
Fusion of Airborne LiDAR Point Clouds and Aerial Images for Heterogeneous Land-Use Urban Mapping


Abstract
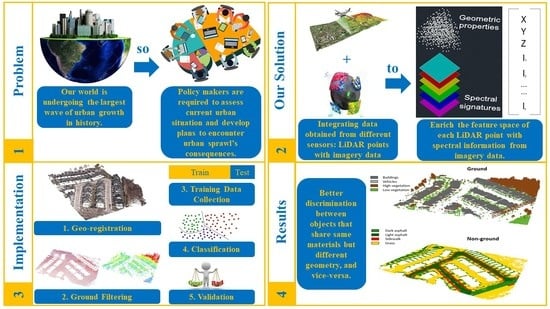
:
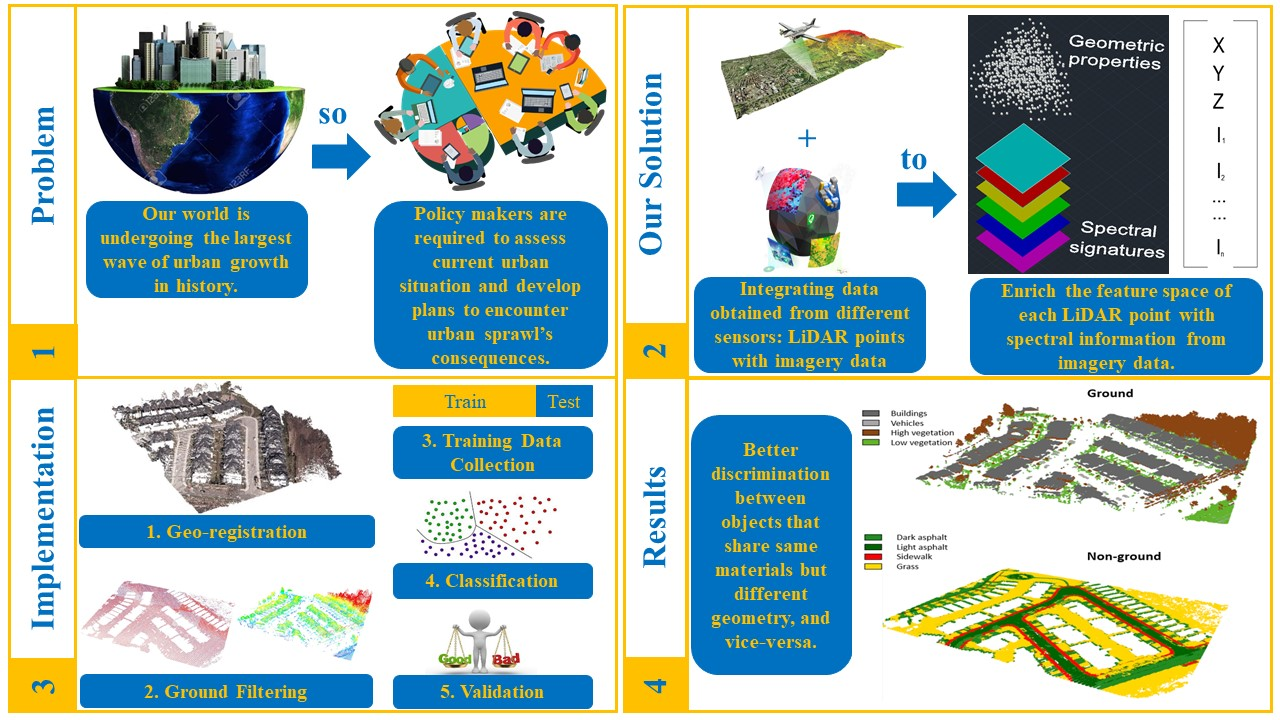{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
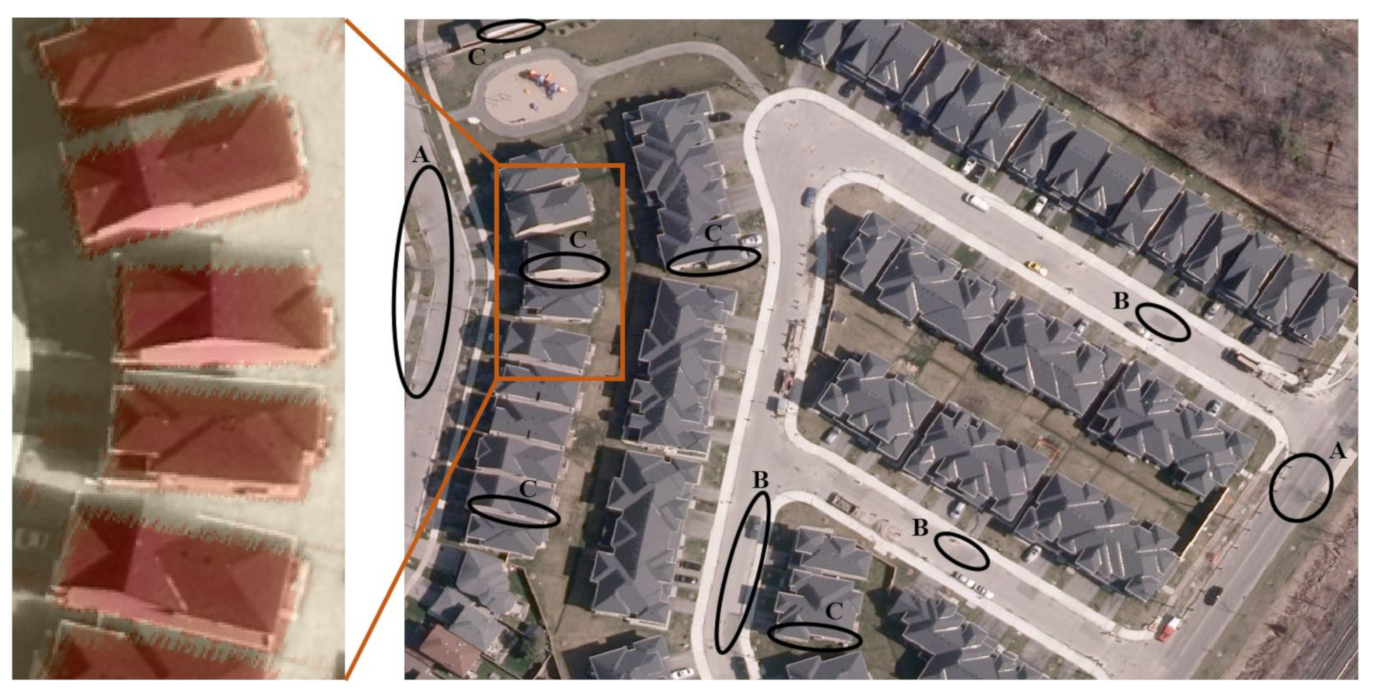{kind=link}
1. Introduction
- Regression algorithms model the relationship between variables and refine it iteratively by adjusting prediction errors (i.e., linear and logistic regression).
- Instance-based algorithms use observations to construct a database, to which new data are compared to find the best match for prediction using a similarity measure (i.e., KNN (K-Nearest Neighbors) and SVM (Support Vector Machine)).
- Regularization algorithms extend regression methods to prioritize simple models over complex ones for better generalization (i.e., ridge and least-angle regression).
- Decision tree algorithms build a model of decisions based on the observations’ attribute values. These decisions branch until a prediction is made for a certain record (i.e., decision tump and conditional decision trees).
- Bayesian algorithms apply Bayes’ Theorem (i.e., naive Bayes and Gaussian naive Bayes).
- Clustering algorithms use built-in data structures to produce groups of maximum commonality (i.e., k-means and k-medians).
- Association rule learning algorithms derive formulas that best explain the relationships between the variables of observations. These rules are generic enough to be applied to large multidimensional datasets (i.e., apriori and eclat).
- Artificial neural network algorithms are pattern-matching-based methods inspired by biological neural networks (i.e., perceptron and MLP (Multilayer Perceptron Neural Network)).
- Deep learning algorithms are higher levels of artificial neural networks (i.e., convolutional and recurrent neural networks).
- Dimensionality reduction algorithms reduce data dimensionality in an unsupervised approach for better space visualization. Abstracted dimensions can be input into a subsequent supervised algorithm (i.e., PCA (Principal Component Analysis) and PCR (Principal Component Regression)).
- Ensemble algorithms are strong learners consisting of multiple weaker learners that are independently trained in parallel and vote toward the final prediction of a record (i.e., Bagging, AdaBoost, and RF (Random Forest)).
