1. Introduction
Waldo Tobler’s first law of geography [
1] says, “everything is related to everything else, but near things are more related than distant things.” Satellite images are snapshots of the Earth’s surface. Therefore, semantic labels of these images are also in agreement with Waldo Tobler’s first law of geography. This means that near satellite images share some common latent patterns and distant satellite images are quite different from one another. For instance, as shown in
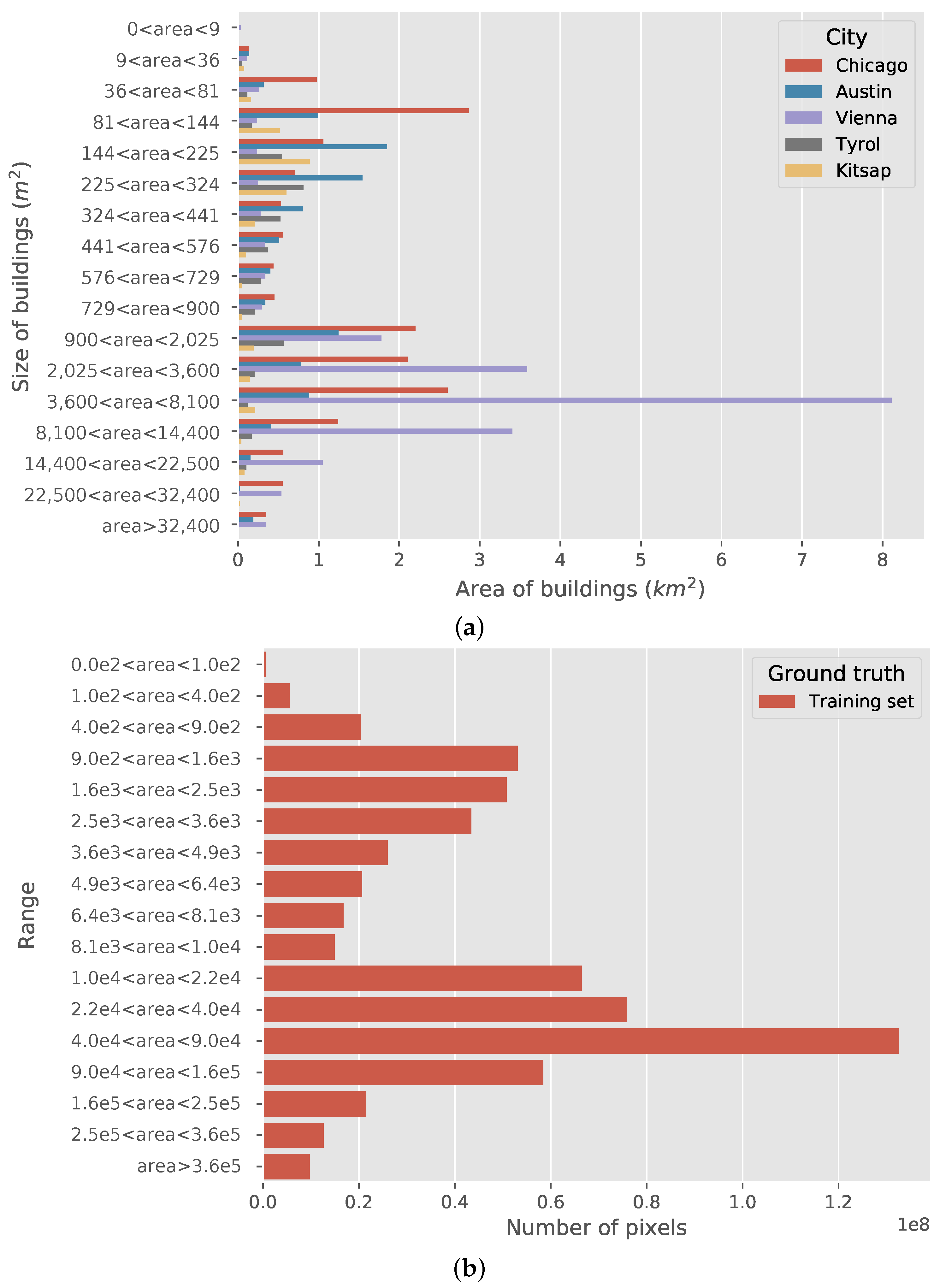
Figure 1a,b, buildings from different cities are diverse in terms of color, size, morphological structure and density. It can be seen from
Figure 2a that each city in this figure has its own regularity. However, this kind of geospatial distribution is difficult to describe and quantify using features from an image patch with a rather small size. Thus, in previous studies, parts of these patterns have been expressed as region-specific configurations or models [
2,
3,
4,
5]. Instead of manually building region-specific configurations, we resort to powerful DNNs to automatically learn the regional similarity and diversity of large-scale data from geographic coordinates. Geographic coordinates are one of the most notable characteristics of satellite images, which have been omitted in previous studies. To the best of our knowledge, this is the first attempt to map high-resolution satellite images on a large scale by modeling their geographic coordinates.
