1. Introduction
River ecosystems and their basins have been subjected to profound disturbances, mainly due to the increase in human population and consequent degradation of natural resources, therefore the protection of these ecosystems is essential. A well-functioning watershed carries out nutrient cycling, carbon storage, erosion, sedimentation, and flood control, soil formation, and water filtration. They supply drinking water, water for agriculture and manufacturing, a habitat to numerous plants and animals, as well as opportunities for recreation and the enjoyment of nature. Watershed management is the study of the soil, plant, and water resources of a catchment and the process of creating and implementing plans, programs, and projects aimed at their conservation and sustainable exploitation. Some objectives of watershed management are the protection of drinking water sources from environmental pollutants, limiting the supply of fertilizers from agricultural lands, mitigating the risk of flooding, and restoring riparian vegetation [
1,
2,
3,
4,
5]. A very influential report by FAO describes the experiences from different watershed management projects conducted in several countries [
6].
Figure 1,
Figure 2 and
Figure 3 show some examples of rivers and riparian vegetation in Galicia, their wild fauna, and threats to which they are subjected.
Remotely sensed imagery has the potential to assist watershed management. Vegetation studies in river basins have traditionally been carried out through in-situ surveys, but there is the problem that they require a large amount of work and there are also areas that are difficult to access. The use of imaging systems, whether from satellites or airplanes, facilitate the study of large areas of land [
7]. However, remote sensing techniques, when applied to watersheds, present some difficulties [
8]. Riparian vegetation is difficult to distinguish because of its dense distribution and similar spectral and textural characteristics of different species.
The spectral characteristics of the wetlands and riparian vegetation are determined by the composition of the plant communities, the meteorology, and the hydrological regime, which exhibit significant variability in the different locations and throughout the year. The confusion between the different cover classes can be exacerbated by the presence of topographic shadows, which are often mistaken for dark flooded surfaces. In addition, the canopy cover of coniferous forests can hide small wetlands and transition zones when viewed from above. Furthermore, the variable light and climatic conditions make it impossible to apply an automated process in a uniform way [
9]. These problems are aggravated by the small percentage of the areas occupied by wetlands and riparian vegetation in the landscape, which makes the application of classification algorithms difficult due to the existence of more abundant land cover classes.
Unmanned aerial vehicles (UAV) are an efficient and low-cost method for the characterization of vegetation over large areas [
10,
11]. An example of UAV is shown in
Figure 4. The miniaturization of high-quality sensors, such as multispectral and hyperspectral imaging systems, and the application of advanced processing algorithms makes it possible to minimize the difficulties listed above [
12]. Some remote sensing methods using multispectral and hyperspectral imagery have been applied to river basin characterization on a large scale. In [
13] ground-based data in conjunction with low-altitude UAV imagery was used to assess vegetation and ground cover characteristics in central Oregon, USA. Reflectance characteristics from multispectral imagery (RGB, near infrared, and red-edge wavelengths), several vegetation indices (including NDVI) and SVM supervised classification were used to estimate the canopy cover and to identify different vegetation species at the watershed.
A procedure to map riparian vegetation in the middle Rio Grande River, New Mexico, was presented in [
14]. Airborne multispectral digital images and an iterative supervised classification procedure were used in that study. At each iteration, the existing signature set was used to classify the image using a maximum likelihood scheme. In [
15] a classification of riparian forest species and their health condition using multi-temporal hyperspatial and light detection and ranging (LiDAR) imagery from UAVs was carried out. Different spectral, vegetation, and texture indices were used, in conjunction with a multiscale segmentation and a random-forest classifier. For its part, [
16] shows how a detailed riparian vegetation mapping can be used to prioritize conservation and restoration sites around the San Rafael River, a desert river in south-eastern Utah, United States. They use multispectral satellite imagery and oblique aerial photography, in conjunction with multi-resolution image segmentation and classification rules based on object properties such as spectral reflectance, shape, size, and neighborhood relations.
