
Spatial-Aware Network for Hyperspectral Image Classification


Abstract
:1. Introduction
- This paper incorporates, for the first time in the literature, a side window filtering framework into deep architecture for HSI classification. We utilize SWF to effectively discover the spatial structure information in HSIs.
- This paper proposes an effective deep learning method. There are only a very small number of parameters that need to be determined. Thus, the proposed method can efficiently learn the spectral-spatial features by using a small number of training samples.
2. Methodology
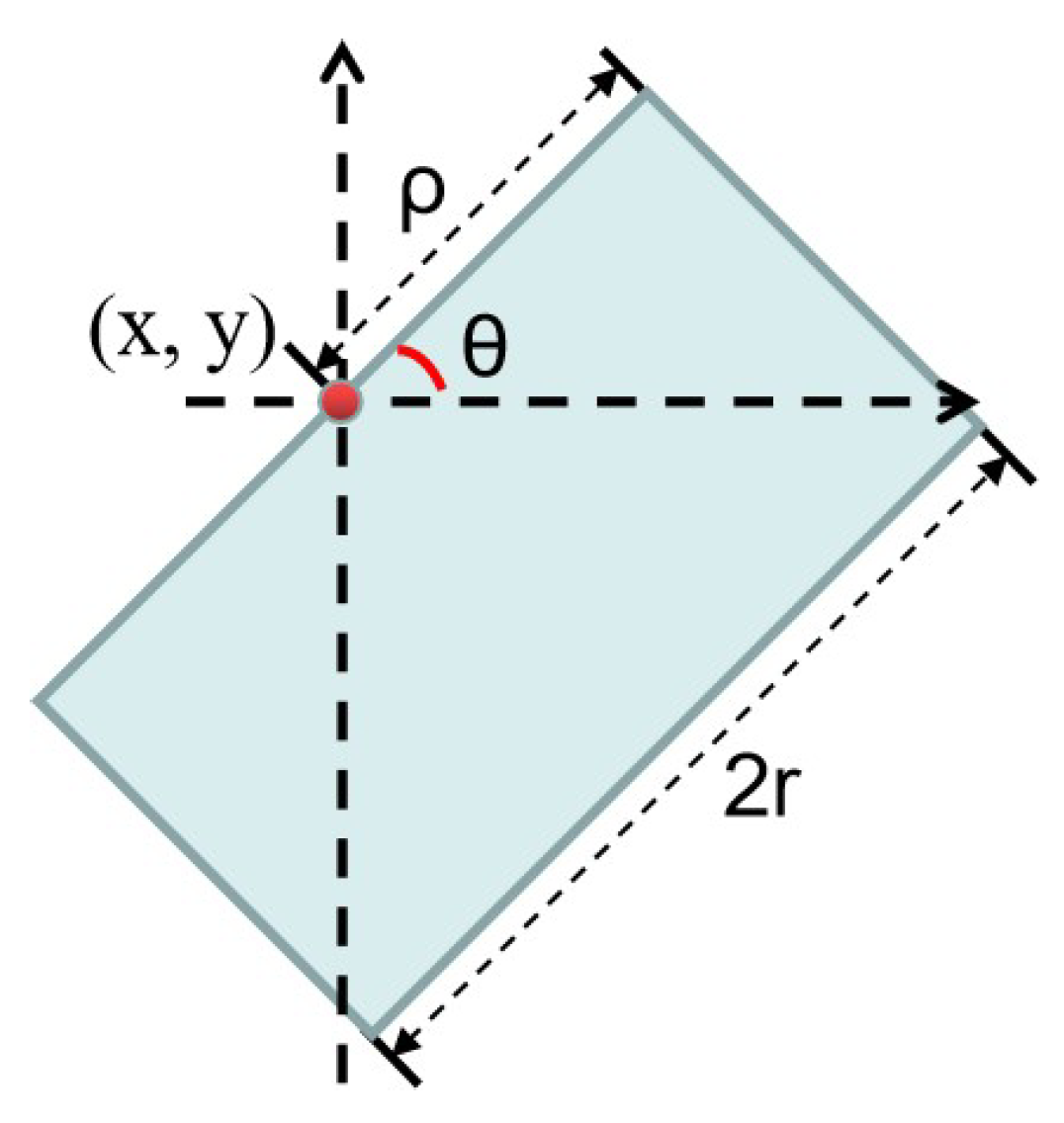
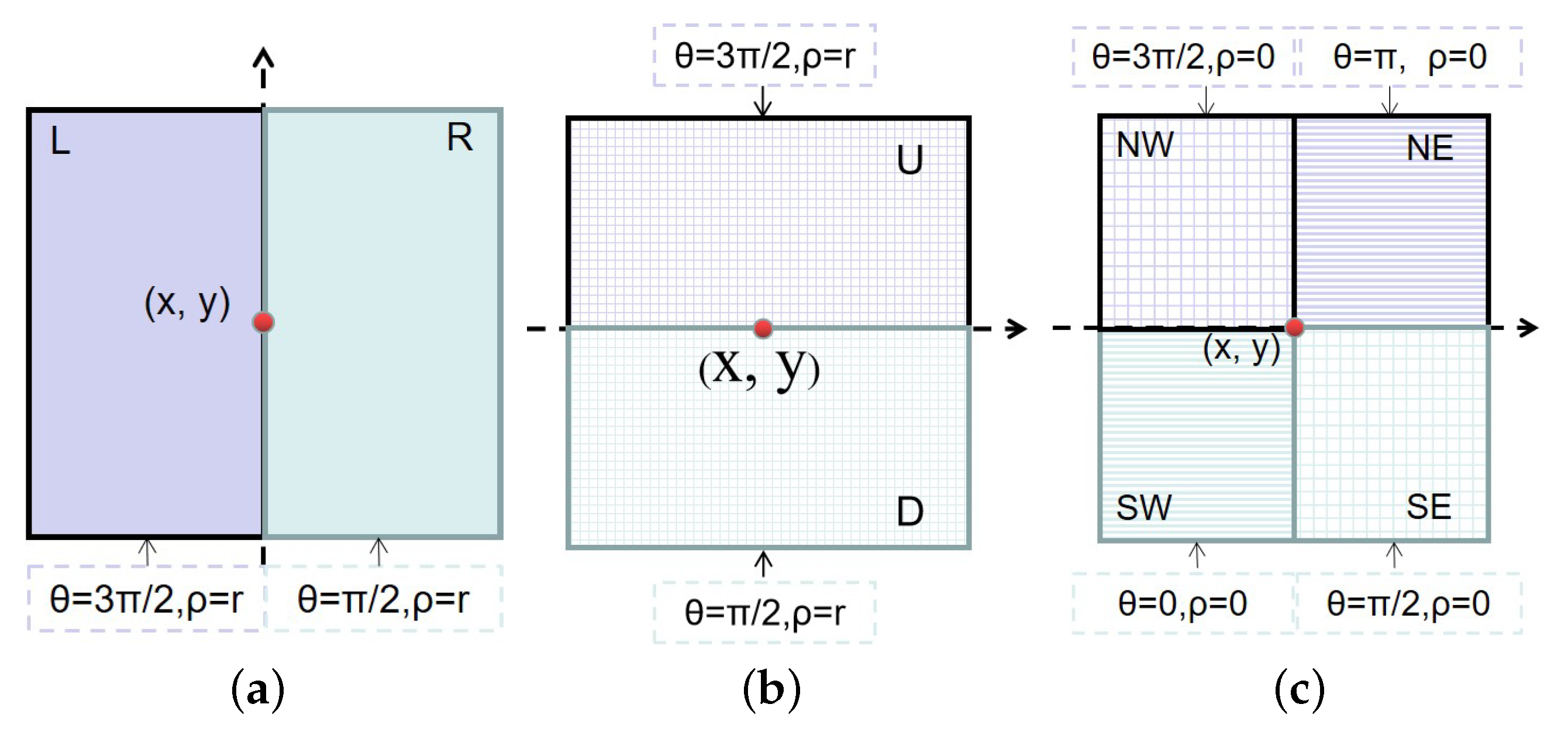
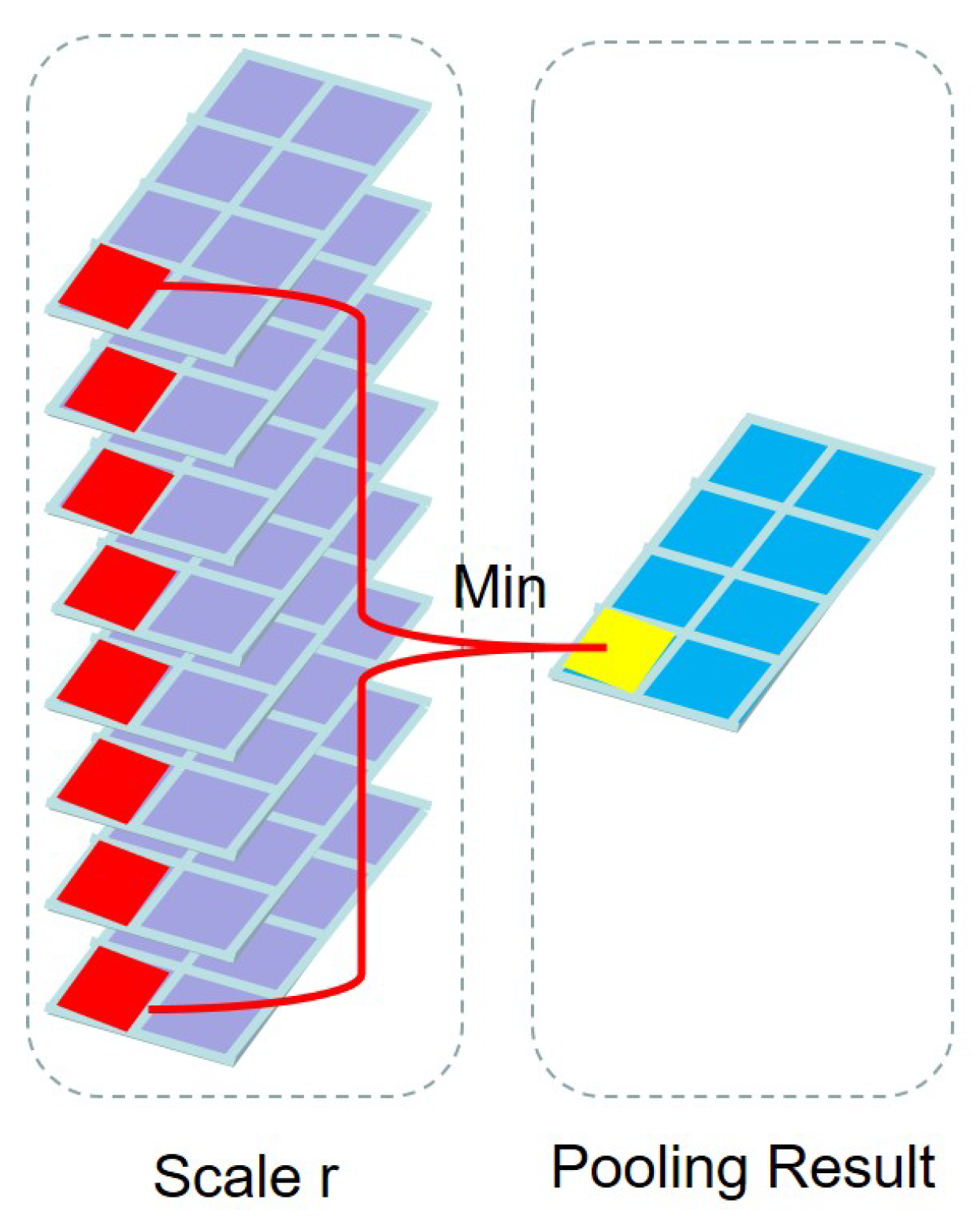
2.1. Spatial-Aware Network for Feature Learning
2.2. Classification Layer
| Algorithm 1 SANet |
| Require: , . Ensure: Predicted Labels.
|
3. Experimental Results and Analysis
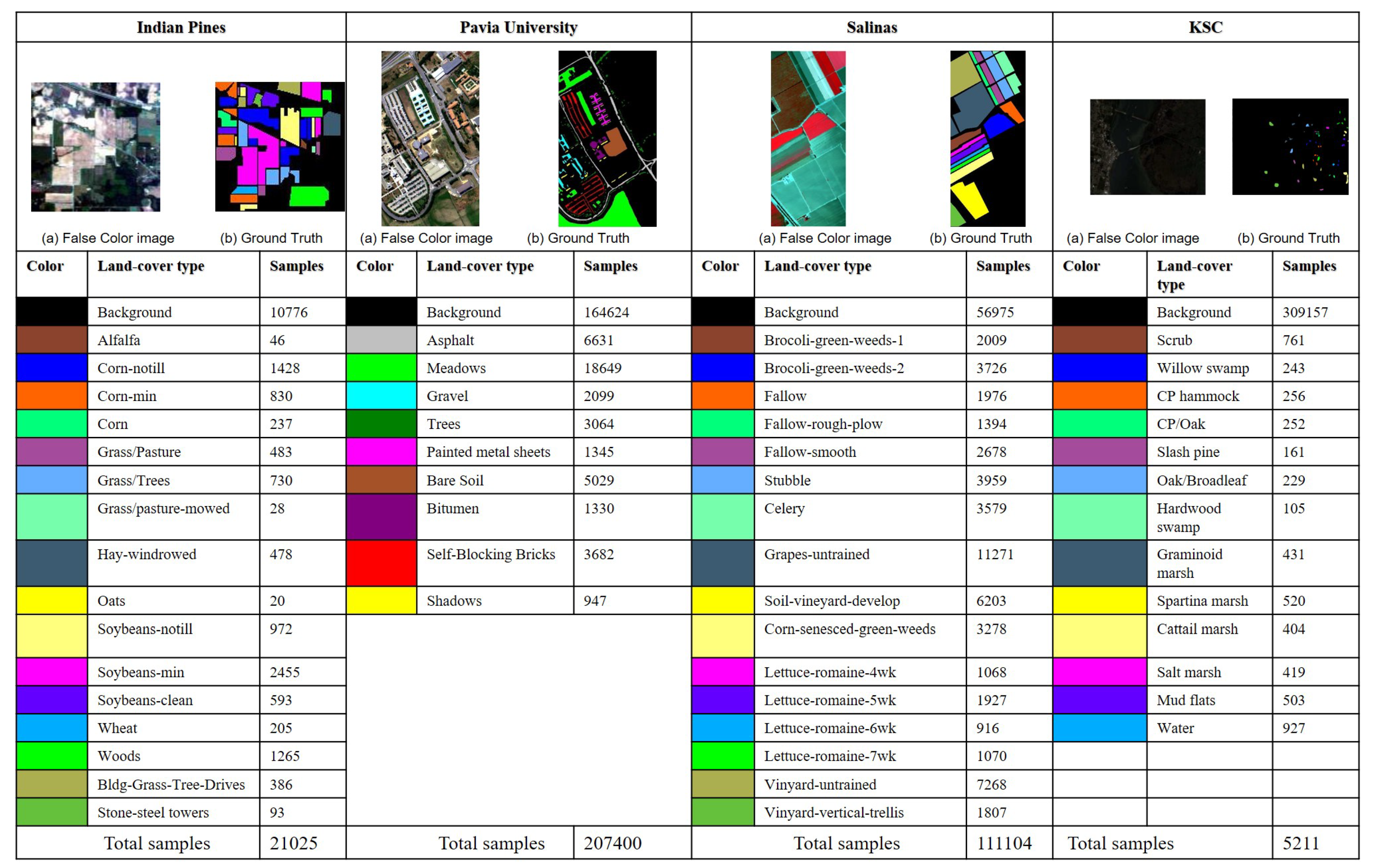
3.1. Data Sets
3.1.1. Indian Pines
3.1.2. Pavia University
3.1.3. Salinas
3.1.4. KSC
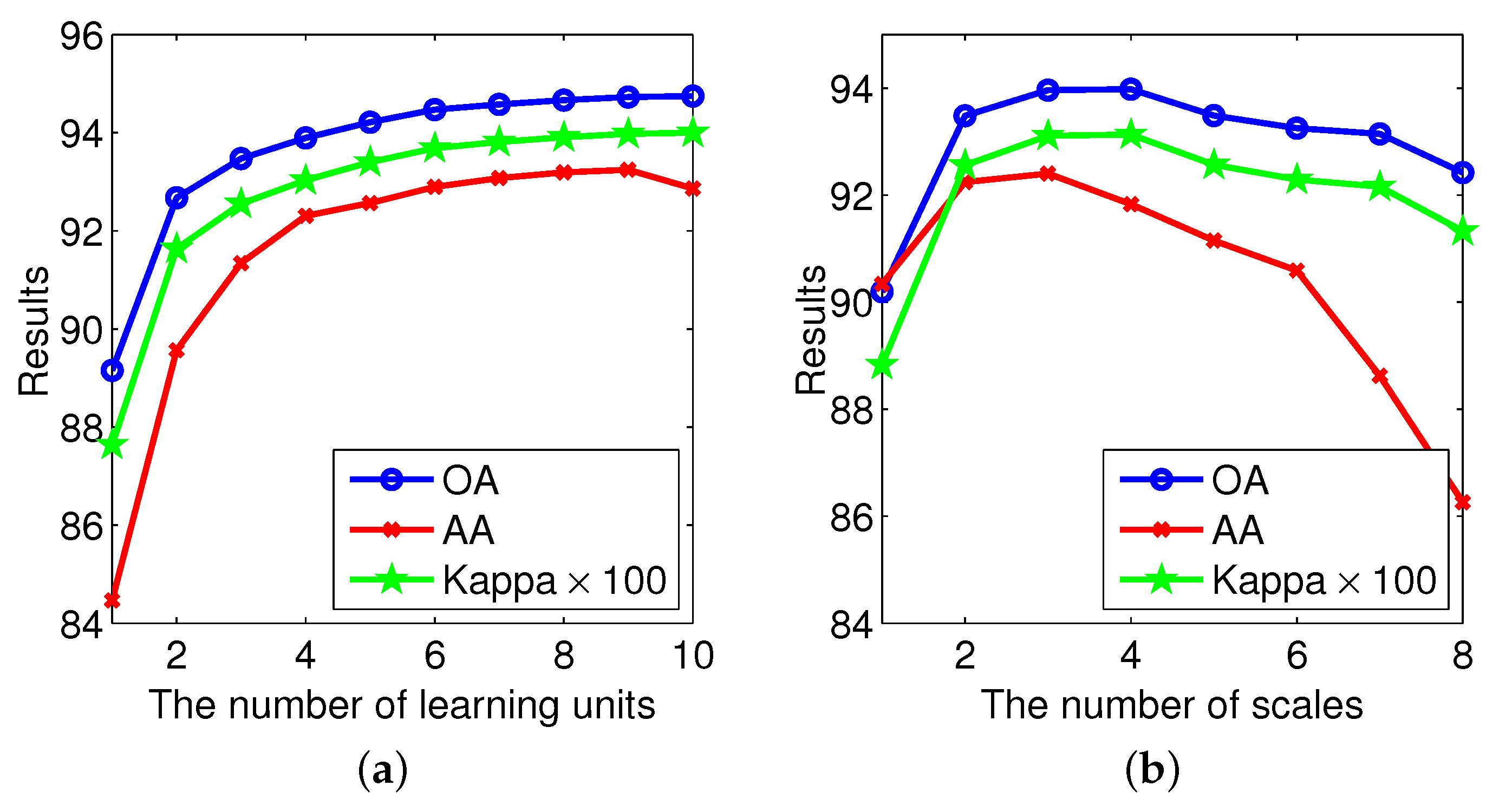
3.2. SANet Structure Analysis
3.2.1. Depth Effect
3.2.2. Scale Effect
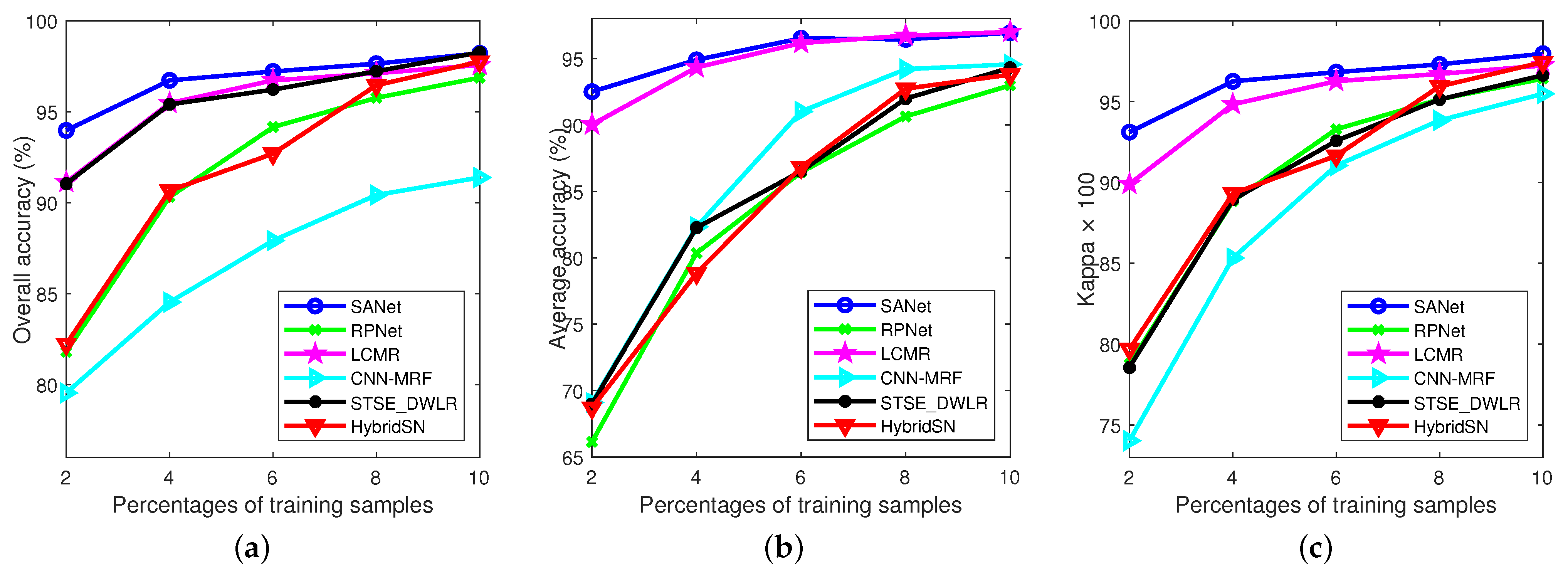
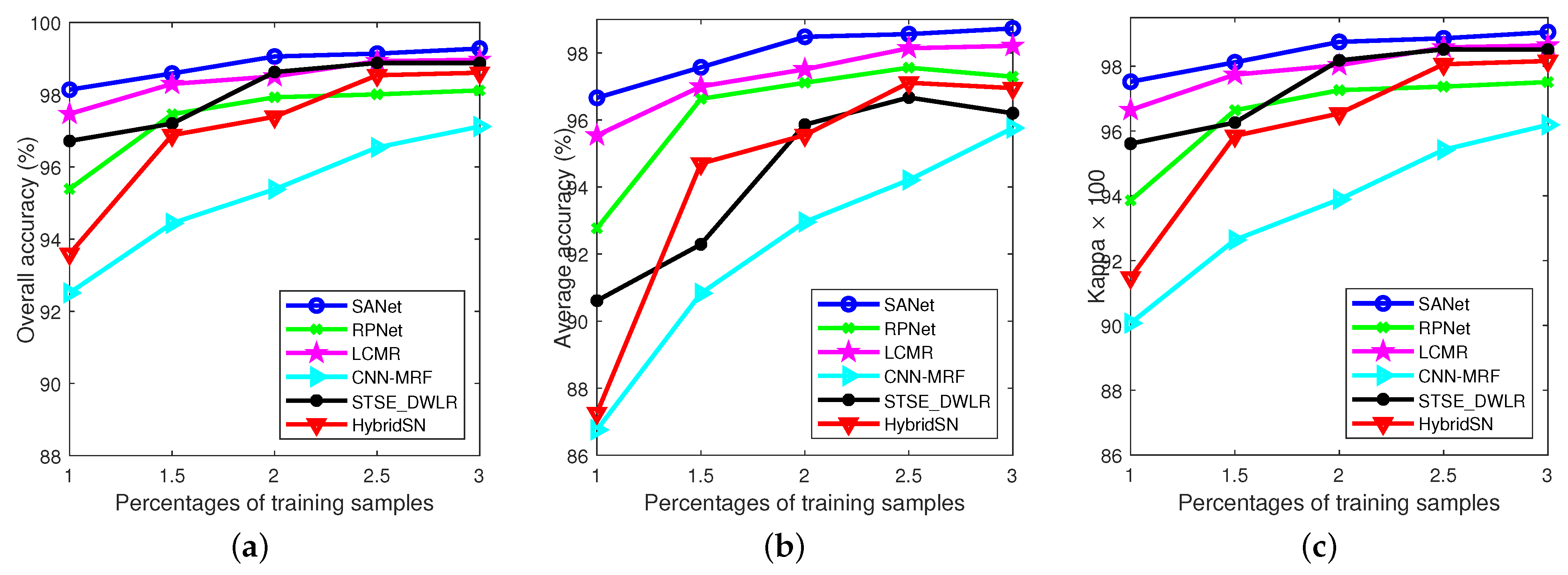
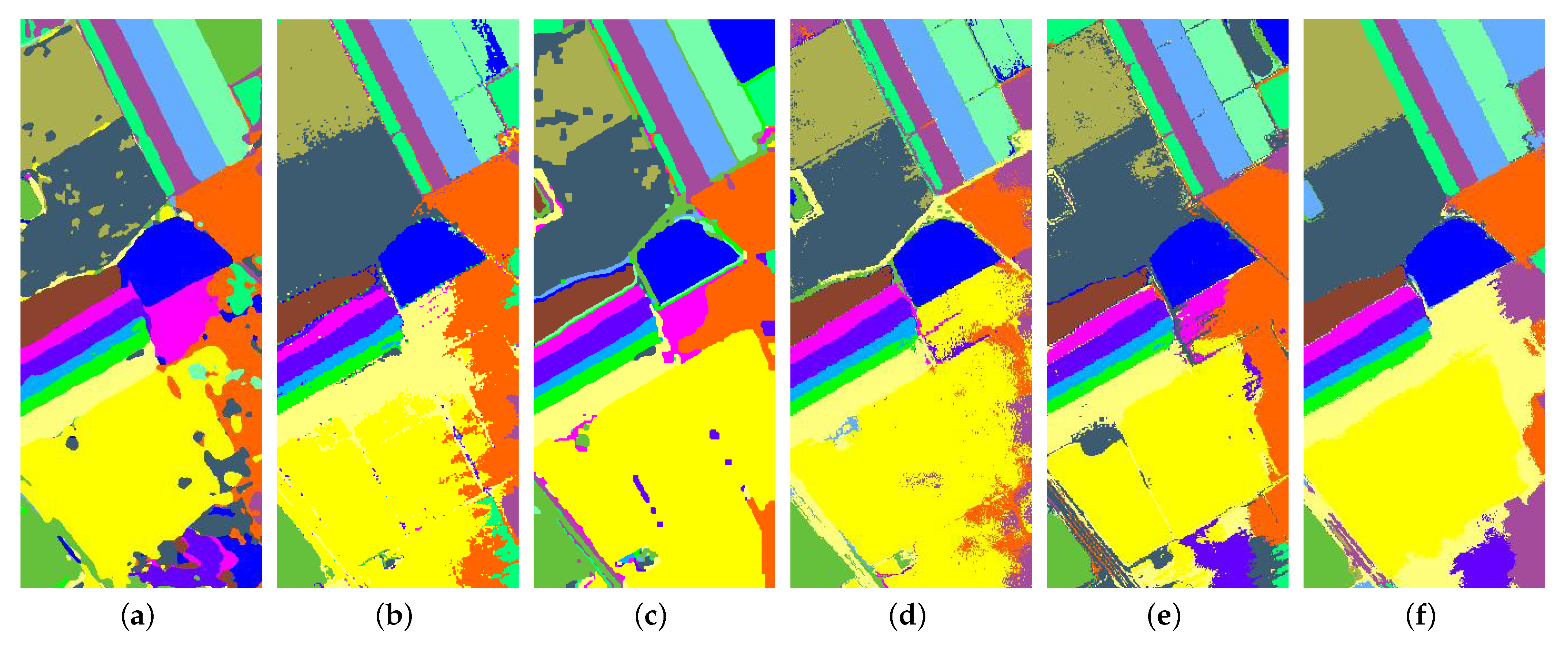
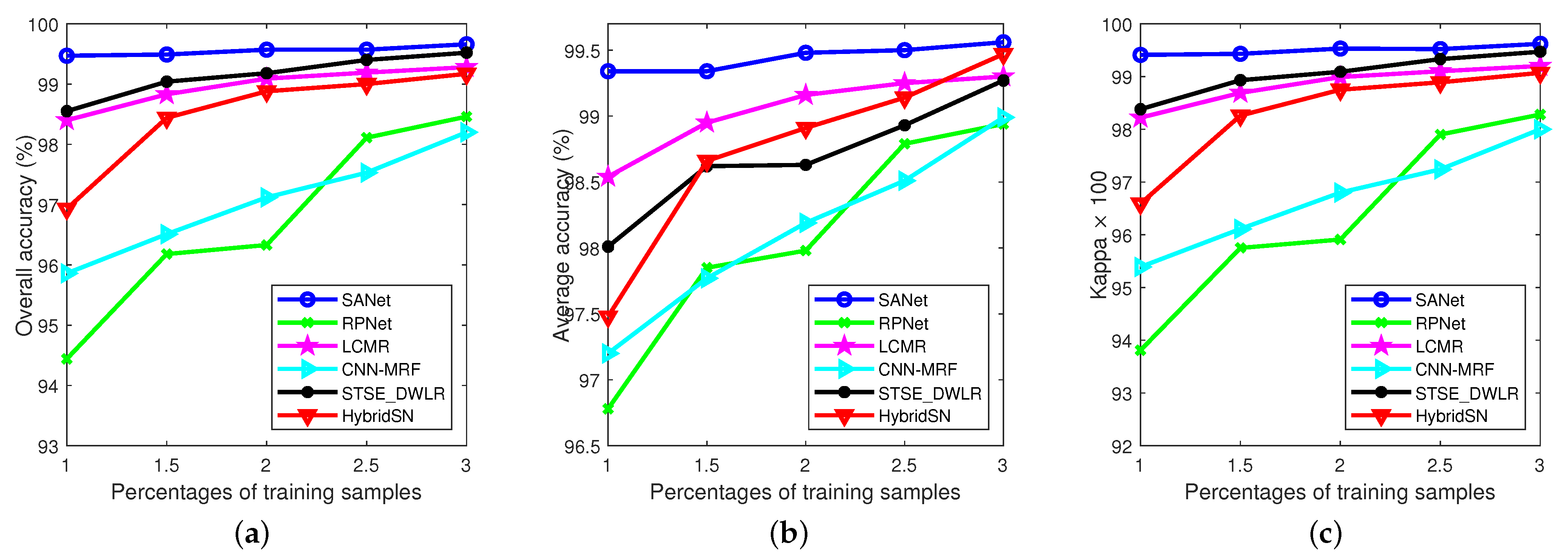
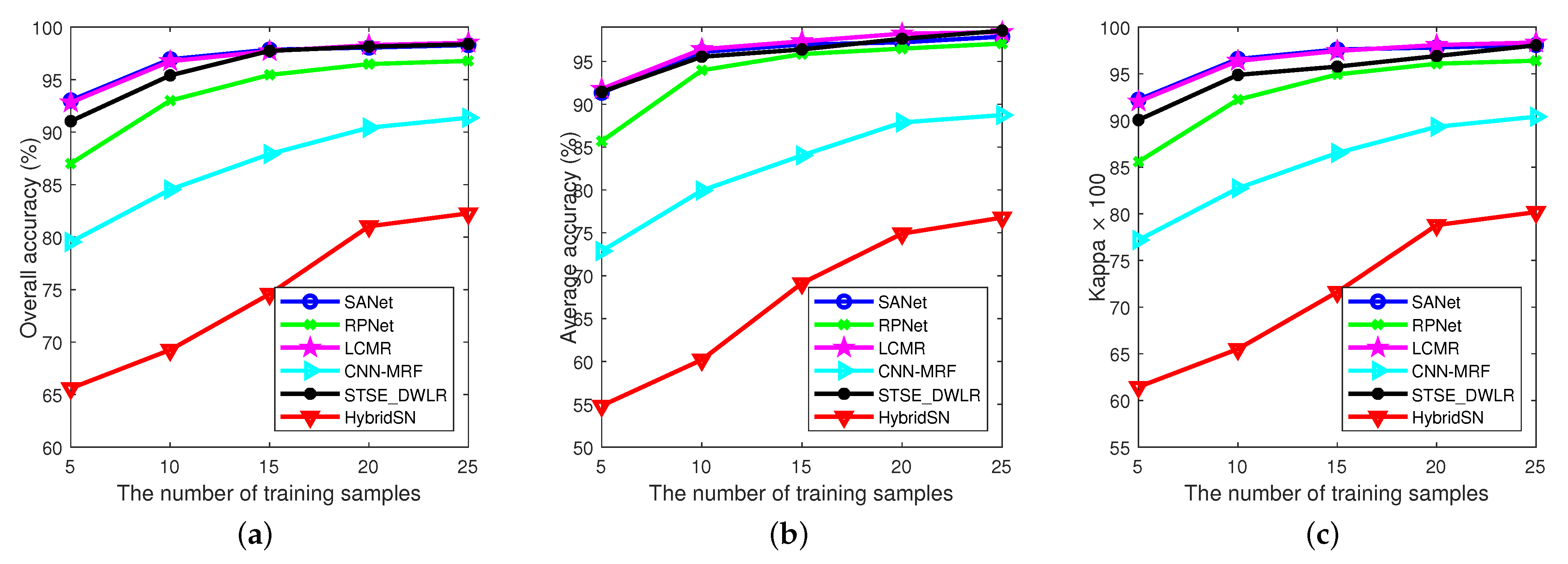
3.3. Comparison with State-of-the-Art Methods
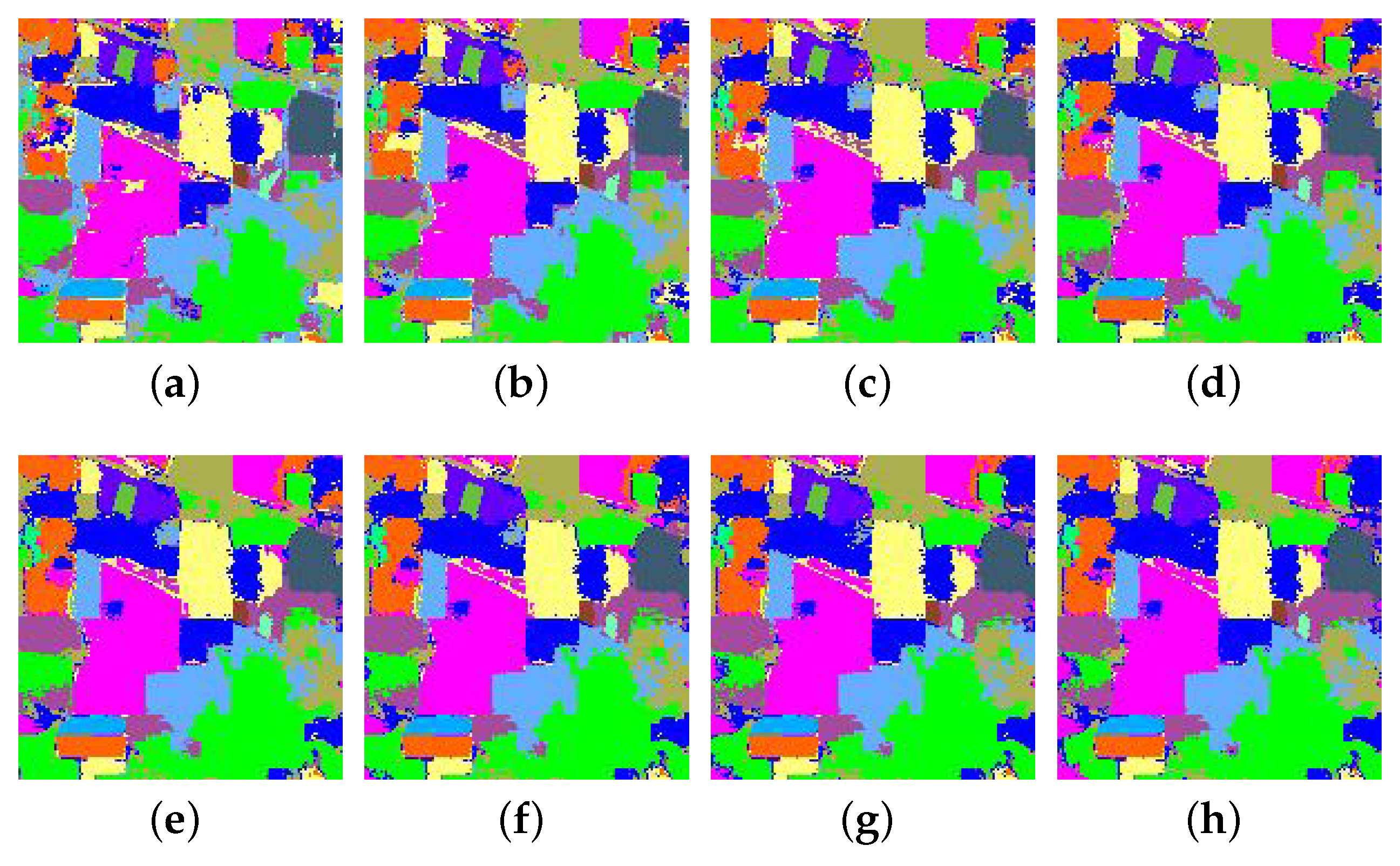
3.3.1. Experimental Results on Indian Pines Data Set
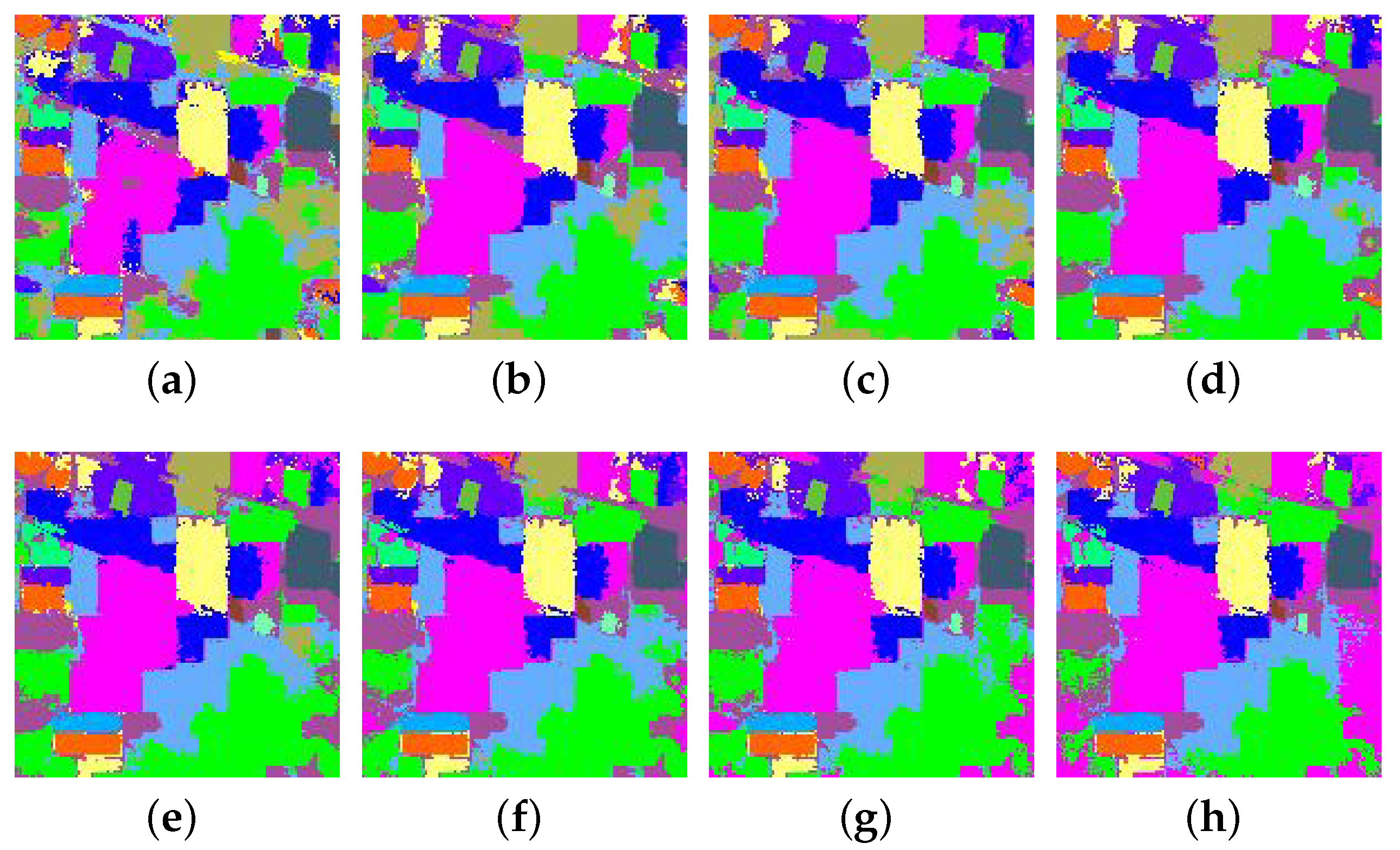
3.3.2. Experimental Results on Pavia University Data Set
3.3.3. Experimental Results on the Salinas Data Set
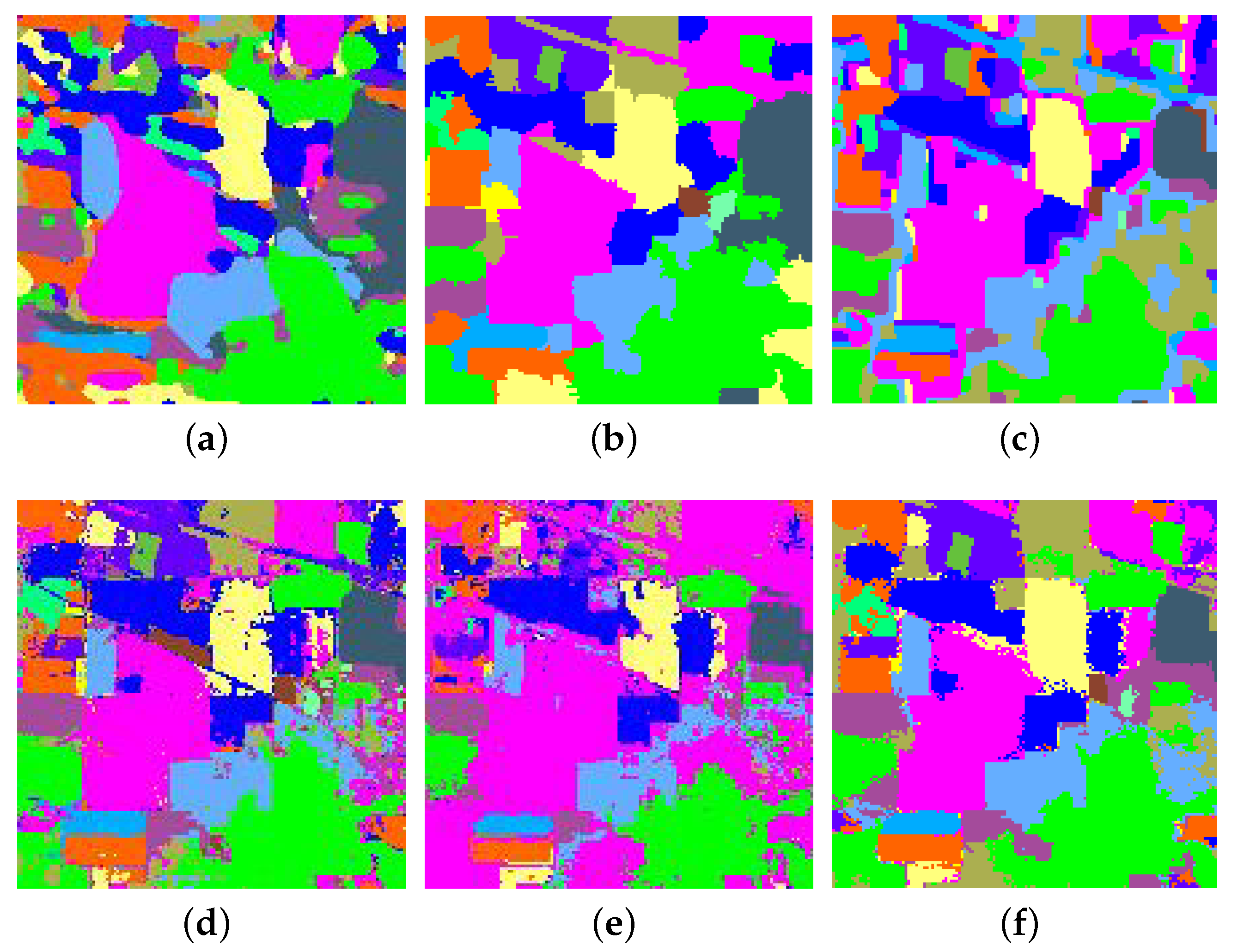
3.3.4. Experimental Results on the KSC Data Set
4. Conclusions and Future Research
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Wan, S.; Gong, C.; Zhong, P.; Du, B.; Zhang, L.; Yang, J. Multiscale dynamic graph convolutional network for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 3162–3177. [Google Scholar] [CrossRef] [Green Version]
- Zhang, L.; Zhang, L.; Du, B. Deep learning for remote sensing data: A technical tutorial on the state of the art. IEEE Geosci. Remote Sens. Mag. 2016, 4, 22–40. [Google Scholar] [CrossRef]
- Goetz, A.F. Three decades of hyperspectral remote sensing of the Earth: A personal view. Remote Sens. Environ. 2009, 113, S5–S16. [Google Scholar] [CrossRef]
- Li, S.; Song, W.; Fang, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Deep Learning for Hyperspectral Image Classification: An Overview. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6690–6709. [Google Scholar] [CrossRef] [Green Version]
