
Semi-Supervised Multi-Temporal Deep Representation Fusion Network for Landslide Mapping from Aerial Orthophotos




Abstract
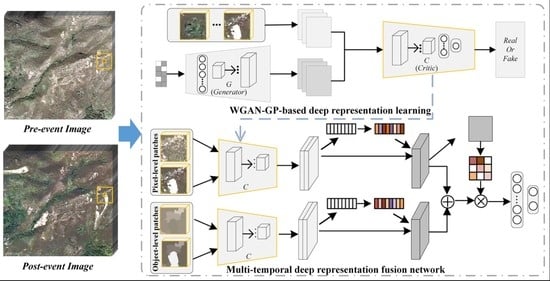
:
1. Introduction
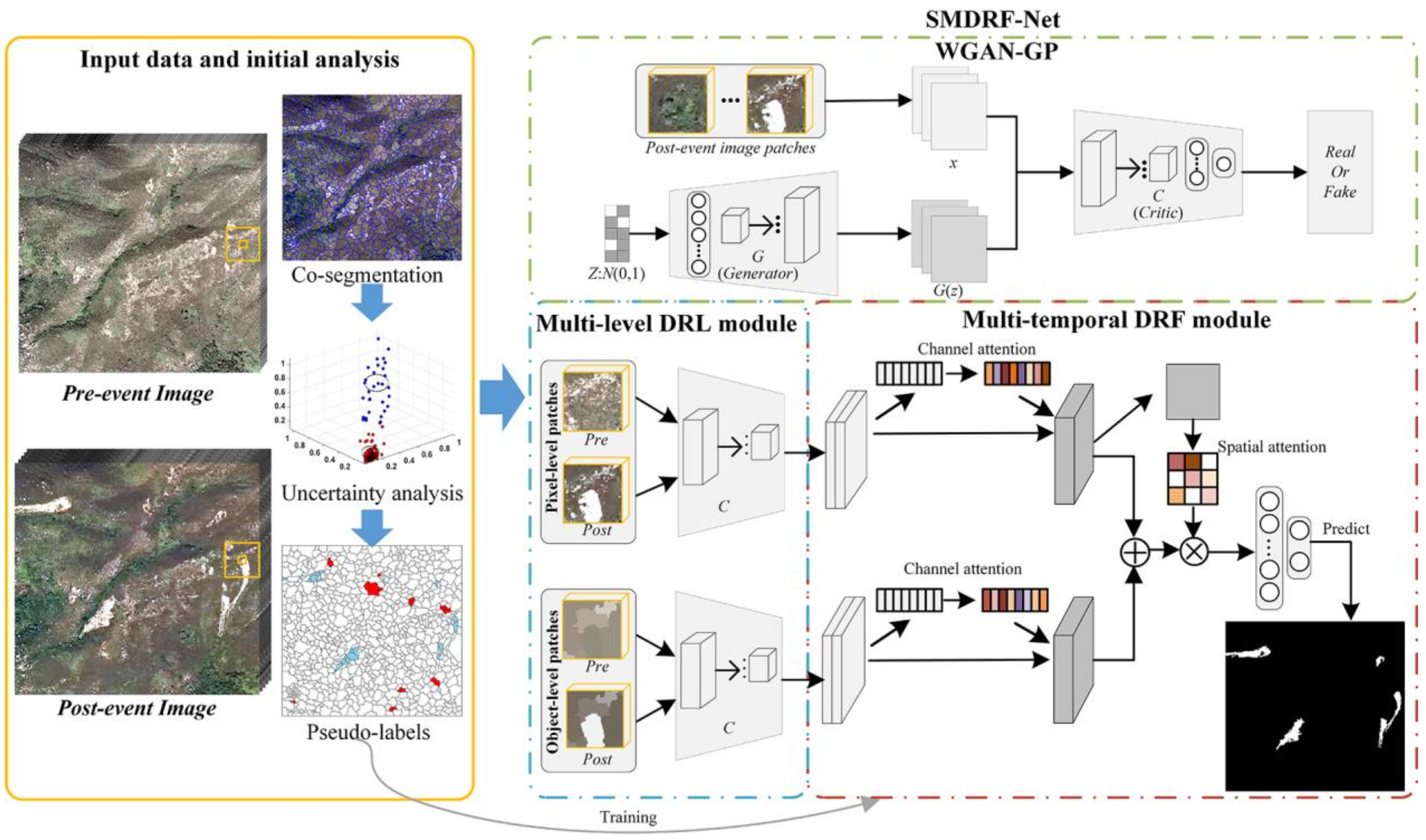
- This study proposes a semi-supervised deep-learning-based LM framework for learning spatio-temporal relationships between pre- and post-event imagery and directly achieving LM results without manual annotations by automatically generating pseudo-labels based on a comprehensive uncertainty index.
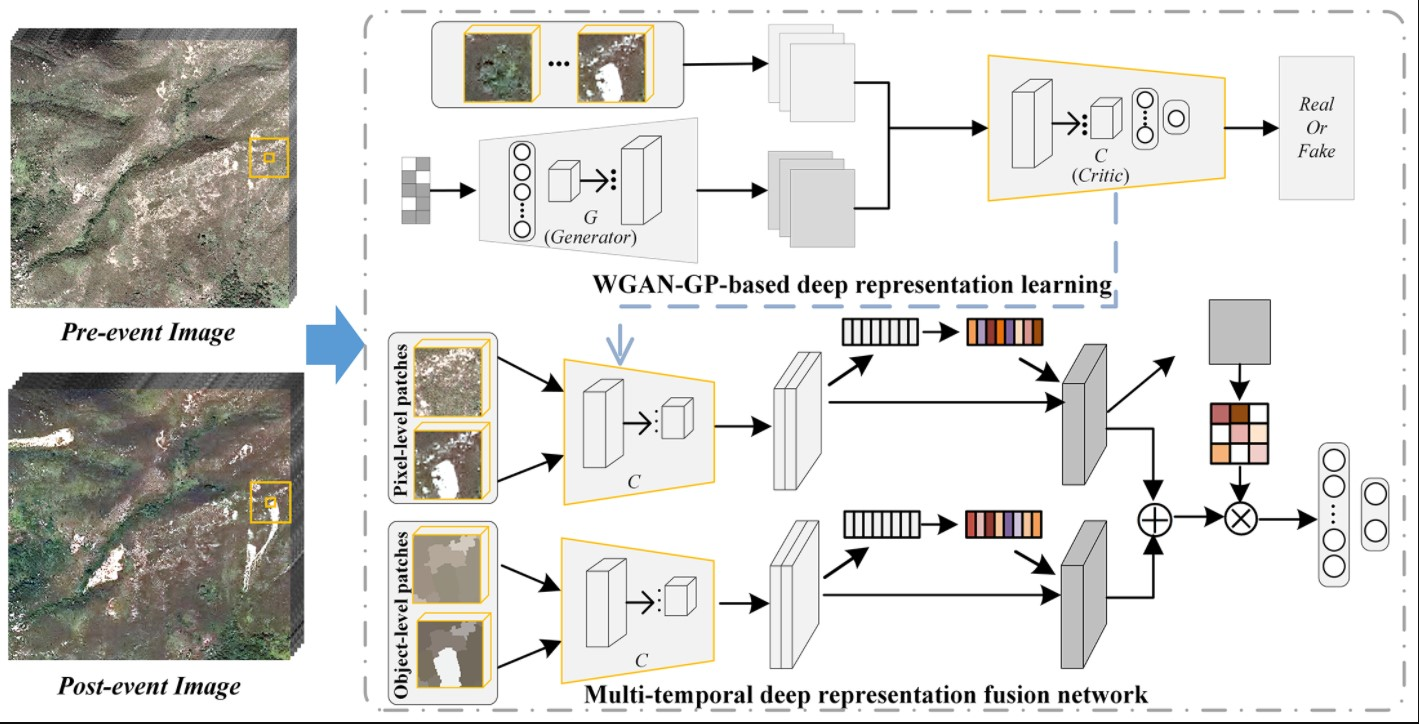
- WGAN-GP is adopted to extract discriminative deep features through unsupervised adversarial training. It is then applied as the deep feature extractor in the SMDRF-Net through transfer learning to efficiently learn pixel- and object-level deep representations. This can improve the class separability between landslide and non-landslide patterns while retaining the precise outlines of landslide objects in the high-level feature space.
