1. Introduction
Multi-agent systems consisting of autonomous mobile robots have gained significant attention in various strategic real-world applications such as reconnaissance and surveillance [
1,
2,
3,
4], search and rescue operations [
5,
6], etc. This is as a result of progress made in the development of autonomous systems technology. Among their many applications, rapid deployment in high network latency areas is a key functionally that is attracting attention from researchers and industry players. In order to complete certain missions, multi-agent systems consisting of autonomous systems need to spread out from an initial drop off point in unknown areas to achieve some fixed configurations such as forming a temporal ad hoc network or provide a complete map of the environment. We use the term deployment to describe this phase. The study on AMR deployment and mobility problems is an important research field, which is significant for both military and civilian applications. In hazardous areas such as fire burnt areas, toxic urban regions, disaster hit areas, or remote planets and battlefields, human operations sometimes become impossible or dangerous. Hence, unmanned systems can be deployed in those challenging areas to replace or facilitate human work such as gathering information in search and rescue, provide communication support or perform target tracking and surveillance. In these regards, AMR provides greater practicality and shows robust performance in recent studies. The fundamental problem is an approach of how to rapidly perform the deployment optimally in these environments.
The tremendous potential offered by AMR for possible applications such as these, stem from the fact that using multi-AMR in general can lead to increased flexibility and redundancy, resulting in an overall increase in reliability. Moreover, multi-AMR working as a team can perform an exploration, mapping and localization, surveillance task or any other group mission more effectively and efficiently compared to a single agent [
7,
8]. Besides covering wider area, the deployment of a multi-AMR systems in general, would provide greater benefits regarding area-coverage, mission duration and optimized task sharing and execution between participating agents. For complex tasks that would often require a certain level of cooperation, each system within the team might need to have a compatible messaging interface to enable the exchange of messages with other teammates and/or with command centers within its communication range. The resulting network of the team can be used to facilitate the task performance of the team within the environment [
9,
10].
This paper analyzes the characteristics and requirements of deploying AMR or unmanned vehicles to provide remote sensing, mapping and coverage of burnt areas and proposes a network deployment and adjustment algorithm that can facilitate operations in various situations such as during fire outbreaks and post fire management. For instance, when disasters such as large fires occur, previously established networks might be destroyed or incapacitated. In scenarios such as these, autonomous systems carrying wireless devices can be deployed to create an end-to-end communication network to support rescue efforts or access the severity of damage. The networks deployed in these situations can guide human firefighters and responders to potential targets for rescue and to areas that require attention while warning them of dangerous areas along the way. In these application settings, the robots team or mobile agents might be deployed from a single or multiple accessible drop of points to coordinate detection of environmental information by spreading out as much as possible to traverse and detect the given area in order to collect enough information to assist the execution of tasks while keeping connected. State-of-the-art approaches of deployment of mobile agents for communication support or area exploration and mapping often employ one of three different management strategies to manage and control such systems including centralized, decentralized or distributed strategies [
11]. In the centralized approach, each entity or robot communicates with every other entity in the systems, and the decision-making process of the entire team or swarm is centralized or executed by a single decision maker. In a distributed approach, each entity in the task environment communicates its information and coordinates its actions with others, while in the decentralized approaches, agents rely only on the available local information. In this case, the exchange of information may not be required among the different entities and coordination between entities may be achieved through shared global variable(s).
Based on these strategies, some deployment approaches such as Voronoi-inspired algorithms [
12,
13] assume that the global information of the unexplored area can be previously obtained by humans, thus potential locations for deployment can be calculated. During the deployment, robots already have knowledge about the pre-calculated locations they should go to. For other approaches, such as the virtual-force [
14] based algorithm, the capability of gaining real-time information and knowledge is assumed, therefore the AMR team can interact with low network latency and perform actions in a synchronized way. However, those assumptions are sometimes infeasible in unexplored areas. For example, in some areas, such as disaster hit areas, outer space, battlefields, etc., humans may only have access to limited information. In an area after an earthquake or fire burnt areas, where the roads and buildings are damaged and destroyed, the structure may be significantly changed. Thus, a pre-calculated approach maybe be rendered ineffective or useless. In disaster hit areas or remote planets, where the network latency is unpredictable, robots will take an extremely long time to communicate. Thus, an accurate synchronization cannot be achieved by the team and real-time information cannot be updated instantly.