- Bioucas-Dias, J.M.; Plaza, A.; Camps-Valls, G.; Scheunders, P.; Nasrabadi, N.; Chanussot, J. Hyperspectral remote sensing data analysis and future challenges. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–36. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Sun, Y.; Shang, K.; Zhang, L.; Wang, S. Crop classification based on feature band set construction and object-oriented approach using hyperspectral images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2016, 9, 4117–4128. [Google Scholar] [CrossRef]
- Uzkent, B.; Rangnekar, A.; Hoffman, M. Aerial vehicle tracking by adaptive fusion of hyperspectral likelihood maps. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 39–48. [Google Scholar]
- He, X.; Chen, Y.; Lin, Z. Spatial-Spectral Transformer for Hyperspectral Image Classification. Remote Sens. 2021, 13, 498. [Google Scholar] [CrossRef]
- Yang, W.; Peng, J.; Sun, W.; Du, Q. Log-Euclidean Kernel-Based Joint Sparse Representation for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 5023–5034. [Google Scholar] [CrossRef]
- Ma, Y.; Zhang, Y.; Mei, X.; Dai, X.; Ma, J. Multifeature-Based Discriminative Label Consistent K-SVD for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 4995–5008. [Google Scholar] [CrossRef]
- Signoroni, A.; Savardi, M.; Baronio, A.; Benini, S. Deep Learning Meets Hyperspectral Image Analysis: A Multidisciplinary Review. J. Imaging 2019, 5, 52. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Le Saux, B.; Lefèvre, S. Deep Learning for Classification of Hyperspectral Data: A Comparative Review. IEEE Geosci. Remote Sens. Mag. 2019, 7, 159–173. [Google Scholar] [CrossRef] [Green Version]
- Kang, X.; Zhuo, B.; Duan, P. Dual-path network-based hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2018, 16, 447–451. [Google Scholar] [CrossRef]
- Jia, S.; Deng, X.; Zhu, J.; Xu, M.; Zhou, J.; Jia, X. Collaborative representation-based multiscale superpixel fusion for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7770–7784. [Google Scholar] [CrossRef]
- Tu, B.; Wang, J.; Zhang, G.; Zhang, X.; He, W. Texture Pattern Separation for Hyperspectral Image Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2019, 12, 3602–3614. [Google Scholar] [CrossRef]
- Pan, B.; Shi, Z.; Xu, X. MugNet: Deep learning for hyperspectral image classification using limited samples. ISPRS J. Photogramm. Remote Sens. 2018, 145, 108–119. [Google Scholar] [CrossRef]
