Unstructured Road Segmentation Based on Road Boundary Enhancement Point-Cylinder Network Using LiDAR Sensor



Abstract
:
1. Introduction
- In unstructured road semantic segmentation, we directly perform feature extraction on point clouds while using the Point-Cylinder module instead of using projection methods. In this way, the point cloud information can be fully utilized, which makes the segmentation result more accurate.
- We propose a network structure with boundary enhancement. The accuracy of road boundary segmentation can be enhanced by calculating the boundary point cloud above the original point cloud road plane and then putting it into the neural network to compensate for the resulting feature map.
- The proposed method performs better in unstructured road scenes when compared with some open-source semantic segmentation algorithms.
2. Related Works
2.1. Structured Road Segmentation Method
2.2. Unstructured Road Segmentation Method
3. Methods
3.1. Network Overview
3.2. Road Boundary Enhancement Module
| Algorithm 1 3D RANSAC-Boundary algorithm |
| 1. init inliersResult, inliers, maxIterations, diatanceTol, zTol |
| 2. for i in range(maxIterations): |
| 3. while (inliers.size() < 3): |
| 4. inliers.append (random points) |
| 5. end while |
| 6. calculate the plane using the first three point in inliers to get parameters A, B, C, D |
| 7. for j in range(cloud.size()): |
| 8. if distance (cloud[i], plane) < diatanceTol: |
| 9. inliers.append(cloud[i]) |
| 10. end if |
| 11. end for |
| 12. if (inliers.size() > inliersResult.size()): |
| 13. inliersResult = inliers |
| 14. end if |
| 15. end for |
| 16. for (point:(cloud-inliersResult)) |
| 17. if ((the distance between point and last plane in the previous for cycle) < zTol) |
| 18. Results.append(point) |
| 19. end if |
| 20. end for |
| 21. return Results |
3.3. Network Structure
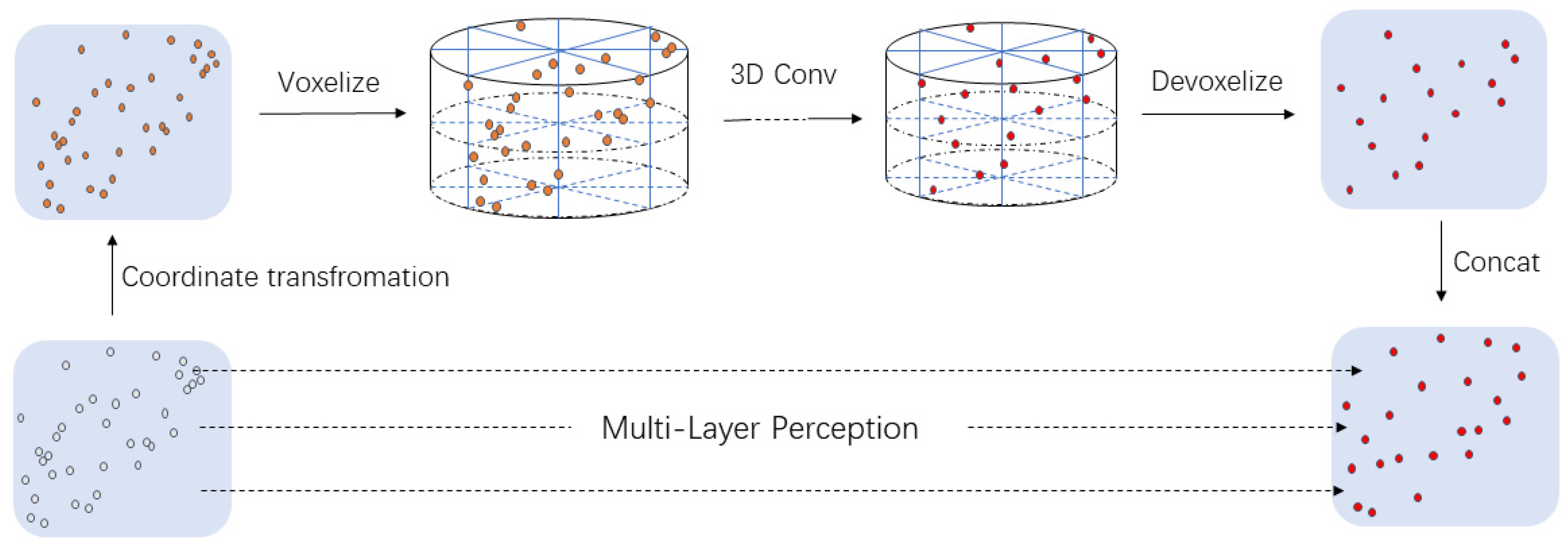
3.3.1. Point-Cylinder Substructure
3.3.2. Two-Branch 3D Encoder–Decoder Structure
3.3.3. Loss Function and Optimizer
4. Experiments and Results
4.1. Dataset
4.2. Metrics
4.3. Experimental Results
4.4. Summary
- (1)
- The BE-PCFCN model performs well in the task of road segmentation. The IoU of road segmentation exceeds the current best algorithm by 4% on the KITTI dataset.