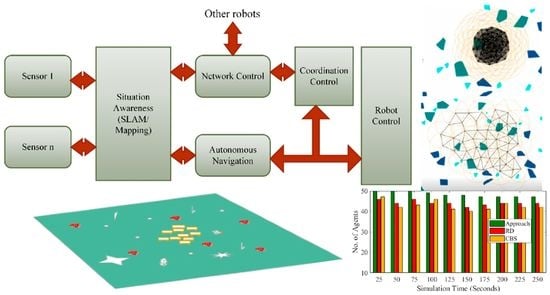
In this paper, we present a decentralized deployment strategy for robot teams taking into account the above issues. The main idea underlies that, the multiple AMR team deployment problem is a multi-agent coordination problem. Through coordination, the asynchronous robots are coupled and they can decide how to cooperatively complete their mission. In order to reduce the communication cost in a large scale team, a decentralized approach is proposed. This proposed approach has three advantages. Firstly, this approach does not require any previously known information about the deploying area, in other words, robots only need to gain the knowledge about the environment when they are situated in the environment. Secondly, decentralized approach does not need a powerful system to achieve global observation, information or states of the whole team, as each mobile robot only has local observation. Thirdly, an AMR team applying a decentralized approach needs only to communicate with physically local neighbors through message exchange, resulting in simple protocols and cheap communication resource consumption among the AMR team.
On the other hand, the technological advancement in land, aerial and marine robotics as purpose-built systems are making the use of multi-agent teams to support various operations and missions by deploying several mobile agents for area coverage and temporal communication networks formation in recent years possible. This is attributed to the fact that multi-agent teams can outperform a single agent for the same task while enabling flexibility, reduced operational cost and efficiency. Multi-agent teams can be used in a variety of complex missions and operations such as: surveillance and communication in unknown and dynamic environments (i.e., disaster hit areas, remote planets), environmental monitoring (i.e., deployment and monitoring in remote planet, forests, and disaster areas) and operations in law enforcement missions such as border patrols, etc. Several approaches have been proposed in the literature to tackle the mobile robots/sensor deployment for operations support and optimal area coverage and mapping using a team of mobile agents. These have resulted in various solutions ranging from machine learning to bio-inspired approaches. Our approach is inspired by the working mechanism of the biological immune system to perform deployment and coverage using tokens by deciding who, when and how to act during deployment process to ensure robust connectivity and coverage of the team.
The artificial immune system (AIS) is a typical multi-agent and decentralized information processing system inspired by the working mechanisms exhibited by the biological immune system [
15,
16], which is adaptive. The advantages of high parallelism, distributed operation, strong adaptability, and self-organization exhibited by the biological immune system has inspired various theories and models that represent the different aspects proposed under the artificial immune system, such as the immune network [
17] and danger theory [
18], and several applications have been demonstrated based on these theories [
19].
The immune network theory is a critical theory of the artificial immune system that exhibits characteristics of adaptiveness of the immune system. The immune network theory proposed by Jerne [
17] suggests that the immune system is capable of achieving immunological memory by the presence of a mutually reinforcing network of B-Cells that produces an interaction mechanism between network cells. Jerne’s theory stipulates that this network would be self-regulating through stimulatory and suppressive interaction. This interaction is as a result of the idiotope of one antibody being recognized by the paratope of another antibody with or without the presence of an antigen that possesses an epitope. The recognized antibody is suppressed while the recognizer antibody is simulated. In the robotics domain, a computational model of Jerne’s idiotypic network theory has been proposed in [
16] as a means of inducing adaptive behavior mediation and has demonstrated some encouraging results. In these idiotypic networks, competence modules are mapped to both environmental stimuli (antigens) and to each other, leading to the formation of a dynamic chain of stimulation and suppression that influence their concentration levels globally.
On the other hand, the concept of danger theory [
18] stipulates that, in other to properly contain attacks, the immune system responds to harmful and dangerous events that causes damage to cells. This danger signals from the damaged cells forms a danger zone that attracts the attention of the concerned immune cells. The attracted cells get stimulated and undergo clonal expansion to contain the attack. Consequently, the danger theory assumes that the immune system is activated by danger signals that are emitted by damaged cells, i.e., cells affected by foreign agents or with mechanical damage.
