
SDGH-Net: Ship Detection in Optical Remote Sensing Images Based on Gaussian Heatmap Regression

Abstract
:
1. Introduction
- To solve the overfitting problem of the fully connected layer, a novel and concise SDGH-Net model of ship detection in optical remote sensing image based on Gaussian heatmap regression is proposed. The model directly outputs the feature map of the ship, and the position of the ship can be obtained after simple post-processing, which improves the ship detection capability.
- To more accurately detect targets of different scales, we designed a multi-scale feature extraction and fusion network to construct multi-scale features using dilated convolution, which helps to improve the capability to detect different ships.
2. Materials and Methods
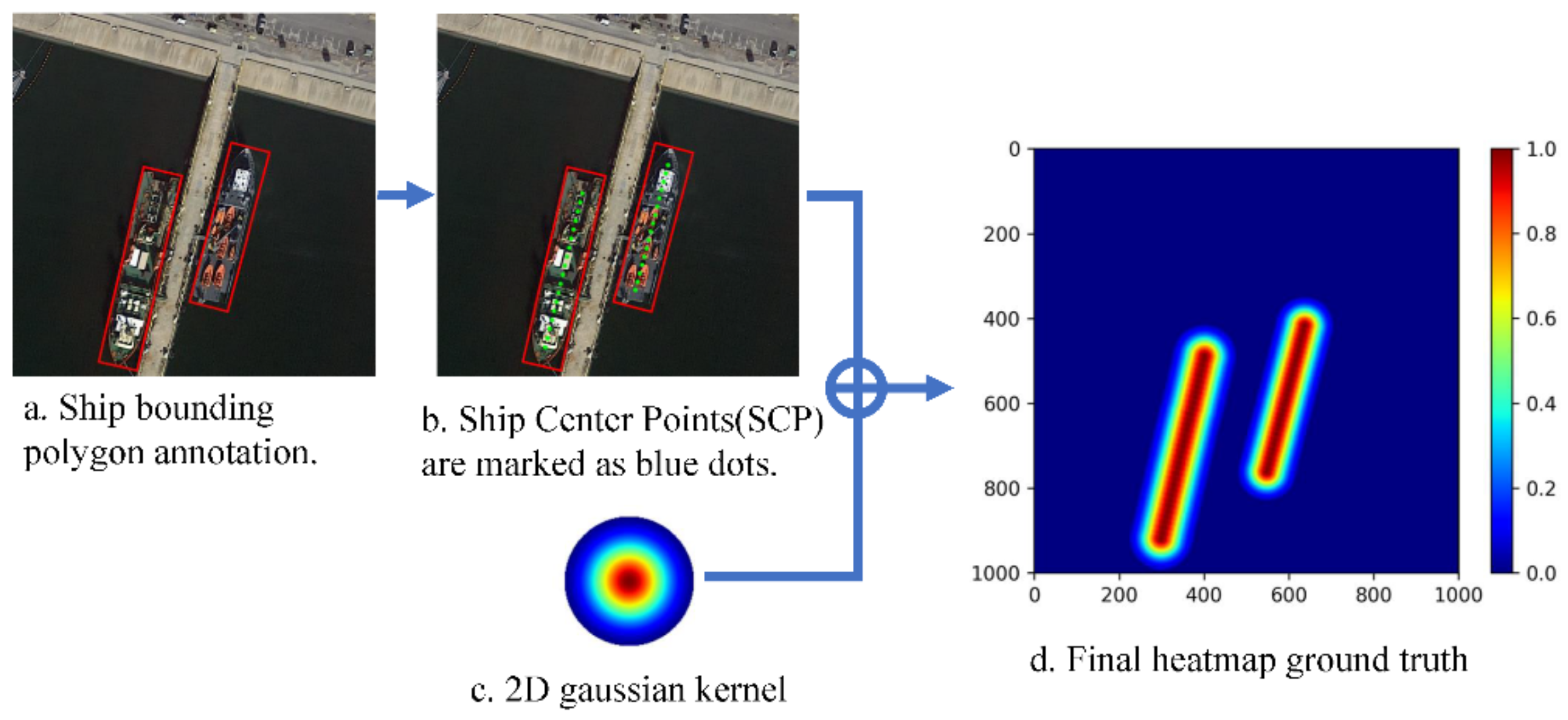
2.1. Ground Truth Generation
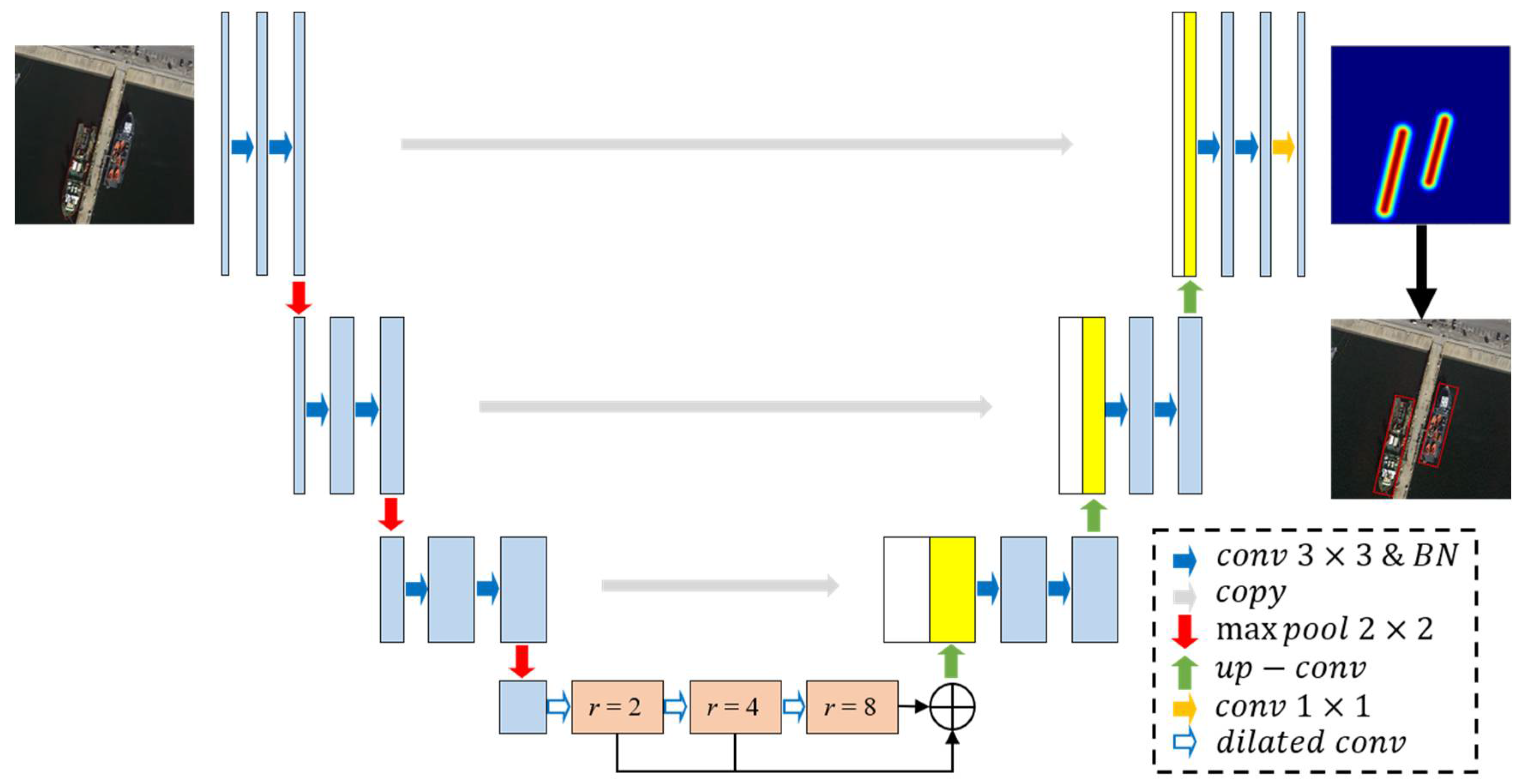
2.2. Improved Network Structure
2.2.1. Batch Normalization
2.2.2. Dilated Convolution
2.2.3. Loss Function
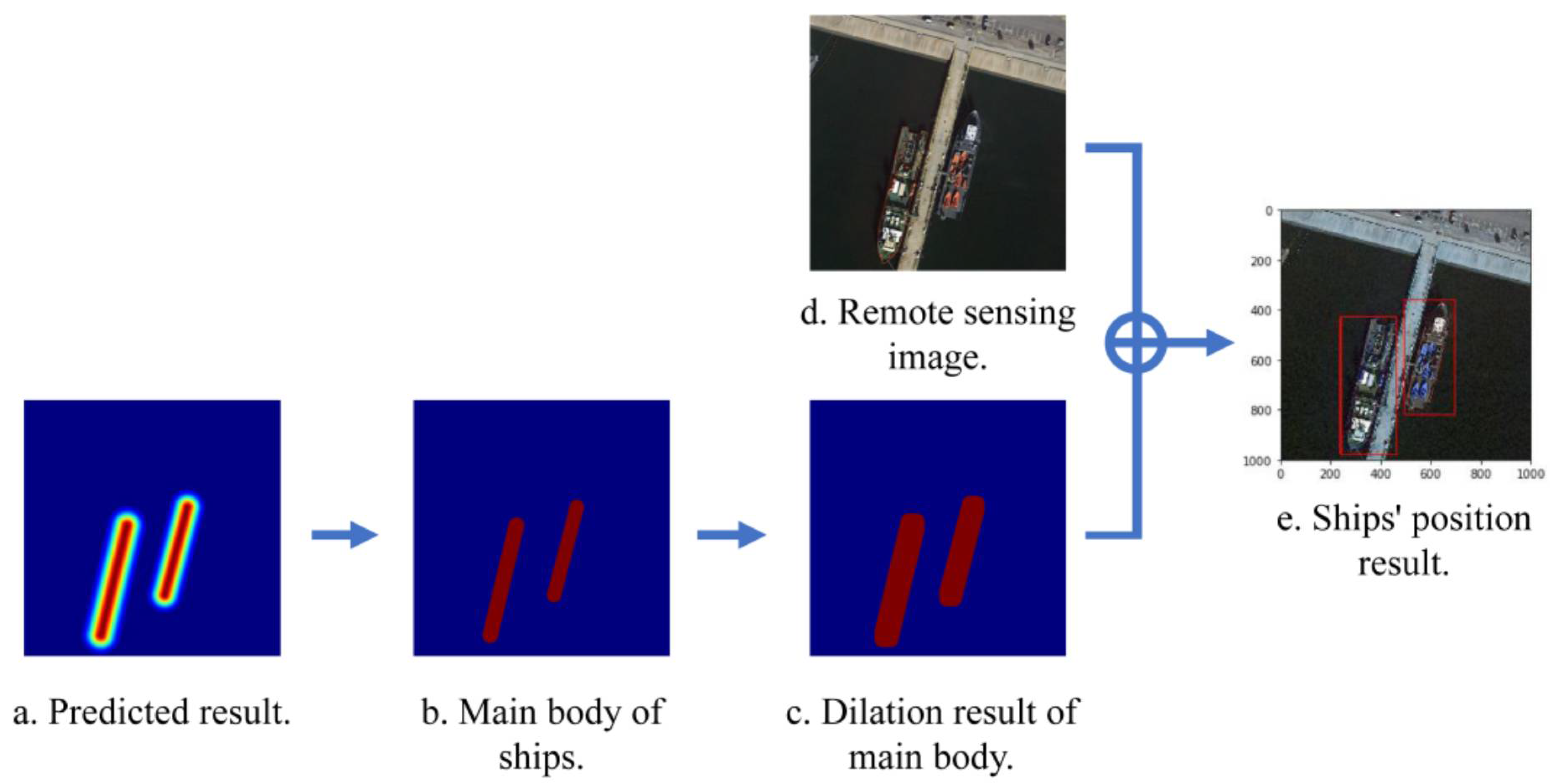
2.3. Post-Processing
2.4. Training
2.4.1. Data Augmentation
2.4.2. Adjust Learning Rate Dynamically
2.4.3. Early Stopping
2.5. Testing
Test Time Augmentation
3. Experiments and Results
3.1. Dataset
3.2. Evaluation Metrics