- (2)
- In the simple unstructured road scenes, BE-PCFCN can accurately segment the road and environment around the road with the boundary enhancement module.
- (3)
- In the complex unstructured roads, BE-PCFCN has obvious advantages over other algorithms. However, when the input data are a 32-beams LiDAR point cloud, the point cloud on the ground will become sparse. Sometimes the road boundary feature cannot be obtained, which will result in poor segmentation results. However, once enough road boundary features are obtained, the network will still have an excellent output.
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chen, H.; Zhao, Y.; Ma, X. Critical Factors Analysis of Severe Traffic Accidents Based on Bayesian Network in China. J. Adv. Transp. 2020, 2020, 8878265. [Google Scholar] [CrossRef]
- Huang, J.; Kong, B.; Li, B.; Zheng, F. A New Method of Unstructured Road Detection Based on HSV Color Space and Road Features. In Proceedings of the 2007 International Conference on Information Acquisition, Jeju, Korea, 9–11 July 2007. [Google Scholar]
- Liu, Y.-B.; Zeng, M.; Meng, Q.-H. Unstructured Road Vanishing Point Detection Using Convolutional Neural Networks and Heatmap Regression. IEEE Trans. Instrum. Meas. 2021, 70. [Google Scholar] [CrossRef]
- Hu, Q.; Yang, B.; Xie, L.; Rosa, S.; Guo, Y.; Wang, Z.; Trigoni, N.; Markham, A. Randla-net: Efficient semantic segmentation of large-scale point clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 11108–11117. [Google Scholar]
- Cortinhal, T.; Tzelepis, G.; Aksoy, E.E. SalsaNext: Fast, Uncertainty-aware Semantic Segmentation of LiDAR Point Clouds for Autonomous Driving. arXiv 2020, arXiv:2003.03653. [Google Scholar]
- Milioto, A.; Vizzo, I.; Behley, J.; Stachniss, C. RangeNet ++: Fast and Accurate LiDAR Semantic Segmentation. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019. [Google Scholar]
- Wu, B.; Wan, A.; Yue, X.; Keutzer, K. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3d lidar point cloud. In Proceedings of the ICRA, IEEE International Conference on Robotics and Automation, Brisbane, Australia, 21–25 May 2018; pp. 1887–1893. [Google Scholar]
- Gao, B.; Xu, A.; Pan, Y.; Zhao, X.; Yao, W.; Zhao, H. Off-Road Drivable Area Extraction Using 3D LiDAR Data. arXiv 2020, arXiv:2003.04780. [Google Scholar]
- Cheng, Y.-T.; Patel, A.; Wen, C.; Bullock, D.; Habib, A. Intensity Thresholding and Deep Learning Based Lane Marking Extraction and Lane Width Estimation from Mobile Light Detection and Ranging (LiDAR) Point Clouds. Remote Sens. 2020, 12, 1379. [Google Scholar] [CrossRef]
- Liu, H.; Ye, Q.; Wang, H.; Chen, L.; Yang, J. A Precise and Robust Segmentation-Based Lidar Localization System for Automated Urban Driving. Remote Sens. 2019, 11, 1348. [Google Scholar] [CrossRef] [Green Version]
- Thomas, H.; Qi, C.R.; Deschaud, J.-E.; Marcotegui, B.; Goulette, F.; Guibas, L.J. Kpconv: Flexible and deformable convolution for point clouds. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6411–6420. [Google Scholar]
- Qi Charles, R.; Su, H.; Kaichun, M.; Guibas, L.J. PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Yuan, Y.; Jiang, Z.; Wang, Q. Video-based road detection via online structural learning. Neurocomputing 2015, 168, 336–347. [Google Scholar] [CrossRef]
- Broggi, A.; Cardarelli, E.; Cattani, S.; Sabbatelli, M. Terrain Mapping for Off-road Autonomous Ground Vehicles Using Rational B-Spline Surfaces and Stereo Vision. In Proceedings of the Intelligent Vehicles Symposium, Gold Coast, Australia, 23–26 June 2013. [Google Scholar]
- Wang, P.-S.; Liu, Y.; Sun, C.; Tong, X. Adaptive O-CNN: A Patch-based Deep Representation of 3D Shapes. ACM Trans. Graph. 2018, 37, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Wu, B.; Zhou, X.; Zhao, S.; Yue, X.; Keutzer, K. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In Proceedings of the IEEE International Conference on Robotics and Automation, Montreal, QC, Canada, 20–24 May 2019; pp. 4376–4382. [Google Scholar]
- Zhang, Y.; Zhou, Z.; David, P.; Yue, X.; Xi, Z.; Gong, B.; Foroosh, H. Polarnet: An improved grid representation for online lidar point clouds se-mantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–18 June 2020; pp. 9601–9610. [Google Scholar]
- Lei, H.; Akhtar, N.; Mian, A. Octree Guided CNN With Spherical Kernels for 3D Point Clouds. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9623–9632. [Google Scholar]