Since the spectral characteristics of the different species of vegetation in the riparian zones are very similar, and also present large individual variability, techniques based on textures have been developed. Textures can be defined as the pattern of microstructures (coarseness, contrast, directionality, line-likeness, regularity, and roughness) that characterizes the image [
17]. Different papers focused on the classification of vegetation species using texture features in color, multi or hyperspectral imagery can be found in the literature. The simplest methods to characterize vegetation using textures are based on color histograms, statistical measures (mean, standard deviation, skewness, kurtosis, entropy, etc.) [
18,
19]. Two simple methods for texture extraction, based on the analysis of patterns in the neighborhood of a pixel, are local binary pattern (LBP) and gray-level co-occurrence matrix (GLCM) [
20,
21].
More elaborate texture methods based on local invariant descriptors, such as speeded-Up robust features (SURF) and scale-invariant feature transform (SIFT), can also be used for characterizing vegetation species [
22,
23]. A classification chain based on textures may be combined with other types of features obtained by UAVs to improve the classification results. Among them are spectral features, vegetation indices, and morphological measures [
18,
24]. In [
25] different techniques for vegetation classification in multi and hyperspectral images based on texture extraction and bag of words (BoW) are compared. The techniques are structured into three groups: codebook-based, descriptor-based, and spectrally enhanced descriptor-based groups. Finally, convolutional neural networks (CNN) can also be used to classify vegetation exploiting textures, although their computational complexity and execution times are much higher [
26,
27].
The main objective of this work is to monitor the river basins of Galicia, Spain, using five-band multispectral images taken by UAVs and appropriate image processing algorithms, in order to replace in-site surveys, which require an enormous amount of time and effort. The software solution presented consists of a supervised classification chain based on spatial-spectral characteristics and texture descriptors at superpixel level. Since the study is carried out on a large scale, the selected algorithms are fast and various strategies are used to reduce execution times. A previous version of this work was presented in [
28].
The rest of the article is organized into four sections.
Section 2 presents the methods used in this study, including the description of the proposed classification chain involving superpixel computation and texture extraction. The experimental results for the evaluation in terms of classification performance and computational cost are presented in
Section 3. Then, the discussion is carried out in
Section 4. Finally,
Section 5 summarizes the main conclusions.
2. Materials and Methods
In this section we present the methods and procedures used for the monitorization of the river basins in Galicia.
2.1. Study Area
Galicia is a region in the north-west of Spain with Atlantic climate, mild temperatures and abundant rain most of the year, although summers can have low rainfall [
29]. A map with the main rivers of this region is shown in
Figure 5. In Galicia, riverside forests cover an area of 25,000 hectares with a great diversity of arboreal, shrub, and herbaceous species distributed as follows [
30]:
According to the level of water required by the trees, as observed in the cross section in
Figure 6, several bands of land can be distinguished. In the first line, closer to the river, alders (
Alnus glutinosa) and willows (
Salix atrocinerea) can be found; followed by birch trees (
Betula pendula and
B. pubescens), hazelnuts (
Corylus avellana), ash trees (
Fraxinus angustifolia, and
F. excelsior) and white maples (
Acer pseudoplatanus); and further away from the river there are laurels (
Laurus nobilis), oaks (
Quercus robur), and elms (
Ulmus minor);
As for shrubs, there are species such as the black elderberry (Sambucus nigra) and the crawfish (Frangula alnus); climbing plants, among which ivy (Hedera helix), the honeysuckle (Lonicera periclymenun), dulcamara or devil’s grapes (Solanum dulcamara), and hops (Humulus lupulus); as well as thorny rosaceae, mainly blackberries (Rubus fruticosus);
As for herbaceous plants, there are sedges, grasses, and reeds; ferns, mainly the royal fern (Osmunda regalis); and other vascular plants such as devil’s turnips (Oenanthe crocata), cattails (Typha latifolia), yellow lilies (Iris pseudacorus), loosestrife or puffins (Lythrum salicaria), daffodils (Narcissus cyclamineus), and spearmint (Mentha aquatica) can be found.