Comparatively, the multi-agent deployment coordination control is similar in characteristics with those in the biological immune system since both require coordination and adaptive control of agent’s behaviors in a dynamic or unknown environment. In our approach, we combined immune-based methods with token-based approach to find an appropriate amount of suppression and simulation of behaviors to response to situations during agents deployment, in addition to adapting the internal mechanism of each agent so that agents are adaptive to situations in the environment. The robots decisions for providing efficient mobility support are achieved with an intersection of token messages exchange, immune network theory and danger theory. We show that, deployment problem can be solved through multi-agent decentralized coordination, implementing coupling of asynchronous robots. The proposed approach enables individual agents of the team to consider theirs situational information and tokens from other agents to improve movement decisions such as the direction and distances to moved. In addition, as the communication cost of the large-scale agent team is expensive, if token message can be passed optimally, it can reach the destination with minimum distance and the overall communication cost of for agents’ coordination can be minimized. The concept of danger theory and immune network is used to minimize the overall communication cost by determining an adaptive token generation and passing in the the agent team.
The remainder of this paper is organized as follows: In
Section 2, we discussed the background of decentralized coordination and related deployment approaches from the literature.
Section 3 introduces the problem description and scenario. In
Section 4, we provide our decentralized coordination approach for deployment where the modeling of the deployment problem and our decentralized algorithm is proposed. Next, in
Section 5, the empirical analysis to evaluate the performance of the proposed algorithm is presented through experiments. Finally,
Section 6 and
Section 7 discuss and summarizes the main contributions of this work.
2. Related Work
Mobile systems deployment and coverage maximization approaches have been widely studied in the literature for different application scenarios. In the study of improving the efficiency and connectivity in mobile wireless sensors and robotics networks, a relevant functional requirement is to maximize the coverage while maintaining connectivity with other nodes of the network and/or with a base station in the region of interest by employing proper deployment of sensors. By adopting a centralized approach, energy efficient deployment algorithms based on multi-objective immune algorithm were presented in [
20,
21]. In the first approach, the authors present an immune-based node deployment algorithm that takes into consideration mobility and coverage cost. While in their second approach, voronoi diagram was introduced to complement the immune-based approach by using it to adjust sensing nodes. However, despite considering energy efficiency, mobility and redundant coverage, this approaches is centralized and might suffer from usual problems of centralized approaches. In [
22], a distributed movement assisted sensor deployment algorithm is presented to enhance area coverage in a distributed mobile sensor network. The Edge Based Centroid algorithm adopted in their work moves sensor nodes towards the centroid of the local Voronoi polygon from the initial deployment position. A dispersion movement algorithm for multi-robot systems that uses the number of communication links of each individual robot for movement control is proposed in [
23]. Reference [
24] presents a holistic connectivity controller (HCC) to regulate and restore inter-agent connections during the dispersion of the mobile network. In [
25], a dispersion algorithm based on wireless signal intensities is proposed. The signal intensities are modeled by employing a sampling technique, which takes into consideration both the distance and relative orientations of the wireless sensor. Similar approaches that use the strength of the robots’ radio signals and the gradient descent algorithm to achieve a swarm dispersion are presented in [
26,
27].
Further more, authors in [
28] studied the coverage of specific zones of interest that can change dynamically over time by using a swarm of flying robots. The mobility of the flying devices is achieved through particle swarm optimization and virtual forces algorithm. In this approach, flying robots only require the local information from the neighbors to update their velocity and trajectory. A collaborative complete coverage and path planning approach for single robot and multi-robot systems where the coverage from a robot movement is maximized by a a novel cost function and goal selection function to facilitate collaborative exploration for a multi-robot system is proposed in [
29]. The proposed method is able to optimize the overall coverage efficiency by considering local gains from individual robots and the global gain by the goal selection function. A decentralized deployment process for wireless mobile sensor networks focused on deployment efficiency, connectivity maintenance and network reparation is discussed in [
30]. In [
31], a novel distributed algorithm for deploying multiple robots in an unknown two-dimensional (2D) area to achieve complete blanket coverage is presented. A redeployment scheme based an artificial immune systems for wireless mobile sensor nodes initially deployed randomly is proposed in [
32]. The authors employ artificial immune systems inspired approach to calculate the appropriate positions for sensors to redeploy. A comprehensive review of various evolutionary algorithms employed for deploying sensor nodes at optimized positions in wireless sensor networks is presented [
33].
