
A Method of Ground-Based Cloud Motion Predict: CCLSTM + SR-Net



Abstract
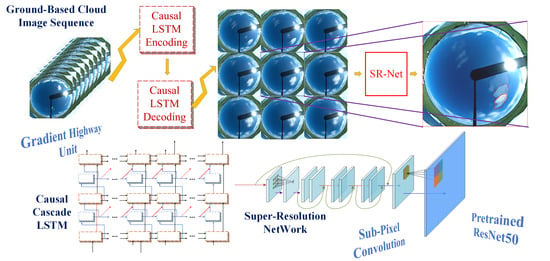
:
1. Introduction
- Traditional methods mostly use single-channel grayscale images or binary images after cloud recognition. The prediction results of this method can obtain RGB three-channel color images, which can be extracted with features such as the red–blue ratio;
- Traditional methods can only predict the direction of cloud motion. This method can predict the cloud contour changes while predicting the cloud motion trajectory;
- Traditional methods have to perform distortion correction, shading belt filtering and other preprocessing. In contrast, this method directly obtains the prediction results without any preprocessing. This is helpful for extracting more features, such as the reflection intensity of the shading belt to sunlight (the shading belt is not pure black reflected in the figure) and so on;
- This method can continuously give cloud motion prediction results at multiple moments, and they all have high reliability.
2. Training Preparation
2.1. Training Image Dataset
2.2. Image Preprocessing
2.3. Experimental Equipment
3. Prediction Model
3.1. Cascade Causal LSTM
- Reduce the parameters of the model with the same receptive field;
- Increase the network depth within a unit and enhance the unit’s fitting ability.
3.2. Prediction Results of CCLSTM
3.3. Ablation Study
- The original PredRNN++;
- The original PredRNN++ with a double number of filters in the convolution layers;
- CCLSTM with no ReLU activation function between the double-layer convolution filter compared with the final version;
- CCLSTM, which does not contain a double-layer convolution filter and jumpers compared with the final version;
- A 7-layer structure with 4 layers of Causal LSTM cells interleaved with 3 layers of GHUs;
- The original PredRNN++ with the vertical depth increased by one layer.
4. Super-Resolution Reconstruction of Predicted Images
4.1. Super-Resolution Network
4.2. Perceptual Losses
4.3. Ablation Study of Loss Function
- Use the pixel-level MSE as the loss, no dilated convolution and no perceptual loss;
- Use the L2 perceptual loss, no dilated convolution and all are taken as 0.05;
- Use the L1 perceptual loss; no dilated convolution and the values of , , and are 0.08, 0.04, 0.02 and 0.01. ;
- Use the L1 perceptual loss; no dilated convolution and the values of , , , and are 0.04, 0.02, 0.01, 0.01 and 0.05;
- Use the L1 perceptual loss; no dilated convolution and the values of , , , and are 0.002, 0.005, 0.01, 0.02 and 0.04;
- Use the pixel-level MAE as the loss, with dilated convolution and no perceptual loss;
- Use the L1 perceptual loss, with dilated convolution and the values of , , , and are 0.04, 0.02, 0.01, 0.01 and 0.005.
- Comparing (a) with (f), for the carefully selected dataset, the difference between the MSE loss and the MAE loss is not big, and the addition of the dilated convolution makes the result slightly improved;
- Compare (a)/(f) with other results with added perceptual losses; a pure pixel-level loss will cause the result to be too smooth;
- Comparing (d) with (g), using dilated convolution to increase the receptive field helps to improve the image quality in some subtleties;
- Compared with (d) and (e), the increasing and decreasing of the perceptual layers’ weights will bring different degrees of the grid effect. The greater the weight used by the deeper layers in the perceptual model (ResNet50 here), the more serious the grid effect. The severity of the grid effect in the figure is (e) > (b) > (c) > (d) > (g), which is consistent with the selection of in each plan.
