
YOLO-RTUAV: Towards Real-Time Vehicle Detection through Aerial Images with Low-Cost Edge Devices




Abstract
:1. Introduction
2. Related Works
- The vehicle in the image is small in size. For example, a px image may contain multiple vehicles of size less than px;
- A large number of objects in a single view. A single image could contain up to hundreds of vehicles in a parking lot;
- High variation. Images taken with different altitudes will present objects of the same class with different features. For example, when the altitude is high, a vehicle will be viewed as a single rectangular object and is difficult to differentiate;
- Highly affected by the illumination condition and occlusions. Reflection due to sunlight and background noise such as trees and buildings would render the object unobserved.
3. Methodology
3.1. Object Detection Algorithm
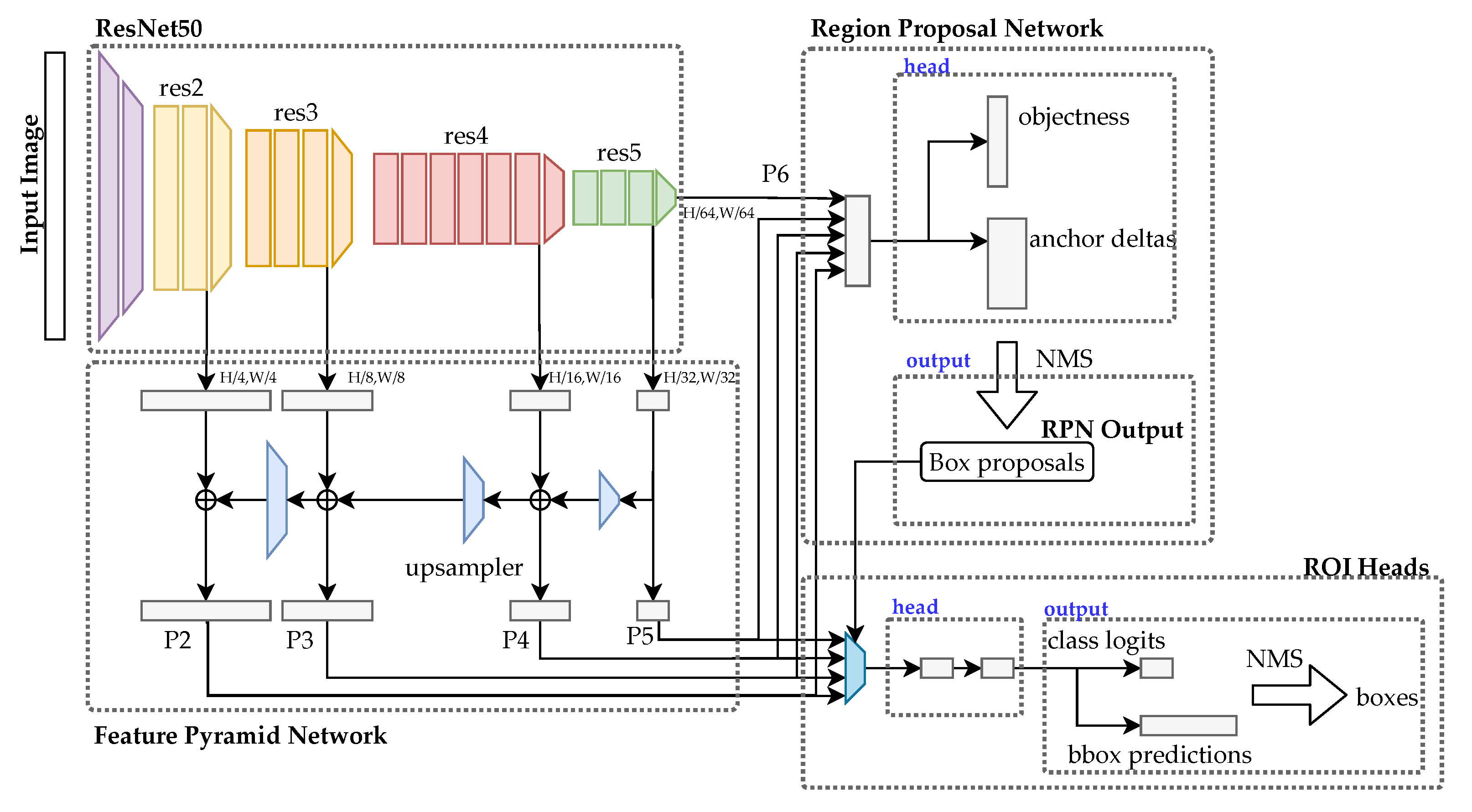
3.1.1. Two-Stage Detector: Faster R-CNN
3.1.2. One-Stage Detector: You Only Look Once
3.2. Proposed Model: YOLO-RTUAV
- Detect small objects in aerial images;
- Efficient, yet accurate for real-time detection in low-end hardware;
- Small in size and reduced in parameters.
- Changing the output network to a larger size, allowing smaller objects to be detected;
- Usage of Leaky ReLU over the Mish activation function [63] in the convolutional layers to reduce the inference time. The backbone remains the same as the original YOLOv4-Tiny, which is CSPDarknet-19;
- Usage of several convolutional layers to reduce the complexity of the models;
- DIoU-NMS is used to reduce suppression error and lower the occurrence of missed detection;
- Complete IoU loss is used to accelerate the training of the model and improve the detection accuracy;
- Mosaic data augmentation is used to reduce overfitting and allows the model to identify smaller-scale objects better.