- Luo, F.; Zhang, L.; Du, B.; Zhang, L. Dimensionality reduction with enhanced hybrid-graph discriminant learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5336–5353. [Google Scholar] [CrossRef]
- Plaza, A.; Martinez, P.; Plaza, J.; Perez, R. Dimensionality reduction and classification of hyperspectral image data using sequences of extended morphological transformations. IEEE Trans. Geosci. Remote Sens. 2005, 43, 466–479. [Google Scholar] [CrossRef] [Green Version]
- Chang, C.I.; Du, Q.; Sun, T.L.; Althouse, M.L. A joint band prioritization and band-decorrelation approach to band selection for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 1999, 37, 2631–2641. [Google Scholar] [CrossRef] [Green Version]
- Ghamisi, P.; Maggiori, E.; Li, S.; Souza, R.; Tarablaka, Y.; Moser, G.; De Giorgi, A.; Fang, L.; Chen, Y.; Chi, M.; et al. New frontiers in spectral-spatial hyperspectral image classification: The latest advances based on mathematical morphology, Markov random fields, segmentation, sparse representation, and deep learning. IEEE Geosci. Remote Sens. Mag. 2018, 6, 10–43. [Google Scholar] [CrossRef]
- He, N.; Paoletti, M.E.; Haut, J.M.; Fang, L.; Li, S.; Plaza, A.; Plaza, J. Feature extraction with multiscale covariance maps for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 755–769. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Liu, C.; Li, S. Recent advances on spectral–spatial hyperspectral image classification: An overview and new guidelines. IEEE Trans. Geosci. Remote Sens. 2018, 56, 1579–1597. [Google Scholar] [CrossRef]
- Li, W.; Du, Q. Gabor-filtering-based nearest regularized subspace for hyperspectral image classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 1012–1022. [Google Scholar] [CrossRef]
- Benediktsson, J.A.; Palmason, J.A.; Sveinsson, J.R. Classification of hyperspectral data from urban areas based on extended morphological profiles. IEEE Trans. Geosci. Remote Sens. 2005, 43, 480–491. [Google Scholar] [CrossRef]
- He, L.; Li, J.; Plaza, A.; Li, Y. Discriminative low-rank Gabor filtering for spectral–spatial hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2016, 55, 1381–1395. [Google Scholar] [CrossRef]
- Kang, X.; Li, S.; Benediktsson, J.A. Spectral–spatial hyperspectral image classification with edge-preserving filtering. IEEE Trans. Geosci. Remote Sens. 2014, 52, 2666–2677. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral–spatial hyperspectral image segmentation using subspace multinomial logistic regression and Markov random fields. IEEE Trans. Geosci. Remote Sens. 2012, 50, 809–823. [Google Scholar] [CrossRef]