3.3. Implementation Details
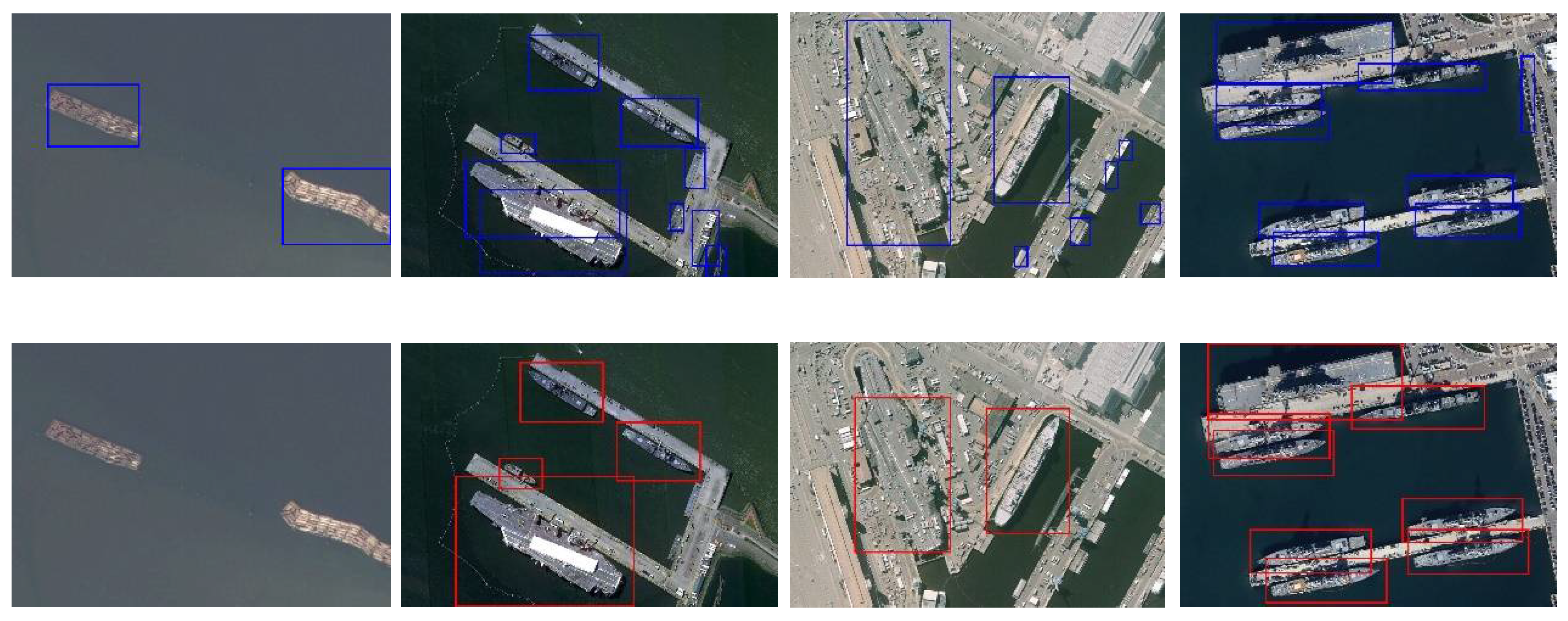
3.4. Comparative Experiments of Different Methods
3.5. Comparative Experiment of Different Tmain Values
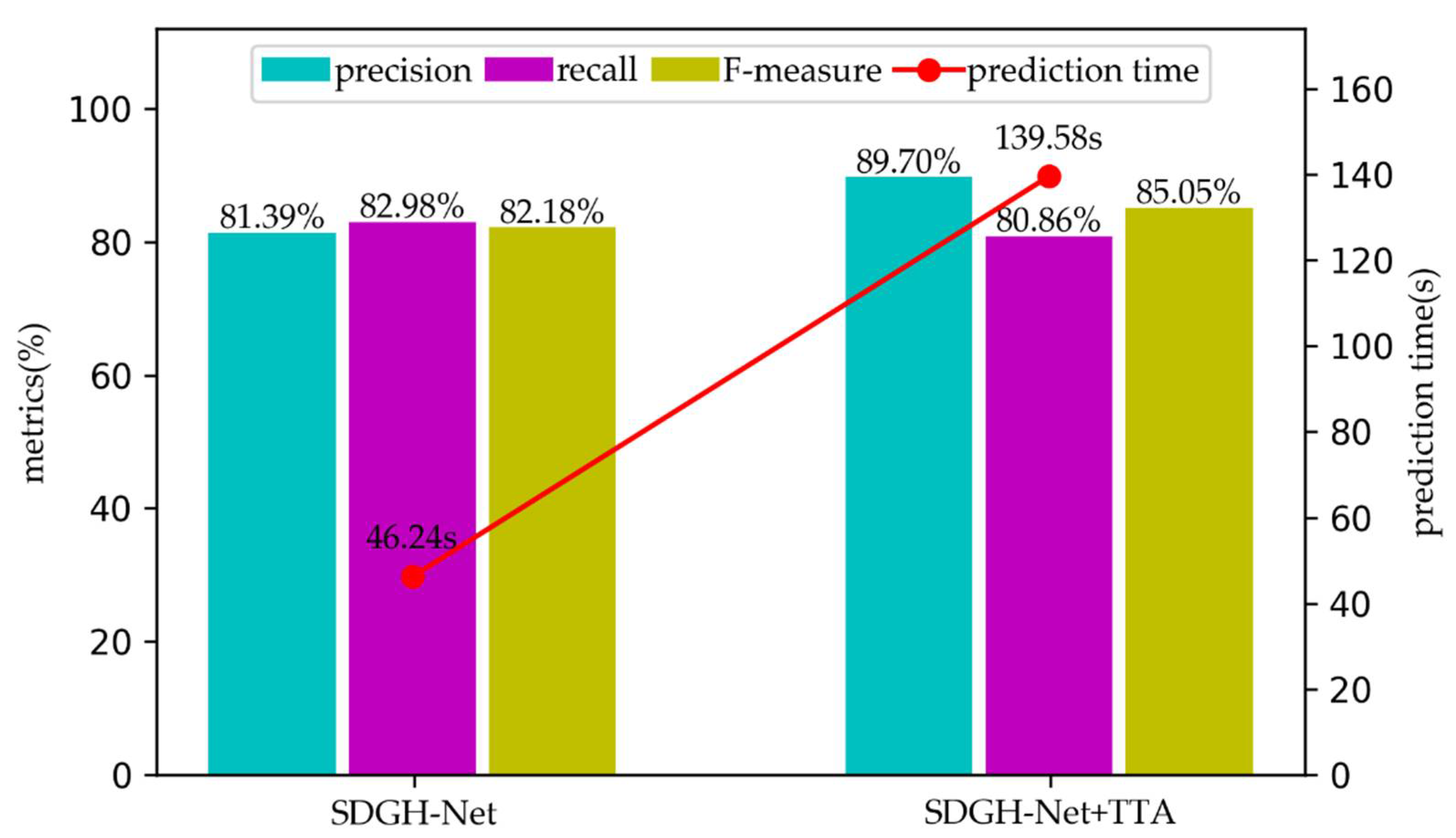
3.6. Comparative Experiment with or without TTA
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SDGH-Net | Ship Detection Network based on Gaussian Heatmap Regression |
| SAR | Synthetic Aperture Radar |
| CNN | Convolutional Neural Networks |
| R-CNN | Regions with CNN Features |
| SPP-net | Spatial Pyramid Pooling Networks |
| SSD | Single Shot MultiBox Detector |
| SLC | Sequence Local Context |
| HRoI | Horizontal Region of Interest |
| BFP | Balanced Feature Pyramid |
| CF-SDN | Coarse-to-fine Ship Detection Network |
| PBS | Priority-based Selection |
| NMS | Non-Maximum Suppression |
| SPP | Spatial Pyramid Pooling |
| SSD | Single Shot Multibox Detector |
| YOLO | You Only Look Once |
| SCPs | Ship Center Points |
| BN | Batch Normalization |
| IoU | Intersection over Union |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| TTA | Test Time Augmentation |
| MSE | Mean Squared Error |
| Adam | Adaptive Moment Estimation |
| GPU | Graphics Processing Unit |
References