4. Experiment Settings
4.1. Dataset Description
4.1.1. VAID Dataset
4.1.2. COWC Dataset
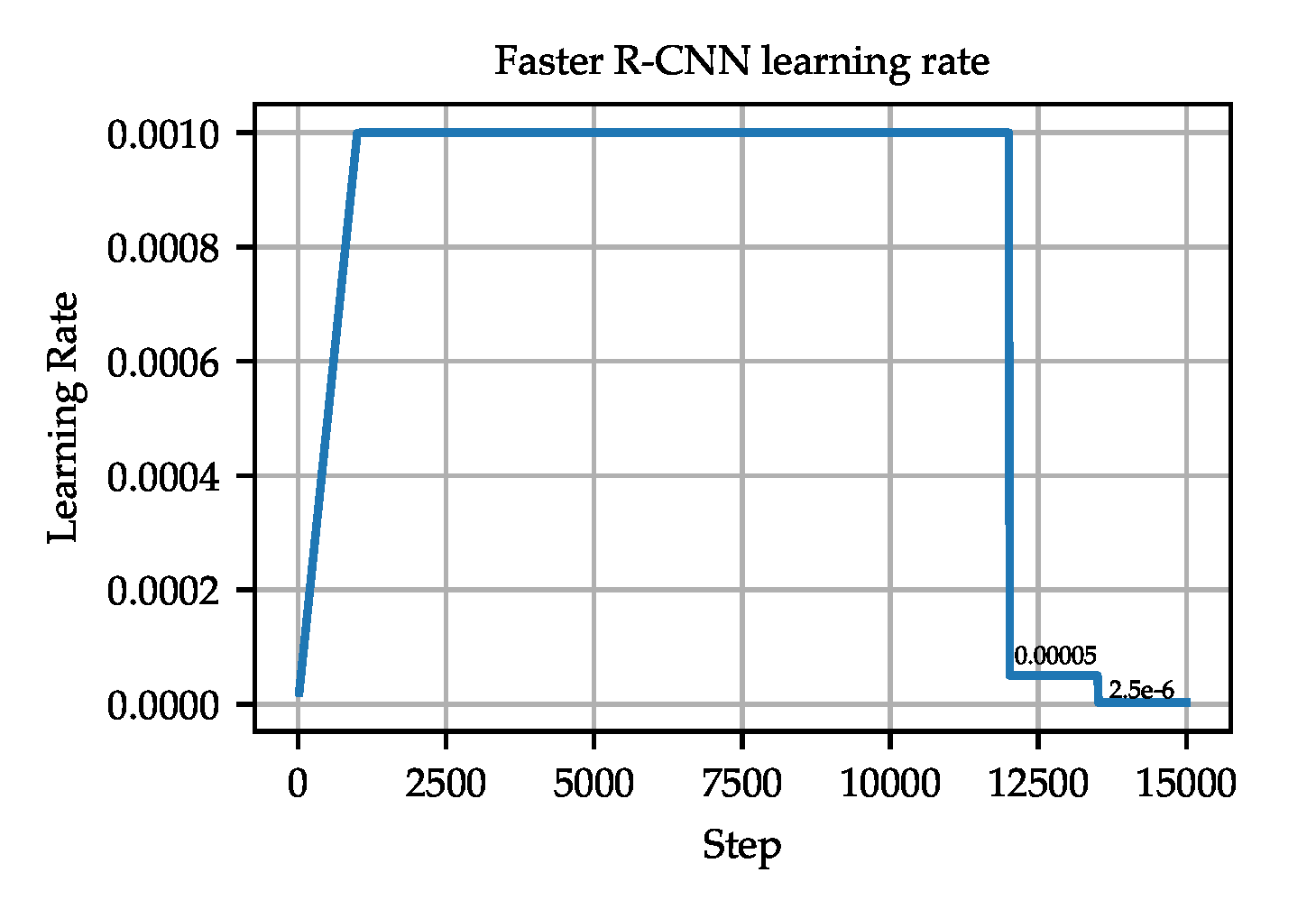
4.2. Experimental Setup
4.3. Evaluation Criteria and Metrics
- The IoU measuring the overlap between the predicted and the ground truth bounding boxes, as discussed in Equation (2);
- The main evaluation metric used in evaluating object detection models is mAP. mAP provides a general overview of the performance of the trained model. A higher mAP represents better detection performance. Equation (8) shows how mAP is calculated;where is the average precision for the i-th class and C is the total number of classes. corresponds to the area under the PR curve and is calculated as shown in Equation (9):where and is the recall ratio and precision ratio when the n-th threshold is set. Usually, and represents the AP (single class) calculated with the IoU set as 0.5 and 0.75, respectively. is the average value of AP with the IoU ranging from 0.5 to 0.95 with a step of 0.05. , , and , on the other hand, represent the average APs of all classes at different settings of the IoU;
- Besides mean average precision (mAP), precision, recall, and the F1-score are also common criteria for model evaluation. The computations are as follows:where , , and represent true positive, false positive, and false negative, respectively;
- The precision–recall curve (PR curve) plots the precision against the recall rate. As the confidence index is set to a smaller value, the recall increases, signaling more objects to be detected, while the precision decreases since false positive objects increase. The PR curve is useful to visualize the performance of a trained model. A perfect score would be at , where both precision and recall is at 1. Therefore, if a curve bows towards , the model performs very well;
- Number of frames per second (FPS) and inference time (in milliseconds) to measure the processing speed.
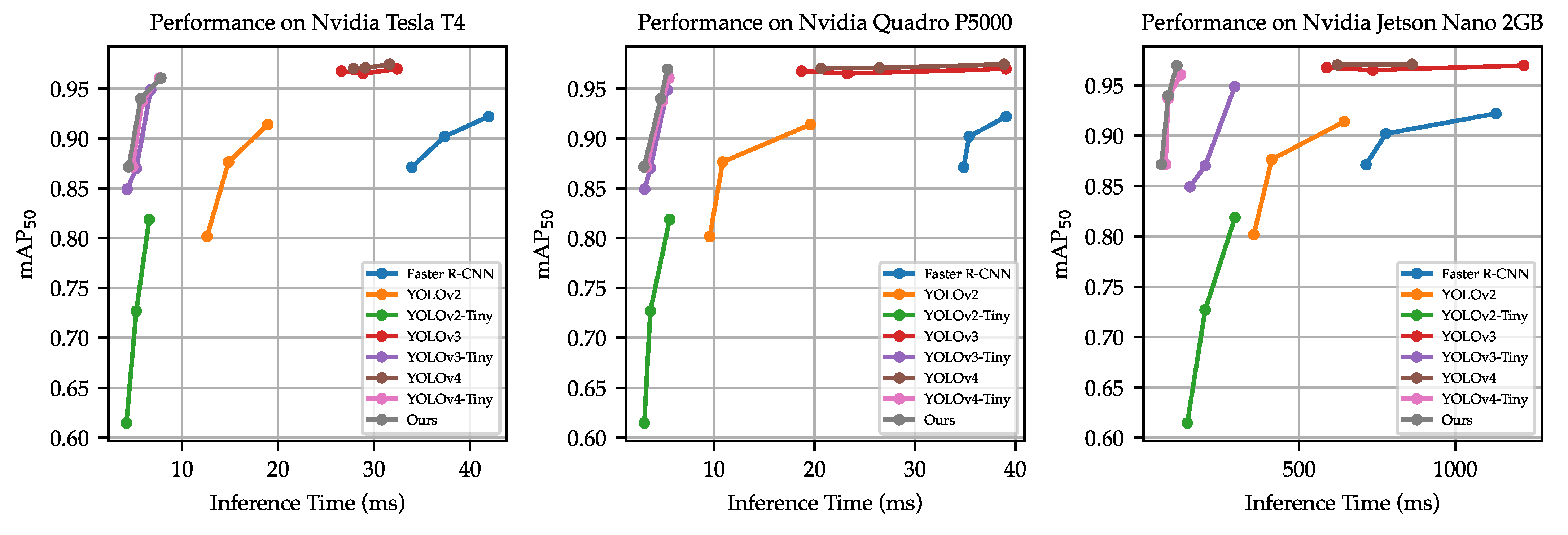
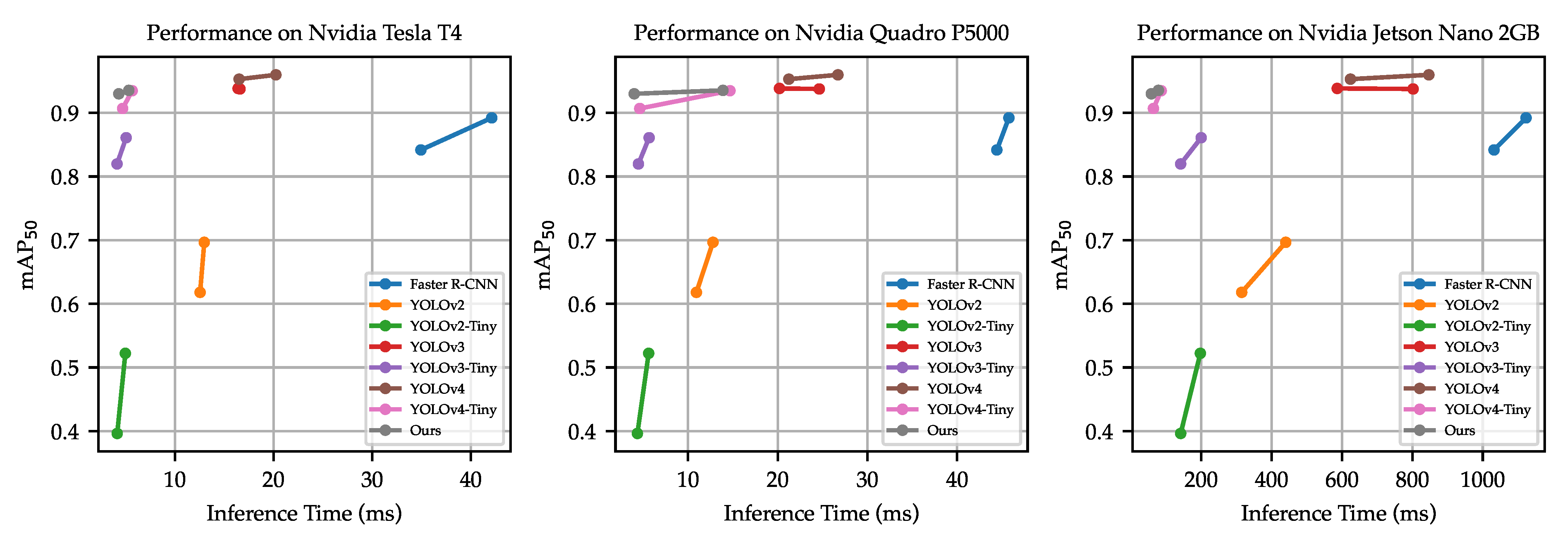
5. Results and Discussion
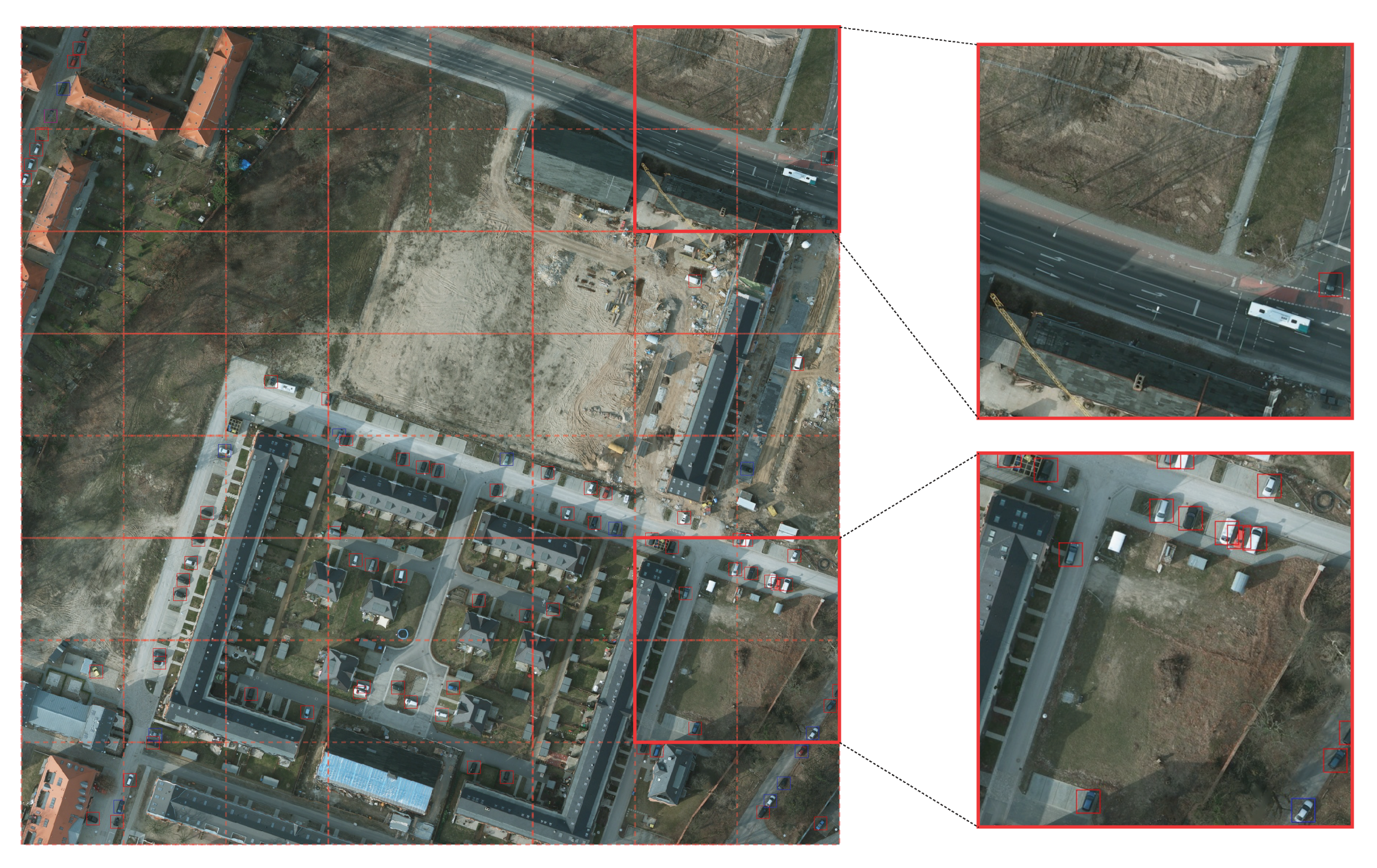
5.1. VAID Dataset
5.2. COWC Dataset
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. YOLO-RTUAV Design Process


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Naive Solution | Ours | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Layer | Type | Filter | Size/Stride | Input Size | Output Size | BFLOPs | Type | Filter | Size/Stride | Input Size | Output Size | BFLOPs |
| 0 | Convolutional | 32 | / 2 | 0.113 | Convolutional | 32 | / 2 | 0.113 | ||||
| 1 | Convolutional | 64 | / 2 | 0.604 | Convolutional | 64 | / 2 | 0.604 | ||||
| 2 | Convolutional | 64 | / 1 | 1.208 | Convolutional | 64 | / 1 | 1.208 | ||||
| 3 | Route 2 | Route 2 | ||||||||||
| 4 | Convolutional | 32 | / 1 | 0.302 | Convolutional | 32 | / 1 | 0.302 | ||||
| 5 | Convolutional | 32 | / 1 | 0.302 | Convolutional | 32 | / 1 | 0.302 | ||||
| 6 | Route 5 4 | Route 5 4 | ||||||||||
| 7 | Convolutional | 64 | / 1 | 0.134 | Convolutional | 64 | / 1 | 0.134 | ||||
| 8 | Route 2 7 | Route 2 7 | ||||||||||
| 9 | Maxpool | / 2 | 0.002 | Maxpool | / 2 | 0.002 | ||||||
| 10 | Convolutional | 128 | / 1 | 1.208 | Convolutional | 128 | / 1 | 1.208 | ||||
| 11 | Route 10 | Route 10 | ||||||||||
| 12 | Convolutional | 64 | / 1 | 0.302 | Convolutional | 64 | / 1 | 0.302 | ||||
| 13 | Convolutional | 64 | / 1 | 0.302 | Convolutional | 64 | / 1 | 0.302 | ||||
| 14 | Route 13 12 | Route 13 12 | ||||||||||
| 15 | Convolutional | 128 | / 1 | 0.134 | Convolutional | 128 | / 1 | 0.134 | ||||
| 16 | Route 10 15 | Route 10 15 | ||||||||||
| 17 | Maxpool | / 2 | 0.001 | Maxpool | / 2 | 0.001 | ||||||
| 18 | Convolutional | 256 | / 1 | 1.208 | Convolutional | 256 | / 1 | 1.208 | ||||
| 19 | Route 18 | Route 18 | ||||||||||
| 20 | Convolutional | 128 | / 1 | 0.302 | Convolutional | 128 | / 1 | 0.302 | ||||
| 21 | Convolutional | 128 | / 1 | 0.302 | Convolutional | 128 | / 1 | 0.302 | ||||