Geospatial information is often involved in the global mapping process of widely distributed satellite images. At global-scale mapping, the heterogeneity of the data makes it unfeasible to describe them using a uniform model. A common idea for handling this problem is to partition the entire world into several regions. Based on local similarities, an index-based method [
2] selects a region-specific threshold for each region. Similarly, classifier-based methods train a classifier for each area with region-specific parameters [
3,
4]. For the interactive method [
5], knowledge-based verification is attached to different areas after classification. Global low-resolution reference data can also be used as an indicator to overcome the heterogeneity in datasets [
7]. Weighting samples by frequency has been adopted to mitigate the class imbalance among different cities [
8]. All of these methods can enable the model to appropriately capture the regional pattern of the data, which is accomplished by using region-specific configurations based on experts’ experiences.
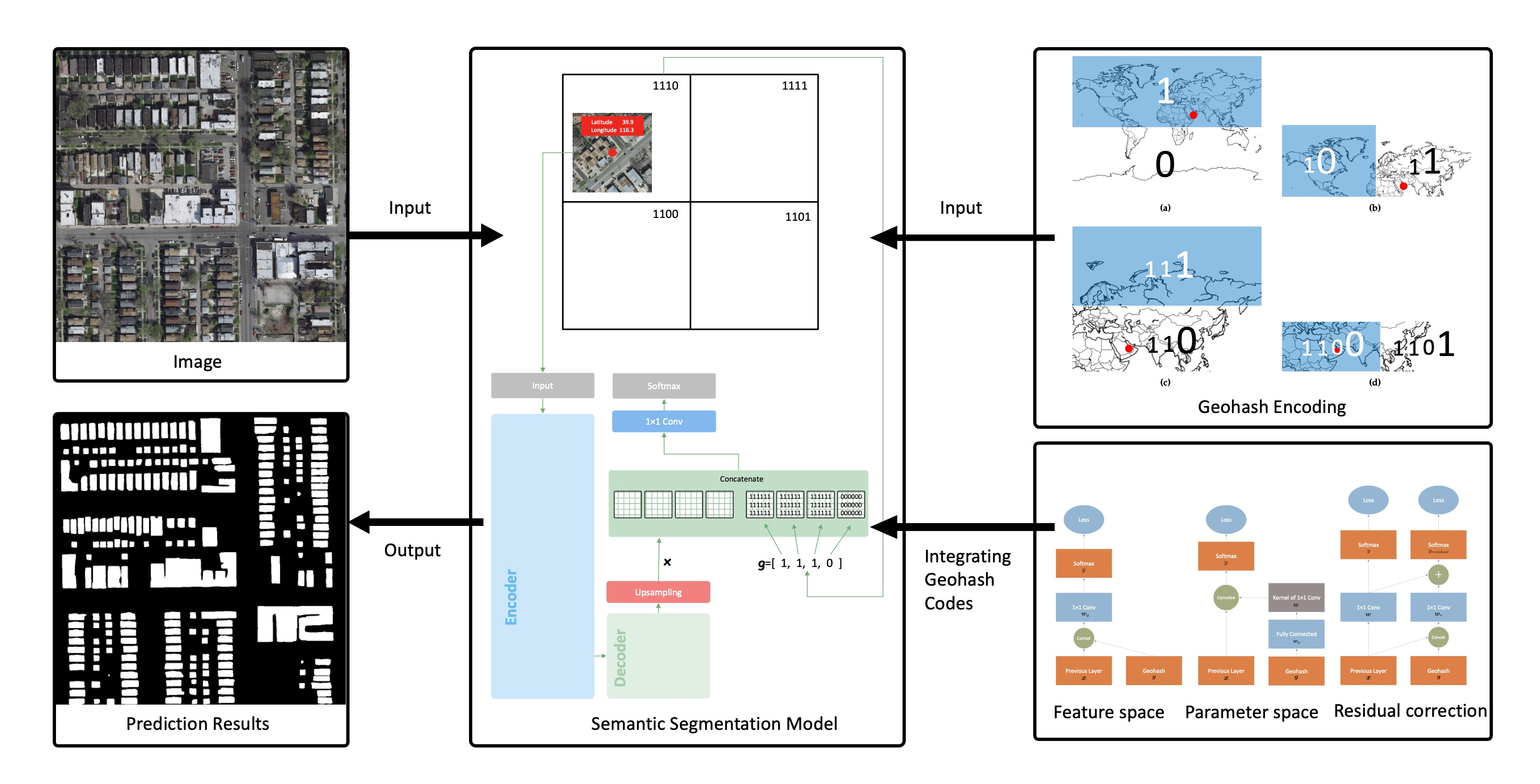
In this paper, rather than directly dividing the dataset into multiple groups, we aim to learn the regional characteristics using DNNs. This is accomplished by feeding DNNs with binary codes converted from the geographic coordinates of the images. The essential conversion builds on the idea of the geohash method [
9], which was invented for retrieving and locating image tiles [
7,
10,
11,
12,
13]. It should be noted that the geohash code is just a type of geographical coordinate. Readers should not confuse this term with the hash code used in cryptography. In cryptography, a hash function must satisfy the following requirements: uniformity property, uniqueness property, second pre-image resistance and collision resistance. The method called “geohash codes” in this paper does not satisfy these requirements, thus the “geohash codes” used in geography are quite different from hash codes used in cryptography. The closer two positions are, the more bits of geocodes they share. There are a few existing studies on using geospatial coordinates to improve the model performance of different applications [
14,
15,
16]. The GPS encoding feature [
14] converts geospatial coordinates into the code of grid cells, which is a special type of one-hot encoding in essence. It incorporates location features by adding a concatenate layer to boost the accuracy of image classification. Geolocation can also be a benefit for predicting dialect words via mixture density networks [
15]. The input features of the mixture density network are purely latitude and longitude coordinates without any other features, and the model output dialect words with given geospatial coordinates. Disaster assessment is another practical application scenario [