2. Methods
2.1. LiDAR-Image Geo-Registration
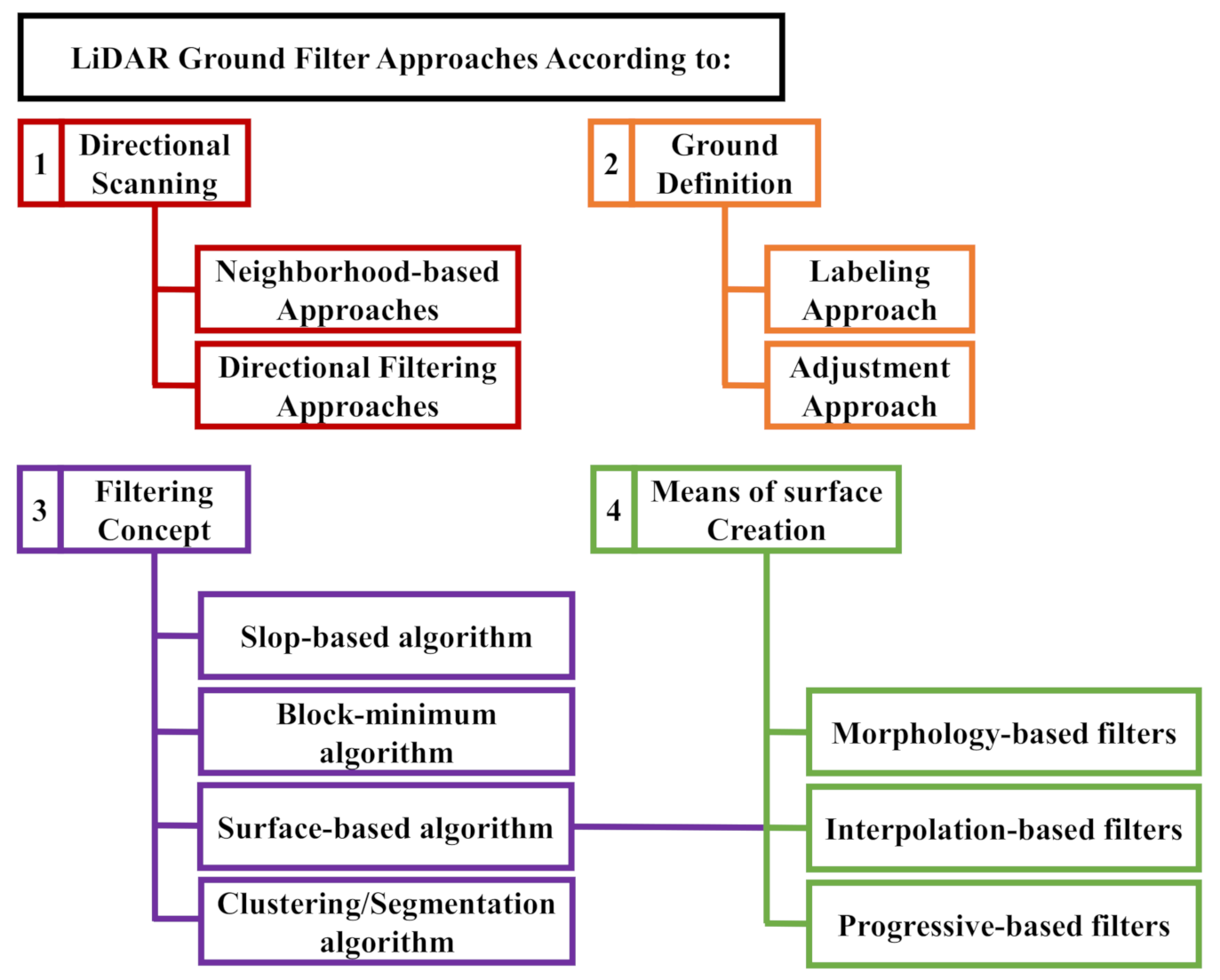
2.2. LiDAR Ground Filtering
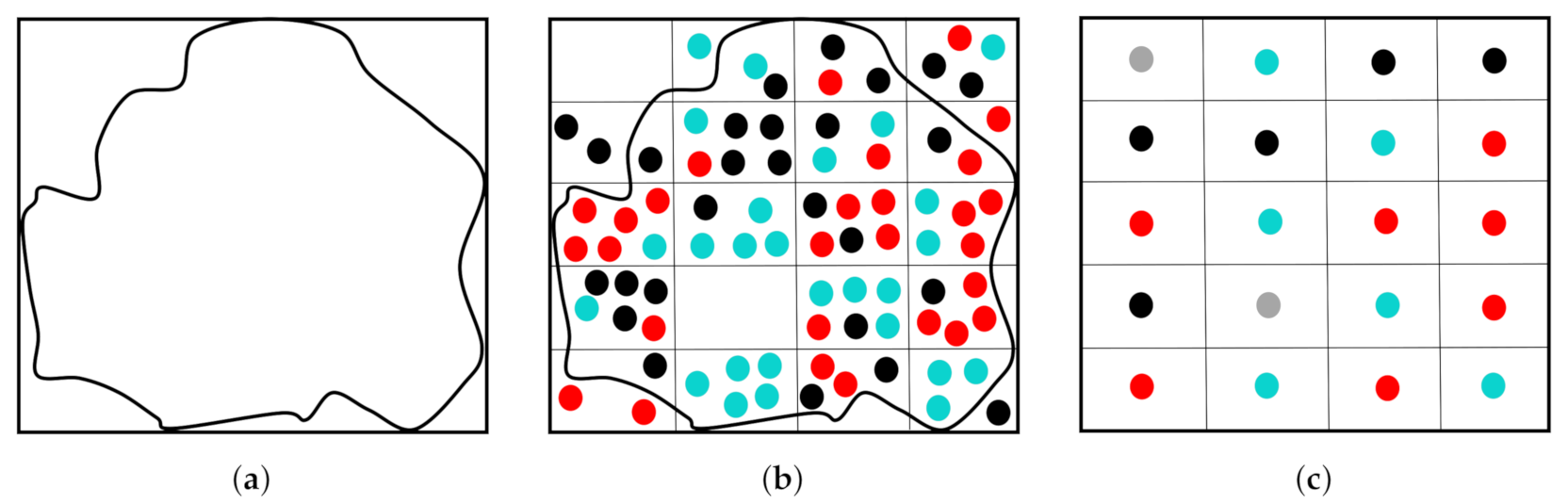
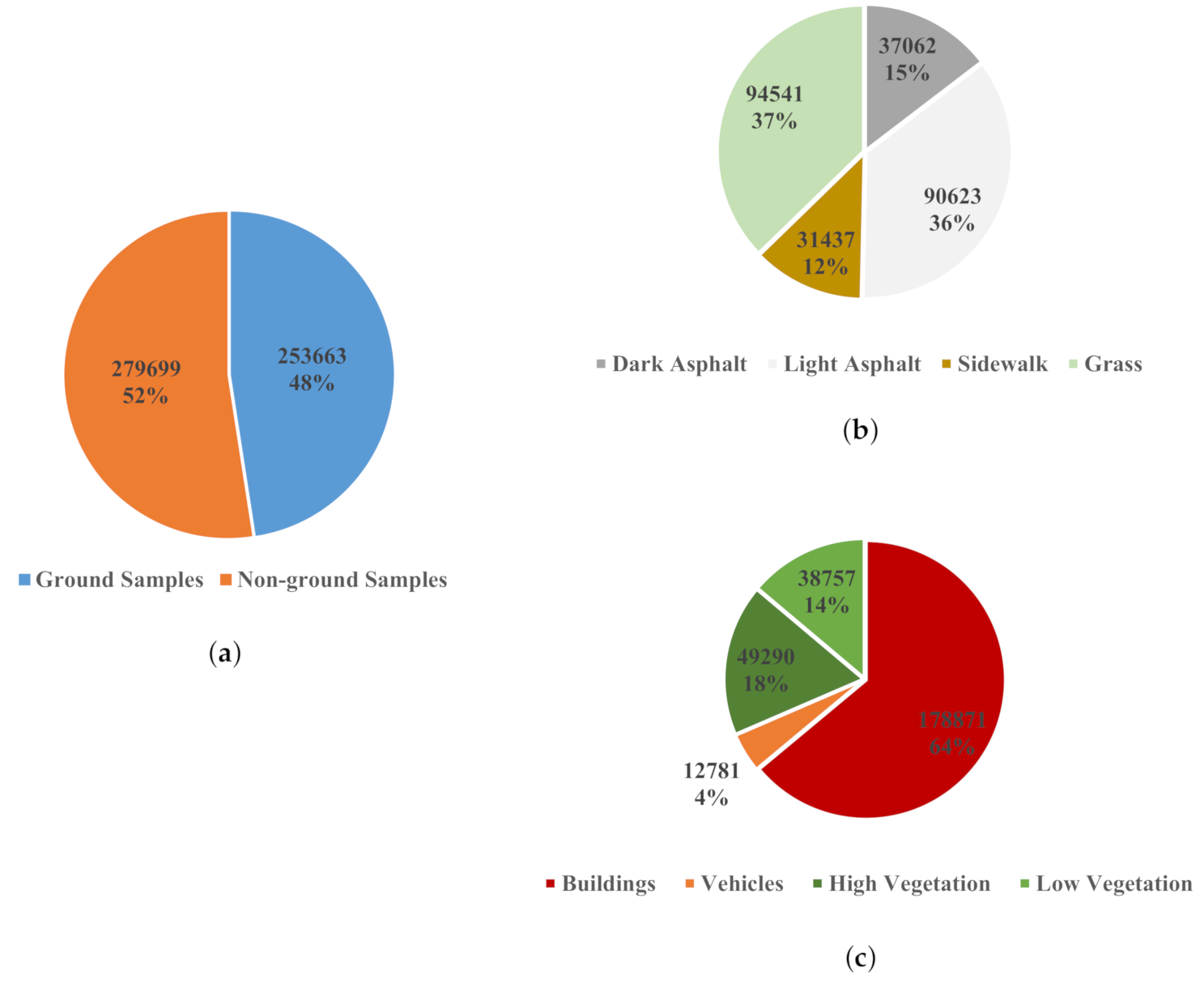
2.3. Training Data Collection
2.4. Supervised Machine Learning Point-Based Classification
2.4.1. Maximum Likelihood (ML) Classifier
2.4.2. Support Vector Machine (SVM) Classifier
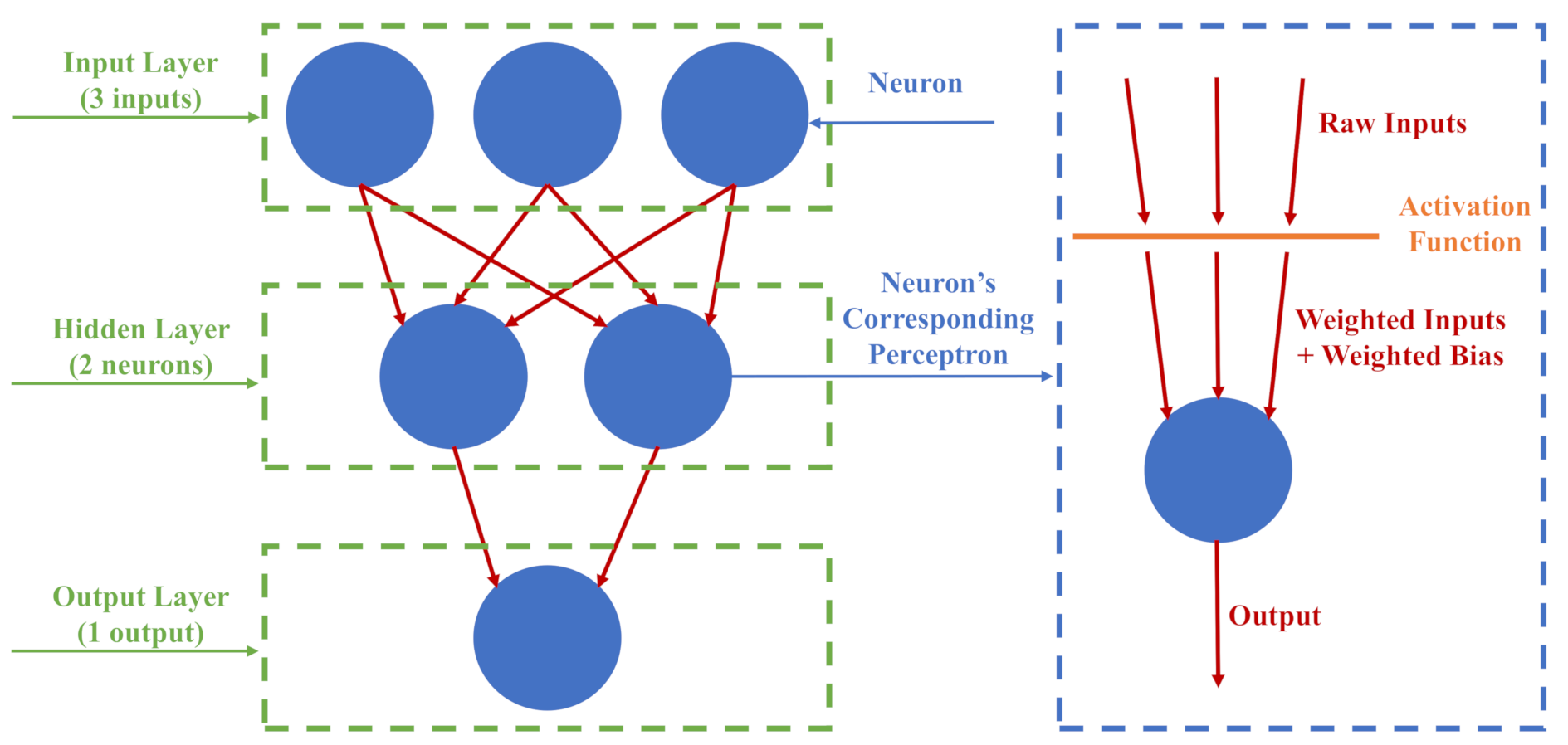