| 22 | Route 21 20 | Route 21 20 | ||||||||||
| 23 | Convolutional | 256 | / 1 | 0.134 | Convolutional | 256 | / 1 | 0.134 | ||||
| 24 | Route 18 23 | Route 18 23 | ||||||||||
| 25 | Convolutional | 27 | / 1 | 0.038 | Convolutional | 36 | / 1 | 0.038 | ||||
| 26 | YOLO | YOLO | ||||||||||
| 27 | Route 25 | Route 25 | ||||||||||
| 28 | Convolutional | 256 | / 1 | 0.019 | Convolutional | 256 | / 1 | 0.019 | ||||
| 29 | Upsample | Upsample | ||||||||||
| 30 | Route 16 | |||||||||||
| 31 | Convolutional | 128 | / 1 | 0.268 | ||||||||
| 32 | Route 29 16 | Route 31 29 | ||||||||||
| 33 | Convolutional | 512 | / 1 | 19.327 | Convolutional | 256 | / 1 | 0.805 | ||||
| 34 | Convolutional | 36 | / 1 | 0.151 | Convolutional | 36 | / 1 | 0.075 | ||||
| 35 | YOLO | YOLO | ||||||||||
| Model | Input Size | Model Size | BFLOPs | # Param | Precision | Recall | F1 Score | Inference Time (ms) | |||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Tesla T4 | Quadro P5000 | Jetson Nano | |||||||||
| (a) VAID dataset | |||||||||||
| Naive | 14.7MB | 17.23 | 3.68M | 0.8754 | 0.9686 | 0.5770 | 0.7232 | 5.37 | 4.48 | 80.02 | |
| Naive | 14.7MB | 26.09 | 3.68M | 0.9463 | 0.9699 | 0.8795 | 0.9225 | 6.88 | 5.17 | 99.31 | |
| Naive | 14.7MB | 36.80 | 3.68M | 0.9612 | 0.9637 | 0.9465 | 0.9550 | 9.36 | 7.57 | 128.32 | |
| Ours | 5.8MB | 5.13 | 1.44M | 0.8715 | 0.9646 | 0.5686 | 0.7154 | 4.42 | 3.01 | 59.13 | |
| Ours | 5.8MB | 7.77 | 1.44M | 0.9398 | 0.9658 | 0.8714 | 0.9162 | 5.67 | 4.67 | 80.98 | |
| Ours | 5.8MB | 10.95 | 1.44M | 0.9602 | 0.9602 | 0.9433 | 0.9517 | 7.78 | 5.36 | 108.46 | |
| (b) COWC dataset | |||||||||||
| Naive | 14.7 MB | 17.19 | 3.67M | 0.9345 | 0.9001 | 0.9536 | 0.9261 | 5.18 | 14.48 | 79.81 | |
| Naive | 14.7 MB | 26.09 | 3.68M | 0.9405 | 0.8989 | 0.9625 | 0.9296 | 6.59 | 14.05 | 98.21 | |
| Ours | 5.7 MB | 5.10 | 1.43M | 0.9299 | 0.8772 | 0.9422 | 0.9085 | 4.32 | 4.00 | 58.36 | |
| Ours | 5.7 MB | 7.73 | 1.43M | 0.9353 | 0.8853 | 0.9552 | 0.9189 | 5.33 | 13.89 | 78.33 | |
References
- Scherer, J.; Yahyanejad, S.; Hayat, S.; Yanmaz, E.; Andre, T.; Khan, A.; Vukadinovic, V.; Bettstetter, C.; Hellwagner, H.; Rinner, B. An autonomous multi-UAV system for search and rescue. In Proceedings of the First Workshop on Micro Aerial Vehicle Networks, Systems, and Applications for Civilian Use, Florence, Italy, 19–22 May 2015; pp. 33–38. [Google Scholar]
- Alotaibi, E.T.; Alqefari, S.S.; Koubaa, A. Lsar: Multi-uav collaboration for search and rescue missions. IEEE Access 2019, 7, 55817–55832. [Google Scholar] [CrossRef]
- Messina, G.; Modica, G. Applications of UAV thermal imagery in precision agriculture: State of the art and future research outlook. Remote Sens. 2020, 12, 1491. [Google Scholar] [CrossRef]
- Liu, S.; Wang, S.; Shi, W.; Liu, H.; Li, Z.; Mao, T. Vehicle tracking by detection in UAV aerial video. Sci. China Inf. Sci. 2019, 62, 24101. [Google Scholar] [CrossRef] [Green Version]
- Song, W.; Li, S.; Guo, Y.; Li, S.; Hao, A.; Qin, H.; Zhao, Q. Meta transfer learning for adaptive vehicle tracking in UAV videos. In Proceedings of the International Conference on Multimedia Modeling, Daejeon, Korea, 5–8 January 2020; pp. 764–777. [Google Scholar]
- Zhao, X.; Pu, F.; Wang, Z.; Chen, H.; Xu, Z. Detection, tracking, and geolocation of moving vehicle from uav using monocular camera. IEEE Access 2019, 7, 101160–101170. [Google Scholar] [CrossRef]
- Green, D.R.; Hagon, J.J.; Gómez, C.; Gregory, B.J. Using low-cost UAVs for environmental monitoring, mapping, and modelling: Examples from the coastal zone. In Coastal Management; Elsevier: Amsterdam, The Netherlands, 2019; pp. 465–501. [Google Scholar]