In this paper, we treat the mobile robot deployment problem as multi-agent coordination problem and approach it from a perspective which differ from previous work. Our coordination approach implements the coupling of the asynchronous agents, addressing three problems of the previous work. The first problem of some previous studies is that deployed robots focus on their own observations and knowledge to make decision and then act (e.g., calculate neighbor’s and obstacle’s locations and orientations then choose a position to move). However, some trivial but essential information for the teams is ignored. For example, if one robot observes that it is situated in a location that is blocked by obstacles, then its best choice is to inform other vehicles about this fact, and thus prevent other agents unnecessarily accessing this corner, rather than just leave this corner itself. That information can be obtained and shared through coordination and the whole team will get more useful information for deployment, and thus helps the team make more efficient and useful decisions.
Another problem is the connectivity loss problem, this is because robots have no extra information about others’ potential actions. When robots start to execute a moving action, they have no idea of the consequent configuration of the network. In a connected network, for example, even if only two neighboring robots move simultaneously, the resulting connected network may lead to two separated components. However, those two robots may not notice the fact because they still maintain the connection with some other robots. Another example in simultaneous moving strategy is that if robots observe that there is no connected neighbor, it may try to move back to the previous location to find neighbors. However, due to the location changes of other vehicles, it might be difficult to find a neighbor. Through coordination, robots can get information from other robots, which provides knowledge (local network topology, others’ neighbor lists, etc.) for making more sensible decisions. For example, based on this information, robots can decide to choose the suitable robots to move or a suitable distance and direction to move in order to eliminate the possibility of connectivity loss. Similarly, during the movement of some robots, other robots can decide to stay in the current locations to wait for the feedback of the moving robots, thus even when an agent observes the connectivity loss, it can relocate to the previous locations to connect with those staying robots to prevent the connectivity loss.
An individual robot also may not be able predict the utility brought to the whole team after some actions, leading to energy waste because those actions actually bring no utility improvement to the whole team. This is because of their limited local observation. In a swarm-inspired algorithm for deployment, for example, obviously the utility can be significantly improved by the location changes of the boundary robots, but in existing approaches such as [
