
Multi-Hypothesis Topological Isomorphism Matching Method for Synthetic Aperture Radar Images with Large Geometric Distortion


Abstract
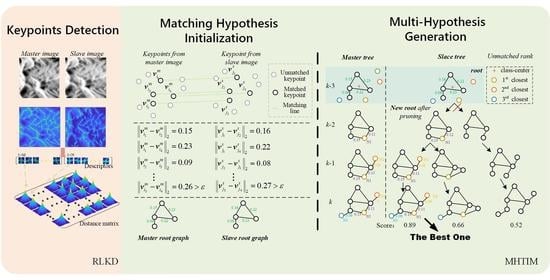
:
1. Introduction
2. Methods
2.1. Problem Description
2.2. Ridge Line Keypoint Detection Method
2.2.1. Quick Detection of Intersection of Ridge Lines
2.2.2. Keypoint Generation and Descriptor
2.2.3. Quick Matching
2.3. Multi-Hypothesis Topological Isomorphism Matching Method
- Multi-hypothesis generation: According to the ranking results, select the top candidate keypoints and add them to the graph to generate new hypotheses.
- Hypothesis score calculation: We use five graph indicators and node angle similarity indicators to rank the new hypotheses. The hypothesis that ranks first in a single indicator gets a certain score. The final score of a new hypothesis is the sum of the scores assumed under each indicator.
- Pruning: New hypotheses are sorted in terms of their final scores, pruning low-scoring hypothesis branches, retaining high-scoring hypothesis branches, and updating the root node, matching, and candidate point sets.
2.3.1. Hypothesis Initialization and Candidate Keypoints Sorting
2.3.2. Multi-Hypothesis Generation
2.3.3. Hypothesis Score Calculation
2.3.4. Pruning
3. Experiment
3.1. Data Set
3.2. Implementation Details
3.3. Evaluation Index
- Mean-Absolute Error (MAE):MAE is capable to measure the alignment error of keypoints, which is defined as follows:where, is the transfer model, and is the number of keypoint pairs that are correctly matched, that is, NKM.
- Number of Keypoints Matched (NKM):We use the final number of matching keypoints generated by each method as the number of keypoints matched to measure the effectiveness of the transfer model fitting.
- Proportion of Keypoints Matched (PKM):In order to evaluate whether the keypoints detected by the method are efficient, we also use PKM as one of the evaluation indicators. PKM is defined as follows:In the equation, represents the number of matching keypoints in the master image, and represents the number of all keypoints detected in the master image.
3.4. Result Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Payne, K.; Warrington, S.; Bennett, O. High Stakes: The Future for Mountain Societies; Food and Agriculture Organization of the United Nations: Rome, Italy, 2002. [Google Scholar]
- Jiang, X.; Ma, J.; Xiao, G.; Shao, Z.; Guo, X. A review of multimodal image matching: Methods and applications. Inf. Fusion 2021, 73, 22–71. [Google Scholar] [CrossRef]
- Pallotta, L.; Giunta, G.; Clemente, C. Subpixel SAR image registration through parabolic interpolation of the 2-D cross correlation. IEEE Trans. Geosci. Remote Sens. 2020, 58, 4132–4144. [Google Scholar] [CrossRef] [Green Version]
- Xiang, Y.; Tao, R.; Wan, L.; Wang, F.; You, H. OS-PC: Combining feature representation and 3-D phase correlation for subpixel optical and SAR image registration. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6451–6466. [Google Scholar] [CrossRef]
- Wang, Z.; Yang, Y.; Ding, Z.; Lin, S.; Zhang, T.; Lv, Z. A high-accuracy interferometric SAR images registration strategy combined with cross correlation and spectral diversity. In Proceedings of the International Conference on Radar Systems (Radar 2017), Belfast, UK, 23–26 October 2017. [Google Scholar]
- Scheiber, R.; Moreira, A. Coregistration of interferometric SAR images using spectral diversity. IEEE Trans. Geosci. Remote Sens. 2000, 38, 2179–2191. [Google Scholar] [CrossRef]
- Gabriel, A.K.; Goldstein, R.M. Crossed orbit interferometry: Theory and experimental results from SIR-B. Int. J. Remote Sens. 1988, 9, 857–872. [Google Scholar] [CrossRef]
- Lin, Q.; Vesecky, J.F.; Zebker, H.A. New approaches in interferometric SAR data processing. IEEE Trans. Geosci. Remote Sens. 1992, 30, 560–567. [Google Scholar] [CrossRef]