- Tripolitsiotis, A.; Prokas, N.; Kyritsis, S.; Dollas, A.; Papaefstathiou, I.; Partsinevelos, P. Dronesourcing: A modular, expandable multi-sensor UAV platform for combined, real-time environmental monitoring. Int. J. Remote Sens. 2017, 38, 2757–2770. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. arXiv 2015, arXiv:1506.01497. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.J.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Liu, Y.; Yang, F.; Hu, P. Small-object detection in UAV-captured images via multi-branch parallel feature pyramid networks. IEEE Access 2020, 8, 145740–145750. [Google Scholar] [CrossRef]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pham, M.T.; Courtrai, L.; Friguet, C.; Lefèvre, S.; Baussard, A. YOLO-Fine: One-stage detector of small objects under various backgrounds in remote sensing images. Remote Sens. 2020, 12, 2501. [Google Scholar] [CrossRef]
- Lin, H.Y.; Tu, K.C.; Li, C.Y. VAID: An Aerial Image Dataset for Vehicle Detection and Classification. IEEE Access 2020, 8, 212209–212219. [Google Scholar] [CrossRef]
- Mundhenk, T.N.; Konjevod, G.; Sakla, W.A.; Boakye, K. A large contextual dataset for classification, detection and counting of cars with deep learning. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 785–800. [Google Scholar]
- Ma, B.; Liu, Z.; Jiang, F.; Yan, Y.; Yuan, J.; Bu, S. Vehicle Detection in Aerial Images Using Rotation-Invariant Cascaded Forest. IEEE Access 2019, 7, 59613–59623. [Google Scholar] [CrossRef]
- Raj, S.U.; Manikanta, M.V.; Harsitha, P.S.S.; Leo, M.J. Vacant Parking Lot Detection System Using Random Forest Classification. In Proceedings of the 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; Volume 2019, pp. 454–458. [Google Scholar]
- Zhou, H.; Wei, L.; Lim, C.P.; Creighton, D.; Nahavandi, S. Robust Vehicle Detection in Aerial Images Using Bag-of-Words and Orientation Aware Scanning. IEEE Trans. Geosci. Remote Sens. 2018, 56, 7074–7085. [Google Scholar] [CrossRef]
- Liu, K.; Mattyus, G. Fast Multiclass Vehicle Detection on Aerial Images. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1938–1942. [Google Scholar]
- Gleason, J.; Nefian, A.V.; Bouyssounousse, X.; Fong, T.; Bebis, G. Vehicle detection from aerial imagery. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 2065–2070. [Google Scholar]
- Xu, Y.; Yu, G.; Wu, X.; Wang, Y.; Ma, Y. An Enhanced Viola-Jones Vehicle Detection Method From Unmanned Aerial Vehicles Imagery. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1845–1856. [Google Scholar] [CrossRef]
- Chen, Z.; Wang, C.; Wen, C.; Teng, X.; Chen, Y.; Guan, H.; Luo, H.; Cao, L.; Li, J. Vehicle Detection in High-Resolution Aerial Images via Sparse Representation and Superpixels. IEEE Trans. Geosci. Remote. Sens. 2016, 54, 103–116. [Google Scholar] [CrossRef]
- Cao, S.; Yu, Y.; Guan, H.; Peng, D.; Yan, W. Affine-Function Transformation-Based Object Matching for Vehicle Detection from Unmanned Aerial Vehicle Imagery. Remote Sens. 2019, 11, 1708. [Google Scholar] [CrossRef] [Green Version]
- Cao, L.; Luo, F.; Chen, L.; Sheng, Y.; Wang, H.; Wang, C.; Ji, R. Weakly supervised vehicle detection in satellite images via multi-instance discriminative learning. Pattern Recognit. 2017, 64, 417–424. [Google Scholar] [CrossRef]
- Tong, K.; Wu, Y.; Zhou, F. Recent advances in small object detection based on deep learning: A review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Srivastava, S.; Narayan, S.; Mittal, S. A survey of deep learning techniques for vehicle detection from UAV images. J. Syst. Archit. 2021, 117, 102152. [Google Scholar] [CrossRef]
- Eggert, C.; Brehm, S.; Winschel, A.; Zecha, D.; Lienhart, R. A closer look: Small object detection in faster R-CNN. In Proceedings of the 2017 IEEE International Conference on Multimedia and Expo (ICME), Hong Kong, China, 10–14 July 2017; Volume 2017, pp. 421–426. [Google Scholar]
- Cao, C.; Wang, B.; Zhang, W.; Zeng, X.; Yan, X.; Feng, Z.; Liu, Y.; Wu, Z. An Improved Faster R-CNN for Small Object Detection. IEEE Access 2019, 7, 106838–106846. [Google Scholar] [CrossRef]