- The novel spatio-temporal DRF in the SMDRF-Net is developed to merge multi-temporal and multi-level deep representations using the channel and spatial attention; the former exploits the non-linear dependencies of multi-temporal deep feature maps whereas the latter characterizes the inter-spatial relationship of the combined representations. Integrating the two can further enhance the feature representation ability of network models.
2. Proposed Method
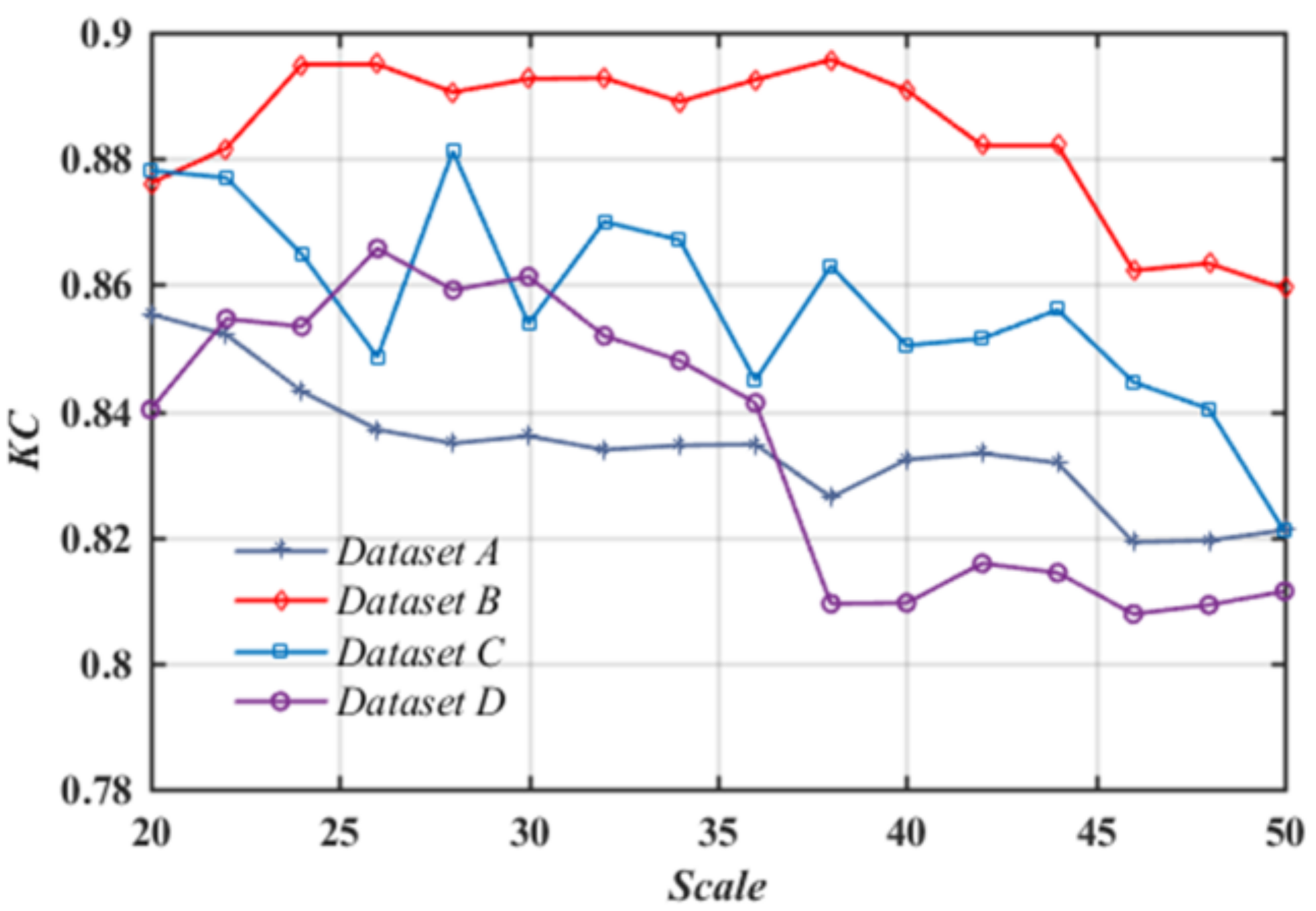
2.1. Initial CD and Analysis