16]. It employs the pre-trained DNNs for the feature extraction of flooding images. Then these image features, along with the latitude and longitude coordinates, are used for training other machine learning models, such as random forest, logistic regression, multilayer perceptron and support vector machine. In this paper, the geocodes, generated by the geohash method, embed the spatial information into models to assist in the semantic segmentation. Essentially, the geohash method is a special type of binary space partitioning. It converts the decimal coordinates of longitude and latitude into binary numbers. Both decimal and binary numbers can represent an accurate position, but the binary geocode is more convenient for controlling the code length. With extra geospatial information, the geohash codes increase the distinguishability of the model. Regulating the length of the binary code can force certain areas to share the same geocode. Thus, adjusting the code length can keep the model from suffering from a risk of overfitting.
To validate the effectiveness of our proposed method, we apply it to the task of semantic segmentation using DNNs. Semantic segmentation with DNNs has produced remarkable results in recent years. Different from the conventional methods for image segmentation [
17,
18,
19,
20,
21,
22], DNNs can learn rich semantic features in an end-to-end manner, which requires large-scale data. However, the demand for large-scale data is not involved in conventional segmentation methods, but this also limits their generalization performance. Most of the conventional segmentation methods utilize low-level features to extract objects of images, while deep learning approaches build hierarchical semantic features with numerous layers. The use of a fully convolutional network (FCN) [
23] is the first work that trains convolutional neural networks (CNNs) for semantic segmentation in an end-to-end way. The input image of an FCN can be an arbitrary size, combining the feature maps at different resolutions via skip connections. A deconvolutional network [
24] is proposed to recover the original size of the input images. U-Net [
25] is an extension of the FCN, the upsampling parts of which are composed of deconvolutional layers. Dilated convolution [
26,
27] expands the receptive field of the convolutional layers and retains the high resolution of the feature maps. Atrous Spatial Pyramid Pooling (ASPP) [
28] captures multi-scale context information with various dilation rates. The Pyramid Scene Parsing Network (PSPNet) [
29] pools at various scales to better extract the global context information. These approaches have significantly improved the prediction results of semantic segmentation. There are plenty of previous works that focus on the semantic segmentation of high-resolution satellite images using DNNs, such as [
30,
31,
32,
33]. The datasets employed in these works virtually cover one or two cities [
30,
31]. When facing the challenge of covering more cities [
32,
33], the performance of the deep neural network fluctuates in different regions.
