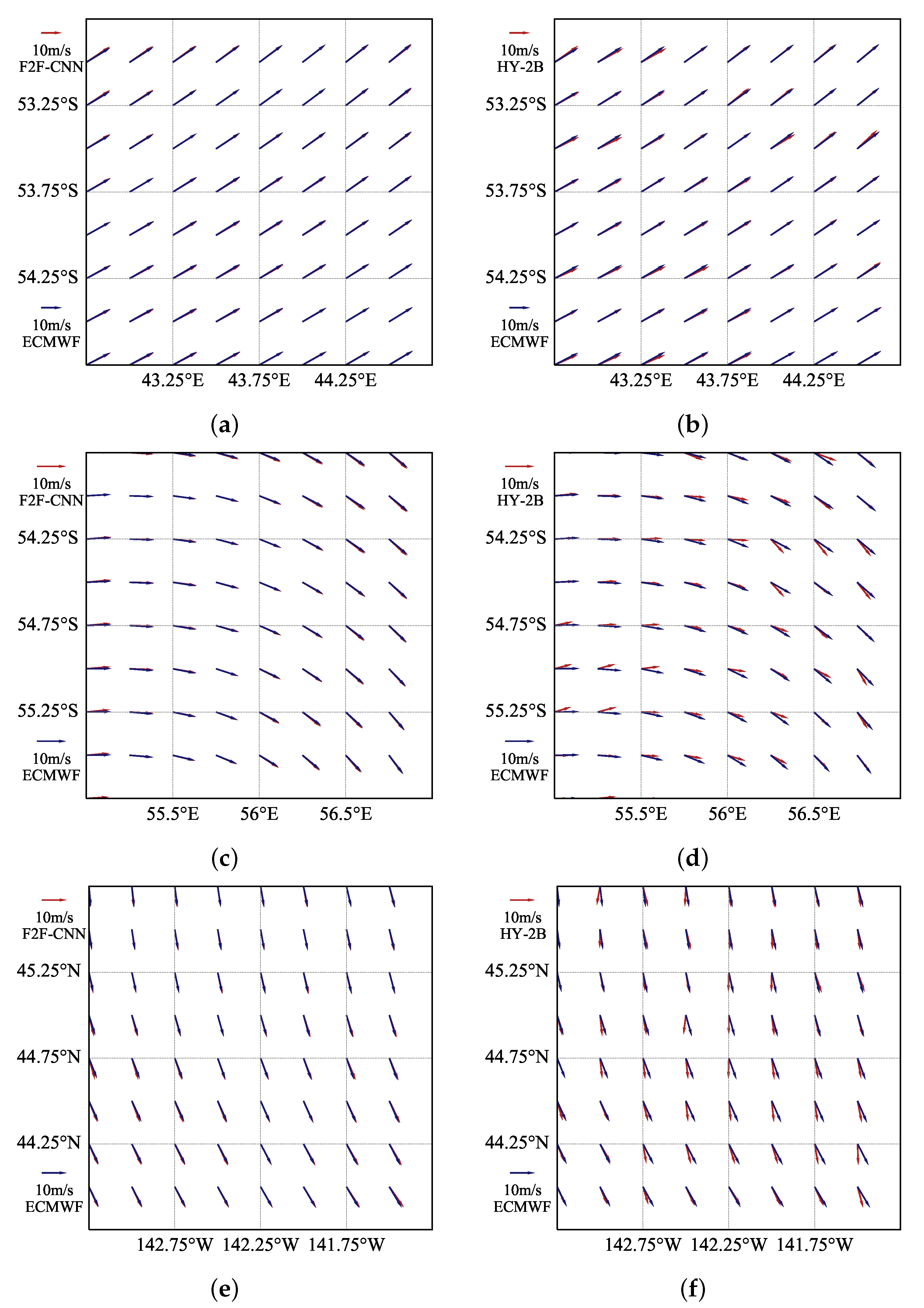
To make the comparison result more convincing and more authentic, we control the quality of the scatterometer data. We need to eliminate abnormal data values and low-reliability data for different scatterometer products. We only keep the wind vector cells with the quality mark of “Reserved” and the mark value of 0 in the HY-2B scatterometer product as our experimental objects (“Good” in ASCAT, and the mark value is also zero).
