
CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection


Abstract
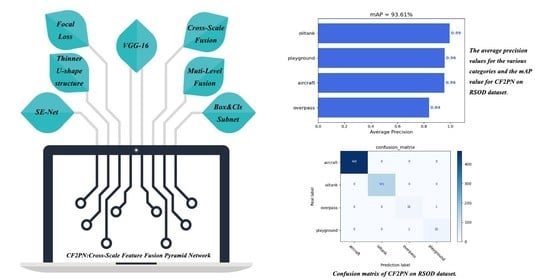
:
1. Introduction
- The remote sensing images are much larger in size than natural images, leading to a large number of samples being treated as the background when extracting candidate boxes and thus causing object class imbalances.
- The complex scenes of remote sensing images allow them to be characterized by inter-class diversity and intra-class similarities.
- Remote sensing images generally have a larger field of view, i.e., objects are smaller relative to the size of the image, and small and tiny objects are difficult to deal with.
- This paper proposes a multi-scale feature fusion and multi-level pyramid network that improves the M2Det to address the problem of inter-class similarities and intra-class diversity caused by remote sensing images with complex and variable scenes.
- To balance the amount of positive and negative samples from the background to the object in remote sensing images we adopt the focal loss function.
- We use the method of cross-scale feature fusion to enhance the association between scene contexts.
2. Materials and Methods
2.1. Related Work
2.2. Proposed Method
2.2.1. Backbone Network
2.2.2. CSFM
2.2.3. TUM
2.2.4. FFM2
2.2.5. SFAM
2.2.6. Classification and Regression Subnets
2.2.7. Loss Function
| Algorithm 1: The procedure of CF2PN |
| Input:, refers to input remote sensing images. |
| Step 1: Input to the VGG-16 network to generate feature maps P. |
| = {, , , , } |
| Step 2:= (, , , , ), gets Base Feature by . |
| Step 3: refers to the list of feature maps by |
| = [] |
| for in range (1, 9) |
| if = 1 |
| = (Conv(Base feature)) |
| else 1 |
| = ((Base feature, )) |
| = .append() |
| Step 4: Enter into the to obtain six different scale of the feature maps . |
| Output: Predict into classification and regression subnets and obtain predict results. |
3. Experiments
3.1. DIOR Dataset
3.2. RSOD Dataset
3.3. Evaluation Metrics
3.4. Training Details
4. Results and Discussion
4.1. Experimental Results and Analysis
4.2. Comparative Experiment
4.3. Ablation Experiments and Discussion
5. Conclusions
Author Contributions
Funding
Informed Consent Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| CF2PN | Cross-scale Feature Fusion Pyramid Network |
| CSFM | Cross-scale Fusion Module |
| TUM | Thinning U-shaped Module |
| DIOR | object DetectIon in Optical Remote sensing images |
| SOTA | State Of The Art |
| M2Det | A Single-Shot Object Detector based on Multi-Level Feature Pyramid Network |
| HOG | Histogram of Oriented Gradient |
| SVM | Support Vector Machine |
| CNN | Convolutional Neural Network |
| R-CNN | Region- Convolutional Neural Network |
| RPN | Region Proposal Network |
| YOLO | You Only Look Once |
| MIF-CNN | Multi-scale Image block-level Fully Convolutional Neural Network |
| FFPN | Feature Fusion Deep Networks |
| CPN | Category Prior Network |
| SCFPN | Scene Contextual Feature Pyramid Network |
| SCRDet | Towards More Robust Detection for Small, Cluttered and Rotated Objects |
| InLD | Instance Level Denoising |
| SPPNet | Spatial Pyramid Pooling Network |
| MLFPN | Multi-level Feature Pyramid Network |
| SSD | Single Shot MultiBox Detector |
| NMS | Non-Maximum Suppression |
