
Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion


Abstract
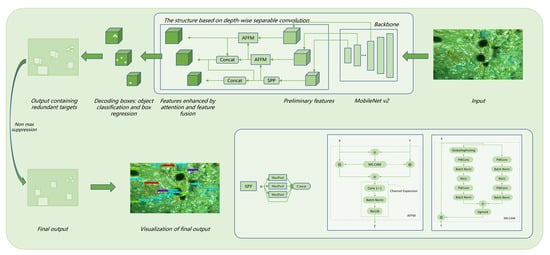
:
1. Introduction
2. Related Works
2.1. Object Detection
2.2. Lightweight Networks
2.3. Multi-Scale Features Fusion for Small Object Detection
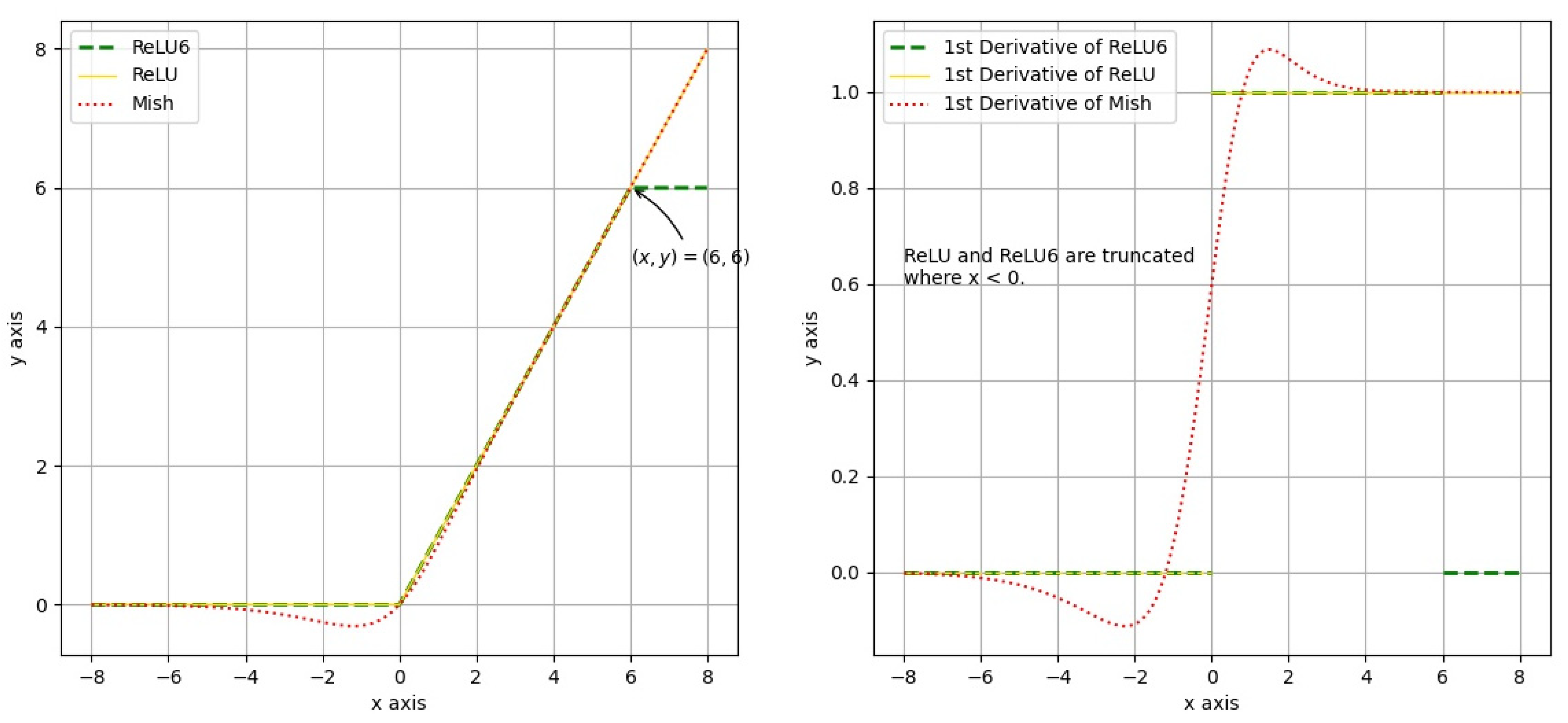
2.4. Activation Functions
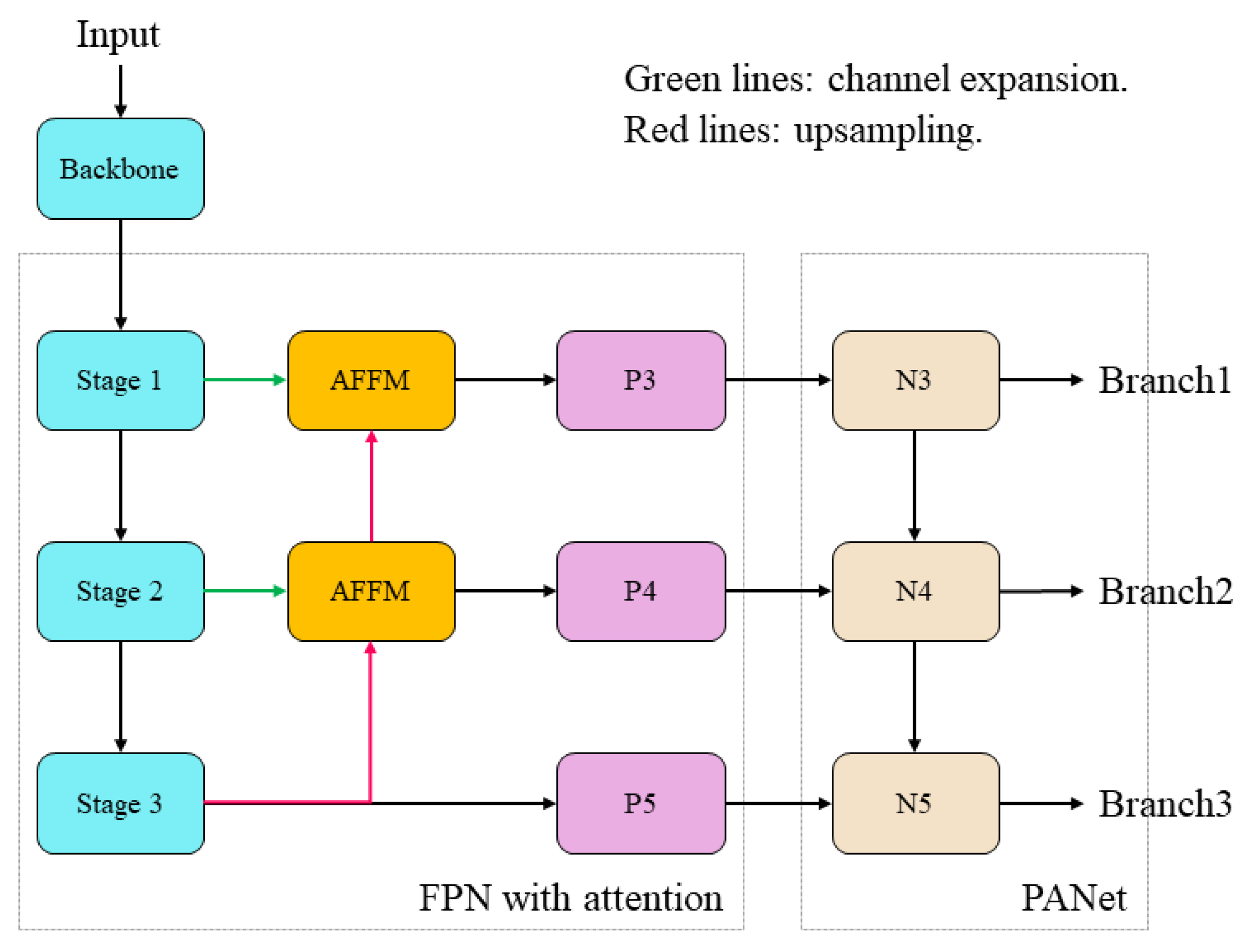
3. Methodology
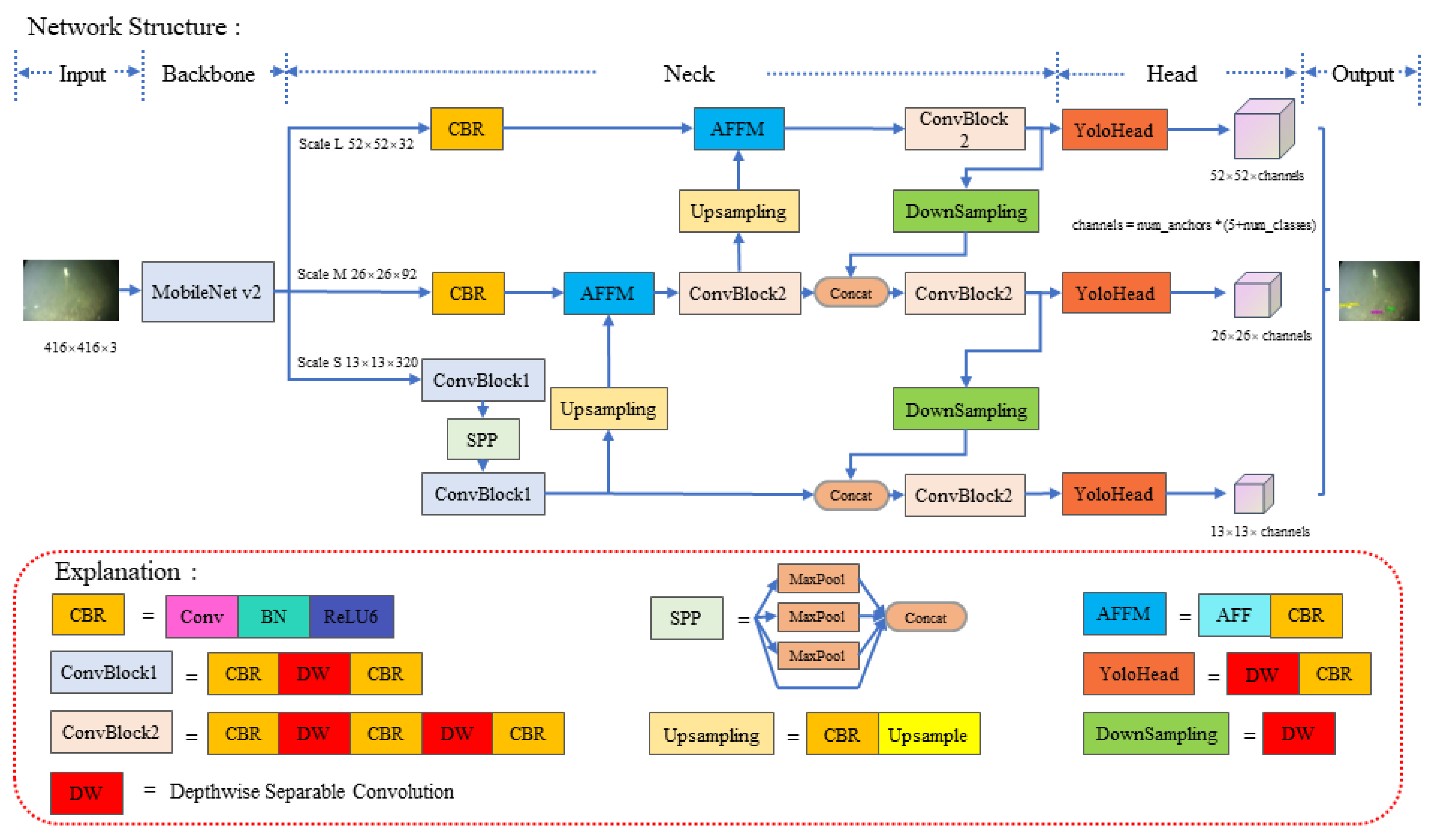
3.1. Network Structure
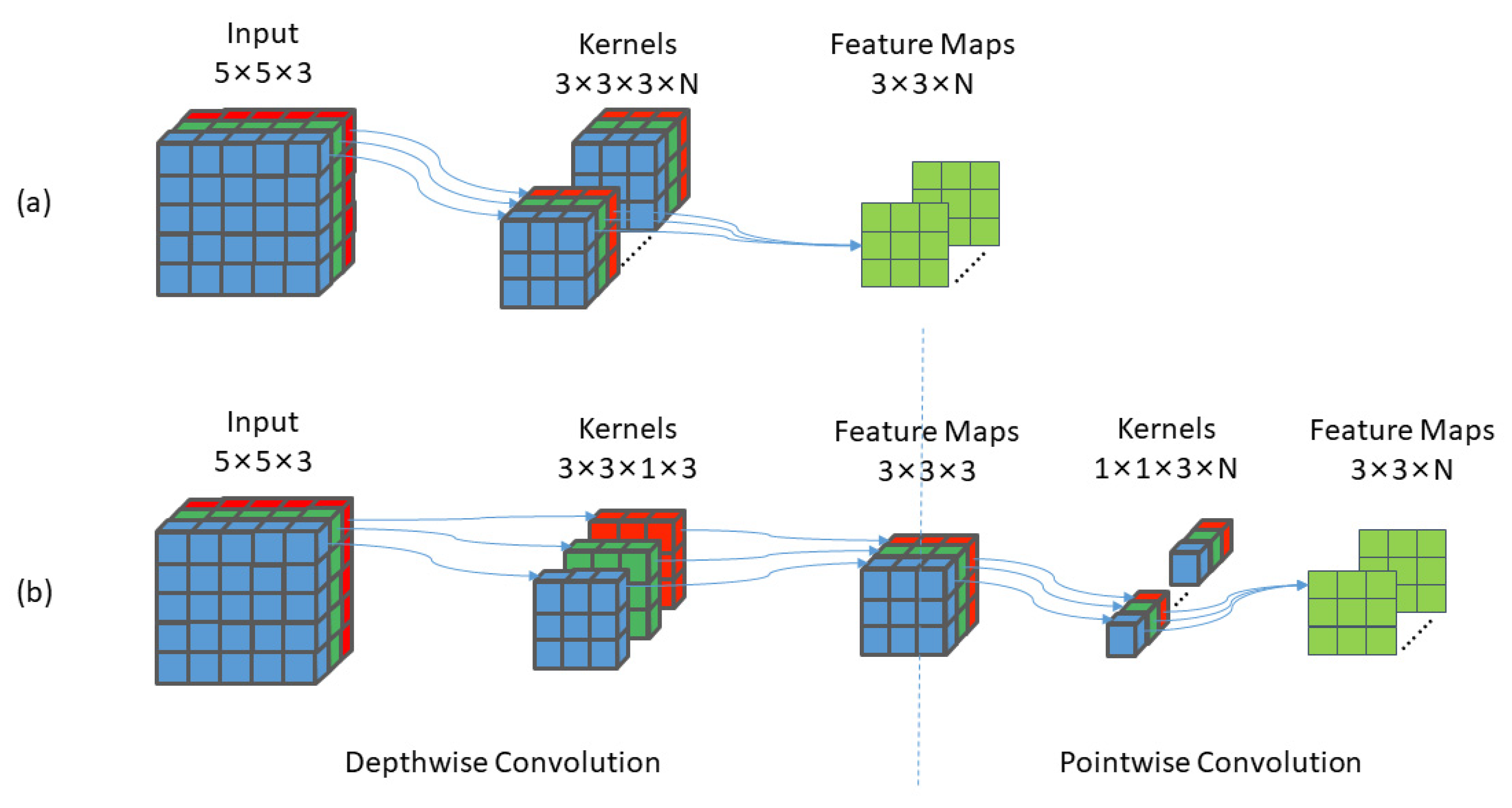
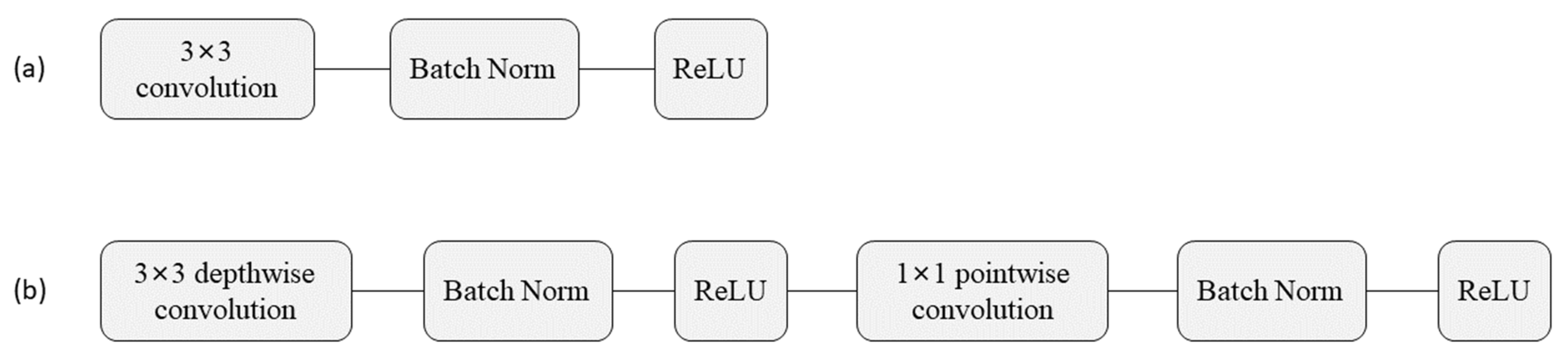
3.2. Depth-Wise Separable Convolution
3.3. Attentional Feature Fusion
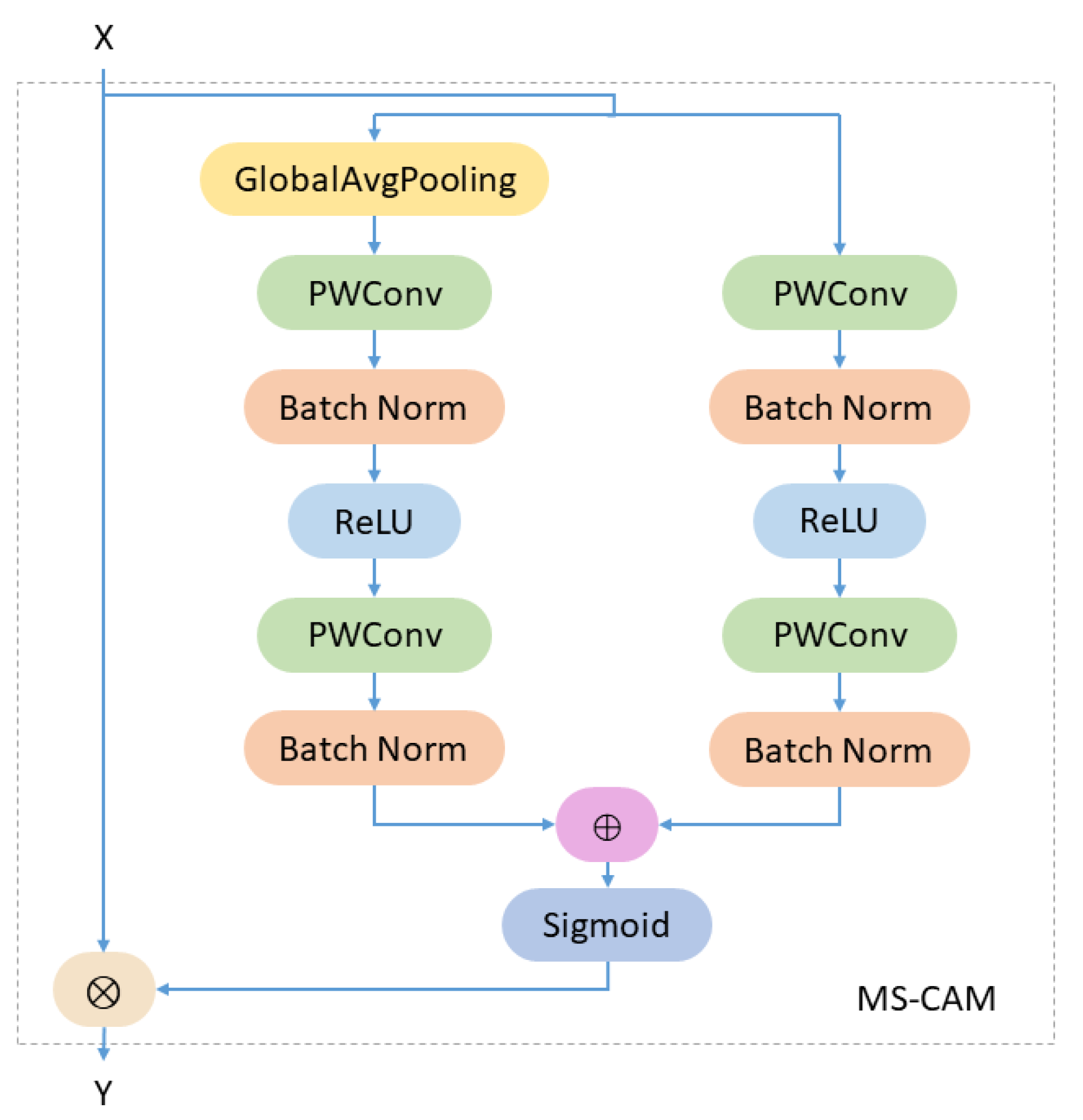
3.3.1. Multi-Scale Channel Attention Module
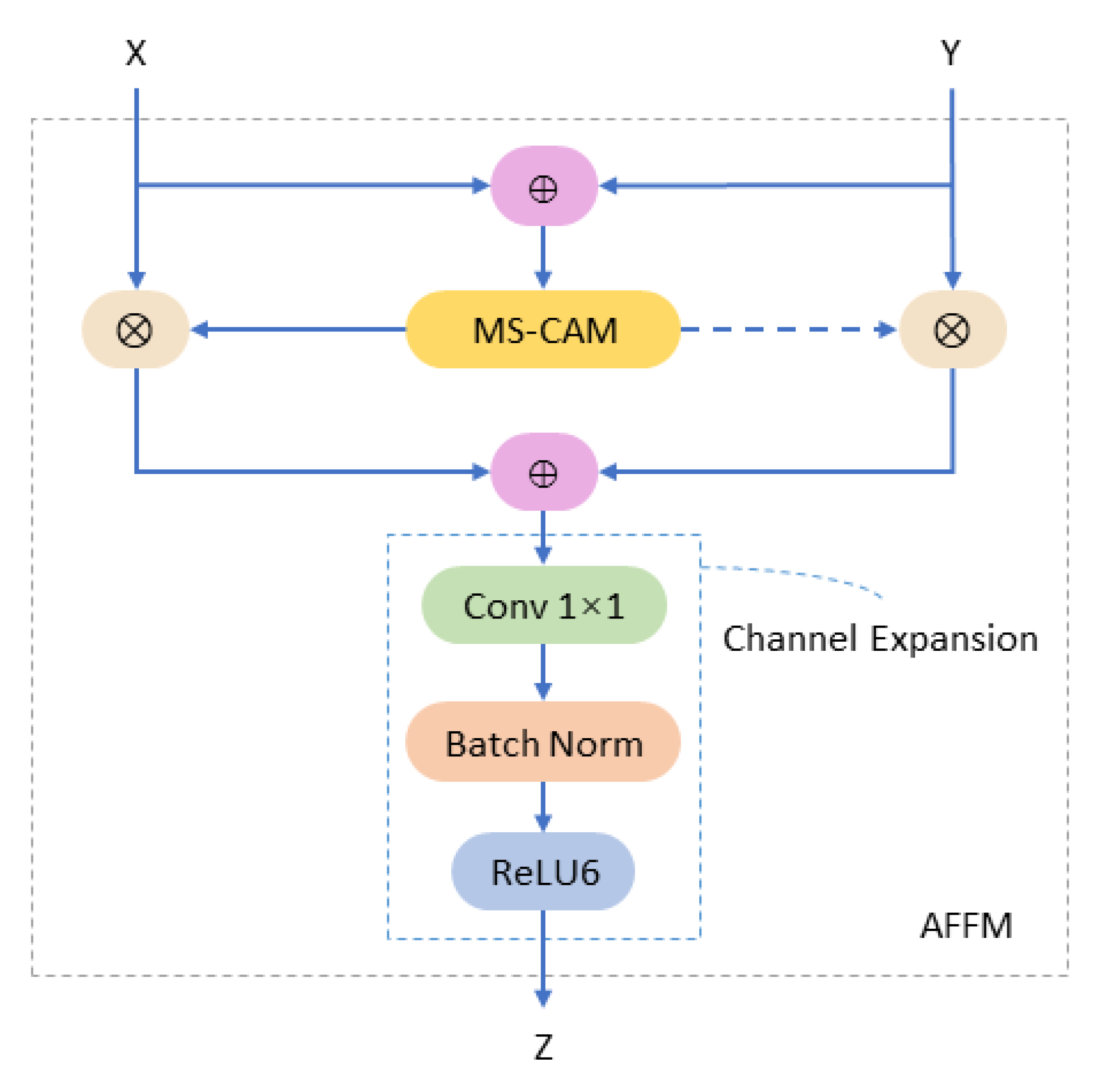
3.3.2. Modified Attentional Feature Fusion Module
4. Experiments and Results
4.1. General Datasets and Underwater Image Datasets
4.1.1. PASCAL VOC Dataset
4.1.2. Brackish Dataset
4.1.3. URPC Dataset
4.2. Experimental Setup
4.2.1. Experimental Environment
4.2.2. Training Parameter Settings
4.2.3. Testing Parameter Settings
4.3. Experimental Results
4.3.1. Ablation Experiments
4.3.2. Comparison with Other Object Detection Algorithms
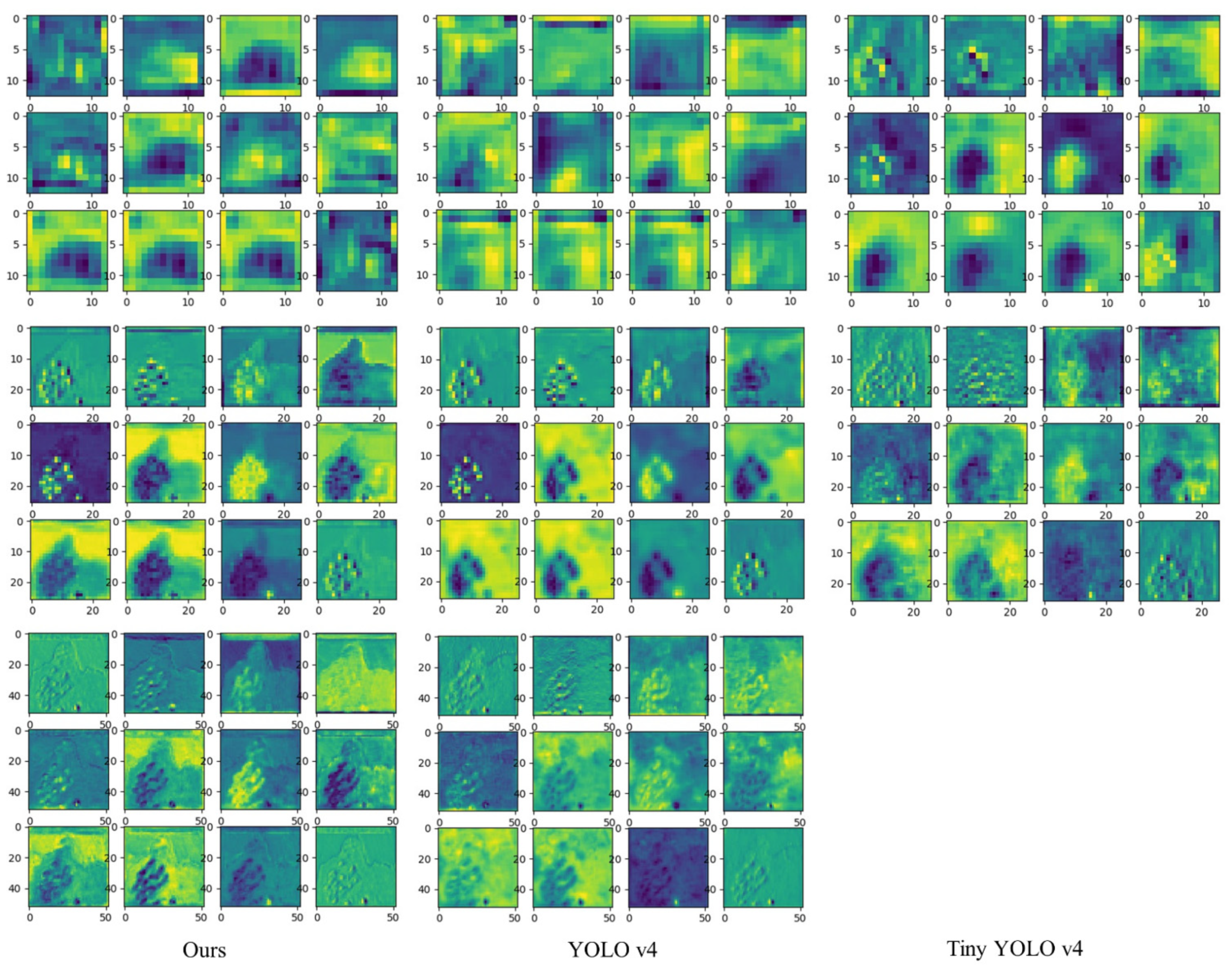
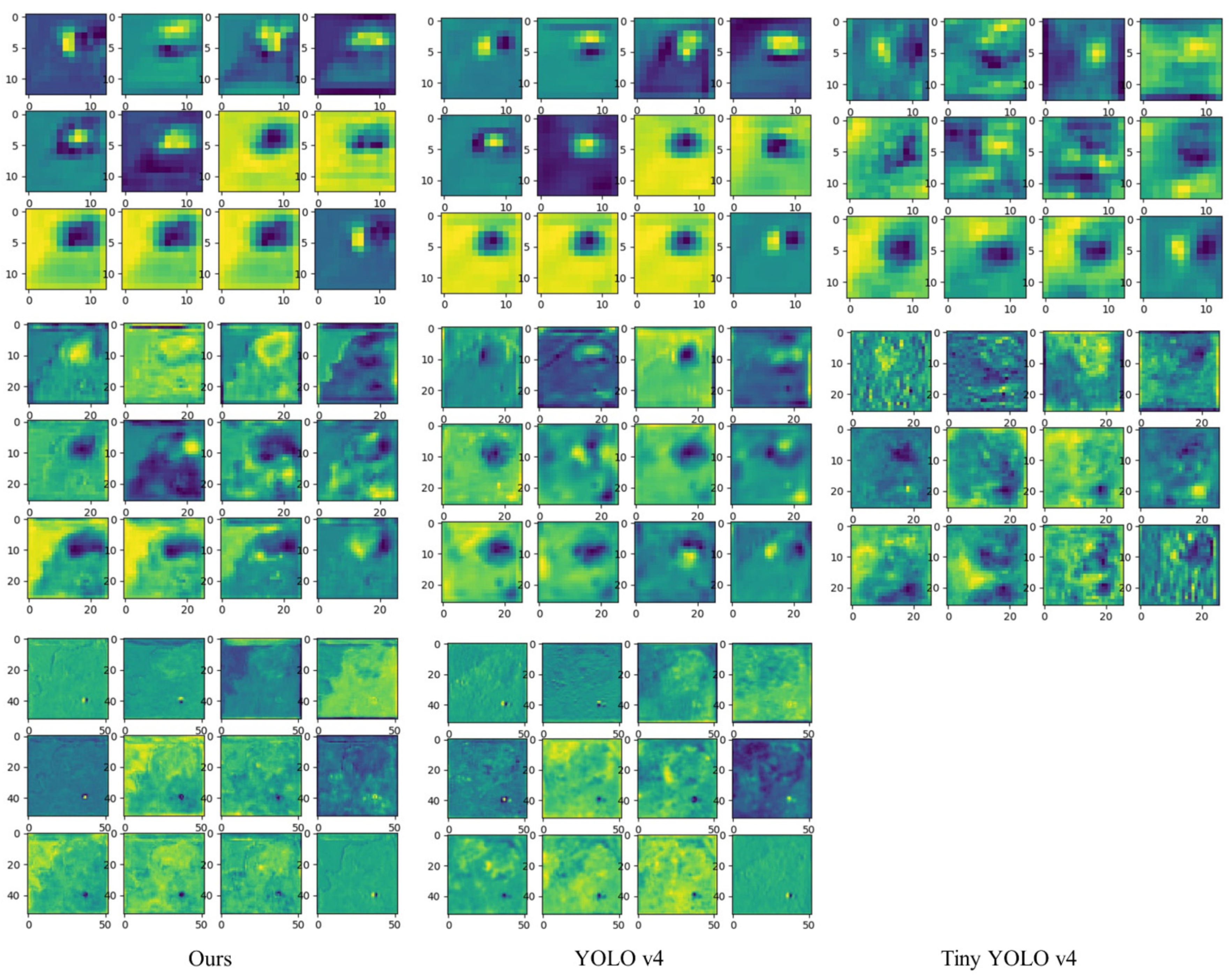
4.3.3. Detection Results on Underwater Datasets
5. Discussion
5.1. Lightweight Techniques for Underwater Object Detection
5.2. Challenges of Underwater Small Target Detection
5.3. Applicability in Different Underwater Marine Scenarios
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Deans, C.; Marmugi, L.; Renzoni, F. Active Underwater Detection with an Array of Atomic Magnetometers. Appl. Opt. 2018, 57, 2346. [Google Scholar] [CrossRef]