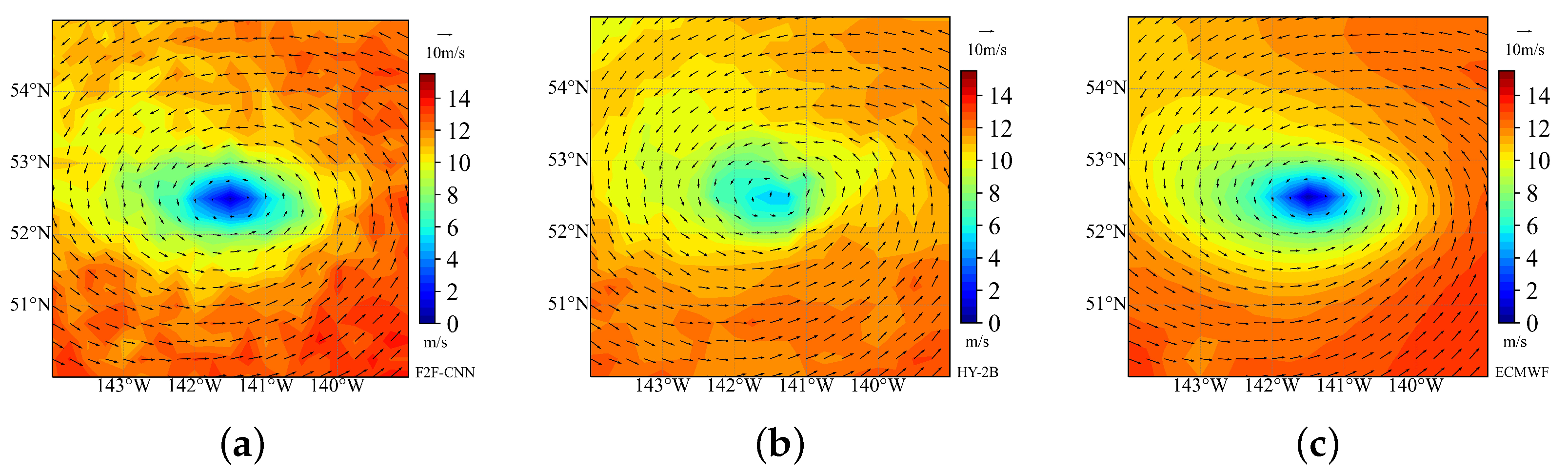
According to the requirements of the F2F-CNN method, we divided the obtained data into training data and test data. The multiple orbital L2A data of the microwave scatterometer in May and June 2019 are selected as the training data and the first set of test data. For the second set of test data we select the L2A data observed and generated by the HY-2B microwave scatterometer in May 2020. The second set of test data contain cyclone structures that help demonstrate the reconstruction capability of this retrieval method for cyclones. In addition, we also prepared HY-2B L2B data, ASCAT L2 data and buoy data to validate the F2F-CNN results.
The L2A data of HY-2B stores observations from multiple sampling points in each wind vector cell, which is to ensure that each wind vector cell has no less than three sets of NRCS with different azimuth/incidence angles and imaging geometry parameters, so that the unique wind speed and direction can be accurately inversed [
18]. According to the organization form of ECMWF label data, we re-match the L2A data with the label data wind vector cell to ensure that each label data cell has four sets of NRCS and observation geometric parameters with different azimuth/incident angles. According to the range of each cell of the ECMWF grid, we re-match each sampling point of the L2A data to the ECMWF cell. Subsequently, we classified the data of multiple sampling points in each cell, and classified the sampling points with the same incident angle and azimuth angle into one category (although the polarization method is the same, the incident angle and azimuth angle are also different, therefore, we should set the range, consider that the sampling points with the incident angle and the azimuth angle within a certain range of difference are regarded as the same type of observation point), and finally divided the matching sampling points in each cell into four categories. Finally, we used inverse distance weight (IDW) to interpolate the sampling point data of each type of face element to the center position of the vector cell. This method is implemented by Equations (1) and (2),
where
represents the estimated value of interpolation,
represents the attribute value of the
i-th sample (
).
p is the power of the distance, and the default is 2,
is the distance.