| VGG | Visual Geometry Group |
| SENet | Squeeze-and-Excitation Network |
| FFM | Feature Fusion Module |
| ReLU | Rectified Linear Unit |
| IOU | Intersection-Over-Union |
| SGD | Stochastic gradient descent |
| GT | Ground Truth |
| ResNet | Residual Network |
| TP | True Positive |
| FP | False Positive |
| FN | False Negative |
| TN | True Negative |
| AP | Average Precision |
| Map | Mean Average Precision |
References
- Hou, Y.; Zhu, W.; Wang, E. Hyperspectral Mineral Target Detection Based on Density Peak. Intell. Autom. Soft Comput. 2019, 25, 805–814. [Google Scholar] [CrossRef]
- Sun, L.; Wu, F.; He, C.; Zhan, T.; Liu, W.; Zhang, D. Weighted Collaborative Sparse and L1/2 Low-Rank Regularizations With Superpixel Segmentation for Hyperspectral Unmixing. IEEE Geosci. Remote Sens. Lett. 2020. [Google Scholar] [CrossRef]
- Papageorgiou, C.P.; Oren, M.; Poggio, T. A general framework for object detection. In Proceedings of the Sixth International Conference on Computer Vision, Bombay, India, 4–7 January 1998. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), San Diego, CA, USA, 20–26 June 2005; pp. 886–893. [Google Scholar]
- Fu, L.; Li, Z.; Ye, Q. Learning Robust Discriminant Subspace Based on Joint L2,p- and L2,s-Norm Distance Metrics. IEEE Trans. Neural Netw. Learn. Syst. 2020. [Google Scholar] [CrossRef] [PubMed]
- Ye, Q.; Li, Z.; Fu, L.; Yang, W.; Yang, G. Nonpeaked Discriminant Analysis for Data Representation. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3818–3832. [Google Scholar] [CrossRef] [PubMed]
- Ye, Q.; Yang, J.; Liu, F.; Zhao, C.; Ye, N.; Yin, T. L1-Norm Distance Linear Discriminant Analysis Based on an Effective Iterative Algorithm. IEEE Trans. Circuits Syst. Video Technol. 2018, 28, 114–129. [Google Scholar] [CrossRef]
- Ye, Q.; Zhao, H.; Li, Z.; Yang, X.; Gao, S.; Yin, T.; Ye, N. L1-norm Distance Minimization Based Fast Robust Twin Support Vector k-plane clustering. IEEE Trans. Neural Netw. Learn. Syst. 2018, 29, 4494–4503. [Google Scholar] [CrossRef]
- Gunn, S.R. Support vector machines for classification and regression. ISIS Tech. Rep. 1998, 14, 5–16. [Google Scholar]
- Xu, F.; Zhang, X.; Xin, Z.; Yang, A. Investigation on the Chinese Text Sentiment Analysis Based on ConVolutional Neural Networks in Deep Learning. Comput. Mater. Contin. 2019, 58, 697–709. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Li, C.; Liu, Q. R2N: A Novel Deep Learning Architecture for Rain Removal from Single Image. Comput. Mater. Contin. 2019, 58, 829–843. [Google Scholar] [CrossRef] [Green Version]
- Wu, H.; Liu, Q.; Liu, X. A Review on Deep Learning Approaches to Image Classification and Object Segmentation. Comput. Mater. Contin. 2019, 60, 575–597. [Google Scholar] [CrossRef] [Green Version]
- Zhang, X.; Lu, W.; Li, F.; Peng, X.; Zhang, R. Deep Feature Fusion Model for Sentence Semantic Matching. Comput. Mater. Contin 2019, 61, 601–616. [Google Scholar] [CrossRef]
- Hung, C.; Mao, W.; Huang, H. Modified PSO Algorithm on Recurrent Fuzzy Neural Network for System Identification. Intell. Auto Soft Comput. 2019, 25, 329–341. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate target detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–27 June 2014; pp. 580–587. [Google Scholar]