- Zhong, P.; Wang, R. Jointly learning the hybrid CRF and MLR model for simultaneous denoising and classification of hyperspectral imagery. IEEE Trans. Neural Netw. Learn. Syst. 2014, 25, 1319–1334. [Google Scholar] [CrossRef]
- Li, C.; Ma, Y.; Mei, X.; Liu, C.; Ma, J. Hyperspectral image classification with robust sparse representation. IEEE Geosci. Remote Sens. Lett. 2016, 13, 641–645. [Google Scholar] [CrossRef]
- Jia, S.; Zhang, X.; Li, Q. Spectral–Spatial Hyperspectral Image Classification Using l1/2 Regularized Low-Rank Representation and Sparse Representation-Based Graph Cuts. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2473–2484. [Google Scholar] [CrossRef]
- Chen, C.; Chen, N.; Peng, J. Nearest regularized joint sparse representation for hyperspectral image classification. IEEE Geosci. Remote Sens. Lett. 2016, 13, 424–428. [Google Scholar] [CrossRef]
- Wei, Y.; Zhou, Y.; Li, H. Spectral-Spatial Response for Hyperspectral Image Classification. Remote Sens. 2017, 9, 203. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Wei, Y. Learning hierarchical spectral–spatial features for hyperspectral image classification. IEEE Trans. Cybern. 2016, 46, 1667–1678. [Google Scholar] [CrossRef]
- Peng, J.; Li, L.; Tang, Y.Y. Maximum likelihood estimation-based joint sparse representation for the classification of hyperspectral remote sensing images. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 1790–1802. [Google Scholar] [CrossRef] [PubMed]
- Peng, J.; Jiang, X.; Chen, N.; Fu, H. Local adaptive joint sparse representation for hyperspectral image classification. Neurocomputing 2019, 334, 239–248. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, L. Beyond the Patchwise Classification: Spectral-Spatial Fully Convolutional Networks for Hyperpsectral Image Classificaiton. IEEE Trans. Big Data 2020, 6, 492–506. [Google Scholar] [CrossRef]
- Jiang, J.; Chen, C.; Yu, Y.; Jiang, X.; Ma, J. Spatial-aware collaborative representation for hyperspectral remote sensing image classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 404–408. [Google Scholar] [CrossRef]
- Tarabalka, Y.; Chanussot, J.; Benediktsson, J.A. Segmentation and classification of hyperspectral images using watershed transformation. Pattern Recognit. 2010, 43, 2367–2379. [Google Scholar] [CrossRef] [Green Version]