In most cases, the automatic extraction of a representation requires large-scale and widely distributed datasets. The prevalence of DNNs has resulted in the emergence of large-scale remote sensing datasets, such as AID [
34], NWPU-RESISC45 [
35], the ISPRS 2D Semantic Labeling Benchmark [
36] and DOTA [
37]. The sizes of these datasets are much larger than before, and their samples have been widely selected from around the world. Unfortunately, the rich information of the geospatial location is eliminated when building these datasets. Without attaching geographic coordinates, they are only treated as ordinary photos. As we focus on the semantic segmentation of high-resolution satellite images, the Inria Aerial Image dataset [
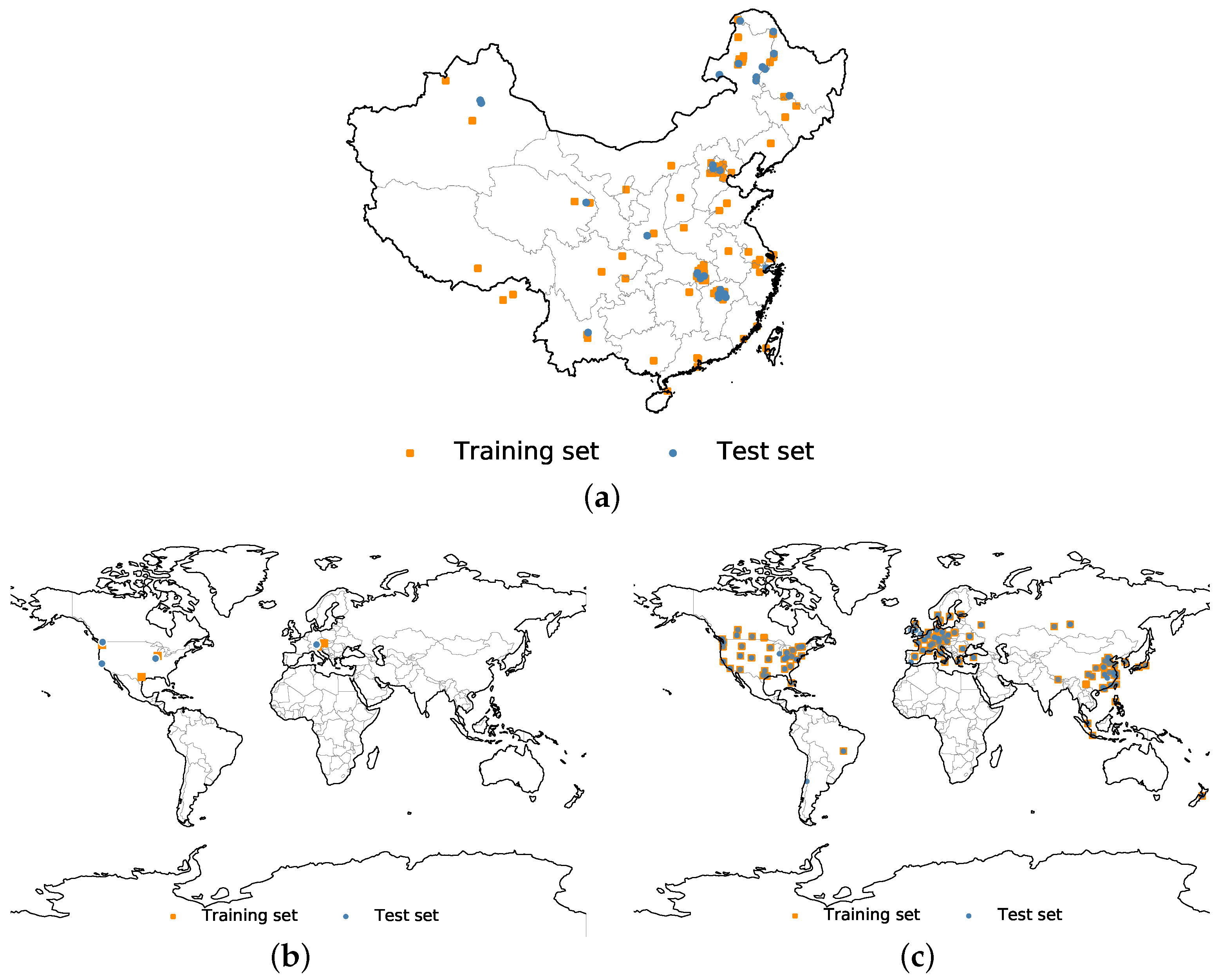
6] and the Gaofen Image Dataset (GID) [
38] are the only publicly available high-resolution datasets that retain the geographic coordinates for each image tile. These two datasets provide us with an opportunity to explore the influence of embedding geospatial information into DNNs. Additionally, we have built a worldwide dataset, called the Building dataset for Disaster Reduction and Emergence Management (DREAM-B), to further validate the proposed method.
Figure 3 shows the spatial distributions of the three datasets.