We matched the three closest data in the ECMWF data according to the collection time of each sampling point. According to Equations (3) and (4), the longitudinal and latitudinal component winds in these three ECMWF data are converted into wind speed and wind direction, where the wind direction is saved according to a 0° direction due north and increasing clockwise.
where
u is the latitudinal wind component,
v is the longitudinal wind component, and
is the wind speed (in m/s), and
is the wind direction (in radians). Assuming that the three moments to match the ECMWF are
,
and
, the corresponding wind speed (wind direction) values are
,
and
. We obtained the wind speed (or wind direction) value
at time
t according to Equations (5) and (6),
where
.
For matching HY-2B L2B data and ASCAT L2 data with ECMWF data, we choose the bilinear interpolation method, which is a linear interpolation in two directions perpendicular to each other according to Equations (9)–(11). Suppose we want to obtain the unknown function
f at the point
and it is known that the value of the function
f at the four points
,
,
and
. Linear interpolation is first performed in the x-direction based on Equations (7) and (8), and then again in the y-direction based on Equation (
9),
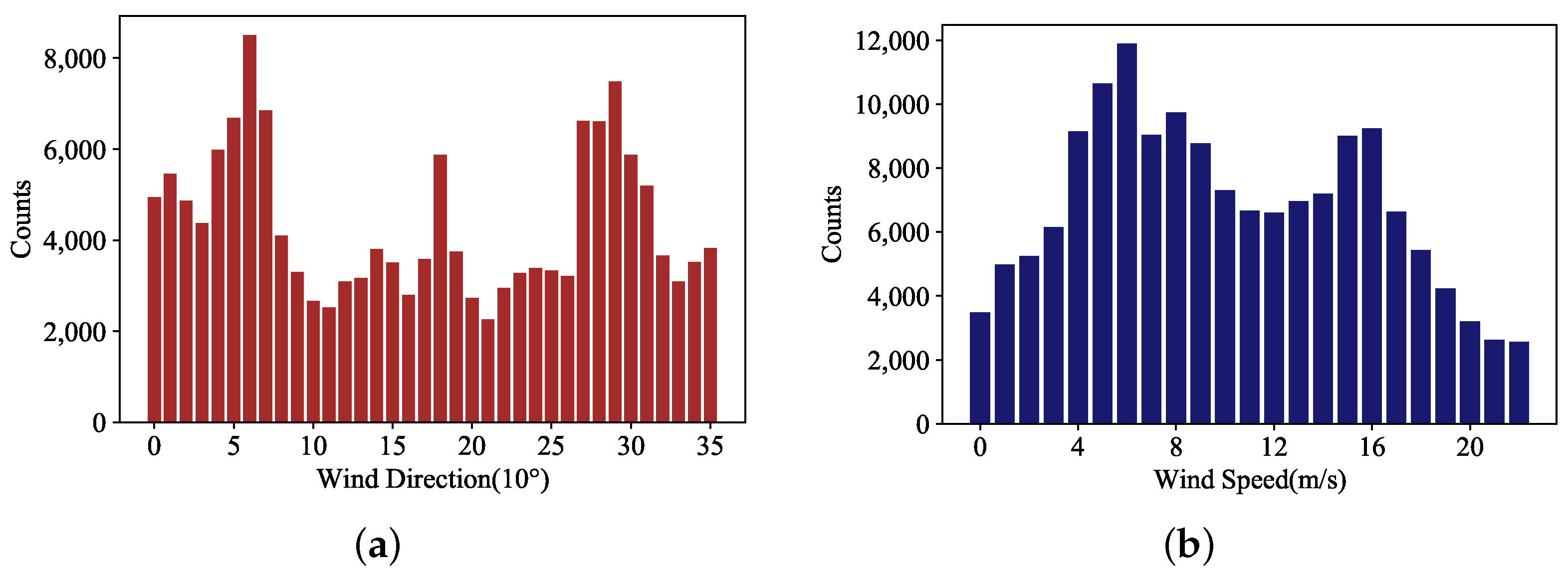