- Tu, B.; Kuang, W.; Zhao, G.; Fei, H. Hyperspectral image classification via superpixel spectral metrics representation. IEEE Signal Process. Lett. 2018, 25, 1520–1524. [Google Scholar] [CrossRef]
- Zheng, C.; Wang, N.; Cui, J. Hyperspectral image classification with small training sample size using superpixel-guided training sample enlargement. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7307–7316. [Google Scholar] [CrossRef]
- Zehtabian, A.; Ghassemian, H. Automatic object-based hyperspectral image classification using complex diffusions and a new distance metric. IEEE Trans. Geosci. Remote Sens. 2016, 54, 4106–4114. [Google Scholar] [CrossRef]
- Deng, C.; Xue, Y.; Liu, X.; Li, C.; Tao, D. Active transfer learning network: A unified deep joint spectral–spatial feature learning model for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1741–1754. [Google Scholar] [CrossRef] [Green Version]
- Shrestha, A.; Mahmood, A. Review of Deep Learning Algorithms and Architectures. IEEE Access 2019, 7, 53040–53065. [Google Scholar] [CrossRef]
- Kang, X.; Li, C.; Li, S.; Lin, H. Classification of hyperspectral images by Gabor filtering based deep network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1166–1178. [Google Scholar] [CrossRef]
- Hang, R.; Liu, Q.; Hong, D.; Ghamisi, P. Cascaded recurrent neural networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 5384–5394. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.; Lin, Z.; Zhao, X.; Wang, G.; Gu, Y. Deep learning-based classification of hyperspectral data. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2014, 7, 2094–2107. [Google Scholar] [CrossRef]
- Chen, Y.; Zhao, X.; Jia, X. Spectral–spatial classification of hyperspectral data based on deep belief network. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 8, 2381–2392. [Google Scholar] [CrossRef]
- Cao, X.; Zhou, F.; Xu, L.; Meng, D.; Xu, Z.; Paisley, J. Hyperspectral image classification with Markov random fields and a convolutional neural network. IEEE Trans. Image Process. 2018, 27, 2354–2367. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yang, X.; Ye, Y.; Li, X.; Lau, R.Y.; Zhang, X.; Huang, X. Hyperspectral image classification with deep learning models. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5408–5423. [Google Scholar] [CrossRef]
- Zhu, L.; Chen, Y.; Ghamisi, P.; Benediktsson, J.A. Generative adversarial networks for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2018, 56, 5046–5063. [Google Scholar] [CrossRef]