- Zhu, C.R.; Zhou, H.; Wang, R.S.; Guo, J. A novel hierarchical method of ship detection from spaceborne optical image based on shape and texture features. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3446–3456. [Google Scholar] [CrossRef]
- Wang, S.Q. Ship wake detection in SAR images based on Radon transformation and morphologic image processing. J. Remote Sens. 2001, 5, 294–298. [Google Scholar]
- Brusch, S.; Lehner, S.; Fritz, T.; Soccorsi, M.; Soloviev, A.; van Schie, B. Ship surveillance with TerraSAR-X. IEEE Trans. Geosci. Remote Sens. 2010, 49, 1092–1103. [Google Scholar] [CrossRef]
- Corbane, C.; Najman, L.; Pecoul, E.; Demagistri, L.; Petit, M. A complete processing chain for ship detection using optical satellite imagery. Int. J. Remote Sens. 2010, 31, 5837–5854. [Google Scholar] [CrossRef]
- Zou, Z.; Shi, Z. Ship Detection in Spaceborne Optical Image With SVD Networks. IEEE Trans. Geosci. Remote Sens. 2016, 54, 5832–5845. [Google Scholar] [CrossRef]
- Shi, Z.W.; Yu, X.R.; Jiang, Z.G.; Li, B. Ship detection in high-resolution optical imagery based on anomaly detector and local shape feature. IEEE Trans. Geosci. Remote Sens. 2014, 52, 4511–4523. [Google Scholar] [CrossRef]
- Wang, Z.; Zhou, Y.; Wang, S.; Wang, F.; Xu, Z. House building extraction from high resolution remote sensing image based on IEU-Net. J. Remote Sens. 2021, in press. [Google Scholar]