- Pydyn, A.; Popek, M.; Kubacka, M.; Janowski, Ł. Exploration and Reconstruction of a Medieval Harbour Using Hydroacoustics, 3-D Shallow Seismic and Underwater Photogrammetry: A Case Study from Puck, Southern Baltic Sea. Archaeol. Prospect. 2021, 1–16. [Google Scholar] [CrossRef]
- Czub, M.; Kotwicki, L.; Lang, T.; Sanderson, H.; Klusek, Z.; Grabowski, M.; Szubska, M.; Jakacki, J.; Andrzejewski, J.; Rak, D.; et al. Deep Sea Habitats in the Chemical Warfare Dumping Areas of the Baltic Sea. Sci. Total Environ. 2018, 616, 1485–1497. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Swizerland, 2016; pp. 21–37. [Google Scholar]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 936–944. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path Aggregation Network for Instance Segmentation. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Dai, Y.; Gieseke, F.; Oehmcke, S.; Wu, Y.; Barnard, K. Attentional Feature Fusion. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 5–9 January 2021; pp. 3559–3568. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Wang, C.-Y.; Mark Liao, H.-Y.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A New Backbone That Can Enhance Learning Capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 1571–1580. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.-C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Pedersen, M.; HAurum, J.B.; Gade, R.; Moeslund, T.B.; Madsen, N. Detection of Marine Animals in a New Underwater Dataset with Varying Visibility. In Proceedings of the The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-Level Accuracy with 50x Fewer Parameters and <0.5 MB Model Size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Lin, W.