- Everingham, M.; VanGool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes (VOC) Challenge. IJCV 2010, 88, 303–338. [Google Scholar] [CrossRef] [Green Version]
- Li, X.; Shang, M.; Qin, H.; Chen, L. Fast Accurate Fish Detection and Recognition of Underwater Images with Fast R-CNN; IEEE: Piscataway, NJ, USA, 2015; pp. 921–925. [Google Scholar]
- Qian, R.; Liu, Q.; Yue, Y.; Coenen, F.; Zhang, B. Road Surface Traffic Sign Detection with Hybrid Region Proposal and Fast R-CNN; IEEE: Piscataway, NJ, USA, 2016; pp. 555–559. [Google Scholar]
- Wang, K.; Dong, Y.; Bai, H.; Zhao, Y.; Hu, K. Use Fast R-CNN and Cascade Structure for Face Detection; IEEE: Piscataway, NJ, USA, 2016; p. 4. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Target detection with Region Proposal Networks. In Advances in Neural Information Processing Systems; IEEE: Piscataway, NJ, USA, 2015; Volume 28. [Google Scholar]
- Mhalla, A.; Chateau, T.; Gazzah, S.; Ben Amara, N.E.; Assoc Comp, M. PhD Forum: Scene-Specific Pedestrian Detector Using Monte Carlo Framework and Faster R-CNN Deep Model; IEEE: Piscataway, NJ, USA, 2016; pp. 228–229. [Google Scholar]
- Zhai, M.; Liu, H.; Sun, F.; Zhang, Y. Ship Detection Based on Faster R-CNN Network in Optical Remote Sensing Images; Springer: Singapore, 2020; pp. 22–31. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Target detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Zhang, X.; Qiu, Z.; Huang, P.; Hu, J.; Luo, J. Application Research of YOLO v2 Combined with Color Identification. In Proceedings of the 2018 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery, Zhengzhou, China, 18–20 October 2018; pp. 138–141. [Google Scholar]
- Itakura, K.; Hosoi, F. Automatic Tree Detection from Three-Dimensional Images Reconstructed from 360 degrees Spherical Camera Using YOLO v2. Remote Sens. 2020, 12, 988. [Google Scholar] [CrossRef] [Green Version]
- Bi, F.; Yang, J. Target Detection System Design and FPGA Implementation Based on YOLO v2 Algorithm; IEEE: Singapore, 2019; pp. 10–14. [Google Scholar]
- Redmon, J.; Ali, F. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Zhang, X.; Yang, W.; Tang, X.; Liu, J. A Fast Learning Method for Accurate and Robust Lane Detection Using Two-Stage Feature Extraction with YOLO v3. Sensors 2018, 18, 4308. [Google Scholar] [CrossRef] [Green Version]
- Adarsh, P.; Rathi, P.; Kumar, M. YOLO v3-Tiny: Target detection and Recognition Using One Stage Improved Model; IEEE: Piscataway, NJ, USA, 2020; pp. 687–694. [Google Scholar]
- Liu, G.; Nouaze, J.C.; Mbouembe, P.L.T.; Kim, J.H. YOLO-Tomato: A Robust Algorithm for Tomato Detection Based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Liu, M.; Wang, X.; Zhou, A.; Fu, X.; Ma, Y.; Piao, C. UAV-YOLO: Small Object Detection on Unmanned Aerial Vehicle Perspective. Sensors 2020, 20, 2238. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Gu, J.; Huang, Z.; Wen, J. Application Research of Improved YOLO V3 Algorithm in PCB Electronic Component Detection. Appl. Sci. 2019, 9, 3750. [Google Scholar] [CrossRef] [Green Version]
- Huang, Z.; Wang, J. DC-SPP-YOLO: Dense connection and spatial pyramid pooling based YOLO for target detection. Inf. Sci. 2020, 522, 241–258. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Fu, C.; Berg, A.C. SSD: Single Shot Multibox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 2–29 October 2017; pp. 2980–2988. [Google Scholar]