- Ren, Y.; Zhu, C.; Xiao, S. Small Object Detection in Optical Remote Sensing Images via Modified Faster R-CNN. Appl. Sci. 2018, 8, 813. [Google Scholar] [CrossRef] [Green Version]
- Guan, L.; Wu, Y.; Zhao, J. SCAN: Semantic Context Aware Network for Accurate Small Object Detection. Int. J. Comput. Intell. Syst. 2018, 11, 936–950. [Google Scholar] [CrossRef] [Green Version]
- Cao, G.; Xie, X.; Yang, W.; Liao, Q.; Shi, G.; Wu, J. Feature-fused SSD: Fast detection for small objects. In Proceedings of the Ninth International Conference on Graphic and Image Processing (ICGIP 2017), Qingdao, China, 14–16 October 2017; Volume 10615. [Google Scholar]
- Cui, L.; Ma, R.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Xu, M. MDSSD: Multi-scale deconvolutional single shot detector for small objects. Sci. China Ser. Inf. Sci. 2020, 63, 120113. [Google Scholar] [CrossRef] [Green Version]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-Shot Refinement Neural Network for Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4203–4212. [Google Scholar]
- Yang, M.Y.; Liao, W.; Li, X.; Rosenhahn, B. Deep Learning for Vehicle Detection in Aerial Images. In Proceedings of the 2018 25th IEEE International Conference on Image Processing (ICIP), Athens, Greece, 7–10 October 2018; pp. 3079–3083. [Google Scholar]
- Sommer, L.; Schumann, A.; Schuchert, T.; Beyerer, J. Multi Feature Deconvolutional Faster R-CNN for Precise Vehicle Detection in Aerial Imagery. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 635–642. [Google Scholar]
- Zhong, J.; Lei, T.; Yao, G. Robust Vehicle Detection in Aerial Images Based on Cascaded Convolutional Neural Networks. Sensors 2017, 17, 2720. [Google Scholar] [CrossRef] [Green Version]
- Rajput, P.; Nag, S.; Mittal, S. Detecting Usage of Mobile Phones using Deep Learning Technique. In Proceedings of the 6th EAI International Conference on Smart Objects and Technologies for Social Good, Antwerp, Belgium, 14–16 September 2020; pp. 96–101. [Google Scholar]
- Tang, T.; Deng, Z.; Zhou, S.; Lei, L.; Zou, H. Fast vehicle detection in UAV images. In Proceedings of the 2017 International Workshop on Remote Sensing with Intelligent Processing (RSIP), Shanghai, China, 19–21 May 2017; pp. 1–5. [Google Scholar]
- Sommer, L.; Nie, K.; Schumann, A.; Schuchert, T.; Beyerer, J. Semantic labeling for improved vehicle detection in aerial imagery. In Proceedings of the 2017 14th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Lecce, Italy, 29 August–1 September 2017; pp. 1–6. [Google Scholar]
- Xie, X.; Yang, W.; Cao, G.; Yang, J.; Zhao, Z.; Chen, S.; Liao, Q.; Shi, G. Real-Time Vehicle Detection from UAV Imagery. In Proceedings of the 2018 IEEE Fourth International Conference on Multimedia Big Data (BigMM), Xi’an, China, 13–16 September 2018; pp. 1–5. [Google Scholar]
- Yang, J.; Xie, X.; Yang, W. Effective Contexts for UAV Vehicle Detection. IEEE Access 2019, 7, 85042–85054. [Google Scholar] [CrossRef]
- Carlet, J.; Abayowa, B. Fast Vehicle Detection in Aerial Imagery. arXiv 2017, arXiv:1709.08666. [Google Scholar]
- Ammour, N.; Alhichri, H.S.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M.A.A. Deep Learning Approach for Car Detection in UAV Imagery. Remote Sens. 2017, 9, 312. [Google Scholar] [CrossRef] [Green Version]
- Audebert, N.; Saux, B.L.; Lefèvre, S. Segment-before-detect: Vehicle detection and classification through semantic segmentation of aerial images. Remote Sens. 2017, 9, 368. [Google Scholar] [CrossRef] [Green Version]
- Huang, R.; Pedoeem, J.; Chen, C. YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 2503–2510. [Google Scholar]
- Zhang, P.; Zhong, Y.; Li, X. SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Kim, S.J.; Park, S.; Na, B.; Yoon, S. Spiking-YOLO: Spiking Neural Network for Energy-Efficient Object Detection. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton New York Midtown, NY, USA, 7–12 February 2020; Volume 34, pp. 11270–11277. [Google Scholar]