-H.; Zhong, J.-X.; Liu, S.; Li, T.; Li, G. ROIMIX: Proposal-Fusion Among Multiple Images for Underwater Object Detection. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 2588–2592. [Google Scholar]
- Uplavikar, P.; Wu, Z.; Wang, Z. All-In-One Underwater Image Enhancement Using Domain-Adversarial Learning. arXiv 2019, arXiv:1905.13342. [Google Scholar]
- Sun, X.; Shi, J.; Liu, L.; Dong, J.; Plant, C.; Wang, X.; Zhou, H. Transferring Deep Knowledge for Object Recognition in Low-Quality Underwater Videos. Neurocomputing 2018, 275, 897–908. [Google Scholar] [CrossRef] [Green Version]
- Xu, F.; Wang, H.; Peng, J.; Fu, X. Scale-Aware Feature Pyramid Architecture for Marine Object Detection. Neural Comput. Appl. 2021, 33, 3637–3653. [Google Scholar] [CrossRef]
- Pan, T.-S.; Huang, H.-C.; Lee, J.-C.; Chen, C.-H. Multi-Scale ResNet for Real-Time Underwater Object Detection. Signal Image Video Process. 2021, 15, 941–949. [Google Scholar] [CrossRef]
- Salman, A.; Siddiqui, S.A.; Shafait, F.; Mian, A.; Shortis, M.R.; Khurshid, K.; Ulges, A.; Schwanecke, U. Automatic Fish Detection in Underwater Videos by a Deep Neural Network-Based Hybrid Motion Learning System. ICES J. Mar. Sci. 2019, 77, 1295–1307. [Google Scholar] [CrossRef]
- Chen, L.; Liu, Z.; Tong, L.; Jiang, Z.; Wang, S.; Dong, J.; Zhou, H. Underwater Object Detection Using Invert Multi-Class Adaboost with Deep Learning. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Hu, K.; Lu, F.; Lu, M.; Deng, Z.; Liu, Y. A Marine Object Detection Algorithm Based on SSD and Feature Enhancement. Complexity 2020, 2020, 5476142. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Wang, R.J.; Li, X.; Ling, C.X. Pelee: A Real-Time Object Detection System on Mobile Devices. arXiv 2019, arXiv:1804.06882. [Google Scholar]