- Zhao, W.; Ma, W.; Jiao, L.; Chen, P.; Yang, S.; Hou, B. Multi-scale image block-level f-cnn for remote sensing images target detection. IEEE Access 2019, 7, 43607–43621. [Google Scholar] [CrossRef]
- Sergievskiy, N.; Ponamarev, A. Reduced focal loss: 1st place solution to xview target detection in satellite imagery. arXiv 2019, arXiv:1903.01347. [Google Scholar]
- Chen, C.; Gong, W.; Chen, Y.; Li, W. Target detection in remote sensing images based on a scene-contextual feature pyramid network. Remote Sensing 2019, 11, 339. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Yang, J.; Yan, J.; Zhang, Y.; Zhang, T.; Guo, Z. SCRDet: Towards more robust detection for small, cluttered and rotated objects. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 22 April 2019; pp. 8232–8241. [Google Scholar]
- Yang, X.; Yan, J.; Yang, X.; Tang, J.; Liao, W.; He, T. SCRDet++: Detecting small, cluttered and rotated objects via instance-level feature denoising and rotation loss smoothing. arXiv 2020, arXiv:2004.13316. [Google Scholar]
- Li, K.; Wan, G.; Cheng, G.; Meng, L.; Han, J. Target detection in optical remote sensing images: A survey and a new benchmark. ISPRS 2020, 159, 296–307. [Google Scholar]
- Zhao, Q.; Sheng, T.; Wang, Y.; Tang, Z.; Ling, H. M2det: A single-shot object detector based on multi-level feature pyramid network. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 9259–9266. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-YOLOv4: Scaling Cross Stage Partial Network. arXiv 2020, arXiv:2011.08036. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Wu, E. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7132–7141. [Google Scholar]
- Sun, L.; Tang, Y.; Zhang, L. Rural Building Detection in High-Resolution Imagery Based on a Two-Stage CNN Model. IEEE Geosci. Remote Sens. Lett. 2017, 14, 1998–2002. [Google Scholar] [CrossRef]
- Cheng, G.; Zhou, P.; Han, J. Learning Rotation-Invariant Convolutional Neural Networks for Target detection in VHR Optical Remote Sensing Images. IEEE Geosci. Remote Sens. 2016, 54, 7405–7415. [Google Scholar] [CrossRef]
- Chen, C.Y.; Gong, W.G.; Hu, Y.; Chen, Y.L.; Ding, Y. Learning Oriented Region-based Convolutional Neural Networks for Building Detection in Satellite Remote Sensing Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2017, XLII-1/W1, 461–464. [Google Scholar] [CrossRef] [Green Version]
- Deng, Z.; Sun, H.; Zhou, S.; Zhao, J.; Lei, L.; Zou, H. Multi-scale target detection in remote sensing imagery with convolutional neural networks. ISPRS J. Photogramm. Remote Sens. 2018, 145, 3–22. [Google Scholar] [CrossRef]
- Yang, X.; Sun, H.; Fu, K.; Yang, J.; Sun, X.; Yan, M.; Guo, Z. Automatic Ship Detection in Remote Sensing Images from Google Earth of Complex Scenes Based on Multiscale Rotation Dense Feature Pyramid Networks. Remote Sens. 2018, 10, 132. [Google Scholar] [CrossRef] [Green Version]
- Gao, X.; Sun, X.; Zhang, Y.; Yan, M.; Xu, G.; Sun, X.; Jiao, J.; Fu, K. An end-to-end neural network for road extraction from remote sensing imagery by multiple feature pyramid network. IEEE Access. 2018, 6, 39401–39414. [Google Scholar] [CrossRef]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages | Defects |