2.4.3. Multilayer Perceptron (MLP) Artificial Neural Network Classifier
2.4.4. Bootstrap Aggregation (Bagging) Classifier
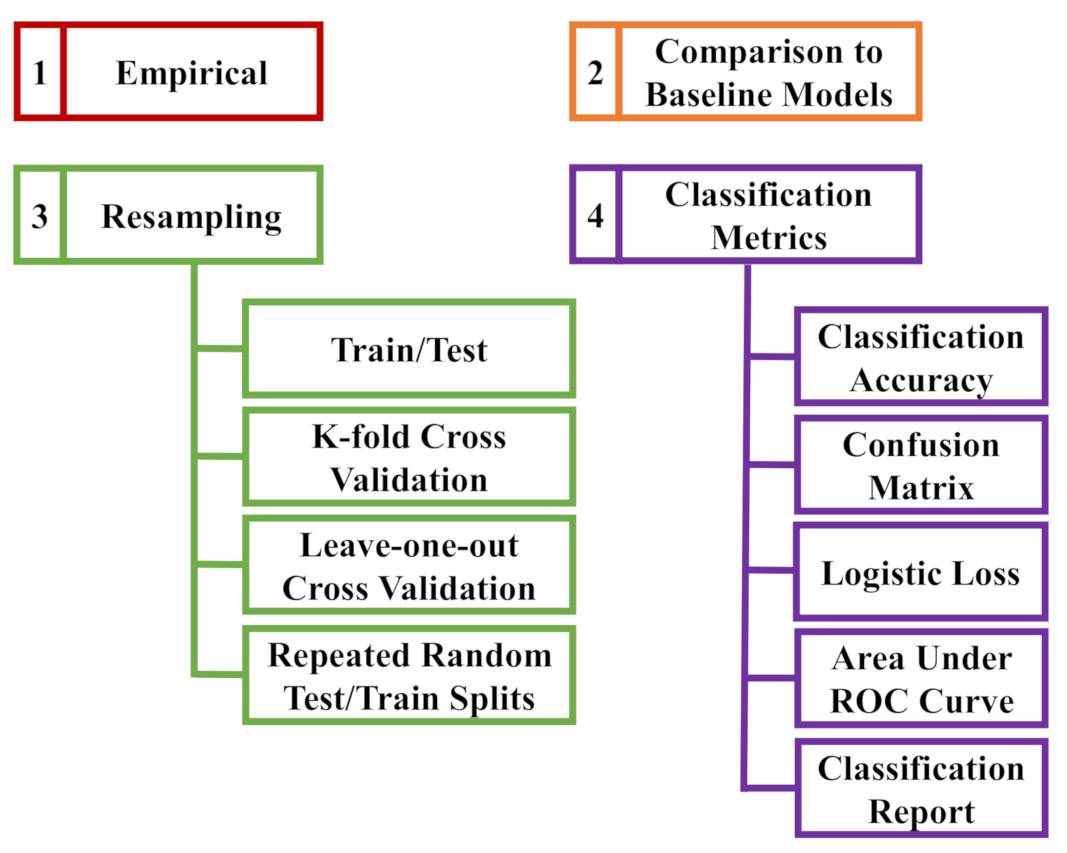
2.5. Model Validation
3. Experimental Work
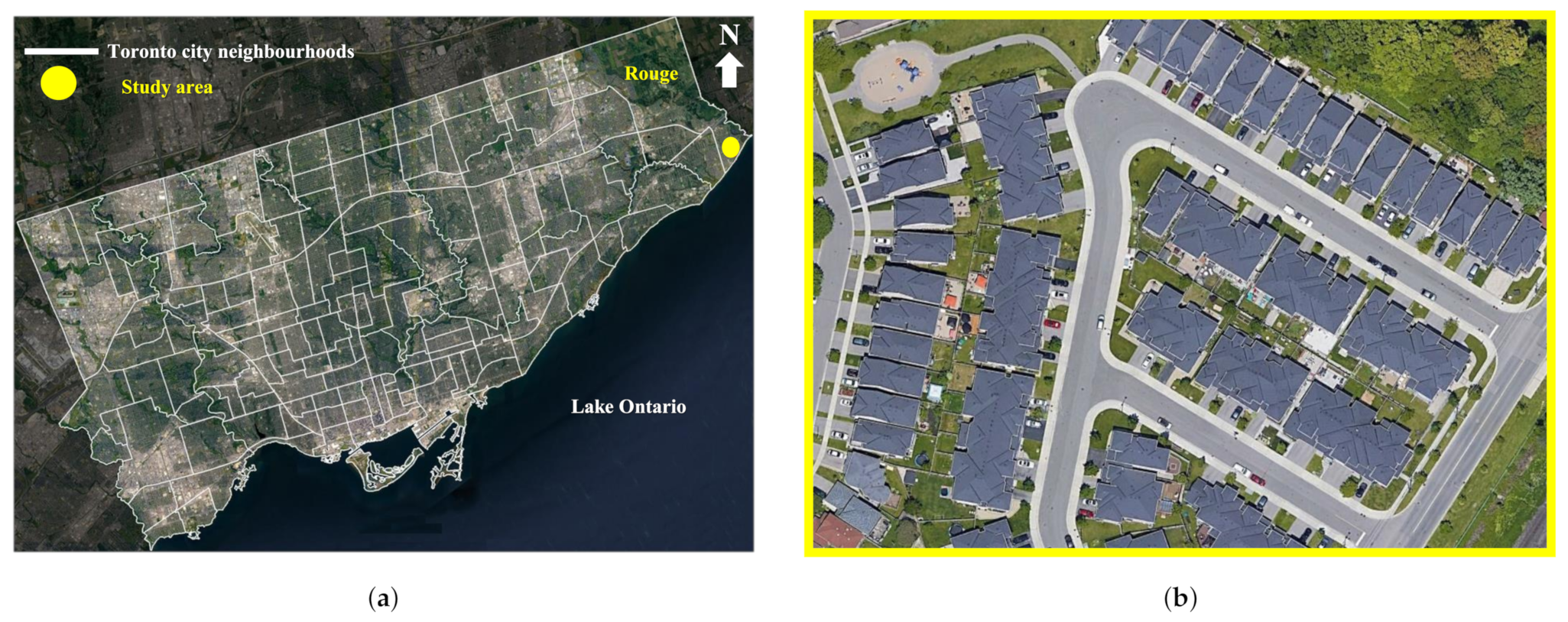
3.1. Study Area and Datasets
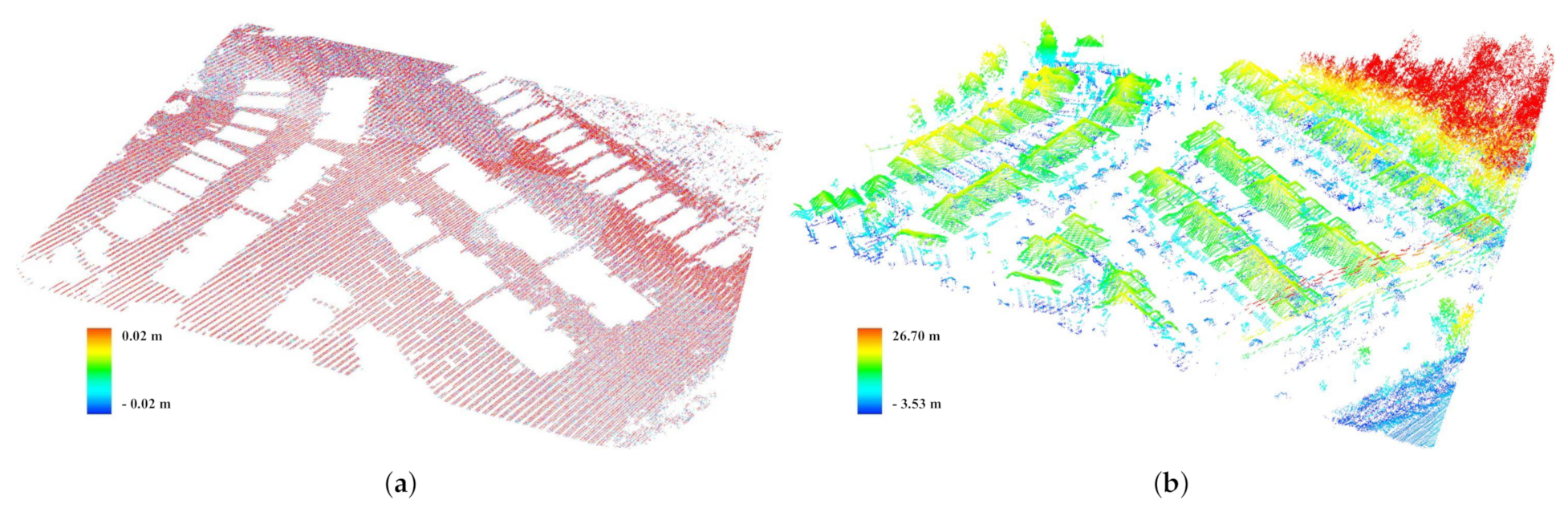
3.2. Data Geo-Registration
3.3. Ground Filtering
3.4. Training Samples Acquisition
3.5. Point-Based Classification
- 1.