- Li, Y.; Li, J.; Lin, W.; Li, J. Tiny-DSOD: Lightweight Object Detection for Resource-Restricted Usages. arXiv 2018, arXiv:1807.11013. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2015, arXiv:1409.1556. [Google Scholar]
- Misra, D. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2020, arXiv:1908.08681. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. arXiv 2015, arXiv:1502.03167. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Loshchilov, I.; Hutter, F. SGDR: Stochastic Gradient Descent with Warm Restarts. arXiv 2017, arXiv:1608.03983. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switerland, 2014; Volume 8693, pp. 740–755. ISBN 978-3-319-10601-4. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. arXiv 2021, arXiv:2011.08036. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-FCN: Object Detection via Region-Based Fully Convolutional Networks. arXiv 2016, arXiv:1605.06409. [Google Scholar]
- Singh, B.; Li, H.; Sharma, A.; Davis, L.S. R-FCN-3000 at 30fps: Decoupling Detection and Classification. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1081–1090. [Google Scholar]
- Kong, T.; Sun, F.; Yao, A.; Liu, H.; Lu, M.; Chen, Y. RON: Reverse Connection with Objectness Prior Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5244–5252. [Google Scholar]
- Zhou, P.; Ni, B.; Geng, C.; Hu, J.; Xu, Y. Scale-Transferrable Object Detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 528–537. [Google Scholar]