The size of the continuous wind field is set to 9 × 9. Each continuous wind field is composed of 81 adjacent wind vector cells with a size of 25 km × 5 km. We traversed each of the obtained data and used each vector cell in turn as the central cell, spreading the vector cell outward in 4 layers to form (1 + 2 × 4) × (1 + 2 × 4) = 81 cells. If all 81 vector cells have the complete data required for the experiment, the 9 × 9 continuous wind field is considered to be a complete training (test) wind field data. Screening the wind vector cells in each direction from 0 to 360° (
Figure 3a) and each velocity level from 0 to 25 m/s (
Figure 3b) in a balanced manner, we thus obtained 156,815 continuous wind field data for the training and test of the neural network.
Since the ECMWF data, ASCAT L2 data and the L2B data of HY-2B are both sea surface wind information at a height of 10 m. We need to convert the wind speed of the buoy data to the wind speed at a height of 10 m according to the Equation (
10) [
24], and the wind direction is not needed to convert,
where
z represents the height from the sea surface,
and
represent the wind speed at 10 m height and the wind speed at
z height, respectively.
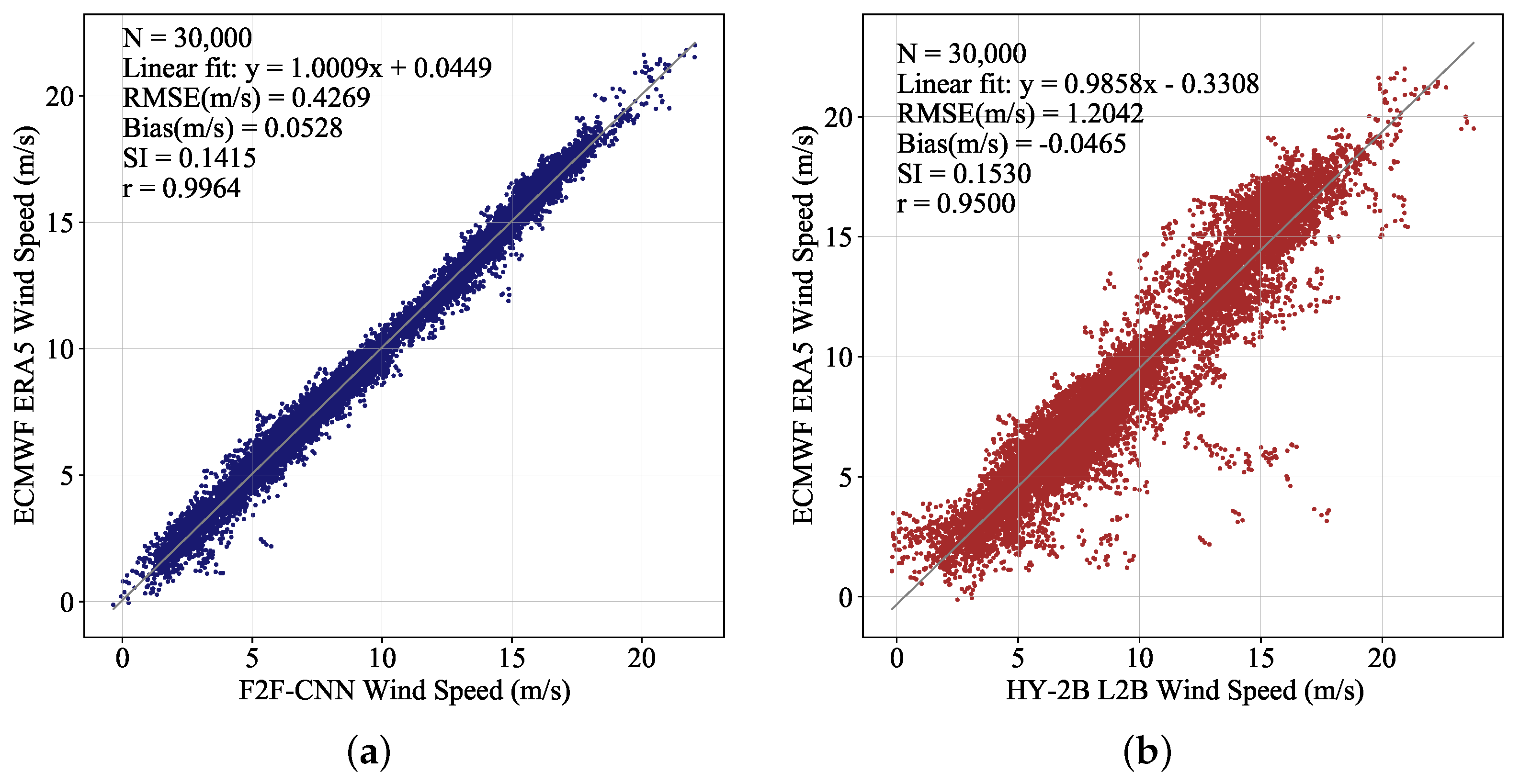
Four statistical parameters are used to evaluate the accuracy of wind field data obtained by the various methods mentioned in this paper. These comprised the
RMSE (Equation (
11)),
Bias (Equation (
12)), correlation coefficient (r) (Equation (
13)) and scatter index (SI) (Equation (
14)), which can be expressed as follows:
where
S represents the value to be tested,