4.4. Super-Resolution Results
5. Results
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Wang, C.; Shi, C.; Xiao, B. A Selection Criterion for the Optimal Resolution of Ground-Based Remote Sensing Cloud Images for Cloud Classification. IEEE Trans. Geosci. Remote Sens. 2019, 57, 1358–1367. [Google Scholar] [CrossRef]
- Dev, S.; Wen, B.; Lee, Y.H.; Winkler, S. Ground-based image analysis: A tutorial on machine-learning techniques and applications. IEEE Geosci. Remote Sens. Mag. 2016, 4, 79–93. [Google Scholar] [CrossRef]
- Leveque, L.; Dev, S.; Hossari, M.; Lee, Y.H.; Winkler, S. Subjective Quality Assessment of Ground-based Camera Images. In Proceedings of the 2019 Photonics & Electromagnetics Research Symposium-Fall (PIERS-FALL), Xiamen, China, 17–20 December 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 3168–3174. [Google Scholar]
- Silva, A.A.; Echer, M.P.D. Ground-based measurements of local cloud cover. Meteorol. Atmos. Phys. 2013, 120, 201–212. [Google Scholar] [CrossRef]
- Sun, Y.C.; Venugopal, V.; Brandt, A.R. Short-term solar power forecast with deep learning: Exploring optimal input and output configuration. Sol. Energy 2019, 188, 730–741. [Google Scholar] [CrossRef]
- Liu, B.M.; Ma, Y.Y.; Gong, W.; Zhang, M.; Yang, J. Study of continuous air pollution in winter over Wuhan based on ground-based and satellite observations. Atmos. Pollut. Res. 2018, 9, 156–165. [Google Scholar] [CrossRef]
- Long, C.N.; Sabburg, J.M.; Calbo, J.; Pages, D. Retrieving cloud characteristics from ground-based daytime color all-sky images. J. Atmos. Ocean. Technol. 2006, 23, 633–652. [Google Scholar] [CrossRef] [Green Version]
- Dissawa, D.M.L.H.; Ekanayake, M.P.B.; Godaliyadda, G.M.R.I.; Ekanayake, J.B.; Agalgaonkar, A.P. Cloud motion tracking for short-term on-site cloud coverage prediction. In Proceedings of the Seventeenth International Conference on Advances in ICT for Emerging Regions, Colombo, Sri Lanka, 6–9 September 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- El Jaouhari, Z.; Zaz, Y.; Masmoudi, L. Cloud tracking from whole-sky ground-based images. In Proceedings of the 3rd International Renewable and Sustainable Energy Conference, Marrakech, Morocco, 10–13 December 2015; pp. 1–5. [Google Scholar]
- Dissawa, D.M.L.H.; Godaliyadda, G.M.R.I.; Ekanayake, M.P.B.; Ekanayake, J.B.; Agalgaonkar, A.P. Cross-correlation based cloud motion estimation for short-term solar irradiation predictions. In Proceedings of the IEEE International Conference on Industrial and Information Systems, Peradeniya, Sri Lanka, 15–16 December 2017; pp. 1–6. [Google Scholar]
- Jamaly, M.; Kleissl, J. Robust cloud motion estimation by spatio-temporal correlation analysis of irradiance data. Sol. Energy 2018, 159, 306–317. [Google Scholar] [CrossRef]
- Ye, L.; Cao, Z.; Xiao, Y.; Yang, Z. Supervised Fine-Grained Cloud Detection and Recognition in Whole-Sky Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 7972–7985. [Google Scholar] [CrossRef]
- Shi, C.; Wang, C.; Wang, Y.; Xiao, B. Deep convolutional activations-based features for ground-based cloud classification. IEEE Geosci. Remote Sens. Lett. 2017, 14, 816–820. [Google Scholar] [CrossRef]
- Liu, S.; Li, M.; Zhang, Z.; Xiao, B.; Cao, X. Multimodal ground-based cloud classification using joint fusion convolutional neural network. Remote Sens. 2018, 10, 822. [Google Scholar] [CrossRef] [Green Version]
- Liu, S.; Duan, L.; Zhang, Z.; Cao, X. Hierarchical multimodal fusion for ground-based cloud classification in weather station networks. IEEE Access 2019, 7, 85688–85695. [Google Scholar] [CrossRef]
- Liu, S.; Duan, L.; Zhang, Z.; Cao, X.; Durrani, T.S. Multimodal Ground-Based Remote Sensing Cloud Classification via Learning Heterogeneous Deep Features. IEEE Trans. Geosci. Remote Sens. 2020, 58, 7790–7800. [Google Scholar] [CrossRef]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.; Wong, W.; Woo, W. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 7–12 December 2015; Volume 28. [Google Scholar]