- Wong, A.; Famouri, M.; Shafiee, M.J.; Li, F.; Chwyl, B.; Chung, J. YOLO Nano: A Highly Compact You Only Look Once Convolutional Neural Network for Object Detection. arXiv 2019, arXiv:1910.01271. [Google Scholar]
- Ringwald, T.; Sommer, L.; Schumann, A.; Beyerer, J.; Stiefelhagen, R. UAV-Net: A Fast Aerial Vehicle Detector for Mobile Platforms. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019; pp. 544–552. [Google Scholar]
- He, Y.; Pan, Z.; Li, L.; Shan, Y.; Cao, D.; Chen, L. Real-Time Vehicle Detection from Short-range Aerial Image with Compressed MobileNet. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, Canada, 20–24 May 2019; pp. 8339–8345. [Google Scholar]
- Mandal, M.; Shah, M.; Meena, P.; Devi, S.; Vipparthi, S.K. AVDNet: A Small-Sized Vehicle Detection Network for Aerial Visual Data. IEEE Geosci. Remote Sens. Lett. 2020, 17, 494–498. [Google Scholar] [CrossRef] [Green Version]
- Azimi, S.M. ShuffleDet: Real-Time Vehicle Detection Network in On-Board Embedded UAV Imagery. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018; pp. 88–99. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Misra, D. Mish: A self regularized non-monotonic neural activation function. arXiv 2019, arXiv:1908.08681. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, Hilton New York Midtown, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]
- Wu, Y.; Kirillov, A.; Massa, F.; Lo, W.Y.; Girshick, R. Detectron2. 2019. Available online: https://github.com/facebookresearch/detectron2 (accessed on 8 August 2021).
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; Sun, J. YOLOX: Exceeding YOLO Series in 2021. arXiv 2021, arXiv:2107.08430. [Google Scholar]
















| Parameters | Models | ||||||
|---|---|---|---|---|---|---|---|
| YOLOv2 | YOLOv2-Tiny | YOLOv3 | YOLOv3-Tiny | YOLOv4 | YOLOv4-Tiny | Ours | |
| Number of layers | 31 | 15 | 106 | 23 | 161 | 37 | 35 |
| Anchors | 5 | 5 | 9 | 6 | 9 | 6 | 6 |
| Multilevel prediction | - | - | 3 | 2 | 3 | 2 | 2 |
| Backbone | Darknet-19 | 9 Conv Layers | Darknet-53 | Darknet-19 | CSPDarknet-53 | CSPDarknet-19 | CSPDarknet-19 |
| FPN | ✗ | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
| SPP | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ |
| PAN | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ |
| Augmentation | |||||||
| Saturation | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Exposure | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Hue | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| Mosaic | ✗ | ✗ | ✗ | ✗ | ✓ | ✓ | ✓ |
| Model Size | 194 MB | 43 MB | 236 MB | 34 MB | 245 MB | 23 MB | 5.5 MB |
| Class | Sedan | Minivan | Truck | Pickup Truck | Bus | Cement Truck | Trailer |
|---|---|---|---|---|---|---|---|
| Training | 28,613 | 313 | 2192 | 2118 | 413 | 128 | 542 |
| Validation | 7930 | 129 | 684 | 610 | 111 | 48 | 158 |
| Testing | 3787 | 59 | 311 | 283 | 56 | 15 | 104 |
| Class | Sedan | Pickup | Other | Unknown |
|---|---|---|---|---|
| Training | 6240 | 486 | 4012 | 905 |
| Validation | 780 | 68 | 617 | 153 |
| Testing | 653 | 53 | 426 | 96 |
| Parameters | Dataset | |
|---|---|---|
| VAID | COWC | |
| Number of images | 5985 | 1829 |
| in training dataset | 4189 | 1467 |
| in validation dataset | 1197 | 183 |
| in testing dataset | 599 | 179 |
| Number of classes | 7 | 4 |
| Number of objects | 48,606 | 14,489 |
| in training dataset | 34,319 | 11,643 |
| in validation dataset | 9670 | 1618 |
| in testing dataset | 4615 | 1228 |
| Spatial resolution | 12.5 cm | 15 cm |
| Vehicle size (pixels) | ||
| Models | Anchor Box Sizes |
|---|---|
| Faster R-CNN | Size: (32,32), (64,64), (128,128), (256,256), (512,512) |
| Aspect Ratio: 0.5, 1.0, 2.0 | |
| YOLOv2 | (0.57273,0.677385), (1.87446,2.06253), (3.33843,5.47434), (7.88282,3.52778), (9.77052,9.16828) |
| YOLOv2-Tiny | (0.57273,0.677385), (1.87446,2.06253), (3.33843,5.47434), (7.88282,3.52778), (9.77052,9.16828) |