- Liu, Z.; Tang, H.; Lin, Y.; Han, S. Point-Voxel CNN for Efficient 3D Deep Learning. In Proceedings of the Conference and Workshop on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Graham, B.; Engelcke, M.; van der Maaten, L. 3D Semantic Segmentation With Submanifold Sparse Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9224–9232. [Google Scholar]
- Tang, H.; Liu, Z.; Zhao, S.; Lin, Y.; Lin, J.; Wang, H.; Han, S. Searching Efficient 3D Architectures with Sparse Point-Voxel Convolution. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Chen, L.-C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer Assisted Intervention Society, Munich, Germany, 5–9 October 2015; Springer: New York, NY, USA, 2015; pp. 234–241. [Google Scholar]
- Çiçek, Ö.; Abdulkadir, A.; Lienkamp, S.S.; Brox, T.; Ronneberger, O. 3D U-Net: Learning Dense Volumetric Segmentation from Sparse Annotation. arXiv 2016, arXiv:1606.06650. [Google Scholar]
- Liu, T.; Liu, D.; Yang, Y.; Chen, Z. Lidar-based Traversable Region Detection in Off-road Environment. In Proceedings of the 2019 Chinese Control Conference (CCC), Guangzhou, China, 27–30 July 2019. [Google Scholar]
- Holder, C.J.; Breckon, T.P.; Wei, X. From On-Road to Off: Transfer Learning Within a Deep Convolutional Neural Network for Segmentation and Classification of Off-Road Scenes. In Lecture Notes in Computer Science; Springer Science+Business Media: Berlin/Heidelberg, Germany, 2016; pp. 149–162. [Google Scholar]
- Zhou, H.; Zhu, X.; Song, X.; Ma, Y.; Wang, Z.; Li, H.; Lin, D. Cylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation. arXiv 2020, arXiv:2008.01550. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Choy, C.; Gwak, J.Y.; Savarese, S. 4D Spatio-Temporal ConvNets: Minkowski Convolutional Neural Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zhang, Z.; Sabuncu, M.R. Generalized cross entropy loss for training deep neural networks with noisy labels. In Advances in Neural Information Processing Systems, Proceedings of the 2018 Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2018; pp. 8778–8788. [Google Scholar]
- Berman, M.; Triki, A.R.; Blaschko, M.B. The lovász-softmax loss: A tractable surrogate for the optimization of the intersection-over-union measure in neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4413–4421. [Google Scholar]
- Qi, C.R.; Li, Y.; Su, H.; Guibas, L.J. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In Advances in Neural Information Processing Systems, Proceedings of the 2017 Conference on Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Morgan Kaufmann Publishers Inc.: Burlington, MA, USA, 2018; pp. 5099–5108. [Google Scholar]
- Gerdzhev, M.; Razani, R.; Taghavi, E.; Liu, B. Tornado-net: Multiview total variation semantic segmentation with diamond inception module. arXiv 2020, arXiv:2008.10544. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Road IoU | Buildings IoU | Vegetation IoU | |
|---|---|---|---|
| PointNet [12] | 61.6 | 41.4 | 31.0 |
| PointNet++ [34] | 72.0 | 62.3 | 41.5 |
| RandLA-Net [4] | 90.4 | 86.9 | 81.7 |
| Kpconv [11] | 88.8 | 90.5 | 84.8 |
| SalsaNext [5] | 91.7 | 90.2 | 81.8 |
| TORANDONet [35] | 89.7 | 91.3 | 85.6 |
| SPVNAS [22] | 90.2 | 91.6 | 86.1 |
| Cylinder3D [29] | 91.4 | 91.0 | 85.4 |
| BE-PCFCN without boundary enhancement | 90.4 | 90.8 | 80.7 |
| BE-PCFCN | 95.6 | 88.4 | 80.3 |
| Road IOU | Road Recall | Road Precision | |
|---|---|---|---|
| SPVNAS | 75.0 | 96.0 | 77.3 |
| BE-PCFCN | 77.2 | 97.8 | 78.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, Z.; Li, X.; Xu, J.; Yuan, J.; Tao, J. Unstructured Road Segmentation Based on Road Boundary Enhancement Point-Cylinder Network Using LiDAR Sensor. Remote Sens. 2021, 13, 495. https://doi.org/10.3390/rs13030495
Zhu Z, Li X, Xu J, Yuan J, Tao J. Unstructured Road Segmentation Based on Road Boundary Enhancement Point-Cylinder Network Using LiDAR Sensor. Remote Sensing. 2021; 13(3):495. https://doi.org/10.3390/rs13030495
Chicago/Turabian StyleZhu, Zijian, Xu Li, Jianhua Xu, Jianhua Yuan, and Ju Tao. 2021. "Unstructured Road Segmentation Based on Road Boundary Enhancement Point-Cylinder Network Using LiDAR Sensor" Remote Sensing 13, no. 3: 495. https://doi.org/10.3390/rs13030495
APA StyleZhu, Z., Li, X., Xu, J., Yuan, J., & Tao, J. (2021). Unstructured Road Segmentation Based on Road Boundary Enhancement Point-Cylinder Network Using LiDAR Sensor. Remote Sensing, 13(3), 495. https://doi.org/10.3390/rs13030495