- Wang, Y.; Long, M.; Wang, J.; Gao, Z.; Yu, P.S. PredRNN: Recurrent Neural Networks for Predictive Learning using Spatiotemporal LSTMs. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Wang, Y.; Gao, Z.; Long, M.; Wang, J.; Yu, P.S. PredRNN++: Towards A Resolution of the Deep-in-Time Dilemma in Spatiotemporal Predictive Learning. In Proceedings of the 35th International Conference on Machine Learning, Stockholmsmässan, Stockholm, Sweden, 10–15 July 2018; Volume 80, pp. 5123–5132. [Google Scholar]
- Fan, H.; Zhu, L.; Yang, Y. Cubic LSTMs for Video Prediction. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; ASSOC Advancement Artificial Intelligence: Palo Alto, CA, USA, 2019; pp. 8263–8270. [Google Scholar]
- Xu, Z.; Du, J.; Wang, J.; Jiang, C.; Ren, Y. Satellite Image Prediction Relying on GAN and LSTM Neural Networks. In Proceedings of the ICC 2019–2019 IEEE International Conference on Communications, Shanghai, China, 20–24 May 2019; pp. 1–6. [Google Scholar]
- Denton, E.; Birodkar, V. Unsupervised Learning of Disentangled Representations from Video. In Proceedings of the 31st Annual Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Su, X.; Li, T.; An, C.; Wang, G. Prediction of Short-Time Cloud Motion Using a Deep-Learning Model. Atmosphere 2020, 11, 1151. [Google Scholar] [CrossRef]
- Wang, X.; Gao, L.; Song, J.; Shen, H. Beyond Frame-level CNN: Saliency-Aware 3-D CNN With LSTM for Video Action Recognition. IEEE Signal Process. Lett. 2017, 24, 510–514. [Google Scholar] [CrossRef]
- Wu, H.; Lu, Z.; Zhang, J.; Ren, T. Facial Expression Recognition Based on Multi-Features Cooperative Deep Convolutional Network. Appl. Sci. 2021, 11, 1428. [Google Scholar] [CrossRef]
- Chow, C.; Urquhart, B.; Lave, M.; Dominguez, A.; Kleissl, J.; Shields, J.; Washom, B. Intra-hour forecasting with a total sky imager at the UC San Diego solar energy testbed. Sol. Energy 2011, 85, 2881–2893. [Google Scholar] [CrossRef] [Green Version]
- Huynh-Thu, Q.; Ghanbari, M. Scope of validity of PSNR in image/video quality assessment. Electron. Lett. 2008, 44, 800–801. [Google Scholar] [CrossRef]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [Green Version]
- Zhao, X.; Wei, H.K.; Wang, H.; Zhu, T.T.; Zhang, K.J. 3D-CNN-based feature extraction of ground-based cloud images for direct normal irradiance prediction. Sol. Energy 2019, 181, 510–518. [Google Scholar] [CrossRef]
- Ledig, C.; Theis, L.; Huszár, F.; Caballero, J.; Cunningham, A.; Acosta, A.; Aitken, A.; Tejani, A.; Totz, J.; Wang, Z.; et al. Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 105–114. [Google Scholar]
- Balakrishnan, G.; Dalca, A.; Zhao, A.; Guttag, J.; Durand, F.; Freeman, W. Visual Deprojection: Probabilistic Recovery of Collapsed Dimensions. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 171–180. [Google Scholar]
- Ye, J.; Shen, Z.; Behrani, P.; Ding, F.; Shi, Y. Detecting USM image sharpening by using CNN. Signal Process. Image Commun. 2018, 68, 258–264. [Google Scholar] [CrossRef]
- Lai, W.; Huang, J.; Ahuja, N.; Yang, M. Fast and Accurate Image Super-Resolution with Deep Laplacian Pyramid Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 2599–2613. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Yu, F.; Koltun, V. Multi-Scale Context Aggregation by Dilated Convolutions. arXiv 2016, arXiv:1511.07122. [Google Scholar]
- Shi, W.; Caballero, J.; Huszár, F.; Totz, J.; Aitken, A.; Bishop, R.; Rueckert, D.; Wang, Z. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 1874–1883. [Google Scholar]
- Johnson, J.; Alahi, A.; Li, F. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. In Proceedings of the 14th European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; Volume 9906, pp. 694–711. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 770–778. [Google Scholar]