- Xu, Z.; Zhou, Y.; Wang, S.; Wang, L.; Wang, Z. U-Net for urban green space classification in GF-2 remote sensing images. J. Image Graph. 2021, in press. [Google Scholar]
- Xu, Z.; Zhou, Y.; Wang, S.; Wang, L.; Li, F.; Wang, S.; Wang, Z. A novel intelligent classification method for urban green space based on high-resolution remote sensing images. Remote Sens. 2020, 12, 3845. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Feng, Y.; Diao, W.; Sun, X.; Yan, M.; Gao, X. Towards automated ship detection and category recognition from high-resolution aerial images. Remote Sens. 2019, 11, 1901. [Google Scholar] [CrossRef] [Green Version]
- Ma, J.; Zhou, Z.; Wang, B.; Zong, H.; Wu, F. Ship detection in optical satellite images via directional bounding boxes based on ship center and orientation prediction. Remote Sens. 2019, 11, 2173. [Google Scholar] [CrossRef] [Green Version]
- Tian, T.; Pan, Z.; Tan, X.; Chu, Z. Arbitrary-oriented inshore ship detection based on multi-scale feature fusion and contextual pooling on rotation region proposals. Remote Sens. 2020, 12, 339. [Google Scholar] [CrossRef] [Green Version]