The natural environment of the river banks in Galicia has undergone a profound transformation due to the intense anthropic pressure that it has historically endured. The alluvial plains that originally housed phreatophyte forests have been transformed into cultivated areas and meadows and, subsequently, into pine or eucalyptus plantations.
Figure 7 shows photographs of tree species typical of the riparian zones of Galicia and the invasive species pine and eucalyptus.
Pines, mainly Pinus pinaster, but also P. sylvestris, and P. pinea, are native species of the Atlantic region, but they are not typical tree species of river banks. Pines have been used for reforestation in places where they did not grow naturally for the use of wood. They replaced native oak or chestnut forests that were being cut down, and currently these conifers occupy 30% of the Galician forest area.
Eucalyptus globulus is an invasive tree in Galicia, which, due to its high expansive capacity, replaces autonomous species. It currently occupies a 20% of the Galician forest area and threatens the Atlantic forest. Eucalyptus on river banks eliminate native vegetation and change the load of leaves in rivers, providing material that is more difficult to decompose. Consequently, rivers in which there is a greater presence of eucalyptus will have a lower quality of organic matter, reducing the abundance and diversity of detritivore organisms. In addition, eucalyptus trees change the seasonality of the ecosystem, since most of their leaves fall in summer in a way that is not synchronized with the communities that feed on this matter. Eucalyptus also burns fast and easily, which favors forest fires and causes erosion and deterioration of the land. Additionally, the trend of global climate change towards drier environments could aggravate this problem, since fast-growing trees such as eucalyptus or pines consume much more water than native species. Therefore, eucalyptus trees reduce the diversity and life of river banks and increase the risk of rivers drying out in summer.
2.2. Objectives
The overall objective of this study is the classification of the vegetation in the Galician hydrographic basins, as well as the detection of natural and artificial elements up to a maximum distance of 100 m from the river. This study is part of a broader project of integrated water management in order to optimize water resources in Galicia, while preserving the balance of the natural environment and river ecosystems, respecting the achievement of the environmental objectives established for the water bodies and attending to the new scenarios determined by climate change [
4]. Specifically, the aim is to easily monitor the status of Galician hydrographic basins and detect alterations, such as new constructions, felling of trees, or eucalyptus plantations and crops that could have been planted illegally. Specifically, two sub-objectives are considered:
Detection of natural or artificial obstacles in its proximity that may modify the river bed and constructions (roads, paths, and other constructions) that may damage the ecosystem;
Characterization of the areas covered by vegetation, in particular distinguishing between native and invasive tree species.
The identification will be carried out over five-band multispectral (RGB, red-edge, and infrared) images obtained by a UAV. The spectral characteristics of the different elements as captured by this sensor are shown in
Figure 8. Specifically, the following 10 classes are considered:
Natural elements: water, bare soil, and rocks;
Artificial elements: asphalt, concrete, and tiles;
Vegetation types: meadows, native trees, pines, and eucalyptus.
This class selection was made taking into account the elements present in the hydrographic basins of Galicia, as well as those that are of interest for watershed management. For example, the class “soil”, in addition to identifying rural roads, can be used to detect deforestation. In Galicia, houses usually have roofs covered with reddish tiles or made of fiber cement. The class “concrete” is used to detect this second type of roof, as well as the rest of the constructions, which are usually made of concrete. The class “asphalt” represents the roads. Regarding the types of vegetation, four classes have been selected in order to distinguish the native species from the invasive ones.
Since the multispectral signatures for the different vegetation types are very similar, the proposed method is based on the extraction of texture information from the images. Moreover, native trees have similar canopies and, hence, similar texture features, which are however different from the canopies of pines and eucalyptus. Therefore, the use of texture methods allows us to distinguish native trees from pines and eucalyptus. Fast algorithms have been selected for classifying large areas of land.
2.3. Classification Chain
The proposed classification process for monitoring riparian areas in Galicia is shown in
Figure 9. It is a supervised classification procedure that requires training from samples (pixels) in which the type of material or vegetation is known. The output is a color classification map that assigns to each pixel a class label from the 10 available. The proposed classification chain includes four modules: superpixel computation, texture codebook generation, texture feature encoding, and classification.