2.2. The Proposed SMDRF-Net
2.2.1. Unsupervised DRL with WGAN-GP
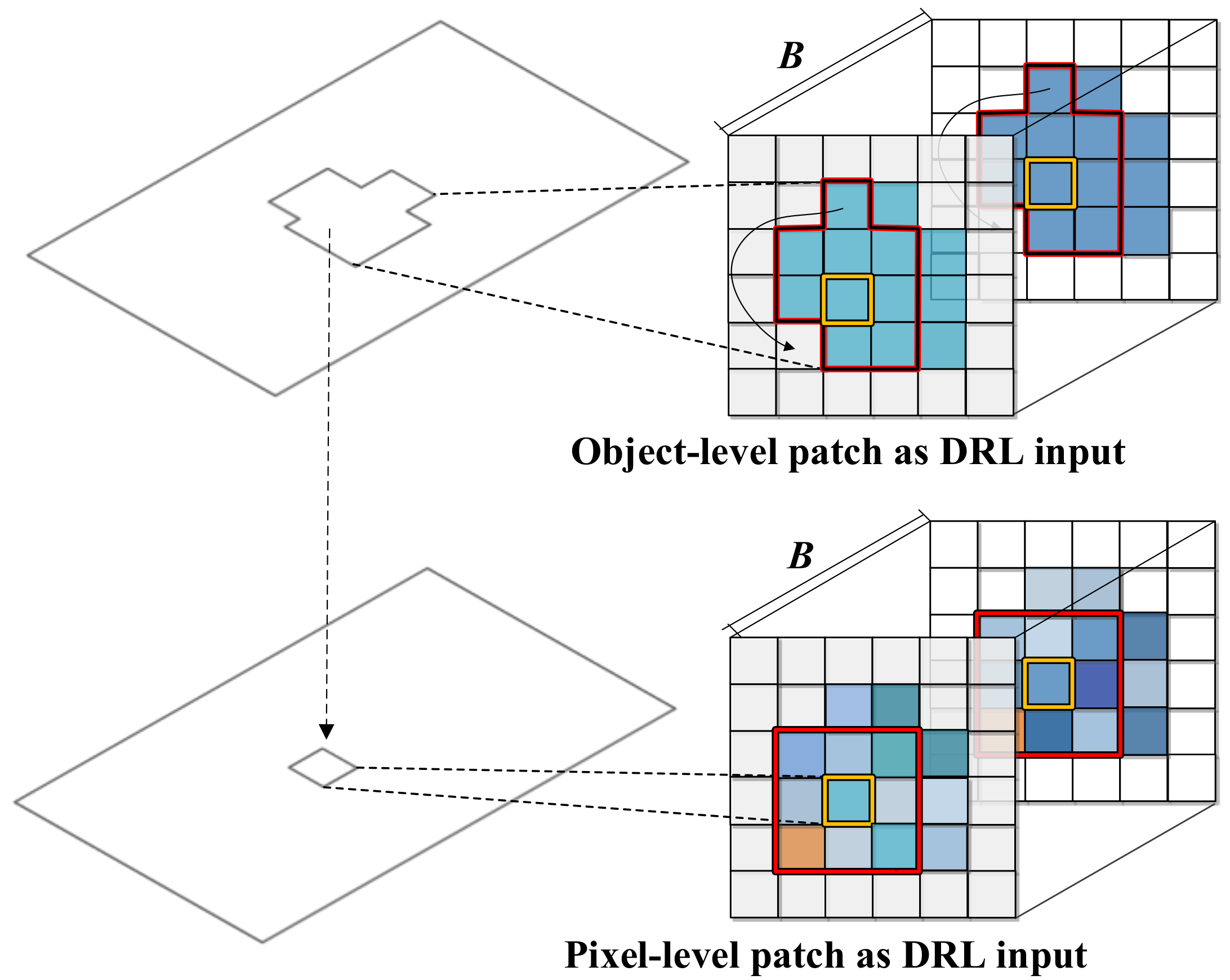
2.2.2. Multi-Level DRL Module Based on Transfer Learning
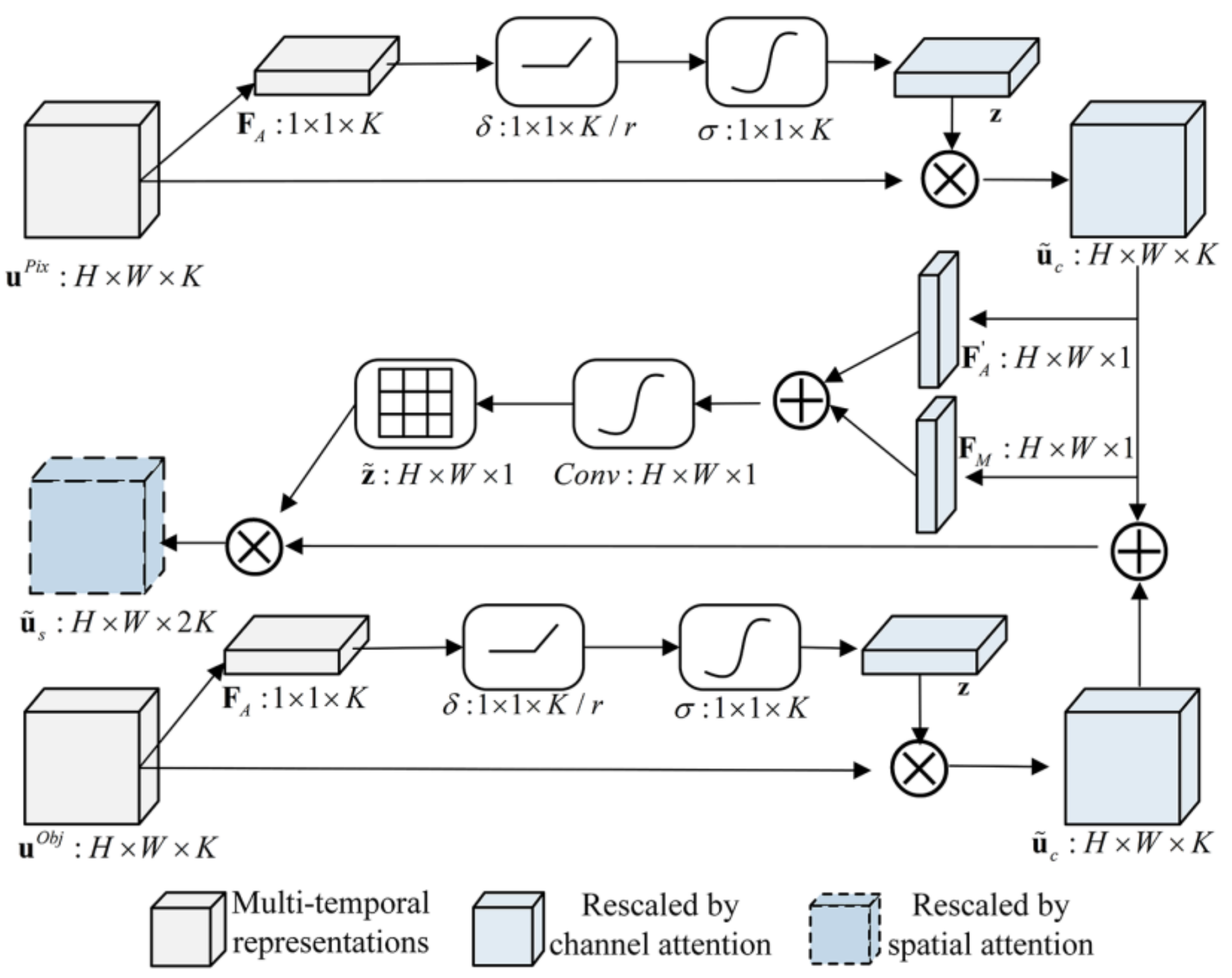
2.2.3. Attention-Based Multi-Temporal DRF Module
3. Experiments and Analyses
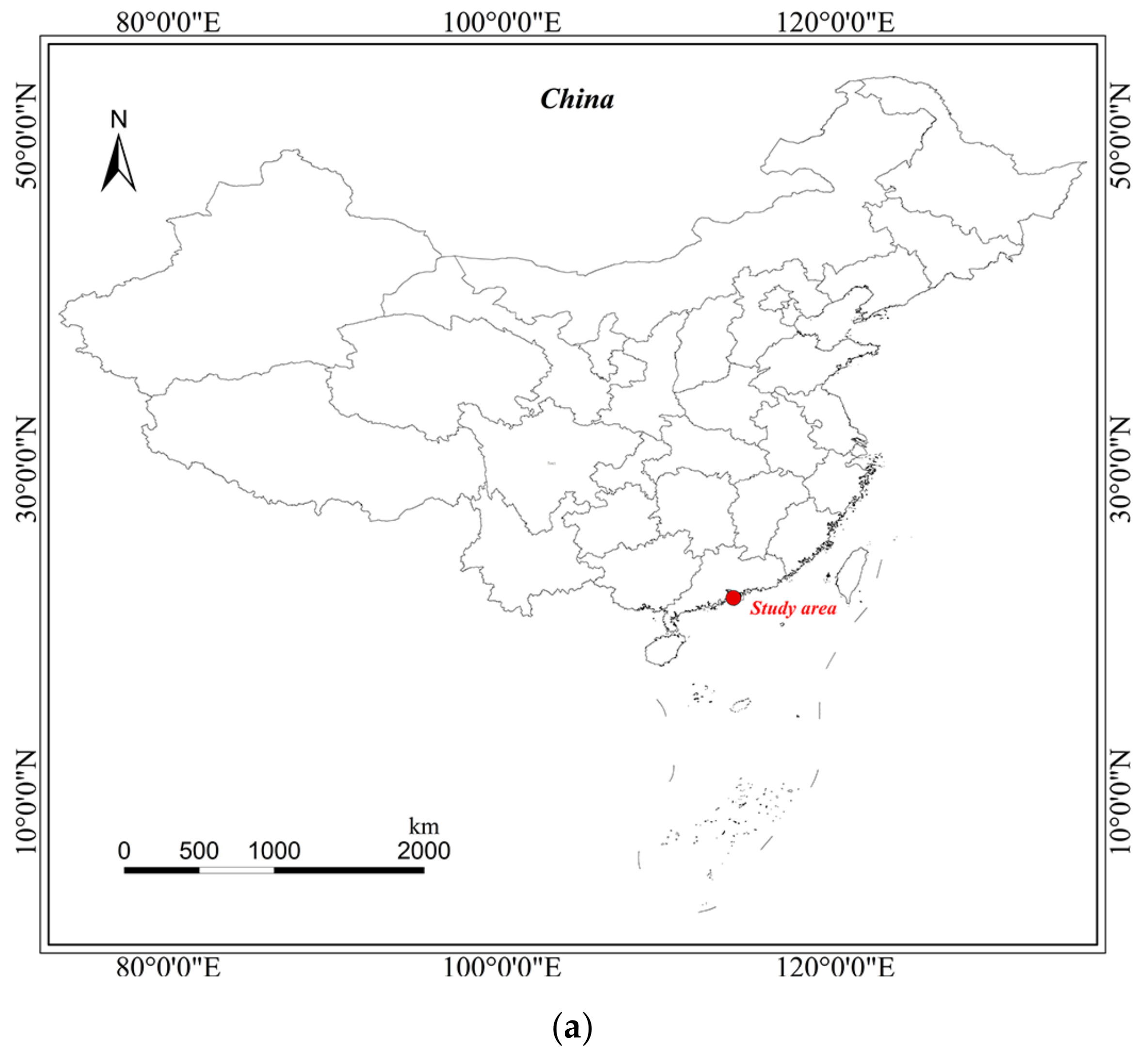
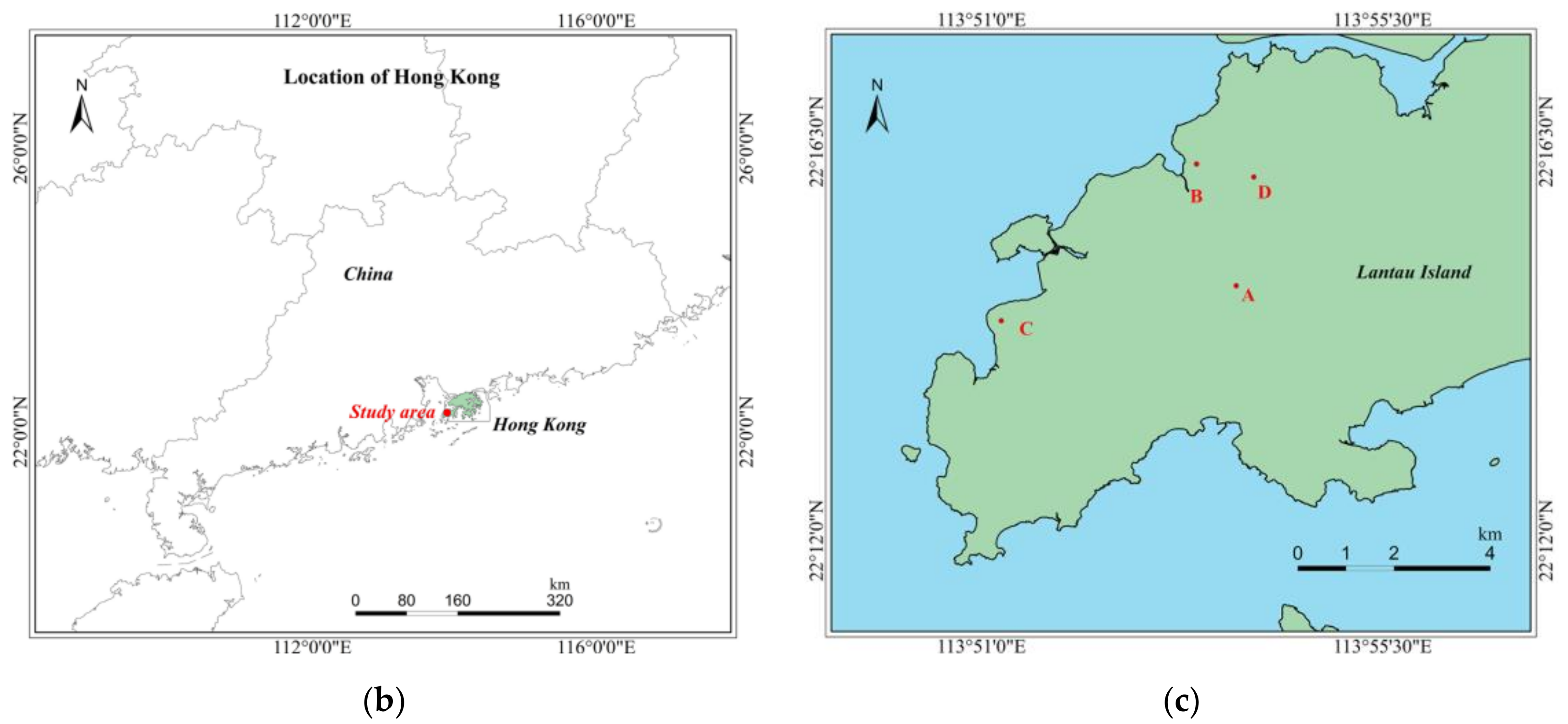
3.1. Dataset Descriptions
3.2. Experimental Setting
3.2.1. General Information
- Completeness (CP): , where is the number of correctly detected landslide pixels and indicates the number of real landslide pixels in the ground truth map;
- Correctness (CR): , where is the number of all detected landslide pixels;
- Quality (QA): , where is the number of misdetected landslide pixels;
- Kappa coefficient (KC): , where and are the proportion of agreement and chance agreement with respect to the confusion matrix, respectively;
- Overall Accuracy (OA): , where is the number of incorrectly detected landslide pixels in the LM map and is the total number of pixels in the ground truth map.