14], the boundary robots and inner robots are based on the same rules to move. After several periods of the location adjustment, some inner robots’ locations remain approximately unchanged, but they have consumed some resources trembling between the original location. By coordinating, it is practical for the robot team to decide and act more feasibly, such as which robots is more appropriate to move, or where and how to move in order to increase the team’s utility.
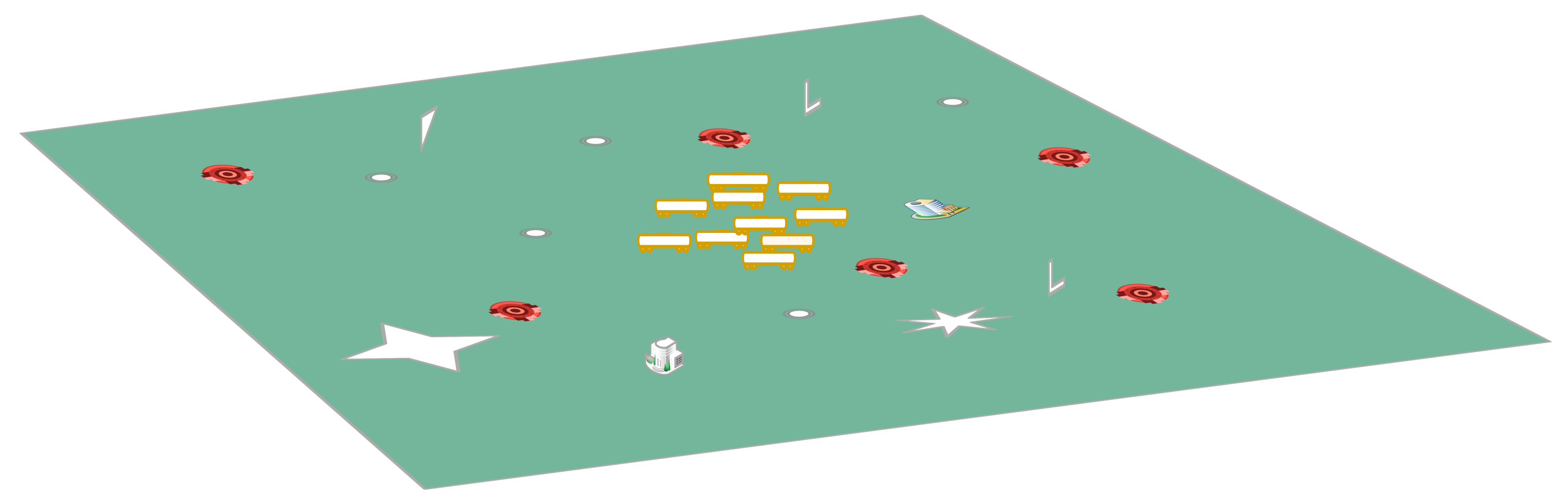
3. Multi-Robot Network Deployment Problem
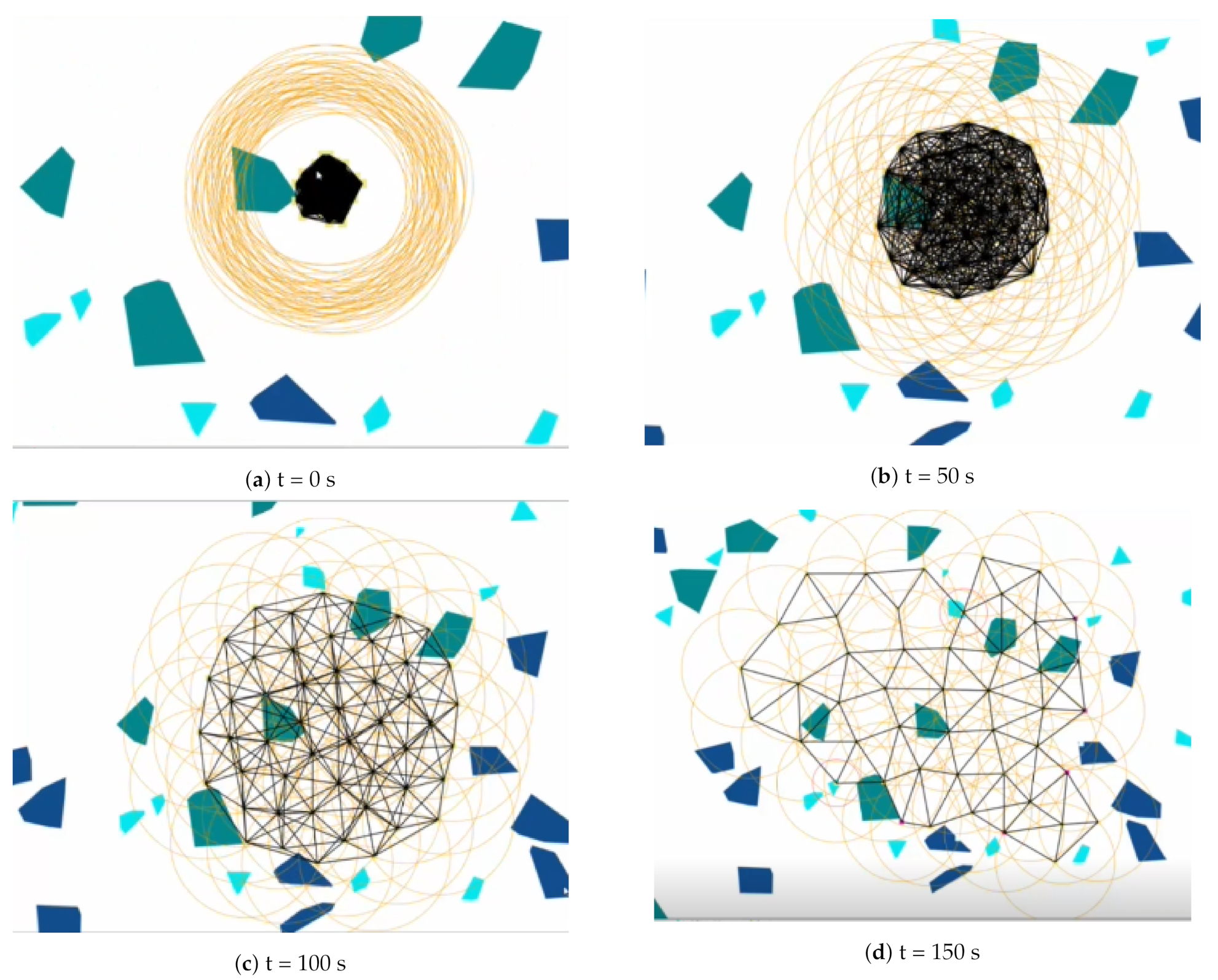
At the initial step, there is a team of mobile agents, placed at initial drop off point in an unexplored or surveillance region ∪, do be dispersed to cover a task area such as burnt region, outer space, or battlefields. ∪ may contain a set of different entities or no go areas. The first kind of entity is areas where agent should not move into (e.g., burning area, collapsed structures, holes in the roads), which is called risked or dangerous areas. Agents are not willing to enter those areas as they may lead to unpredictable damage to agents. The second kind of entity are obstacles which agents cannot pass through (e.g., buildings, stones). Certain entities will have some impacts on robots. For example, a metallic wall situated between two robots will weaken the wireless signal strength. If a robot enters a trap region, it may be damaged and no longer be useful or movable. The goal of the team is to gradually adjust their locations through moving, and finally achieve some fixed configuration. An ad hoc network will be formed by the team, which can be utilized or provide support for other operations. We use the term deployment to describe this adjustment phase of the team.
After the multi-robot team finishes deployment and finally forms an ad hoc network or a surveillance map, the performance of the system can be evaluated based on three factors. The first factor is the energy consumption of the team. Energy is used to move, communicate, sense and afterwards apply. If a robot spends too much energy for deployment, then it will not have sufficient energy for later application or actual task execution. The second factor is the time consumption, . Time is often essential in some emergent cases, such as search and rescue in large disasters. The third factor that needs to be taken into account is the quality of the final ad hoc network Q, which can be evaluated by two key factors. The first being the total coverage of the ad hoc network, where the coverage is defined as the joint areas covered by the whole team. In supporting rescue teams and