2.3.1. Superpixel Computation
Superpixel algorithms divide the image into approximately similarly sized segments, whose shape is adapted to the characteristics of the image. In this way, sets of pixels of uniform content called superpixels are obtained. The shape regularity of the superpixels or their adaptation to the structures of the image can be adjusted usually by means of a parameter. Superpixels can be used both as an initial simplification stage in classification operations and for the detection of objects and structures. Different superpixel algorithms have been proposed, such as ETPS, seeds, ERS, QS, LSC, etc. [
31]. Algorithms for generating superpixels can be broadly categorized as either graph-based or gradient ascent methods.
Graph-based algorithms tend to be slower than those of the second category (complexity
) or higher, where
N is the number of pixels of the image), and frequently they do not offer an explicit control over the number of superpixels or their compactness [
32]. Regarding the gradient ascent algorithms, SLIC [
32] and waterpixels [
33] are among the fastest ones. In both algorithms all operations are local (limited to the neighborhood of the superpixel), consisting of the calculation of distances in the case of SLIC or comparisons and propagation of labels in the case of waterpixels. Despite their simplicity, SLIC and waterpixels adhere well to boundaries and allow easy control of segment size and compactness. Both algorithms will be considered for the proposed classification chain. Examples of the segmentation maps obtained are shown in
Figure 10.
2.3.2. Texture Codebook Generation
The objective of this module is to generate a codebook with a set of basic elements or primitives (called textons) that can be used to represent any texture present in the images. The design principle is to obtain a compact and discriminative codebook that allows classifying the textures with precision [
26]. To obtain the dictionary elements, techniques ranging from predefined to learned ones and convolutional neural networks (CNN) can be used. Examples of techniques with predefined codebooks are LBP, GLCM, filter-based methods, and keypoint feature extractors (SURF, SIFT). On the other hand, two fast and efficient algorithms for generating a learned codebook are
kmeans clustering and Gaussian mixture modeling (GMM). Dictionary elements in
kmeans are the cluster centers while GMM uses both mean centers and covariances to describe the spreads of the clusters. Additionally, GMM can capture overlapping distributions in the feature space. These two algorithms and CNNs will be considered for the proposed classification chain.
2.3.3. Texture Feature Encoding
Given the generated texture codebook and an image, feature encoding represents the image based on the codebook. It is a key component that decisively influences texture classification in terms of both accuracy and speed. Three efficient feature encoding methods that will be considered are bag of words (BoW), vector of locally aggregated descriptors (VLAD), and Fisher vectors (FV). BoW builds a histogram counting the number of local features assigned to each codeword and, therefore, encodes the zero order statistics of the distribution of local descriptors. VLAD accumulates the differences of local features assigned to each codeword. Finally, FV extends the BoW by encoding higher order statistics (first and second order), including information about the fitting error [
26]. The differences among the different methods is shown in
Figure 11. In the present study, the texture information will be used to distinguish the different elements present in each superpixel. In
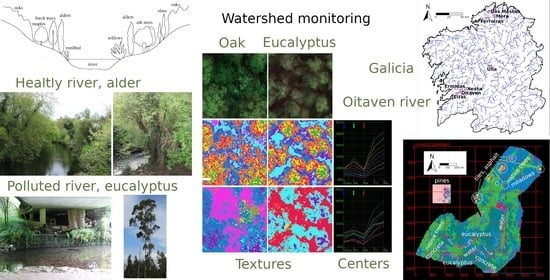
Figure 12, textures corresponding to oaks, pines, and eucalyptus are shown. They present observable differences in terms of their canopy structures.