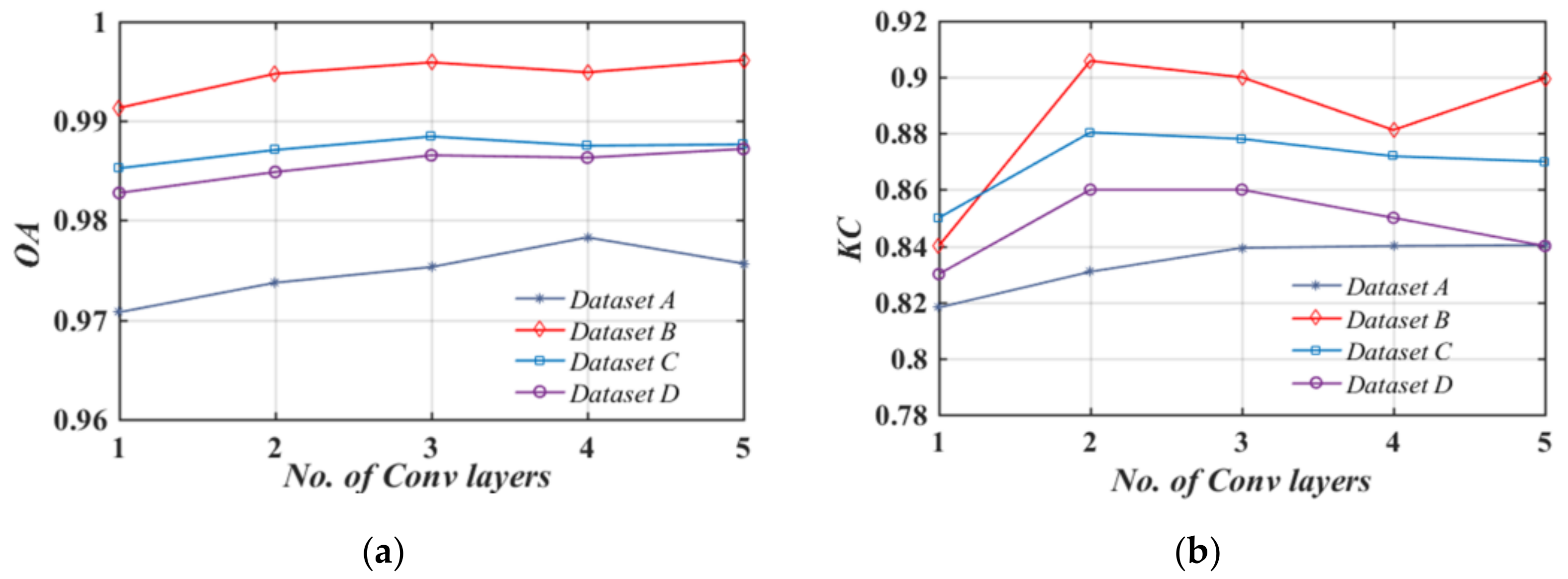
3.2.2. Network Structures
3.2.3. Network Training
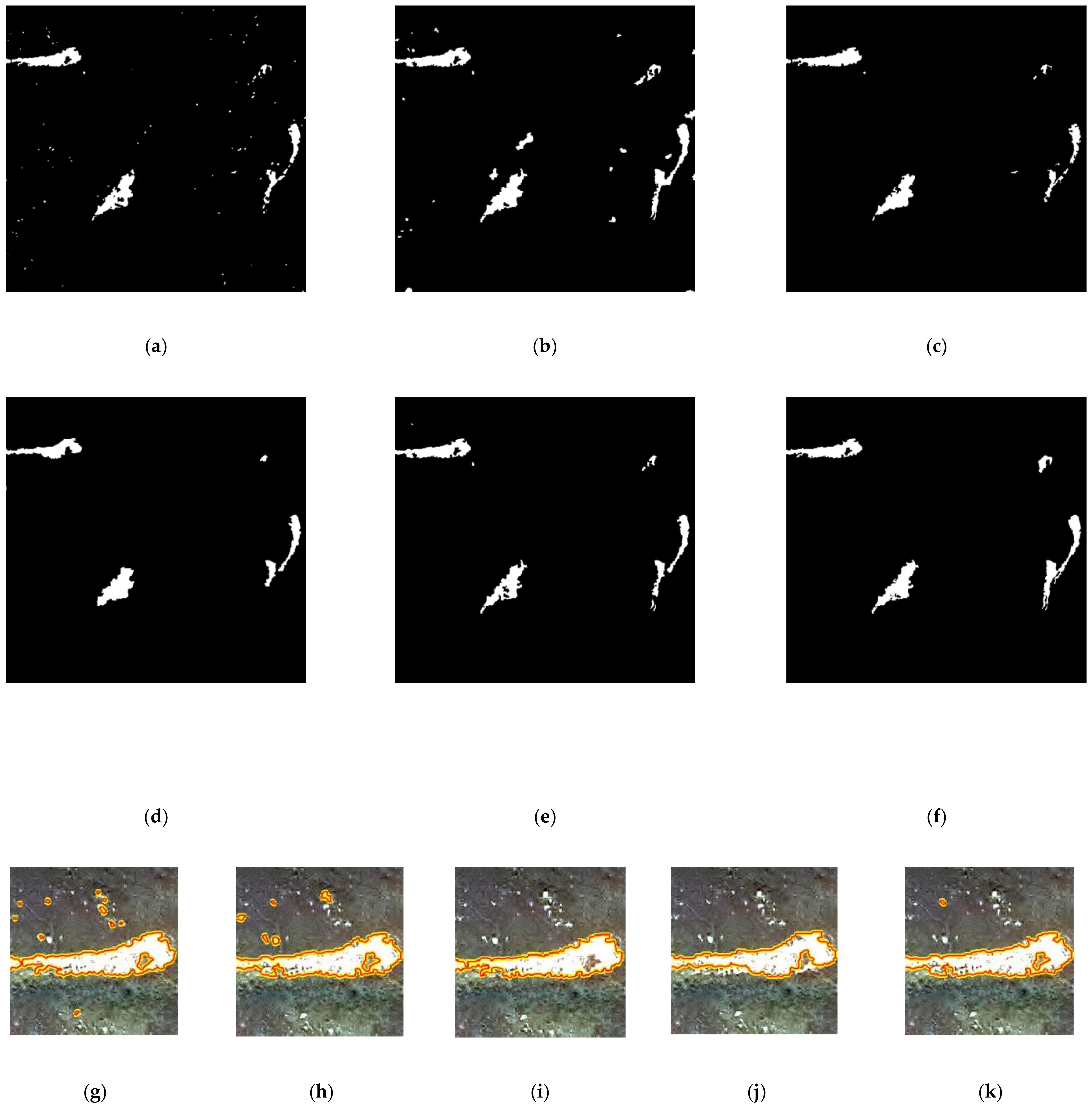
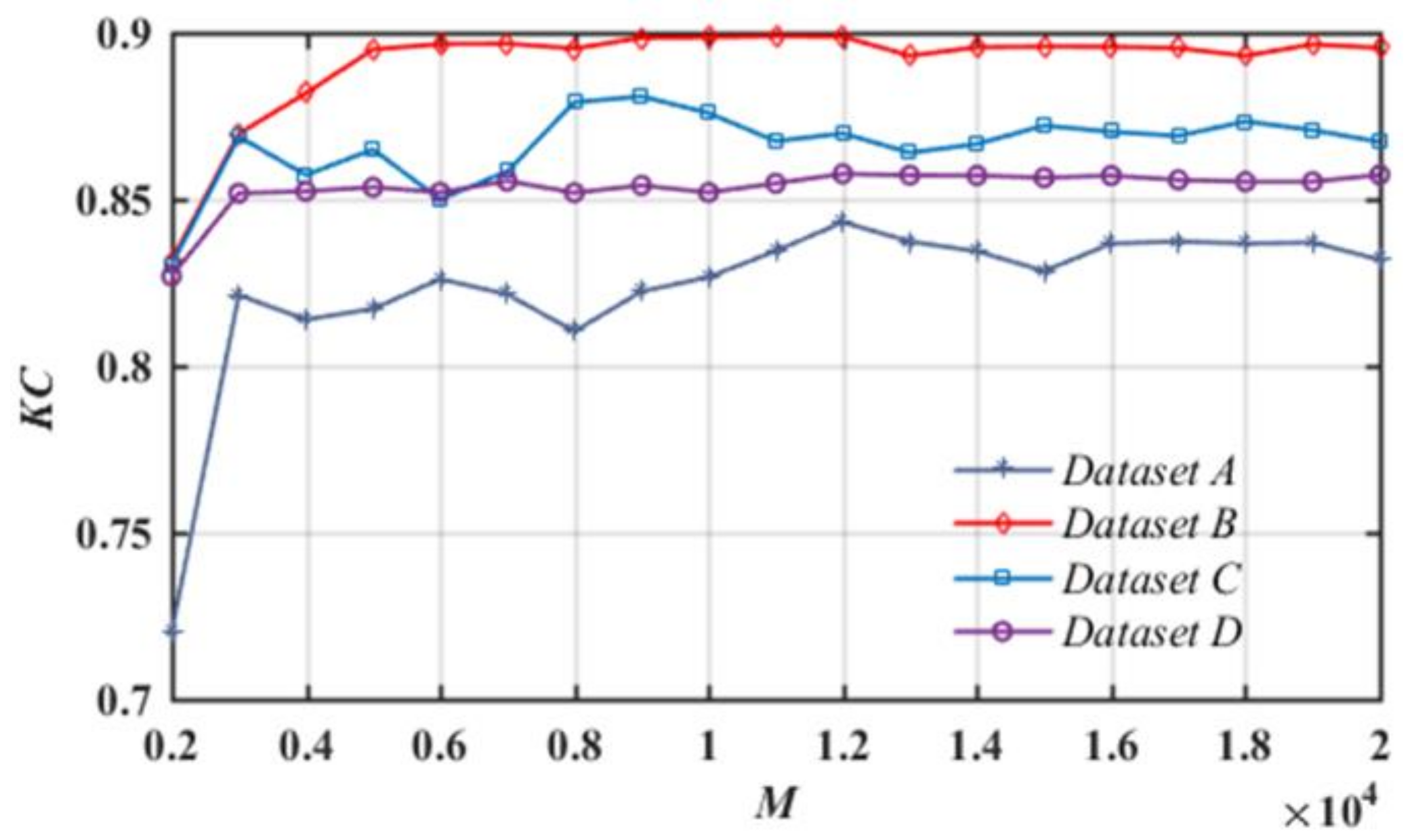
3.3. Results and Analysis
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Park, N.-W.; Chi, K. Quantitative assessment of landslide susceptibility using high-resolution remote sensing data and a generalized additive model. Int. J. Remote Sens. 2008, 29, 247–264. [Google Scholar] [CrossRef]
- Yang, X.; Chen, L. Using multi-temporal remote sensor imagery to detect earthquake-triggered landslides. Int. J. Appl. Earth Obs. 2010, 12, 487–495. [Google Scholar] [CrossRef]
- Ciampalini, A.; Raspini, F.; Bianchini, S.; Frodella, W.; Bardi, F.; Lagomarsino, D.; Di Traglia, F.; Moretti, S.; Proietti, C.; Pagliara, P.; et al. Remote sensing as tool for development of landslide databases: The case of the Messina Province (Italy) geodatabase. Geomorphol. 2015, 249, 103–118. [Google Scholar] [CrossRef]
- Hervás, J.; Barredo, I.J.; Rosin, P.L.; Pasuto, A.; Mantovani, F.; Silvano, S. Monitoring landslides from optical remotely sensed imagery: The case history of Tessina landslide, Italy. Geomorphol. 2003, 54, 63–75. [Google Scholar] [CrossRef]
- Liu, P.; Li, Z.; Hoey, T.; Kincal, C.; Zhang, J.; Zeng, Q.; Muller, J.-P. Using advanced InSAR time series techniques to monitor landslide movements in Badong of the Three Gorges region, China. Int. J. Appl. Earth Obs. Geoinformation 2013, 21, 253–264. [Google Scholar] [CrossRef]
- Lu, P.; Stumpf, A.; Kerle, N.; Casagli, N. Object-Oriented Change Detection for Landslide Rapid Mapping. IEEE Geosci. Remote Sens. Lett. 2011, 8, 701–705. [Google Scholar] [CrossRef]
- Metternicht, G.; Hurni, L.; Gogu, R. Remote sensing of landslides: An analysis of the potential contribution to geo-spatial systems for hazard assessment in mountainous environments. Remote Sens. Environ. 2005, 98, 284–303. [Google Scholar] [CrossRef]
- Zhong, C.; Liu, Y.; Gao, P.; Chen, W.; Li, H.; Hou, Y.; Nuremanguli, T.; Ma, H. Landslide mapping with remote sensing: Challenges and opportunities. Int. J. Remote Sens. 2020, 41, 1555–1581. [Google Scholar] [CrossRef]
- Guzzetti, F.; Mondini, A.C.; Cardinali, M.; Fiorucci, F.; Santangelo, M.; Chang, K.-T. Landslide inventory maps: New tools for an old problem. Earth-Science Rev. 2012, 112, 42–66. [Google Scholar] [CrossRef] [Green Version]
- Lv, Z.; Liu, T.; Wan, Y.; Benediktsson, J.A.; Zhang, X. Post-Processing Approach for Refining Raw Land Cover Change Detection of Very High-Resolution Remote Sensing Images. Remote Sens. 2018, 10, 472. [Google Scholar] [CrossRef] [Green Version]
- Keyport, R.N.; Oommen, T.; Martha, T.R.; Sajinkumar, K.; Gierke, J.S. A comparative analysis of pixel- and object-based detection of landslides from very high-resolution images. Int. J. Appl. Earth Obs. Geoinformation 2018, 64, 1–11. [Google Scholar] [CrossRef]
- Lv, Z.; Liu, T.; Benediktsson, J.A. Object-Oriented Key Point Vector Distance for Binary Land Cover Change Detection Using VHR Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2020, 58, 6524–6533. [Google Scholar] [CrossRef]
- Zhang, X.; Shi, W.; Lv, Z.; Peng, F. Land Cover Change Detection from High-Resolution Remote Sensing Imagery Using Multitemporal Deep Feature Collaborative Learning and a Semi-supervised Chan–Vese Model. Remote Sens. 2019, 11, 2787. [Google Scholar] [CrossRef] [Green Version]
- Lu, P.; Qin, Y.; Li, Z.; Mondini, A.C.; Casagli, N. Landslide mapping from multi-sensor data through improved change detection-based Markov random field. Remote Sens. Environ. 2019, 231, 111235. [Google Scholar] [CrossRef]