- Zhang, Z.; Liu, H.; Zhang, L.; Wang, S.; Li, Z.; Wu, J. A large width SAR image registration method based on the compelex correlation function. In Proceedings of the 2016 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Beijing, China, 10–15 July 2016; pp. 6476–6479. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Wang, B.; Zhang, J.; Lu, L.; Huang, G.; Zhao, Z. A uniform SIFT-like algorithm for SAR image registration. IEEE Geosci. Remote Sens. Lett. 2015, 12, 1426–1430. [Google Scholar] [CrossRef]
- Dellinger, F.; Delon, J.; Gousseau, Y.; Michel, J.; Tupin, F. SAR-SIFT: A SIFT-like algorithm for SAR images. IEEE Trans. Geosci. Remote Sens. 2014, 53, 453–466. [Google Scholar] [CrossRef] [Green Version]
- Dhouha, B.; Khaled, K.; Hassen, M. An overview of image matching algorithms from two radically points of view. In Proceedings of the 2016 International Image Processing, Applications and Systems (IPAS), Sfax, Tunisia, 5–7 November 2016; pp. 1–6. [Google Scholar]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; pp. 2564–2571. [Google Scholar]
- Tola, E.; Lepetit, V.; Fua, P. Daisy: An efficient dense descriptor applied to wide-baseline stereo. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 815–830. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Bay, H.; Ess, A.; Tuytelaars, T.; Van Gool, L. Speeded-up robust features (SURF). Comput. Vis. Image Underst. 2008, 110, 346–359. [Google Scholar] [CrossRef]
- Rosten, E.; Drummond, T. Machine learning for high-speed corner detection. In Proceedings of the European Conference on Computer Vision, Graz, Austria, 7–13 May 2006; pp. 430–443. [Google Scholar]
- Kang, J.; Wang, Y.; Zhu, X.X. Multipass sar interferometry based on total variation regularized robust low rank tensor decomposition. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5354–5366. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Huang, H.; Yu, A.; Dong, Z. An efficient and adaptive approach for noise filtering of SAR interferometric phase images. IEEE Geosci. Remote Sens. Lett. 2011, 8, 1140–1144. [Google Scholar] [CrossRef]
- Wang, Y.; Zhu, X.X. SAR Tomography via Nonlinear Blind Scatterer Separation. IEEE Trans. Geosci. Remote Sens. 2020, 59, 5751–5763. [Google Scholar] [CrossRef]
- Shi, Y.; Bamler, R.; Wang, Y.; Zhu, X.X. Sar tomography at the limit: Building height reconstruction using only 3–5 Tandem-x bistatic interferograms. arXiv 2020, arXiv:2003.07803. [Google Scholar] [CrossRef]
- Ma, W.; Wen, Z.; Wu, Y.; Jiao, L.; Gong, M.; Zheng, Y.; Liu, L. Remote sensing image registration with modified SIFT and enhanced feature matching. IEEE Geosci. Remote Sens. Lett. 2016, 14, 3–7. [Google Scholar] [CrossRef]
- Xiang, Y.; Wang, F.; Wan, L.; You, H. An advanced rotation invariant descriptor for SAR image registration. Remote Sens. 2017, 9, 686. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Jiang, X.; Fan, A.; Jiang, J.; Yan, J. Image matching from handcrafted to deep features: A survey. Int. J. Comput. Vis. 2021, 129, 23–79. [Google Scholar] [CrossRef]
- Sun, W.; Wang, H.; Zhao, X. A simplification method for grid-based DEM using topological hierarchies. Surv. Rev. 2018, 50, 454–467. [Google Scholar] [CrossRef]
- Dharampal, V.M. Methods of image edge detection: A review. J. Electr. Electron. Syst. 2015, 4. [Google Scholar] [CrossRef] [Green Version]
- Xie, S.; Tu, Z. Holistically-nested edge detection. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1395–1403. [Google Scholar]
- Liu, Y.; Cheng, M.M.; Hu, X.; Wang, K.; Bai, X. Richer convolutional features for edge detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3000–3009. [Google Scholar]
- Xu, L.; Qiao, J.; Lin, S.; Wang, X. Research on the Task Assignment Problem with Maximum Benefits in Volunteer Computing Platforms. Symmetry 2020, 12, 862. [Google Scholar] [CrossRef]
- Derpanis, K.G. Overview of the RANSAC Algorithm. Image Rochester NY 2010, 4, 2–3. [Google Scholar]