2.3.4. Classification
Once the spatial or texture features have been obtained, the final operation is classification. Three supervised classification algorithms are widely used, since they are fast and provide good results: SVM, KELM, and random forest. In the proposed classification chain, the classification is performed at superpixel level, that is, each superpixel provides a single input sample to the classifier, which can be the average of the pixels in the segment or the texture feature. As reference values for the superpixels used in training, the class of the central pixel of each segment is taken. A hierarchical scheme of three classifiers is used, since the separation between plant species is especially complicated due to their very similar spectra and individual variability. First, a separation is made into two classes: plant species and the rest. A second classifier then separates the different plant classes from each other. Finally, a third classifier performs the separation of the different non-plant classes. This is shown in detail in the diagram of
Figure 9.
2.4. Datasets
With the objective of monitoring the interaction of the masses of native vegetation with artificial structures and river beds, eight locations in Galicia were studied. They were selected based on the presence of native vegetation, eucalyptus, and pines. The native vegetation, that populates areas near the water streams due to its ability to survive under unstable water conditions, includes oaks, birches, alders, and willows. Different artificial structures are also present and are identified: rooftops covered by tiles, some concrete structures, asphalt roads, stone structures, and bare soil roads. These locations correspond to stretches of the rivers Oitaven, Xesta, Eiras, Ermidas, Ferreiras, Das Mestas, Mera, and Ulla, which are marked on the map of
Figure 5.
The datasets were captured by the MicaSense RedEdge multispectral camera mounted on a custom UAV. This sensor provides the blue (475 nm), green (560 nm), red (668 nm), red-edge (717 nm), and NIR (840 nm) channels. The flights were conducted during the summer months of 2018, 2019, and 2020, on sunny days around noon and early afternoon in order to minimize shadows. Each flight captured data over long distances at a height of 120 m, with a spatial resolution of 10 cm/pixel. Each dataset was built as the orthomosaic of the frames captured by the UAV, each of which is of size pixels.
The usual registration, geometric and light corrections operations were carried out. Specifically, the radiometric calibration of the sensor was carried out using the calibration panel and the irradiance sensor available in the camera. Subsequently, the images were processed with the Pix4D software. The option that allows irradiance information to be included at the time of capture was selected for correction. This software was also used to create the flight plan, carry out geometric corrections and generate the orthomosaic. As an example,
Figure 13 shows the route followed by the UAV over the Oitaven river. The left part of
Figure 14 displays a color composition of the datasets obtained.
The construction of accurate reference data was a long-term process, involving forestry experts and the authors of the paper. Information from vegetation inventories, field visits, and the expertise of the forestry experts, along with the analysis of canopy textures, were the main elements considered in producing the reference data. The reference maps for the rivers Oitaven, Xesta, Eiras, Ermidas, Ferreiras, Das Mestas, Mera, and Ulla can be seen in the right part of
Figure 14. The characteristics of the eight datasets are detailed in
Table 1.
3. Results
This section contains information about the experimental conditions, parameter selection, and classification results obtained. The experiments were carried out on a low-end PC with a dual-core Intel Pentium G3220 at 3.00 GHz and 8 GB of RAM. The code was written in C and compiled using gcc under Ubuntu 20.04. CNN code was compiled in CUDA and executed on a NVidia GeForce GTX 1050 GPU with 2 GB of memory.
Classification results in terms of overall accuracy (OA), average accuracy (AA), and execution times are presented. In all experiments, 15% training superpixels are used, as shown in the fifth column of
Table 1. For each of the superpixels used in training only one reference value is used. In the test stage, the classifier provides a class per superpixel, and this class is assigned to all the pixels of the superpixel. Those pixels used during training are excluded in the accuracy calculation. The proposed classification chain was run on the eight datasets, classifying superpixels of riparian tree crowns and artificial and natural elements into 10 classes.
3.1. Algorithm Comparison
The aim of the first set of experiments is to analyze how the different algorithms influence the classification accuracies and the execution times.
Table 2 shows the results of the available alternatives for each module using the Oitaven dataset with 15% of training superpixels. The best accuracy results were obtained for the WP, GMM, FV, and KELM algorithms, which are considered the base chain. The rest of the measurements were taken substituting the indicated algorithm in the base chain.