- Li, Z.; Shi, W.; Myint, S.W.; Lu, P.; Wang, Q. Semi-automated landslide inventory mapping from bitemporal aerial photographs using change detection and level set method. Remote Sens. Environ. 2016, 175, 215–230. [Google Scholar] [CrossRef]
- Zhang, X.; Shi, W.; Liang, P.; Hao, M. Level set evolution with local uncertainty constraints for unsupervised change detection. Remote Sens. Lett. 2017, 8, 811–820. [Google Scholar] [CrossRef]
- Zhang, X.; Shi, W.; Hao, M.; Shao, P.; Lyu, X. Level set incorporated with an improved MRF model for unsupervised change detection for satellite images. Eur. J. Remote Sens. 2017, 50, 202–210. [Google Scholar] [CrossRef] [Green Version]
- Bazi, Y.; Melgani, F.; Al-Sharari, H.D. Unsupervised Change Detection in Multispectral Remotely Sensed Imagery With Level Set Methods. IEEE Trans. Geosci. Remote Sens. 2010, 48, 3178–3187. [Google Scholar] [CrossRef]
- Bazi, Y.; Bruzzone, L.; Melgani, F. An unsupervised approach based on the generalized Gaussian model to automatic change detection in multitemporal SAR images. IEEE Trans. Geosci. Remote Sens. 2005, 43, 874–887. [Google Scholar] [CrossRef] [Green Version]
- Cheng, K.-S.; Wei, C.; Chang, S. Locating landslides using multi-temporal satellite images. Adv. Space Res. 2004, 33, 296–301. [Google Scholar] [CrossRef]
- Mondini, A.C.; Guzzetti, F.; Reichenbach, P.; Rossi, M.; Cardinali, M.; Ardizzone, F. Semi-automatic recognition and mapping of rainfall induced shallow landslides using optical satellite images. Remote Sens. Environ. 2011, 115, 1743–1757. [Google Scholar] [CrossRef]
- Li, Z.; Shi, W.; Lu, P.; Yan, L.; Wang, Q.; Miao, Z. Landslide mapping from aerial photographs using change detection-based Markov random field. Remote Sens. Environ. 2016, 187, 76–90. [Google Scholar] [CrossRef] [Green Version]
- Nichol, J.; Wong, M.S. Satellite remote sensing for detailed landslide inventories using change detection and image fusion. Int. J. Remote Sens. 2005, 26, 1913–1926. [Google Scholar] [CrossRef]
- Stumpf, A.; Kerle, N. Object-oriented mapping of landslides using Random Forests. Remote Sens. Environ. 2011, 115, 2564–2577. [Google Scholar] [CrossRef]
- Kurtz, C.; Stumpf, A.; Malet, J.-P.; Gançarski, P.; Puissant, A.; Passat, N. Hierarchical extraction of landslides from multiresolution remotely sensed optical images. ISPRS J. Photogramm. Remote Sens. 2014, 87, 122–136. [Google Scholar] [CrossRef] [Green Version]
- Lv, Z.; Shi, W.; Zhang, X.; Benediktsson, J.A. Landslide Inventory Mapping From Bitemporal High-Resolution Remote Sensing Images Using Change Detection and Multiscale Segmentation. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 1520–1532. [Google Scholar] [CrossRef]
- Piralilou, S.T.; Shahabi, H.; Jarihani, B.; Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Aryal, J. Landslide Detection Using Multi-Scale Image Segmentation and Different Machine Learning Models in the Higher Himalayas. Remote Sens. 2019, 11, 2575. [Google Scholar] [CrossRef] [Green Version]
- Knevels, R.; Petschko, H.; Leopold, P.; Brenning, A. Geographic Object-Based Image Analysis for Automated Landslide Detection Using Open Source GIS Software. ISPRS Int. J. Geo-Information 2019, 8, 551. [Google Scholar] [CrossRef] [Green Version]
- Hussain, M.; Chen, D.; Cheng, A.; Wei, H.; Stanley, D. Change detection from remotely sensed images: From pixel-based to object-based approaches. ISPRS J. Photogramm. Remote Sens. 2013, 80, 91–106. [Google Scholar] [CrossRef]
- Drăguţ, L.; Csillik, O.; Eisank, C.; Tiede, D. Automated parameterisation for multi-scale image segmentation on multiple layers. ISPRS J. Photogramm. Remote Sens. 2014, 88, 119–127. [Google Scholar] [CrossRef] [Green Version]