- Hast, A.; Nysjö, J.; Marchetti, A. Optimal Ransac-towards a Repeatable Algorithm for Finding the Optimal Set; Václav Skala–Union Agency: Pilsen, Czech Republic, 2013. [Google Scholar]
- De Boer, P.T.; Kroese, D.P.; Mannor, S.; Rubinstein, R.Y. A tutorial on the cross-entropy method. Ann. Oper. Res. 2005, 134, 19–67. [Google Scholar] [CrossRef]
- Delahaye, D.; Chaimatanan, S.; Mongeau, M. Simulated annealing: From basics to applications. In Handbook of Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2019; pp. 1–35. [Google Scholar]
- Goshtasby, A. Image registration by local approximation methods. Image Vis. Comput. 1988, 6, 255–261. [Google Scholar] [CrossRef]
- Yang, J.; Huang, Z.; Quan, S.; Qi, Z.; Zhang, Y. SAC-COT: Sample Consensus by Sampling Compatibility Triangles in Graphs for 3-D Point Cloud Registration. IEEE Trans. Geosci. Remote Sens. 2021, 1–15. [Google Scholar] [CrossRef]
- Chen, Q.; Yu, A.; Sun, Z.; Huang, H. A multi-mode space-borne SAR simulator based on SBRAS. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 4567–4570. [Google Scholar]
- Wang, M.; Liang, D.; Huang, H.; Dong, Z. SBRAS—An advanced simulator of spaceborne radar. In Proceedings of the 2007 IEEE International Geoscience and Remote Sensing Symposium, Barcelona, Spain, 23–27 July 2007; pp. 4942–4944. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Definition |
|---|---|
| , | LoG operator in the range and azimuth direction |
| Two-dimensional Gaussian filter | |
| Standard deviation | |
| , | Responses of image function I through and |
| , | Ridge detection in range and azimuth direction |
| The final edge detection result | |
| The coordinate of edge intersection in | |
| v | Keypoint produced by RLKD |
| s | Keypoint descriptor produced by RLKD |
| The similarity between two descriptors | |
| The conjugate operation | |
| The real correlation coefficient matrix of and | |
| D | The similarity matrix |
| Keypoints detected in the master image | |
| Keypoints detected in the slave image | |
| , | The matching keypoint set of master image |
| The candidate keypoint set of master image | |
| , | The matching keypoint set of slave image |
| The candidate keypoint set of slave image | |
| The putative self-distance matrices of | |
| The putative self-distance matrices of | |
| The master undirected weighted graph | |
| The slave undirected weighted graph | |
| The closeness between and in their respective graphs | |
| The node angle similarity | |
| , | The final matching pair set |
| Method | MAE (pixel) | NKM | TIME |
|---|---|---|---|
| Correlation | 0.59 | 21 | 0.90 s |
| Mutual information | 0.67 | 18 | 0.84 s |
| Cross entropy | 0.63 | 20 | 0.88 s |
| Method | RLKD | RLKD + MHTIM | ||
|---|---|---|---|---|
| MAE (pixel) | NKM | MAE (pixel) | NKM | |
| Similarity | 1.44 | 11 | 2.61 | 20 |
| Polynomial (order 2) | 0.63 | 18 | 1.19 | 26 |
| Affine | 0.78 | 16 | 0.84 | 18 |
| LWM | 0.59 | 21 | 0.55 | 31 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiao, R.; Wang, Q.; Lai, T.; Huang, H. Multi-Hypothesis Topological Isomorphism Matching Method for Synthetic Aperture Radar Images with Large Geometric Distortion. Remote Sens. 2021, 13, 4637. https://doi.org/10.3390/rs13224637
Jiao R, Wang Q, Lai T, Huang H. Multi-Hypothesis Topological Isomorphism Matching Method for Synthetic Aperture Radar Images with Large Geometric Distortion. Remote Sensing. 2021; 13(22):4637. https://doi.org/10.3390/rs13224637
Chicago/Turabian StyleJiao, Runzhi, Qingsong Wang, Tao Lai, and Haifeng Huang. 2021. "Multi-Hypothesis Topological Isomorphism Matching Method for Synthetic Aperture Radar Images with Large Geometric Distortion" Remote Sensing 13, no. 22: 4637. https://doi.org/10.3390/rs13224637
APA StyleJiao, R., Wang, Q., Lai, T., & Huang, H. (2021). Multi-Hypothesis Topological Isomorphism Matching Method for Synthetic Aperture Radar Images with Large Geometric Distortion. Remote Sensing, 13(22), 4637. https://doi.org/10.3390/rs13224637