- Fang, L.; He, N.; Li, S.; Plaza, A.J.; Plaza, J. A new spatial–spectral feature extraction method for hyperspectral images using local covariance matrix representation. IEEE Trans. Geosci. Remote Sens. 2018, 56, 3534–3546. [Google Scholar] [CrossRef]
- Xu, Y.; Du, B.; Zhang, F.; Zhang, L. Hyperspectral image classification via a random patches network. ISPRS J. Photogramm. Remote Sens. 2018, 142, 344–357. [Google Scholar] [CrossRef]
- Muralidhar, N.; Islam, M.R.; Marwah, M.; Karpatne, A.; Ramakrishnan, N. Incorporating Prior Domain Knowledge into Deep Neural Networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 36–45. [Google Scholar]
- Pan, B.; Shi, Z.; Xu, X. Hierarchical guidance filtering-based ensemble classification for hyperspectral images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 4177–4189. [Google Scholar] [CrossRef]
- Kang, X.; Xiang, X.; Li, S.; Benediktsson, J.A. PCA-based edge-preserving features for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2017, 55, 7140–7151. [Google Scholar] [CrossRef]
- Della Porta, C.J.; Bekit, A.A.; Lampe, B.H.; Chang, C.I. Hyperspectral Image Classification via Compressive Sensing. IEEE Trans. Geosci. Remote Sens. 2019, 57, 8290–8303. [Google Scholar] [CrossRef]
- Yin, H.; Gong, Y.; Guoping, Q. Side Window Filtering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 147–156. [Google Scholar]
- Du, C.; Wang, Y.; Wang, C.; Shi, C.; Xiao, B. Selective feature connection mechanism: Concatenating multi-layer cnn features with a feature selector. Pattern Recognit. Lett. 2020, 129, 108–114. [Google Scholar] [CrossRef]
- Roy, S.K.; Krishna, G.; Dubey, S.R.; Chaudhuri, B.B. HybridSN: Exploring 3D-2D CNN Feature Hierarchy for Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 17, 492–506. [Google Scholar]
- Pu, H.; Chen, Z.; Wang, B.; Jiang, G.M. A Novel Spatial–Spectral Similarity Measure for Dimensionality Reduction and Classification of Hyperspectral Imagery. IEEE Trans. Geosci. Remote Sens. 2014, 52, 7008–7022. [Google Scholar]
- Paoletti, M.E.; Haut, J.M.; Fernandez-Beltran, R.; Plaza, J.; Plaza, A.J.; Pla, F. Deep pyramidal residual networks for spectral–spatial hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 740–754. [Google Scholar] [CrossRef]
- Haut, J.M.; Paoletti, M.E.; Plaza, J.; Li, J.; Plaza, A. Active learning with convolutional neural networks for hyperspectral image classification using a new bayesian approach. IEEE Trans. Geosci. Remote Sens. 2018, 56, 6440–6461. [Google Scholar] [CrossRef]