T represents the true value used for measurement,
represents the mean value of the test value,
represents the mean value of the true value, and
n represents the number of test values.
3.3. Establishing and Training the Neural Network
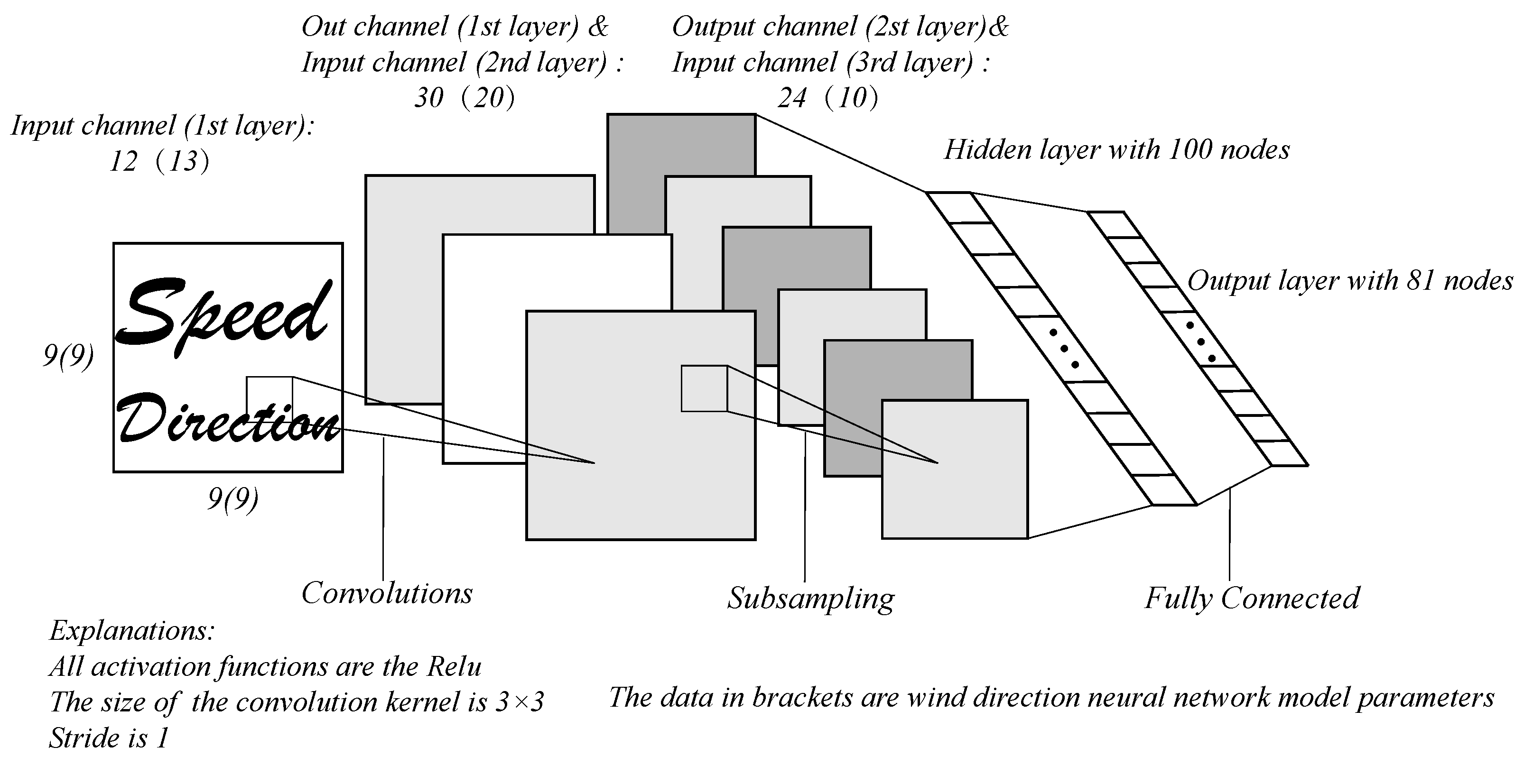
We applied CNN to retrieve the sea surface wind speed and direction. The basic convolutional neural network consists of three structures, i.e., convolution, activation and pooling. The most important process of the entire network is to adjust the network weights through training, the specific structure is shown in
Figure 4.
The wind speed retrieval is not only related to the NRCS, but also to the incident angle of the antenna beam and the observed azimuth angle [
25]. Each training sample contains four different sets of incidence angle, azimuth angle, and NRCS, so the number of input channels of the convolutional layer of the neural network should be 12. To ensure that the whole wind field is derived simultaneously, the node number of the fully connected output layer should be 81, where the output nodes correspond strictly to the positions of the continuous wind field. The 81 output nodes are assumed to be
, the values of the 9 × 9 vector cells are
, the correspondence can be obtained according to Equation (
15),
The neural network for wind speed retrieval consists of two convolutional layers and two fully connected layers. The number of input channels and output channels of the first convolutional layer are 12 and 30, respectively. The 30 channels are input to the second layer, which outputs 24 channels. The fully connected network contains a hidden layer with 100 nodes, and there are 81 nodes of the fully connected layer. All activation functions are the ReLU function, the size of the convolution kernel of the two convolution layers is 3 × 3, and the stride is 1. To train the neural network adequately, we set epoch to 100, the batch size to 64, and the loss function to RMSE.
The wind direction retrieval requires not only the 12 parameters used in the wind speed retrieval, but also the wind speed [
25]. Therefore, the number of input channels of the wind direction retrieval is 13, and the number of output channels in the first and second convolutional layers are 20 and 10, respectively. The rest of the settings are consistent with the wind speed retrieval model. The loss function of the wind retrieval neural network is still chosen as RMSE, but the calculation method is different. The wind direction error can be calculated in two different directions along the circumference of the circle. Combining with the actual situation, we take the smaller error value of the two directions as our true error based on Equation (
16),
where
is the true difference between the neural network output and the direction label, and
is the output value of the neural network, and
is the label value.