- Ma, L.; Liu, Y.; Zhang, X.; Ye, Y.; Yin, G.; Johnson, B.A. Deep learning in remote sensing applications: A meta-analysis and review. ISPRS J. Photogramm. Remote Sens. 2019, 152, 166–177. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, L.; Yin, K.; Luo, H.; Li, J. Landslide identification using machine learning. Geosci. Front. 2021, 12, 351–364. [Google Scholar] [CrossRef]
- Ghorbanzadeh, O.; Blaschke, T.; Gholamnia, K.; Meena, S.R.; Tiede, D.; Aryal, J. Evaluation of Different Machine Learning Methods and Deep-Learning Convolutional Neural Networks for Landslide Detection. Remote Sens. 2019, 11, 196. [Google Scholar] [CrossRef] [Green Version]
- Lei, T.; Zhang, Y.; Lv, Z.; Li, S.; Liu, S.; Nandi, A.K. Landslide Inventory Mapping From Bitemporal Images Using Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2019, 16, 982–986. [Google Scholar] [CrossRef]
- Lv, Z.; Liu, T.; Kong, X.; Shi, C.; Benediktsson, J.A. Landslide Inventory Mapping with Bitemporal Aerial Remote Sensing Images Based on the Dual-path Full Convolutional Network. IEEE J. Selected Topics Appl. Earth Observ. Remote Sens. 2020, 58, 4575–4584. [Google Scholar] [CrossRef]
- Zhao, W.; Du, S.; Emery, W.J. Object-Based Convolutional Neural Network for High-Resolution Imagery Classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2017, 10, 3386–3396. [Google Scholar] [CrossRef]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; IEEE: IEEE, 2019; pp. 3141–3149. [Google Scholar]
- Pan, B.; Shi, Z.; Xu, X. MugNet: Deep learning for hyperspectral image classification using limited samples. ISPRS J. Photogrammetry Remote Sens. 2018, 145, 108–119. [Google Scholar] [CrossRef]
- Wu, H.; Prasad, S. Semi-Supervised Deep Learning Using Pseudo Labels for Hyperspectral Image Classification. IEEE Trans. Image Process. 2018, 27, 1259–1270. [Google Scholar] [CrossRef]
- Yang, M.; Jiao, L.; Liu, F.; Hou, B.; Yang, S. Transferred Deep Learning-Based Change Detection in Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2019, 57, 6960–6973. [Google Scholar] [CrossRef]
- Zhang, X.; Shi, W.; Lv, Z. Uncertainty Assessment in Multitemporal Land Use/Cover Mapping with Classification System Semantic Heterogeneity. Remote Sens. 2019, 11, 2509. [Google Scholar] [CrossRef] [Green Version]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A.C. Improved training of wasserstein gans. Adv. Neur. Inf. Proc. Syst. 2017, 30, 5767–5777. [Google Scholar]
- Drăgut, L.; Tiede, D.; Levick, S.R. ESP: A tool to estimate scale parameter for multiresolution image segmentation of remotely sensed data. Int. J. Geogr. Inf. Sci. 2010, 24, 859–871. [Google Scholar] [CrossRef]
- Lei, T.; Jia, X.; Zhang, Y.; Liu, S.; Meng, H.; Nandi, A.K. Superpixel-Based Fast Fuzzy C-Means Clustering for Color Image Segmentation. IEEE Trans. Fuzzy Syst. 2018, 27, 1753–1766. [Google Scholar] [CrossRef] [Green Version]
- Wang, Q.; Shi, W. Unsupervised classification based on fuzzy c-means with uncertainty analysis. Remote Sens. Lett. 2013, 4, 1087–1096. [Google Scholar] [CrossRef]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Proc. Adv. Neural. Inf. Process. Syst. 2014, 2, 2672–2680. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. In Proceedings of the 4th International Conference on Learning Representations, ICLR 2016—Conference Track Proceedings, San Juan, PR, USA, 2–4 May 2016. [Google Scholar]
- Zhang, M.; Gong, M.; Mao, Y.; Li, J.; Wu, Y. Unsupervised Feature Extraction in Hyperspectral Images Based on Wasserstein Generative Adversarial Network. IEEE Trans. Geosci. Remote Sens. 2019, 57, 2669–2688. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International conference on machine learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]