- H, I.
- 2.
- H, I, RGB.
- 3.
- H, I, RGB, NIR.
- 4.
- H, I, RGB, NIR, NDVI.
3.5.1. ML and SVM Classifications
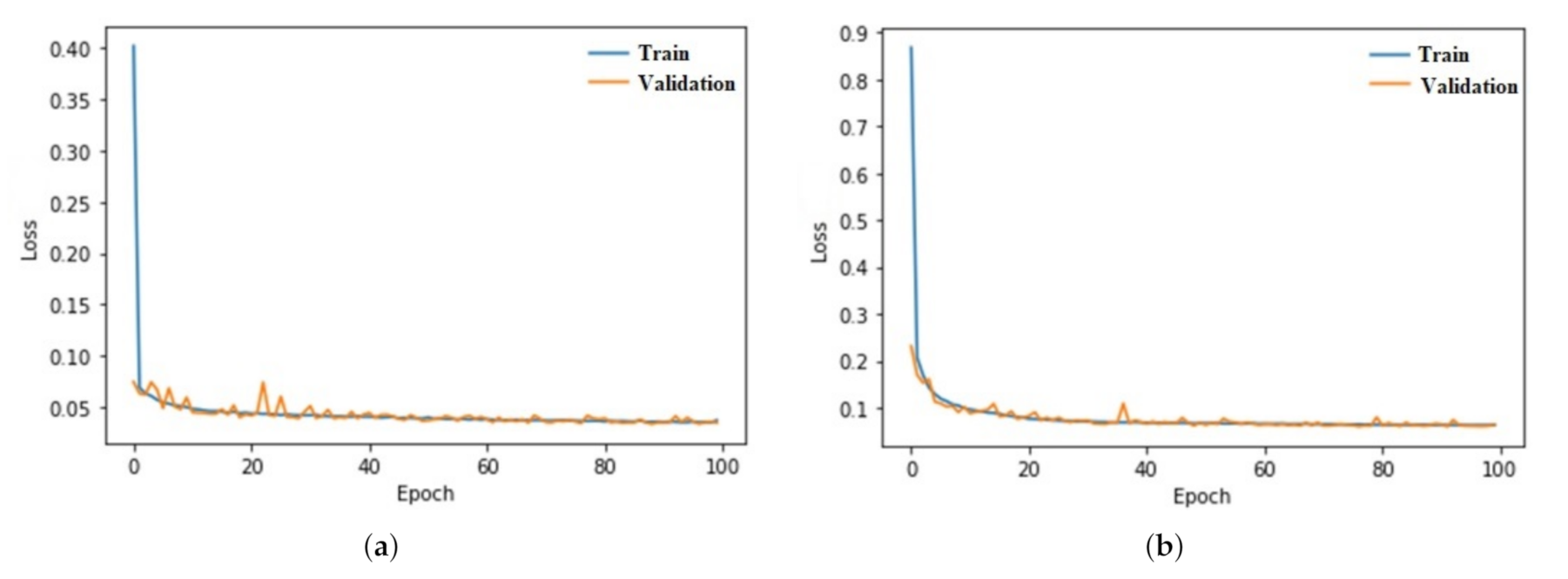
3.5.2. MLP Neural Network Classification
3.5.3. Bagging Classification
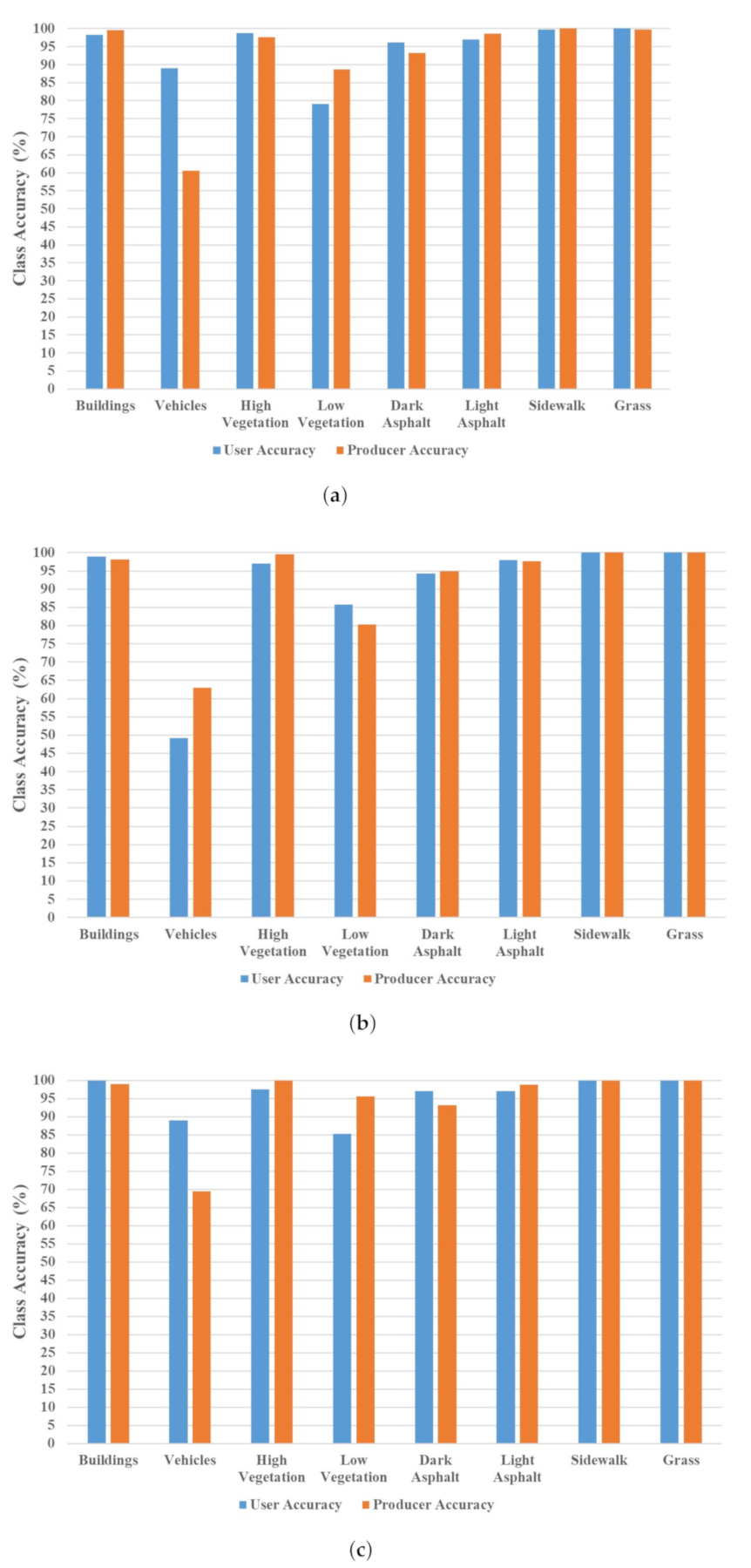
3.5.4. Accuracy Assessment
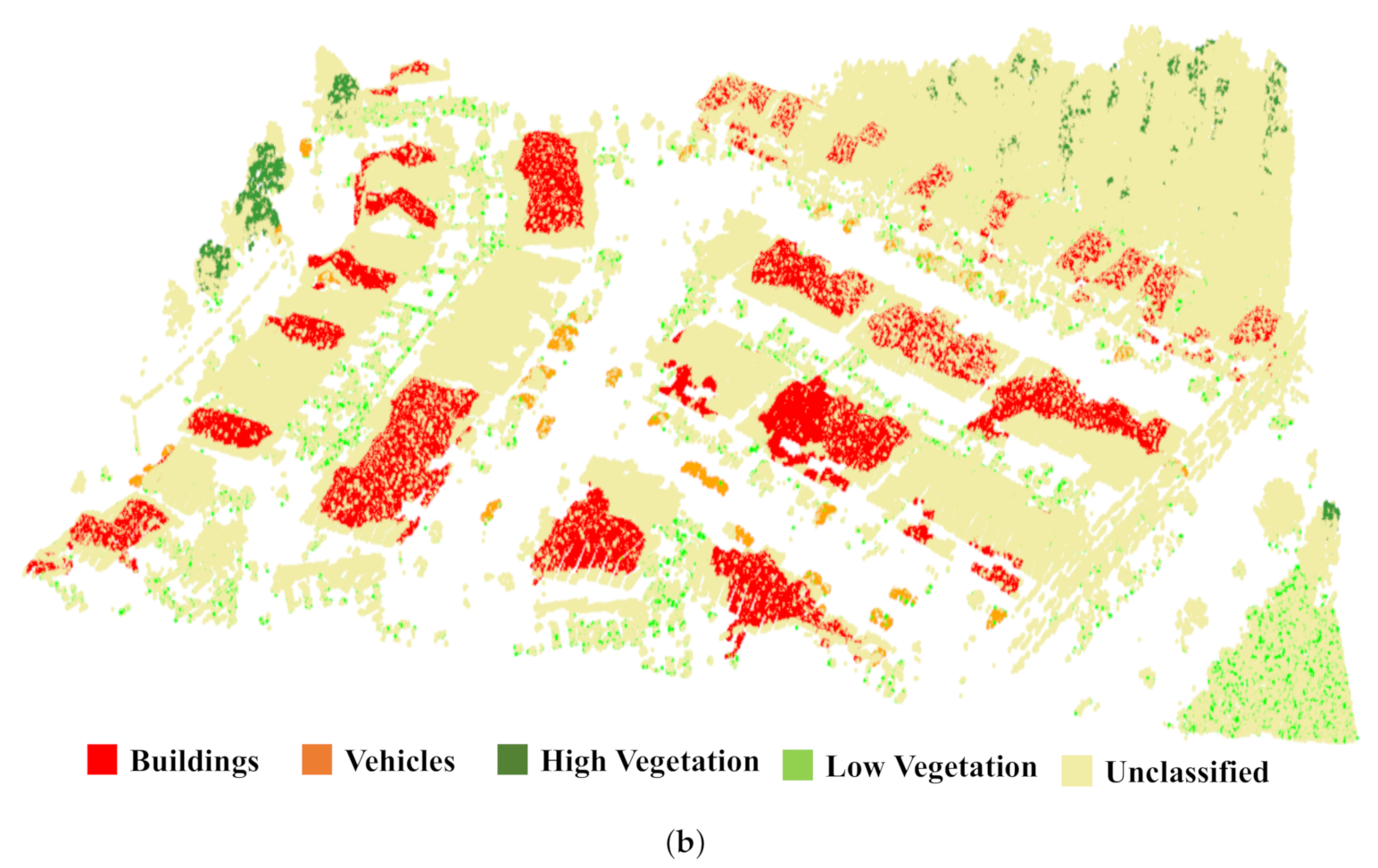
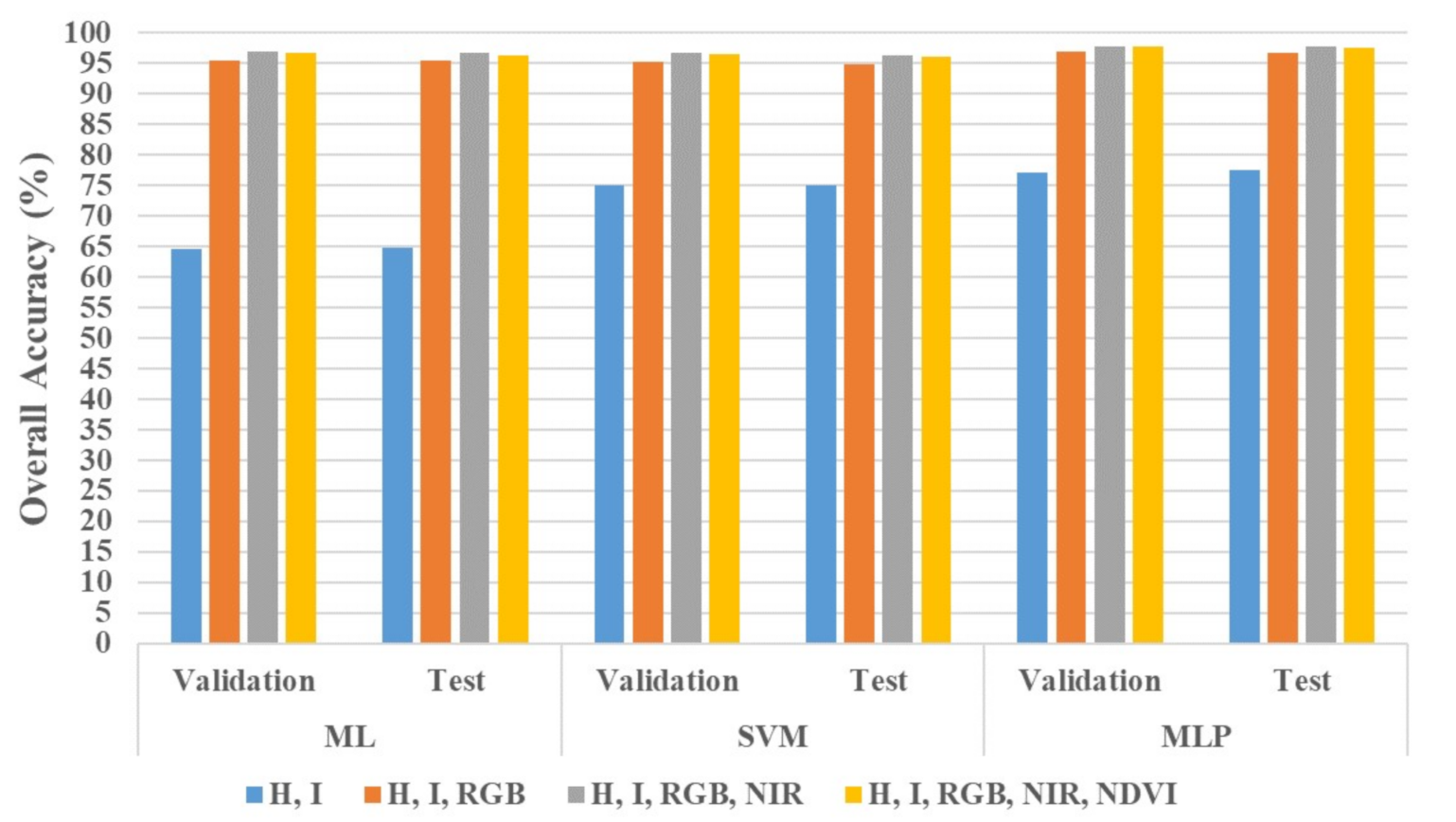
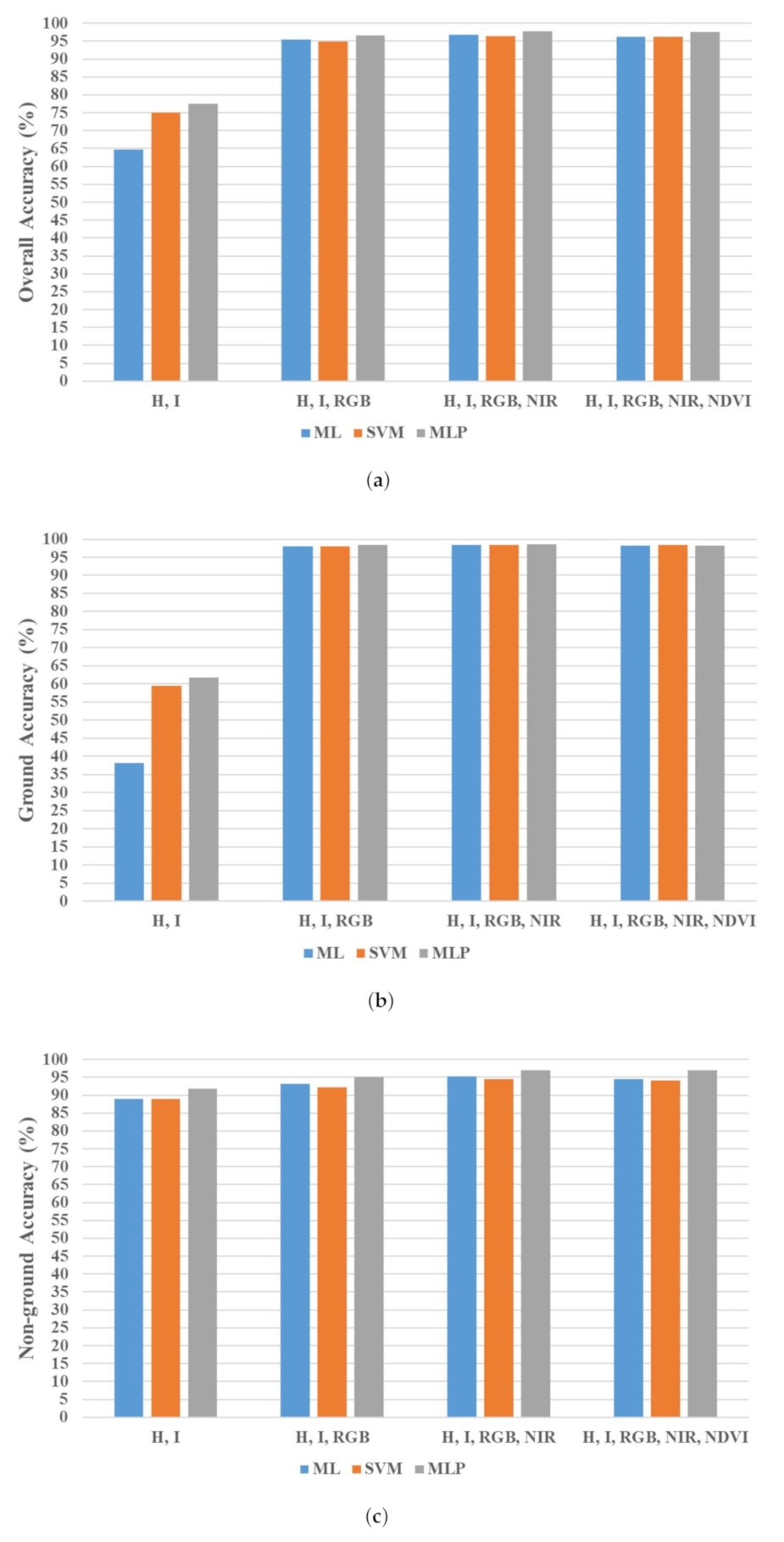
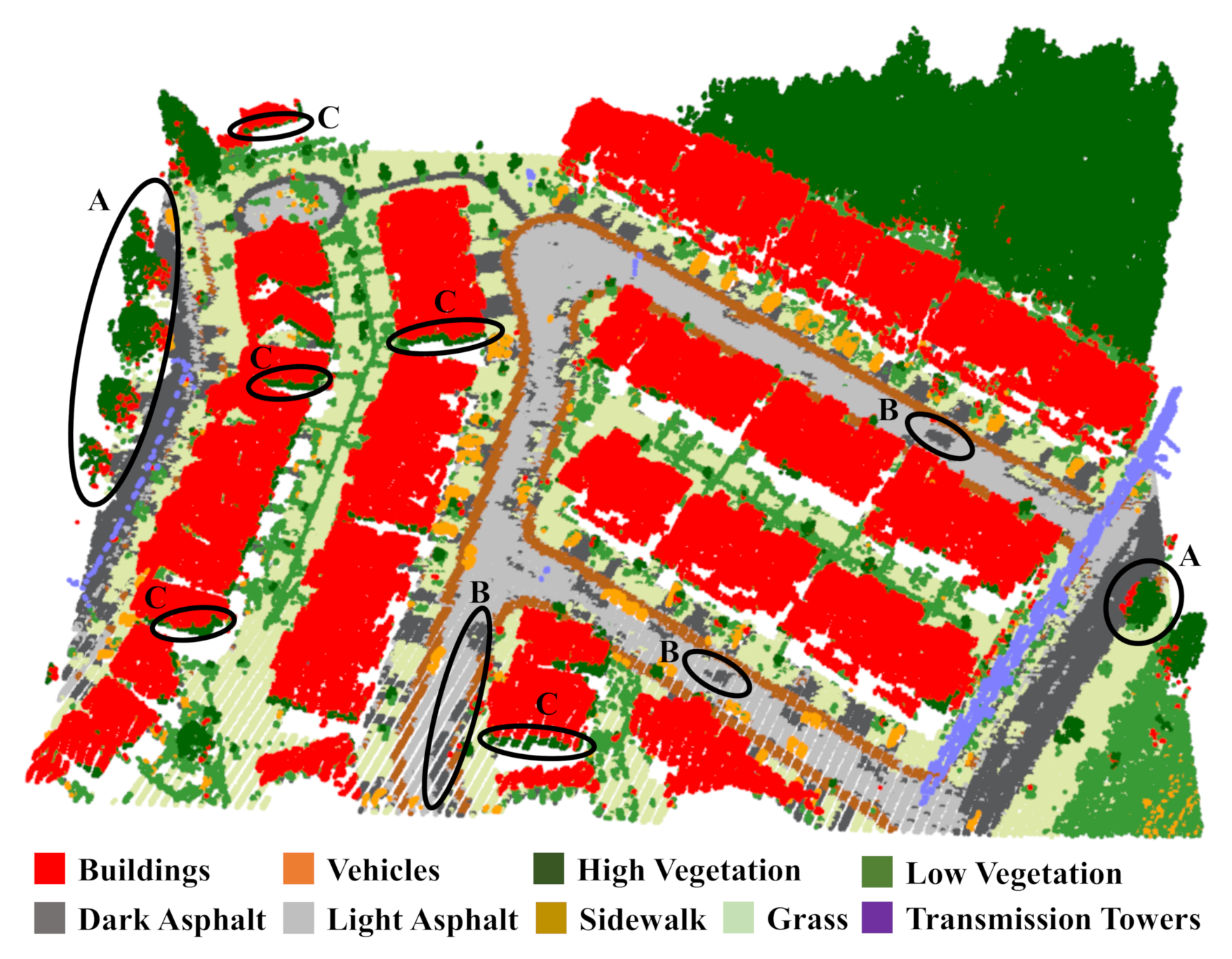
4. Results
5. Discussion
- Referring to the geo-registration of both data types by the PC model and scene abstraction algorithm that locate control points, which are not limited to points on traditional linear elements and intersections. The approach does not require data to be georeferenced, applies empirical registration models without knowing the physical model characteristics, and overcomes the problem of airborne LiDAR data not coming with onboard optical images collected during the same flight mission. Full details about the geo-registration approach are found in [46].