|---|---|---|
| R-CNN | CNN accelerated feature extraction. | Unable to achieve end-to-end; limited by selective search algorithm. |
| Fast-RCNN | The addition of SPPNet [17,18,19] effectively avoids the loss of spatial information. | Limited by selective search algorithm. |
| Faster-RCNN | Introduction of RPN instead of selective search algorithm improves detection speed. | Selective search and detection are divided into two stages resulting in slow speed; poor detection for small targets. |
| YOLO | Converts the target detection task into a regression problem, greatly speeding up detection. | Detection for small targets and objects close to each other will not be effective. |
| SSD | Achieved multi-scale detection. | The feature map extracted first is large, but the semantic information is not enough, and the semantic information extracted later is rich and the feature map is too small, resulting in small target detection effect. |
| RetinaNet | The focal loss function is introduced to effectively solve the problem of positive and negative sample imbalance | Using the FPN network, each feature map is represented by a single layer of the backbone, resulting in less comprehensive extracted features. |
| M2Det | The introduction of the new feature pyramid solves the defect that the feature map of each scale in the traditional feature pyramid contains only single level or few levels of features. | Only the features of the last two layers of the backbone network are used for fusion, and a large amount of semantic information is lost, which is not significant enough for direct application to remote sensing images |
| M2Det | ||
|---|---|---|
| VGG-16 | x1, x2, x3, x4, x5 | Convolution |
| FFMv1 | Base Feature = Concatenation (x4, x5) | Fusion |
| TUM × 7 | p1, p2, p3, p4, p5, p6 | Fusion |
| FFMv2 × 7 | Concatenation (Base Feature, p1) | Fusion |
| TUM | f1, f2, f3, f4, f5, f6 | Fusion |
| SFAM | SFAM (f1, f2, f3, f4, f5, f6) | Reweight |
| CF2PN | ||
|---|---|---|
| VGG-16 | x1, x2, x3, x4, x5 | Convolution |
| CSFM | Base Feature = Concatenation (x1, x2, x3, x4, SE(x5)) | Fusion |
| TUM × 7 | p1, p2, p3, p4, p5, p6 | Fusion |
| FFM2 × 7 | Concatenation (Base Feature, p1) | Fusion |
| TUM | f1, f2, f3, f4, f5, f6 | Fusion |
| SFAM | SFAM (f1, f2, f3, f4, f5, f6) | Reweight |
| Class and Box Subnets × 5 | t1, t2, t3, t4, t5, t6 | Convolution |
| Class | Image | Instances |
|---|---|---|
| Aircraft | 446 | 4993 |
| Oil tank | 165 | 1586 |
| Overpass | 176 | 180 |
| Playground | 189 | 191 |
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| airplane | airport | bridge | vehicle | ship | expressway toll station | golf field | harbor | chimney | dam |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| overpass | stadium | train station | storage tank | ground track field | tennis court | expressway service area | windmill | basketball court | baseball field |
| Detection Methods | Backbone | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | Class | mAP (%) | F1 Score (%) |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Network | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |||