For the superpixel computation module the algorithm that provides the best results in terms of classification accuracy is waterpixels followed by SLIC, both with similar execution times. In both cases, the algorithms have been configured to provide segments with a side length of 20 pixels. However, the sizes provided by the algorithms are approximate, since the assignment of pixels to superpixels depends on the structures of the image. Besides, the SLIC algorithm contains a disconnected region correction stage, while watershed tends to over-segment. To avoid these problems, both algorithms include a segment aggregation stage that requires the superpixels to contain a minimum of 100 pixels. In our experiments, the precision results provided by waterpixels were better than those of SLIC, due to the fact that, in the former, the segments effectively generated were closer to the requested size. Alternatively, other superpixel algorithms, such as ETPS, could be used in this module, but they have a higher computational complexity, which is a problem given the large size of the images used.
Regarding the texture codebook generation module, the best results were obtained by the GMM clustering algorithm, followed by kmeans. GMM builds the codebook from the pixel values using Gaussian distributions that take the mean and deviation as parameters, while in kmeans the codebook is generated, taking into account only the cluster centers. Therefore, kmeans only considers spherical clusters, while GMM can be adjusted to elliptic clusters. Another implication of its covariance structure is that GMM allows a point to belong to each cluster to a different degree, while in kmeans a point belongs to one and only one cluster. For the row “none” in the table, no codebook was generated, so for the characterization of the segments in the next module, the averages of the values of the segment pixels contained within a median absolute deviation (MAD) were used.
In any case, for the construction of the codebook, it is not necessary to use all the pixels of the dataset, which would take excessive computation time. It is enough to consider a representative set of pixels that captures the variation present in the dataset. For GMM a subset of 10,000 pixels was used, while for kmeans 100,000 pixels were necessary to obtain similar results. This is the reason why kmeans took a longer execution time than GMM. In general, the higher the number of clusters, the higher the classification precision, but the execution time also increases. In our case, 80 clusters were computed for both algorithms.
Regarding the texture feature encoding module, five algorithms were considered: MAD, BoW kmeans, BoW GMM, VLAD, and FV. The simplest algorithm is MAD, which calculates the average of the pixels within each superpixel. On the other hand, the algorithm that provided the best results was FV, followed by VLAD. On the contrary, the worst results were provided by the two versions of BoW. BoW counts the number of local features assigned to each codeword (zero order statistics of the distribution), while VLAD accumulates the differences of local features assigned to each codeword (first order statistics) and FV encodes the first and second order statistics. Encoding a larger amount of information increases the accuracy of the classification, but it also increases the execution time. Thus, the fastest algorithm is MAD, while the slowest algorithms are those based on GMM, that is, BoW GMM, and FV. None of these texture feature encoding algorithms require the setting of any relevant parameter.
Finally, for the classification module four algorithms were tested: SVM, KELM, random forest, and CNN. The best results were provided by KELM and SVM. These two classifiers are kernel-type algorithms that map the data to a larger feature space. In our experiments, an RBF kernel with and was used for both classifiers. On the other hand, the final classification accuracies obtained by random forest were slightly worse. For its part, CNN does not require the texture generation and encoding modules, but due to its computational requirements the execution was carried out on a GPU. In our case, the CNN is composed of a convolutional layer and two directly connected layers. For the convolutional layer, five filters of size , max-pooling of factor 2 and sigmoid activation function were used, while the directly connected hidden layer contains 100 neurons and sigmoid activation functions. The precision values obtained by the CNN were not remarkable since this type of algorithms require a fairly large training set to provide good results. Regarding the execution times, the best values were obtained by SVM followed by random forest.
3.2. Classification Performance
In the next experiments, the proposed classification chain was run on the eight datasets. Three types of algorithm chains were considered: faster algorithms, those with the best classification accuracies, and a deep-learning one. The fastest chain is made up of the SLIC + MAD + SVM algorithms, the chain with better accuracy is WP + FV + 3KELM (the
notation refers to using a hierarchy of three classifiers, as shown in
Figure 9, otherwise only one classifier is used), while the deep-learning chain consists of WP + CNN.