- Suggesting the inclusion of the CED to the PC filter for a more concise detection of geo-registration primitives. This study highlights the importance of a thorough qualitative inspection of the abovementioned geo-registration method’s results, as empirical models might cause overparameterization that cannot be quantitatively revealed.
- Introducing a new data fusion approach to LiDAR point cloud classification that constructs radiometric-based feature spaces from spectral characteristics inherited from aerial images. With affordable sensors and computationally inexpensive feature spaces that include only I and H from LiDAR data and RGB, NIR, and NDVI from aerial photos, we achieved a mapping accuracy over 95% with a conventional classifier as ML and over 97% with MLP.
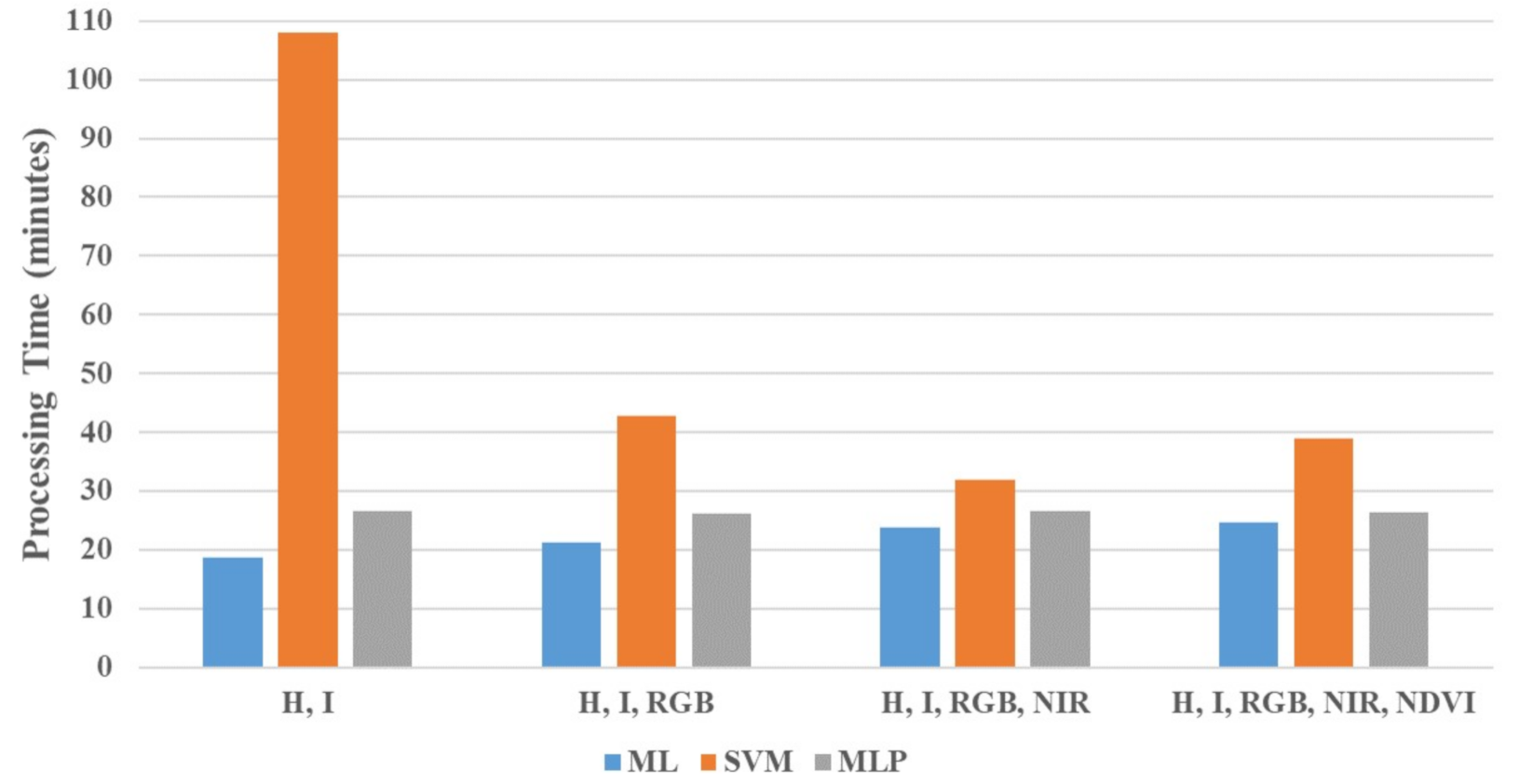
- Investigating different combinations of the features as mentioned above with various commonly known classifiers: ML, SVM, and MLP in regards to the logic behind each classifier, overall and per-class accuracies, and processing time. This comparison helped exclude SVM and derived features (i.e., NDVI) from enhancing the mapping accuracies.
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CED | Canny Edge Detector |
| CRF | Conditional Random Field |
| DIM | Dense Image Matching |
| GBT | Gradient Boosted Trees |
| GNB | Gaussian Naive Bayes |
| H | Height |
| HMP | Hierarchical Morophological Profile |
| HSV | Hue Saturation Value |
| I | Intensity |
| IDE | Integrated Development Environment |
| IDW | Inverse Distance Weighted |
| IMMW | Iterative Majority Moving Window |
| KNN | K-Nearest Neighbors |
| LiDAR | Light Detection and Ranging |
| LULC | Land Use Land Cover |
| MIR | Mid Infrared |
| ML | Maximum Likelihood |
| MLP | Multilayer Perceptron Neural Network |
| MP | Morophological Profile |
| NAD | North American Datum |
| NDSM | Normalized Digital Surface Model |
| NDVI | Normalized Difference Vegetation Index |
| NIR | Near Infrared |
| NN | Nearest Neighbor |
| PC | Phase Congruency |
| PCA | Principal Component Analysis |
| PCR | Principal Component Regression |
| ReLU | Rectified Linear Unit |
| RF | Random Forest |
| RGB | Red Green Blue |
| ROC | Receiver Operating Characteristics |
| SVM | Support Vector Machine |
| TIN | Triangulated Inverse Network |
| UAS | Unmanned Aircraft System |
| UAV | Unmanned Aerial Vehicle |
| UTM | Universal Transverse Mercator |
References
- World Health Organization. Hidden cities: Unmasking and overcoming health inequities in urban settings. In Centre for Health Development and World Health Organization; World Health Organization: Geneva, Switzerland, 2010. [Google Scholar]
- Güneralp, B.; Reba, M.; Hales, B.U.; Wentz, E.A.; Seto, K.C. Trends in urban land expansion, density, and land transitions from 1970 to 2010: A global synthesis. Environ. Res. Lett. 2020, 15, 044015. [Google Scholar] [CrossRef]
- Oliinyk, O.; Serhiienko, L.; Legan, I. Public administration of economic and ecological urbanization consequences. Fundam. Appl. Res. Pract. Lead. Sci. Sch. 2020, 37, 27–33. [Google Scholar]
- Long, T.; Jiao, W.; He, G.; Zhang, Z.; Cheng, B.; Wang, W. A generic framework for image rectification using multiple types of feature. ISPRS J. Photogramm. Remote. Sens. 2015, 102, 161–171. [Google Scholar] [CrossRef]
- Lefsky, M.A.; Cohen, W.B.; Parker, G.G.; Harding, D.J. Lidar remote sensing for ecosystem studies: Lidar, an emerging remote sensing technology that directly measures the three-dimensional distribution of plant canopies, can accurately estimate vegetation structural attributes and should be of particular interest to forest, landscape, and global ecologists. BioScience 2002, 52, 19–30. [Google Scholar]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Fusion of hyperspectral and LIDAR remote sensing data for classification of complex forest areas. IEEE Trans. Geosci. Remote. Sens. 2008, 46, 1416–1427. [Google Scholar] [CrossRef] [Green Version]
- Jaboyedoff, M.; Oppikofer, T.; Abellán, A.; Derron, M.H.; Loye, A.; Metzger, R.; Pedrazzini, A. Use of LIDAR in landslide investigations: A review. Nat. Hazards 2012, 61, 5–28. [Google Scholar] [CrossRef] [Green Version]
- Radiohead-House of Cards. Light Detection and Ranging (LiDAR). [University Lecture]; Portland State University: Portland, OR, USA, 2017. [Google Scholar]
- NOAA. What Is LIDAR? National Ocean Service Website. Available online: http://oceanservice.noaa.gov/facts/lidar.html (accessed on 8 March 2020).