firefighters, for example, the robots’ goal will be to maximize the coverage area in order to increase the probability to detect victims or identify danger to first responders. Another factor is the connectivity of the network. Basically, we require the deployed systems must be connected, if there are several components, some pairs of the agents might loose connection. In a communication system for example, this lost of connection might splits the whole network into many separate parts. Thus, leading to disastrous outcomes (e.g., the communication system is no longer serviceable). We also need network’s robustness to evaluate connectivity, as the network with bad robustness will lead to expensive communication energy consumption. For example, if one network is formed like a straight line then the communication cost is undesirable high. However, there is always a trade-off between coverage and connectivity.
The goal of the deployed systems is to maximize communication or sensing coverage while maintaining connectivity within limited communication and movement energy. Every robot hopes to keep connection with at least
agents for robustness. So, we define team’s weighted utility function and the evaluating terms for utility function as shown in Equation (
1);
is defined as the joint communication coverage of the whole robot team, a robot
’s communication coverage is a circle with center in position of
and radius
. On the other hand,
, represents the connectivity loss penalty while the
is the numbers of component of the formed ad hoc network. For example, if there is only a component then the penalty is zero (0).
is sum of the robustness loss penalty of all the robots while the robustness penalty for a robot
is described as the difference between
and its neighbor’s size
as shown in Equation (
2). If its neighbor’s size is greater then
, then the robustness penalty is zero. Here,
is a robustness factor defined as the minimum number of neighbors robot
should keep connection with. Based on our problem definition, we set
to 1, and
to a factor
according to the specific scenario. We set
to
∞ (such that
) because the aim is to obtain a connected network.
6. Discussion
The fundamental problem of mobile agents deployment for coverage with connectivity constraints is how to establish decentralized coordination among the multiple agents team and how to control their movement and behavior to achieve a desired configuration. This becomes more challenging with the absence of GPS for positions and navigation. With the absence or access to GPS, robots can only perform local localization by sending hello messages out and estimate their neighbor size and relative locations based on the responses they get in return. This mechanism is a key requirement that can facilitate robots deployment when services are incapacitated during disasters.