- Shen, Z.; Liu, Z.; Li, J.; Jiang, Y.-G.; Chen, Y.; Xue, X. DSOD: Learning Deeply Supervised Object Detectors from Scratch. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Honolulu, HI, USA, 21–26 July 2017; pp. 1937–1945. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. arXiv 2016, arXiv:1510.00149. [Google Scholar]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning Convolutional Neural Networks for Resource Efficient Inference. arXiv 2017, arXiv:1611.06440. [Google Scholar]
- He, Y.; Zhang, X.; Sun, J. Channel Pruning for Accelerating Very Deep Neural Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1398–1406. [Google Scholar]
- Kisantal, M.; Wojna, Z.; Murawski, J.; Naruniec, J.; Cho, K. Augmentation for Small Object Detection. In Proceedings of the 9th International Conference on Advances in Computing and Information Technology (ACITY 2019), Sydney, Australia, 21–22 December 2019; Aircc Publishing Corporation: Chennai, India, 2019; pp. 119–133. [Google Scholar]
- Li, J.; Liang, X.; Wei, Y.; Xu, T.; Feng, J.; Yan, S. Perceptual Generative Adversarial Networks for Small Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1951–1959. [Google Scholar]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Species Category | Annotations | Video Occurrences |
|---|---|---|
| Big fish | 3241 | 30 |
| Crab | 6538 | 29 |
| Jellyfish | 637 | 12 |
| Shrimp | 548 | 8 |
| Small fish | 9556 | 26 |
| Starfish | 5093 | 30 |
| Species Category | Annotations |
|---|---|
| Holothurian | 5537 |
| Echinus | 22343 |
| Starfish | 6841 |
| Scallop | 6720 |
| Environment | Versions or Model Number |
|---|---|
| CPU | Intel(R) Xeon(R) Gold 6130, 2.10 GHz |