- Wu, H.; Li, Y.; Li, J.; Gong, J. A two-step displacement correction algorithm for registration of lidar point clouds and aerial images without orientation parameters. Photogramm. Eng. Remote. Sens. 2010, 76, 1135–1145. [Google Scholar] [CrossRef]
- Dalponte, M.; Bruzzone, L.; Gianelle, D. Tree species classification in the Southern Alps based on the fusion of very high geometrical resolution multispectral/hyperspectral images and LiDAR data. Remote. Sens. Environ. 2012, 76, 123–258. [Google Scholar] [CrossRef]
- Tonolli, S.; Dalponte, M.; Neteler, M.; Rodeghiero, M.; Vescovo, L.; Gianelle, D. Fusion of airborne LiDAR and satellite multispectral data for the estimation of timber volume in the Southern Alps. Remote. Sens. Environ. 2011, 115, 2486–2498. [Google Scholar] [CrossRef]
- Christiansen, M.P.; Laursen, M.S.; Jørgensen, R.N.; Skovsen, S.; Gislum, R. Designing and testing a UAV mapping system for agricultural field surveying. Sensors 2017, 17, 2703. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Qin, X.; Wu, G.; Lei, J.; Fan, F.; Ye, X.; Mei, Q. A novel method of autonomous inspection for transmission line based on cable inspection robot lidar data. Sensors 2018, 18, 596. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kumar, G.A.; Patil, A.K.; Chai, Y.H. Alignment of 3D point cloud, CAD model, real-time camera view and partial point cloud for pipeline retrofitting application. In Proceedings of the 2018 International Conference on Electronics, Information, and Communication (ICEIC), Honolulu, HI, USA, 24–27 January 2018; pp. 1–4. [Google Scholar]
- Bonatti, R.; Wang, W.; Ho, C.; Ahuja, A.; Gschwindt, M.; Camci, E.; Kayacan, E.; Choudhury, S.; Scherer, S. Autonomous aerial cinematography in unstructured environments with learned artistic decision-making. J. Field Robot. 2018, 37, 606–641. [Google Scholar] [CrossRef] [Green Version]
- Völz, B.; Behrendt, K.; Mielenz, H.; Gilitschenski, I.; Siegwart, R.; Nieto, J. A data-driven approach for pedestrian intention estimation. In Proceedings of the 2016 IEEE 19th International Conference on Intelligent Transportation Systems (ITSC), Rio de Janeiro, Brazil, 1–4 November 2016; pp. 2607–2612. [Google Scholar]
- Bhatta, B. Analysis of Urban Growth and Sprawl from Remote Sensing Data; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Lu, D.; Weng, Q. A survey of image classification methods and techniques for improving classification performance. Int. J. Remote Sens. 2007, 28, 823–870. [Google Scholar] [CrossRef]
- Van Genderen, J.L. Advances in environmental remote sensing: Sensors, algorithms, and applications. Int. J. Digit. Earth 2011, 4, 446–447. [Google Scholar] [CrossRef]
- Expert System. What Is Machine Learning? A Definition. Expert System Website. Available online: https://expertsystem.com/machine-learning-definition (accessed on 6 May 2020).
- Schowengerdt, R.A. Remote Sensing, Models, and Methods for Image Processing, 3rd ed.; Academic Press: Cambridge, MA, USA, 2007. [Google Scholar]
- El-Ashmawy, N.T.H. Innovative Approach for Automatic Land Cover Information Extraction from LiDAR Data. Ph.D. Dissertation, Ryerson University, Toronto, ON, Canada, 2015. [Google Scholar]
- Cortijo, F.; de la Blanca, N.P. Image classification using non-parametric classifiers and contextual information. Int. Arch. Photogramm. Remote Sens. 1996, 31, 120–124. [Google Scholar]
- Brownlee, J. A Tour of Machine Learning Algorithms. Machine Learning Mastery Website. Available online: https://machinelearningmastery.com/a-tour-of-machine-learning-algorithms (accessed on 14 August 2020).
- Alba, G.E.R.M.A.N. Remote sensing classification algoritms analysis applied to land cover change. Mario Gulich Inst. Argent. 2014.
- Atkinson, P.M. Sub-pixel target mapping from soft-classified, remotely sensed imagery. Photogramm. Eng. Remote. Sens. 2005, 71, 839–846. [Google Scholar] [CrossRef] [Green Version]
- Myint, S.W.; Gober, P.; Brazel, A.; Grossman-Clarke, S.; Weng, Q. Per-pixel vs. object-based classification of urban land cover extraction using high spatial resolution imagery. Remote Sens. Environ. 2011, 115, 1145–1161. [Google Scholar] [CrossRef]
- Yan, W.Y.; Shaker, A.; El-Ashmawy, N. Urban land cover classification using airborne LiDAR data: A review. Remote Sens. Environ. 2015, 158, 295–310. [Google Scholar] [CrossRef]
- Bater, C.W.; Coops, N.C. Evaluating error associated with lidar-derived DEM interpolation. Comput. Geosci. 2009, 35, 289–300. [Google Scholar] [CrossRef]
- Liu, X. Airborne LiDAR for DEM generation: Some critical issues. Prog. Phys. Geogr. 2008, 32, 31–49. [Google Scholar]
- Guo, Q.; Li, W.; Yu, H.; Alvarez, O. Effects of topographic variability and lidar sampling density on several DEM interpolation methods. Photogramm. Eng. Remote Sens. 2010, 76, 701–712. [Google Scholar] [CrossRef] [Green Version]
- Jochem, A.; Höfle, B.; Rutzinger, M.; Pfeifer, N. Automatic roof plane detection and analysis in airborne lidar point clouds for solar potential assessment. Sensors 2009, 9, 5241–5262. [Google Scholar] [CrossRef]
- El-Ashmawy, N.; Shaker, A. Raster vs. point cloud LiDAR data classification. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 40, 79. [Google Scholar] [CrossRef] [Green Version]
- Lodha, S.K.; Fitzpatrick, D.M.; Helmbold, D.P. Aerial lidar data classification using adaboost. In Proceedings of the Sixth International Conference on 3-D Digital Imaging and Modeling-IEEE, Montreal, QC, Canada, 21–23 August 2007; pp. 435–442. [Google Scholar]
- Gao, Y.; Li, M.C. Airborne lidar point cloud classification based on multilevel point cluster features. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 42, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Wang, C.; Shu, Q.; Wang, X.; Guo, B.; Liu, P.; Li, Q.C. A random forest classifier based on pixel comparison features for urban LiDAR data. ISPRS J. Photogramm. Remote Sens. 2019, 148, 75–86. [Google Scholar] [CrossRef]
- Zaboli, M.; Rastiveis, H.; Shams, A.; Hosseiny, B.; Sarasua, W.A. Classification of mobile terrestrial Lidar point cloud in urban area using local descriptors. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2019, 42, 1117–1122. [Google Scholar] [CrossRef] [Green Version]
- Niemeyer, J.; Rottensteiner, F.; Sörgel, U.; Heipke, C.A. Hierarchical higher order crf for the classification of airborne lidar point clouds in urban areas. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2016, 41, 655–662. [Google Scholar] [CrossRef] [Green Version]
- Huo, L.Z.; Silva, C.A.; Klauberg, C.; Mohan, M.; Zhao, L.J.; Tang, P.; Hudak, A.T. Supervised spatial classification of multispectral LiDAR data in urban areas. PLoS ONE 2018, 13, e0206185. [Google Scholar] [CrossRef]
- Morsy, S.; Shaker, A.; El-Rabbany, A. Multispectral LiDAR data for land cover classification of urban areas. Sensors 2017, 17, 958. [Google Scholar] [CrossRef] [Green Version]
- Morsy, S.; Shaker, A.; El-Rabbany, A. Clustering of multispectral airborne laser scanning data using Gaussian decomposition. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, 42, 269–276. [Google Scholar] [CrossRef] [Green Version]
- Becker, C.; Häni, N.; Rosinskaya, E.; d’Angelo, E.; Strecha, C. Classification of aerial photogrammetric 3D point clouds. arXiv 2017, arXiv:1705.08374. [Google Scholar] [CrossRef] [Green Version]
- Zhou, M.; Kang, Z.; Wang, Z.; Kong, M. Airborne lidar point cloud classification fusion with dim point cloud. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 375–382. [Google Scholar] [CrossRef]
- Megahed, Y.; Yan, W.Y.; Shaker, A. Semi-automatic approach for optical and LiDAR data integration using phase congruency model at multiple resolutions. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, 43, 611–618. [Google Scholar] [CrossRef]
- Megahed, Y.; Yan, W.Y.; Shaker, A. A phase-congruency-based scene abstraction approach for 2d-3d registration of aerial optical and LiDAR images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 964–981. [Google Scholar] [CrossRef]
- Zhang, J.; Lin, X. Filtering airborne LiDAR data by embedding smoothness-constrained segmentation in progressive TIN densification. ISPRS J. Photogramm. Remote Sens. 2013, 81, 44–59. [Google Scholar] [CrossRef]
- Li, Y.; Yong, B.; Wu, H.; An, R.; Xu, H.; Xu, J.; He, Q. Filtering airborne lidar data by modified white top-hat transform with directional edge constraints. Photogramm. Eng. Remote Sens. 2014, 80, 133–141. [Google Scholar] [CrossRef]
- Meng, X. Determining Urban Land Uses through Building-Associated Element Attributes Derived from Lidar and Aerial Photographs. Ph.D. Dissertation, Texas State University, San Marcos, YX, USA, 2010. [Google Scholar]
- Shan, J.; Aparajithan, S. Urban DEM generation from raw LiDAR data. Photogramm. Eng. Remote. Sens. 2005, 71, 217–226. [Google Scholar] [CrossRef] [Green Version]
- Sohn, G.; Dowman, I.J. A model-based approach for reconstructing a terrain surface from airborne LIDAR data. Photogramm. Rec. 2008, 23, 170–193. [Google Scholar] [CrossRef]
- Milledge, D.G.; Lane, S.N.; Warburton, J. The potential of digital filtering of generic topographic data for geomorphological research. Earth Surf. Process. Landf. 2009, 34, 63–74. [Google Scholar] [CrossRef]
- Axelsson, P.E. DEM generation from laser scanner data using adaptive TIN models. Int. Arch. Photogramm. Remote. Sens. Spat. Inf. Sci. 2000, 32 Pt B4/1, 110–117. [Google Scholar]
- GIS Geography. Image Classification Techniques in Remote Sensing. GIS Geography Website. Available online: http://gisgeography.com/image-classification-techniques-remote-sensing (accessed on 5 March 2020).