To ensure the generalization ability of the neural network, we randomly disrupted the experimental data. We used about 80% of the obtained data as the training data (
) and the rest as test data (
). We obtained 126,815 training data and 30,000 test data, which are normalized according to Equation (
14) in the following order,
where
is the training data set, and
is the mean of the training data, and
is the standard deviation of the training data.
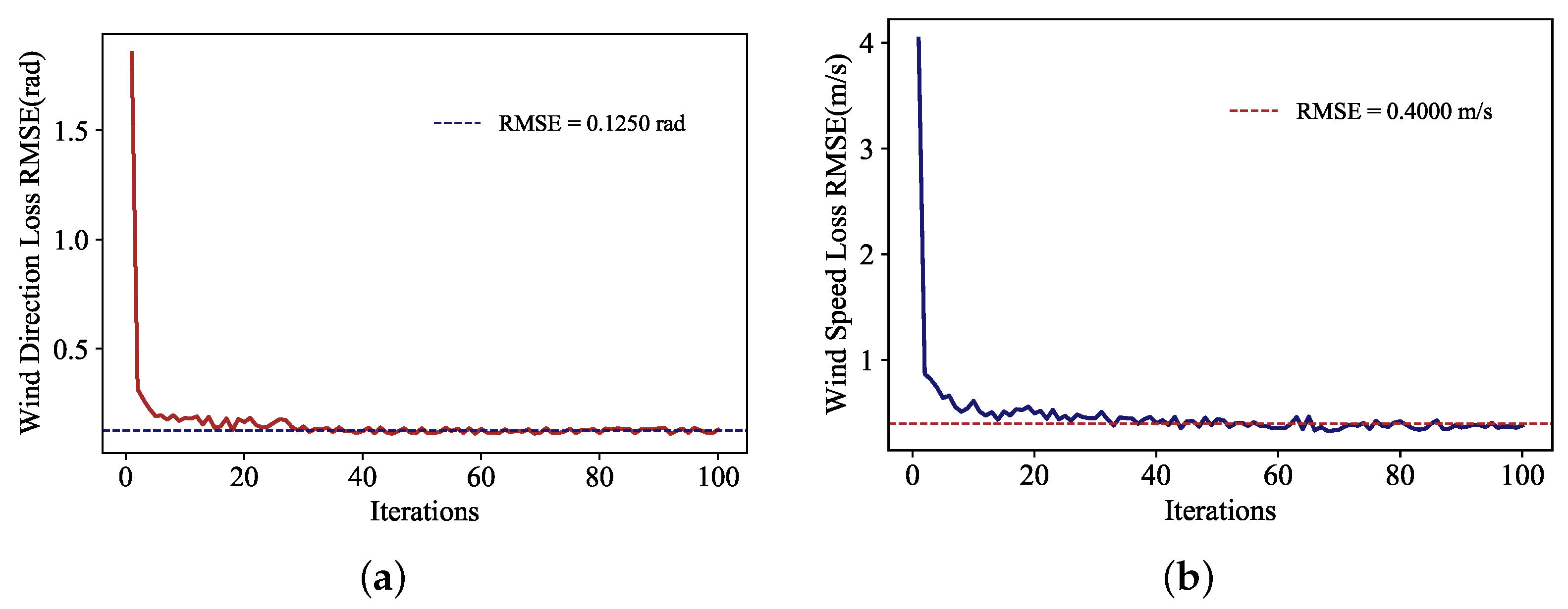
After 20 iterations of the wind speed retrieval neural network, the loss function value has decreased significantly. After 100 iterations, the RMSE is stabilized around 0.4000 m/s (
Figure 5a), and the training of the wind speed retrieval model is completed. The RMSE decreased significantly after 30 iterations, and the error function value (RMSE) is stabilized at about 0.1250 rad after 100 iterations (
Figure 5b). The wind direction retrieval model is saved after training.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}