| YOLOv3 | (10,13), (16,30), (33,23), (30,61), (62,45), (59,119), (116,90), (156,198), (373,326) |
| YOLOv3-Tiny | (10,14), (23,27), (37,58), (81,82), (135,169), (344,319) |
| YOLOv4 | (12,16), (19,36), (40,28), (36,75), (76,55), (72,146), (142,110), (192,243), (459,401) |
| YOLOv4-Tiny | (10,14), (23,27), (37,58), (81,82), (135,169), (344,319) |
| Ours | (10,14), (23,27), (37,58), (81,82), (135,169), (344,319) |
| Model | Input Size | Precision | Recall | F1 Score | Sedan | Minivan | Truck | Pickup Truck | Bus | Cement Truck | Trailer | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | 0.8711 | 0.7859 | 0.8068 | 0.7962 | 0.5390 | 0.6668 | 0.4668 | 0.3838 | 0.7134 | 0.5178 | 0.5746 | |
| Faster R-CNN | 0.9020 | 0.8283 | 0.7813 | 0.8041 | 0.5891 | 0.7268 | 0.5209 | 0.4482 | 0.7441 | 0.5966 | 0.6199 | |
| Faster R-CNN | 0.9219 | 0.8578 | 0.7657 | 0.8091 | 0.6203 | 0.7289 | 0.5690 | 0.5154 | 0.7693 | 0.6629 | 0.6823 | |
| YOLOv2 | 0.8017 | 0.7920 | 0.6971 | 0.7415 | 0.6874 | 0.9215 | 0.6733 | 0.6693 | 0.9462 | 0.8513 | 0.8630 | |
| YOLOv2 | 0.8764 | 0.8396 | 0.8022 | 0.8205 | 0.7951 | 0.9619 | 0.8118 | 0.7942 | 0.9601 | 0.9144 | 0.8970 | |
| YOLOv2 | 0.9139 | 0.8643 | 0.8626 | 0.8634 | 0.8592 | 0.9805 | 0.8723 | 0.8658 | 0.9721 | 0.9127 | 0.9350 | |
| YOLOv2-Tiny | 0.6147 | 0.4887 | 0.5686 | 0.5256 | 0.4373 | 0.7750 | 0.3992 | 0.4169 | 0.8643 | 0.6975 | 0.7128 | |
| YOLOv2-Tiny | 0.7269 | 0.5896 | 0.6926 | 0.6369 | 0.5927 | 0.8629 | 0.6110 | 0.5394 | 0.9465 | 0.6980 | 0.8375 | |
| YOLOv2-Tiny | 0.8187 | 0.6600 | 0.7822 | 0.7159 | 0.7154 | 0.9664 | 0.6810 | 0.6823 | 0.9669 | 0.8588 | 0.8601 | |
| YOLOv3 | 0.9675 | 0.9374 | 0.9789 | 0.9577 | 0.9753 | 0.9819 | 0.9734 | 0.9634 | 0.9825 | 0.9446 | 0.9512 | |
| YOLOv3 | 0.9650 | 0.9434 | 0.9828 | 0.9627 | 0.9857 | 0.9871 | 0.9727 | 0.9670 | 0.9737 | 0.9271 | 0.9419 | |
| YOLOv3 | 0.9697 | 0.9495 | 0.9849 | 0.9669 | 0.9861 | 0.9849 | 0.9757 | 0.9697 | 0.9808 | 0.9370 | 0.9539 | |
| YOLOv3-Tiny | 0.8491 | 0.8192 | 0.8566 | 0.8375 | 0.8415 | 0.9752 | 0.8359 | 0.7634 | 0.9631 | 0.7038 | 0.8610 | |
| YOLOv3-Tiny | 0.8702 | 0.8579 | 0.8867 | 0.8721 | 0.9025 | 0.9663 | 0.8815 | 0.8028 | 0.9688 | 0.7174 | 0.8521 | |
| YOLOv3-Tiny | 0.9486 | 0.8975 | 0.9436 | 0.9200 | 0.9471 | 0.9891 | 0.9413 | 0.9230 | 0.9708 | 0.9165 | 0.9524 | |
| YOLOv4 | 0.9702 | 0.9400 | 0.9843 | 0.9617 | 0.9854 | 0.9954 | 0.9760 | 0.9712 | 0.9762 | 0.9355 | 0.9519 | |
| YOLOv4 | 0.9708 | 0.9418 | 0.9886 | 0.9646 | 0.9865 | 0.9871 | 0.9730 | 0.9796 | 0.9837 | 0.9283 | 0.9571 | |
| YOLOv4 | 0.9743 | 0.9438 | 0.9883 | 0.9655 | 0.9860 | 0.9851 | 0.9785 | 0.9793 | 0.9911 | 0.9450 | 0.9555 | |
| YOLOv4-Tiny | 0.8715 | 0.9673 | 0.5651 | 0.7134 | 0.7047 | 0.9823 | 0.8233 | 0.7411 | 0.9821 | 0.9271 | 0.9403 | |
| YOLOv4-Tiny | 0.9370 | 0.9643 | 0.8655 | 0.9122 | 0.9041 | 0.9858 | 0.9281 | 0.9120 | 0.9801 | 0.9038 | 0.9452 | |
| YOLOv4-Tiny | 0.9605 | 0.9588 | 0.9415 | 0.9501 | 0.9551 | 0.9843 | 0.9687 | 0.9507 | 0.9848 | 0.9264 | 0.9533 | |
| Ours | 0.8715 | 0.9646 | 0.5686 | 0.7154 | 0.7160 | 0.9858 | 0.8332 | 0.7564 | 0.9761 | 0.9101 | 0.9230 | |
| Ours | 0.9398 | 0.9658 | 0.8714 | 0.9162 | 0.9233 | 0.9781 | 0.9385 | 0.9060 | 0.9862 | 0.9148 | 0.9314 | |
| Ours | 0.9605 | 0.9602 | 0.9433 | 0.9517 | 0.9642 | 0.9833 | 0.9668 | 0.9488 | 0.9898 | 0.9272 | 0.9414 |
| Model | Model Size (MB) | BFLOPs | Number of Parameters | Inference Time (ms) | Frame Per Second (FPS) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Tesla T4 | Quadro P5000 | Jetson Nano | Tesla T4 | Quadro P5000 | Jetson Nano | |||||
| Faster R-CNN | 330 | 134.40 | 41.80 M | 0.9020 | 40.08 | 56.23 | 779.98 | 25.0 | 17.8 | 1.3 |
| YOLOv2 | 202 | 44.45 | 50.61 M | 0.8764 | 14.84 | 10.85 | 412.70 | 67.4 | 92.2 | 2.4 |
| YOLOv2-Tiny | 44.2 | 8.10 | 11.05 M | 0.7269 | 5.22 | 3.64 | 199.04 | 191.6 | 274.7 | 4.1 |
| YOLOv3 | 246 | 98.99 | 61.61 M | 0.9650 | 28.85 | 23.28 | 735.55 | 34.7 | 42.96 | 1.4 |