- Chen, D.; Stow, D. The effect of training strategies on supervised classification at different spatial resolutions. Photogramm. Eng. Remote Sens. 2002, 68, 1155–1162. [Google Scholar]
- Huang, X.; Weng, C.; Lu, Q.; Feng, T.; Zhang, L. Automatic labelling and selection of training samples for high-resolution remote sensing image classification over urban areas. Remote Sens. 2015, 7, 16024–16044. [Google Scholar] [CrossRef] [Green Version]
- Jensen, J.R. Introductory Digital Image Processing: A Remote Sensing Perspective, 2nd ed.; Prentice-Hall Inc.: Upper Saddle River, NJ, USA, 1996. [Google Scholar]
- Brownlee, J. Probability for machine learning: Discover how to harness uncertainty with Python. In Machine Learning Mastery; 2000; Available online: https://books.google.com.hk/books?id=uU2xDwAAQBAJ&pg=PP1&lpg=PP1&dq=Probability+for+machine+learning:+discover+how+to+harness+uncertainty+with+Python&source=bl&ots=Bawvg5zIG6&sig=ACfU3U31uLA2M4n5MjbDXwISjuwZyr-OYw&hl=zh-TW&sa=X&redir_esc=y&hl=zh-CN&sourceid=cndr#v=onepage&q=Probability%20for%20machine%20learning%3A%20discover%20how%20to%20harness%20uncertainty%20with%20Python&f=false (accessed on 30 October 2020).
- Paola, J.D.; Schowengerdt, R.A. A detailed comparison of backpropagation neural network and maximum-likelihood classifiers for urban land use classification. IEEE Trans. Geosci. Remote Sens. 1995, 33, 981–996. [Google Scholar] [CrossRef]
- Maselli, F.; Conese, C.; Petkov, L.; Resti, R. Inclusion of prior probabilities derived from a nonparametric process into the maximum-likelihood classifier. Photogramm. Eng. Remote Sens. 1992, 58, 201–207. [Google Scholar]
- Otukei, J.R.; Blaschke, T. Land cover change assessment using decision trees, support vector machines and maximum likelihood classification algorithms. Int. J. Appl. Earth Obs. Geoinf. 2010, 12, S27–S31. [Google Scholar] [CrossRef]
- Bolstad, P.; Lilles, T.M. Rapid maximum likelihood classification. Photogramm. Eng. Remote Sens. 1991, 57, 67–74. [Google Scholar]
- Brownlee, J. Master machine learning algorithms: Discover how they work and implement them from scratch. In Machine Learning Mastery; 2019; Available online: https://datageneralist.files.wordpress.com/2018/03/master_machine_learning_algo_from_scratch.pdf (accessed on 30 October 2020).
- Brownlee, J. Deep learning with Python: Develop deep learning models on Thaeno and TensorFlow using Keras. In Machine Learning Mastery; 2020; Available online: https://www.coursehero.com/file/32130187/deep-learning-with-pythonpdf/ (accessed on 30 October 2020).
- MissingLink. Seven Types of Neural Network Activation Functions: How to Choose? MissingLink Website. Available online: https://missinglink.ai/guides/neural-network-concepts/7-types-neural-network-activation-functions-right/ (accessed on 28 October 2020).
- Brownlee, J. Ordinal and One-Hot Encodings for Categorical Data. Machine Learning Mastery Website. Available online: https://machinelearningmastery.com/one-hot-encoding-for-categorical-data/ (accessed on 30 October 2020).
- Brownlee, J. Machine Learning Algorithms from Scratch with Python. In Machine Learning Mastery; 2020; Available online: https://scholar.google.ca/scholar?hl=en&as_sdt=0%2C5&as_vis=1&q=Brownlee%2C+J.+Machine+learning+algorithms+from+scratch.+In+Machine+Learning+Mastery%3B+2020.&btnG= (accessed on 30 October 2020).
- Brownlee, J. Difference between a Batch and an Epoch in a Neural Network. Machine Learning Mastery Website. Available online: https://machinelearningmastery.com/difference-between-a-batch-and-an-epoch/ (accessed on 30 October 2020).
- Brownlee, J. Machine learning mastery with Python: Understand your data, create accurate models and work projects end-to-end. In Machine Learning Mastery; 2020; Available online: https://docplayer.net/60629865-Machine-learning-mastery-with-python.html (accessed on 30 October 2020).
- Gouillart, E. Scikit-Image: Image Processing. Scipy Lecture Notes Website. Available online: https://scipy-lectures.org/packages/scikit-image/index.html (accessed on 16 November 2020).
- OpenCV. OpenCV-Python Tutorials. OpenCV Website. Available online: https://docs.opencv.org/master/d6/d00/tutorial_py_root.html (accessed on 16 November 2020).
- GDAL. GDAL Documentation. GDAL Website. Available online: https://gdal.org/ (accessed on 16 November 2020).
- LAStools. Lasground-New. Rapidlasso GmbH. Available online: https://rapidlasso.com/lastools/lasground (accessed on 1 October 2020).
- LAStools. Lasnoise. Rapidlasso GmbH. Available online: https://rapidlasso.com/lastools/lasnoise/ (accessed on 1 February 2021).
- Ma, X.; Tong, X.; Liu, S.; Luo, X.; Xie, H.; Li, C. Optimized sample selection in SVM classification by combining with DMSP-OLS, Landsat NDVI and GlobeLand30 products for extracting urban built-up areas. Remote Sens. 2017, 9, 236. [Google Scholar] [CrossRef] [Green Version]
- Remote Sensing Note. Maximum Likelihood Classifier. Japan Association of Remote Sensing Website. Available online: http://sar.kangwon.ac.kr/etc/rs_note/rsnote/cp11/cp11-7.htm (accessed on 18 November 2020).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.V.; erplas, J. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Keras. Python and NumPy Utilities: To_categorical Function. Keras Website. Available online: https://keras.io/api/utils/python_utils/#to_categorical-function (accessed on 1 November 2020).
- Brownlee, J. Why One-Hot Encode Data in Machine Learning? Machine Learning Mastery Website. Available online: https://machinelearningmastery.com/why-one-hot-encode-data-in-machine-learning/ (accessed on 1 November 2020).
- Brownlee, J. A Gentle Introduction to the Rectified Linear Unit (ReLU). Machine Learning Mastery Website. Available online: https://machinelearningmastery.com/rectified-linear-activation-function-for-deep-learning-neural-networks/ (accessed on 1 November 2020).
- Brownlee, J. How to Fix the Vanishing Gradients Problem Using the ReLU. Machine Learning Mastery Website. Available online: https://machinelearningmastery.com/how-to-fix-vanishing-gradients-using-the-rectified-linear-activation-function/ (accessed on 1 November 2020).
- Brownlee, J. Softmax Activation Function with Python. Machine Learning Mastery Website. Available online: https://machinelearningmastery.com/softmax-activation-function-with-python/ (accessed on 1 November 2020).
- Keras. Probabilistic Losses. Keras Website. Available online: https://keras.io/api/losses/probabilistic_losses/ (accessed on 1 November 2020).
- Keras. Adam. Keras Website. Available online: https://keras.io/api/optimizers/adam/ (accessed on 1 November 2020).
- Brownlee, J. What Is the Difference between Test and Validation Datasets? Machine Learning Mastery Website. Available online: https://machinelearningmastery.com/difference-test-validation-datasets/ (accessed on 19 November 2020).
- Brownlee, J. What Does Stochastic Mean in Machine Learning? Machine Learning Mastery Website. Available online: https://machinelearningmastery.com/stochastic-in-machine-learning/ (accessed on 7 December 2020).
- Brownlee, J. Embrace Randomness in Machine Learning. Machine Learning Mastery Website. Available online: https://machinelearningmastery.com/randomness-in-machine-learning/ (accessed on 7 December 2020).
- Megahed, Y.; Cabral, P.; Silva, J.; Caetano, M. Land cover mapping analysis and urban growth modelling using remote sensing techniques in greater Cairo region—Egypt. ISPRS Int. J. Geo Inf. 2015, 4, 1750–1769. [Google Scholar] [CrossRef] [Green Version]





















Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Megahed, Y.; Shaker, A.; Yan, W.Y. Fusion of Airborne LiDAR Point Clouds and Aerial Images for Heterogeneous Land-Use Urban Mapping. Remote Sens. 2021, 13, 814. https://doi.org/10.3390/rs13040814
Megahed Y, Shaker A, Yan WY. Fusion of Airborne LiDAR Point Clouds and Aerial Images for Heterogeneous Land-Use Urban Mapping. Remote Sensing. 2021; 13(4):814. https://doi.org/10.3390/rs13040814
Chicago/Turabian StyleMegahed, Yasmine, Ahmed Shaker, and Wai Yeung Yan. 2021. "Fusion of Airborne LiDAR Point Clouds and Aerial Images for Heterogeneous Land-Use Urban Mapping" Remote Sensing 13, no. 4: 814. https://doi.org/10.3390/rs13040814
APA StyleMegahed, Y., Shaker, A., & Yan, W. Y. (2021). Fusion of Airborne LiDAR Point Clouds and Aerial Images for Heterogeneous Land-Use Urban Mapping. Remote Sensing, 13(4), 814. https://doi.org/10.3390/rs13040814