Table 3 shows the classification accuracies and execution times obtained for each chain. In all experiments, 15% of training superpixels were used in each dataset. The average accuracies for the eight datasets were AA = 87.79 and OA = 66.68 for the fastest chain, AA = 92.65 and OA = 80.39 for the most accurate chain, and AA = 89.67 and OA = 73.45 for the CNN chain. The AA values obtained are lower than those of OA, because some classes contain a very small number of labeled segments, resulting in lower accuracy results. Regarding execution times, the average values were
,
, and
s, for the corresponding three chains. It should be noted that the very long execution time of 2312 s obtained for the Mera dataset (the largest one) was due to the fact that the computer RAM was not enough for the execution of the program and the swap memory in the SSD unit had to be used.
Finally,
Table 4 shows disaggregated data for three of the datasets with the best accuracy chain (WP + FV + 3KELM). It shows the accuracy results, as well as the number of superpixels used for each one of the 10 classes. In general, the accuracies obtained for all the classes are similar, except for those in which very few training superpixels are available. These small classes also make the AA values lower than the OA ones.
Once the classification maps are obtained, colors assigned to superpixels allow the identification of the different elements in the river basin. In our case, the objective is the detection of constructions (buildings, roads, paths, etc.) in the proximity of the river, as well as the characterization of the areas covered by vegetation, in particular distinguishing between native and invasive tree species. Some examples are illustrated in
Figure 15, where the areas covered by artificial elements and the different types of vegetation are easily identifiable.
4. Discussion
Accurate regional-scale maps of wetlands and riparian areas are essential for targeting conservation and monitoring efforts. UAV technology provides a fast and cost-effective method for forest cover assessment and species classification [
10,
11]. It also allows detecting situations that threaten the ecosystem, such as altered flow regime, fish passage barriers, habitat loss, and non-native vegetation. For the processing of the captured images, depending on the conditions and requirements of the study, different methods and algorithms have been developed.
In some case studies, when high resolution images are available, the use of traditional indices, such as NDVI and others may be sufficient [
12]. In other cases, the analysis of the spectral ranges can produce a subdivision in cover classes that allows distinguishing specific tree species [
13]. If a classification at the pixel level is not enough, spectral-spatial techniques can be applied [
34]. In other studies, the canopy height model, which provides an estimation of dendrometric and structural features of the vegetation can be useful [
15,
24].
The approach presented in this paper has the advantage of ease of implementation and low cost, since medium-sized UAVs and multispectral sensors can be used. The algorithms used have been selected for their favorable relationship between precision, computational resource consumption, and execution time. Given the type of sensor, the path followed by the UAV and the fact that the vegetation is dense and compact, which makes it difficult to delimit individual trees, it has not been possible to use the canopy height model. On the other hand, the spectral ranges of the different tree species are very similar and largely overlap. In small scenarios, these issues could be sufficiently compensated with very high resolution, but this is hardly applicable to large areas.
Taking these limitations into account, a classification based on textures has been used in this study. Although the canopy structure of the different native species (alders, willows, birches, oaks, etc.) is very similar, they are easily distinguishable from pines and eucalyptus. This facilitates the identification of the areas occupied by these invasive species. It was necessary to carry out field visits to identify the tree species and build the reference maps.
For the detection of objects and structures in images, different algorithms based on textures have been proposed in the literature. These range from the most basic ones that use very simple features [
18] to the most advanced ones based on BoW, keypoints, or CNNs [
25,
26]. LBP and GLCM [
35] are two simple methods for texture extraction that use information from the neighborhood of a pixel. They are also very fast methods, since they do not require the codebook generation stage. However, in these algorithms the extraction is carried out in predetermined locations, so they are only suitable for detecting objects whose textures have regular patterns. In our case, the vegetation contains very irregular texture patterns and the precision results obtained with these two methods have been low. More advanced methods for the extraction of information in the neighborhood of a pixel are based on the detection of keypoints and the construction of invariant descriptors, among which SURF and SIFT stand out [
22]. However, the construction of the descriptors is a costly process which must be done in multiple positions within each superpixel. In this study we have evaluated several BoW-based methods, including VLAD and FV for the characterization of vegetation.