- Guo, H.Y.; Yang, X.; Wang, N.N.; Song, B.; Gao, X.B. A rotational libra R-CNN method for ship detection. IEEE Trans. Geosci. Remote Sens. 2020, 58, 5772–5781. [Google Scholar] [CrossRef]
- Wu, Y.; Ma, W.; Gong, M.; Bai, Z.; Zhao, W.; Guo, Q.; Chen, X.; Miao, Q. A coarse-to-fine network for ship detection in optical remote sensing images. Remote Sens. 2020, 12, 246. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Sheng, W.; Jiang, J.; Jing, N.; Wang, Q.; Mao, Z. Priority branches for ship detection in optical remote sensing images. Remote Sens. 2020, 12, 1196. [Google Scholar] [CrossRef] [Green Version]
- Tang, G.; Liu, S.; Fujino, I.; Claramunt, C.; Wang, Y.; Men, S. H-YOLO: A single-shot ship detection approach based on region of interest preselected network. Remote Sens. 2020, 12, 4192. [Google Scholar] [CrossRef]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Wang, Q.; Zheng, Y.; Betke, M. SA-text: Simple but accurate detector for text of arbitrary shapes. arXiv 2019, arXiv:1911.07046. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as points. arXiv 2019, arXiv:1904.07850. [Google Scholar]
- Baek, Y.; Lee, B.; Han, D.; Yun, S.; Lee, H. Character region awareness for text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9365–9374. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: Munich, Germany, 2015; pp. 234–241. [Google Scholar]