- Sangkloy, P.; Lu, J.; Fang, C.; Yu, F.; Hays, J. Scribbler: Controlling deep image synthesis with sketch and color. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 6836–6845. [Google Scholar]
- Yang, C.; Lu, X.; Lin, Z.; Shechtman, E.; Wang, O.; Li, H. High-Resolution Image Inpainting Using Multi-scale Neural Patch Synthesis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 4076–4084. [Google Scholar]
- Li, M.; Hsu, W.; Xie, X.; Cong, J.; Gao, W. SACNN: Self-Attention Convolutional Neural Network for Low-Dose CT Denoising with Self-Supervised Perceptual Loss Network. IEEE Trans. Med. Imaging. 2020, 39, 2289–2301. [Google Scholar] [CrossRef] [PubMed]
- Xu, X.; Xie, M.; Miao, P.; Qu, W.; Xiao, W.; Zhang, H.; Liu, X.; Wong, T. Perceptual-Aware Sketch Simplification Based on Integrated VGG Layers. IEEE Trans. Vis. Comput. Graph. 2019, 27, 178–189. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Distribution | CCLSTM | SR-Net |
|---|---|---|
| Training set | 18,020 | 3800 |
| Val. set | 680 | 900 |
| Test and analysis | 740 | 1800 |
| Run for SR-Net | 18,200 | - |
| Sequence | t + 1 | t + 2 | t + 3 | t + 4 | t + 5 | t + 6 | t + 7 | t + 8 | t + 9 | t + 10 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| PSNR | Original PredRNN++ | 27.035 | 25.131 | 24.181 | 23.491 | 23.069 | 22.628 | 22.451 | 22.233 | 22.038 | 21.854 |
| Original double filters | 27.322 | 25.212 | 24.185 | 23.531 | 23.12 | 22.933 | 22.754 | 22.463 | 22.248 | 22.058 | |
| CCLSTM no ReLU in D | 27.236 | 25.84 | 24.645 | 23.994 | 23.444 | 22.956 | 22.625 | 22.309 | 21.982 | 21.775 | |
| CCLSTM no D&J | 26.473 | 25.183 | 23.854 | 23.301 | 22.825 | 22.549 | 22.424 | 22.462 | 22.157 | 22.148 | |
| Interleaved 7-layers | 26.685 | 24.978 | 23.59 | 22.715 | 22.063 | 22.637 | 22.46 | 22.489 | 22.396 | 22.425 | |
| PredRNN++ add a layer | 27.158 | 25.809 | 24.462 | 23.692 | 22.844 | 22.544 | 22.328 | 21.905 | 21.588 | 21.423 | |
| Final CCLSTM | 27.377 | 25.614 | 24.664 | 24.102 | 23.381 | 23.18 | 22.81 | 22.357 | 22.023 | 21.671 | |
| SSIM | Original PredRNN++ | 0.84 | 0.795 | 0.763 | 0.74 | 0.725 | 0.714 | 0.708 | 0.701 | 0.696 | 0.694 |
| Original double filters | 0.847 | 0.797 | 0.76 | 0.738 | 0.722 | 0.71 | 0.702 | 0.697 | 0.696 | 0.694 | |
| CCLSTM no ReLU in D | 0.848 | 0.804 | 0.77 | 0.746 | 0.731 | 0.717 | 0.707 | 0.701 | 0.697 | 0.695 | |
| CCLSTM no D&J | 0.819 | 0.777 | 0.744 | 0.726 | 0.71 | 0.698 | 0.694 | 0.692 | 0.69 | 0.691 | |
| Interleaved 7-layers | 0.821 | 0.775 | 0.742 | 0.718 | 0.706 | 0.703 | 0.701 | 0.702 | 0.704 | 0.705 | |
| PredRNN++ add a layer | 0.843 | 0.801 | 0.765 | 0.74 | 0.722 | 0.708 | 0.701 | 0.695 | 0.689 | 0.686 | |
| Final CCLSTM | 0.852 | 0.809 | 0.775 | 0.751 | 0.738 | 0.729 | 0.722 | 0.712 | 0.708 | 0.703 |
| Sequence | t + 1 | t + 2 | t + 3 | t + 4 | t + 5 | t + 6 | t + 7 | t + 8 | t + 9 | t + 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| PSNR (dB) | 27.436 | 25.687 | 24.84 | 23.985 | 23.442 | 22.928 | 22.848 | 22.316 | 22.034 | 21.763 |
| SSIM | 0.837 | 0.807 | 0.785 | 0.744 | 0.74 | 0.732 | 0.724 | 0.707 | 0.702 | 0.7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, Z.; Wang, Z.; Li, X.; Zhang, J. A Method of Ground-Based Cloud Motion Predict: CCLSTM + SR-Net. Remote Sens. 2021, 13, 3876. https://doi.org/10.3390/rs13193876
Lu Z, Wang Z, Li X, Zhang J. A Method of Ground-Based Cloud Motion Predict: CCLSTM + SR-Net. Remote Sensing. 2021; 13(19):3876. https://doi.org/10.3390/rs13193876
Chicago/Turabian StyleLu, Zhiying, Zehan Wang, Xin Li, and Jianfeng Zhang. 2021. "A Method of Ground-Based Cloud Motion Predict: CCLSTM + SR-Net" Remote Sensing 13, no. 19: 3876. https://doi.org/10.3390/rs13193876
APA StyleLu, Z., Wang, Z., Li, X., & Zhang, J. (2021). A Method of Ground-Based Cloud Motion Predict: CCLSTM + SR-Net. Remote Sensing, 13(19), 3876. https://doi.org/10.3390/rs13193876