- Chen, J.; Yuan, Z.; Peng, J.; Chen, L.; Huang, H.; Zhu, J.; Liu, Y.; Li, H. DASNet: Dual Attentive Fully Convolutional Siamese Networks for Change Detection in High-Resolution Satellite Images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2021, 14, 1194–1206. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Lecture Notes in Computer Science; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2018; pp. 7132–7141. [Google Scholar]
- Ormsby, T.; Napoleon, E.; Burke, R.; Groessl, C.; Bowden, L. Getting to Know ArcGIS Desktop; Esri Press: Redlands, CA, USA, 2010. [Google Scholar]
- Gong, M.; Zhan, T.; Zhang, P.; Miao, Q. Superpixel-Based Difference Representation Learning for Change Detection in Multispectral Remote Sensing Images. IEEE Trans. Geosci. Remote Sens. 2017, 55, 2658–2673. [Google Scholar] [CrossRef]
- Jiang, F.; Gong, M.; Zhan, T.; Fan, X. A Semisupervised GAN-Based Multiple Change Detection Framework in Multi-Spectral Images. IEEE Geosci. Remote Sens. Lett. 2020, 17, 1223–1227. [Google Scholar] [CrossRef]















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | The Center Coordinate | Resolution (m) | Size (Pixels) | Acquisition Time | Land Cover Types |
|---|---|---|---|---|---|
| A | 22° 14′ 52′′ N, 113°53′ 52′′ E | 0.5 | 960 × 960 | December 2007 and November 2014 | forests |
| B | 22° 16′ 14′′ N, 113°53′ 24′′ E | 0.5 | 740 × 780 | December 2007 and November 2014 | shrublands and volcanic rocks |
| C | 22° 14′ 28′′ N, 113°51′ 14′′ E | 0.5 | 700 × 700 | December 2005 and November 2008 | dense grasslands and sparse woodlands |
| D | 22° 16′ 06′′ N, 113°54′ 05′′ E | 0.5 | 600 × 600 | December 2005 and November 2008 | sparse shrublands and grasslands with some rocks |
| Dataset | Method | CP | CR | QA | KC | OA |
|---|---|---|---|---|---|---|
| A | CDMRF | 0.48 | 0.78 | 0.42 | 0.57 | 95.03% |
| OMV | 0.89 | 0.69 | 0.64 | 0.76 | 96.15% | |
| SDRL | 0.70 | 0.83 | 0.61 | 0.74 | 96.63% | |
| SGAN | 0.64 | 0.82 | 0.56 | 0.70 | 96.19% | |
| SMDRF-Net | 0.91 | 0.83 | 0.76 | 0.85 | 97.54% | |
| B | CDMRF | 0.74 | 0.84 | 0.65 | 0.79 | 99.17% |
| OMV | 0.92 | 0.70 | 0.66 | 0.79 | 99.02% | |
| SDRL | 0.71 | 0.93 | 0.67 | 0.80 | 99.27% | |
| SGAN | 0.71 | 0.91 | 0.66 | 0.79 | 99.23% | |
| SMDRF-Net | 0.90 | 0.92 | 0.83 | 0.90 | 99.59% | |
| C | CDMRF | 0.60 | 0.85 | 0.55 | 0.69 | 97.54% |
| OMV | 0.94 | 0.71 | 0.68 | 0.80 | 97.79% | |
| SDRL | 0.80 | 0.83 | 0.69 | 0.81 | 98.22% | |
| SGAN | 0.60 | 0.88 | 0.56 | 0.70 | 97.57% | |
| SMDRF-Net | 0.85 | 0.91 | 0.78 | 0.87 | 98.83% | |
| D | CDMRF | 0.81 | 0.83 | 0.70 | 0.81 | 98.29% |
| OMV | 0.94 | 0.70 | 0.67 | 0.79 | 97.76% | |
| SDRL | 0.93 | 0.75 | 0.71 | 0.82 | 98.20% | |
| SGAN | 0.73 | 0.91 | 0.68 | 0.80 | 98.32% | |
| SMDRF-Net | 0.92 | 0.85 | 0.80 | 0.86 | 98.84% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, X.; Pun, M.-O.; Liu, M. Semi-Supervised Multi-Temporal Deep Representation Fusion Network for Landslide Mapping from Aerial Orthophotos. Remote Sens. 2021, 13, 548. https://doi.org/10.3390/rs13040548
Zhang X, Pun M-O, Liu M. Semi-Supervised Multi-Temporal Deep Representation Fusion Network for Landslide Mapping from Aerial Orthophotos. Remote Sensing. 2021; 13(4):548. https://doi.org/10.3390/rs13040548
Chicago/Turabian StyleZhang, Xiaokang, Man-On Pun, and Ming Liu. 2021. "Semi-Supervised Multi-Temporal Deep Representation Fusion Network for Landslide Mapping from Aerial Orthophotos" Remote Sensing 13, no. 4: 548. https://doi.org/10.3390/rs13040548
APA StyleZhang, X., Pun, M. -O., & Liu, M. (2021). Semi-Supervised Multi-Temporal Deep Representation Fusion Network for Landslide Mapping from Aerial Orthophotos. Remote Sensing, 13(4), 548. https://doi.org/10.3390/rs13040548