- Li, J.; Bioucas-Dias, J.M.; Plaza, A. Spectral-spatial classification of hyperspectral data using loopy belief propagation and active learning. IEEE Trans. Geosci. Remote Sens. 2013, 51, 844–856. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | HybridSN | STSE_DWLR | CNN-MRF | LCMR | RPNet | SANet |
|---|---|---|---|---|---|---|
| 1 | 17.78 | 97.78 | 46.67 | 96.67 | 14.67 | 97.56 |
| 2 | 70.29 | 82.47 | 70.33 | 91.54 | 86.90 | 92.49 |
| 3 | 71.87 | 85.23 | 67.75 | 84.06 | 69.43 | 89.82 |
| 4 | 70.69 | 82.28 | 43.36 | 77.72 | 26.21 | 78.58 |
| 5 | 83.30 | 79.41 | 78.94 | 93.51 | 83.62 | 88.88 |
| 6 | 97.76 | 97.23 | 85.69 | 95.58 | 90.69 | 98.36 |
| 7 | 48.15 | 60.00 | 36.30 | 100.0 | 70.74 | 99.26 |
| 8 | 99.57 | 100.0 | 92.46 | 100.0 | 84.81 | 99.94 |
| 9 | 0.000 | 13.68 | 69.47 | 74.21 | 41.58 | 62.11 |
| 10 | 79.22 | 83.74 | 63.03 | 83.61 | 78.68 | 88.63 |
| 11 | 91.77 | 96.13 | 87.88 | 92.44 | 95.92 | 96.26 |
| 12 | 54.73 | 79.35 | 59.52 | 83.80 | 48.43 | 89.35 |
| 13 | 78.11 | 98.41 | 71.05 | 97.15 | 89.10 | 99.30 |
| 14 | 96.53 | 97.89 | 95.05 | 96.71 | 92.17 | 99.95 |
| 15 | 63.76 | 98.44 | 57.27 | 93.04 | 55.63 | 91.64 |
| 16 | 75.82 | 88.79 | 80.77 | 80.44 | 29.67 | 99.01 |
| OA | 82.22 | 90.38 | 77.39 | 91.12 | 81.80 | 93.97 |
| AA | 68.71 | 83.80 | 69.10 | 90.03 | 66.14 | 91.95 |
| 0.797 | 0.890 | 0.740 | 0.899 | 0.788 | 0.931 |
| HybridSN | STSE_DWLR | CNN-MRF | LCMR | RPNet | SANet |
|---|---|---|---|---|---|
| 170.18 | 26.15 | 438 | 9.59 | 5.82 | 11.73 |
| No. | HybridSN | STSE_DWLR | CNN-MRF | LCMR | RPNet | SANet |
|---|---|---|---|---|---|---|
| 1 | 90.78 | 99.84 | 93.79 | 95.82 | 91.40 | 98.55 |
| 2 | 99.84 | 99.98 | 98.51 | 99.53 | 97.94 | 99.85 |
| 3 | 71.80 | 99.83 | 65.04 | 92.23 | 86.48 | 92.54 |
| 4 | 73.95 | 74.82 | 95.95 | 98.25 | 91.23 | 92.38 |
| 5 | 98.05 | 99.62 | 96.66 | 97.81 | 95.51 | 99.69 |
| 6 | 99.86 | 100.0 | 93.15 | 99.14 | 93.83 | 99.21 |
| 7 | 99.62 | 99.98 | 64.00 | 94.75 | 81.66 | 96.95 |
| 8 | 92.24 | 97.97 | 80.21 | 92.97 | 87.40 | 95.93 |
| 9 | 59.23 | 43.48 | 93.55 | 89.36 | 96.03 | 94.87 |
| OA | 93.59 | 96.72 | 92.51 | 97.47 | 93.87 | 98.14 |
| AA | 87.26 | 90.61 | 86.76 | 95.54 | 91.28 | 96.67 |
| 0.932 | 0.956 | 90.07 | 0.967 | 0.918 | 0.975 |
| No. | HybridSN | STSE_DWLR | CNN-MRF | LCMR | RPNet | SANet |
|---|---|---|---|---|---|---|
| 1 | 99.80 | 99.23 | 99.73 | 99.89 | 99.03 | 100.0 |
| 2 | 99.97 | 99.69 | 98.13 | 99.31 | 99.73 | 99.94 |
| 3 | 99.49 | 99.80 | 98.72 | 99.76 | 99.38 | 100.0 |