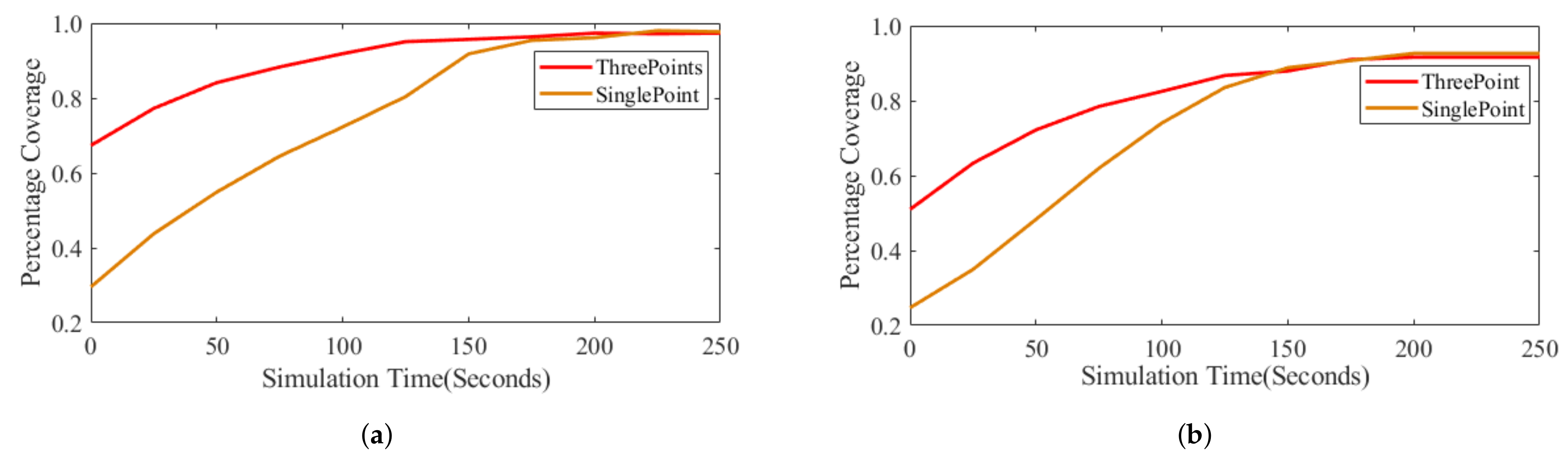
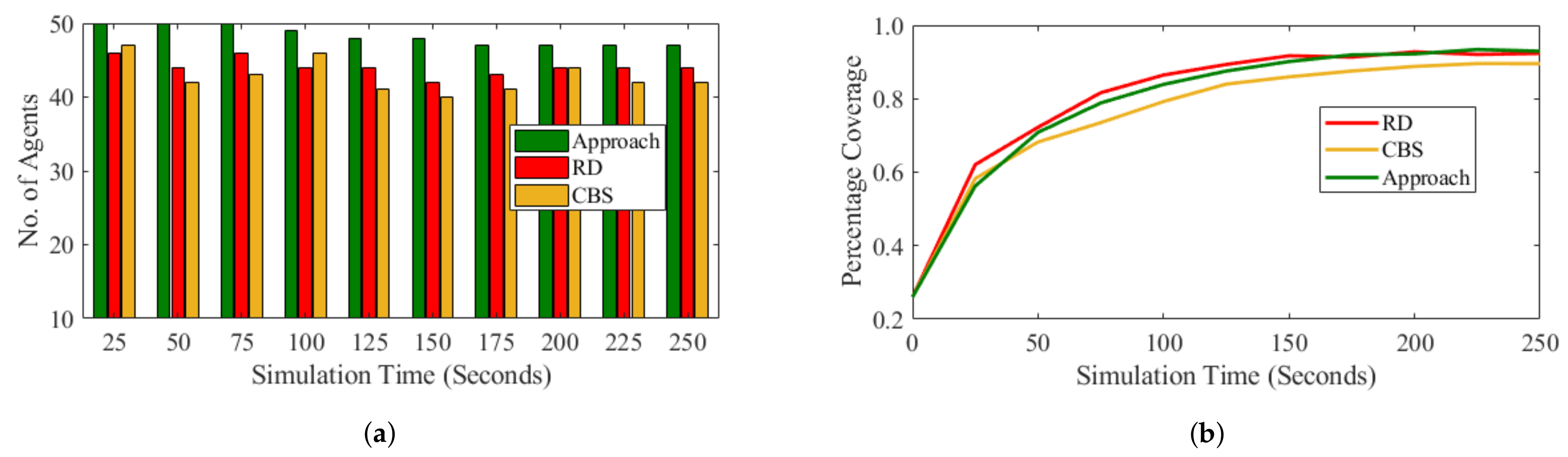
The approach presented in this paper enabled the successful deployment of mobile robots to achieve maximum coverage while meeting a connectivity constraints. While the approach presented in this work achieved similar coverage with the approach presented in [
35] and better coverage than the one presented in [
31], our approach outperforms both in terms of the connectivity constraints satisfaction of the mobile robots during and after the final configuration is achieved.