This paper is organized as follows:
Section 2 presents the key ideas of encoding geographic coordinates. In
Section 3, the experimental setup is described. We present the results of the experiments in
Section 4 and discuss them in
Section 5. Finally, conclusions are drawn in
Section 6.
6. Conclusions
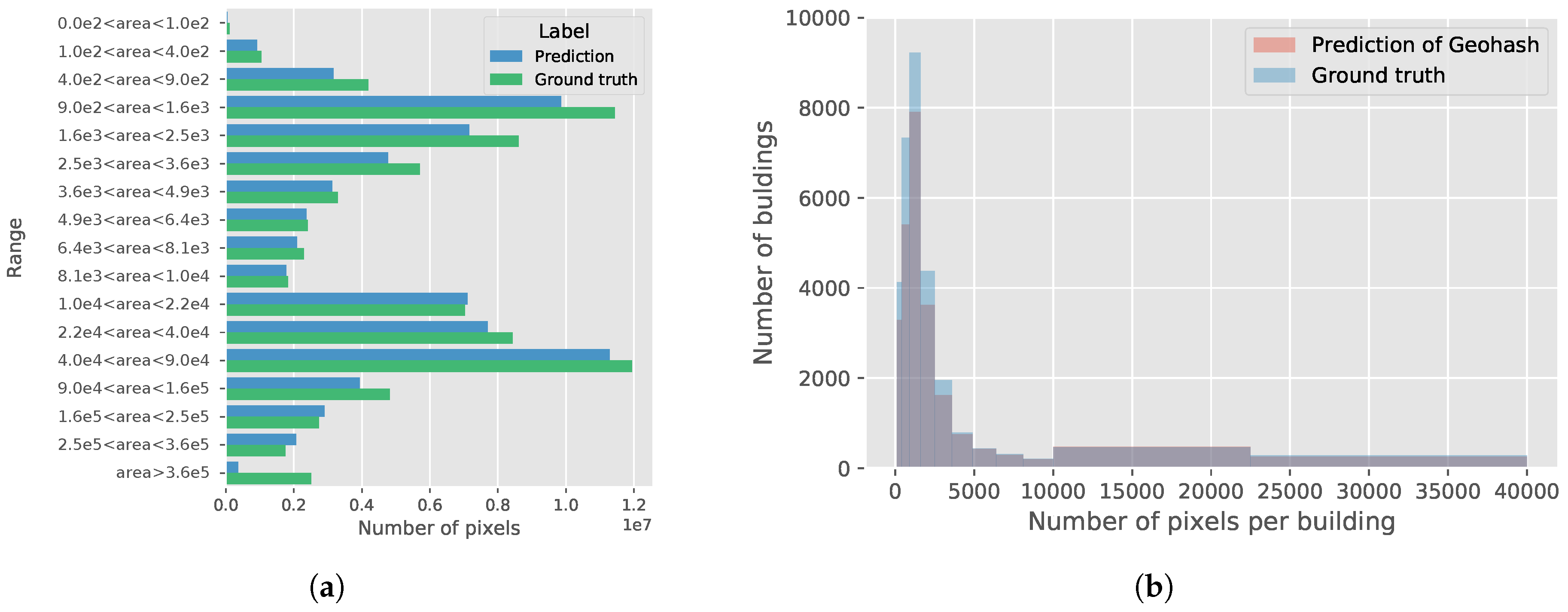
Satellite images have shown strong spatial patterns in a great many applications and datasets. Adapting the model according to the geospatial location of data is the missing part of the traditional deep learning approaches. In this paper, we studied the approach of integrating geospatial information into DNNs based on the geohash method. Specifically, a binary geohash code with bits of 0 and 1 was utilized in the proposed method. We conducted three strategies to combine the binary geohash code with the existing architectures of CNNs: feature space, parameter space, and residual correction. Experiments were conducted on three widely distributed datasets to investigate the best manner of using the geographic coordinates. The results for the experiments demonstrate that the simplest approach of treating the binary geohash code as an extra feature map is the most effective method. Additionally, the impact of the precision of the binary geohash code was analyzed in detail. All of these results demonstrate that the geospatial information has a non-negligible influence on the large-scale semantic segmentation of satellite images, and the proposed method can, to some extent, learn this type of geospatial information.
This paper is an attempt to utilize the spatial information of remote sensing data. Geospatial locations are regarded as part of the input data. Another possible way is to transform the spatial information into the component of the model rather than the component of the data, which has not been explored in this paper. In a larger sense, extracting knowledge from remote sensing data is not touched on in this research and is still a big challenge worth studying. Besides, the currently employed dataset contains only a few categories. In the future, we will investigate the different impacts of geospatial information on specific land-use classes using more datasets.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}