| 4 | 99.49 | 99.17 | 88.47 | 97.36 | 98.80 | 99.94 |
| 5 | 99.81 | 97.16 | 99.89 | 98.38 | 99.01 | 98.62 |
| 6 | 100.0 | 99.81 | 99.74 | 99.40 | 99.63 | 99.87 |
| 7 | 99.66 | 99.36 | 99.69 | 99.36 | 99.48 | 99.85 |
| 8 | 96.30 | 99.50 | 93.57 | 97.94 | 92.30 | 99.72 |
| 9 | 98.65 | 99.46 | 99.59 | 99.78 | 99.26 | 100.0 |
| 10 | 99.37 | 97.45 | 95.55 | 98.39 | 97.85 | 97.20 |
| 11 | 98.32 | 94.74 | 99.75 | 99.91 | 96.16 | 99.70 |
| 12 | 99.94 | 99.95 | 99.86 | 99.95 | 99.98 | 100.0 |
| 13 | 91.36 | 95.46 | 98.84 | 98.62 | 98.81 | 98.82 |
| 14 | 86.37 | 91.95 | 98.03 | 95.12 | 95.68 | 94.91 |
| 15 | 88.99 | 96.42 | 85.82 | 95.97 | 89.41 | 98.99 |
| 16 | 100.0 | 99.01 | 99.25 | 97.51 | 98.43 | 99.21 |
| OA | 96.34 | 98.55 | 95.86 | 98.40 | 96.31 | 99.39 |
| AA | 97.48 | 98.01 | 97.20 | 98.54 | 97.68 | 99.17 |
| 0.966 | 0.984 | 0.954 | 0.982 | 0.959 | 0.993 |
| No. | HybridSN | STSE_DWLR | CNN-MRF | LCMR | RPNet | SANet |
|---|---|---|---|---|---|---|
| 1 | 98.03 | 79.84 | 98.05 | 91.56 | 82.38 | 93.76 |
| 2 | 54.79 | 83.91 | 56.06 | 89.24 | 75.08 | 99.16 |
| 3 | 61.43 | 92.71 | 66.25 | 97.81 | 71.83 | 92.95 |
| 4 | 30.12 | 93.00 | 31.06 | 85.38 | 76.03 | 69.51 |
| 5 | 50.13 | 90.45 | 48.17 | 84.55 | 90.00 | 77.95 |
| 6 | 68.21 | 98.17 | 72.00 | 91.12 | 76.70 | 93.62 |
| 7 | 99.90 | 98.80 | 99.86 | 93.80 | 99.90 | 96.80 |
| 8 | 79.46 | 80.68 | 79.28 | 88.29 | 88.12 | 86.29 |
| 9 | 81.86 | 87.50 | 81.03 | 83.05 | 86.82 | 90.70 |
| 10 | 68.92 | 97.44 | 70.07 | 99.42 | 88.67 | 97.42 |
| 11 | 77.42 | 87.83 | 79.37 | 91.98 | 93.77 | 94.20 |
| 12 | 77.11 | 98.49 | 76.65 | 97.01 | 87.53 | 95.04 |
| 13 | 100.0 | 100.0 | 100.0 | 100.0 | 97.14 | 100.0 |
| OA | 79.53 | 91.04 | 79.55 | 92.83 | 87.01 | 93.02 |
| AA | 72.88 | 91.45 | 72.91 | 91.79 | 85.69 | 91.34 |
| 0.7717 | 0.9005 | 0.7720 | 0.9203 | 0.8558 | 0.9223 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wei, Y.; Zhou, Y. Spatial-Aware Network for Hyperspectral Image Classification. Remote Sens. 2021, 13, 3232. https://doi.org/10.3390/rs13163232
Wei Y, Zhou Y. Spatial-Aware Network for Hyperspectral Image Classification. Remote Sensing. 2021; 13(16):3232. https://doi.org/10.3390/rs13163232
Chicago/Turabian StyleWei, Yantao, and Yicong Zhou. 2021. "Spatial-Aware Network for Hyperspectral Image Classification" Remote Sensing 13, no. 16: 3232. https://doi.org/10.3390/rs13163232
APA StyleWei, Y., & Zhou, Y. (2021). Spatial-Aware Network for Hyperspectral Image Classification. Remote Sensing, 13(16), 3232. https://doi.org/10.3390/rs13163232