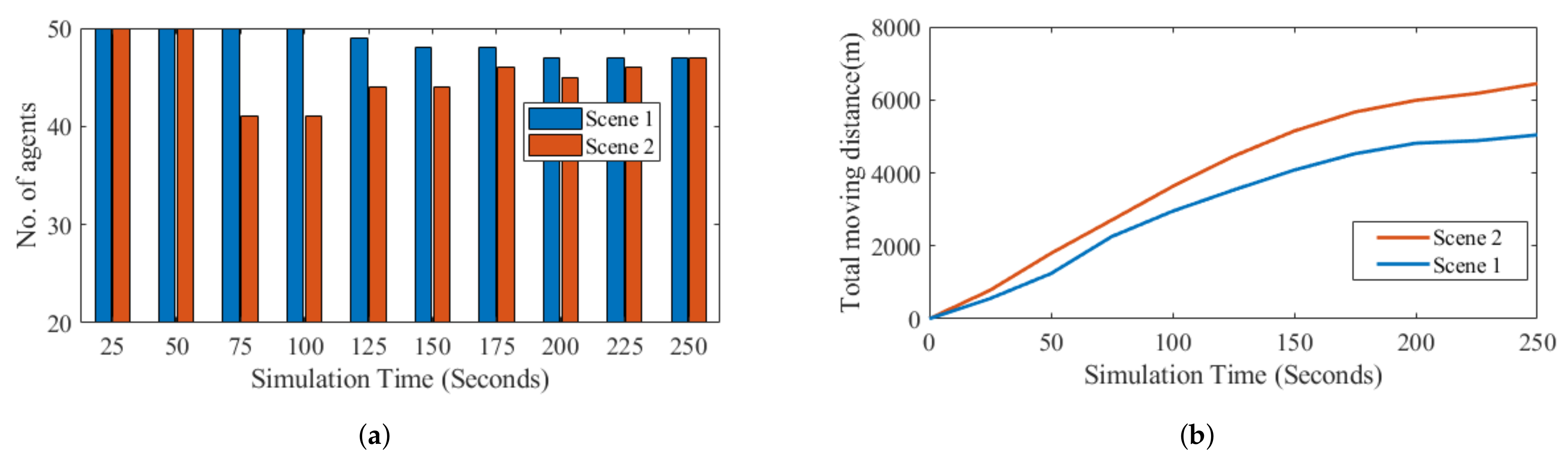
Comparing the centralized and random approach with the approach presented in this work, the two algorithms have more robot losses, less coverage and less moving distance. The less moving distance achieved by both heuristic centralized and random approaches can be attributed to the significant number of ineffective robots. Total moving distance and connectivity of robots during deployment is affected by the complexity and difficulty level of the environments. Generally, the cumulative distance of the system increases with higher complexity and uncertainty levels of the operating environment. This distance determines the amount energy consumed by the robots during deployments. Furthermore, about to more robots fail to satisfy the connectivity constraints in the obstacle rich environments as compared to deployment in obstacle free environments. Ultimately, there is no significant difference in the robustness and coverage as more robots meet the connectivity constraints of the final configuration in both settings.
While the requirement of the decentralized approach is for robots to exchange information, which may increase the amount of message exchange and energy consumption, the information exchange is essential for efficient deployment and reduce robots loss as shown in
Table 1. By sending out information tokens, our approach was able to reduce number of ineffective robots and achieve higher effective coverage.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}