- Liu, Z.; Yuan, L.; Weng, L.; Yang, Y. A high resolution optical satellite image dataset for ship recognition and some new baselines. In Proceedings of the 6th International Conference on Pattern Recognition Application and Methods (ICPRAM 2017), Porto, Portugal, 24–26 February 2017; pp. 324–331. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning (ICML), Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Yu, F.; Koltun, V. Multi-scale context aggregation by dilated convolutions. In Proceedings of the International Conference on Learning Representations, San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2999–3007. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and efficient object detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Tan, M.; Le, Q.V. Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Precision (%) | Recall (%) | F-Measure (%) |
|---|---|---|---|
| YOLOv3 | 92.85 | 76.14 | 83.66 |
| Retinanet | 87.13 | 68.81 | 76.88 |
| EfficientDet | 91.25 | 69.63 | 78.98 |
| Faster R-CNN | 93.32 | 57.53 | 71.18 |
| SDGH-Net+TTA | 89.70 | 80.86 | 85.05 |
| Methods | Backbone | Prediction Time (s) | Number of Parameters (MB) |
|---|---|---|---|
| YOLOv3 | Darknet-53 | 19.85 | 235 |
| Retinanet | ResNet-50 | 37.16 | 139 |
| Efficientdet | EfficientNet | 42.82 | 27 |
| Faster R-CNN | ResNet-50 | 174.02 | 108 |
| SDGH-Net+TTA | − | 139.58 | 115 |
| Precision | Recall | F-Measure | |
|---|---|---|---|
| 0.5 | 90.67 | 79.97 | 84.98 |
| 0.6 | 89.70 | 80.86 | 85.05 |
| 0.7 | 86.34 | 78.25 | 82.10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Z.; Zhou, Y.; Wang, F.; Wang, S.; Xu, Z. SDGH-Net: Ship Detection in Optical Remote Sensing Images Based on Gaussian Heatmap Regression. Remote Sens. 2021, 13, 499. https://doi.org/10.3390/rs13030499
Wang Z, Zhou Y, Wang F, Wang S, Xu Z. SDGH-Net: Ship Detection in Optical Remote Sensing Images Based on Gaussian Heatmap Regression. Remote Sensing. 2021; 13(3):499. https://doi.org/10.3390/rs13030499
Chicago/Turabian StyleWang, Zhenqing, Yi Zhou, Futao Wang, Shixin Wang, and Zhiyu Xu. 2021. "SDGH-Net: Ship Detection in Optical Remote Sensing Images Based on Gaussian Heatmap Regression" Remote Sensing 13, no. 3: 499. https://doi.org/10.3390/rs13030499
APA StyleWang, Z., Zhou, Y., Wang, F., Wang, S., & Xu, Z. (2021). SDGH-Net: Ship Detection in Optical Remote Sensing Images Based on Gaussian Heatmap Regression. Remote Sensing, 13(3), 499. https://doi.org/10.3390/rs13030499