For the classification of an image using textures it is necessary to delimit regions on which the texture features are computed. This is usually done using patches, segments, or objects, often through multi-resolution techniques [
15]. The procedure used in this study is based on the generation of superpixels. Among the many superpixel algorithms that have been proposed in the literature, we have evaluated SLIC and WP, which provide very good results with short computation times.
Another advantage of our method is that, due to the limited resources it requires, it should be applicable to larger areas than those considered in this work. As we have indicated, the selected superpixel algorithms require only local operations, so they are easily scalable. As for the texture codebook generation stage, it only requires a set of pixels that captures the variability of the dataset, so it displays a low dependence on the dataset size. The same happens with the training stage in the classification. Finally, texture feature encoding and testing stages can be performed independently for each of the superpixels.
The method could be adapted to other regions in which the monitoring of the interaction between the natural environment and human activities is required. Specifically, it would be applicable to the detection of invasive species, felling of trees, new constructions, or crops in other ecosystems. One of the advantages of the method is that it separates the detection of the vegetation from the rest of the natural and artificial elements present on the ground. In the case of the latter, their detection does not usually pose a problem, since they usually present quite different spectral signatures and textures. For the selection of the vegetation classes, the patterns of their textures should be taken into account so that their separation is feasible, considering the type of sensor and the spatial resolution used.
If the amount of computational resources is not a problem, it should be noted that some parameters could be adjusted to improve accuracy or speed, but not both at the same time. Among them are the number of centers in
k-means and GMM, and the number of trees in random forest. Regarding the superpixel generation stage, other algorithms could be used. For example ETPS, which in many cases generates superpixels with better adhesion. For the texture stage, methods based on the detection of keypoints and the construction of descriptors could be considered. Finally, if powerful GPUs are available, deeper neural networks could also be used for texture extraction. Additionally, to increase precision, spatial processing algorithms could be included, such as extended morphological or attribute profiles [
36], performing a fusion with the texture branch. However, these algorithms based on morphological operations or attributes greatly increase the processing time and the required storage space.
Since one of the limitations of this study is the low spectral resolution of the multispectral sensor, which limits the identification of vegetation species, the use of a hyperspectral sensor on board the UAV should improve the results. However, the use of hyperspectral imagery has the disadvantage of significantly increasing the size of the datasets, which for large areas of land implies huge storage spaces and longer execution times [
37].
In relation to the detection of the river course in the images, it must be taken into account that often the vegetation in the riparian zones of Galicia completely hides the river when viewed from above. Additionally, in summer, some parts of the river dry up and leave rocks or bare soil uncovered. In such cases, the river channel appears fragmented. To solve this issue, algorithms for the repair of partial occlusions in topographic data could be added [
38].
5. Conclusions
In this article a method based on UAVs and multispectral images for monitoring watershed areas in Galicia, Spain, was presented. It was designed with the specific aim of identifying areas occupied by invasive tree species, as well as detect man-made structures that occupy the river basin. Since the different species of vegetation have a very similar spectra, a procedure based on advanced texture methods was used.
The extraction of spatial information is carried out from the original image through segmentation based on superpixels and textures. Segmentation generates homogeneous segments or superpixels in the image. On the other hand, for each superpixel, its texture is characterized by a feature encoding algorithm based on the content of each segment. This information is used in a hierarchical classification structure to initially separate the artificial and natural structures from the plant species. Subsequently, the different types of structures and the different plant species are classified separately.
For the proposed classification chain, fast and efficient algorithms have been selected in order to process large areas of land. The output is a classification map where the areas covered by artificial elements and the different types of vegetation are easily identifiable. The experimental results over Galician riversides show that the proposed scheme is suitable for monitoring the natural environment in watershed ecosystems.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}