| GPU | NVIDIA RTX 2080ti, Single GPU, Memory of 11G |
| OS | Ubuntu 16.04 |
| CUDA | V 10.2 |
| PyTorch | V 1.2.0 |
| Python | V 3.6 |
| Model | Method | mAP(%) (*, *) | Parameters (M) (*) | Model Size (MB) (*) | Speed (FPS) | |||
|---|---|---|---|---|---|---|---|---|
| Baseline | Dw | AFFM | Mish | |||||
| Model1 | √ | 80.73 | 38.74 | 154.6 | 51.85 | |||
| Model2 | √ | 80.38 (−0.35, 0) | 10.47 (−72.97%) | 46.8 (−69.72%) | 48.00 | |||
| Model3 | √ | √ | 81.16 (+0.43, +0.78) | 10.73 (−72.30%) | 47.8 (−69.08%) | 44.92 | ||
| Model4 | √ | √ | √ | 81.67 (+0.94, +1.29) | 10.73 (−72.30%) | 47.8 (−69.08%) | 44.18 | |
| Training Data | Method | Backbone | Input Size | mAP (%) | Parameters (M) | Model Size (MB) | GPU | Speed (FPS) |
|---|---|---|---|---|---|---|---|---|
| COCO [40] + 07 + 12 | YOLO v4 [12] | CSPDarknet53 | 416 × 416 | 89.88 | 64.04 | 244.7 | RTX 2080ti | 36.14 |
| Tiny YOLO v4 [41] | Tiny CSPDarknet53 | 416 × 416 | 78.41 | 5.96 | 22.6 | RTX 2080ti | 123.51 | |
| 07 + 12 | Faster-RCNN [11] | VGG16 | 1000 × 600 | 73.2 | 134.70 | ~ | K 40 | 7 |
| Faster-RCNN [18] | ResNet101 | 1000 × 600 | 76.4 | ~ | ~ | Titan X | 5 | |
| SA-FPN [26] | ResNet50 | 1280 × 768 | 79.1 | ~ | ~ | GTX 1080ti | 4 | |
| SSD300 [4] | VGG16 | 300 × 300 | 74.3 | 26.30 | ~ | Titan X | 46 | |
| R-FCN [42] | ResNet50 | 1000 × 600 | 77.4 | 31.90 | ~ | Titan X | 11 | |
| R-FCN3000 [43] | ResNet50 | 1000 × 600 | 79.5 | ~ | ~ | P6000 | 30 | |
| RON384++ [44] | VGG16 | 384 × 384 | 75.4 | ~ | ~ | Titan X | 15 | |
| STDN321 [45] | DenseNet169 | 321 × 321 | 79.3 | ~ | ~ | Titan Xp | 40.1 | |
| STDN513 [45] | DenseNet169 | 513 × 513 | 80.9 | ~ | ~ | Titan Xp | 28.6 | |