| Faster RCNN [20] | ResNet-101 | 41.28 | 67.47 | 66.01 | 81.36 | 18.24 | 69.21 | 38.35 | 55.81 | 32.58 | 68.73 | 48.96 | 34.14 | 43.66 | 18.5 | 51.02 | 19.96 | 71.81 | 41.37 | 5.76 | 41.03 | 45.76 | 26.06 |
| SSD [34] | VGG-16 | 82.55 | 54.79 | 78.76 | 88.92 | 35.75 | 74.39 | 52.02 | 71.39 | 58.67 | 52.21 | 74.9 | 44.52 | 49.59 | 78.35 | 69.32 | 60.12 | 89.92 | 38.23 | 39.54 | 82.46 | 63.82 | 40.58 |
| RetinaNet [35] | ResNet-101 | 75.39 | 70.3 | 73.39 | 85.61 | 31.34 | 72.11 | 62.86 | 78.45 | 50.26 | 74.73 | 76.7 | 56.46 | 53.3 | 72.37 | 71.81 | 48.33 | 87.67 | 41.57 | 26.9 | 78.01 | 64.38 | 38.88 |
| YOLOv3 [27] | Darknet53 | 66.98 | 79.71 | 78.39 | 85.89 | 39.64 | 72.44 | 70.69 | 85.65 | 65.01 | 74.61 | 79.83 | 44.97 | 58.93 | 33.67 | 59.61 | 34.58 | 89.14 | 61.72 | 37.88 | 79.16 | 64.93 | 44.49 |
| YOLOV4-tiny [43] | CSPdarknet53-tiny | 59.22 | 65.01 | 71.55 | 80.01 | 27.13 | 72.49 | 56.2 | 70.39 | 47.22 | 67.3 | 70.16 | 48.41 | 49.97 | 30.65 | 69.43 | 28.35 | 80.56 | 49.49 | 15.49 | 50.94 | 55.5 | 34.52 |
| M2Det [42] | VGG-16 | 68.03 | 78.37 | 69.14 | 88.71 | 31.48 | 71.94 | 68.05 | 74.57 | 48.14 | 73.98 | 73.15 | 54.97 | 54.55 | 29.96 | 68.87 | 30.58 | 85.79 | 54.06 | 17.94 | 65.52 | 60.39 | 37.03 |
| CF2PN | VGG-16 | 78.32 | 78.29 | 76.48 | 88.4 | 37 | 70.95 | 59.9 | 71.23 | 51.15 | 75.55 | 77.14 | 56.75 | 58.65 | 76.06 | 70.61 | 55.52 | 88.84 | 50.83 | 36.89 | 86.36 | 67.25 | 38.01 |
| Detection Methods | Backbone Network | Aircraft | Oil Tank | Overpass | Playground | mAP (%) | F1 Score (%) |
|---|---|---|---|---|---|---|---|
| Faster RCNN [20] | ResNet-101 | 50.20 | 98.12 | 95.45 | 99.31 | 85.77 | 77.00 |
| SSD [34] | VGG-16 | 57.05 | 98.89 | 93.51 | 100.00 | 87.36 | 79.75 |
| RetinaNet [35] | ResNet-101 | 75.01 | 99.23 | 54.68 | 94.66 | 80.90 | 75.75 |
| YOLOv3 [27] | Darknet53 | 84.80 | 99.10 | 81.20 | 100.00 | 91.27 | 88.00 |
| YOLOV4-tiny [43] | CSPdarknet53-tiny | 66.47 | 99.42 | 80.68 | 99.31 | 86.47 | 82.25 |
| M2Det [42] | VGG-16 | 80.99 | 99.98 | 79.10 | 100.00 | 90.02 | 80.50 |
| CF2PN | VGG-16 | 95.52 | 99.42 | 83.82 | 95.68 | 93.61 | 89.25 |
| Detection Methods | mAP(%) | F1 Score(%) | Parameters |
|---|---|---|---|
| M2Det | 60.39 | 37.03 | 86.5M |
| M2Det + CSFM | 57.76 | 35.16 | 86.2M |
| M2Det + focal loss | 63.32 | 32.95 | 91.9M |
| CF2PN | 67.25 | 38.01 | 91.6M |
| Detection Methods | mAP (%) | F1 Score (%) | Parameters |
|---|---|---|---|
| M2Det | 90.02 | 80.50 | 86.5M |
| M2Det + CSFM | 87.30 | 76.75 | 86.2M |
| M2Det + focal loss | 91.00 | 86.50 | 91.9M |
| CF2PN | 93.61 | 89.25 | 91.6M |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Li, G.; Chen, Q.; Ju, M.; Qu, J. CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection. Remote Sens. 2021, 13, 847. https://doi.org/10.3390/rs13050847
Huang W, Li G, Chen Q, Ju M, Qu J. CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection. Remote Sensing. 2021; 13(5):847. https://doi.org/10.3390/rs13050847
Chicago/Turabian StyleHuang, Wei, Guanyi Li, Qiqiang Chen, Ming Ju, and Jiantao Qu. 2021. "CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection" Remote Sensing 13, no. 5: 847. https://doi.org/10.3390/rs13050847
APA StyleHuang, W., Li, G., Chen, Q., Ju, M., & Qu, J. (2021). CF2PN: A Cross-Scale Feature Fusion Pyramid Network Based Remote Sensing Target Detection. Remote Sensing, 13(5), 847. https://doi.org/10.3390/rs13050847