| YOLOv3-Tiny | 34.8 | 8.27 | 8.69 M | 0.8702 | 5.23 | 3.65 | 199.20 | 191.2 | 274.0 | 5.0 |
| YOLOv4 | 256 | 90.29 | 64.04 M | 0.9708 | 29.08 | 26.48 | 861.87 | 34.4 | 37.8 | 1.2 |
| YOLOv4-Tiny | 23.6 | 10.30 | 5.89 M | 0.9370 | 5.83 | 3.27 | 80.56 | 71.5 | 305.8 | 12.4 |
| Ours | 5.8 | 7.77 | 1.44 M | 0.9398 | 5.67 | 4.67 | 80.98 | 176.4 | 214.1 | 12.3 |
| Model | Input Size | Precision | Recall | F1 Score | Sedan | Pickup | Other | Unknown | |
|---|---|---|---|---|---|---|---|---|---|
| Faster R-CNN | 0.8417 | 0.8339 | 0.6259 | 0.7150 | 0.7284 | 0.7008 | 0.6984 | 0.4942 | |
| Faster R-CNN | 0.8921 | 0.8902 | 0.6393 | 0.7442 | 0.7534 | 0.7689 | 0.7326 | 0.5868 | |
| YOLOv2 | 0.6180 | 0.7202 | 0.6751 | 0.6969 | 0.7157 | 0.6975 | 0.6783 | 0.3804 | |
| YOLOv2 | 0.6966 | 0.7644 | 0.7687 | 0.7665 | 0.8244 | 0.6462 | 0.7606 | 0.5551 | |
| YOLOv2-Tiny | 0.3963 | 0.4338 | 0.5684 | 0.4921 | 0.4971 | 0.4242 | 0.4372 | 0.2266 | |
| YOLOv2-Tiny | 0.5222 | 0.4979 | 0.6775 | 0.5740 | 0.6881 | 0.5854 | 0.5437 | 0.2717 | |
| YOLOv3 | 0.9383 | 0.8953 | 0.9536 | 0.9235 | 0.9606 | 0.9347 | 0.9674 | 0.8905 | |
| YOLOv3 | 0.9375 | 0.9116 | 0.9568 | 0.9337 | 0.9602 | 0.9093 | 0.9678 | 0.9127 | |
| YOLOv3-Tiny | 0.8197 | 0.7883 | 0.8795 | 0.8314 | 0.9111 | 0.7869 | 0.8758 | 0.7050 | |
| YOLOv3-Tiny | 0.8609 | 0.8006 | 0.9055 | 0.8498 | 0.9104 | 0.8699 | 0.9177 | 0.7456 | |
| YOLOv4 | 0.9529 | 0.8757 | 0.9756 | 0.9230 | 0.9727 | 0.9208 | 0.9880 | 0.9299 | |
| YOLOv4 | 0.9597 | 0.8832 | 0.9731 | 0.9260 | 0.9737 | 0.9585 | 0.9778 | 0.9286 | |
| YOLOv4-Tiny | 0.9068 | 0.8748 | 0.9389 | 0.9057 | 0.9566 | 0.8430 | 0.9622 | 0.8654 | |
| YOLOv4-Tiny | 0.9347 | 0.8787 | 0.9552 | 0.9153 | 0.9626 | 0.9153 | 0.9659 | 0.8951 | |
| Ours | 0.9299 | 0.8772 | 0.9422 | 0.9085 | 0.9589 | 0.9179 | 0.9670 | 0.8759 | |
| Ours | 0.9353 | 0.8853 | 0.9552 | 0.9189 | 0.9800 | 0.9155 | 0.9655 | 0.8804 |
| Model | Model Size (MB) | BFLOPs | Number of Parameters | Inference Time (ms) | Frame Per Second (FPS) | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Tesla T4 | Quadro P5000 | Jetson Nano | Tesla T4 | Quadro P5000 | Jetson Nano | |||||
| Faster R-CNN | 330 | 134.40 | 41.80 M | 0.8921 | 42.12 | 45.77 | 1123 | 23.7 | 21.8 | 0.9 |
| YOLOv2 | 202 | 44.45 | 50.59 M | 0.6966 | 12.98 | 12.78 | 440.21 | 77.0 | 78.2 | 2.3 |
| YOLOv2-Tiny | 44.2 | 8.10 | 11.04 M | 0.5222 | 4.98 | 5.61 | 197.54 | 200.8 | 178.3 | 5.1 |
| YOLOv3 | 256 | 98.96 | 61.59 M | 0.9375 | 16.60 | 24.63 | 802.03 | 60.2 | 40.6 | 1.2 |
| YOLOv3-Tiny | 34.7 | 8.26 | 8.68 M | 0.8609 | 5.06 | 5.66 | 199.90 | 197.6 | 176.7 | 5.0 |
| YOLOv4 | 244 | 90.26 | 64.02 M | 0.9597 | 20.24 | 26.71 | 846.78 | 49.4 | 37.4 | 1.2 |
| YOLOv4-Tiny | 23.5 | 10.29 | 5.89 M | 0.9347 | 5.67 | 14.67 | 86.21 | 176.4 | 68.2 | 11.6 |
| Ours | 5.5 | 7.73 | 1.43M | 0.9353 | 5.33 | 13.89 | 78.33 | 187.6 | 72.0 | 12.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Koay, H.V.; Chuah, J.H.; Chow, C.-O.; Chang, Y.-L.; Yong, K.K. YOLO-RTUAV: Towards Real-Time Vehicle Detection through Aerial Images with Low-Cost Edge Devices. Remote Sens. 2021, 13, 4196. https://doi.org/10.3390/rs13214196
Koay HV, Chuah JH, Chow C-O, Chang Y-L, Yong KK. YOLO-RTUAV: Towards Real-Time Vehicle Detection through Aerial Images with Low-Cost Edge Devices. Remote Sensing. 2021; 13(21):4196. https://doi.org/10.3390/rs13214196
Chicago/Turabian StyleKoay, Hong Vin, Joon Huang Chuah, Chee-Onn Chow, Yang-Lang Chang, and Keh Kok Yong. 2021. "YOLO-RTUAV: Towards Real-Time Vehicle Detection through Aerial Images with Low-Cost Edge Devices" Remote Sensing 13, no. 21: 4196. https://doi.org/10.3390/rs13214196
APA StyleKoay, H. V., Chuah, J. H., Chow, C. -O., Chang, Y. -L., & Yong, K. K. (2021). YOLO-RTUAV: Towards Real-Time Vehicle Detection through Aerial Images with Low-Cost Edge Devices. Remote Sensing, 13(21), 4196. https://doi.org/10.3390/rs13214196