| DSOD300 [46] | DS/64-192-48-1 | 300 × 300 | 77.7 | 14.80 | 59.2 | Titan X | 17.4 | |
| DSOD300_lite [46] | DS/64-192-48-1 | 300 × 300 | 76.7 | 10.4 | 41.8 | Titan X | 25.8 | |
| DSOD300_smallest [46] | DS/64-64-16-1 | 300 × 300 | 73.6 | 5.9 | 23.5 | Titan X | ~ | |
| SqueezeNet-SSD [34] | SqueezeNet | 300 × 300 | 64.3 | 5.50 | ~ | Titan X | 44.7 | |
| MobileNet-SSD [34] | MobileNet | 300 × 300 | 68.0 | 5.50 | ~ | Titan X | 59.3 | |
| Pelee [33] | PeleeNet | 304 × 304 | 70.9 | 5.43 | ~ | TX2(FP32) | 77 | |
| Tiny DSOD [34] | G/32-48-64-80 | 300 × 300 | 72.1 | 0.95 | ~ | Titan X | 105 | |
| Ours | MobileNet v2 | 416 × 416 | 81.67 | 10.73 | 47.8 | RTX 2080ti | 44.18 |
| Method | mAP | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Table | Dog | Horse | Mbike | Person | Plant | Sheep | Sofa | Train | Tv |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RON384++ | 77.6 | 86.0 | 82.5 | 76.9 | 69.1 | 59.2 | 86.2 | 85.5 | 87.2 | 59.9 | 81.4 | 73.3 | 85.9 | 86.8 | 82.2 | 79.6 | 52.4 | 78.2 | 76.0 | 86.2 | 78.0 |
| SSD512 | 76.8 | 82.4 | 84.7 | 78.4 | 73.8 | 53.2 | 86.2 | 87.5 | 86.0 | 57.8 | 83.1 | 70.2 | 84.9 | 85.2 | 83.9 | 79.7 | 50.3 | 77.9 | 73.9 | 82.5 | 75.3 |
| R-FCN | 79.5 | 82.5 | 83.7 | 80.3 | 69.0 | 69.2 | 87.5 | 88.4 | 88.4 | 65.4 | 87.3 | 72.1 | 87.9 | 88.3 | 81.3 | 79.8 | 54.1 | 79.6 | 78.8 | 87.1 | 79.5 |
| Faster R-CNN | 76.4 | 79.8 | 80.7 | 76.2 | 68.3 | 55.9 | 85.1 | 85.3 | 89.8 | 56.7 | 87.8 | 69.4 | 88.3 | 88.9 | 80.9 | 78.4 | 41.7 | 78.6 | 79.8 | 85.3 | 72.0 |
| STDN513 | 80.9 | 86.1 | 89.3 | 79.5 | 74.3 | 61.9 | 88.5 | 88.3 | 89.4 | 67.4 | 86.5 | 79.5 | 86.4 | 89.2 | 88.5 | 79.3 | 53.0 | 77.9 | 81.4 | 86.6 | 85.5 |
| ours | 81.6 | 88.5 | 87.5 | 83.1 | 75.2 | 67.1 | 85.3 | 90.2 | 88.9 | 60.9 | 89.7 | 78.4 | 89.5 | 89.5 | 84.9 | 84.8 | 55.1 | 86.9 | 74.3 | 90.8 | 82.0 |
| Method | mAP (%) | Big Fish (%) | Crab (%) | Jelly Fish (%) | Shrimp (%) | Small Fish (%) | Star Fish (%) | Parameters (M) | Model Size (MB) | Speed (FPS) |
|---|---|---|---|---|---|---|---|---|---|---|
| YOLO v4 | 93.56 | 98.57 | 91.39 | 96.86 | 94.77 | 83.96 | 95.82 | 64.04 | 244.0 | 36.91 |
| Tiny YOLO v4 | 80.16 | 95.52 | 67.48 | 78.36 | 83.81 | 61.54 | 94.25 | 5.96 | 22.4 | 122.08 |
| Ours | 92.65 | 97.59 | 91.12 | 95.54 | 94.48 | 81.06 | 96.10 | 10.73 | 47.5 | 44.22 |
| Method | mAP (%) | Holothurian (%) | Echinus (%) | Starfish (%) | Scallop (%) |
|---|---|---|---|---|---|
| YOLO v4 | 81.01 | 71.21 | 89.94 | 85.58 | 77.30 |
| Tiny YOLO v4 | 67.83 | 54.09 | 80.43 | 77.94 | 58.87 |
| Ours | 79.54 | 70.38 | 90.11 | 85.52 | 72.16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, M.; Xu, S.; Song, W.; He, Q.; Wei, Q. Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sens. 2021, 13, 4706. https://doi.org/10.3390/rs13224706
Zhang M, Xu S, Song W, He Q, Wei Q. Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sensing. 2021; 13(22):4706. https://doi.org/10.3390/rs13224706
Chicago/Turabian StyleZhang, Minghua, Shubo Xu, Wei Song, Qi He, and Quanmiao Wei. 2021. "Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion" Remote Sensing 13, no. 22: 4706. https://doi.org/10.3390/rs13224706
APA StyleZhang, M., Xu, S., Song, W., He, Q., & Wei, Q. (2021). Lightweight Underwater Object Detection Based on YOLO v4 and Multi-Scale Attentional Feature Fusion. Remote Sensing, 13(22), 4706. https://doi.org/10.3390/rs13224706